
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。
-
2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。
-
3、Flik Table API和SQL基础系列 本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。
-
4、Flik Table API和SQL提高与应用系列 本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。
-
5、Flink 监控系列 本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
(文章目录)
本文介绍了Flink sink结果至console、文件和socket几端中,具体以实际情况为准。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本专题分为以下几篇文章: 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(1) - File、Socket、console 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(2) - jdbc/mysql 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(3) - redis 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(4) - clickhouse 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(5) - kafka 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(6) - 分布式缓存 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(7) - 广播变量 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(8) - 完整版
一、maven依赖
<properties>
<encoding>UTF-8</encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
</dependencies>
二、Flink sink介绍
Data sinks 使用 DataStream 并将它们转发到文件、套接字、外部系统或打印它们。
Flink 自带了多种内置的输出格式,这些格式相关的实现封装在 DataStreams 的算子里:
- writeAsText() / TextOutputFormat - 将元素按行写成字符串。通过调用每个元素的 toString() 方法获得字符串。
- writeAsCsv(…) / CsvOutputFormat - 将元组写成逗号分隔值文件。行和字段的分隔符是可配置的。每个字段的值来自对象的 toString() 方法。
- print() / printToErr() - 在标准输出/标准错误流上打印每个元素的 toString() 值。 可选地,可以提供一个前缀(msg)附加到输出。这有助于区分不同的 print 调用。如果并行度大于1,输出结果将附带输出任务标识符的前缀。
- writeUsingOutputFormat() / FileOutputFormat - 自定义文件输出的方法和基类。支持自定义 object 到 byte 的转换。
- writeToSocket - 根据 SerializationSchema 将元素写入套接字。
