
TiDB 数据库核心原理与架构笔记
1.功能介绍
-
TiDB Server集群(无状态,不存储数据)
- 处理客户端发送的sql语句,进行解析编译优化,生成执行计划
- 如果是insert要将表的数据转换为key和value的形式,向TiKV存储
- 执行online DDL
- 每隔十分钟左右进行垃圾回收(GC)将历史版本数据删除
- 可水平扩展,增强并发处理能力
-
TiKV
-
存储数据(数据持久化),存储引擎集群,默认创建三副本(只有一个leader可以读写,其他都不可以读写,其他的跟着leader变),高可用性
-
存region(行存)
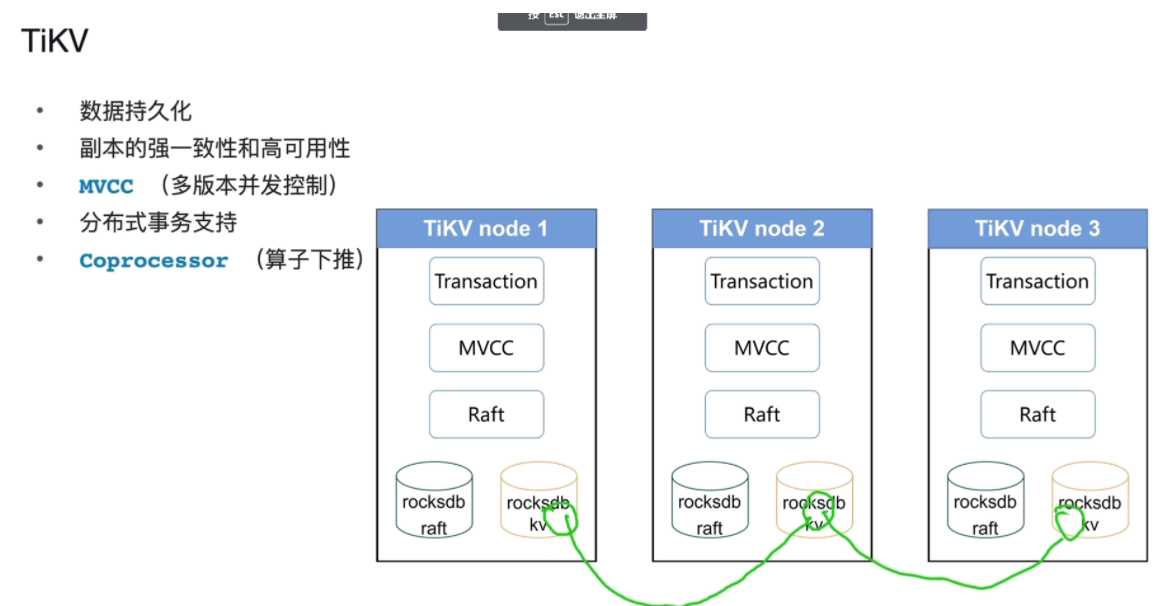
- rocksdb单机的Key-Value存储引擎(内部使用这个数据库保障TiKV的数据持久化)
- rockdbkv(rocksdb实例):将表数据转换为key-value的形式存储在rockdb实例中
- rockdbraft(rocksdb实例):存储表的增删改等指令
- Raft协议(保障了三副本的强一致性)
- MVCC(保障了其他操作可以正常执行,例:读的是修改前的数据)
- Transaction事务层(支持事务)
- 算子下推实际上是一个分布式计算的模型
-
-
TiFlash
- 存储数据,存储引擎集群
- 存region(列存,擅长统计分析数据)
- TiKV行存更多承载在线交易型业务OLTP(事务型)
- TiFlash更多承载分析型业务OLAP(暴力扫描)
- HTAP(OLTP,OLAP)支持
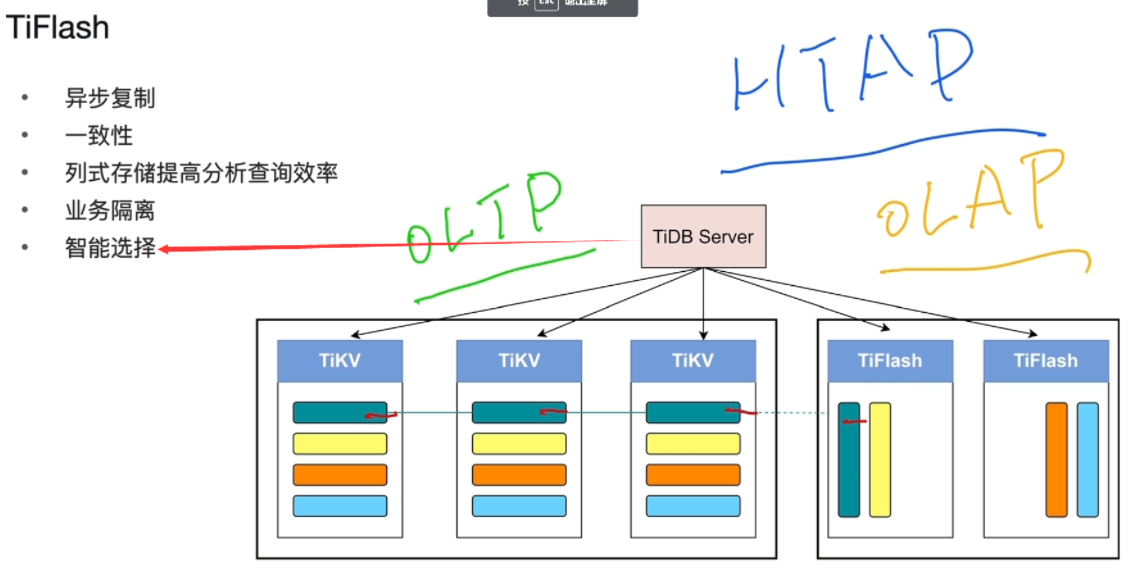
-
region : 96M->144M
- 数据库表切分,分布存储在TiKV
-
PD:PlacementDriver
- 集群的大脑
- 存储想要的表在TiKV,TiFlash的对应位置(这些信息叫做:region 的元数据:表在哪些TiKV,TiFlash上分布信息)region与TiKV,TiFlash的对应关系
- 存储查询每条sql执行的开始时间,结束时间(TSO对时间进行标识,计时器:对一个事务有开始的TSO有结束的TSO)
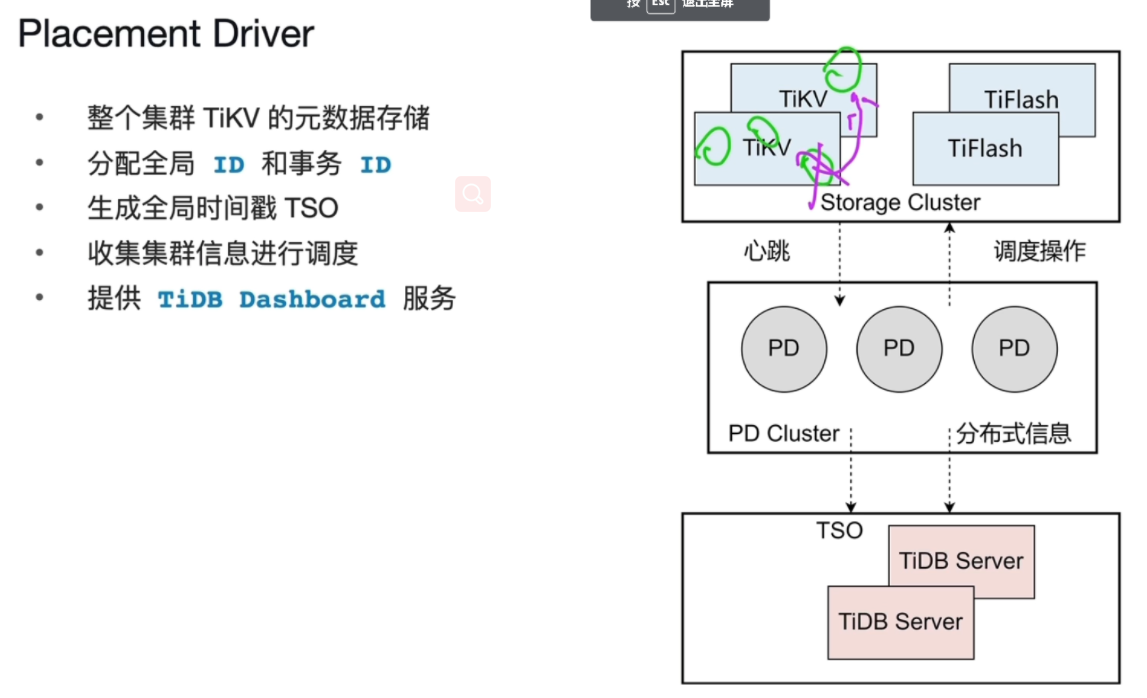
-
体系特点:
- 水平扩容或缩容
- 金融级高可用
- 实时HTAP
- 云原生的分布式数据库
- 兼容MySQL5.7协议




-
题目:


2.TiDBServer详情
-
TiDB server 架构
-
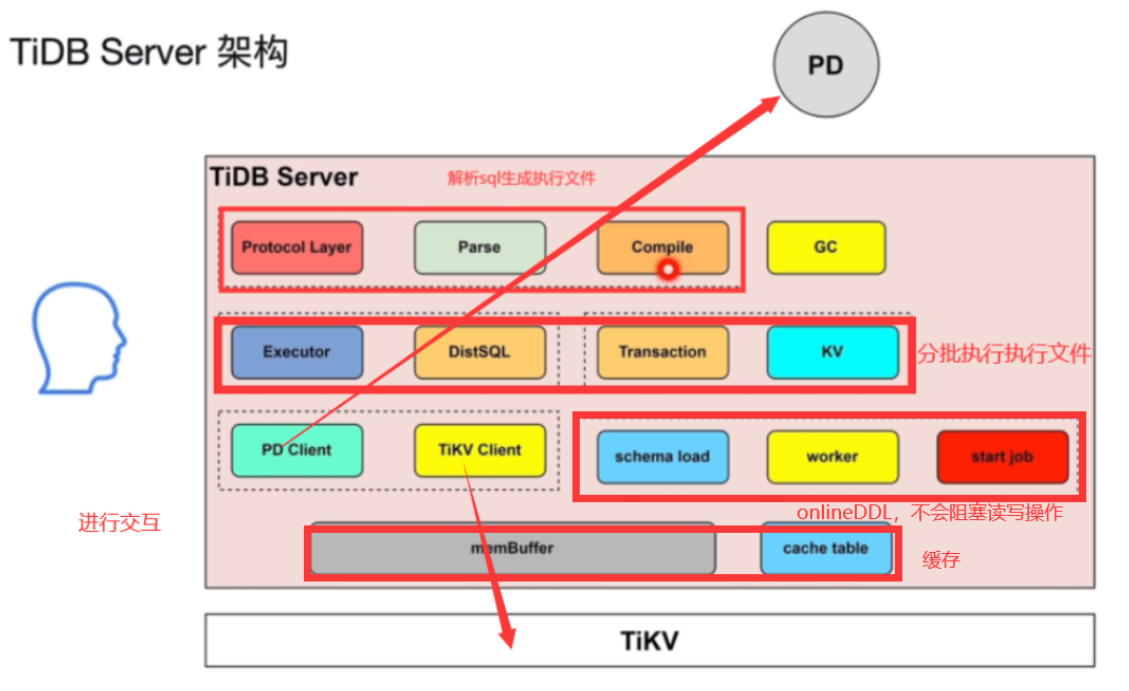
-
功能:

-
处理客户端的连接(Protocol Layer)
-
SQL 语句的解析和编译(Parse,Compile)生成执行计划交由Excutor进行执行
- AST语法树
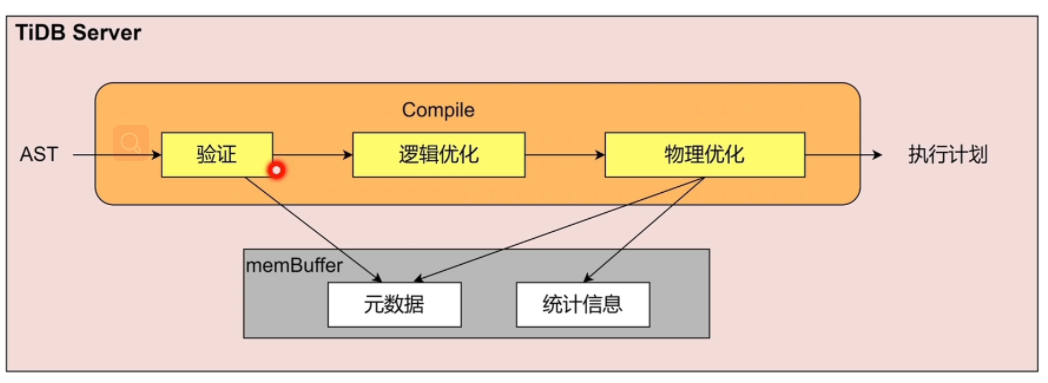
-
关系型数据与 KV 的转化
-
聚簇表:标号+原表主键做主键(主键唯一)

-
region(默认大小96M->144M,超出分裂,分布式存储在TiKV中)

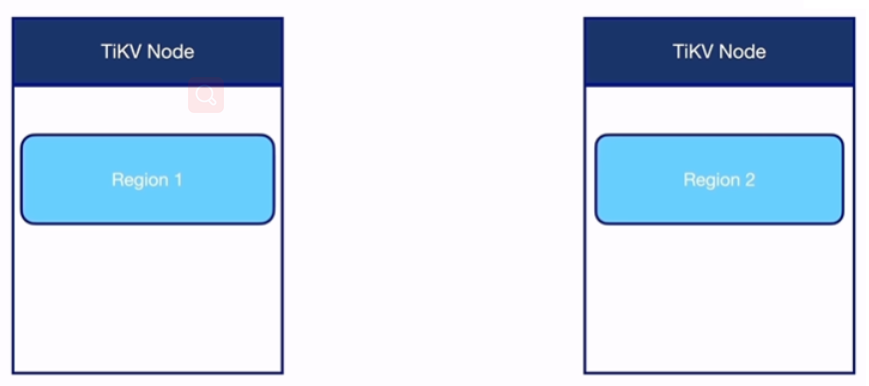
-
-
非聚簇表(自动生成主键)
-
-
SQL 语句的执行
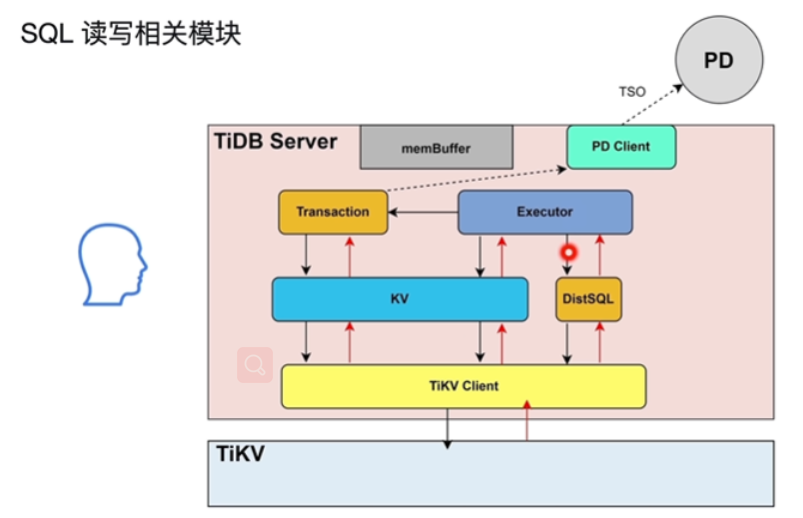
- DistSQL将复杂sql的执行计划转换为单表计算任务组合发送给TiKV,涉及一张表涉及多个region
- 简单查询,点查走KV就不走DistSQL
- Transaction将开始时间和结束时间(TSO)发送给PDClient
-
在线 DDL 的执行
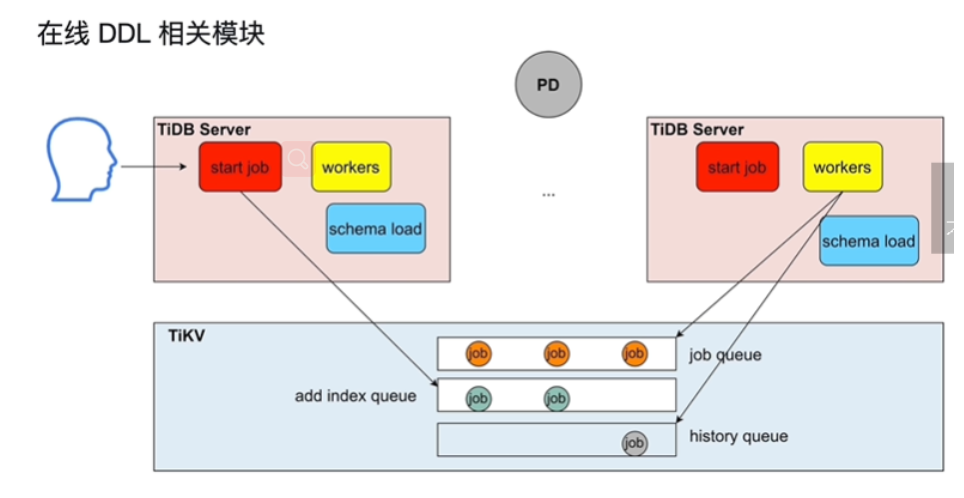
- 对于整个tidb数据库来说,同一时刻只能有一个TiDBServer做DDL操作(worker)
- owner执行job,不是固定的,有任期时长,轮换当owner,谁当owner谁复制执行job队列的DDLJob
- schema load将最新的所有的表信息同步到内部的缓存中,好根据这些信息执行jobqueue里面的job
- TIKV持久化存储
-
垃圾回收(定期清理过期版本的数据)
- GCLifeTime(默认十分钟)保存当前时间到savepoint时间的数据,其他的进行清除
-
热点小表缓存 V6.0 (cacheTable)进一步热点缓存区
-
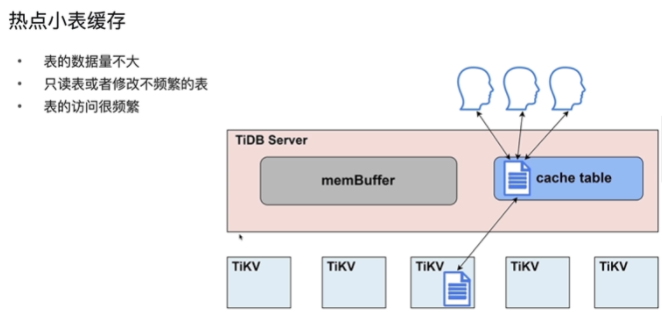
-
解决数据可能不一致的问题(缓存租约,既存在使用时间,租约时间内,可以读,无法进行写操作)
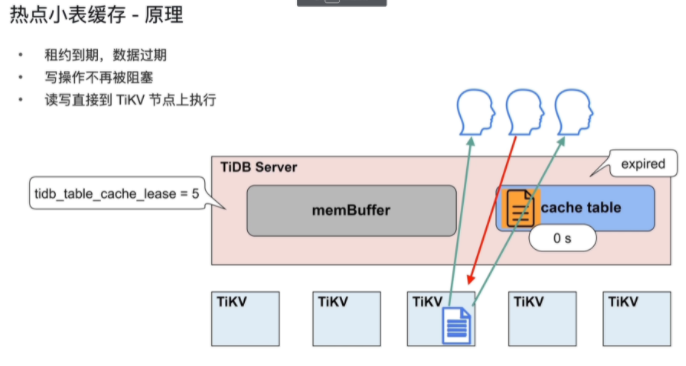
-
应用:
- TiDB 对于每张缓存表的大小限制为 64 MB
- 适用于查询频繁、数据量不大、极少修改的场景
- 在租约 (tidb_table_cache_lease) 时间内,写操作会被阻塞
- 当租约到期 (tidb_table_cache_lease) 时,读性能会下降
- 不支持对缓存表直接做 DDL 操作,需要先关闭
- 对于表加载较慢或者极少修改的表,可以适当延长 tidb_table_cache_lease 保持读性能稳定
-
-
TiDB缓存
-
默认使用TIDB数据库的所有内存
-
使用场景

-
tidb_mem_quota_query限制每条sql占用的缓存
-
oom-action决定超出了上面缓存以后的操作
-
-
-
-
题目:













3.TiKV
-
概述
-
TiKV 架构和作用
- RocksDB (单机kvmap)针对 Flash 存储进行优化,延迟极小,使用 LSM 存储引擎。
- 高性能的 Key-Value 数据库
- 完善的持久化机制,同时保证性能和安全性
- 良好的支持范围查询
- 为需要存储 TB 级别数据到本地 FLASH(固态盘) 或者 RAM 的应用服务器设计
- 针对存储在高速设备的中小键值进行优化 —可以存储在 FLASH 或者直接存储在内存
- 性能随 CPU 数量线性提升,对多核系统友好
- RocksDB (单机kvmap)针对 Flash 存储进行优化,延迟极小,使用 LSM 存储引擎。
-
TiKV 数据持久化和读取
-
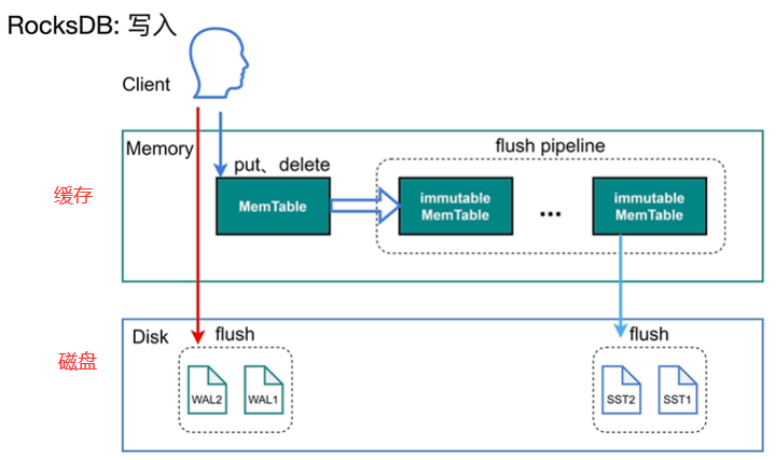
- RSMTree:客户提供(tom,xxx,xxx,xxx,信息)
- 顺序写
- SST(键值对存储,key排好序的,找文件时采用二分查找)
- MenTable,当写的数据大于write_bufffer_size时(写满了后),将数据转存在immutable MenTable中,读时数据永远是最新的
- immutable MenTable(不可修改),刷到磁盘中,防止写阻塞。(设置write stall=5):当immutable MenTable大于5个时,写会限速(流控)
- WAL(日志文件)(预写,防丢失)保障事务的原子性和持久性,设置sync_log=true直接压入磁盘,不经过操作系统的缓存,最后会被SST覆盖

- compaction:当level层数据达到4个时向下压缩到第下一层(压缩,key排好序形成一个SST文件)
- 只需要一次磁盘IO,一次内存IO,比B+树效率高
- 读写只需要操作MenTable即可
- 对写友好,对查询没有那么友好(比B+树查询慢)
-
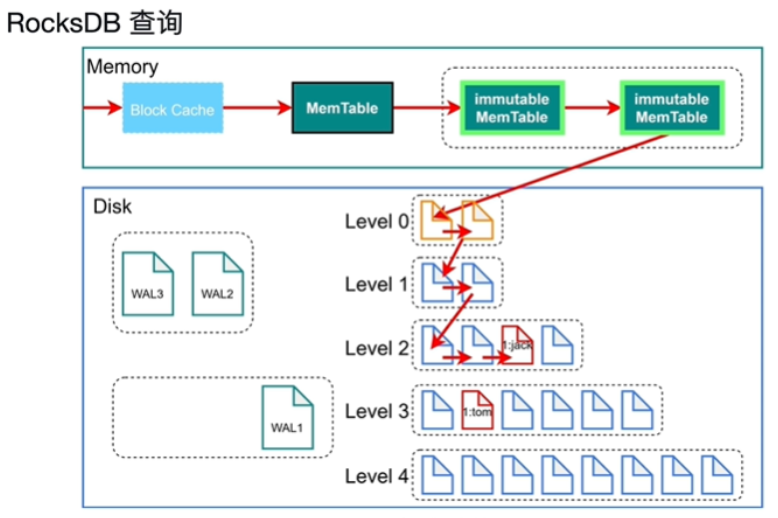
- 每个文件都有一个bloom filter(帮助判断集合中的元素在不在这个文件中,不在肯定不在,在不一定在)
-
列簇(CF)(rocksdb的数据分片技术)按照不同的属性分配不同的Column Familiy(存的是一类属性)

- 写入形式:write(cf1,id,name,age)write(cf2,id,addr,tel),如果没有指定分配列簇会自动加入default列簇
- Column Familiy共享WAL(日志文件不分)
-
-
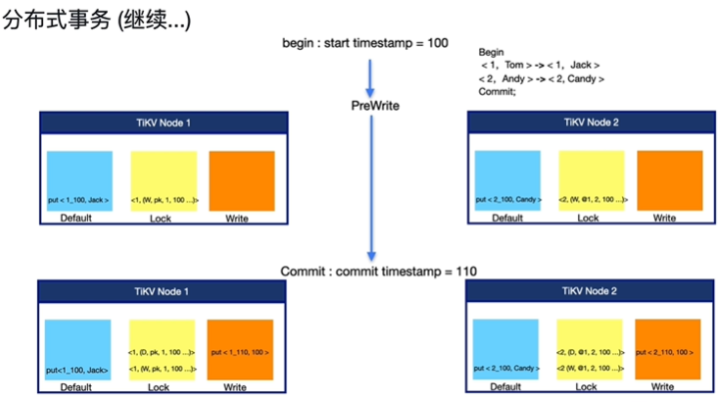
TiKV 如何提供 MVCC 和分布式事务支持
- 事务存储进TiKV
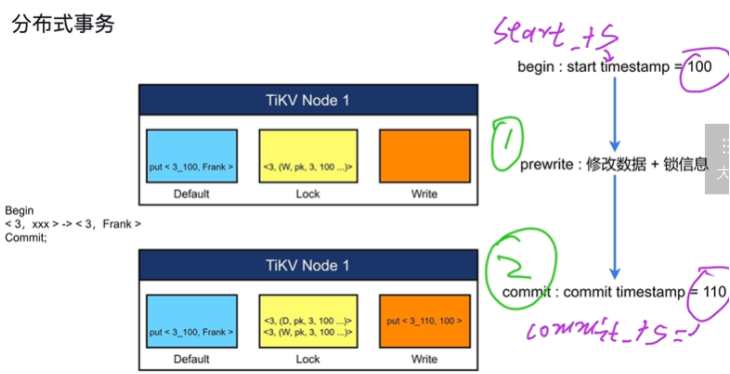
- 存在时间戳TSO
- 提交时修改信息和锁信息被写入TiKV中,才被别人感知(乐观锁),默认乐观锁
- 直接写入TiKV中,被别人感知(悲观锁)
- 一个TiKV节点中对应三个列簇(cf)(
- 修改的数据Default:数据会加时间戳,比如:(3_100)
- 锁信息Lock:只有一把主锁
- 提交信息Write(包括时间戳 )
- write 列:当用户写入了一行数据时,如果该行数据长度小于 255 字节,那么会被存储 write 列中,否则的话该行数据会被存入到 default 列中。
- default 列:用于存储超过 255 字节长度的数据。
- w(写锁)可以读不能写
- pk(主锁):只在分布式事务的第一行加锁
- @1我的主锁在1这,其他行我加是一个主锁指向,随着主锁走的
- 锁释放:加一行去掉锁的语句(将W改为D),不会删除
- 分布式事务解决了原子性问题
- MVCC(多版本并发控制)
- 增删改是以新值进行添加
- 可以读取所有历史版本值,包括未提交的值(悲观锁)
- 不阻塞读,阻塞写操作
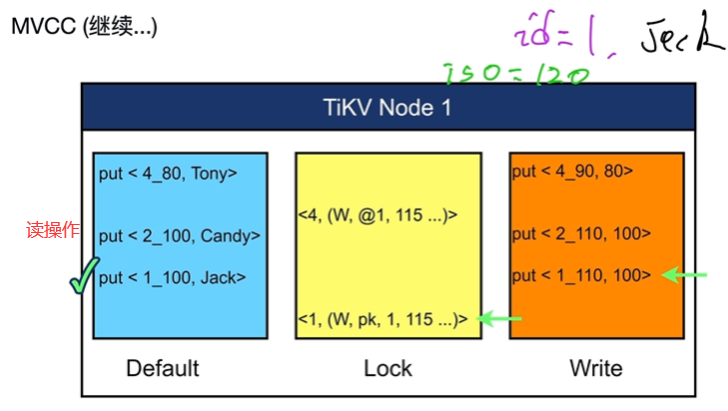
- 事务存储进TiKV
-
TiKV 基于 Raft 算法的分布式一致性
-
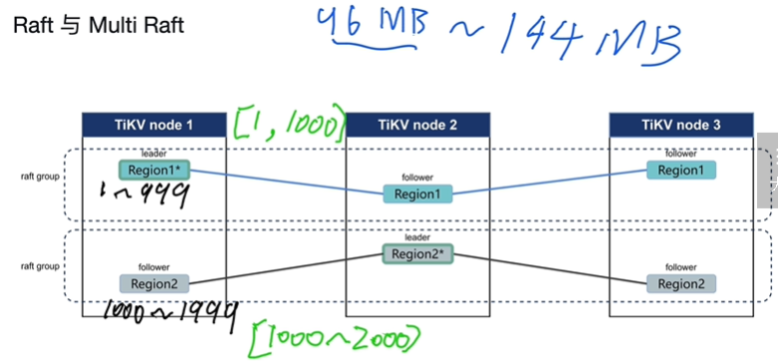
- region超出了分裂,太小合并
- raft group有三个region
- multi raft是多个raft group组成
- candidate (候选者)是由于leader长时间没有统治信息,由follower投票选出来的
- Raft 算法实现了分布式数据的强一致性
- 写数据只写leader,leader将指令变成日志的形式,向所有的follower复制,当大多数节点都收到日志,并持久化后,follower会返回append成功的信息给leader后,leader会apply到rocksdb的kv的编程数据中
- TiKV中超过50000个region后管理成本很高,因为每个region会定期向PD汇报自己的心跳信息,网络压力比较大
-
raft日志复制功能
-
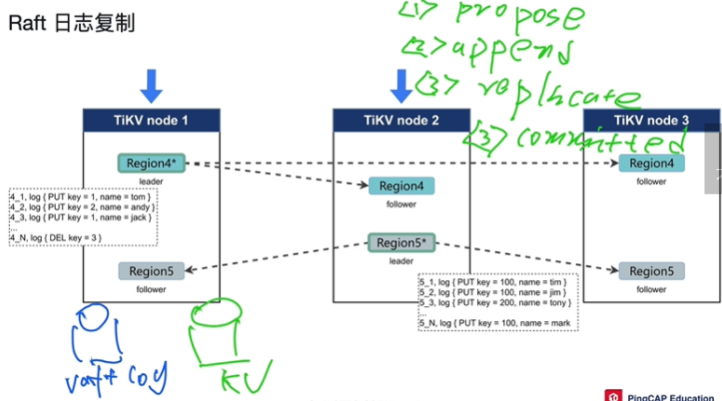
-
第一步:propose,操作被leader收到了,leader准备开始同步
-
第二步:append,将日志写入racksdb中
- 将写入请求变成一条日志,变成一条写入日志,叫做raft log,存到自己的日志文件里(对TiKV存储在本地的racksdb实例中,专门存raft log)
- 唯一标识:region号_日志当前序号.log,从标识找到先后顺序,哪个region发出的知道
- Replicate:将leader的日志分发复制给其他follower所在节点。其他节点持久化到存储中后,会返回响应值(append成功的信息)给leader后,超过一半以上的节点给了回应后,leader会apply到rocksdb的kv的编程数据中
-
第三步:commited,大多数region表示append成功持久化消息后TiKV会将这条日志取出来,应用转换为数据写在另一个rocksdb中,叫做rocksdbKV
-
第四步:apply
-
有两个rocksdb实例,一个是log一个是kv
-
-
leader选举

- term:时长不固定
- election timeout=10s,未发送心跳信息时超过10s后,就认为现在集群就处于没有leader的状态,开始投票选自己,可能会重复选举
- random election timeout 降低重复选举的概率
- candidate (候选者)发请求,我要当leader,term大的candidate 成为leader
- heatbeat time interal = 10s leader固定10s发送心跳信息

-
-
TiKV 的 Coprocessor(协同处理器,提供算子下推的能力)
-
数据写入
-
数据读取(主要解决读取数据时保证是从leader中读)
- readIndex Read
- 等读
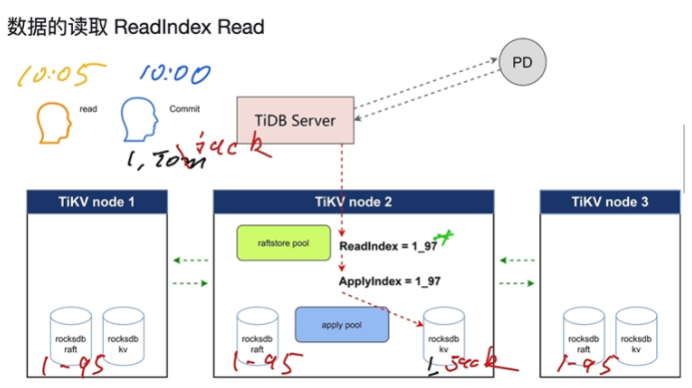

- LeaseRead(优化)localRead
- FollowerRead
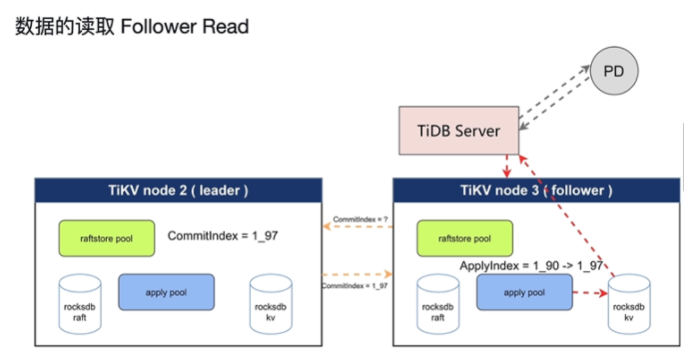
- 和leader中的数据保持线性一致
- readIndex Read
-
Coprocessor
-
-
题目:



















4.PD(Placement Driver)
-
描述 PD 的架构与功能
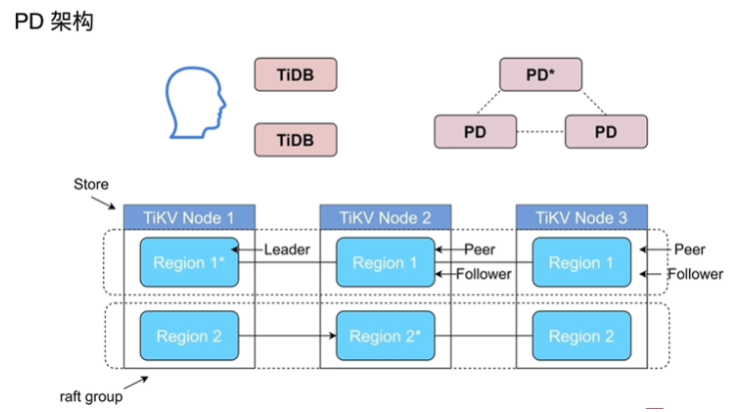
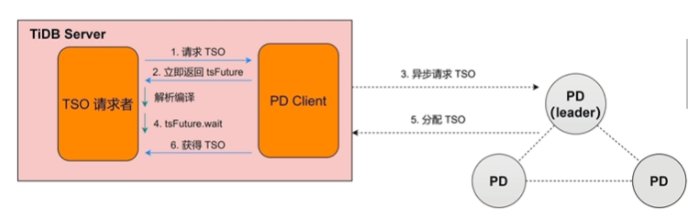
- PD有三个,有leader,只有leader可以获得TSO
- 整个集群 TiKV 的元数据存储,region在哪个TIKV上
- 分配全局 ID 和事务 ID
- 生成全局时间戳 TSO
- 收集集群信息进行调度
- 提供 label, 支持高可用(打标签)
- 提供 TiDB Dashboard
- 路由功能
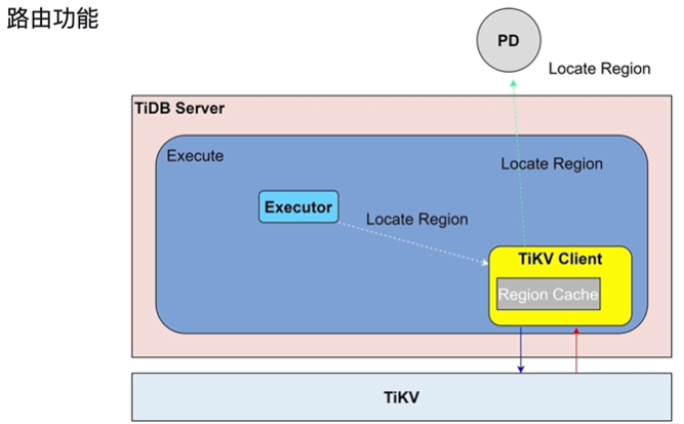
- 找region在哪个TIKV上
- TiDBClient缓存TiKVRegion位置,有时不需要从PD中获取Region位置,减轻缓存压力
- 数据太旧,可能重新访问PD写到TiKVClient
-
描述 TSO 的分配
-
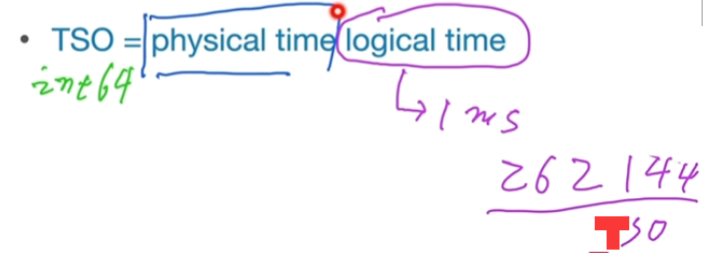
TSO = physical time + logical time
-
-
TSO 是64位的整形数
-
TSO 分配
- 某个时间段有批处理功能
- 解决IO存储性能瓶颈方法:
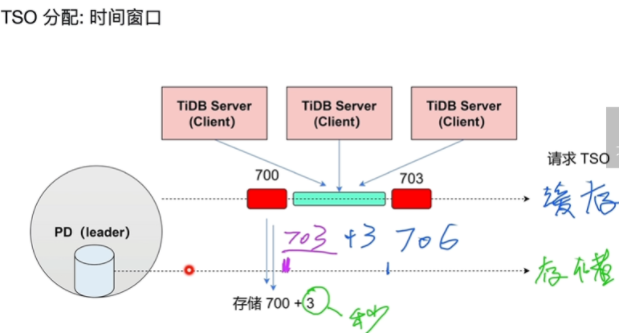
- 磁盘IO变成了3秒一次
- 将一段时间的TSO放到缓存中TiDBServer各种会话排队来使用
-
高可用

- 当leader宕机后,新leader直接跳过这3秒,形成新的TSO来继续分配,保障了高可用性(一个PD宕机后,系统依然可以使用)
- 增长性可以保障,连续性不能保障
-
-
描述 PD 的调度原理
-
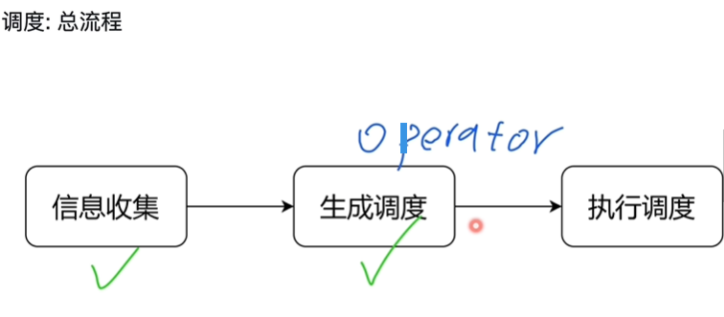
-
PD知道全局的region分布,TiKV会周期性的汇报心跳信息
-
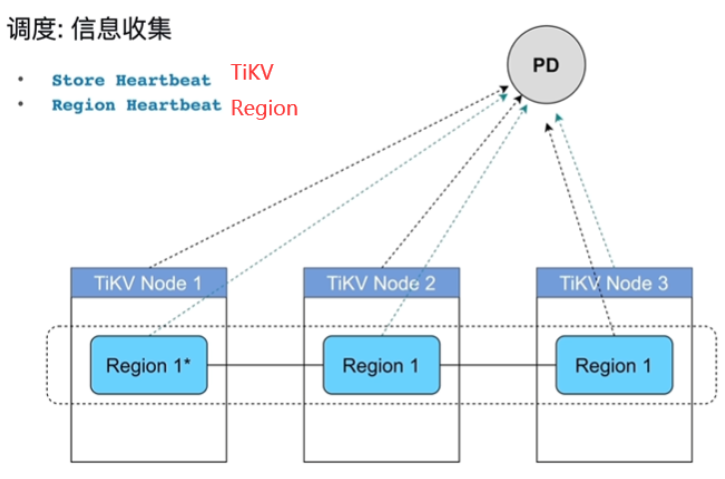
-
生成调度注意点:
- Balance(leader,Region),Hot Region,集群拓扑,缩容,故障恢复,Region merge
-
-
描述 label 的作用
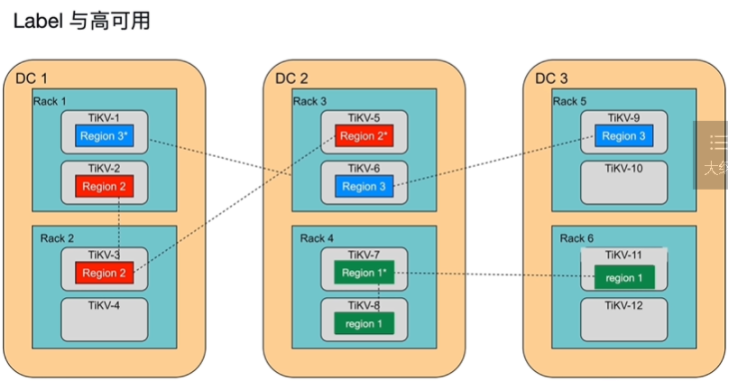
- DC:独立数据中心
- 12台主机,6个机柜,3个主中心
- raft协议,多数派原则,如果一个数据中心坏了,有两个主从region坏了,则不可用了
- region3可用性比较高,region不可用,数据库不可用
- Region原始分布默认随PD随机分步的
- PD只能保障同一个TiKV节点上,不会存在一个region的两个节点,region存储是由PD控制的
- PD按照label 期待的格式进行region的分配,PD使用label 感知region的具体分布
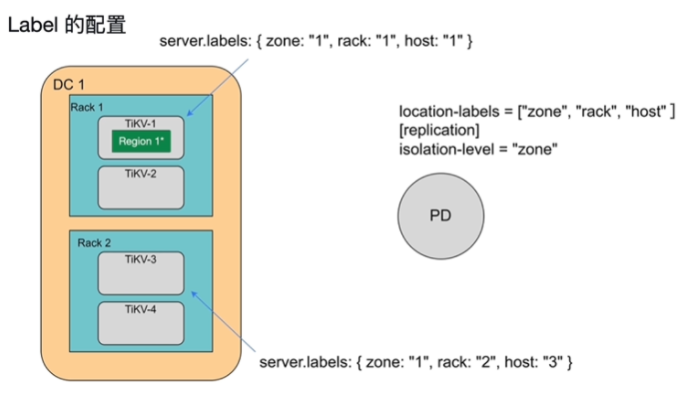
- 隔离级别设置isolation,表示副本分布
-
题目:














