
背景
Mixup(混合)
定义
对于一个样本\((x_i,y_i)\),将其与另一个样本\((x_j,y_j)\)混合:
其中\(\lambda\)采样于Beta(α,α),α>0,j采样于Uniform([n]),n为数据集大小。
作用
Mixup是一种线性插值的数据增强,由于其简单性、泛化性和Robust,mixup 已成为机器学习的一项基本技术。广泛用于semi-supervised learning,noisy-label learning等。
DNN的校准(Calibration)
模型的不确定性
一个经过良好校准的模型应该对可能是真实情况的预测充满信心,而当它可能不准确时则表明高度不确定性。
- 在一个二分类任务中取出大量(M个)模型预测概率为0.6的样本,其中有0.6M个样本真实的标签是1。总结一下,就是模型在预测的时候说某一个样本的概率为0.6,这个样本就真的有0.6的概率是标签为1。
- 还是在一个二分类任务中取出大量(M个)模型预测概率为0.6的样本,而这些样本的真实标签全部都是1。虽然从accuracy的角度来考察,模型预测样本概率为0.6最后输出时会被赋予的标签就是1,即accuracy是100%。但是从置信度的角度来考察,这个模型明显不够自信,本来这些全部都是标签为1的样本,我们肯定希望这个模型自信一点,输出预测概率的时候也是1。[引用]
抽象来说,完美的校准模型应该满足\(\mathbb{P}(\hat{y}=y|\hat{p}=p) = p,p\in[0,1]\),其中\(\hat{y}\)是模型的预测标签,\(\hat{p}\)是模型的预测概率,y是真实标签。
早期研究
在早期,对于模型输出不确定性(uncertainty)研究主要集中在贝叶斯神经网络(Bayesian Neural Networks)上,但是由于其计算复杂度高,所以并没有得到广泛应用。而近年来,神经网络的不确定性研究逐渐成为热点。
[1]指出后校准(post-calibration)对于过度自信的深度神经网络的重要性。在这篇论文,作者选择最简单的后校准方法:Temperature Scaling(TS)。
post-calibration就是对模型的输出进行操作,可以是直接在模型输出上改,也可以是使用特殊的损失函数。而本文讨论的一般calibration,就是在训练时引入mixup。
Introduction
(省略了参考文献的引用)
Mixup的效果
- Mixup可以改善模型架构和数据集校准。
- Mixup对高维状态下校准的影响存在理论解释。
- Mixup隐式执行标签平滑,因此可以避免过度自信问题。
- 也有经验观察表明,mixup并不一定能改善校准:实证研究表明,与单独使用集成的其中之一相比,将混合与集成相结合会降低校准性能(这里的集成指的是:每个输入x,计算T次mixup后的结果,求平均)。特别是,研究者认为混合和集成都会导致模型信心不足,因此当它们一起使用时会出现信心不足的问题。
对于Mixup的研究和贡献
作者总结了之前的mixup的问题:
- 某些方法不经过后校准,就去作比较不公平(即使它们都在训练时进行了校准)。
- 训练时校准的模型表现好,不代表后校准后模型表现好。
提出了疑问:
- mixup 真的有助于校准吗?
- 如果没有,是什么导致了失败?
- 我们如何减轻校准中的mixup陷阱?
