
说明:本人正在跟随台大李宏毅老师的课程学习,为了加强学习效果,特写成blog来记录,所有博客中的图片均截取自李宏毅老师的PPT。
一、机器学习是在干什么?
以中学时代所学的函数为例,做应用题时我们都会建立相应的正比例函数、二次函数等来解决,给定一个自变量x都能得到唯一的因变量y。现在我想找到一个函数ƒ,它的输入并不是数字,而是一段语音,最后相应的文字,亦或输入的是一副图片,最后输出的是图片中的内容,那么如何求解该函数?显然,人类做不到,那就交给机器(计算机)来找!
二、不同类型的函数(亦即不同的任务)
Regression(回归问题类):输出的是scalar(标量),标量只有大小而无方向,可以表示温度、湿度、长度等。>scalar(标量),标量只有大小而无方向,可以表示温度、湿度、长度等。
Classification(分类):给一些选项或类别,函数可以输出正确的一类(class),一个one-hot向量
Structured Learning(结构化预测):输出一个句子或一张图......输出的是结构化结果
三、机器学习的三个步骤
以预测隔天的视频点击量为例
1. Function with unkonwn parameters
写出一个带有未知参数的函数,先预测一下这个函数会是什么形式(基于数据所在领域的一些先验知识)
设:\(y = b + w*x_1\),其中y是要预测的第二天的值,\(x_1\)是当天已知的值,\(b\)和\(w\)是未知的参数,要通过后面的步骤来确定(从大量数据中学习)
