
C++之线程库
前言
C++的线程库,不是只有线程,有好几个库,包括了创建线程,锁,条件变量,原子操作等待
thread类
在C++11之前,涉及到多线程问题,都是和平台相关的,比如windows和linux下各有自己的接口,这使得代码的可移植性比较差。C++11中最重要的特性就是对线程进行支持了,使得C++在并行编程时不需要依赖第三方库,而且在原子操作中还引入了原子类的概念。要使用标准库中的线程,必须包含< thread >头文件
构造函数
thread类是不支持拷贝构造的!
thread类是可以支持创建空线程(什么都不走)——像是linux下面的pthread就要求传入参数
**thread类是支持接收可调用对象——例如:==仿函数,函数指针,lambda,function包装器,==而且可以支持传入==多个参数!==**如果是类似linux下的原生接口就只允许传入一个参数!如果想要传入多个参数还需要用结构体!
thread类是支持移动构造
操作相关接口
thread库还有一个this_thread是一个命名空间
这个命名空间里面封装了一些全局函数,是公共的全局操作——专门用来在线程体内获取线程本身的信息!或者堆线程本身进行操作!
get_id就是用来获取线程的id
sleep_for用来让线程休眠多长时间!
sleep_until让线程休眠到指定时间!
yield这个接口的作用是让出线程的CPU时间片,因为某些原因导致了线程继续执行的条件不满足但是时间片还没有用完,那么就可以调用这个接口让线程让出CPU,然后去唤醒其他线程!——==这个接口的作用一般用于无锁编程,配合一些原子操作进行控制!==(yield的意思就是让出)==C++11中thread库最大的优势就是封装,分别对linux和Windows的创建线程的接口都进行的封装!(例如:linux是使用fork接口创建进程,Windows是CreateProcessW接口来创建的)——这是通过条件编译来实现的!==
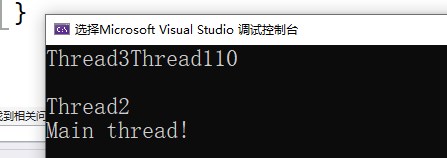
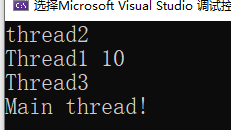
void ThreadFunc(int a) { cout << "Thread1" << a << endl; } class TF { public: void operator()() { cout << "Thread3" << endl; } }; int main() { // 线程函数为函数指针 thread t1(ThreadFunc, 10); // 线程函数为lambda表达式 thread t2([] {cout << "Thread2" << endl; }); // 线程函数为函数对象 TF tf; thread t3(tf); t1.join(); t2.join(); t3.join(); cout << "Main thread!" << endl; return 0; }
因为不知道那个线程会先启动!而且C++中cout的流缓冲区属于共享资源!被多个线程同时访问就会出现这样的问题
换成printf的话打印就没有问题了!
==C++中Thread类的无参构造的用处——创建线程池!==
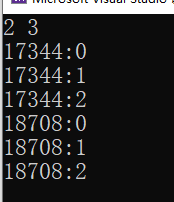
#include<thread> #include<iostream> #include<vector> using namespace std; int main() { int n,m; cin >> n >> m; vector<thread> threads; threads.resize(n); //这里就相当于创建了n个线程对象!只不过是n个空线程!可以认为在底层其实只是将这个数据结构创建出来了!但是没有真正的去创建线程! //那么我们该如何让线程对象跑起来呢?——使用移动构造/移动赋值! // for (const auto t : threads)//这是不支持的!因为范围for相当于将threads里面的每一个对象赋值个给t,但是thread类是不支持拷贝构造的! // { // } for (auto& t : threads)//这里使用引用,就可以修改threads里面的每一个对象了! { t = thread([m] { for (size_t i = 0; i < m; i++) { cout << this_thread::get_id() << ":" << i << endl;//在get_id要通过对象来调用!但是我们没有对象!怎么办?使用this_thread这个类我们就可以获取 } });//使用移动赋值 } for (auto& t : threads) { t.join(); } //如果不等待,会导致主线程先执行完毕,然后导致多个从线程还在运行!但是主线程已经结束从而导致程序崩溃! return 0; }


线程函数的参数
关于线程函数的参数是以值拷贝的方式拷贝到线程栈空间中的,因此:即使线程参数为引用类型,在线程中修改后也不能修改外部实参,因为其实际引用的是线程栈中的拷贝,而不是外部实参。
mutex类
在多线程的情况下,有可能会出现数据不一致的问题!
