
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置 16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1) 16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2) 16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3) 16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4) 16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6) 17、Flink 之Table API: Table API 支持的操作(1) 17、Flink 之Table API: Table API 支持的操作(2) 18、Flink的SQL 支持的操作和语法 19、Flink 的Table API 和 SQL 中的内置函数及示例(1) 19、Flink 的Table API 和 SQL 中的自定义函数及示例(2) 19、Flink 的Table API 和 SQL 中的自定义函数及示例(3) 19、Flink 的Table API 和 SQL 中的自定义函数及示例(4) 20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上 21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明 21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理 21、Flink 的table API与DataStream API 集成(3)- changelog流处理、管道示例、类型转换和老版本转换示例 21、Flink 的table API与DataStream API 集成(完整版) 22、Flink 的table api与sql之创建表的DDL 24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1 24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2 24、Flink 的table api与sql之Catalogs(java api操作视图)-3 24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4 25、Flink 的table api与sql之函数(自定义函数示例) 26、Flink 的SQL之概览与入门示例 27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1) 27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2) 27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3) 27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4) 27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5) 27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6) 27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7) 28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句 29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1) 29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2) 30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等) 31、Flink的SQL Gateway介绍及示例 32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例 33、Flink 的Table API 和 SQL 中的时区 35、Flink 的 Formats 之CSV 和 JSON Format 36、Flink 的 Formats 之Parquet 和 Orc Format 41、Flink之Hive 方言介绍及详细示例 40、Flink 的Apache Kafka connector(kafka source的介绍及使用示例)-1 40、Flink 的Apache Kafka connector(kafka sink的介绍及使用示例)-2 40、Flink 的Apache Kafka connector(kafka source 和sink 说明及使用示例) 完整版 42、Flink 的table api与sql之Hive Catalog 43、Flink之Hive 读写及详细验证示例 44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例--网上有些说法好像是错误的
(文章目录)
本文系统介绍了kafka连接器的source、sink、身份验证、版本升级、问题排查的几个主要 方面,关于常用的功能均以可运行的示例进行展示并提供完整的验证步骤。 本专题为了便于阅读以及整体查阅分为三个部分: 40、Flink 的Apache Kafka connector(kafka source的介绍及使用示例)-1 40、Flink 的Apache Kafka connector(kafka sink的介绍及使用示例)-2 40、Flink 的Apache Kafka connector(kafka source 和sink 说明及使用示例) 完整版 本文依赖kafka集群能正常使用。 本文分为9个部分,即maven依赖、source、sourcefunction、sink、producer、连接器指标、身份认证、版本升级及问题排查。 本文的示例是在Flink 1.17版本中运行。
一、Apache Kafka 连接器
Flink 提供了 Apache Kafka 连接器使用精确一次(Exactly-once)的语义在 Kafka topic 中读取和写入数据。
1、maven依赖
Apache Flink 集成了通用的 Kafka 连接器,它会尽力与 Kafka client 的最新版本保持同步。 该连接器使用的 Kafka client 版本可能会在 Flink 版本之间发生变化。 当前 Kafka client 向后兼容 0.10.0 或更高版本的 Kafka broker。 有关 Kafka 兼容性的更多细节,请参考 Kafka 官方文档。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.1</version>
</dependency>
如果使用 Kafka source,flink-connector-base 也需要包含在依赖中:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.17.1</version>
</dependency>
Flink 目前的流连接器还不是二进制发行版的一部分。 在集群中运行需要增加kafka的jar包,然后重启集群。比如/usr/local/bigdata/flink-1.13.5/lib/flink-sql-connector-kafka_2.11-1.13.5.jar。
2、kafka source
1)、使用示例
Kafka Source 提供了构建类来创建 KafkaSource 的实例。 以下代码片段展示了如何构建 KafkaSource 来消费 “alan_kafkasource” 最早位点的数据, 使用消费组 “flink_kafka”,并且将 Kafka 消息体反序列化为字符串:
1、Flink 1.13版本实现
- maven依赖
<properties>
<encoding>UTF-8</encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.13.6</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- flink连接器 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
</dependencies>
- 实现代码
import java.util.Properties;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
......
public static void test1() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
// 准备kafka连接参数
Properties props = new Properties();
// 集群地址
props.setProperty("bootstrap.servers", "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092");
// 消费者组id
props.setProperty("group.id", "flink_kafka");
// latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费
// earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props.setProperty("auto.offset.reset", "latest");
// 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("flink.partition-discovery.interval-millis", "5000");
// 自动提交(提交到默认主题,后续学习了Checkpoint后随着Checkpoint存储在Checkpoint和默认主题中)
props.setProperty("enable.auto.commit", "true");
// 自动提交的时间间隔
props.setProperty("auto.commit.interval.ms", "2000");
// 使用连接参数创建FlinkKafkaConsumer/kafkaSource
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("alan_kafkasource", new SimpleStringSchema(), props);
// 使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
// 3、 transformation
// 4、 sink
kafkaDS.print();
// 5、/ execute
env.execute();
}
- 验证
1、创建kafka主题alan_kafkasource,kafka命令发送数据
[alanchan@server2 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic alan_kafkasource --partitions 1 --replication-factor 1
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_kafkasource
>alan,18
>alanchan,19
>alanchan,20
2、启动应用程序,并观察控制台输出 
2、Flink 1.17版本实现
- maven依赖
<properties>
<encoding>UTF-8</encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- flink连接器 -->
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
- 实现代码
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
......
