
【HMM基本概念】
隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,用于描述一个含有未知参数(隐状态)的马尔可夫过程。在HMM中,我们不能直接观察到状态,但可以观察到每个状态产生的一些相关数据(观测值)。HMM的目标是,给定观测序列,估计出最可能的状态序列。
HMM的基本假设有两个(见例子的图):
1. 齐次马尔可夫性假设:即任意时刻的状态只与前一时刻的状态有关,与其他时刻状态及观测无关。
2. 观测独立性假设:即任意时刻的观测只与该时刻的状态有关,与其他观测和状态无关。
【举一个例子】
举一个日常生活中的例子,我们希望根据当前天气的情况来预测未来天气情况。一种办法就是假设这个模型的每个状态都只依赖于前一个的状态,即马尔科夫假设,这个假设可以极大简化这个问题。当然,这个例子也是有些不合实际的。但是,这样一个简化的系统可以有利于我们的分析,所以我们通常接受这样的假设,因为我们知道这样的系统能让我们获得一些有用的信息,尽管不是十分准确的。

上面的图显示了天气进行转移的模型。天气类型为三种:sunny, cloudy, rainy,
注意一个含有N个状态的一阶过程有N²个状态转移。每一个转移的概率叫做状态转移概率,就是从一个状态转移到另一个状态的概率。这所有的N²个概率可以用一个状态转移矩阵来表示,上面天气例子的状态转移矩阵如下:
[[0.5, 0.375, 0.125],
[0.25, 0.125, 0.625],
[0.25, 0.375, 0.375]]

这个矩阵表示,如果昨天是阴天,那么今天有25%的可能是晴天,12.5%的概率是阴天,62.5%的概率会下雨,很明显,矩阵中每一行的和都是1。
为了初始化这样一个系统,我们需要一个初始的概率向量:
[1.0, 0.0, 0.0]

这个向量表示第一天是晴天。到这里,我们就为上面的一阶马尔科夫过程定义了以下三个部分:
- 状态:晴天、阴天和下雨。
- 初始向量:定义系统在时间为0的时候的状态的概率。
- 状态转移矩阵:每种天气转换的概率。所有的能被这样描述的系统都是一个马尔科夫过程。
然而,当马尔科夫过程不够强大的时候,我们又该怎么办呢?在某些情况下,马尔科夫过程不足以描述我们希望发现的模式。
比如我们的股市,如果只是观测市场,我们只能知道当天的价格、成交量等信息,但是并不知道当前股市处于什么样的状态(牛市、熊市、震荡、反弹等等),在这种情况下我们有两个状态集合,一个可以观察到的状态集合(股市价格成交量状态等)和一个隐藏的状态集合(股市状况)。我们希望能找到一个算法可以根据股市价格成交量状况和马尔科夫假设来预测股市的状况。
在上面的这些情况下,可以观察到的状态序列和隐藏的状态序列是概率相关的。于是我们可以将这种类型的过程建模为有一个隐藏的马尔科夫过程和一个与这个隐藏马尔科夫过程概率相关的并且可以观察到的状态集合,就是隐马尔可夫模型。
隐马尔可夫模型(Hidden Markov Model) 是一种统计模型,用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步的分析。下图是一个三个状态的隐马尔可夫模型状态转移图,其中x表示隐含状态,y表示可观察的输出,a表示状态转换概率,b表示输出概率(也就是观测概率,见第二个例子,y仅仅和当前状态x有关)。