- addSink - 调用自定义 sink function。Flink 捆绑了连接到其他系统(例如 Apache Kafka)的连接器,这些连接器被实现为 sink functions。
注意,DataStream 的 write*() 方法主要用于调试目的。它们不参与 Flink 的 checkpointing,这意味着这些函数通常具有至少有一次语义。刷新到目标系统的数据取决于 OutputFormat 的实现。这意味着并非所有发送到 OutputFormat 的元素都会立即显示在目标系统中。此外,在失败的情况下,这些记录可能会丢失。
为了将流可靠地、精准一次地传输到文件系统中,请使用 FileSink。此外,通过 .addSink(…) 方法调用的自定义实现也可以参与 Flink 的 checkpointing,以实现精准一次的语义。
三、sink 到文件、console示例
1、console输出
该种方法比较简单,直接调用print方法即可。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*
*/
public class TestSinkFileDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> ds = env.fromElements("i am alanchan", "i like flink");
System.setProperty("HADOOP_USER_NAME", "alanchan");
// transformation
// sink
ds.print();
ds.print("输出标识");
// i like flink
// i am alanchan
// 输出标识> i like flink
// 输出标识> i am alanchan
// execute
env.execute();
}
}
2、sink到文件
1)、sink txt文件到hdfs上
sink到本地是一样的,不再赘述。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*
*/
public class TestSinkFileDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> ds = env.fromElements("i am alanchan", "i like flink");
System.setProperty("HADOOP_USER_NAME", "alanchan");
// transformation
// sink
ds.print();
ds.print("输出标识");
// i like flink
// i am alanchan
// 输出标识> i like flink
// 输出标识> i am alanchan
// 并行度与写出的文件个数有关,一个并行度写一个文件,多个并行度写多个文件
//如果并行度是1的话,该路径是一个文件名称;
//如果并行度大于1的话,该路径是一个文件夹,文件夹下的文件名是并行度的数字,并行度为2,该文件夹下会创建名称为1和2的两个文件
//运行下面的示例时,hdfs上不能存在该文件,也即下面两行代码运行时需要注释一行
ds.writeAsText("hdfs://server2:8020///flinktest/sinktest/words").setParallelism(2);
ds.writeAsText("hdfs://server2:8020///flinktest/sinktest/words").setParallelism(1);
// execute
env.execute();
}
}
