
今天用30行代码爬取下载视频
比较简单啊
关注公众号
公众号回复 梨视频 获取源代码
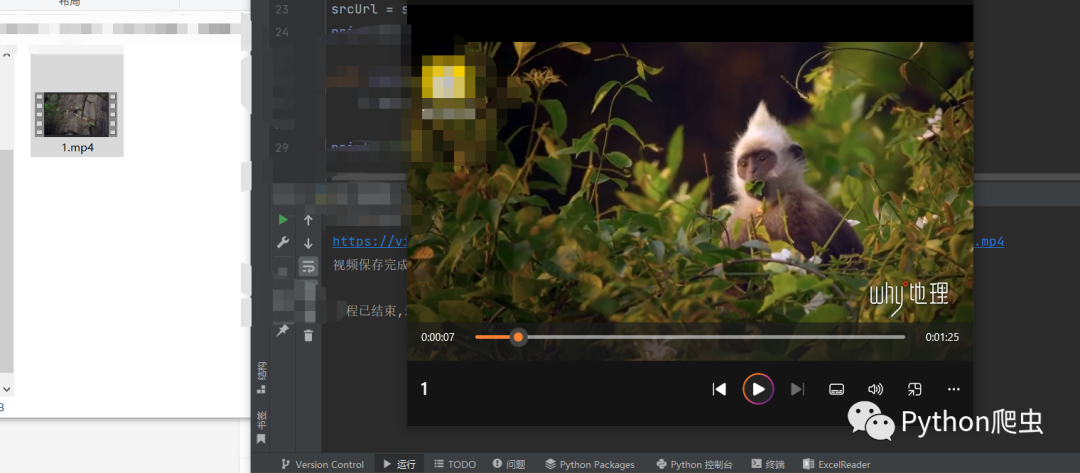
先看效果
可以正常播放没问题
首先打开网站,随便点开一个视频
然后打开开发者模式
开始分析
内容应该是异步传输,所以我们点击网路,点击xhr
然后看到一个文件
里面存放着json格式的数据
全部点开,可以看到一个srcurl
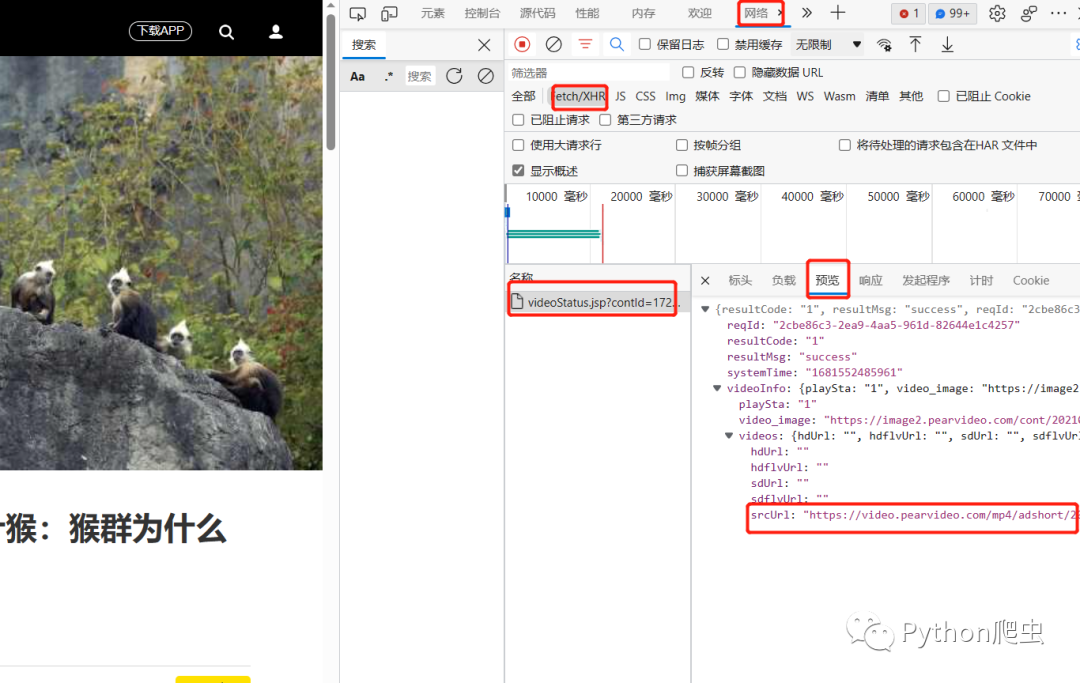
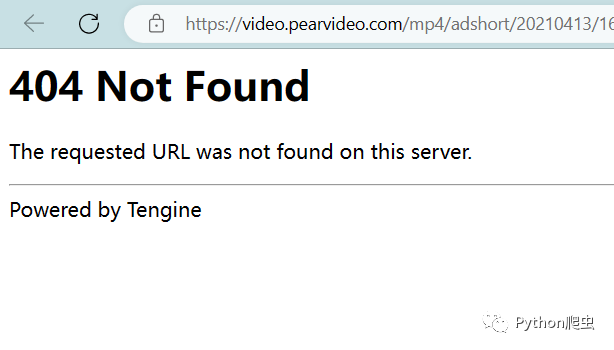
看着像是视频源,但是我们打开它却是404
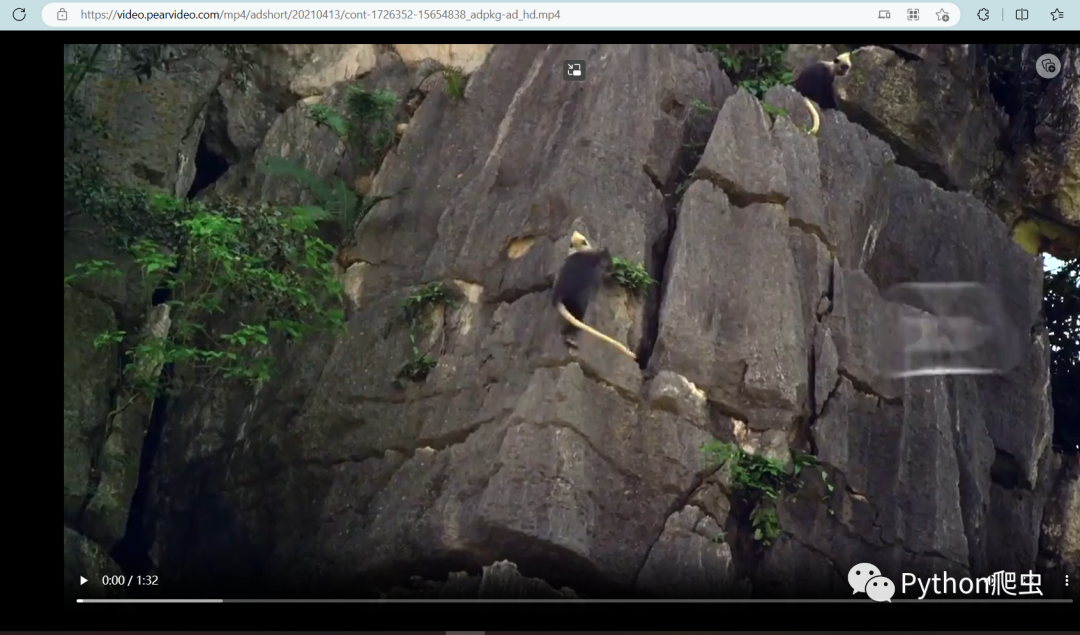
而真实的视频源地址是
https://video.pearvideo.com/mp4/adshort/20210413/cont-1726352-15654838_adpkg-ad_hd.mp4
# 得到的地址
https://video.pearvideo.com/mp4/adshort/20210413/1681552485961-15654838_adpkg-ad_hd.mp4
# 真实地址
https://video.pearvideo.com/mp4/adshort/20210413/cont-1726352-15654838_adpkg-ad_hd.mp4
发现是把那串数字替换成了cont-1726352
1726352是视频id
直接在视频首页连接获取就可以
1681552485961这串数字在json数据里有