隐马尔可夫模型(HMM)的观测序列生成是指根据模型的参数(初始状态概率、状态转移概率和观测概率)生成一系列的观测数据。
具体步骤如下:
1. 根据初始状态概率分布选择一个初始状态。
2. 根据当前状态的观测概率分布生成一个观测数据。
3. 根据当前状态的状态转移概率分布选择下一个状态。
4. 重复步骤2和3,直到生成足够数量的观测数据。
一个HMM应用:根据当前天气的情况来预测未来天气情况
天气类型为三种:sunny, cloudy, rainy,
注意一个含有N个状态的一阶过程有N²个状态转移。每一个转移的概率叫做状态转移概率,就是从一个状态转移到另一个状态的概率。这所有的N²个概率可以用一个状态转移矩阵来表示,上面天气例子的状态转移矩阵如下:
[[0.5, 0.375, 0.125],
[0.25, 0.125, 0.625],
[0.25, 0.375, 0.375]]
这个矩阵表示,如果昨天是阴天,那么今天有25%的可能是晴天,12.5%的概率是阴天,62.5%的概率会下雨,很明显,矩阵中每一行的和都是1。
为了初始化这样一个系统,我们需要一个初始的概率向量:
[1.0, 0.0, 0.0]
这个向量表示第一天是晴天。到这里,我们就为上面的一阶马尔科夫过程定义了以下三个部分:
状态:晴天、阴天和下雨。
初始向量:定义系统在时间为0的时候的状态的概率。
状态转移矩阵:每种天气转换的概率。所有的能被这样描述的系统都是一个马尔科夫过程。
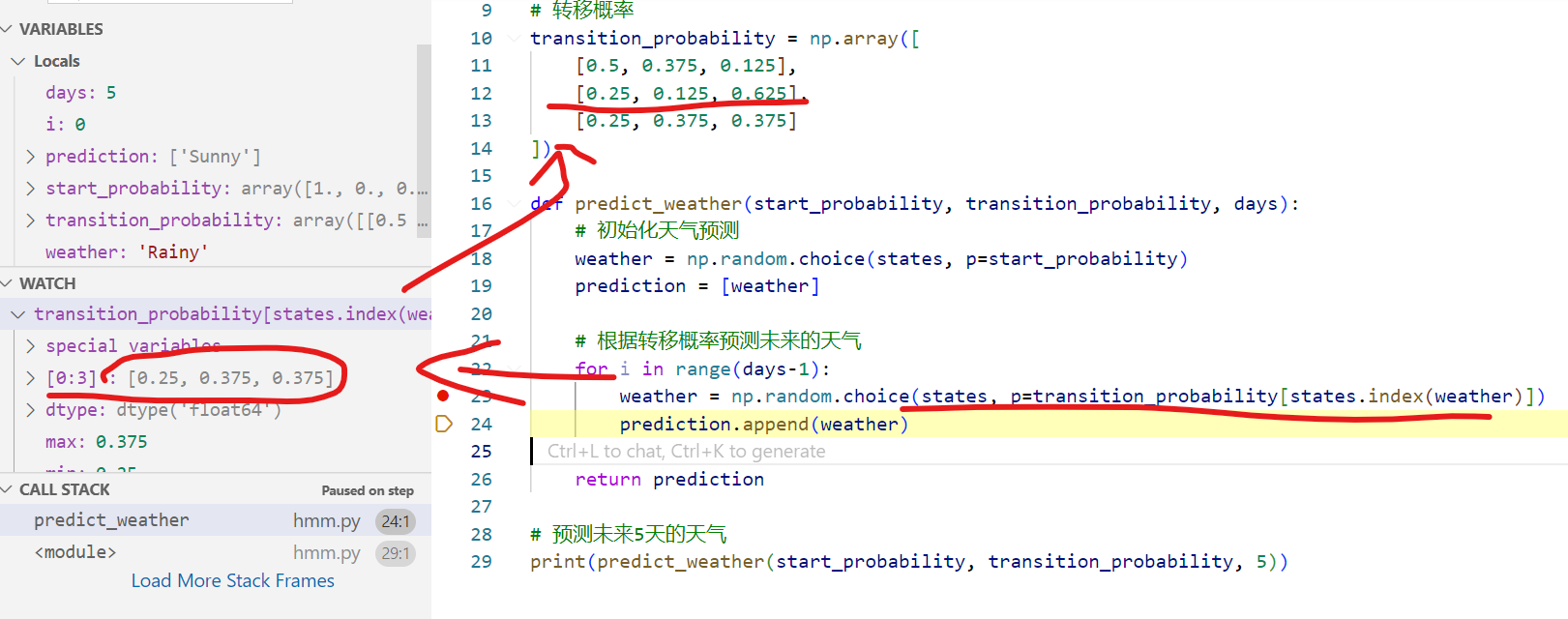
使用HMM预测未来5天的天气。给出python代码如下:
【python编码实现】
import numpy as np
# 状态集合
states = ('Sunny', 'Cloudy', 'Rainy')
# 初始状态概率
start_probability = np.array([1.0, 0.0, 0.0])
# 转移概率
transition_probability = np.array([
[0.5, 0.375, 0.125],
[0.25, 0.125, 0.625],
[0.25, 0.375, 0.375]
])
def predict_weather(start_probability, transition_probability, days):
# 初始化天气预测
weather = np.random.choice(states, p=start_probability)
prediction = [weather]
# 根据转移概率预测未来的天气
for i in range(days-1):
weather = np.random.choice(states, p=transition_probability[states.index(weather)])
prediction.append(weather)
return prediction
# 预测未来5天的天气
print(predict_weather(start_probability, transition_probability, 5))
输出:
['Sunny', 'Sunny', 'Rainy', 'Rainy', 'Rainy']
上面这个例子没有观测概率这个,因为观测值是基于隐含变量的概率分布输出。
我们来一个有观测概率的例子。就是说y的输出依赖观测概率b1,而b1依赖隐藏变量x,