public static void test2() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("alan_kafkasource")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
// 4、 sink
kafkaDS.print();
// 5、execute
env.execute();
}
- 验证 1、创建kafka主题alan_kafkasource,kafka命令发送数据
[alanchan@server2 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic alan_kafkasource --partitions 1 --replication-factor 1
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_kafkasource
>alan,18
>alanchan,19
>alanchan,20
2、启动应用程序,并观察控制台输出 
3、说明
以下属性在构建 KafkaSource 时是必须指定的:
- Bootstrap server,通过 setBootstrapServers(String) 方法配置
- 消费者组 ID,通过 setGroupId(String) 配置
- 要订阅的 Topic / Partition,请参阅 Topic / Partition 一节
- 用于解析 Kafka 消息的反序列化器(Deserializer),请参阅消息解析一节
2)、Topic / Partition 订阅
Kafka Source 提供了 3 种 Topic / Partition 的订阅方式:
1、Topic 列表
订阅 Topic 列表中所有 Partition 的消息
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("alan_kafkasource1","alan_kafkasource2")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())
.build();
2、正则表达式匹配
订阅与正则表达式所匹配的 Topic 下的所有 Partition
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("alan_kafkasource*")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())
.build();
3、Partition 列表
订阅指定的 Partition
- 实现代码
import java.util.Arrays;
import java.util.HashSet;
import java.util.Properties;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.kafka.common.TopicPartition;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
........
public static void test3() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(
new TopicPartition("topic_alan", 0), // Partition 0 of topic "topic_alan"
new TopicPartition("topic_alanchan", 3))); // Partition 5 of topic "topic_alanchan"
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setPartitions(partitionSet)
//.setTopics("alan_kafkasource")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
// 4、 sink
kafkaDS.print();
// 5、execute
env.execute();
}
- 验证 1、创建kafka主题,topic_alan和topic_alanchan,其中topic_alanchan有四个分区,topic_alan只有一个分区 topic_alan主题信息
 topic_alanchan主题信息
topic_alanchan主题信息 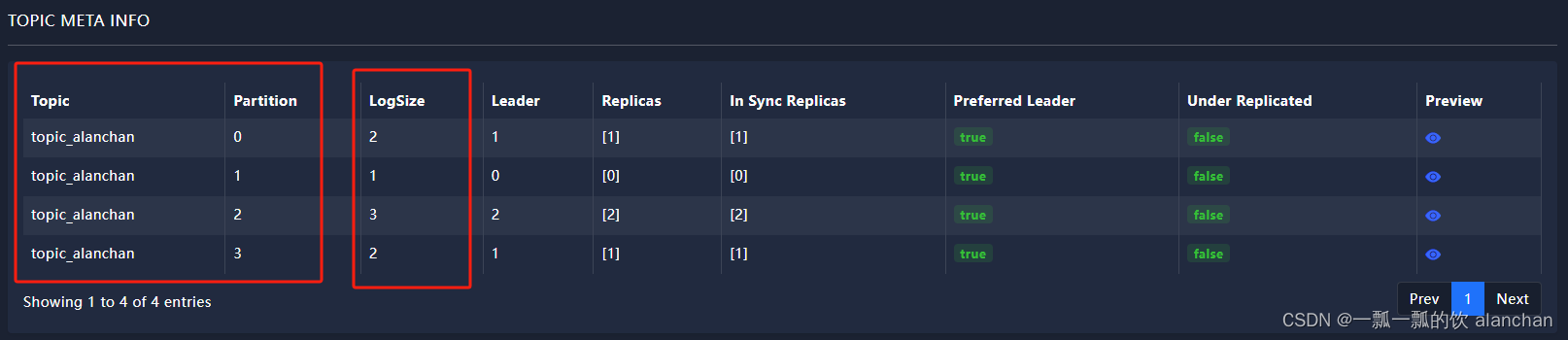
 topic_alanchan主题信息
topic_alanchan主题信息 
2、启动程序 3、通过命令向topic_alan和topic_alanchan主题中发送数据 topic_alan主题发送的数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic topic_alan
>alan,18
>alan,19
>alan,20
>

topic_alanchan主题发送的数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic topic_alanchan
>alanchan,28
>alan,29
>alanchan,30
>alanchan,31
>alanchan,32
>alanchan,33
>alanchan,34
>alanchan,35
>

4、程序控制台输出 
3)、消息解析
代码中需要提供一个反序列化器(Deserializer)来对 Kafka 的消息进行解析。 反序列化器通过 setDeserializer(KafkaRecordDeserializationSchema) 来指定,其中 KafkaRecordDeserializationSchema 定义了如何解析 Kafka 的 ConsumerRecord。
如果只需要 Kafka 消息中的消息体(value)部分的数据,可以使用 KafkaSource 构建类中的 setValueOnlyDeserializer(DeserializationSchema) 方法,其中 DeserializationSchema 定义了如何解析 Kafka 消息体中的二进制数据。
也可使用 Kafka 提供的解析器 来解析 Kafka 消息体。例如使用 StringDeserializer 来将 Kafka 消息体解析成字符串:
- 示例代码
import java.util.Arrays;
import java.util.HashSet;
import java.util.Properties;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
......