#include<thread> #include<iostream> #include<vector> using namespace std; int g_val = 0; void func1(int n) { for (size_t i = 0; i < n; i++) { g_val++; } } int main() { thread t1(func1,100000); thread t2(func1,100000); t1.join(); t2.join(); cout << g_val << endl; }
、
==为了解决这个问题!所以我们可以通过加锁来解决!C++也给我们提供了mutex库用==
mutex类的构造函数
==我们可以看到mutex是不能拷贝构造的!也不能赋值拷贝!==
lock是加锁!——如果此时锁被其他线程占用就会阻塞!
unlock就是解锁!
try_lock——就是尝试加锁!是一种不阻塞式的加锁!如果加锁失败不是阻塞而是返回错误!while(try_lock(mutx) != -1)//获取到锁! { //进行线程安全的操作! unlock(); } else { //... }==注意递归里面使用互斥锁要小心!!==
void func(int n) { lock(); //执行线程安全的操作! func(n-1); unlokc();//这样子是一定会发生死锁的!! }==所以还专门提供了一个类——递归互斥锁!==
所有的操作都和mutex是一样的!——但是这个锁在进行上面的操作的时候就不会发生死锁!
原理是,锁的内部肯定会知道持有锁的线程的id!在再次的获取锁的时候判断一下!看看是不是同一个线程,如果是同一个!那么就直接进入!
#include<thread> #include<iostream> #include<vector> #include<mutex> using namespace std; mutex mtx; int g_val = 0; void func1(int n) { for (size_t i = 0; i < n; i++) { mtx.lock(); g_val++; mtx.unlock(); } } int main() { thread t1(func1,100000); thread t2(func1,100000); //多个线程同时能执行一个函数的本质是因为线程是有自己的独立的栈结构! //但是代码段是共享的!两个线程都可以访问这个函数!所以函数执行是不会互相干扰的! t1.join(); t2.join(); cout << g_val << endl; }
void func1(int n) { mtx.lock(); for (size_t i = 0; i < n; i++) { g_val++; } mtx.unlock(); //锁可以放在外面也是可以的!但是这样子就变成了两个线程是串行执行的! }int main() { thread t1(func1,10000000); thread t2(func1,10000000); t1.join(); t2.join(); cout << g_val << endl; }==如果我们将值放大一点!我们就会发现放在外面的线程执行速度会比里面的快!为什么?放在里面两个线程都是并行的执行!但是放在外面确实串行的执行!为什么串行的速度反倒是比并行的还要快?==
因为放在里面!会导致两个线程在CPU里面频繁的进行切换!检测到没有锁,那么就进行保存上下文,切换上下文等一系列的事情!然后切换到有锁的哪一个线程!这样子要频繁切换20000000次!这样子性能消耗就很大!
如果是放在外面呢?——那么就是一次性全部执行完毕然后就切换一次到另一个线程然后一次性执行完毕!——整个过程只切换了一次!
==所以在循环体里面中间执行的操作性能消耗很少执行速度很快,那么放在外面反倒是比放在里面更加省性能!==
==如果是一个例如红黑树的插入这种性能消耗比较大的操作,放在里面是可以的!因为这样子是不会频繁的进行切换!==
mutex库一共有四个类
后面两个就是多了两个接口
一个是加锁多长时间!(try_lock_for)例如:锁1分钟,1分钟后还没有被解锁就自动解锁,如果这之前就被解锁了那么就没有用了!
一个是加锁到哪一个固定时间点——(try_lock_until)例如:锁到某一个特定的时间点!
这两个接口要配合chrono这个类使用
 、
、




atomic类
上面的数据不一致问题除了使用加锁的,还能使用原子操作!
