
【EM算法简介】
EM算法,全称为期望最大化算法(Expectation-Maximization Algorithm),是一种迭代优化算法,主要用于含有隐变量的概率模型参数的估计。EM算法的基本思想是:如果给定模型的参数,那么可以根据模型计算出隐变量的期望值;反过来,如果给定隐变量的值,那么可以通过最大化似然函数来估计模型的参数。EM算法就是通过交替进行这两步来找到参数的最大似然估计。
EM算法的基本步骤如下:
1. 初始化模型参数
2. E步:计算隐变量的期望值
3. M步:最大化似然函数,更新模型参数
4. 重复步骤2和3,直到模型参数收敛
【EM算法举例】
K-means算法可以被看作是一种特殊的EM算法。在K-means算法中,我们试图找到一种方式将数据点分配到K个集群中,使得每个数据点到其所在集群中心的距离之和最小。
如果我们将集群分配看作是隐变量,那么K-means算法就可以看作是EM算法:
1. E步:期望步骤。给定当前的集群中心(模型参数),我们可以计算每个数据点最近的集群中心,也就是将每个数据点分配到一个集群中。这个步骤就是计算隐变量的期望值。
2. M步:最大化步骤。给定当前的集群分配(隐变量的值),我们可以计算新的集群中心,也就是每个集群中所有数据点的均值。这个步骤就是最大化似然函数,更新模型参数。
通过交替进行E步和M步,K-means算法可以找到一种集群分配和集群中心,使得每个数据点到其所在集群中心的距离之和最小。这就是K-means算法使用EM算法的地方。
【再举一个例子】
见:https://zhuanlan.zhihu.com/p/78311644 写得非常好,关键摘录如下:
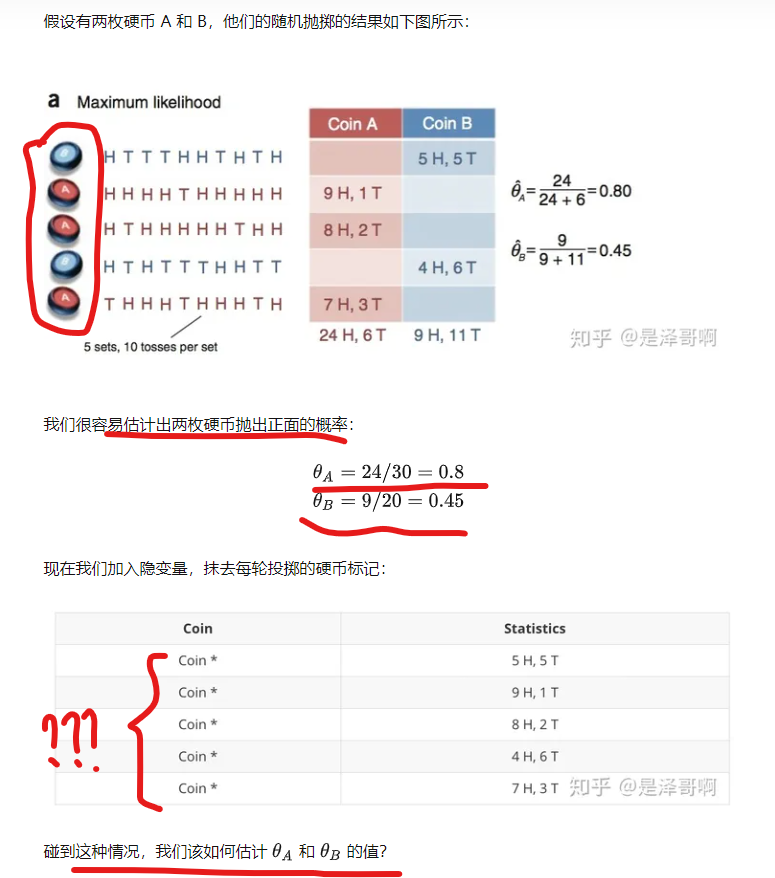
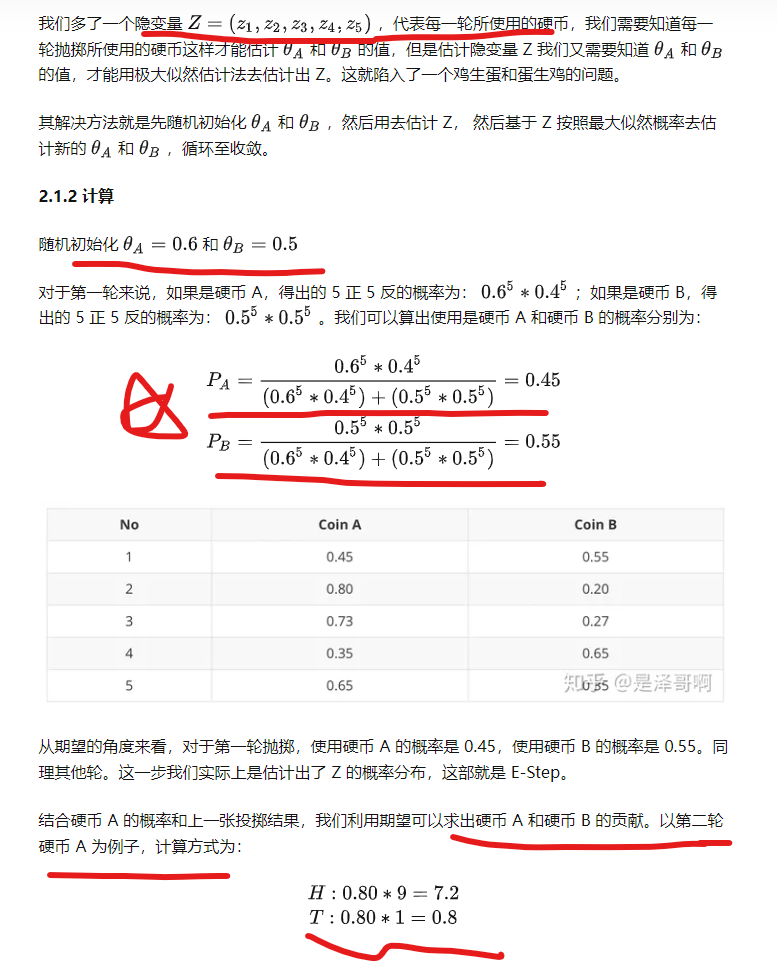
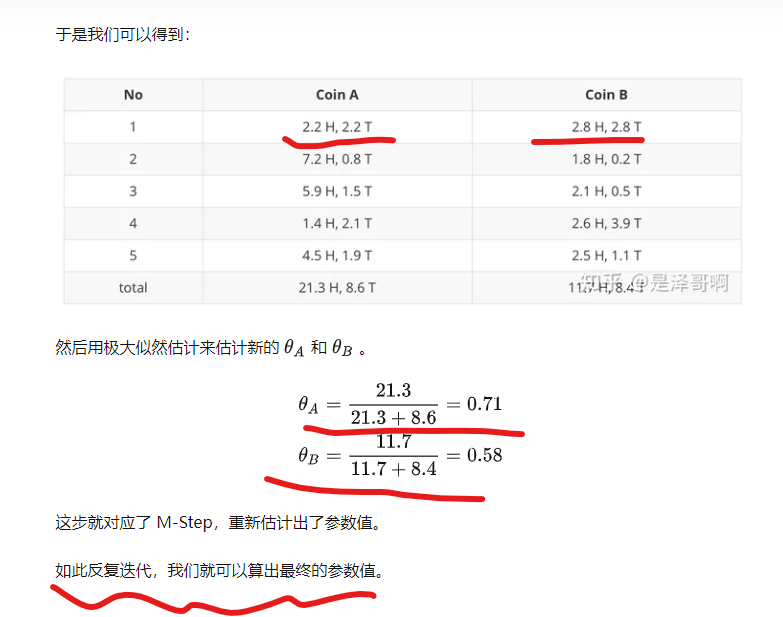
【python编程实现】
import math
import random
def coin_em(rolls, theta_A=None, theta_B=None, maxiter=10000, tol=1e-6):
# 初始化参数
theta_A = theta_A or random.random()
theta_B = theta_B or random.random()
loglike_old = 0
for i in range(maxiter):
# E步
heads_A, tails_A, heads_B, tails_B = e_step(rolls, theta_A, theta_B)
# M步
theta_A, theta_B = m_step(heads_A, tails_A, heads_B, tails_B)