总结了贡献:
- 加入后校准降低了总体的不确定估计。
- 解耦mixup并找到校准退化的元凶。
- 考虑准确性和预算的情况下,mixup这种类似集成的方法不比一般的深度集成好。
- mixup校准问题可通过引入训练解决。通过这个过程,每个原始样本的输出可以恢复,以便从one-hot标签中学习,避免置信惩罚的负面影响。
Mixup是否有助于校准
设置含/不含后校准的指标:
- 用期望校准误差(Expected Calibration Error,ECE)评估校准。
- Calibrated ECE:加入TS经过后校准的ECE。
TS 的工作原理是将 softmax 层的温度替换为在保留验证集上产生最佳校准结果的值。
- Optimal ECE:直接在测试集上找到温度,并将结果表示为最佳 ECE,它可以被视为校准 ECE 的下限,并帮助我们识别哪个模型在事后校准阶段更可校准。
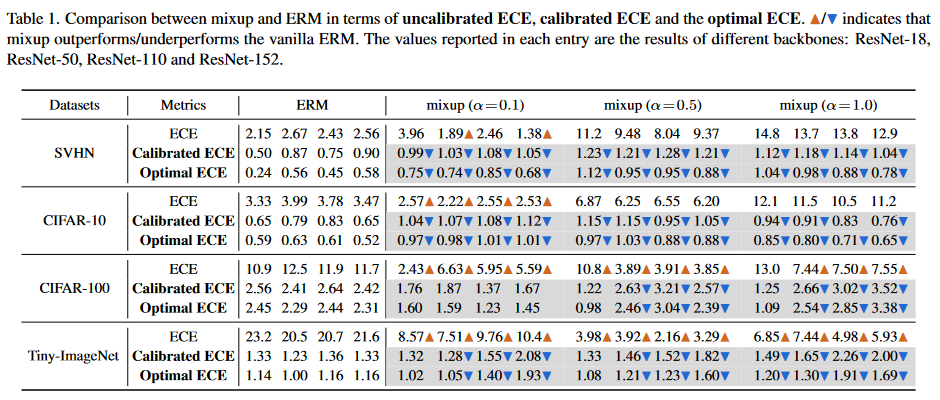
- 仅考虑没有后校准的模型,也就是和ECE指标水平的这部分行,mixup表现大部分优于ERM。
- 当涉及后校准(Calibrated ECE & Optimal ECE),mixup就比ERM逊色了许多。
这些结果表明,尽管经过 mixup 训练的模型在主训练后可能会提供更好的校准性能,但在校准后阶段很难进一步改进它们,即不如 ERM 训练的模型。对于较大的模型(ResNet-110, ResNet-152),这种现象更加明显。
- 对比ERM,不同的α设置对于mixup的指标也有着重要影响,α=0.1就明显比其他的α要好。
- α为合适的值时有助于校准,这可能是mixup正则化的影响:隐式地惩罚尖锐的输出以避免过度自信的问题。然而,当正则化变得更强,即混合中使用更大的α时,可能会导致信心不足的问题,这也是一种错误校准的情况。
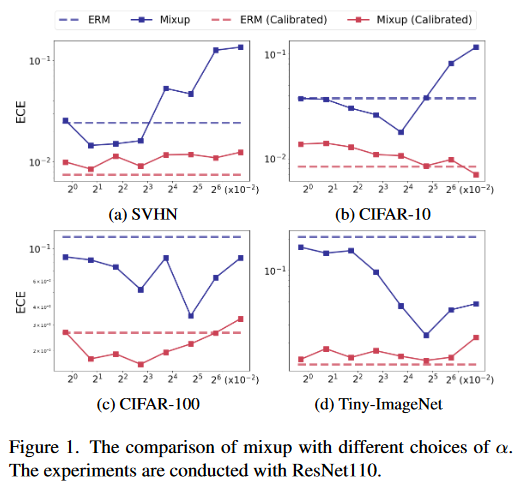
Figure 1展示了:(1) 不同数据集的最佳 α 不同,这意味着我们需要在新任务上仔细选择 α; (2) 即使具有最好的 α,未校准和校准的 ECE 之间仍然存在很大的差距。一旦涉及后校准(a,b,d红线),mixup往往会降低校准性能,尤其是在较大的 α 上(这对于获得所需的精度很重要)。
使用mixup如何做到校准和低ECE共存?
校准中的mixup为何失败
[2]的Theorem 1 mixup可解耦为红色的数据变换(Data Transformation)和蓝色的随机扰动(Random Perturbation):
- 随机变量\(\lambda\sim\mathrm{Beta}_{\left[\frac12,1\right]}(\alpha,\alpha),\ j \sim Uniform([n])\),其中\(\alpha>0,n>0,\bar{\lambda}=\mathbb{E}_\lambda\lambda\),对于\(i\in[n]\)的任意样本可混合为\((\widetilde{x}_i,\widetilde{y}_i)\)。
- \(\bar{x}\)和\(\bar{y}\)是训练集的均值,随机扰动项满足\(\mathbb{E}_{\lambda,j}\epsilon_{i}^{x}=\mathbb{E}_{\lambda,j}\epsilon_i^y=0\)。
假设标签平衡,Data Transformation相当于标签平滑,Random Perturbation的两个\(\epsilon\)期望为0,随机扰动项将为每个变换后的输入和标签添加零均值噪声。
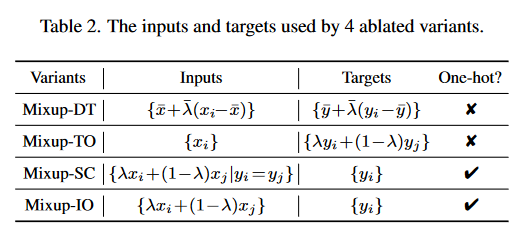
根据式(2)的解耦,对mixup做消融实验:
- Mixup-DT:only uses the Data Transformation part of Equation (2);
- Mixup-TO:mixes between Target labels Only;
- Mixup-SC:mixes within Same Class;
- Mixup-IO: mixes between Inputs Only