**数据不一致的本质原因是因为++这个操作本身不是原子的!——那么我们只要让这个操作本身就变成原子的不就好了? **
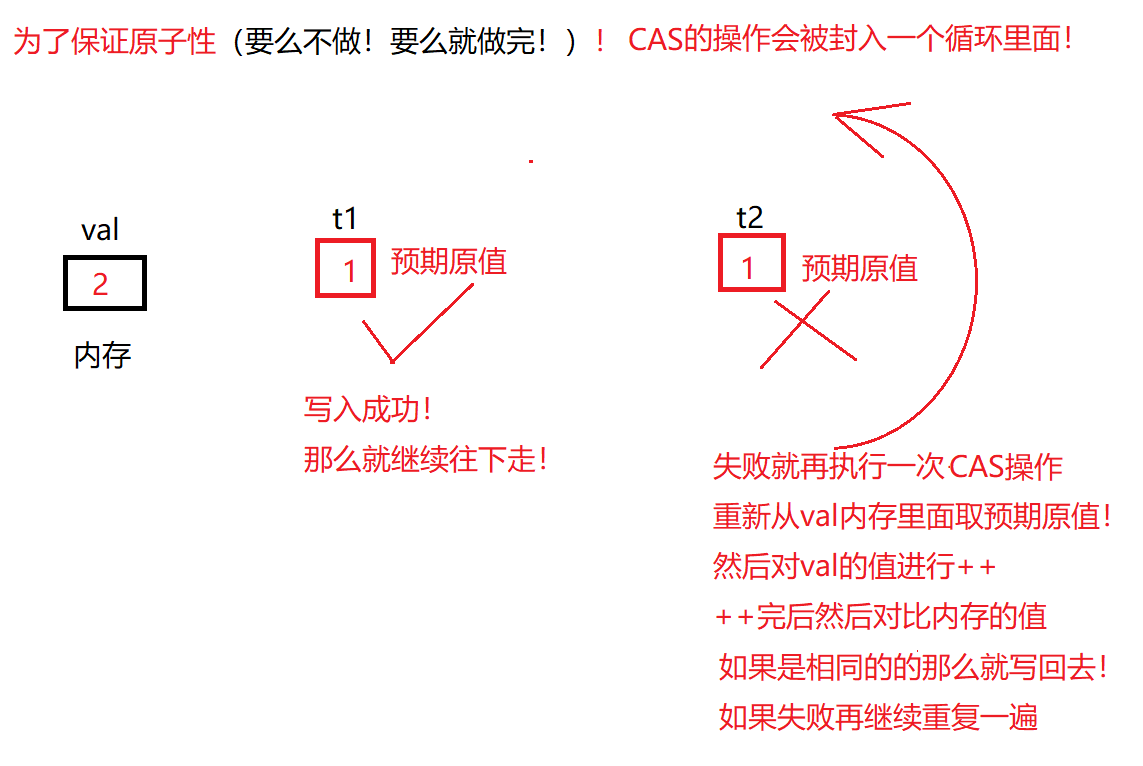
==原子操作一般都是操作系统提供的!——CAB(Compare and Swap)==
什么是CAS?
