
Swin Transformer
- paper: https://arxiv.org/abs/2103.14030 (ICCV 2021)
- code:https://github.com/microsoft/Swin-Transformer/blob/2622619f70760b60a42b996f5fcbe7c9d2e7ca57/models/swin_transformer.py#L458
- 学习链接:
- https://blog.csdn.net/qq_37541097/article/details/121119988
- https://zhuanlan.zhihu.com/p/626820422 (Multi-Head-Attention的作用到底是什么?)
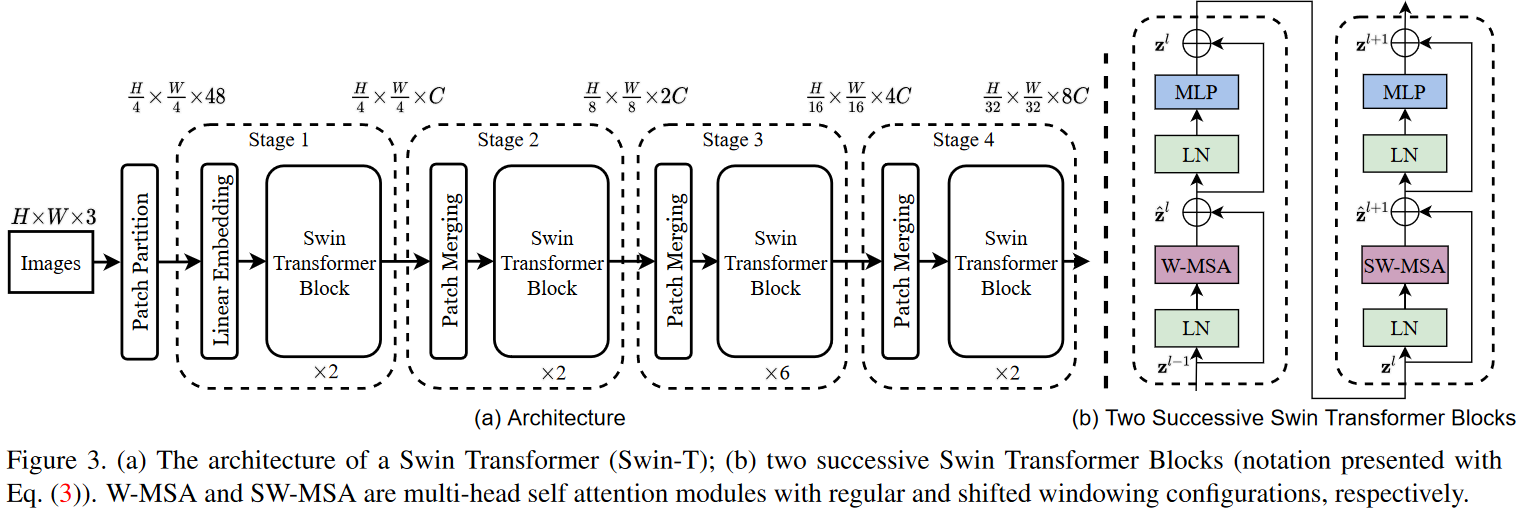
- Patch Partition
对图片进行分块,相邻的4x4的像素为一个Patch,然后在每个Patch中,把每个像素在通道方向展平,堆叠到一起。特征图形状从[H, W, 3]变成了[H/4, W/4, 48]。
- Linear Embedding
对每个像素的通道数据进行线性变换。特征图形状从[H/4, W/4, 48]变成了 [H/4, W/4, C]。
-
Swin Transformer Block
-
Windows Multi-head Self-Attention(W-MSA)
为了减少计算量,对特征图按照MXM大小划分成一个个window,单独对每个windo内部进行self-attention。
-
Shifted Windows Multi-Head Self-Attention(SW-MSA)
W-MSA无法在window与window之间进行信息传递,为了解决这个问题,SW-MSA对偏移的windows内部在进行self-attention。这里用到了masked MSA来防止不同windows中的信息乱窜。
-
-
Patch Merging