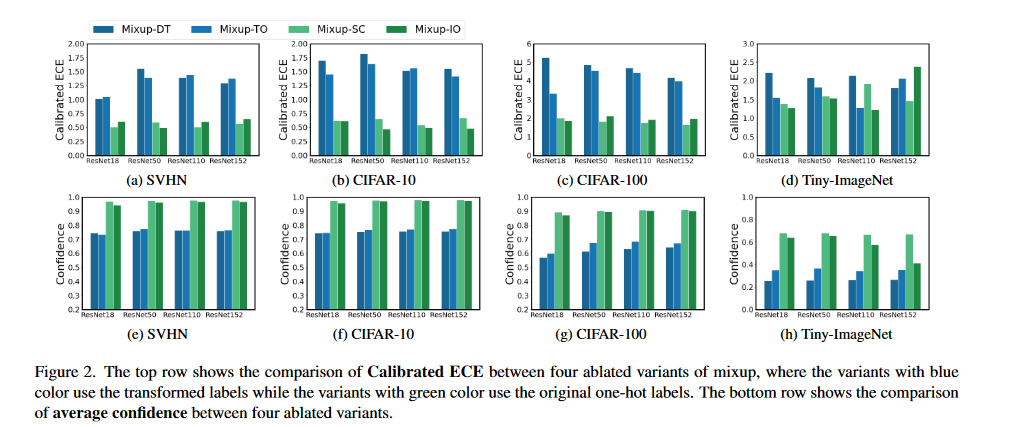
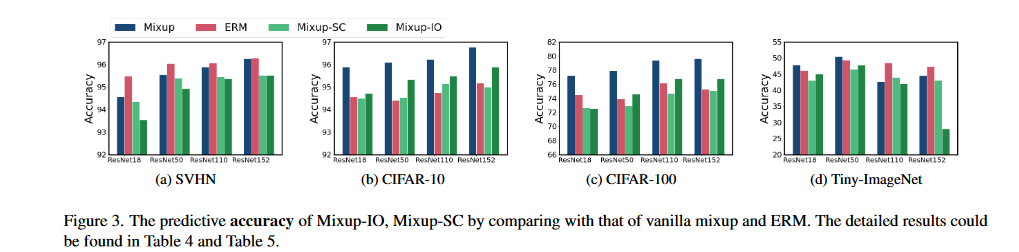
对Target的改变,损害了校准表现。(看DT、TO在ECE和置信度的表现)但SC、IO并不优越,这两者在精度上逊色于DT、TO(图3所示)。如何兼顾准确率与精度?



缓解Mixup的负面效果
[3]给出了mixup对标签y的推理过程,对于x最后的推理结果\(F_{MI}(x)\)就是N次推理集成的结果。

上图来自文献[3]
然而,如果输出空间中没有解耦过程,则很难通过这种简单的mixup推理方法获得精确的标签置信度信息。
根据mixup后的标签:
可以解耦mixup前的标签:
并基于上面的Mixup Inference进行修改:

同样的这里的第7行也是一个集成的结果
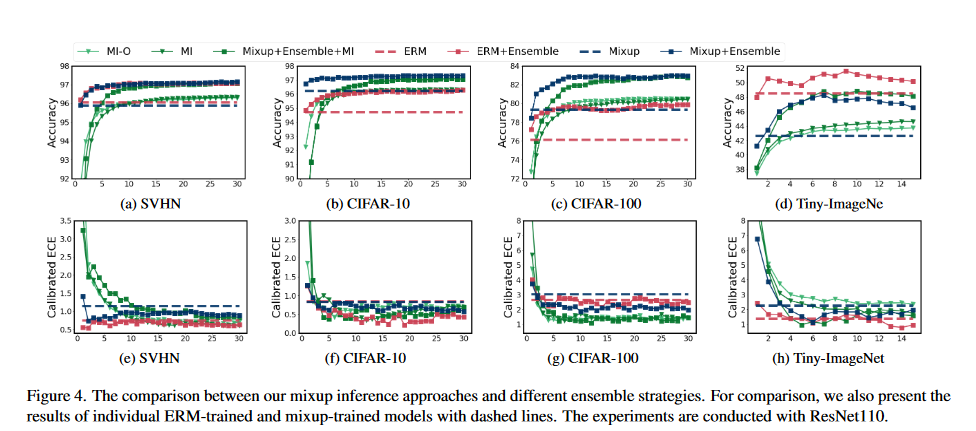
MI-O指的是\(\lambda_2=0,\tilde{y}_2\)从测试集中获取,因此每次迭代只需要进行一次前向推到。
但是上图可以看到MI的结果并不一定不一般的集成和mixup要好。即使在文中,作者对每个样本进行T=15次的迭代,MI的ECE与ACC取得了增长,但还得考虑迭代期间的计算成本和耗时。
原论文从这里开始,作者似乎有意得忽视了集成,在代码中没有找到论文后续提出的方法关于Mixup Inference的T次迭代集成。
观察到Figure 2的MIXUP-SC, MIXUP-IO,由于直接使用one-hot作为标签,没有收到mixup正则化的置信度惩罚的影响,作者考虑到将one-hot与Mixup Inference恢复的\(\hat{y}\)做一个mixup(Figure A(b)):
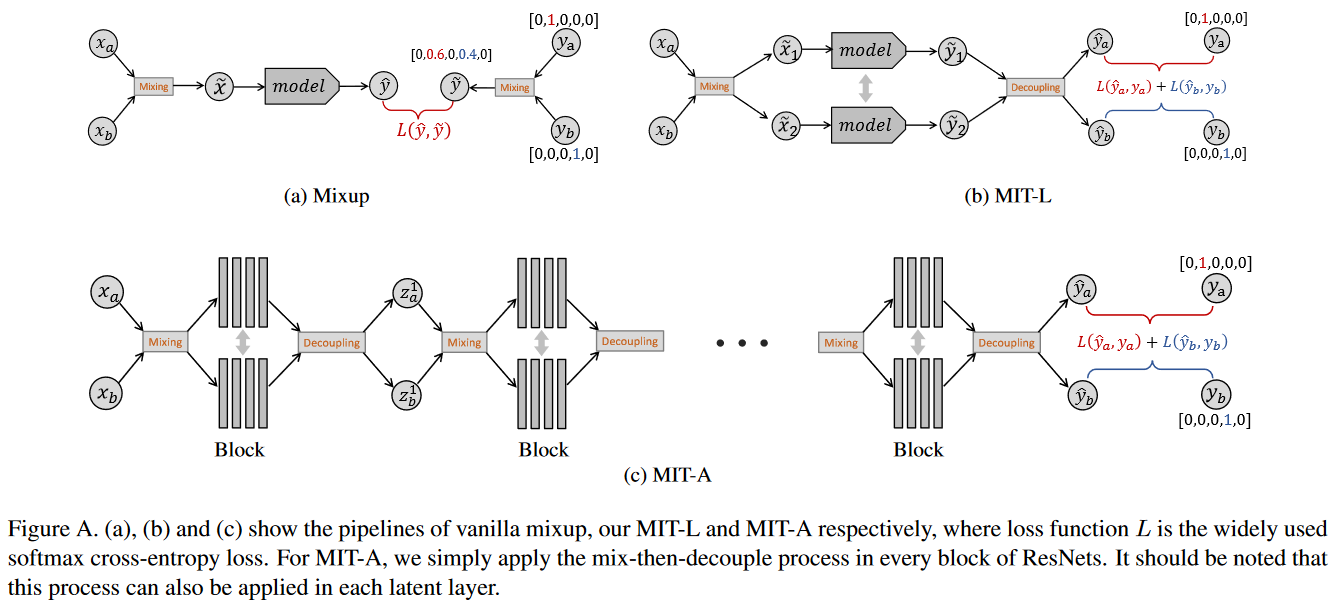
