
基于系统聚类模型的信誉评估研究
摘要
本研究旨在分析个案信誉评估数据并进行相关统计检验和建模。所提供的数据包括银行欠款、其他欠款、收入和信誉值等变量。以下是对每个问题的回答:
对于问题一,对银行欠款均值的95%置信区间和假设检验,进行单样本非参数检验,计算银行欠款均值的95%置信区间,检验银行欠款均值是否为1。得出置信区间为0.00到0.00,均值为1.2548,银行欠款均值不为1,p值为0.00,p<0.05,所以拒绝原假设,银行欠款服不从正态分布。
对于问题二,检验其他欠款是否服从正态分布,进行单样本非参数检验,得出银行欠款的95%置信区间为0.00到0.00,均值为2.8748,p值为0.00,p<0.05,所以拒绝原假设,其他欠款服不从正态分布。
对于问题三,检验不同信誉的个案银行欠款均值是否有显著性差异,运用两独立样本t检验,得出不同信誉的个案的银行欠款均值之间没有显著性差异(t(60) = 0.578, p = 0.560)。这意味着良好信誉个案与不好信誉个案在银行欠款方面的平均值没有显著差异。
对于问题四,为了不同教育水平下的收入是否有显著性差异,运用方差分析,得出教育水平对收入产生了显著影响(F(3, 58) = 3.002, p = .038)。这意味着不同教育水平的人群的平均收入有所差异。接着两两比较,得出初中毕业生和大专毕业生的收入差异不显著,而他们与研究生之间的收入差异是显著的。同时,高中毕业生的收入也显著低于研究生。
对于问题五,基于给定得数据,建立适当的系统聚类模型,通过主成分分析,进行数据降维,再计算综合因子得分,利用综合因子得分对原始的信誉数据进行预测。得到个案601-615预测结果,除了610这个个案预测为信誉不好,其他均为信誉良好。通过比较原始信誉数据和预测数据发现,有435个个案信誉预测准确,计算得出预测准确率为72.5%。模型准确性较高。
关键词:系统聚类模型 主成分分析 单样本非参数检验 两独立样本t检验 方差分析
一、问题重述
1.1 问题的提出
1. 设银行欠款服从正态分布,求银行欠款均值的95%置信区间,并检验均值是否为1。
2. 检验其它欠款是否服从正态分布。
3. 设银行欠款服从正态分布,不同信誉的个案的银行欠款均值是否有显著性差异。
4. 假设收入服从正态分布,不同教育水平下的收入是否有显著性差异,并进行两两比较。
5. 建立适当模型预测个案601-615的信誉值。
二、问题分析
对问题1的分析:本问题要求计算银行欠款的均值的95%置信区间,即通过样本数据来估计整体银行欠款的均值,并判断均值是否等于1。针对这个问题,我们可以使用抽样方法得到一定数量的样本数据,并进行统计分析和假设检验。
对问题2的分析:本问题要求检验其他欠款变量是否服从正态分布。为了解决这个问题,可以使用统计方法进行正态性检验,例如Shapiro-Wilk检验或Kolmogorov-Smirnov检验。这些检验将帮助我们确定其他欠款数据是否符合正态分布假设。
对问题3的分析:本问题需要比较不同信誉的个案的银行欠款均值是否存在显著性差异。为了解决这个问题,可以使用两独立样本t检验,该检验能够比较两组样本均值之间的差异是否显著。
对问题4的分析:本问题需要检验不同教育水平下收入的均值是否存在显著性差异,并进行两两比较。为了解决这个问题,可以使用方差分析(ANOVA)来比较组间差异的显著性,以及进行事后多重比较来确定哪些组之间存在显著差异。
对问题5的分析:本问题需要建立一个适当的模型来预测个案601-615的信誉值。根据给定的数据,可以考虑使用聚类模型,例如系统聚类或层次聚类等。通过对已有样本数据进行聚类建模,然后利用模型对新个案的信誉值进行预测。
三、模型建立及求解
3.1数据处理
学号为2513210112 n=12。选取个案:
个案进行筛选之后,筛选数据如下图:
3.2问题一模型建立及求解
设银行欠款服从正态分布,求银行欠款均值的95%置信区间,并检验均值是否为1。
