
去年我们梳理过OpenAI,Anthropic和DeepMind出品的经典RLHF论文。今年我们会针对经典RLHF算法存在的不稳定,成本高,效率低等问题讨论一些新的方案。不熟悉RLHF的同学建议先看这里哦解密Prompt7. 偏好对齐RLHF-OpenAI·DeepMind·Anthropic对比分析
RLHF算法当前存在的一些问题有
- RL的偏好样本的人工标注成本太高,效率低,容易存在标注偏好不一致的问题
- RLHF属于online训练策略,在训练过程中需要让模型进行解码,时间成本高训练效率低
- RLHF在训练过程中需要同时部署Reward模型和SFT模型和更新后的模型,显存占用高训练成本高
- RLHF需要两阶段的训练,需要先训练reward模型,再使用reward模型更新SFT模S型
这一章我们先聊聊训练策略的新方案。用新方案而不是优化或者改良,因为平替们的效果需要更长时间的验证。
SLiC-HF
- SLiC-HF: Sequence Likelihood Calibration with Human Feedback
- CALIBRATING SEQUENCE LIKELIHOOD IMPROVES CONDITIONAL LANGUAGE GENERATION
要说SLiC-HF,肯定要先说下前置的Calibartion Sequence likelihood(SLiC)的对齐技术,毕竟上面这两篇论文的部分作者都相同,思路自然是一脉相承。
SLiC
SLiC对标SFT,也是post-training的指令对齐方案。方案针对指令微调阶段使用MLE也就是next token prediction带来的稀疏训练问题。因为给定context,是有无数种output可能的。而微调阶段只使用唯一的答案进行训练,导致模型训练不充分。一个明显的现象就是序列的解码概率越高,并不意味着生成序列的质量越好,这意味着生成序列其实是未修正的(uncalibrated)
SLiC的思路有些类似半监督。也就是标注数据有限,导致模型参数更新的空间有限的情况下,我们可以使用半监督的平滑性和一致性原则,既和标注样本相似的样本label相同,反之不同的思路,使用无标注样本对模型进行更新

那我们把半监督的思路放到文本生成:
第一步.先使用SFT对齐后的模型,针对标注样本,每个样本生成m个推理候选结果,这些就是半监督中的未标注样本
第二步.使用无监督样本进行对比训练,核心就是训练模型对和标注答案更相似的候选样本给予更高的解码概率,反之更低
这里训练就有两个细节
- 序列相似如何定义?这里没有引入新的向量模型,直接使用大模型解码输出层的向量表征(seq * hidden)和标注结果的向量表征来计算cosine相似度,相似度计算参考了BertScore的F1值。并且这里对序列进行了切分,分别计算span=1,2,4,8等不同长度的F1值,再进行聚合。

- 损失函数如何定义?论文尝试了以下4种不同的对比损失函数,主要差异在pair-wise还是list-wise,拟合相似度的相对排序(i-j),还是绝对打分(P(yi|x)-P(yj|x))的高低。消融实验显示第一个Rank Loss的效果最好。也就是从所有解码生成的候选中随机采样两个,以上F1更高的为正样本,反之为负样本。计算解码概率的Hinge-Loss

这里论文同样加入了正则项,避免模型过度偏离原始SFT对齐的模型,分别尝试了KL和MLE两种不同的正则。消融实验显示KL正则项的效果更好。
所以综上SLiC使用了无监督的思路,用对比学习来进行对齐。下面我们来看如何使用SLiC来对齐人类偏好
SLiC-HF
偏好样本
首先SLiC-HF用的是offline的训练方案,所以先说下偏好样本是如何构建的。论文尝试了Direct和Sample and Rank两种样本构建方案。
Direct方案就是直接使用Reddit摘要数据集中人工标注的正负偏好样本作为\(y^+,y^-\),优点是成本低,缺点是这里的解码结果可能和SFT模型的解码分布存在偏差。
Sample and Rank,也就是先使用以上偏好数据训练Reward模型,论文尝试了两种方案,一个是绝对偏好,模型预测Good/Bad使用解码概率作为label。另一个是相对偏好,也就是模型学习两个摘要之间的相对好坏。

之后使用SFT模型随机解码(temperature=0.7)生成的8个解码候选,使用以上模型打分或排序后,随机采样8个正负样本对。
效果上Sample and Rank要优于Direct,但如果Driect部分是直接使用SFT模型生成候选再人工标注的话,其实结果可能也不差。
损失函数
已经有了正负样本对,那其实只需要用到上面的对比损失函数了,不需要使用半监督了。不过这里的正则器没有选用KL,而是直接使用SFT样本的MLE来防止模型能力衰减。最终的损失函数如下

除了Offline的样本构建训练效率更高之外,SLiC-HF直接使用序列概率表征偏好,因此不需要使用reward模型,同时对比来自样本而非来自模型,因此也不再需要使用冻结参数的SFT模型。训练过程内容中只有一个SFT模型进行梯度更新。
DPO
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- https://github.com/eric-mitchell/direct-preference-optimization
- https://github.com/huggingface/trl/blob/0a6c42c12c637bb7f28782fa72ec45dd64bce0bd/trl/trainer/dpo_trainer.py
DPO和SLiC同样是基于offline的正负偏好样本对,通过对比学习来进行偏好对齐。DPO的偏好样本标注是直接基于SFT模型生成候选,然后人工标注得到正负(win,loss)样本对,然后直接使用损失函数进行拟合,不训练reward模型。不过二者的对比损失函数不同,DPO的损失函数如下

以上\(\pi\)是模型解码输出层每个token
的输出概率logp求和,\(\theta\)是参与梯度更新的模型,ref是SFT对齐后的模型参数作为基准参数被冻结。
所以简单直观的理解也就是DPO的损失函数,让模型对偏好样本的解码概率相比ref升高,让模型对负样本的解码概率相比ref下降。和Triplet Loss的对比损失函数的思路有些相似。
我们和SLiC-HF做下对比,首先SLiC是hinge-loss(maximum-margin),DPO不是。其次SLiC是正负样本直接对比,DPO是正负样本概率分别和基准模型(SFT模型)进行对比,二者的差异有些类似simases和triplet loss,只不过DPO的锚点不是锚点样本而是基准模型。所以模型既需要拟合相对偏好,也需要保证绝对分布不会答复偏离原始SFT模型。在后面的一些对比论文中普遍结论是DPO的损失函数更优,SLiC的对比函数会导致一些reward hacking
论文还进一步从梯度计算的角度进行了阐述,如果上述损失函数对\(\theta\)求导。会得到以下公式

其中\(\hat{r_{\theta}}(x,y)=\beta log(\frac{\pi_{\theta}(y|x)}{\pi_{ref}(y|x)})\)是DPO的核心,既对齐模型的输出层的概率偏离原始SFT模型的幅度能隐式表征偏好,作为 pseudo Reward来进行模型对齐。正负样本差异越大越多更新幅度越大,梯度方向是提高偏好样本的解码概率,降低负样本的解码概率。
RRHF
- RRHF: Rank Responses to Align Language Models with Human Feedback without tears
- https://github.com/GanjinZero/RRHF
RRHF同样是offline构建正负样本对,再采用对比学习进行偏好对齐的方案,那这里我们只看RRHF和SLiC的差异点。
其一是RRHF使用了长度归一化的序列概率来表征偏好,SLiC直接使用了解码概率

其二是SLiC使用了Hinge-Loss,而RRHF是直接拟合正负样本的概率差

其三是正负样本的构建方案,SLiC是基于SFT模型进行随机解码生成候选,并基于Reward模型离线构建正负样本,而RRHF的候选采样方案还对比了beam-search,diversity-beam-search,以及Iterate-beam-search,也就是每训练一个epoch基于微调后的模型重新生成一波候选。Iterate-beam-search的采样方案会有一些效果提升,考虑生成样本会随分布修正而逐渐优化,可以覆盖更多的分布空间。以及Iterate-beam-search其实和PPO在线解码进行模型更新的方案更加相似,但相对效率更高。
三合一大礼包- RSO
STATISTICAL REJECTION SAMPLING IMPROVES PREFERENCE OPTIMIZATION
RSO方案融合了以上三者,主要是DPO和SLiC,分别对损失函数和偏好样本对的构建方式进行了改良。先说损失函数,RSO把SLiC的Hinge-loss加入到DPO的sigmoid-norm损失函数中,得到了如下的hinge-norm损失函数

再有是偏好样本构建,RSO指出既然以上对比函数的目标是拟合最优的Policy,那理论上偏好样本对也应该从\(\pi^*\)来构建。近似于以上RRHF的Iterate-beam-search的最后一个Iterate的样本分布。但\(\pi^*\)还没训练出来要如何拿到它的对比样本呢?
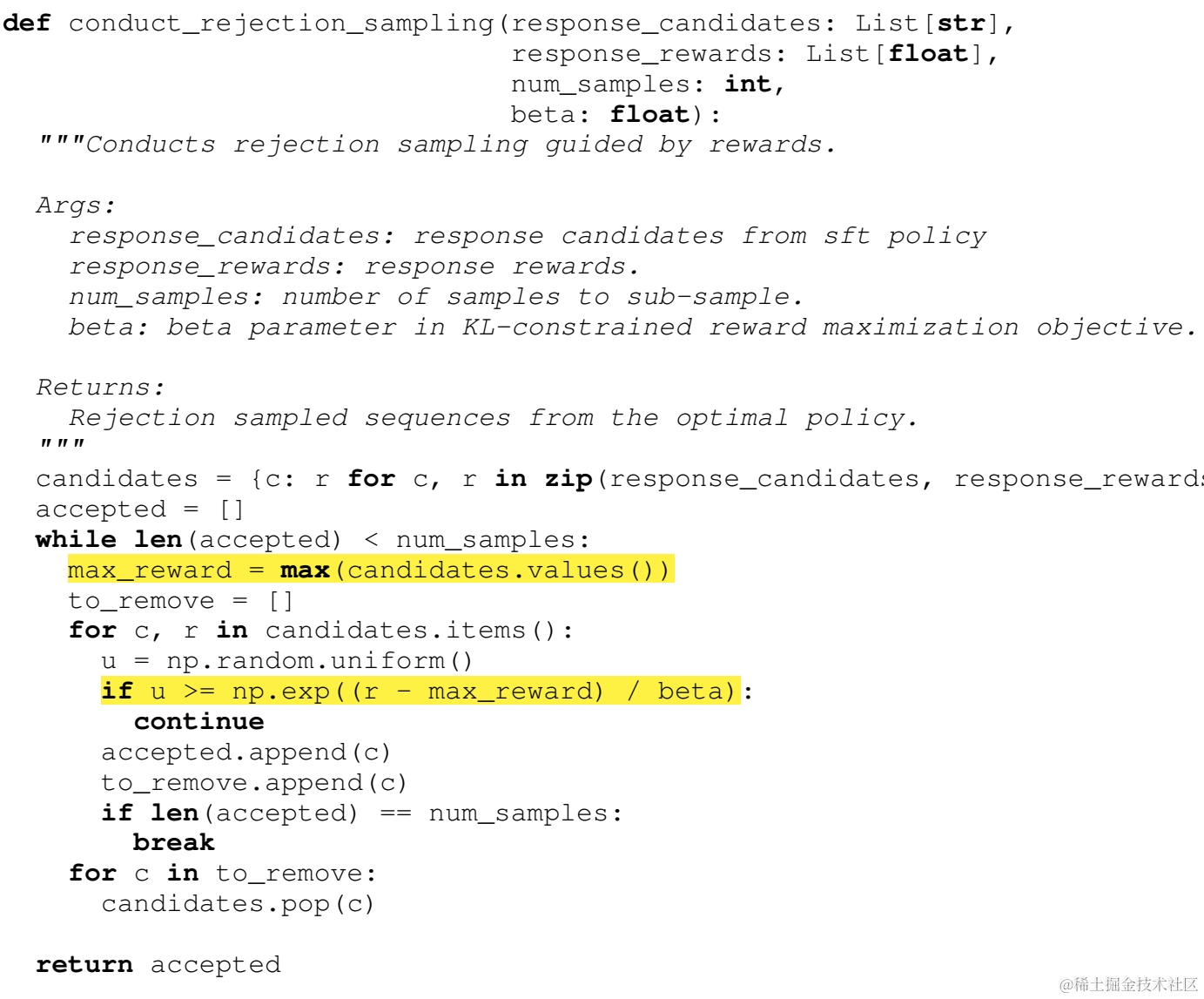
这里RSO提出可以采用从\(\pi_{SFT}\)中拒绝采样来近似\(\pi_{r}\)的分布,对比SLiC的SFT-sample-rank,称之为RSO-Sample-Rank。具体构建方式还是从SFT生成多个解码候选,并使用训练的Reward模型对每个候选进行打分,接着进行拒绝采样。
首先拒绝采样使用g(x)拟合f(x), 计算一个常数C,使得\(c*g(x)>=f(x)\)。则采样过程是从g(x)中采样,当随机变量\(U\sim(0,1)<=\frac{f(x)}{c*g(x)}\)则保留样本,反之拒绝。

这里g(x)就是SFT模型\(\pi_{sft}\),f(x)是最终对齐的模型\(\pi_{r_{\tau}}\),理论上\(m*\pi_{sft}>=\pi_{r_{\tau}}\),这样当\(U<= \frac{\pi_{r_{\tau}}}{m*\pi_{sft}}\)我们保留样本,但因为这里的的\(\pi_{r_{\tau}}\)并无法获得,因此我们用DPO中推导的Policy和reward的关系

为了diff掉正则项Z,论文使用所有随机解码样本的最大reward的(x,y)来作为常数C的估计。

最终得到的拒绝采样的代码如下
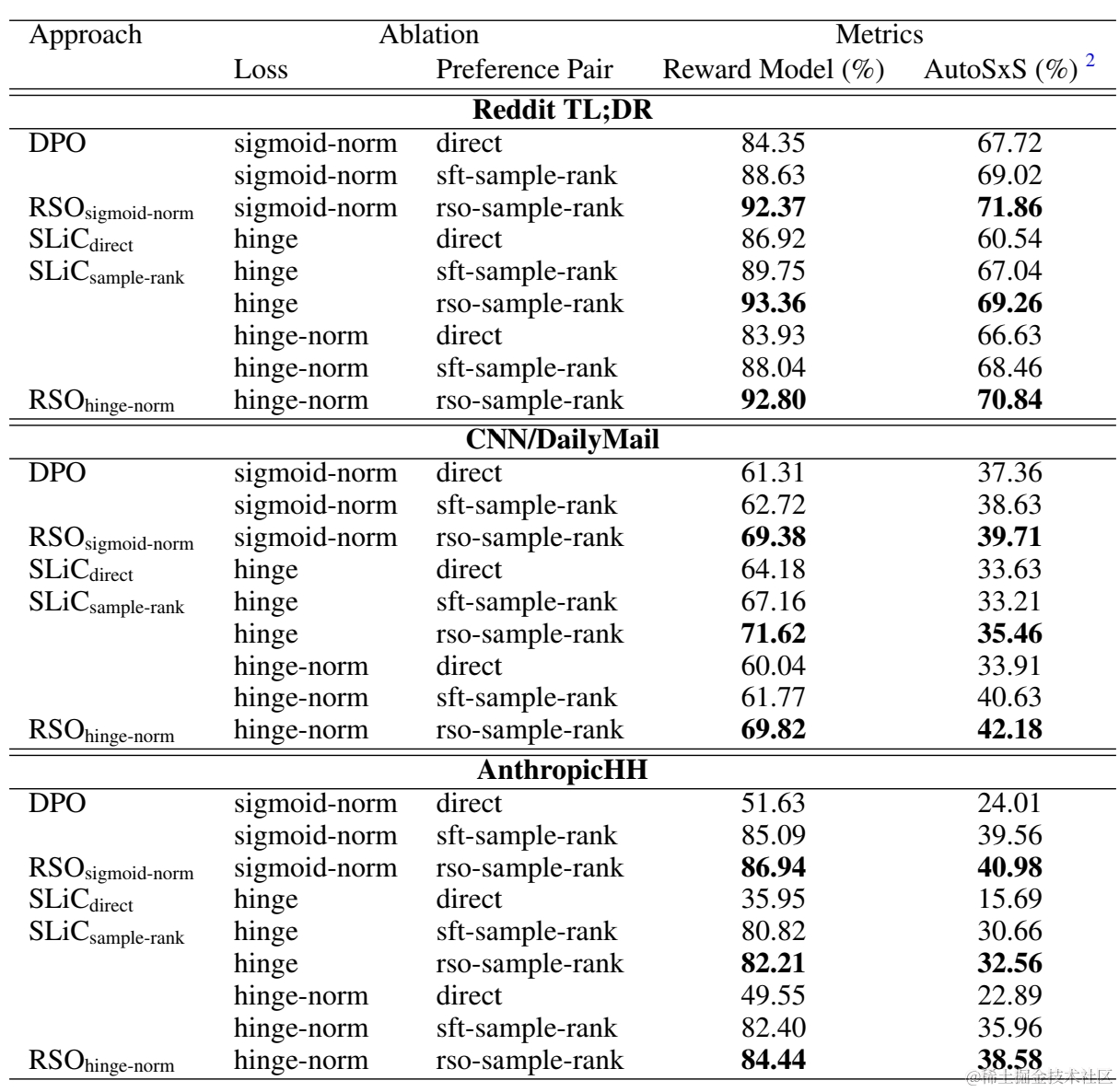
效果上论文对比了DPO,SLiC,RSO,以及不同损失函数,不同采样方案的效果差异。整体上采样带来的收益是更为显著,DPO的损失函数上加不加hinge差异并不大,但都会优于SLiC的直接对比损失函数。
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt