
混淆矩阵

- TP:表示正确拒绝的样本数(坏样本要拒绝)
- FP:表示误报的样本数,即被错误拒绝的样本数(错的记成正的)
- FN:表示漏报的样本数,即被错误准入(错误的拒绝了)的样本数(正例预测成负例,好样本没有准入,正例的少了,召回的少了)(好的少了,好的记成错的)
- TN:正确准入的样本数
TP是真1;FP是假1;FN是假0;TN是真0
ROC曲线

- 横坐标为假正率(FPR)
- 表示负样本被预测为1的概率
- 纵坐标为真正率(TPR)
表示正样本被预测为1的概率
绘制方法:
- 1.对输出概率进行降序排序
- 2.确定阈值
- 3.根据阈值点计算TPR和FPR
- 4.苗点连线
ROC曲线反映了排序质量的好坏,也就是预测结果的好坏(正例在前,反例在后)。
AUC
AUC是ROC曲线的量化指标,即ROC曲线下的面积。AUC值越大越好,即面积曲线下面积越大越好。
AUC的意义:随机抽取一对正负样本,AUC是把正样本预测为1的概率大于把负样本预测为1的概率的概率。这句话有点拗口,用公式写就是:
- 指该正样本预测为1的概率
- 指该负样本预测为1的概率
- 当auc=0.5时,模型没有分类能力,完全是随机猜测
- auc>0.5时,把1预测为1的概率,比把0预测为1的概率大,说明模型有一定的分类能力
- 当auc<0.5时,把模型的预测类别取反,即可得到auc>0.5的结果
- auc的最大值为1,此时TPR恒等于1,即正样本永远会被预测正确
- 因为AUC的取值在0.5-1之间,我们更习惯于一个取值在0-1之间的指标,这时候就有了归一化后的AUC,就是基尼系数或基尼统计量(这里的基尼系数和决策树的不同):
AUC的优势:能够综合考虑到正例和负例,因此可以应对样本不均衡的情况。
求解AUC
有两种公式:
- 第一种:

其中 、 分别为正、负样本数。上述公式中的求和是在 个总样本中,取出 个正负样本对,然后计算
- 第二种:
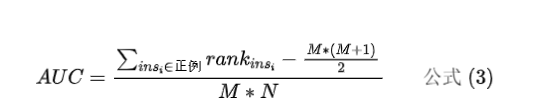
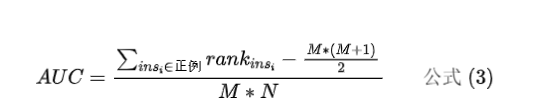
其中 、 分别为正、负样本数。 是第 条样本 的序号(概率得分从小到大排序,排在第 个位置)。 表示只把正样本的序号加起来。
GAUC:Group AUC
为什么要引入GAUC:因为AUC有时候不能满足推荐/广告系统中用户个性化的需求。
看个例子:
假设现有两个用户甲和乙,一共有5个样本其中+表示正样本,-表示负样本。现有两个模型A和B,对5个样本的predict score按从小到大排序如下:

从以上模型预测结果可以看出,对于用户甲的样本,模型A和B对甲的正样本打分都比其负样本高;对于用户乙的样本也是如此,因此分别对于用户甲和乙来说,这两个模型的效果是一样好的。
但这两个模型的AUC如何呢?根据公式(3)计算,,。我们发现AUC在这个场景下不准了。这是因为,AUC是对于全体样本排序后计算的一个值,反映了模型对于整体样本的排序能力。但用户推荐是一个个性化的场景,不同用户之间的商品排序不好放在一起比较。因此阿里妈妈团队使用了Group AUC来作为另一个评价指标。GAUC即先计算各个用户自己的AUC,然后加权平均,公式如下:
实际计算时,权重可以设为每个用户view或click的次数,并且会滤掉单个用户全是正样本或全是负样本的情况。