【再来一个例子】该例来自《统计学习方法》例10.1
python编程实现,hmm的算法应用:
假设有4个盒子,每个盒子里面都有红白两种颜色的球,各个盒子里面的红白球数量分布为观测概率矩阵,如下:
[[0.5, 0.5], ==》例如,选择了盒子1,则红白球概率都是0.5
[0.6, 0.4], ==》选择了盒子2,则红白球概率是0.6和0.4
[0.2, 0.8],
[0.3, 0.7]] ==》无非就是选择了某一个盒子,则红白球的输出概率会改变!
从4个盒子里等概率地选择1个盒子,从这个盒子里随机摸一个球,记录颜色后放回。然后从当前盒子随机转移到下一个盒子,转移规则如下:如果当前盒子为1,那么下一个盒子一定是2;如果当前盒子是2或者3,则分别以概率0.4和0.6转移到左边或者右边的盒子;如果当前盒子是4,那么各以0.5的概率停留在4或者转移到3,确定了转移的盒子后,就从该盒子中随机摸取一个球记录其颜色并放回。
将上述摸球试验独立重复进行5次,得到一个球的观测序列为:[白, 红, 白, 红, 红]
按照HMM的三要素来分析该例子。在上述摸球过程中,我们只能观测到摸到的球的颜色,即可以观测到球的颜色序列,而观察不到球是从哪个盒子摸到的,即观测不到盒子的序列。所以,该例中状态序列即为盒子的序列,观测序列即为摸到的球的颜色序列,具体如下所示。
状态序列为:[盒子1, 盒子2, 盒子3, 盒子4]
观测序列为:[红球, 白球]
状态序列和观测序列长度5,初始概率分布为:[0.25, 0.25, 0.25, 0.25]
状态转移概率分布矩阵为:
[[0,1,0,0],
[0.4,0,0.6,0],
[0, 0.4, 0, 0.6],
[0, 0, 0.5, 0.5]]
根据前面的HMM理论和案例分析,生成其观测序列。
import numpy as np
# 状态集合
states = ('Box1', 'Box2', 'Box3', 'Box4')
# 观测集合
observations = ('Red', 'White')
# 初始状态概率
start_probability = np.array([0.25, 0.25, 0.25, 0.25])
# 状态转移概率
transition_probability = np.array([
[0, 1, 0, 0],
[0.4, 0, 0.6, 0],
[0, 0.4, 0, 0.6],
[0, 0, 0.5, 0.5]
])
# 观测概率
emission_probability = np.array([
[0.5, 0.5],
[0.6, 0.4],
[0.2, 0.8],
[0.3, 0.7]
])
def generate_sequence(start_probability, transition_probability, emission_probability, length):
# 初始化状态和观测
state = np.random.choice(states, p=start_probability)
observation = np.random.choice(observations, p=emission_probability[states.index(state)])
states_sequence = [state]