2. Define Loss from Training Data
Loss是一个函数,输入的参数就是第1步中未知的b和w,记为$L(b, w)$
Loss函数判断的是当确定一组b和w时,输出的数据“好不好”
假设b = 0.5k,w = 1,即\(L(0.5k, 1)\),有\(y = 0.5k + x_1\),我们要判断此时该函数是否够准确,即预测值与实际值(Label)之间的误差大不大
假如我们将每天的实际点击量与预测点击量作差,然后累加求平均值,即 \(L = \frac{1}{N}\sum_n{e_n}\)
其中N表示training data的个数,n代表有多少天,\(e_n\)表示每天的误差。则L越大,代表当前选择的\(b\)与\(w\)不好,L越小代表这一组参数越好。
注意其中\(e = \lvert y - \widehat{y} \rvert\) L is mean absolute error(MAE:平均绝对误差);
\(e = (y - \widehat{y}) ^2\),L is mean square error(MSE:均方误差),两种方法可以根据实际情况确定
3. Optimization
解一个最优化问题,如本例中我们要找到一组最好的w与b,即\(w^*,b^* = arg min_{w,b} L\),我们用到的optimization方法是Gradient Descent即梯度下降法。
Graient Descent
简化一下,假如目前我们只考虑参数w
- (randomly)pick an initial \(w^0\)
- Compute $\dfrac{\partial y}{\partial x}|_{w = w^0} $
- Update \(w\) iteratively
\(w^1 \leftarrow w^0 - \eta\dfrac{\partial L}{\partial w}|_{w = w^0}\)
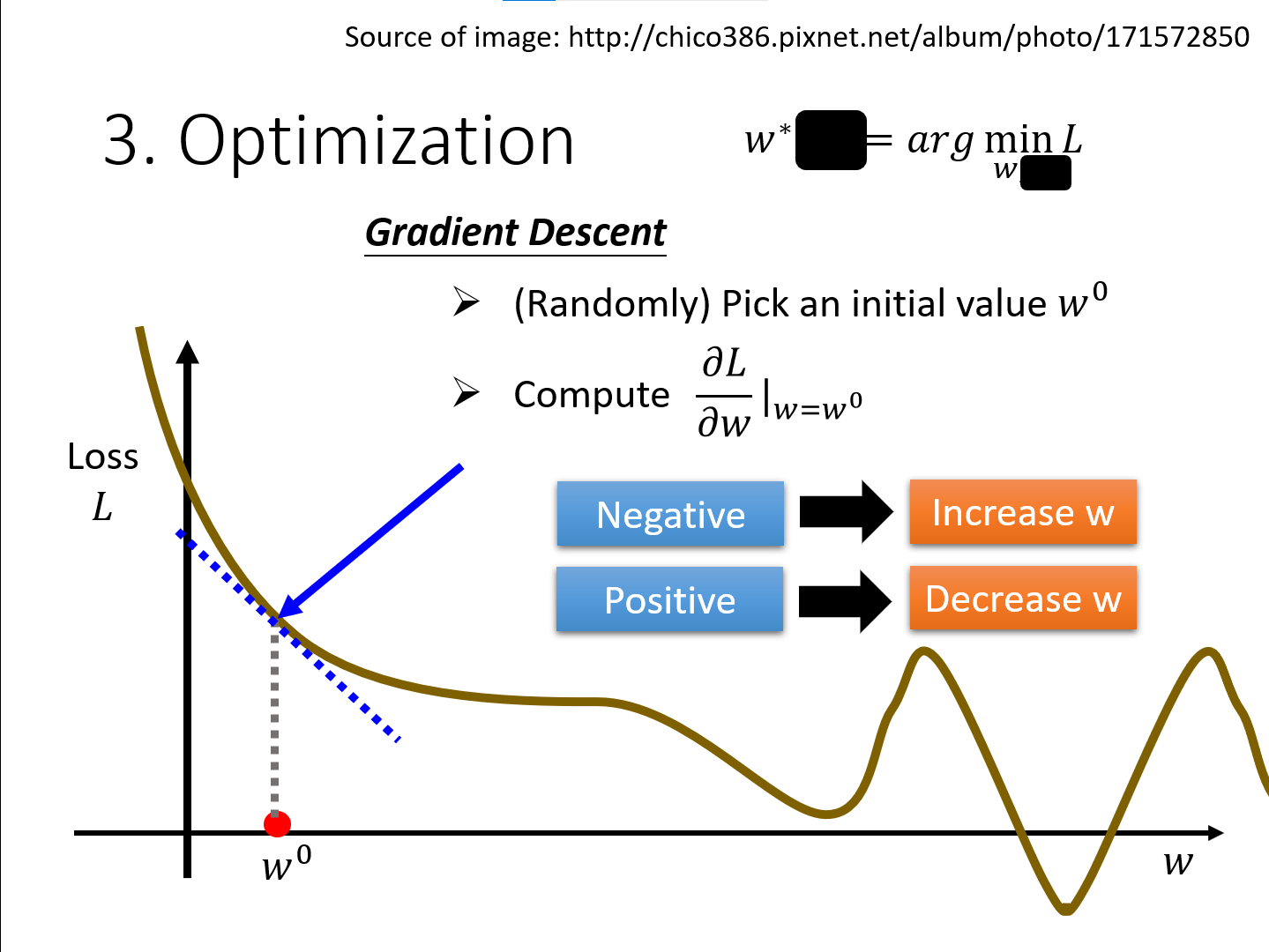
当偏导数为负时,左高右低 $\longrightarrow $ Loss函数递减 $\longrightarrow $ 增大w使其值减小
当偏导数为正时,左低右高 $\longrightarrow $ Loss函数递增 $\longrightarrow $ 减小w使其值减小

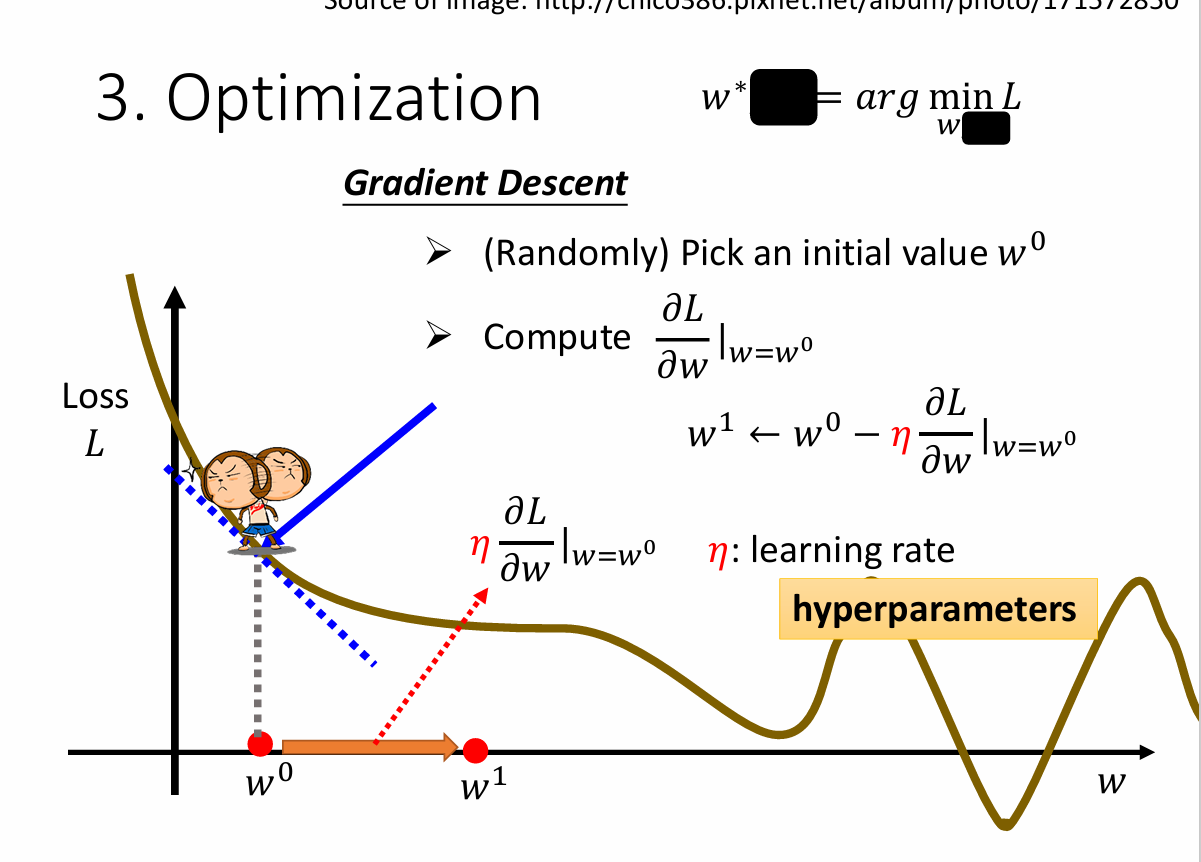
也就是说我要朝哪个方向迈出去走到新的 \(w_1\)处,走的这段距离不仅与偏导数有关,还与 学习率(learning rate)\(\eta\) 有关,即 \(\eta\dfrac{\partial L}{\partial w}|_{w = w^0}\)
这里的 \(\eta\) 是自己根据情况自行设定的,在机器学习中自己设定的参数叫 hyperparameters