# 计算对数似然
loglike_new = loglikelihood(rolls, theta_A, theta_B)
# 检查收敛
if abs(loglike_new - loglike_old) < tol:
break
else:
loglike_old = loglike_new
return theta_A, theta_B
def e_step(rolls, theta_A, theta_B):
heads_A, tails_A, heads_B, tails_B = 0, 0, 0, 0
for trial in rolls:
likelihood_A = likelihood(trial, theta_A)
likelihood_B = likelihood(trial, theta_B)
p_A = likelihood_A / (likelihood_A + likelihood_B)
p_B = 1 - p_A
heads_A += p_A * trial.count("H")
tails_A += p_A * trial.count("T")
heads_B += p_B * trial.count("H")
tails_B += p_B * trial.count("T")
return heads_A, tails_A, heads_B, tails_B
def m_step(heads_A, tails_A, heads_B, tails_B):
theta_A = heads_A / (heads_A + tails_A)
theta_B = heads_B / (heads_B + tails_B)
return theta_A, theta_B
def likelihood(roll, theta):
numHeads = roll.count("H")
flips = len(roll)
return (theta**numHeads) * ((1-theta)**(flips-numHeads))
def loglikelihood(rolls, theta_A, theta_B):
total = 0
for roll in rolls:
heads = roll.count("H")
tails = roll.count("T")
total += math.log(0.5 * likelihood(roll, theta_A) + 0.5 * likelihood(roll, theta_B))
return total
# 测试
rolls = ["HTTTHHTHTH", "HHHHTHHHHH", "HTHHHHHTHH", "HTHTTTHHTT", "THHHTHHHTH"]
print(coin_em(rolls))
输出:
(0.7967659656145668, 0.5195829299707858)
和原始答案比较接近。