public static void test4() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("alan_kafkasource")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.earliest())
.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class))
// .setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
// 4、 sink
kafkaDS.print();
// 5、execute
env.execute();
}
- 验证结果 kafka命令发送数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_kafkasource
>alan,18
>alanchan,19
>alanchan,20
>
程序运行结果 
4)、起始消费位点
Kafka source 能够通过位点初始化器(OffsetsInitializer)来指定从不同的偏移量开始消费 。内置的位点初始化器包括:
KafkaSource.builder()
// 从消费组提交的位点开始消费,不指定位点重置策略
.setStartingOffsets(OffsetsInitializer.committedOffsets())
// 从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))
// 从时间戳大于等于指定时间戳(毫秒)的数据开始消费
.setStartingOffsets(OffsetsInitializer.timestamp(1657256176000L))
// 从最早位点开始消费
.setStartingOffsets(OffsetsInitializer.earliest())
// 从最末尾位点开始消费
.setStartingOffsets(OffsetsInitializer.latest());
- 示例代码
import java.util.Arrays;
import java.util.HashSet;
import java.util.Properties;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
......
public static void test5() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("topic_alanchan")
.setGroupId("flink_kafka")
// .setStartingOffsets(OffsetsInitializer.earliest())
.setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class))
// .setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
// 4、 sink
kafkaDS.print();
// 5、execute
env.execute();
}
- 验证 1、kafka命令行输入数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic topic_alanchan
>alanchan,37
>alanchan,38
>alanchan,39
>alanchan,40
>alanchan,41
>alanchan,42
>alanchan,43
>alanchan,44
>alanchan,45
>alanchan,46
>alanchan,47
>alanchan,48
>alanchan,49
>alanchan,50
>alanchan,51
>
2、运行程序,控制台输出结果  如果内置的初始化器不能满足需求,也可以实现自定义的位点初始化器(OffsetsInitializer)。
如果内置的初始化器不能满足需求,也可以实现自定义的位点初始化器(OffsetsInitializer)。
如果未指定位点初始化器,将默认使用 OffsetsInitializer.earliest()。
5)、有界 / 无界模式
Kafka Source 支持流式和批式两种运行模式。默认情况下,KafkaSource 设置为以流模式运行,因此作业永远不会停止,直到 Flink 作业失败或被取消。 可以使用 setBounded(OffsetsInitializer) 指定停止偏移量使 Kafka Source 以批处理模式运行。当所有分区都达到其停止偏移量时,Kafka Source 会退出运行。
流模式下运行通过使用 setUnbounded(OffsetsInitializer) 也可以指定停止消费位点,当所有分区达到其指定的停止偏移量时,Kafka Source 会退出运行。
- 示例代码
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
public static void test6() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("topic_alan")
.setGroupId("flink_kafka")
// .setStartingOffsets(OffsetsInitializer.earliest())
.setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class))
// .setValueOnlyDeserializer(new SimpleStringSchema())
.setUnbounded(OffsetsInitializer.timestamp(1700546218367L))
.build();
DataStreamSource<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
// 4、 sink
kafkaDS.print();
// 5、execute
env.execute();
}
6)、其他属性
除了上述属性之外,您还可以使用 setProperties(Properties) 和 setProperty(String, String) 为 Kafka Source 和 Kafka Consumer 设置任意属性。KafkaSource 有以下配置项:
- client.id.prefix,指定用于 Kafka Consumer 的客户端 ID 前缀
- partition.discovery.interval.ms,定义 Kafka Source 检查新分区的时间间隔。 请参阅下面的动态分区检查一节
- register.consumer.metrics 指定是否在 Flink 中注册 Kafka Consumer 的指标
- commit.offsets.on.checkpoint 指定是否在进行 checkpoint 时将消费位点提交至 Kafka broker
Kafka consumer 的配置可以参考 Apache Kafka 文档。
请注意,即使指定了以下配置项,构建器也会将其覆盖:
-
key.deserializer 始终设置为 ByteArrayDeserializer
-
value.deserializer 始终设置为 ByteArrayDeserializer
-
auto.offset.reset.strategy 被 OffsetsInitializer#getAutoOffsetResetStrategy() 覆盖
-
partition.discovery.interval.ms 会在批模式下被覆盖为 -1
-
示例代码
import java.util.Arrays;
import java.util.HashSet;
import java.util.Properties;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
......
public static void test7() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
// 准备kafka连接参数
Properties props = new Properties();
// 集群地址
props.setProperty("bootstrap.servers", "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092");
// 消费者组id
props.setProperty("group.id", "flink_kafka");
// latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费
// earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props.setProperty("auto.offset.reset", "latest");
// 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("flink.partition-discovery.interval-millis", "5000");
// 自动提交(提交到默认主题,后续学习了Checkpoint后随着Checkpoint存储在Checkpoint和默认主题中)
props.setProperty("enable.auto.commit", "true");
// 自动提交的时间间隔
props.setProperty("auto.commit.interval.ms", "2000");
KafkaSource<String> source = KafkaSource.<String>builder()
// .setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("topic_alan")
// .setGroupId("flink_kafka")
// .setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
// .setUnbounded(OffsetsInitializer.timestamp(1700546218367L))
.setProperties(props)
.build();
DataStreamSource<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
// 4、 sink
kafkaDS.print();
// 5、execute
env.execute();
}
7)、动态分区检查
为了在不重启 Flink 作业的情况下处理 Topic 扩容或新建 Topic 等场景,可以将 Kafka Source 配置为在提供的 Topic / Partition 订阅模式下定期检查新分区。要启用动态分区检查,请将 partition.discovery.interval.ms 设置为非负值:
// 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("flink.partition-discovery.interval-millis", "5000");
KafkaSource<String> source = KafkaSource.<String>builder().setProperties(props).build();
// 或通过方法属性设置
KafkaSource.builder().setProperty("partition.discovery.interval.ms", "10000"); // 每 10 秒检查一次新分区
分区检查功能默认不开启。需要显式地设置分区检查间隔才能启用此功能。
8)、事件时间和水印
默认情况下,Kafka Source 使用 Kafka 消息中的时间戳作为事件时间。您可以定义自己的水印策略(Watermark Strategy) 以从消息中提取事件时间,并向下游发送水印:
import java.time.Duration;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
......