对特征图进行下采样,H和W都缩小2倍,C增加2倍。Patch Merging会将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置的像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。最后通过一个全连接层在feature map的深度方向做线性变化,将feature map的深度由C变成C/2。
- Relative Position Bias
公式中的B就是就是Relative Position Bias,论文中的消融实验验证了其能带来明显的提升。
MSwin
- paper:https://arxiv.org/abs/2203.10638 (ECCV 2022)
- code:https://github.com/DerrickXuNu/v2x-vit/blob/main/v2xvit/models/sub_modules/mswin.py
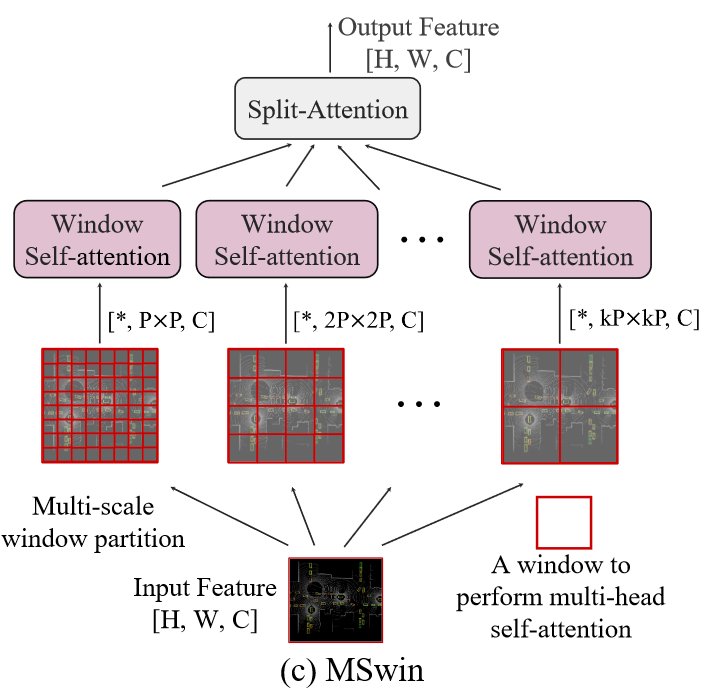
- MSwin把Swin的串行结构改成了并行,最后用了一个Split-Attention融合了所有分支的特征
- MSwin论文中指出不需要用SW-MSA,可达到更大的空间交互(猜测是因为并行的设计?)
Deformable Attention
-
paper:https://openaccess.thecvf.com/content/CVPR2022/html/Xia_Vision_Transformer_With_Deformable_Attention_CVPR_2022_paper.html (CVPR 2022)
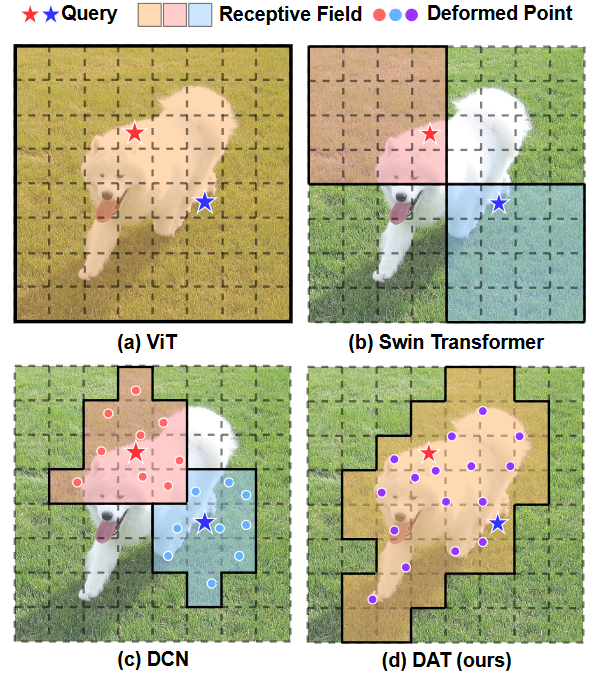

DAT和普通的attention的区别就是,DAT可以汇聚一个自适应的可变感受野信息,一方面可以提高效率,防止无关信息的干扰(相比ViT),另一方面可以使得注意模块更加灵活,有效应对多尺度物体的情况(相比Swin)。
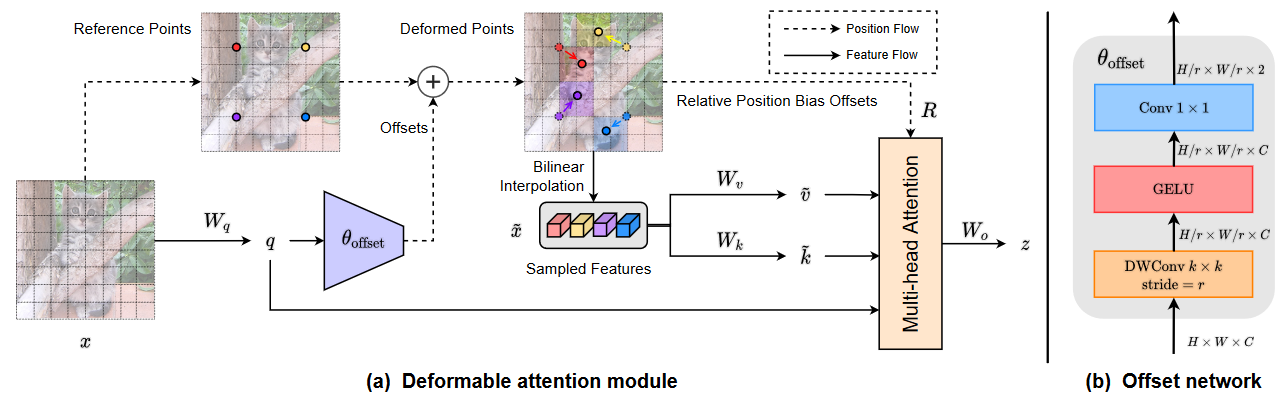
-
输入特征图(假设shape = 1, 256, 48, 176)经过一个卷积层生成查询矩阵q。
-
q通过一个offset network生成偏移量offset(shape = 1, 2, 46, 174),重新排列维度(shape = 1, 46, 174, 2)。
-
生成reference points(shape = 1, 46, 174, 2)。
-
将reference points和offset相加,得到最终的偏移量pos。
-
通过bilinear interpolation,输入pos,输出x_sampled(shape = 1, 256, 46, 174)。
-
由x_sampled生成矩阵k和v。
input = torch.rand(1, 256, 48, 176)
dtype, device = input.dtype, input.device
q = self.proj_q(x) # b c h w
# 生成偏移量
offset = conv_offset(q) # torch.Size([1, 2, 46, 174])
offset_range = torch.tensor([1.0 / (46 - 1.0), 1.0 / (174 - 1.0)]).reshape(1, 2, 1, 1)
# 用 tanh 预定义缩放因子防止偏移量变得太大
offset = offset.tanh().mul(offset_range).mul(2) # torch.Size([1, 2, 46, 174])
offset = einops.rearrange(offset, 'b p h w -> b h w p') # torch.Size([1, 46, 174, 2])
# 生成参考点,最后归一化到[-1,+1]的范围
reference = _get_ref_points(46, 174, 1, dtype, device) # torch.Size([1, 46, 174, 2])
pos = offset + reference
# torch.Size([1, 256, 46, 174])
x_sampled = F.grid_sample(
input=input,
grid=pos[..., (1, 0)], # y, x -> x, y
mode='bilinear', align_corners=True) # B, C, Hg, Wg
MSwin + Deformable Attention
???