我将进行单样本非参数检验,设置显著性水平为0.05,置信区间为95%。并且只对银行欠款字段进行单样本非参数检验。
3.2.1参数设置
如下为字段选择和检验参数图:
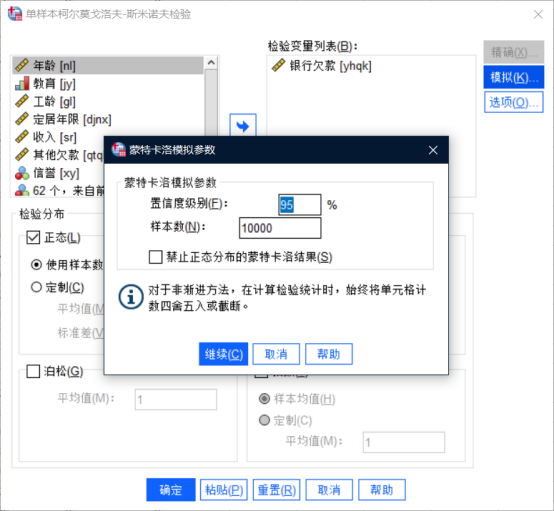
图3字段选择和检验参数图
3.2.2单样本非参数检验分析结果
表1单样本柯尔莫戈洛夫-斯米诺夫检验
单样本柯尔莫戈洛夫-斯米诺夫检验 |
|||
银行欠款 |
|||
N |
62 |
||
正态参数a,b |
平均值 |
1.2548 |
|
标准差 |
1.59786 |
||
最极端差值 |
绝对 |
.222 |
|
正 |
.202 |
||
负 |
-.222 |
||
检验统计 |
.222 |
||
渐近显著性(双尾)c |
.000 |
||
蒙特卡洛显著性(双尾)d |
显著性 |
.000 |
|
95% 置信区间 |
下限 |
.000 |
|
上限 |
.000 |
||
a. 检验分布为正态分布。 |
|||
b. 根据数据计算。 |
|||
c. 里利氏显著性修正。 |
|||
d. 基于 10000 蒙特卡洛样本且起始种子为 12620969 的里利氏法。 |
|||
3.3问题二模型建立及求解
检验其它欠款是否服从正态分布,给出检验的p值和结论。
我将进行单样本非参数检验,设置显著性水平为0.05,置信区间为95%。并且只对其他欠款字段进行单样本非参数检验。
3.3.1参数设置
如下为其他欠款参数设置图:
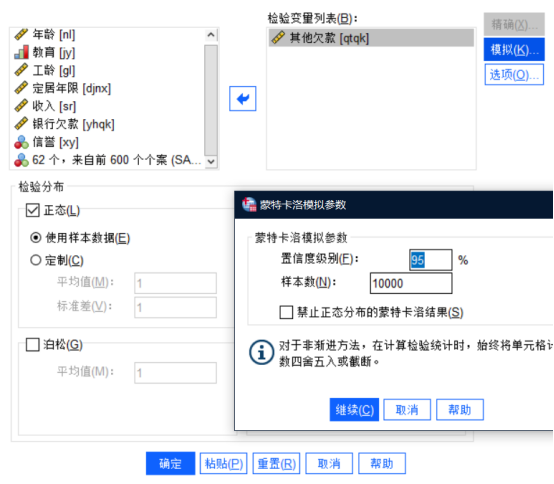
图4其他欠款参数设置图
3.3.2单样本非参数检验分析结果
表2单样本柯尔莫戈洛夫-斯米诺夫检验
单样本柯尔莫戈洛夫-斯米诺夫检验 |
|||
其他欠款 |
|||
N |
62 |
||
正态参数a,b |
平均值 |
2.8748 |
|
标准差 |
2.41666 |
||
最极端差值 |
绝对 |
.179 |
|
正 |
.179 |
||
负 |
-.121 |
||
检验统计 |
.179 |
||
渐近显著性(双尾)c |
.000 |
||
蒙特卡洛显著性(双尾)d |
显著性 |
.000 |
|
95% 置信区间 |
下限 |
.000 |
|
上限 |
.000 |
||
a. 检验分布为正态分布。 |
|||
b. 根据数据计算。 |
|||
c. 里利氏显著性修正。 |
|||
d. 基于 10000 蒙特卡洛样本且起始种子为 1846588404 的里利氏法。 |
|||
3.4问题三模型建立及求解
设银行欠款服从正态分布,不同信誉的个案的银行欠款均值是否有显著性差异。
3.4.1参数设置
如下是独立样本t检验参数设置图:
图5独立样本t检验参数设置图
3.4.2独立样本t检验分析结果
表3组统计
组统计 |
|||||
信誉 |
个案数 |
平均值 |
标准差 |
标准误差平均值 |
|
银行欠款 |
良好 |
50 |
1.3125 |
1.59145 |
.22506 |
不好 |
12 |
1.0142 |
1.67276 |
.48288 |
|
表4独立样本检验
独立样本检验 |
||||||||||
莱文方差等同性检验 |
平均值等同性 t 检验 |
|||||||||
F |
显著性 |
t |
自由度 |
显著性 (双尾) |
平均值差值 |
标准误差差值 |
差值 95% 置信区间 |
|||
下限 |
上限 |
|||||||||
银行欠款 |
假定等方差 |
.000 |
.985 |
.578 |
60 |
.566 |
.29833 |
.51647 |
-.73477 |
1.33142 |
不假定等方差 |
.560 |
16.127 |
.583 |
.29833 |
.53276 |
-.83035 |
1.42700 |
|||
