
项目名称:Vision Transformer for MaskFace
---Intel One API 黑客松比赛
数据集:
RMFD(Real-world Masked Face Dataset)是一个用于人脸口罩检测和识别的数据集。该数据集由中国科学院自动化研究所和云从科技联合发布。RMFD数据集是在真实世界环境中采集的,包含了带口罩和不带口罩的人脸图像。
RMFD数据集具有以下特点:
- 规模庞大:RMFD数据集包含超过5万张人脸图像,涵盖了各种年龄、性别和种族。
- 多样性:数据集中的人脸图像来自于不同的场景,包括室内、室外、白天和夜晚。
- 口罩种类丰富:数据集中的口罩种类多样,包括医用口罩、N95口罩、布口罩等。
- 标注准确:每张图像都有相应的标注信息,指示人脸是否戴口罩。
通过使用RMFD数据集,研究人员和开发者可以训练和评估人脸口罩检测和识别模型,以提高在真实世界环境中的准确性和鲁棒性。这对于应对公共卫生事件和提升人脸识别技术的实用性具有重要意义。
参考资料::
英特尔AI参考套件中提供了类似解决参考代码及方案:https://github.com/idz-cn/Drone-navigation
模型选择
模型选择目前主流的Vision Transformer
VIt(Vision Transformer)模型的创新之处在于将Transformer模型成功应用于计算机视觉领域。传统上,Transformer主要用于自然语言处理任务,如机器翻译和语言建模。VIt模型通过将Transformer应用于图像数据,取得了令人瞩目的成果。
VIt模型的创新点包括:
基于自注意力机制的图像表示:VIt模型使用自注意力机制来建立图像内部的关联性,从而捕捉图像中不同位置之间的重要关系。这使得VIt模型能够有效地学习全局图像表示,而不依赖于传统的卷积操作。
分块策略:为了应对图像数据的高维度和大尺寸,VIt模型采用了分块策略,将输入图像分割成小块,并在每个小块上应用Transformer模型。这样可以降低计算复杂度,并使得模型能够处理更大尺寸的图像。
预训练和微调:VIt模型通常通过在大规模图像数据上进行预训练,然后在特定任务上进行微调。这种预训练和微调的方式使得VIt模型能够从大规模数据中学习通用的图像表示,并在具体任务上展现出较好的性能。
该项目中我用的模型如下
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
from timm.models.vision_transformer import VisionTransformer
# 设置超参数
batch_size = 256
learning_rate = 0.001
num_epochs = 10
# 加载数据集并进行预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_dataset = datasets.ImageNet(root='./data', split='train', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 创建模型并定义损失函数和优化器
model = VisionTransformer(img_size=224, patch_size=16, in_chans=3, num_classes=1000)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
print('Finished Training')
模型测试:
在该项目中,我使用了交叉熵作为评估标准,同时保留每次训练最佳的模型。因此可以达到较好的识别效果。
可视化结果展示如下:
输入:被遮挡的图像
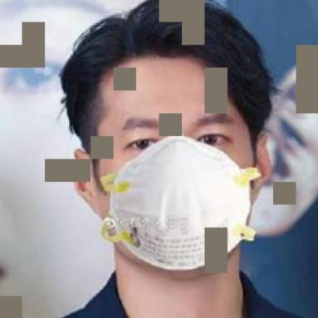
输出:恢复之后的图像

One AI套件使用
VTune Profiler分析PyTorch*程序的性能瓶颈,并进行优化。
步骤:
1. 安装Intel® VTune™ Profiler,并启动。
2. 在VTune Profiler中创建一个新的性能分析项目。
3 .选择“Python*”作为分析类型,并选择要分析的Python脚本。
4.在“高级设置”中,选择“PyTorch*”作为框架,并选择要使用的Python版本和PyTorch版本。
5. 开始分析,并等待分析结果。
5. 在分析结果中,选择“热点”视图,查看程序的性能瓶颈。
6. 根据热点视图中的数据,进行代码优化,例如减少数据传输、使用更高效的算法等。
7. 重新运行程序,并使用VTune Profiler进行性能测试,以验证优化效果。