- 并行度为1的运行结果如下
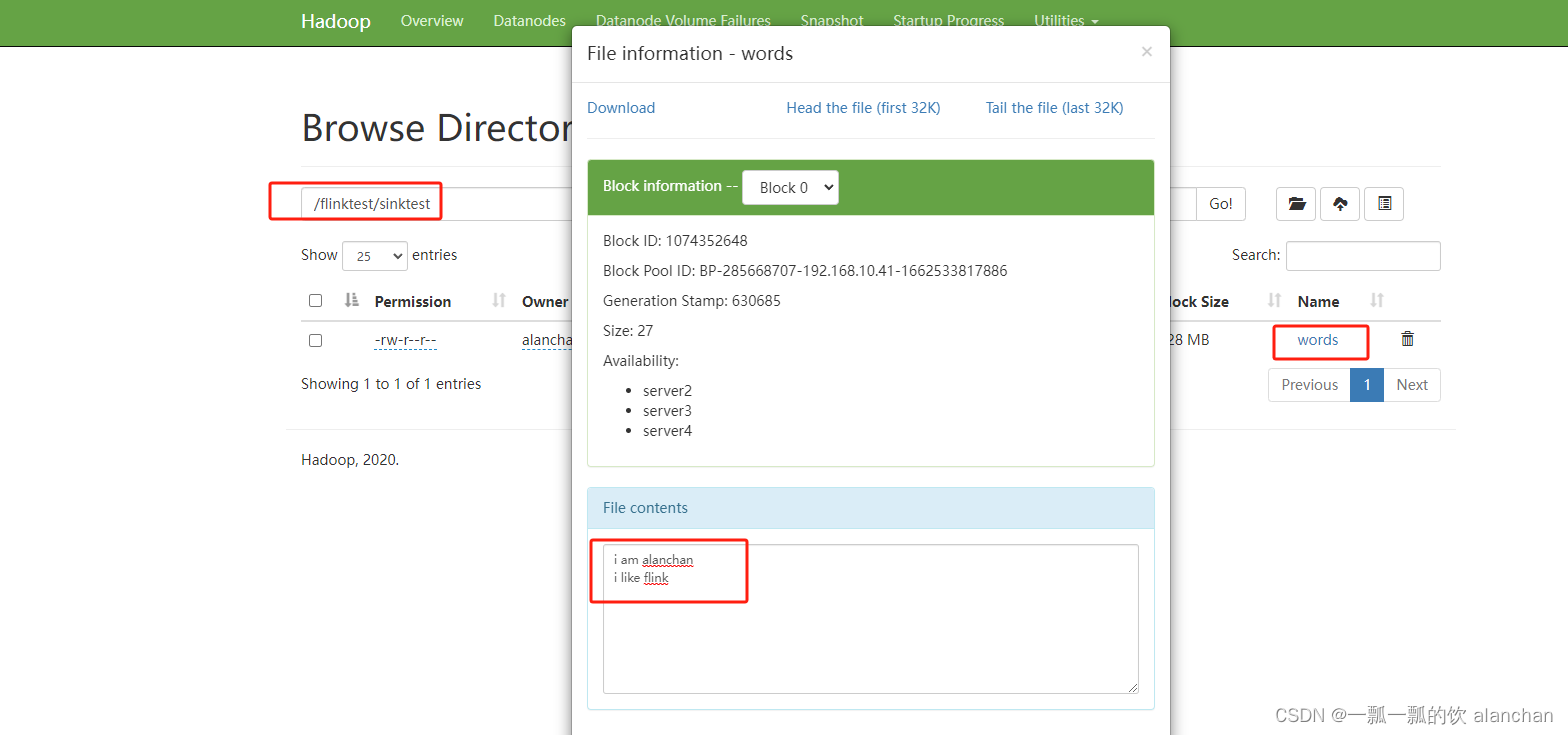
- 并行度为2的运行结果如下
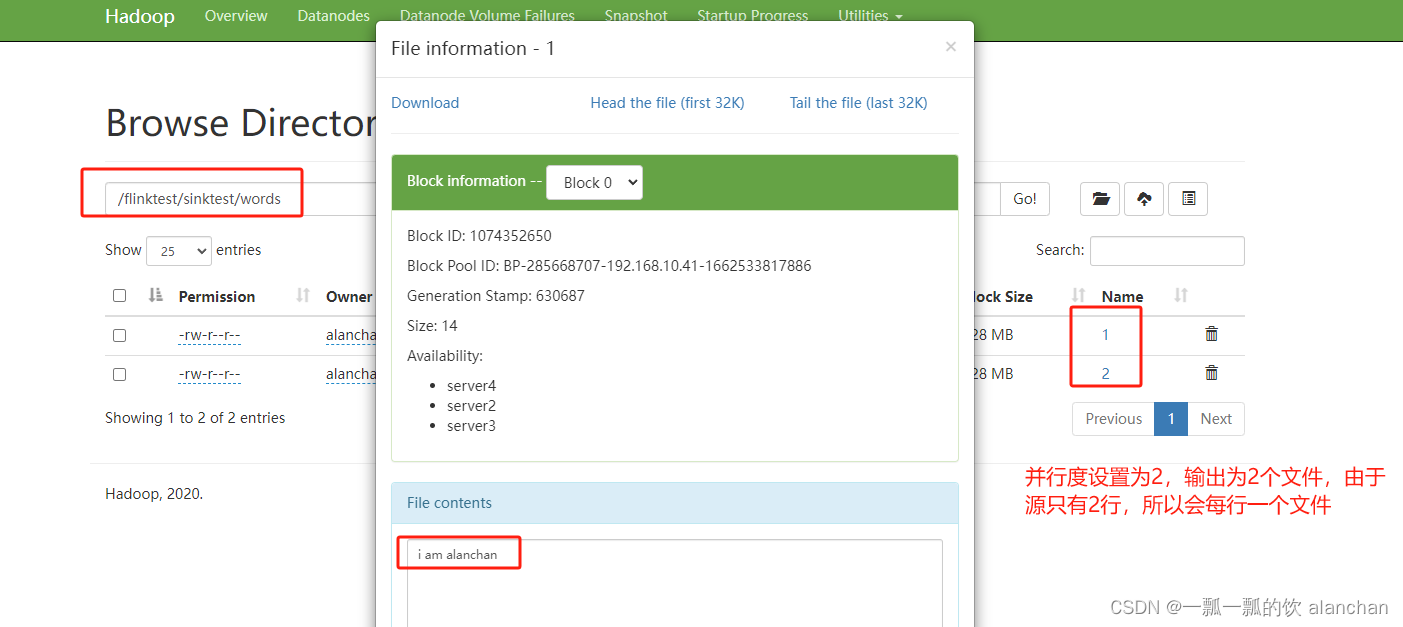


2)、sink csv文件到本地
该方法中只能使用tuple格式组织数据
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.FileSystem.WriteMode;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*
*/
public class TestSinkFileDemo {
public static final String DEFAULT_LINE_DELIMITER = "\n";
public static final String DEFAULT_FIELD_DELIMITER = ",";
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<Tuple2<Integer, String>> ds = env.fromElements(
Tuple2.of(1, "i am alanchan"),
Tuple2.of(2, "i like flink"),
Tuple2.of(3, "i like hadoop too"),
Tuple2.of(4, "你呢?")
);
// transformation
// sink
String file = "D:\\workspace\\flink1.17-java\\testdatadir\\csvfile.csv";
// 使用默认的其他三个参数
// ds.writeAsCsv(file);
// ds.writeAsCsv(file, WriteMode.OVERWRITE);
ds.writeAsCsv(file, WriteMode.OVERWRITE, DEFAULT_LINE_DELIMITER, DEFAULT_FIELD_DELIMITER);
// execute
env.execute();
}
}
- 输出文件
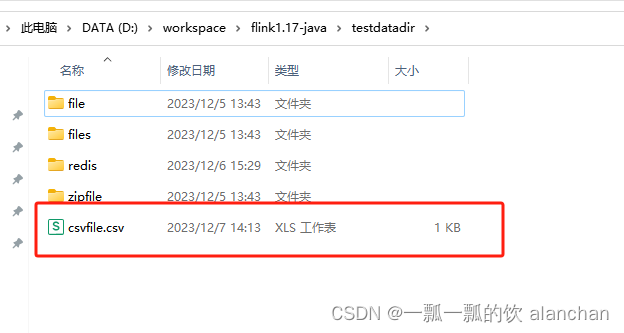


3)、sink text文件到hdfs上(writeUsingOutputFormat)
输出格式Flink 1.17版本实现的如下 
FileOutputFormat系统已经实现了几种格式,如下 
完整代码如下
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.io.FileOutputFormat.OutputDirectoryMode;
import org.apache.flink.api.java.io.CsvOutputFormat;
import org.apache.flink.api.java.io.TextOutputFormat;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.FileSystem.WriteMode;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*
*/
public class TestSinkFileDemo {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> ds = env.fromElements("i am alanchan", "i like flink");
System.setProperty("HADOOP_USER_NAME", "alanchan");
// transformation
// sink
TextOutputFormat format = new TextOutputFormat(new Path("hdfs://server1:8020///flinktest/sinktest/foramts"), "UTF-8");
// CsvOutputFormat format_csv = new CsvOutputFormat(new Path());
format.setOutputDirectoryMode(OutputDirectoryMode.ALWAYS);
format.setWriteMode(WriteMode.OVERWRITE);
ds.writeUsingOutputFormat(format);
// execute
env.execute();
}
}
- 程序运行后,hdfs文件输出结果
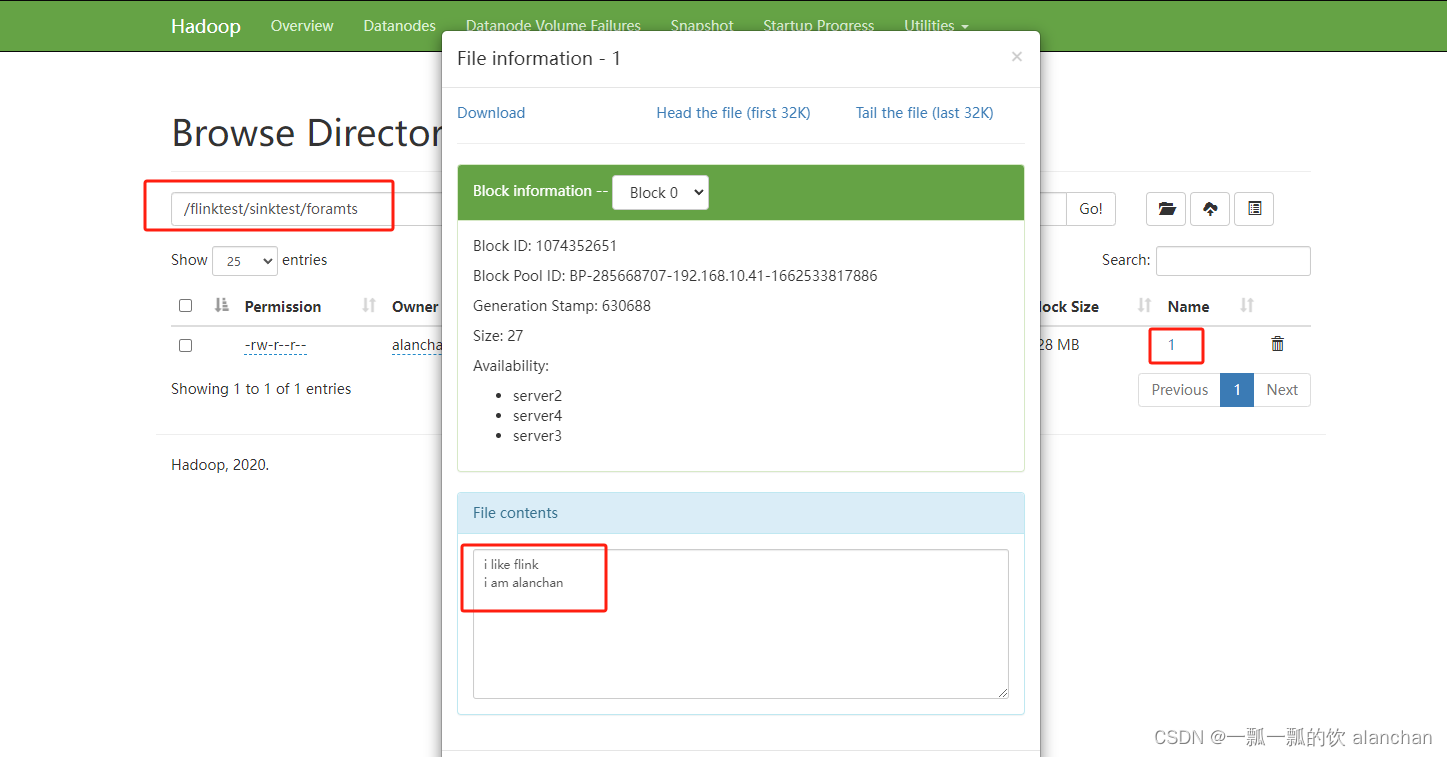

四、sink到socket示例(writeToSocket)
本示例比较简单,没有太多需要说明的地方。 下图是系统内置实现的序列化类,根据自己的需要选择。  完整代码实现
完整代码实现
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.formats.json.JsonSerializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
/**
* @author alanchan
*
*/
public class TestSinkSocketDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> ds = env.fromElements("i am alanchan", "i like flink");
// transformation
// sink
// ip、端口、序列化
ds.writeToSocket("192.168.10.42", 9999, new SimpleStringSchema());
// execute
env.execute();
}
}
- 验证
1、先开通9999端口,本示例是通过nc -lk 9999 来开启的 2、启动应用程序 3、观察9999端口的输出 
以上,本文介绍了Flink sink结果至console、文件和socket几端中,具体以实际情况为准。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为以下几篇文章: 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(1) - File、Socket、console 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(2) - jdbc/mysql 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(3) - redis 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(4) - clickhouse 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(5) - kafka 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(6) - 分布式缓存 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(7) - 广播变量 【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(8) - 完整版