
求解MDP最优策略——动态规划
学习「强化学习」(基于这本教材,强动态规划烈推荐)时的一些总结,在此记录一下。动态规划
在马尔可夫决策过程环境模型已知(也就是状态转移函数P、奖励函数r已知)的情况下,我们可以通过 「动态规划」 求得马尔可夫决策过程的最优策略 \(\pi^*\) 。
1. 动态规划
对于做过算法题目的同学而言,这个词应该并不陌生,比较经典的「背包问题」就是需要利用「动态规划」。动态规划的思想是:将当前问题分解为子问题,求解并记录子问题的答案,最后从中获得目标解。它通常用于求解「最优」性质的问题。
而求解马尔可夫决策过程最优策略的动态规划算法主要有两种:
- 策略迭代
- 价值迭代
2. 策略迭代
「策略迭代」 分为「策略评估」和「策略提升」两部分。
策略评估
策略评估会先设定一个初始状态价值函数 \(V^0\),再通过「动态规划」不断更新策略的状态价值函数 \(V^{k+1} \leftarrow V^k\),当最大的「 \(V^{k+1}(s)\) 与上次的 \(V^k(s)\) 的差距」非常小( \(<\theta\))时,就结束迭代。
策略评估的迭代公式可以看作是「贝尔曼期望方程」+「动态规划」。我们可以看看两者的不同:

光说这些还是不容易理解的,我们用实例演示一遍吧。同样以教材中的「悬崖环境」为例:

假设现在有这么一个 \(5 \times 4\) 区域的悬崖,我们的目标是要找出从起点到终点的最优策略。我们把每个格子都当成一个状态,也就是说,只要智能体移动了一个格子,就转换了一次状态;并且智能体只能「上下左右」地走(如果将走出范围,就当作原地踏步,即「走到自身格子」),每走一步都是一个动作且往不同方向走的概率是相同的。走到悬崖的奖励我们设为-100,走到正常位置的奖励设为-1,走到终点就直接结束(相当于奖励是0),那么我们可以整理出奖励函数 \(r(s, a)\):

-
可能会有的疑惑:\(r(s, a)\) 不是 由状态与动作一起决定 的吗,这里怎么把 \(r(s, a)\) 直接放在状态上了?
答:这其实是种简化的表达方式,我们应该这么看:这里的 \(r(s, a)\) 指 从其它状态(格子)以任意方向走到当前状态(格子)的 \(r(s, a)\),只不过因为它们都相同(因为设置的这个环境比较特殊),所以写在了一起。比如下面这个红色小旗所在格子位置上的 \(r(s, a)\) 其实是它周围格子走到该格子的 \(r(s, a)\):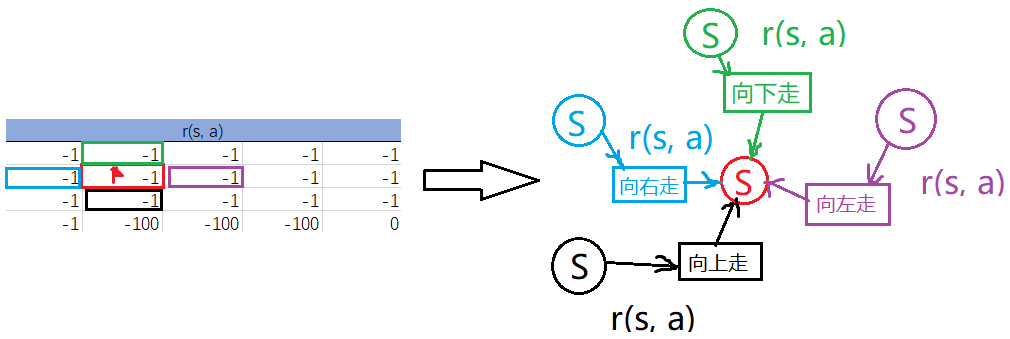

- 我们先让初始 \(V^0\) 全为0,判定迭代结束的小阈值 \(\theta = 0.01\),为了方便,让折扣因子 \(\gamma = 1\),而且由于走一步仅能到达一个状态,所以让所有的状态转移概率都为1 :

-
根据迭代公式,开始迭代 \(V^1\),先以起点的 \(V\) 开始:
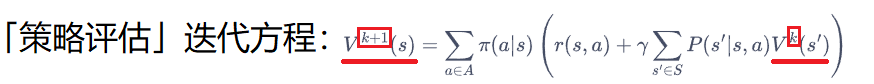 \[ \begin{aligned} V^1(起) &= \frac{1}{4} \times ((-1) + 1 \times 1 \times(V^0(起上))) + \frac{1}{4} \times ((-1) + 1 \times 1 \times(V^0(起下))) \\ &+ \frac{1}{4} \times ((-1) + 1 \times 1 \times(V^0(起左))) + \frac{1}{4} \times ((-100) + 1 \times 1 \times(V^0(起右))) \\ &= \frac{1}{4} \times ((-1) + 1 \times 1 \times(0)) + \frac{1}{4} \times ((-1) + 1 \times 1 \times(0)) \\ &+ \frac{1}{4} \times ((-1) + 1 \times 1 \times(0)) + \frac{1}{4} \times ((-100) + 1 \times 1 \times(0)) \\ & = -25.75\\ \end{aligned} \]
\[ \begin{aligned} V^1(起) &= \frac{1}{4} \times ((-1) + 1 \times 1 \times(V^0(起上))) + \frac{1}{4} \times ((-1) + 1 \times 1 \times(V^0(起下))) \\ &+ \frac{1}{4} \times ((-1) + 1 \times 1 \times(V^0(起左))) + \frac{1}{4} \times ((-100) + 1 \times 1 \times(V^0(起右))) \\ &= \frac{1}{4} \times ((-1) + 1 \times 1 \times(0)) + \frac{1}{4} \times ((-1) + 1 \times 1 \times(0)) \\ &+ \frac{1}{4} \times ((-1) + 1 \times 1 \times(0)) + \frac{1}{4} \times ((-100) + 1 \times 1 \times(0)) \\ & = -25.75\\ \end{aligned} \]每个状态(格子)都计算完后,就得到了完整的新的 \(V^1\):