public static void test1() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092").setTopics("topic_alan")
.setGroupId("flink_kafka").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();
// 设置Watermaker = 当前最大的事件时间 - 最大允许的延迟时间或乱序时间
DataStream<String> kafkaSource = env.fromSource(source, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "Kafka Source");
// 3、 transformation
// 4、 sink
kafkaSource.print();
// 5、execute
env.execute();
}
关于watermark内容可参考文章:7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)
9)、空闲
如果并行度高于分区数,Kafka Source 不会自动进入空闲状态。您将需要降低并行度或向水印策略添加空闲超时。如果在这段时间内没有记录在流的分区中流动,则该分区被视为“空闲”并且不会阻止下游操作符中水印的进度。
如果数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着 WatermarkGenerator 也不会获得任何新数据去生成 watermark。我们称这类数据源为空闲输入或空闲源。在这种情况下,当某些其他分区仍然发送事件数据的时候就会出现问题。由于下游算子 watermark 的计算方式是取所有不同的上游并行数据源 watermark 的最小值,则其 watermark 将不会发生变化。
为了解决这个问题,你可以使用 WatermarkStrategy 来检测空闲输入并将其标记为空闲状态。WatermarkStrategy 为此提供了一个工具接口:
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1));
- 示例代码
import java.time.Duration;
import java.util.Properties;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
/**
* @author alanchan
*
*/
public class TestKafkaSourceWithWatermarkDemo {
public static void test1() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("topic_alan")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
// 设置Watermaker = 当前最大的事件时间 - 最大允许的延迟时间或乱序时间
// default WatermarkStrategy<T> withIdleness(Duration idleTimeout)
// static <T> WatermarkStrategy<T> forBoundedOutOfOrderness(Duration maxOutOfOrderness)
DataStream< String> kafkaDS = env.fromSource(source,
(WatermarkStrategy)WatermarkStrategy
.forBoundedOutOfOrderness(Duration.ofSeconds(60))
.withIdleness(Duration.ofMinutes(60)),
"Kafka Source");
// DataStreamSource<String> kafkaDS = env.fromSource(source, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "Kafka Source");
// 3、 transformation
// 4、 sink
kafkaDS.print();
// 5、execute
env.execute();
}
public static void main(String[] args) throws Exception {
test1();
}
}
10)、消费位点提交
Kafka source 在 checkpoint 完成时提交当前的消费位点 ,以保证 Flink 的 checkpoint 状态和 Kafka broker 上的提交位点一致。如果未开启 checkpoint,Kafka source 依赖于 Kafka consumer 内部的位点定时自动提交逻辑,自动提交功能由 enable.auto.commit 和 auto.commit.interval.ms 两个 Kafka consumer 配置项进行配置。
Kafka source 不依赖于 broker 上提交的位点来恢复失败的作业。提交位点只是为了上报 Kafka consumer 和消费组的消费进度,以在 broker 端进行监控。
11)、监控
Kafka source 会在不同的范围 (Scope)中汇报下列指标。
1、范围
每个metric 度量都被分配了一个标识符和一组key-value对,在这些key-value对下将报告度量。
标识符基于3个组件:注册度量时的用户定义名称、可选的用户定义范围和系统提供的范围。例如,如果A.B是系统作用域,C.D是用户作用域,E是名称,那么度量的标识符将是A.B.C.D.E。
您可以通过在conf/flink-conf.yaml中设置metrics.scope.delimiter键来配置用于标识符的分隔符(默认值:.)。
1)、用户范围
您可以通过调用MetricGroup#addGroup(String name)、MetricGroup#addGroup(int name) 或MetricGroup#addGroup(String key, String value)来定义用户作用域。这些方法影响MetricGroup#getMetricIdentifier和MetricGroup#getScopeComponents返回的内容。
counter = getRuntimeContext()
.getMetricGroup()
.addGroup("MyMetrics")
.counter("myCounter");
counter = getRuntimeContext()
.getMetricGroup()
.addGroup("MyMetricsKey", "MyMetricsValue")
.counter("myCounter");
2)、系统范围System Scope
系统范围包含有关度量的上下文信息,例如它在哪个任务中注册,或者该任务属于哪个作业。
应该包括哪些上下文信息可以通过在conf/flink-conf.yaml中设置以下键来配置。这些键中的每一个都需要一个格式字符串,该字符串可能包含常量(例如“taskmanager”)和变量(例如“<task_id>”),这些常量和变量将在运行时被替换。
- metrics.scope.jm Default: <host>.jobmanager 应用于job manager范围内的所有指标
- metrics.scope.jm-job Default: <host>.jobmanager.<job_name> 应用于 job manager and job范围内的所有度量
- metrics.scope.tm Default: <host>.taskmanager.<tm_id> 应用于task manager范围内的所有度量
- metrics.scope.tm-job Default: <host>.taskmanager.<tm_id>.<job_name> 应用于范围为task manager and job的所有度量
- metrics.scope.task Default: <host>.taskmanager.<tm_id>.<job_name>.<task_name>.<subtask_index> 应用于task范围内的所有度量
- metrics.scope.operator Default: <host>.taskmanager.<tm_id>.<job_name>.<operator_name>.<subtask_index> 应用于作用域为operator的所有度量
变量的数量或顺序没有限制。变量区分大小写。 操作员度量的默认作用域将产生类似于 localhost.taskmanager.1234.MyJob.MyOperator.0.MyMetric 的标识符
如果还希望包含任务名称但省略task manager信息,则可以指定以下格式: metrics.scope.operator: <host>.<job_name>.<task_name>.<operator_name>.<subtask_index>
这可以创建标识符localhost localhost.MyJob.MySource_->_MyOperator.MyOperator.0.MyMetric.
