
案例二:对文本进行分类,类别有财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐
github代码链接点击此文本分类
原作者给出了好几种模型
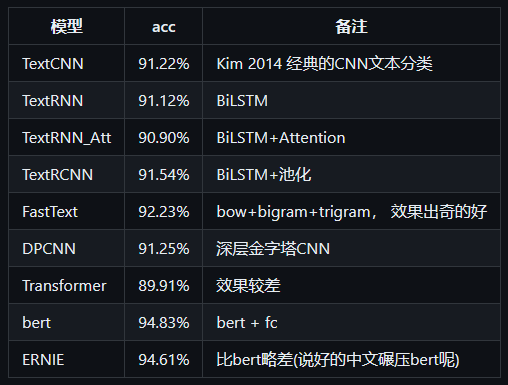
此次仅针对BiLSTM模型分析。
核心代码如下:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)
def forward(self, x):
x, _ = x
out = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
class Model(nn.Module)::定义了一个继承自nn.Module的模型类Model。
针对def __init__(self, config):
def __init__(self, config)::定义了类的初始化方法,接受一个配置参数config,用于初始化模型的各种参数。
super(Model, self).__init__():调用父类nn.Module的初始化方法。
if config.embedding_pretrained is not None::判断是否提供了预训练的词向量。
如果提供了预训练的词向量,则使用nn.Embedding.from_pretrained()方法初始化词嵌入层,并将参数freeze设置为False,表示不冻结词向量参数。
如果没有提供预训练的词向量,则使用nn.Embedding()方法初始化词嵌入层,参数包括词汇表大小config.n_vocab、词向量维度config.embed和填充符索引padding_idx。
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers, bidirectional=True, batch_first=True, dropout=config.dropout):初始化双向LSTM层。
参数包括输入维度config.embed、隐藏层维度config.hidden_size、层数config.num_layers、是否双向、是否批量优先以及dropout率。
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes):初始化全连接层。
输入大小为双向LSTM输出的特征维度乘以2(因为使用了双向LSTM),输出大小为类别数量config.num_classes。
针对def forward(self, x):
def forward(self, x)::定义了模型的前向传播方法。
x, _ = x:由于输入x是一个元组,包含文本数据和对应的标签,这里使用x, _来解包取得文本数据。
out = self.embedding(x):将文本数据x经过词嵌入层得到词向量表示out。
out, _ = self.lstm(out):将词向量表示输入双向LSTM层进行编码,得到LSTM的输出out。
out = self.fc(out[:, -1, :]):取出LSTM输出序列的最后一个时间步的隐藏状态作为整个句子的表示,然后通过全连接层进行分类得到输出out。
return out:返回模型的输出。
思考:
和案例一中代码相比,试分析不同点。
- 在案例二代码中,模型的初始化是通过传入一个配置参数
config来完成的,其中包含了模型所需的各种参数,如词表大小、词向量维度、隐藏层大小等。模型的词嵌入层和LSTM层都会根据配置参数进行初始化。
在案例一代码中,模型的初始化是直接在__init__方法中进行的,并没有接受额外的参数。词嵌入层和LSTM层的大小是根据预先定义的全局变量n_class和n_hidden来确定的。 - 针对
forward,在案例二代码中,前向传播方法forward接受一个输入x,该输入包含了文本数据和对应的标签。模型首先通过词嵌入层将文本序列转换为词向量表示,然后通过LSTM层对词向量进行编码,最后取句子最后时刻的隐藏状态并通过全连接层进行分类。
在案例一代码中,前向传播方法forward接受一个输入X,该输入是一个形状为[batch_size, max_len, n_class]的序列数据。模型首先将输入转置为形状为[max_len, batch_size, n_class],然后通过LSTM层进行序列编码,最后取序列的最后一个时间步的隐藏状态,并通过全连接层进行预测。 - 在案例二代码中,优化器和损失函数的定义并未包含在Model类中,可能是在其他地方进行了定义。
在案例一代码中,定义了一个名为optimizer的优化器和一个交叉熵损失函数nn.CrossEntropyLoss()。
和案例一中代码相比,试分析相同点。
- 模型的输出层都是全连接层:无论是文本分类模型还是序列预测模型,它们都在最后一层使用了全连接层(nn.Linear)来将LSTM的输出映射到最终的预测结果。这样的设计是为了将LSTM输出的特征向量转换为最终的分类或预测结果。
- 使用了相似的参数初始化方式:尽管参数的具体值可能不同,但两个模型都在初始化阶段使用了类似的方法来确定词嵌入层和LSTM层的参数。这包括词汇表大小、词向量维度、隐藏层大小等参数的设置,使得两个模型在结构上具有一定的相似性。
- 使用了相似的前向传播方法:尽管模型任务不同,但它们的前向传播方法都遵循了相似的流程:首先对输入数据进行一些预处理(如词嵌入或转置),然后将数据输入到LSTM模型中进行编码,最后将编码后的结果通过全连接层得到最终的输出。
- 都继承自
nn.Module:两个模型都是基于PyTorch的nn.Module类进行构建的,这是PyTorch中定义模型的标准做法。因此,它们具有相似的模型结构和方法。
对于BiLSTM的实现,两段代码有异曲同工之妙:
- BiLSTM是由两个LSTM组成的,一个按照正序处理输入序列,另一个按照逆序处理输入序列。两者的输出经过连接或者拼接,形成了最终的BiLSTM输出。
- 两段代码中,都可以通过设置参数来定义BiLSTM的输入维度、隐藏层维度、层数、是否双向、是否批量优先以及dropout率等参数。
- 无论哪个案例,都需要经过词嵌入层(如果有)以及适当的预处理后再输入到BiLSTM模型中进行处理。
- 在前向传播过程中,两段代码都会将输入数据传递给BiLSTM模型进行处理,然后取得BiLSTM输出的结果。
这些输出结果通常是每个时间步的隐藏状态,可以根据任务的不同选择不同的输出方式,如取最后一个时间步的隐藏状态或者进行序列的平均池化等。
最终,通过全连接层对BiLSTM的输出进行映射,得到最终的分类或预测结果。