表5独立样本效应大小
独立样本效应大小 |
|||||
标准化量a |
点估算 |
95% 置信区间 |
|||
下限 |
上限 |
||||
银行欠款 |
Cohen d |
1.60666 |
.186 |
-.446 |
.816 |
Hedges 修正 |
1.62710 |
.183 |
-.440 |
.806 |
|
Glass Delta |
1.67276 |
.178 |
-.460 |
.809 |
|
a. 估算效应大小时使用的分母。 Cohen d 使用汇聚标准差。 Hedges 修正使用汇聚标准差,加上修正因子。 Glass Delta 使用控制组的样本标准差。 |
|||||
3.5问题四模型建立及求解
假设收入服从正态分布,不同教育水平下的收入是否有显著性差异,并进行两两比较,运用方差分析。
3.5.1 参数设置
如下是方差分析选项设置图:
图6方差分析选项设置图
如下是方差分析事后对比设置图:
图7方差分析事后对比设置图
3.5.2方差分析结果
表6描述
描述 |
||||||||
收入 |
||||||||
N |
平均值 |
标准差 |
标准误差 |
平均值的 95% 置信区间 |
最小值 |
最大值 |
||
下限 |
上限 |
|||||||
初中 |
37 |
50.22 |
54.336 |
8.933 |
32.10 |
68.33 |
16 |
253 |
高中 |
17 |
49.76 |
30.583 |
7.417 |
34.04 |
65.49 |
15 |
120 |
大专 |
6 |
62.83 |
40.365 |
16.479 |
20.47 |
105.19 |
26 |
135 |
研究生 |
2 |
151.50 |
36.062 |
25.500 |
-172.51 |
475.51 |
126 |
177 |
总计 |
62 |
54.58 |
49.753 |
6.319 |
41.95 |
67.22 |
15 |
253 |
表7方差齐性检验
方差齐性检验 |
|||||
莱文统计 |
自由度 |
自由度 |
显著性 |
||
收入 |
基于平均值 |
.517 |
3 |
58 |
.672 |
基于中位数 |
.102 |
3 |
58 |
.958 |
|
基于中位数并具有调整后自由度 |
.102 |
3 |
44.783 |
.958 |
|
基于剪除后平均值 |
.184 |
3 |
58 |
.907 |
|
表8ANOVA
ANOVA |
|||||
收入 |
|||||
平方和 |
自由度 |
均方 |
F |
显著性 |
|
组间 |
20294.434 |
3 |
6764.811 |
3.002 |
.038 |
组内 |
130700.662 |
58 |
2253.460 |
||
总计 |
150995.097 |
61 |
|||
表9多重比较
多重比较 |
||||||
因变量: 收入 |
||||||
LSD |
||||||
(I) 教育 |
(J) 教育 |
平均值差值 |
标准误差 |
显著性 |
95% 置信区间 |
|
下限 |
上限 |
|||||
初中 |
高中 |
.452 |
13.909 |
.974 |
-27.39 |
28.29 |
大专 |
-12.617 |
20.892 |
.548 |
-54.44 |
29.20 |
|
研究生 |
-101.284* |
34.462 |
.005 |
-170.27 |
-32.30 |
|
高中 |
初中 |
-.452 |
13.909 |
.974 |
-28.29 |
27.39 |
大专 |
-13.069 |
22.542 |
.564 |
-58.19 |
32.05 |
|
研究生 |
-101.735* |
35.486 |
.006 |
-172.77 |
-30.70 |
|