对于此格式字符串,如果同一作业同时运行多次,可能会发生标识符冲突,从而导致度量数据不一致。因此,建议使用通过包括id(例如<job_id>)或通过为作业和运算符分配唯一名称来提供一定程度的唯一性的格式字符串。
3)、所有变量列表
- JobManager: <host>
- TaskManager: <host>, <tm_id>
- Job: <job_id>, <job_name>
- Task: <task_id>, <task_name>, <task_attempt_id>, <task_attempt_num>, <subtask_index>
- Operator: <operator_id>,<operator_name>, <subtask_index>
对于Batch API, <operator_id> = <task_id>.
4)、用户变量
您可以通过调用MetricGroup#addGroup(String key, String value)来定义用户变量。此方法会影响MetricGroup#getMetricIdentifier、MetricGroup#getScopeComponents和MetricGroup#getAllVariables()返回的内容。
用户变量不能用于范围格式。
2、指标范围
 该指标反映了最后一条数据的瞬时值。之所以提供瞬时值是因为统计延迟直方图会消耗更多资源,瞬时值通常足以很好地反映延迟。
该指标反映了最后一条数据的瞬时值。之所以提供瞬时值是因为统计延迟直方图会消耗更多资源,瞬时值通常足以很好地反映延迟。
3、Kafka Consumer 指标
Kafka consumer 的所有指标都注册在指标组 KafkaSourceReader.KafkaConsumer 下。
例如 Kafka consumer 的指标 records-consumed-total 将在该 Flink 指标中汇报: <some_parent_groups>.operator.KafkaSourceReader.KafkaConsumer.records-consumed-total。
您可以使用配置项 register.consumer.metrics 配置是否注册 Kafka consumer 的指标 。默认此选项设置为 true。
关于 Kafka consumer 的指标,您可以参考 Apache Kafka 文档 了解更多详细信息。
12)、安全
要启用加密和认证相关的安全配置,只需将安全配置作为其他属性配置在 Kafka source 上即可。
下面代码未经过验证,由于缺乏环境,代码来源于官网示例。
下面的代码片段展示了如何配置 Kafka source 以使用 PLAIN 作为 SASL 机制并提供 JAAS 配置:
KafkaSource.builder()
.setProperty("security.protocol", "SASL_PLAINTEXT")
.setProperty("sasl.mechanism", "PLAIN")
.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";");
使用 SASL_SSL 作为安全协议并使用 SCRAM-SHA-256 作为 SASL 机制:
KafkaSource.builder()
.setProperty("security.protocol", "SASL_SSL")
// SSL 配置
// 配置服务端提供的 truststore (CA 证书) 的路径
.setProperty("ssl.truststore.location", "/path/to/kafka.client.truststore.jks")
.setProperty("ssl.truststore.password", "test1234")
// 如果要求客户端认证,则需要配置 keystore (私钥) 的路径
.setProperty("ssl.keystore.location", "/path/to/kafka.client.keystore.jks")
.setProperty("ssl.keystore.password", "test1234")
// SASL 配置
// 将 SASL 机制配置为 as SCRAM-SHA-256
.setProperty("sasl.mechanism", "SCRAM-SHA-256")
// 配置 JAAS
.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";");
如果在作业 JAR 中 Kafka 客户端依赖的类路径被重置了(relocate class),登录模块(login module)的类路径可能会不同,因此请根据登录模块在 JAR 中实际的类路径来改写以上配置。 关于安全配置的详细描述,请参阅 Apache Kafka 文档中的"安全"一节。
13)、实现细节
在新 Source API 的抽象中,Kafka source 由以下几个部分组成:
1、数据源分片(Source Split)
Kafka source 的数据源分片(source split)表示 Kafka topic 中的一个 partition。Kafka 的数据源分片包括:
- 该分片表示的 topic 和 partition
- 该 partition 的起始位点
- 该 partition 的停止位点,当 source 运行在批模式时适用
Kafka source 分片的状态同时存储该 partition 的当前消费位点,该分片状态将会在 Kafka 源读取器(source reader)进行快照(snapshot) 时将当前消费位点保存为起始消费位点以将分片状态转换成不可变更的分片。
可查看 KafkaPartitionSplit 和 KafkaPartitionSplitState 类来了解细节。
2、分片枚举器(Split Enumerator)
Kafka source 的分片枚举器负责检查在当前的 topic / partition 订阅模式下的新分片(partition),并将分片轮流均匀地分配给源读取器(source reader)。 注意 Kafka source 的分片枚举器会将分片主动推送给源读取器,因此它无需处理来自源读取器的分片请求。
3、源读取器(Source Reader)
Kafka source 的源读取器扩展了 SourceReaderBase,并使用单线程复用(single thread multiplex)的线程模型,使用一个由分片读取器 (split reader)驱动的 KafkaConsumer 来处理多个分片(partition)。消息会在从 Kafka 拉取下来后在分片读取器中立刻被解析。分片的状态 即当前的消息消费进度会在 KafkaRecordEmitter 中更新,同时会在数据发送至下游时指定事件时间。
3、kafka sourcefunction
FlinkKafkaConsumer 已被弃用并将在 Flink 1.17 中移除,请改用 KafkaSource。 1.13版本的实现参考本文开头的示例。
4、kafka sink
KafkaSink 可将数据流写入一个或多个 Kafka topic。
1)、使用示例
Kafka sink 提供了构建类来创建 KafkaSink 的实例。
以下代码片段展示了如何将字符串数据按照至少一次(at lease once)的语义保证写入 Kafka topic:
1、Flink 1.13版本实现
- 实现代码
import java.util.Properties;
import java.util.Random;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class TestKafkaSinkDemo {
public static void test1() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、source-主题:alan_source
// 准备kafka连接参数
