
CNN源于计算机视觉研究,后来诸多学者将其应用于短文本分类,其基本结构如下图所示:
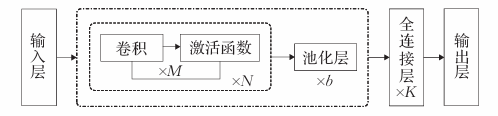
由上图可知,基于CNN的短文本分类模型,通常包括输入层、卷积层、池化层、全连接层和输出层五部分,其中卷积层和池化层是最为关键的特征提取环节。卷积层通过构造二维卷积核,并将其上下移动,在卷积窗口内与文本表示矩阵进行卷积操作,以此来提取文本特征。池化层则是对提取的特征进行选择,筛选出最为明显的特征。通常,在短文本分类时,需要对卷积层与池化层进行多层交替叠加,经过多次特征提取与特征选择,多角度获取文本特征信息;然后,进入全连接层,将特征信息进行整合,并将结果在输出层展示。
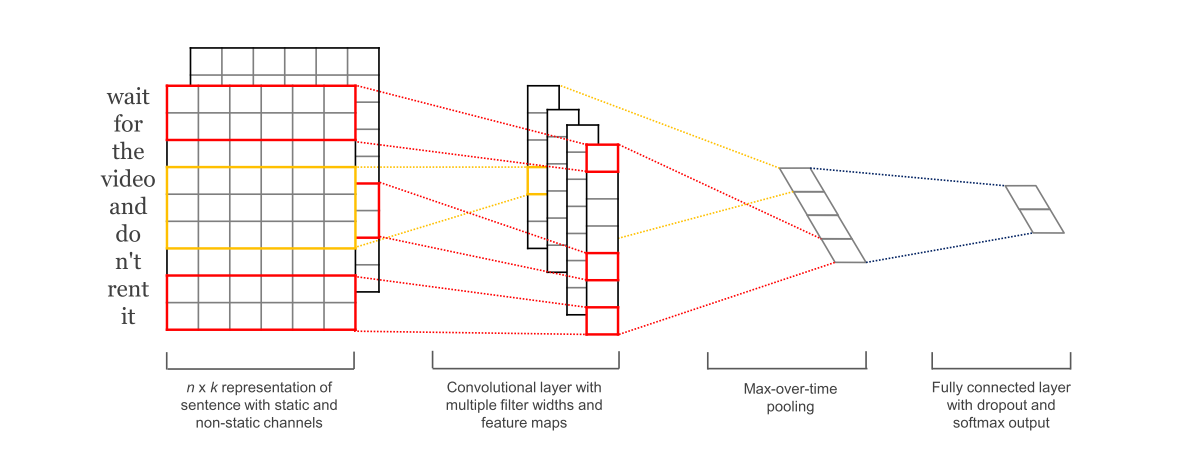
TextCNN是Yoon Kim在2014年提出的模型,开创了用CNN编码n-gram特征的先河。模型结构如上图3所示。
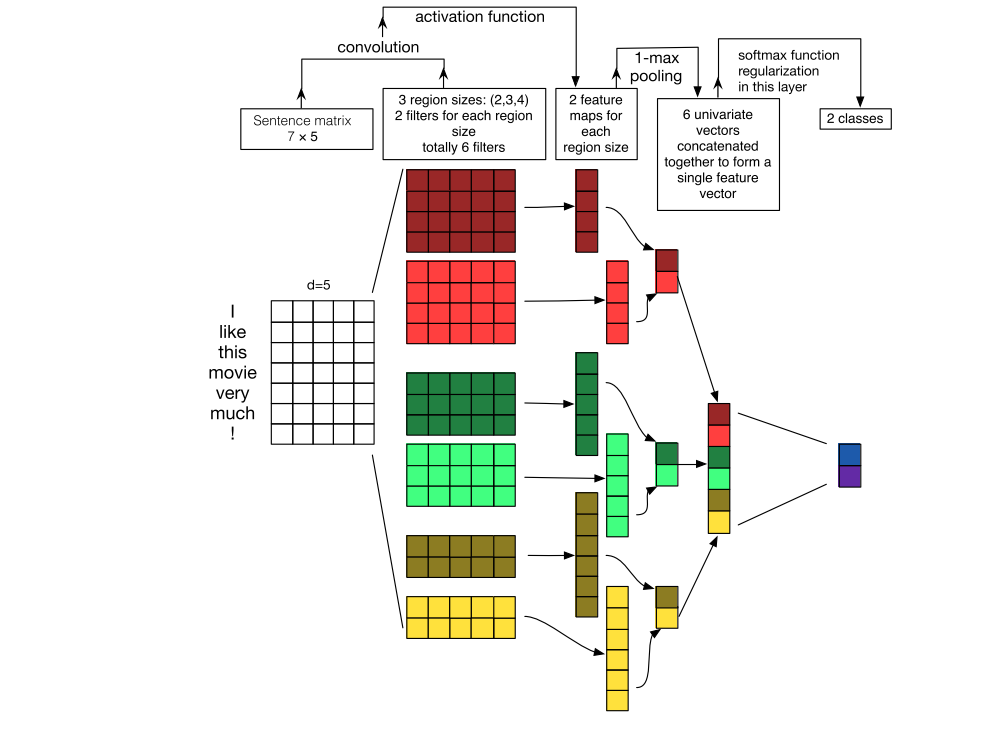
上图是来源于2016年ACL论文A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification
模型详解
数据处理:所有句子padding成一个长度:seq_len
1.模型输入:[batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化,词向量维度为embedding_size:[batch_size, seq_len, embedding_size]
3.卷积层:NLP中卷积核宽度与embedding_size相同,相当于一维卷积。3个尺寸的卷积核(2, 3, 4),每个尺寸的卷积核有100个,卷积后得到三个特征图: [batch_size, 100, seq_len -1] 、[batch_size, 100, seq_len - 2]、[batch_size, 100, seq_len -3]
卷积操作相当于提取了句中的2-gram、3-gram、4-gram信息,多个卷积是为了提取多种特征,最大池化将提取到最重要的信息保留。
4.池化层:对三个特征图做最大池化[batch_size, 100]、[batch_size, 100]、[batch_size, 100]
5.拼接:[batch_size, 300]