observations_sequence = [observation]
# 根据状态转移概率和观测概率生成序列
for i in range(length-1):
state = np.random.choice(states, p=transition_probability[states.index(state)])
observation = np.random.choice(observations, p=emission_probability[states.index(state)])
states_sequence.append(state)
observations_sequence.append(observation)
return states_sequence, observations_sequence
# 生成长度为5的状态序列和观测序列
states_sequence, observations_sequence = generate_sequence(start_probability, transition_probability, emission_probability, 5)
print('States Sequence: ', states_sequence)
print('Observations Sequence: ', observations_sequence)
输出:
States Sequence: ['Box4', 'Box3', 'Box2', 'Box3', 'Box2']
Observations Sequence: ['White', 'White', 'Red', 'White', 'Red']
【动态规划的维特比算法】
接下来是维特比算法了,先举一个通俗的例子:
尝试用高中概率知识去理解一下 Veterbi 算法。内容绝对粗浅,100% 抄袭,欢迎指正。用一个别人家的栗子来说一下。
1.题目背景:
从前有个村儿,村里的人的身体情况只有两种可能:健康或者发烧。
假设这个村儿的人没有体温计或者百度这种神奇东西,他唯一判断他身体情况的途径就是到村头我的偶像金正月的小诊所询问。
月儿通过询问村民的感觉,判断她的病情,再假设村民只会回答正常、头晕或冷。
有一天村里奥巴驴就去月儿那去询问了。
第一天她告诉月儿她感觉正常。
第二天她告诉月儿感觉有点冷。
第三天她告诉月儿感觉有点头晕。
那么问题来了,月儿如何根据阿驴的描述的情况,推断出这三天中阿驴的一个身体状态呢?
为此月儿上百度搜 google ,一番狂搜,发现维特比算法正好能解决这个问题。月儿乐了。
2.已知情况:
隐含的身体状态 = { 健康 , 发烧 }
可观察的感觉状态 = { 正常 , 冷 , 头晕 }
月儿预判的阿驴身体状态的概率分布 = { 健康:0.6 , 发烧: 0.4 }
月儿认为的阿驴身体健康状态的转换概率分布 = {
健康->健康: 0.7 ,
健康->发烧: 0.3 ,
发烧->健康:0.4 ,
发烧->发烧: 0.6
}
月儿认为的在相应健康状况条件下,阿驴的感觉的概率分布 = {
健康,正常:0.5 ,冷 :0.4 ,头晕: 0.1 ;
发烧,正常:0.1 ,冷 :0.3 ,头晕: 0.6
}
阿驴连续三天的身体感觉依次是: 正常、冷、头晕 。
3.题目:
已知如上,求:阿驴这三天的身体健康状态变化的过程是怎么样的?