大专 |
初中 |
12.617 |
20.892 |
.548 |
-29.20 |
54.44 |
高中 |
13.069 |
22.542 |
.564 |
-32.05 |
58.19 |
|
研究生 |
-88.667* |
38.760 |
.026 |
-166.25 |
-11.08 |
|
研究生 |
初中 |
101.284* |
34.462 |
.005 |
32.30 |
170.27 |
高中 |
101.735* |
35.486 |
.006 |
30.70 |
172.77 |
|
大专 |
88.667* |
38.760 |
.026 |
11.08 |
166.25 |
|
*. 平均值差值的显著性水平为 0.05。 |
||||||
3.6问题五模型建立及求解
建立适当模型预测个案601-615的信誉值,给出模型、准确率和预测结果。
对于第五问:建立系统聚类模型,先进行因子分析的主成分分析,对多个特征进行降维成因子变量。再用降维后的因子变量,根据变量之间的系数,计算综合因子得分,再来进行系统聚类分类,来预测个案601-615的信誉值,得到结果。
3.6.1 参数设置
如下是主成分分析如图:
图8主成分分析描述设置图
图9主成分分析提取设置图
3.6.2主成分分析结果
表10相关性矩阵
相关性矩阵 |
||||||||
年龄 |
教育 |
工龄 |
定居年限 |
收入 |
银行欠款 |
其他欠款 |
||
相关性 |
年龄 |
1.000 |
.026 |
.542 |
.594 |
.480 |
.315 |
.351 |
教育 |
.026 |
1.000 |
-.125 |
.058 |
.253 |
.071 |
.163 |
|
工龄 |
.542 |
-.125 |
1.000 |
.310 |
.627 |
.430 |
.430 |
|
定居年限 |
.594 |
.058 |
.310 |
1.000 |
.303 |
.204 |
.200 |
|
收入 |
.480 |
.253 |
.627 |
.303 |
1.000 |
.571 |
.622 |
|
银行欠款 |
.315 |
.071 |
.430 |
.204 |
.571 |
1.000 |
.662 |
|
其他欠款 |
.351 |
.163 |
.430 |
.200 |
.622 |
.662 |
1.000 |
|
显著性 (单尾) |
年龄 |
.262 |
.000 |
.000 |
.000 |
.000 |
.000 |
|
教育 |
.262 |
.001 |
.074 |
.000 |
.039 |
.000 |
||
工龄 |
.000 |
.001 |
.000 |
.000 |
.000 |
.000 |
||
定居年限 |
.000 |
.074 |
.000 |
.000 |
.000 |
.000 |
||
收入 |
.000 |
.000 |
.000 |
.000 |
.000 |
.000 |
||
银行欠款 |
.000 |
.039 |
.000 |
.000 |
.000 |
.000 |
||
其他欠款 |
.000 |
.000 |
.000 |
.000 |
.000 |
.000 |
||
表11公因子方差
公因子方差 |
||
初始 |
提取 |
|
年龄 |
1.000 |
.791 |
教育 |
1.000 |
.946 |
工龄 |
1.000 |
.711 |
定居年限 |
1.000 |
.798 |
收入 |
1.000 |
.766 |
银行欠款 |
1.000 |
.723 |
其他欠款 |
1.000 |
.757 |
提取方法:主成分分析法。 |
||
表12总方差解释
总方差解释 |
||||||
成分 |
初始特征值 |
提取载荷平方和 |
||||
总计 |
方差百分比 |