6.全连接:[batch_size, num_classes]
7.预测:Softmax归一化,将num_class个数中最大的数对应的类作为最终预测。
TextCNN是很适合中短文本场景的强baseline,但不太适合长文本,因为卷积核尺寸通常不会设置很大,无法捕获长距离特征。同时max-pooling也存在局限,会丢掉一些有用特征。另外再仔细想的话,TextCNN和传统的n-gram词袋模型本质是一样的,它的好效果很大部分来自于词向量的引入,解决了词袋模型的稀疏性问题。这也正是TextCNN成功的原因,TextCNN的成功并不是结构的成功,而是证明了预训练词向量 + 微调是提升NLP各项任务的关键能力(实验结果如下图4所示)。

那么怎么改进TextCNN模型的分类效果呢?从模型上看,无非就是以下几个大的方面:
1.词嵌入Embedding
2.卷积层
3.池化层
4全连接层
而Character-level Convolutional Networks for Text Classification这篇文章则从字符级卷积网络进行文本分类进行了实证探索。这个模型的优点就是模型结构简单,并且在大语料上效果很好,可以用于各种语言,不需要做分词处理,在噪音比较多的文本上表现较好。但是缺点就是字符级别的文本长度特别长,不利于处理长文本的分类,只使用字符级别信息,所以模型学习语义方面的信息较少而且在小语料上效果较差。后来学者们也研究了此问题,在论文Shallow word-level vs. deep character-level中就表明:即使在大量训练数据的情况下,浅层字级CNN也比最先进的超深字符级CNN更准确、更快。
为了进一步提高TextCNN模型的分类效果,弥补在获取短文本语义和上下文信息等方面的不足,学者们试图通过增加层数,增大了卷积核获取信息的视野,构建了深度CNN模型。
受这些的启发,Tencent AI Lab在2017年提出了Deep Pyramid Convolutional Neural Networks for Text Categorization模型,从模型性能上纵向比较来看,其也比经典的TextCNN(表格的第二行ShallowCNN)有了明显提高,在Yelp五分类情感分类任务中提升了近2个百分点。

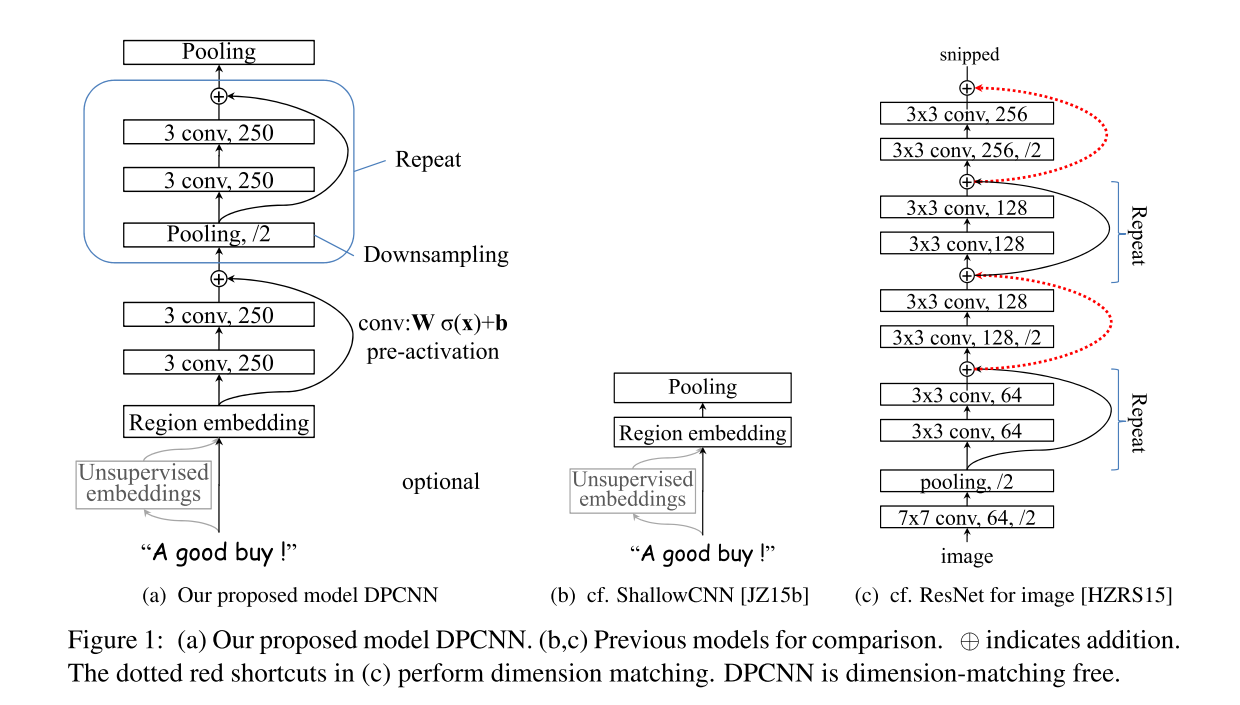