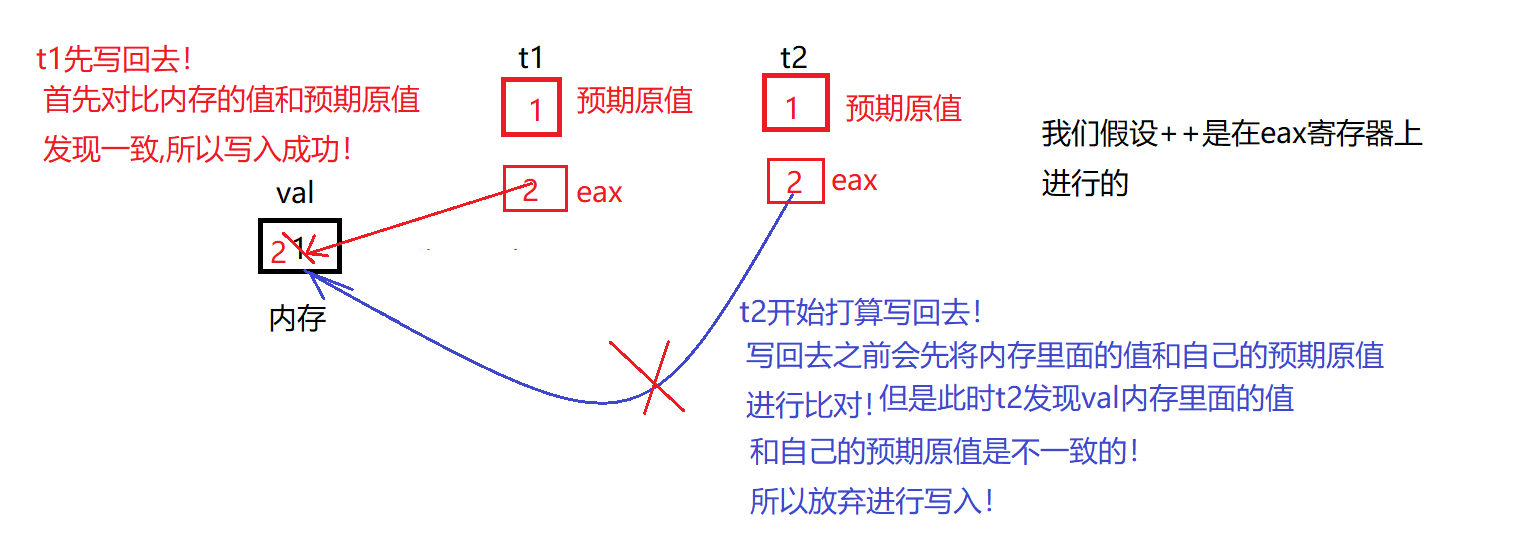
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。 如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该 位置的值。(在 CAS 的一些特殊情况下将仅返回 CAS 是否成功,而不提取当前 值。)
那么如何底层是如何通过CAS让++这个操作变成原子的呢?
==如果不用CAS都会写入成功!——但是有了CAS一定只有一个线程会写入成功!==
==C++提供的atomic库就是相当于C++对于CAS这一系列操作的封装!==
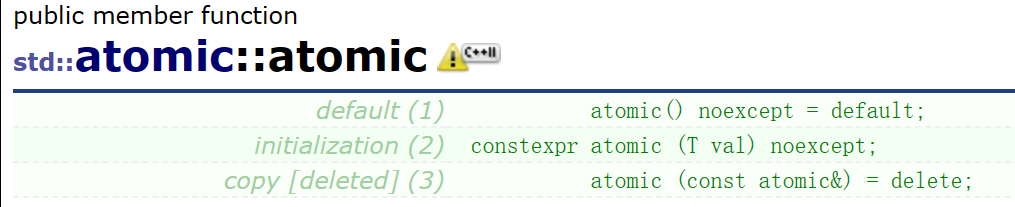
构造函数
我们可以看到atomic这个类是不支持拷贝构造和赋值
成员函数
fetch_add——就是将值原子式的加到atomic容器的值里面!
fetch_sub——就是原子式的减少
fetch_and——就是我们一直用到 按位与操作!只是是原子的!
fetch_or——原子的按位或操作
fetch_xor——原子的按位异或操作!
operator++——原子的++操作
operator--——原子的--操作==这些的底层都是一个while+CAS搞定的!==
is_lock_free——检查该atomic对象是不是无锁的!
store——atomic对象的值进行重新写入!
load——读取atomic对象的值!
exchange——和store的作用一样!也是对值进行重新写入!只是多了一个返回原先拥有的值!
compare_exchange_strong——这就是一个CAS接口我们可以看到第一个参数的值就是预期值!第二个的值就是就是新写入的值!
- 如果当前的值与期望值相等,则将新值存储到原子对象中,返回
true,表示交换成功。- 如果当前值与期望值不相等,则将原子对象的值更新为当前值,返回
false,表示交换失败。- 这个版本的函数在交换成功时能确保新值被存储到原子对象中,因此具有强一致性。
compare_exchange_weak——这就是CAS相关接口!
我们可以看到第一个参数的值就是预期值!第二个的值就是就是新写入的值!
compare_exchange_strong——也是CAS相关接口!用法和上面的weak差不多
- 与
compare_exchange_strong类似,如果当前的值与期望值相等,则将新值存储到原子对象中,返回true,表示交换成功。- 如果当前值与期望值不相等,它可能会重新尝试比较交换操作,也可能放弃尝试,返回
false。这个用于对于数据不一致要求不那么严格的场景!
operator T——是一个类型转换!它的作用是将std::atomic对象转换为其底层的基本数据类型,从而允许你在不需要原子性保证的情况下访问该数据。std::atomic<int> atomicInt = 42; int regularInt = atomicInt;//作用类似这样子!——这样regularInt类型就是一个原生的int类型了!
==回到最开始我们如果不加锁的保持数据一致性呢?==
#include<thread> #include<iostream> #include<vector> #include<atomic> using namespace std; atomic<int> g_val = 0;//原子操作! void func1(int n) { for (size_t i = 0; i < n; i++) { g_val++; } } int main() { thread t1(func1,1000); thread t2(func1,1000); t1.join(); t2.join(); cout << g_val << endl; }
==这样就成功了!——这个比里面加锁快!比里面加锁慢!——因为CAS会导致有些++操作会被放弃!==
但是上面有一个问题,那就是在多线程中,我们不推荐使用全局的对象!
所以我们可以用一个更好的方案
#include<thread> #include<iostream> #include<vector> #include<atomic> int main() { atomic<int> aval = 0; auto func = [&aval](int n) { for (size_t i = 0; i <n; i++) { ++aval; } }; thread t1(func,3000); thread t2(func,1000); t1.join(); t2.join(); cout << aval << endl; }==这就是lambda表达式的好处!可以捕抓局部的变量!==
这样也可以看出,在栈上的变量不一定是线程安全的!因为有lambda表达式可以用来捕抓栈上的变量!——==只要能被多个线程访问到都要考虑是不是线程安全的!==





lock_guard类
int main() { atomic<int> aval = 0; mutex mtx; auto func = [&](int n) { for (size_t i = 0; i <n; i++) { aval++; mtx.lock(); int* a = new int();//如果这个new抛异常了该怎么办? cout << this_thread::get_id() << ":" << aval << endl; mtx.unlock(); } }; thread t1(func,3000); thread t2(func,1000); t1.join(); t2.join(); cout << aval << endl; }这样的情况会不会造成一个线程抛异常后退出,但是锁却没有释放?
==我们可以使用RAII的思想去解决这个问题!构造的时候加锁!析构的时候解锁!让其出了作用域后自动的调用析构函数解锁即可!==
==库里面就已经帮我们封装好了!lock_gurad类==
我们可以看到他主要就是给我们提供了一个构造和析构!
这个锁是一个模板,只要是锁类型的都可以!
int main() { atomic<int> aval = 0; mutex mtx; auto func = [&](int n) { for (size_t i = 0; i <n; i++) { { lock_guard<mutex> lock(mtx);//这样就可以保证出了作用域锁自动的释放! int* a = new int(); cout << this_thread::get_id() << ":" << aval << endl; //我们还可以通过作用域来控制锁的范围! } aval++; } }; thread t1(func,3000); thread t2(func,1000); t1.join(); t2.join(); cout << aval << endl; }

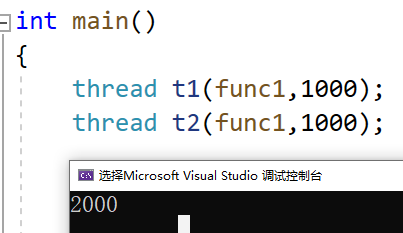
unique_lock
unique_lock是比lock_gurad==更加灵活==的一个锁管理对象!
==unique_lock具有lock_guard的所有特性!——例如构造的时候获取锁!析构的时候释放锁!同时还提供了更多的可可选操作!==
构造函数
unique_lock是支持无参构造和移动构造!
但是不支持拷贝构造!