累积 |
总计 |
方差百分比 |
累积 |
|
1 |
3.267 |
46.665 |
46.665 |
3.267 |
46.665 |
46.665 |
2 |
1.202 |
17.164 |
63.829 |
1.202 |
17.164 |
63.829 |
3 |
1.025 |
14.643 |
78.472 |
1.025 |
14.643 |
78.472 |
4 |
.588 |
8.396 |
86.868 |
|||
5 |
.353 |
5.037 |
91.904 |
|||
6 |
.320 |
4.578 |
96.483 |
|||
7 |
.246 |
3.517 |
100.000 |
|||
提取方法:主成分分析法。 |
||||||
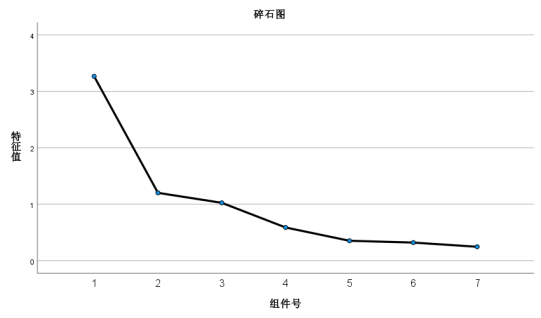
图10碎石图
表13成分矩阵
成分矩阵a |
|||
成分 |
|||
1 |
2 |
3 |
|
年龄 |
.726 |
-.446 |
.254 |
教育 |
.153 |
.632 |
.724 |
工龄 |
.759 |
-.250 |
-.271 |
定居年限 |
.545 |
-.509 |
.492 |
收入 |
.848 |
.215 |
.001 |
银行欠款 |
.735 |
.310 |
-.294 |
其他欠款 |
.763 |
.373 |
-.187 |
提取方法:主成分分析法。 |
|||
a. 提取了 3 个成分。 |
|||
3.6.3 计算综合因子得分
计算综合因子得分,点击计算变量。
计算公式为:
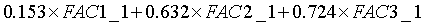
得到综合因子得分,如图所示:
图11综合因子得分展示图
3.6.4 系统聚类模型建立和求解
系统聚类,将得到得综合因子得分变量带入变量框中,将个案标注依据,选择为信誉。
系统聚类分析参数设置如图:
图12系统聚类分析参数设置
图13系统聚类分析方法设置
使用质心聚类和切比雪夫测量,设定聚类数为2。
系统聚类分析结果见附录(一)
个案601-615预测结果如图:
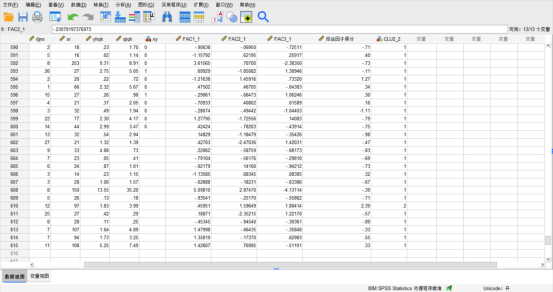
图14个案601-615预测结果
四、模型分析结论
对于问题一,银行欠款的95%置信区间为0.00到0.00,均值为1.2548,p值为0.00,p<0.05,所以拒绝原假设,银行欠款服不从正态分布。
对于问题二,银行欠款的95%置信区间为0.00到0.00,均值为2.8748,p值为0.00,p<0.05,所以拒绝原假设,其他欠款服不从正态分布。
对于问题三,显著性为0.985 ,sig>0.05 那么只考虑方差相等的情况,方差相等:双边检验p= 0.566, p>0.05 所以接受原假设,不同信誉的个案的银行欠款均值之间没有显著性差异。这意味着信誉对于个案的银行欠款金额没有明显影响。
对于问题四,根据统计分析结果,p<0.038,p<0.05,接受原假设不同教育水平下的收入存在显著差异。初中毕业生和大专毕业生的收入差异不显著,而他们与研究生之间的收入差异是显著的。同时,高中毕业生的收入也显著低于研究生。这些结果有助于我们理解教育水平与收入之间的关系。
对于问题五,主成分分析结论:通过总方差解释表和碎石图可知,选取3个变量累积占比为78.472%,当选取变量大于3个时,累积占比变化不大。最适宜选取三个降维后的变量。那么对于信誉的综合因子得分系数由公因子方差教育为主要因子来源,再从成分矩阵里面可知选取对教育的成分系数为0.153,0.632,0.724,作为综合因子得分系数。系统聚类模型分析结论:个案601-615预测结果,除了610这个个案预测为信誉不好,其他均为信誉良好。通过比较原始信誉数据和预测数据发现,有435个个案信誉预测准确,计算得出预测准确率为72.5%。