DPCNN的模型如上图。
模型详解
1.模型输入:[batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化,词向量维度为embedding_size。[batch_size, seq_len, embedding_size]
3.进行卷积,250个尺寸为3的卷积核,论文中称这层为region embedding。[batch_size, 250, seq_len - 2]
4.接两层卷积,每层都是250个尺寸为3的卷积核(等长卷积,先padding再卷积,保证卷积前后的序列长度不变)[batch_size, 250, seq_len - 2]
5.Repeat
a.进行大小为3,步长为2的最大池化,将序列长度压缩为原来的二分之一。(进行采样)
b.接两层等长卷积,每层都是250个尺寸为3的卷积核
c.a的结果加上b的结果
重复以上操作,直至序列长度等于1。[batch_size, 250, 1]
6.全连接 + softmax归一化:
[batch_size, num_class] ==> [batch_size, 1]
DPCNN的核心改进如下:
1.在Region embedding时不采用CNN那样加权卷积的做法,而是对n个词进行pooling后再加个1 * 1的卷积(这儿有疑问,查看一下源码),因为实验下来效果差不多,且作者认为前者的表示能力更强,
2.使用1/2池化层,用size=3 stride=2的卷积核,直接让模型可编码的sequence长度翻倍
3.残差连接,参考ResNet,减缓梯度弥散问题。
TextCNN的过程类似于提取n-gram信息,而且只有一层,难以捕捉长距离特征。而DPCNN,可以看出来它的region embedding就是一个去掉池化层的TextCNN,再将卷积层叠加。
每层序列长度都减半,如图7所示。可以这么理解:相当于在n-gram上再做n-gram。越往后的层,每个位置融合的信息越多,最后一层提取的就是整个序列的语义信息。

上面的DPCNN是从纵向增加层数构建的深度CNN模型,那么横向改变模型是否可行呢?比如在论文A Convolutional Neural Network for Modelling Sentences中使用了动态池化K-Max这一概念细化了短文本特征提取;同时,在池化层保留前K个最大特征值,从多个维度获取短文本特征。