实践中,发现\(\lambda_1\sim\mathrm{Beta}_{[0.5,1]}(\alpha,\alpha)\)与\(\lambda_2\sim\mathrm{Beta}_{[0,0.5]}(\alpha,\alpha)\)差值较大时表现更好。作者还将这种解耦用在了resnet的每个layer之后,对每个隐藏层的输出解耦再mixup,发现表现有也提升,而且这种做法增加的计算成本可忽略不计。
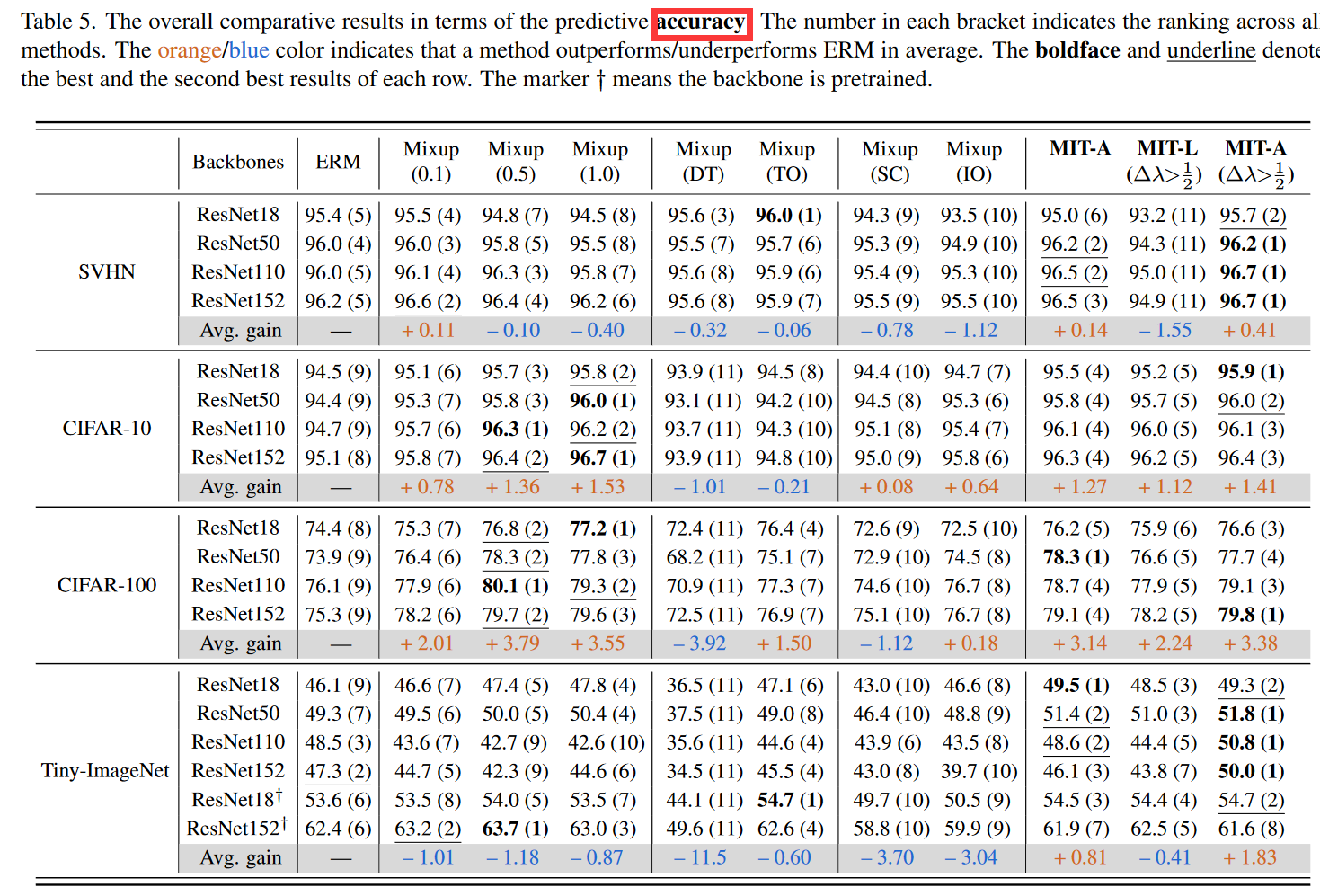
总结
作者用了较大的篇幅介绍mixup解耦的消融实验,发现使用mixup后的target由于置信度惩罚,会影响了模型的自信,最后提出的方法是将模型输出的mixup target 解耦恢复并与one-hot mixup,以及提出了trick:在backbone的每个layer的输出进行mixup操作。
参考文献
- John Platt et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in Large Margin Classifiers, 10(3):61–74, 1999.
- Carratino, Luigi, et al. "On mixup regularization." The Journal of Machine Learning Research 23.1 (2022): 14632-14662.
- Pang, Tianyu, Kun Xu, and Jun Zhu. "Mixup inference: Better exploiting mixup to defend adversarial attacks." arXiv preprint arXiv:1909.11515 (2019).
- 作者公开的代码
- 作者公开的附录