Properties propSource = new Properties();
propSource.setProperty("bootstrap.servers", "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092");// 集群地址
propSource.setProperty("group.id", "flink_kafka");
propSource.setProperty("auto.offset.reset", "latest");
propSource.setProperty("flink.partition-discovery.interval-millis", "5000");
propSource.setProperty("enable.auto.commit", "true");
// 自动提交的时间间隔
propSource.setProperty("auto.commit.interval.ms", "2000");
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("alan_source", new SimpleStringSchema(), propSource);
// 使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
// 3、transformation-统计单词个数
SingleOutputStreamOperator<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
private Random ran = new Random();
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] arr = value.split(",");
for (String word : arr) {
out.collect(Tuple2.of(word, 1));
}
}
}).keyBy(t -> t.f0).sum(1).map(new MapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
System.out.println("输出:" + value.f0 + "->" + value.f1);
return value.f0 + "->" + value.f1;
}
});
// 4、sink-主题alan_sink
Properties propSink = new Properties();
propSink.setProperty("bootstrap.servers", "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092");
propSink.setProperty("transaction.timeout.ms", "5000");
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("alan_sink", new KeyedSerializationSchemaWrapper(new SimpleStringSchema()), propSink,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE); // fault-tolerance
result.addSink(kafkaSink);
// 5、execute
env.execute();
}
public static void main(String[] args) throws Exception {
test1();
}
}
- 验证 1、创建kafka 主题 alan_source 和 alan_sink 2、驱动程序,观察运行控制台 3、通过命令往alan_source 写入数据,同时消费 alan_sink 主题的数据
## kafka生产数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_source
>alan,alach,alanchan,hello
>alan_chan,hi,flink
>alan,flink,good
>alan,alach,alanchan,hello
>hello,123
>
## kafka消费数据
[alanchan@server2 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic alan_sink --from-beginning
alanchan->1
hello->1
alan->1
alach->1
flink->1
alan_chan->1
hi->1
alan->2
flink->2
good->1
alanchan->2
hello->2
alan->3
alach->2
hello->3
123->1
4、应用程序控制台输出 
2、Flink 1.17版本实现
- 代码实现
import java.util.Properties;
import java.util.Random;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class TestKafkaSinkDemo {
public static void test2() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("alan_nsource")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
DataStream<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] arr = value.split(",");
for (String word : arr) {
out.collect(Tuple2.of(word, 1));
}
}
}).keyBy(t -> t.f0).sum(1).map(new MapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
System.out.println("输出:" + value.f0 + "->" + value.f1);
return value.f0 + "->" + value.f1;
}
});
// 4、 sink
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("alan_nsink")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
result.sinkTo(kafkaSink);
// 5、execute
env.execute();
}
public static void main(String[] args) throws Exception {
// test1();
test2();
}
}
- 验证 1、创建kafka 主题 alan_nsource 和 alan_nsink 2、驱动程序,观察运行控制台 3、通过命令往alan_nsource 写入数据,同时消费 alan_nsink 主题的数据
## kafka生产数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_nsource
>alan,alach,alanchan,hello
>alan_chan,hi,flink
>alan,flink,good
>alan,alach,alanchan,hello
>hello,123
>
## kafka消费数据
[alanchan@server2 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic alan_nsink --from-beginning