-
然后进行评估,发现 \(max\{|V^1(s) - V^0(s)|\} = 25.75 > \theta\),还得继续迭代
-
重复与2相同的步骤,根据 \(V^1\) 求出 \(V^2\),又可以得到:

-
……
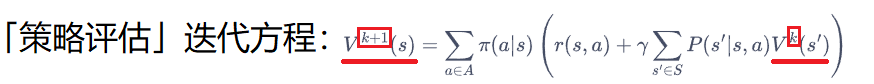



总之,在经过多轮的重复迭代后,我们取得了收敛的 \(V\),这时就进入到了 「策略提升」 环节。
策略提升
接下来就是调整策略 \(\pi\) 了,我们可以直接贪心地在每一个状态选择动作价值最大的动作,也就是:

根据这个调整方式,来看看最终策略提升得到的新的 \(\pi^1\):

然而,这还没有结束,如果不满足 \(\pi^{k-1} = \pi^k\),那么还需要继续进行策略迭代。如果满足了,那么此时的 \(\pi^k\) 就是最优策略、 \(V^k\) 就是最优价值。在这里显然 $ \pi^0 \neq \pi^1$,所以要继续。
总结
最后,综合「策略评估」和「策略提升」,得到策略迭代算法(教材中的):

3. 价值迭代
「策略迭代算法」似乎计算量大了些,既要进行不断迭代 \(V\) ,还要迭代 \(\pi\),有计算量比较小的算法吗? 「价值迭代算法」 可能可以满足你的需求,它虽说也要进行 \(V\) 迭代,但却只用一轮,而后就直接「盖棺定论」将更改后得到的 \(\pi\) 作为「最优策略」了。
它可以看作是:「贝尔曼最优方程」+ 「动态规划」。

可以直接来对比下「策略迭代」与「价值迭代」:

红色框表示的是「\(V\)迭代」,在这部分不同的是,「价值迭代」直接选取最大状态价值而不是「策略迭代」的期望状态价值;蓝色框表示的是「\(\pi\)迭代」,「价值迭代」没有对「策略」进一步进行迭代 (所以才叫「价值迭代」嘛
虽然很简单,但同样我们也来实操一遍「价值迭代」,同样用到刚刚的「悬崖」环境:
-
初始化就不提了,直接根据迭代公式,开始迭代 \(V^1\),先以起点的 \(V\) 开始:
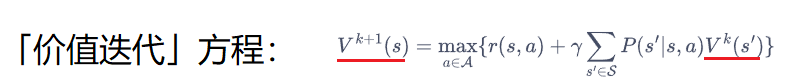 \[ \begin{aligned} V^1(起) &= max\{((-1) + 1 \times 1 \times(V^0(起上))),((-1) + 1 \times 1 \times(V^0(起下))), \\ & ((-1) + 1 \times 1 \times(V^0(起左))),((-100) + 1 \times 1 \times(V^0(起右)))\}\\ &= max\{((-1) + 1 \times 1 \times(0)),((-1) + 1 \times 1 \times(0)), \\ & ((-1) + 1 \times 1 \times(0)),((-100) + 1 \times 1 \times(0))\} \\ & = max\{-1, -1, -1, -100\}\\ & = -1\\ \end{aligned} \]
\[ \begin{aligned} V^1(起) &= max\{((-1) + 1 \times 1 \times(V^0(起上))),((-1) + 1 \times 1 \times(V^0(起下))), \\ & ((-1) + 1 \times 1 \times(V^0(起左))),((-100) + 1 \times 1 \times(V^0(起右)))\}\\ &= max\{((-1) + 1 \times 1 \times(0)),((-1) + 1 \times 1 \times(0)), \\ & ((-1) + 1 \times 1 \times(0)),((-100) + 1 \times 1 \times(0))\} \\ & = max\{-1, -1, -1, -100\}\\ & = -1\\ \end{aligned} \]每个状态(格子)都计算完后,就得到了完整的新的 \(V^1\):

-
同样评估一下是否 \(max\{|V^1(s) - V^0(s)|\} > \theta\) ,如有则继续迭代。这里经过7次迭代就达到判定阈值了:

-
最后同样选取最大动作价值,来更新策略即可。如果动作中有多个「最大动作价值」的动作,则给予等概率。

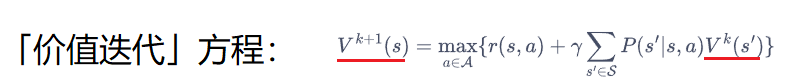



4. 总结
策略迭代在理论上能更好地收敛到最优策略,但有着比较大的计算量;价值迭代可以通过较少的计算就收敛,但不像策略迭代那样有严格的收敛性保证(可以看看这个数学证明)。只能说各有优劣,具体用哪个还得看实际情况。