5.TiDB 数据库 SQL 执行流程
-
描述 DML 语句读写流程
- DML 语句,对表数据修改语句(delete,select,update...)
- DDL 语句,对表结构修改语句(alert,creat 表...)
- 读流程
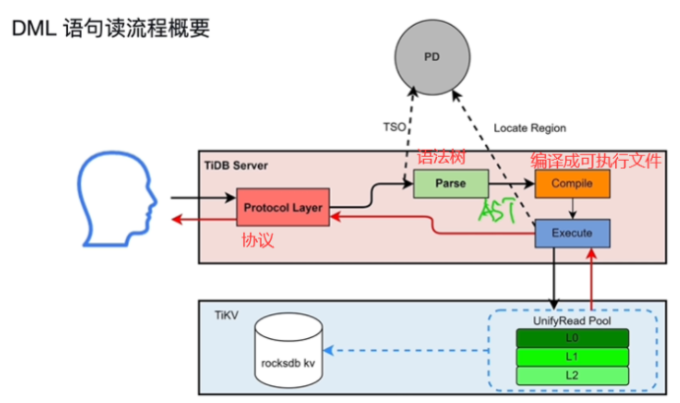
- 只获取开始时间
- 写流程
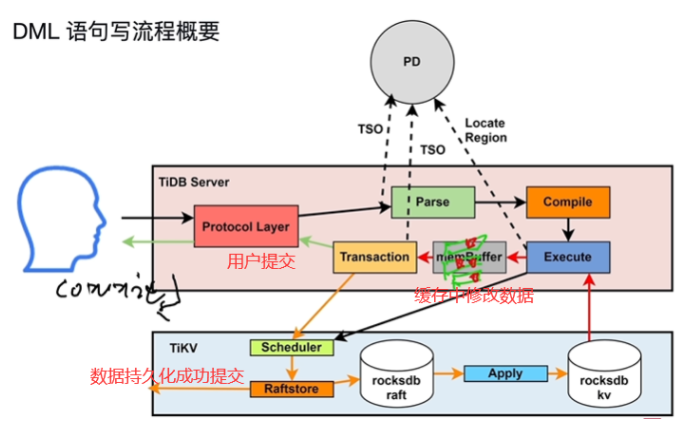
- 获取开始时间,获取结束时间
- (用户提交分为两阶段提交)两阶段提交
- apply将内存中的修改行加锁,修改和锁信息进行持久到TiKV中(leader及其他副本)
- commit写提交信息,将锁清理掉,去PD节点读取结束TSO
-
描述执行流程
- 执行流程
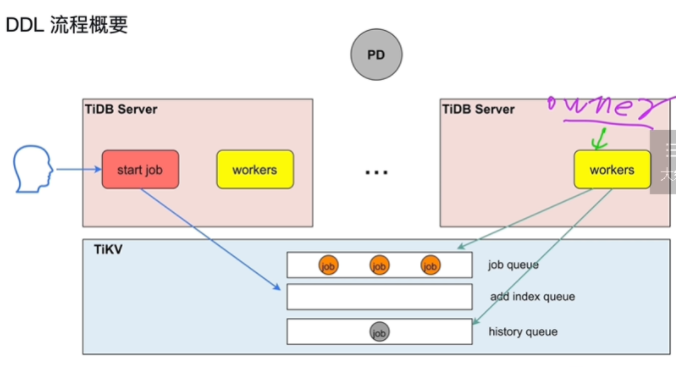
- 从一个TiDBserver读取ddl数据,从owner的TiDBserver具体执行,不一定是同一个
- owner会进行选举,轮流做owner
- Pase解析,compile编译
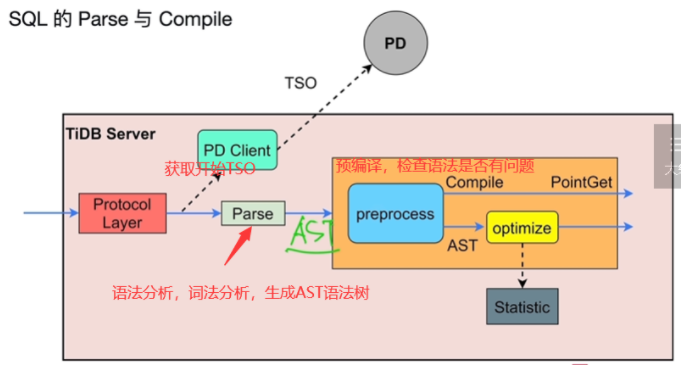
- 只读取一行数据,叫做点查(第一行Compile,PointGet)
- 逻辑优化AST语法树,optimize(优化器)物理优化
- DML 语句读取的执行
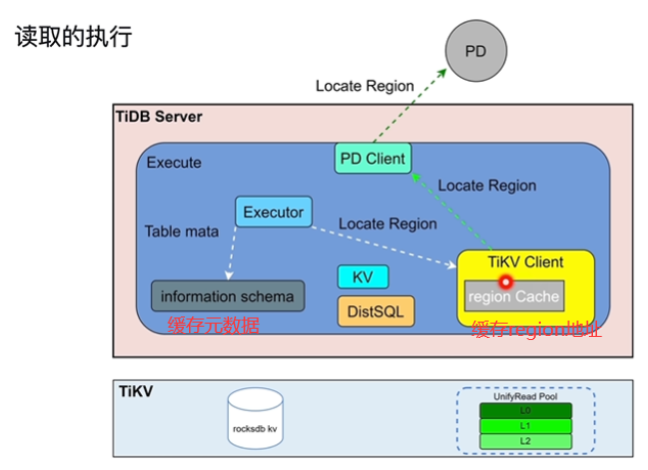
- backoff说明缓存中数据过期,重新从PD中获取
- 元数据:表头,列名

- KV对应点查时
- DistSQL将复杂的操作转换为单表的操作
- snapshot快照

- cop task
- root task
- DML 语句写入的执行
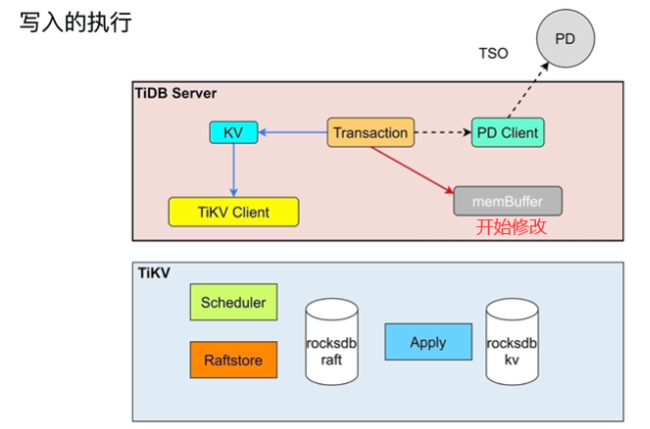
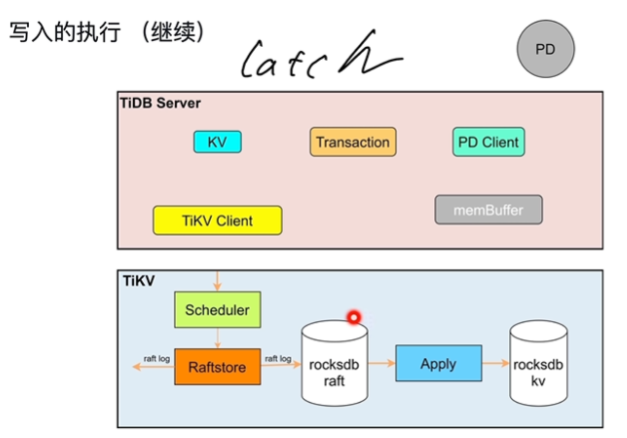
- 解决同key操作冲突的问题,谁获取latch谁执行
- DDL 语句的执行
- 执行流程
-
题目:















6.TiDB 数据库 HTAP 概述
-
描述 HTAP 技术
-

- OLTP(高并发) OLAP(暴力扫描)
-

- ETL工具将数据抽取
-
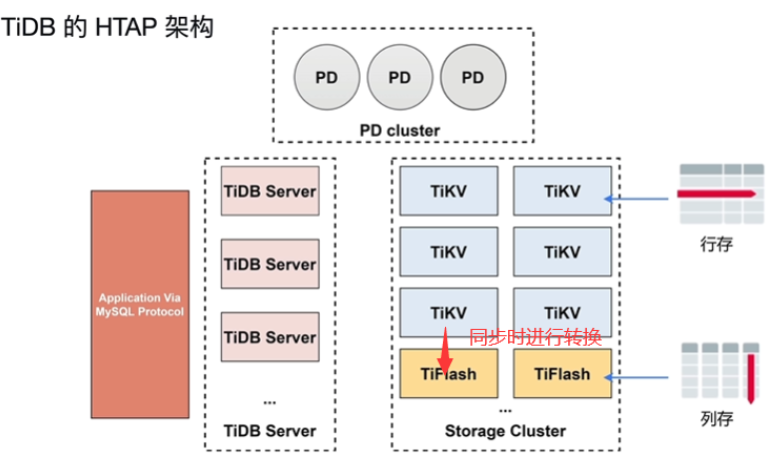
-
HTAP 的基本要求
- 可扩展性:分布式事务,分布式存储
- 同时支持 OLTP 与 OLAP:(同时有两种版本)同时支持行存和列存,OLTP与 OLAP 业务隔离
- 实时性:行存与列存数据实时同步
-
TiDB 的 HTAP 功能特性
- 行列混合:列存 (TiFlash) 支持基于主键的实时更新,TiFlash 作为列存副本,OLTP 与 OLAP 业务隔离
- 智能选择 (CBO 自动或者人工选择 )走TiKV还是TiFlash
- MPP 架构,只能在TiFlash上执行(过滤,聚合,表连接),并行计算
-
MPP
-
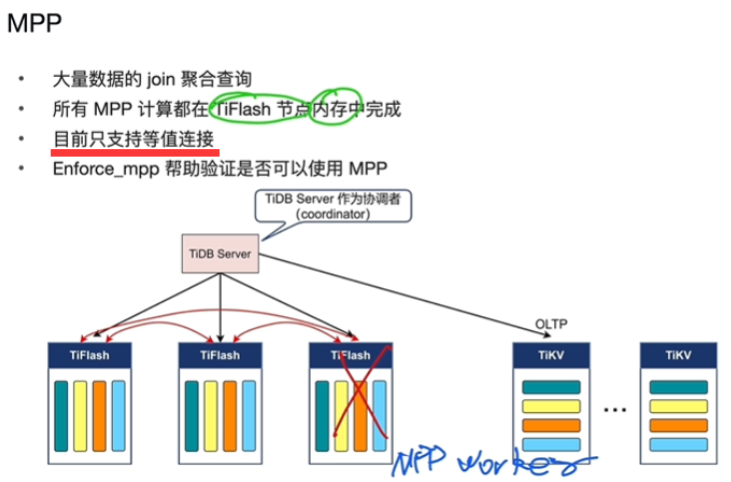
-
过滤,交换数据,表连接,聚合发生在各个TiFlash上做
-
并行计算
-
-
-
工作场景
-
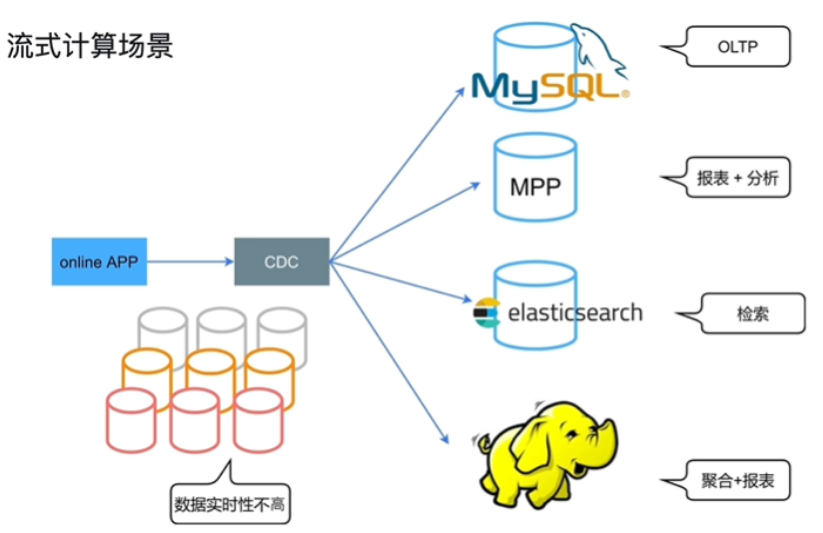
-
题目:










7.TiFlash
-
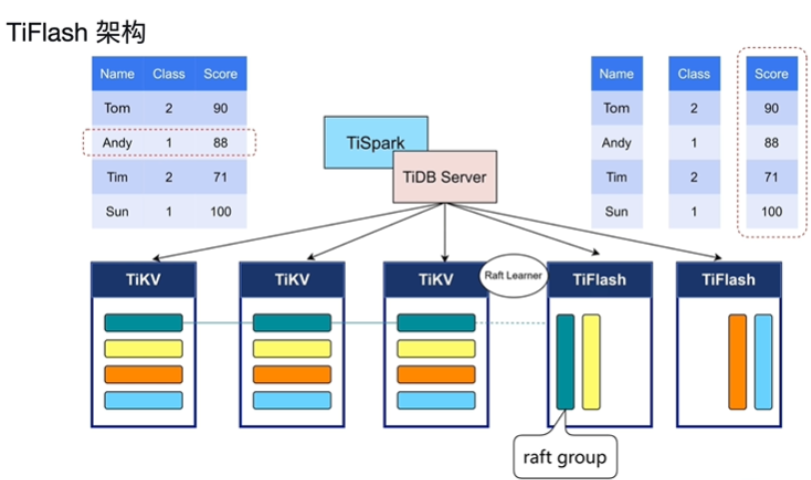
- TiFlash是TiKV的列存版本,数据和分区是一模一样的
- Reft leaner使用日志异步同步
- TiFlash只接入日志,没办法写入,只能读,和其他follower一样,从TiKV的leader复制转换来的,对原来性能影响很小,因此做到了业务的隔离性,如果TiFlash宕机后,重新复制即可
- 存在mvcc快照隔离级别,和TIKV一致性读取
-
TiFlash 主要功能
- 异步复制(Reft leaner)
- 一致性读取(mvcc快照隔离级别)
- 发日志,等待确定后读取
- 引擎智能选择(可以主动选择使用TiKV还是TiFlash还是混合使用)
- 计算加速
- 异步复制(Reft leaner)
-
题目






8.TiDB 6.0 新特性
-
了解 Placement Rules in SQL(SQL中的放置规则)(指定表具体放置在哪个节点上)
- Placement Rules in SQL 之前
- 跨地域部署的集群,无法本地访问
- 无法根据业务隔离资源
- 难以按照业务等级配置资源和副本数
- Placement Rules in SQL 之后
- 跨地域部署的集群,支持本地访问
- 根据业务隔离资源
- 按照业务等级配置资源和副本数
- Placement Rules in SQL 的使用 - 步骤
- 步骤 1:设计业务拓扑, 为不同的 TiKV 实例设置标签
- 步骤 2:创建 PLACEMENT POLICY(布局规则)
- 步骤 3:设定数据对象的 PLACEMENT POLICY
- Placement Rules in SQL 的应用
- 精细化数据放置,控制本地访问与跨区域访问
- 指定副本数,提高重要业务的可用性和数据可靠性
- 将业务按照等级、资源需求或者数据生命周期进行隔离
- 业务数据整合,降低运维成本与复杂度
- Placement Rules in SQL 之前
-
描述小表缓存(分布式数据库热点问题,提高小表的吞吐量)
-
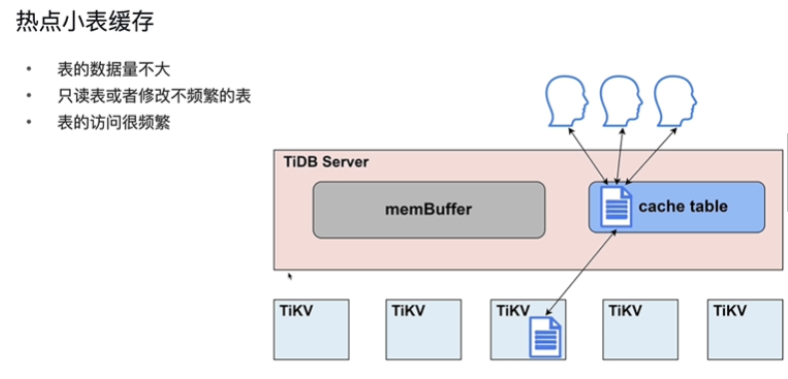
-
原理:
-
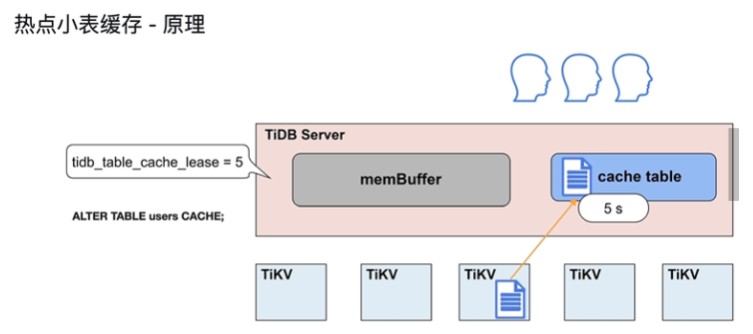
-
租约时间(5s)内,无法进行写操作,可读比较快
-
租约到期,数据过期
- 写操作不再被阻塞
- 读,写,直接到 TiKV 节点上执行
-
数据更新完毕,租约继续开启
-
-
应用
- TiDB 6.0对于每张缓存表的大小限制为 64 MB
- 适用于查询频繁、数据量不大、极少修改的场景
- 在租约 (tidb_table_cache_lease) 时间内,写操作会被阻塞,在小表读,性能提高
- 当租约到期 (tidb_table_cache_lease) 时,到 TiKV读,性能会下降
- 不支持对缓存表直接做 DDL 操作,需要先关闭
- 对于表加载较慢或者极少修改的表,可以适当延长
- tidb_table_cache_lease 保持读性能稳定
-
-
描述内存悲观锁(事务性能提升)
-
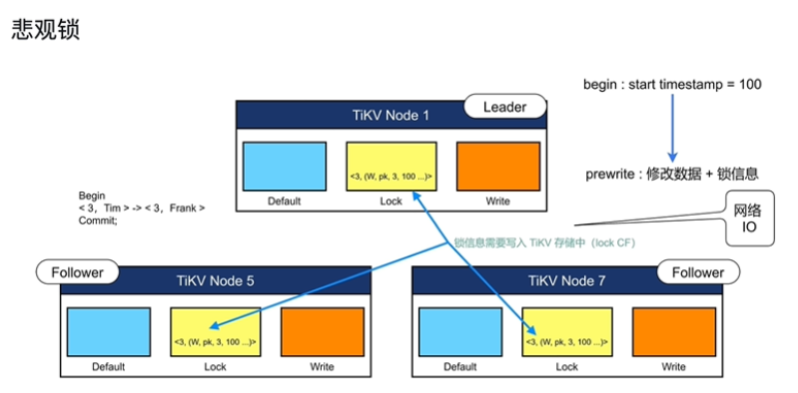
-

-
使用 -

- 配置文件
-
应用
- 减少事务的延时
- 降低磁盘和网络贷款
- 降低 TiKV 的 CPU 消耗
- 锁丢失问题,锁丢失,事务回滚(缺点)
-
-
了解 Top SQL(性能的可观测性:找到某个top5类型的sql,知道哪些sql的消耗(只能)cpu负载/开销是最大的)






-
作用:
- 可视化地展示 CPU 开销最多的 Top 5 类 SQL 语句
- 支持指定 TiDB server 及 TiKV 实例进行查询
- 支持统计所有正在执行的 SQL 语句
- 支持每秒请求数、平均延迟、查询计划等详细执行信息
-
了解 TiDB Enterprise Manager(TiEM)(企业级的管理平台,图形化流程化)
- 企业中 TiDB 集群管理的问题
- 数量增长:集群数量、节点数量、组件数量、工具数量
- 复杂度增长:配置参数复杂度、命令行复杂度、管理接口复杂
- 企业中 TiDB 集群管理的任务
- 部署集群、升级集群、参数管理、组件管理、备份恢复与高可用管理、集群监控与告警、集群日志收集、审计与安全
- 功能
- 一键部署集群 & 多套集群一站式管理、集群原地升级、参数管理、克隆集群 & 主备集群切换
- 企业中 TiDB 集群管理的问题
-
题目:


9.TiDB Cloud
-
在Cloud方向考虑为什么选择TiDB

- 方便横向扩展
- raft实现高可用性
- 方便横向扩展
-
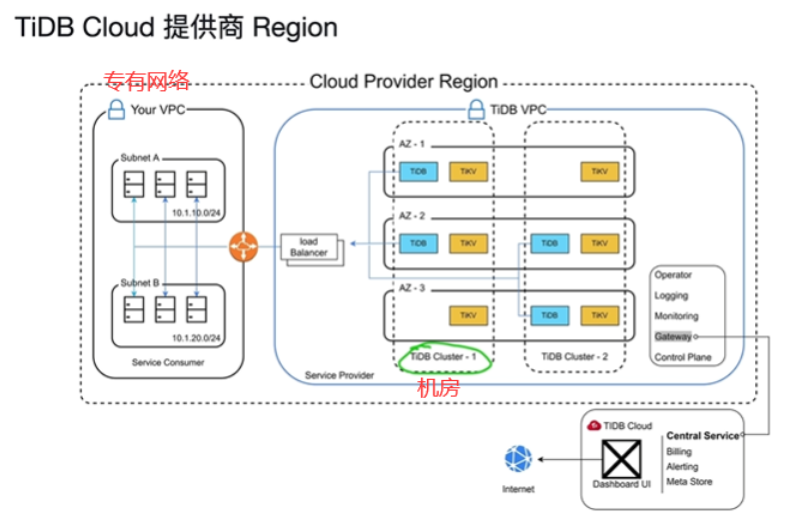
什么是TiDBCloud
-
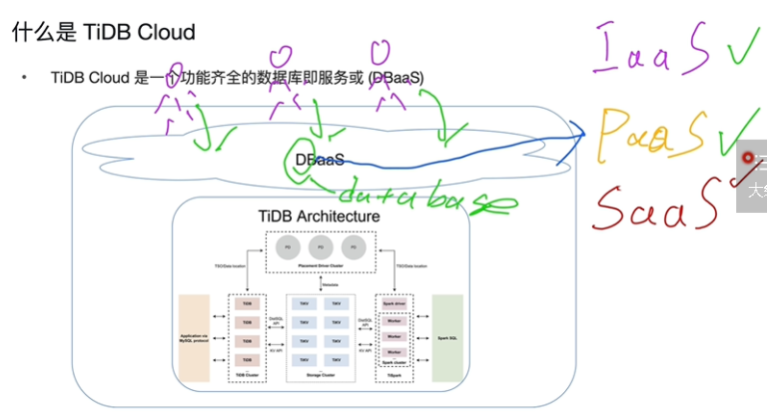
-
IaaS云服务厂商提供的基础硬件设施(服务器...)
-
PaaS云服务厂商提供的基础软件平台设施(操作系统,数据库...)
-
SaaS云服务厂商提供的软件基础设施直接运营即可(论坛软件...)
-
-
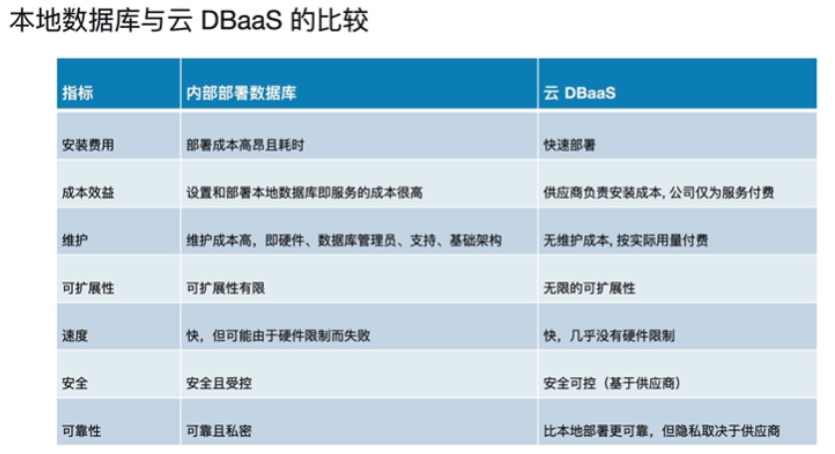
-
-

-

-

-
题目:














10.重点资料总结