所以到时候直接替换就可以了开始写代码
# 视频首页链接
url = 'https://www.pearvideo.com/video_1726352'
# 把contid提取出来
contid = url.split('_')[1]
# 这是存放json数据,视频源的链接
videostatusurl = f'https://www.pearvideo.com/videoStatus.jsp?contId={contid}&mrd=0.8703028188715882'
headers = {
'Referer': url,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.39',
}
# 开始访问
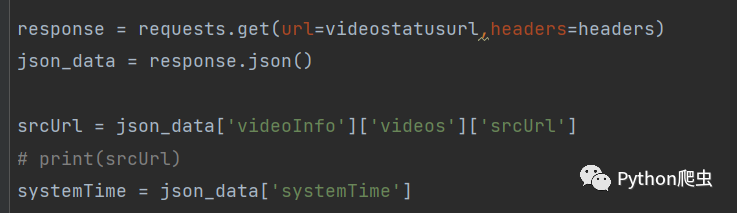
response = requests.get(url=videostatusurl,headers=headers)
json_data = response.json()开始访问,获取数据,提取数据
把systemTime提取出来
因为需要把这串数字替换成contid
这样就可以得到真是视频地址了
然后进行替换
srcUrl = srcUrl.replace(systemTime,f"cont-{contid}")
print(srcUrl)
with open('梨视频/1.mp4',mode='wb',)as f:
f.write(requests.get(srcUrl).content)
print('视频保存完成')看效果
可以播放
公众号回复 梨视频 获取源代码
感谢观看
欢迎分享