alanchan->1
hello->1
alan->1
alach->1
flink->1
alan_chan->1
hi->1
alan->2
flink->2
good->1
alanchan->2
alach->2
alan->3
hello->2
hello->3
123->1
4、应用程序控制台输出 
3、说明
以下属性在构建 KafkaSink 时是必须指定的:
- Bootstrap servers, setBootstrapServers(String)
- 消息序列化器(Serializer), setRecordSerializer(KafkaRecordSerializationSchema)
- 如果使用DeliveryGuarantee.EXACTLY_ONCE 的语义保证,则需要使用 setTransactionalIdPrefix(String)
2)、序列化器
构建时需要提供 KafkaRecordSerializationSchema 来将输入数据转换为 Kafka 的 ProducerRecord。Flink 提供了 schema 构建器 以提供一些通用的组件,例如消息键(key)/消息体(value)序列化、topic 选择、消息分区,同样也可以通过实现对应的接口来进行更丰富的控制。
KafkaRecordSerializationSchema.builder()
.setTopicSelector(new TopicSelector() {
@Override
public String apply(Object t) {
//设置选择的 topic
return "alan_nsink";
}})
.setValueSerializationSchema(new SimpleStringSchema())
.setKeySerializationSchema(new SimpleStringSchema())
.setPartitioner(new FlinkFixedPartitioner())
.build()
- 示例代码
import java.util.Properties;
import java.util.Random;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.sink.TopicSelector;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class TestKafkaSinkDemo {
public static void test3() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setTopics("alan_nsource")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
DataStream<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] arr = value.split(",");
for (String word : arr) {
out.collect(Tuple2.of(word, 1));
}
}
}).keyBy(t -> t.f0).sum(1).map(new MapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
System.out.println("输出:" + value.f0 + "->" + value.f1);
return value.f0 + "->" + value.f1;
}
});
// 4、 sink
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
.setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopicSelector(new TopicSelector() {
@Override
public String apply(Object t) {
//设置选择的 topic
return "alan_nsink";
}})
.setValueSerializationSchema(new SimpleStringSchema())
.setKeySerializationSchema(new SimpleStringSchema())
.setPartitioner(new FlinkFixedPartitioner())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
result.sinkTo(kafkaSink);
// 5、execute
env.execute();
}
public static void main(String[] args) throws Exception {
test3();
}
}
- 验证 1、创建kafka 主题 alan_nsource 和 alan_nsink 2、驱动程序,观察运行控制台 3、通过命令往alan_nsource 写入数据,同时消费 alan_nsink 主题的数据
## kafka生产数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_nsource
>alan,alach,alanchan,hello
>alan_chan,hi,flink
>alan,flink,good
>alan,alach,alanchan,hello
>hello,123
>
## kafka消费数据
[alanchan@server2 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic alan_nsink --from-beginning
alanchan->1
hello->1
alan->1
alach->1
flink->1
alan_chan->1
hi->1
alan->2
flink->2
good->1
alanchan->2
alach->2
alan->3
hello->2
hello->3
123->1
4、应用程序控制台输出 
其中消息体(value)序列化方法和 topic 的选择方法是必须指定的,此外也可以通过 setKafkaKeySerializer(Serializer) 或 setKafkaValueSerializer(Serializer) 来使用 Kafka 提供而非 Flink 提供的序列化器。
3)、容错
KafkaSink 总共支持三种不同的语义保证(DeliveryGuarantee)。对于 DeliveryGuarantee.AT_LEAST_ONCE 和 DeliveryGuarantee.EXACTLY_ONCE,Flink checkpoint 必须启用。
默认情况下 KafkaSink 使用 DeliveryGuarantee.NONE。
以下是对不同语义保证的解释:
- DeliveryGuarantee.NONE 不提供任何保证:消息有可能会因 Kafka broker 的原因发生丢失或因 Flink 的故障发生重复。
- DeliveryGuarantee.AT_LEAST_ONCE: sink 在 checkpoint 时会等待 Kafka 缓冲区中的数据全部被 Kafka producer 确认。消息不会因 Kafka broker 端发生的事件而丢失,但可能会在 Flink 重启时重复,因为 Flink 会重新处理旧数据。
- DeliveryGuarantee.EXACTLY_ONCE: 该模式下,Kafka sink 会将所有数据通过在 checkpoint 时提交的事务写入。因此,如果 consumer 只读取已提交的数据(参见 Kafka consumer 配置 isolation.level),在 Flink 发生重启时不会发生数据重复。然而这会使数据在 checkpoint 完成时才会可见,因此请按需调整 checkpoint 的间隔。请确认事务 ID 的前缀(transactionIdPrefix)对不同的应用是唯一的,以保证不同作业的事务 不会互相影响!此外,强烈建议将 Kafka 的事务超时时间调整至远大于 checkpoint 最大间隔 + 最大重启时间,否则 Kafka 对未提交事务的过期处理会导致数据丢失。