4.过程:
根据 Viterbi 理论,后一天的状态会依赖前一天的状态和当前的可观察的状态。那么只要根据第一天的正常状态依次推算找出到达第三天头晕状态的最大的概率,就可以知道这三天的身体变化情况。
传不了图片,悲剧了。。。
1.初始情况:
- P(健康) = 0.6,P(发烧)=0.4。
2.求第一天的身体情况:
计算在阿驴感觉正常的情况下最可能的身体状态。
- P(今天健康) = P(正常|健康)*P(健康|初始情况) = 0.5 * 0.6 = 0.3
- P(今天发烧) = P(正常|发烧)*P(发烧|初始情况) = 0.1 * 0.4 = 0.04
那么就可以认为第一天最可能的身体状态是:健康。
3.求第二天的身体状况:
计算在阿驴感觉冷的情况下最可能的身体状态。
那么第二天有四种情况,由于第一天的发烧或者健康转换到第二天的发烧或者健康。
- P(前一天发烧,今天发烧) = P(前一天发烧)*P(发烧->发烧)*P(冷|发烧) = 0.04 * 0.6 * 0.3 = 0.0072
- P(前一天发烧,今天健康) = P(前一天发烧)*P(发烧->健康)*P(冷|健康) = 0.04 * 0.4 * 0.4 = 0.0064
- P(前一天健康,今天健康) = P(前一天健康)*P(健康->健康)*P(冷|健康) = 0.3 * 0.7 * 0.4 = 0.084
- P(前一天健康,今天发烧) = P(前一天健康)*P(健康->发烧)*P(冷|发烧) = 0.3 * 0.3 *.03 = 0.027
那么可以认为,第二天最可能的状态是:健康。
4.求第三天的身体状态:
计算在阿驴感觉头晕的情况下最可能的身体状态。
- P(前一天发烧,今天发烧) = P(前一天发烧)*P(发烧->发烧)*P(头晕|发烧) = 0.027 * 0.6 * 0.6 = 0.00972
- P(前一天发烧,今天健康) = P(前一天发烧)*P(发烧->健康)*P(头晕|健康) = 0.027 * 0.4 * 0.1 = 0.00108
- P(前一天健康,今天健康) = P(前一天健康)*P(健康->健康)*P(头晕|健康) = 0.084 * 0.7 * 0.1 = 0.00588
- P(前一天健康,今天发烧) = P(前一天健康)*P(健康->发烧)*P(头晕|发烧) = 0.084 * 0.3 *0.6 = 0.01512
那么可以认为:第三天最可能的状态是发烧。
5.结论
根据如上计算。这样月儿断定,阿驴这三天身体变化的序列是:健康->健康->发烧。
维基百科的这个例子的动态图:File:Viterbi animated demo.gif
这个算法大概就是通过已知的可以观察到的序列,和一些已知的状态转换之间的概率情况,通过综合状态之间的转移概率和前一个状态的情况计算出概率最大的状态转换路径,从而推断出隐含状态的序列的情况。
【python编程实现】
def viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}]
for st in states:
V[0][st] = {"prob": start_p[st] * emit_p[st][obs[0]], "prev": None}
for t in range(1, len(obs)):
V.append({})
for st in states:
max_tr_prob = max(V[t-1][prev_st]["prob"]*trans_p[prev_st][st] for prev_st in states)
for prev_st in states:
if V[t-1][prev_st]["prob"] * trans_p[prev_st][st] == max_tr_prob:
max_prob = max_tr_prob * emit_p[st][obs[t]]
V[t][st] = {"prob": max_prob, "prev": prev_st}
break
opt = []
max_prob = max(value["prob"] for value in V[-1].values())
previous = None
for st, data in V[-1].items():
if data["prob"] == max_prob:
opt.append(st)
previous = st
break
for t in range(len(V) - 2, -1, -1):
opt.insert(0, V[t + 1][previous]["prev"])
previous = V[t + 1][previous]["prev"]
return opt
states = ('健康', '发烧')
observations = ('正常', '冷', '头晕')
start_probability = {'健康': 0.6, '发烧': 0.4}
transition_probability = {
'健康' : {'健康': 0.7, '发烧': 0.3},
'发烧' : {'健康': 0.4, '发烧': 0.6},
}
emission_probability = {
'健康' : {'正常': 0.5, '冷': 0.4, '头晕': 0.1},
'发烧' : {'正常': 0.1, '冷': 0.3, '头晕': 0.6},
}
print(viterbi(observations, states, start_probability, transition_probability, emission_probability))
输出:
['健康', '健康', '发烧']
就是一个dp算法+回溯求path的,不再赘述了!