w走到什么时候会停止?一是可以自己设定,求多少次微分后就停止;二是找到一个最小值时
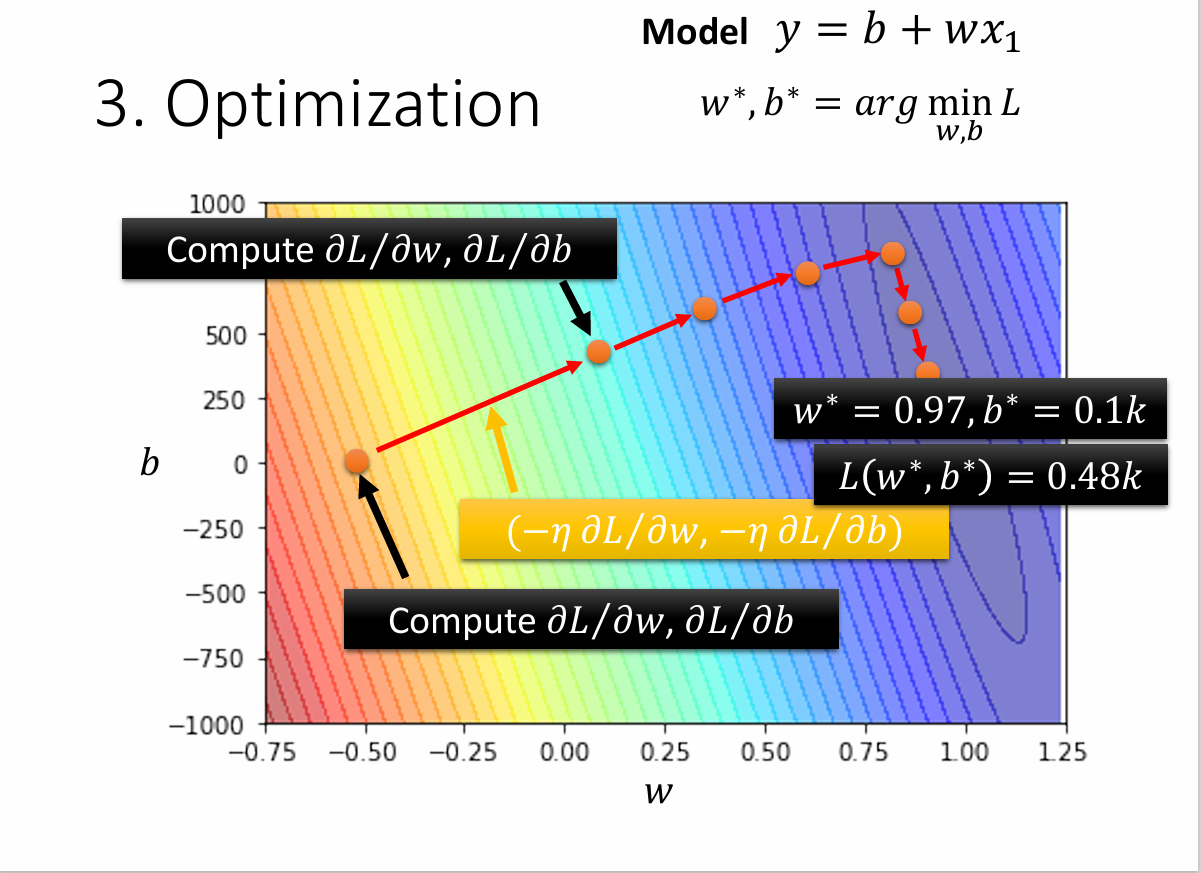
回到最初的两个参数的情况,即\(w^*,b^* = arg min_{w,b} L\)
- (Randomly)Pick initial values \(w^0\), \(b^0\)
- Compute \(\dfrac{\partial L}{\partial w}|_{w = w^0, b = b^0}\) \(\dfrac{\partial L}{\partial b}|_{w = w^0, b = b^0}\)
- Update \(w\), \(b\) iteratively
\(w^1 \leftarrow w^0 - \eta\dfrac{\partial L}{\partial w}|_{w = w^0}\)
\(b^1 \leftarrow b^0 - \eta\dfrac{\partial L}{\partial b}|_{b = b^0}\)
不停地更新下去,直到找到一组最优值

上面的 \(y = b + w*x_1\)我们只考虑了一天,我们对model加强一下,让它能够根据更多的数据来预测,可以写作:
同理,\(x_j\)是第j天的feature,\(w_j\)是权值,\(b\)是bias,\(n\)是总天数