关于锁操作的成员函数
lock获取当前锁管理的锁!如果没有获取到!那么就阻塞!如果lock调用失败!则会抛异常!
try_lock以非阻塞的形式尝试进行加锁!
try_lcok_for与try_lock_until和上面的mutex的用法都是一样的!
unlock手动的进行解锁!——像是lock_guard就只能等出了作用域后让它自己解锁!==unique_lock给我我们更多的选项==
其他成员函数
unique_lock的赋值重载是只支持——移动构造的!要注意!(只接受右值)
swap就是交换两个unique_lock类所持有的锁!
release:放弃所托管的锁所有权,同时返回这个锁的指针!
owns_lock当锁管理的锁是处于加锁的状态的时候!那么就会返回true!——其他情况都会返回false!(例如unique_lock持有锁但是却自己手动调用了unlock函数或者调用release函数放弃锁的所有权!那么就都会返回false)(这个函数是operator bool函数的别名!)
mutex:返回unique_lock所管理互斥锁的指针!——这是返回指针互斥锁的原生类型的指针!



condition_variable类
C++给我们提供的关于条件变量的类!
构造函数
我们可以看到条件变量只支持无参构造!不支持拷贝构造和赋值
等待操作函数
wait就是让线程在该条件变量下面进行等待!
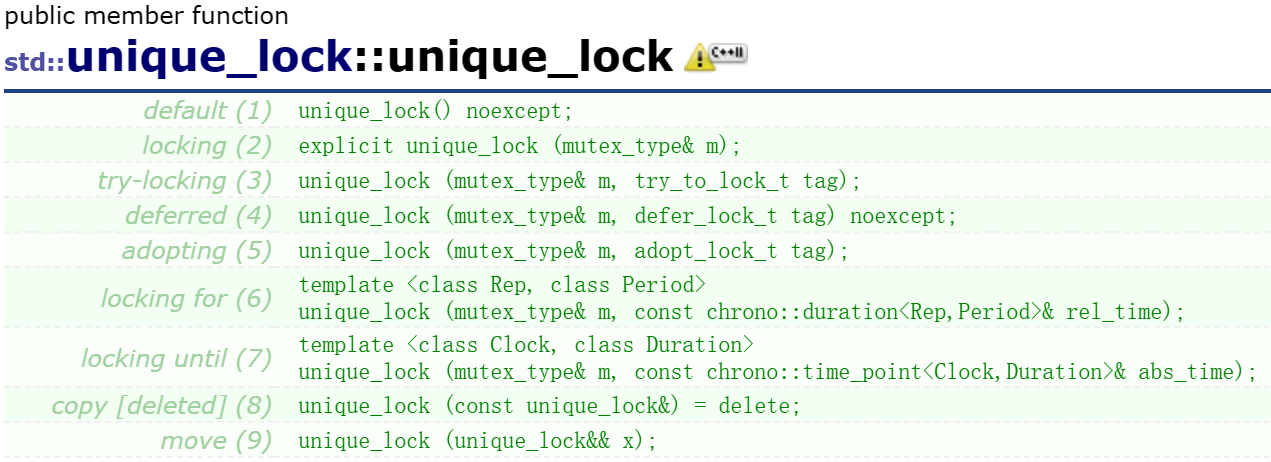
wait_for就是等待一段时间后然后就是自动的唤醒!如果提前被唤醒就没用了!
wait_until等待到某个特定的时间点,然后解锁!如果提前被唤醒!那么就没用!这两个时间相关的函数!在linux下面本质都是使用 pthread_cond_timewait封装出来的!
==这些函数都要配合unique_lock类使用!时间类函数都要配合chrono使用!==
==wait系列的都有一个参数那就是pred——这是一个可调用对象!(你可以传入一个无参数的lambda,仿函数,或者函数)==
==如果指定了pred,当线程未阻塞的时候!pred返回值为true那么就不会阻塞!而是会向下执行!如果是false那么就会阻塞挂起!)==
==当被以这种方式阻塞的线程!只有满足被通知和满足pred返回true的时候!才会真的被唤醒!==
在函数内部的行为类似于
while (!pred()) wait(lck);//只有满足pred返回false才能阻塞 !如果pred返回true,那么就无法阻塞传入的锁都是要是unique_lock类型的!这是为什么呢?
原因就是因为当被挂起的时候,线程就要将自己持有的锁进行释放!否则,其他想要拿到锁的线程就会一直拿不到锁!
使用unique_lock类型的对象就可以手动的去调用unlock成员函数来进行解锁!
同样的等被唤醒就会自动的去调用lock成员函数来进行加锁!如果使用lock_guard就不能做到这一点!因为lock_guard只能在创建时自动加锁!出了作用域自动的解锁!
唤醒操作函数
notify_one唤醒该条件变量下的一个线程!(在linux下面相当于pthread_cond_signal函数)
notify_all唤醒该条件变量下面的所有线程!(相当linux下面的pthread_cond_broadcast)






条件变量的应用——支持两个线程交替打印!一个打印奇数,一个打印偶数!
错误写法!
#include<thread> #include<iostream> #include<vector> int main() { int val = 0;//这是共享资源! thread Odd([&] { while (val <100) { if (val % 2 == 1) { cout << this_thread::get_id() << ":" << val << endl; ++val; } } }); thread Even([&] { while (val<100) { if (val % 2 == 0) { cout << this_thread::get_id() << ":" << val++ << endl; ++val; } } }); Odd.join(); Even.join(); return 0; }这个写法运行有时候可能运行成功!有时候可能运行失败!
==我们以i == 99举例!==
==这样子导致了具有十分强的随机性!==
#include<thread> #include<iostream> #include<vector> int main() { int val = 0;//这是共享资源! thread Odd([&] { while (val <100) { if (val % 2 == 1) { cout << this_thread::get_id() << ":" << val << endl; ++val; } } }); thread Even([&] { while (val<=100)//如果是这样子好像是可以解决的! { if (val % 2 == 0) { cout << this_thread::get_id() << ":" << val++ << endl; ++val; } } }); Odd.join(); Even.join(); return 0; }但是这就可能会导致性能的浪费!因为假如Odd在第一次运行之后,一直占着CPU不走!直到时间片到了被强制剥离!但是这期间就一直都是在进行循环!但是这个循环是无用的循环!进入了while但是if不满足,一直这样子,在一直的空转!
==我们可以使用条件变量!弄成通知式的来访问!奇数线程好了,通知偶数线程,说好了来访问!条件变量本身不是线程安全的!所以访问之前要进行加锁!==
int main() { mutex mtx; condition_variable cv; int val = 0;//这是共享资源!要用锁保护! thread Odd([&] { while (val <100) { unique_lock<mutex> lock(mtx); while (val % 2 == 0) cv.wait(lock);//为偶数的时候等待!使用while是为了防止伪唤醒! cout << this_thread::get_id() << ":" << val << endl; ++val; cv.notify_one();//唤醒偶数进程! } }); thread Even([&] { while (val<100) { unique_lock<mutex> lock(mtx); while (val % 2 == 1)//为奇数的时候等待!使用while是为了防止伪唤醒! cv.wait(lock); cout << this_thread::get_id() << ":" << val << endl; ++val; cv.notify_one();//唤醒奇数进程 } }); Odd.join(); Even.join(); return 0; }==我们还可以充分的利用一下wait的pred参数!简化代码==
#include<thread> #include<iostream> #include<vector> #include<mutex> #include<atomic> #include <condition_variable> int main() { mutex mtx; condition_variable cv;//这个是共享资源! int val = 0;//这个是共享资源! thread Odd([&] { while (val <100) { unique_lock<mutex> lock(mtx); cv.wait(lock, [&] { return val % 2 == 1; });//这个代码本质是我们上面的写法的封装! cout << this_thread::get_id() << ":" << val++<< endl; cv.notify_one();//唤醒偶数进程! } }); thread Even([&] { while (val<100) { unique_lock<mutex> lock(mtx); cv.wait(lock, [&] { return val % 2 == 0; }); cout << this_thread::get_id() << ":" << val++ << endl; cv.notify_one();//唤醒奇数进程 } }); Odd.join(); Even.join(); return 0; }