关于容错,请参考文章:9、Flink四大基石之Checkpoint容错机制详解及示例(checkpoint配置、重启策略、手动恢复checkpoint和savepoint)
4)、监控
Kafka sink 会在不同的范围(Scope)中汇报下列指标。 
5、kafka producer
FlinkKafkaProducer 已被弃用并将在 Flink 1.15 中移除,请改用 KafkaSink。
关于Flink 1.13版本的实现,请参考上文中的示例。
6、kafka 连接器指标
Flink 的 Kafka 连接器通过 Flink 的指标系统提供一些指标来帮助分析 connector 的行为。 各个版本的 Kafka producer 和 consumer 会通过 Flink 的指标系统汇报 Kafka 内部的指标。 该 Kafka 文档列出了所有汇报的指标。
同样也可通过将 Kafka source 在该章节描述的 register.consumer.metrics,或 Kafka sink 的 register.producer.metrics 配置设置为 false 来关闭 Kafka 指标的注册。
7、启用 Kerberos 身份验证
Flink 通过 Kafka 连接器提供了一流的支持,可以对 Kerberos 配置的 Kafka 安装进行身份验证。只需在 flink-conf.yaml 中配置 Flink。 像这样为 Kafka 启用 Kerberos 身份验证:
1、通过设置以下内容配置 Kerberos 票据
- security.kerberos.login.use-ticket-cache:默认情况下,这个值是 true,Flink 将尝试在 kinit 管理的票据缓存中使用 Kerberos 票据。注意!在 YARN 上部署的 Flink jobs 中使用 Kafka 连接器时,使用票据缓存的 Kerberos 授权将不起作用。
- security.kerberos.login.keytab 和 security.kerberos.login.principal:要使用 Kerberos keytabs,需为这两个属性设置值。
2、将 KafkaClient 追加到 security.kerberos.login.contexts:这告诉 Flink 将配置的 Kerberos 票据提供给 Kafka 登录上下文以用于 Kafka 身份验证。
一旦启用了基于 Kerberos 的 Flink 安全性后,只需在提供的属性配置中包含以下两个设置(通过传递给内部 Kafka 客户端),即可使用 Flink Kafka Consumer 或 Producer 向 Kafk a进行身份验证:
- 将 security.protocol 设置为 SASL_PLAINTEXT(默认为 NONE):用于与 Kafka broker 进行通信的协议。使用独立 Flink 部署时,也可以使用 SASL_SSL;请在此处查看如何为 SSL 配置 Kafka 客户端。
- 将 sasl.kerberos.service.name 设置为 kafka(默认为 kafka):此值应与用于 Kafka broker 配置的 sasl.kerberos.service.name 相匹配。客户端和服务器配置之间的服务名称不匹配将导致身份验证失败。
有关 Kerberos 安全性 Flink 配置的更多信息,请参见这里。你也可以在这里进一步了解 Flink 如何在内部设置基于 kerberos 的安全性。
该部分由于没有环境,未做验证,内容来至于官网。将来拟计划以专栏的形式介绍该部分内容。
8、升级到最近的连接器版本
通用的升级步骤概述见 升级 Jobs 和 Flink 版本指南。对于 Kafka,你还需要遵循这些步骤:
- 不要同时升级 Flink 和 Kafka 连接器
- 确保你对 Consumer 设置了 group.id
- 在 Consumer 上设置 setCommitOffsetsOnCheckpoints(true),以便读 offset 提交到 Kafka。务必在停止和恢复 savepoint 前执行此操作。你可能需要在旧的连接器版本上进行停止/重启循环来启用此设置。
- 在 Consumer 上设置 setStartFromGroupOffsets(true),以便我们从 Kafka 获取读 offset。这只会在 Flink 状态中没有读 offset 时生效,这也是为什么下一步非要重要的原因。
- 修改 source/sink 分配到的 uid。这会确保新的 source/sink 不会从旧的 sink/source 算子中读取状态。
- 使用 --allow-non-restored-state 参数启动新 job,因为我们在 savepoint 中仍然有先前连接器版本的状态。
9、问题排查
如果在使用 Flink 时对 Kafka 有问题,Flink 只封装 KafkaConsumer 或 KafkaProducer,你的问题可能独立于 Flink,有时可以通过升级 Kafka broker 程序、重新配置 Kafka broker 程序或在 Flink 中重新配置 KafkaConsumer 或 KafkaProducer 来解决。
一句话,大概是kafka的问题或配置的kafka的问题,和flink关系不大。
下面列出了一些常见问题的示例。
1)、数据丢失
根据你的 Kafka 配置,即使在 Kafka 确认写入后,你仍然可能会遇到数据丢失。特别要记住在 Kafka 的配置中设置以下属性:
- acks
- log.flush.interval.messages
- log.flush.interval.ms
- log.flush.*
上述选项的默认值是很容易导致数据丢失的。请参考 Kafka 文档以获得更多的解释。
2)、UnknownTopicOrPartitionException
导致此错误的一个可能原因是正在进行新的 leader 选举,例如在重新启动 Kafka broker 之后或期间。这是一个可重试的异常,因此 Flink job 应该能够重启并恢复正常运行。也可以通过更改 producer 设置中的 retries 属性来规避。但是,这可能会导致重新排序消息,反过来可以通过将 max.in.flight.requests.per.connection 设置为 1 来避免不需要的消息。
3)、ProducerFencedException
这个错误是由于 FlinkKafkaProducer 所生成的 transactional.id 与其他应用所使用的的产生了冲突。多数情况下,由于 FlinkKafkaProducer 产生的 ID 都是以 taskName + "-" + operatorUid 为前缀的,这些产生冲突的应用也是使用了相同 Job Graph 的 Flink Job。 我们可以使用 setTransactionalIdPrefix() 方法来覆盖默认的行为,为每个不同的 Job 分配不同的 transactional.id 前缀来解决这个问题。
以上,本文系统介绍了kafka连接器的source、sink、身份验证、版本升级、问题排查的几个主要 方面,关于常用的功能均以可运行的示例进行展示并提供完整的验证步骤。 本专题为了便于阅读以及整体查阅分为三个部分: 40、Flink 的Apache Kafka connector(kafka source的介绍及使用示例)-1 40、Flink 的Apache Kafka connector(kafka sink的介绍及使用示例)-2 40、Flink 的Apache Kafka connector(kafka source 和sink 说明及使用示例) 完整版 本专题为了便于阅读以及整体查阅分为三个部分: