
使用python爬虫爬取4399小游戏
准备环境:
python环境,pycharm,requests库,csv库,lxml库
公众号回复 4399 获取源代码
教程:
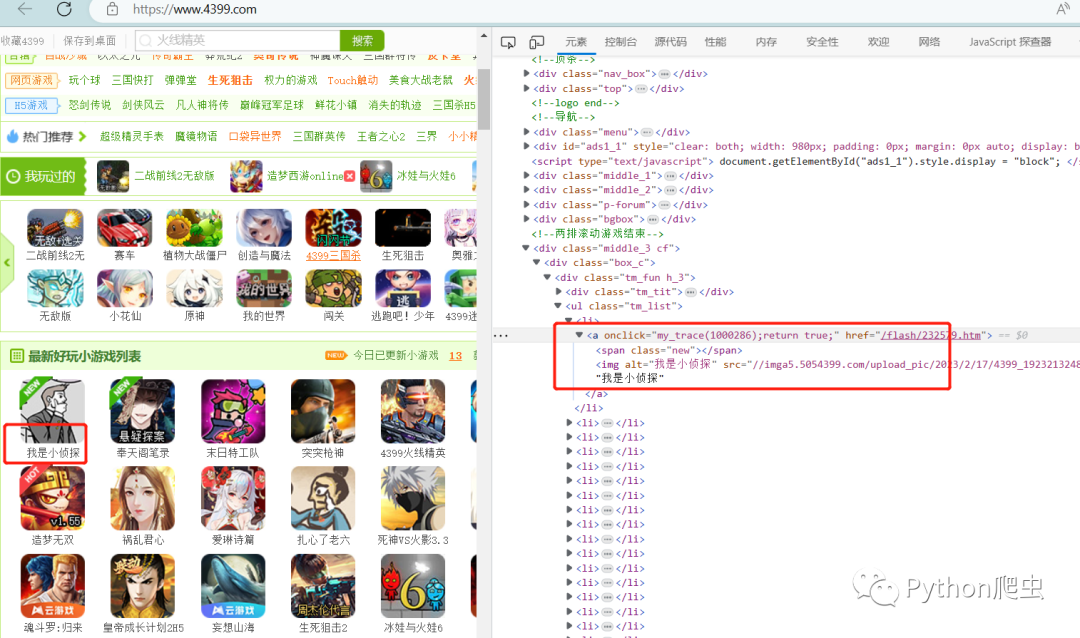
打开4399网站,打开开发者模式,搜索关键字,
观察发现所有的东西都在页面源代码中
每一个游戏对应着每一个ul标签下的li下
思路:
拿到页面源码,提取出li标签的数据,再二次提取
上代码:
访问网站
url = 'https://www.4399.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.63'
}
response = requests.get(url=url,headers=headers)可以看到这个页面使用的是gb2312编码格式

所以我们也改成gb2312
然后用xpath来提取出每一个li标签
response = requests.get(url=url,headers=headers)
response.encoding='gb2312'
page = response.text
html = etree.HTML(page)
lis = html.xpath('//*[@id="skinbody"]/div[10]/div[1]/div[1]/ul/li')for循环每一个li标签,二次提取出游戏名字和游戏地址
for li in lis:
href = ''.join(li.xpath('./a/@href'))
dit['游戏地址'] = 'https://www.4399.com/'+href
dit['游戏名'] = ''.join(li.xpath('./a/text()'))
w_header.writerow(dit)
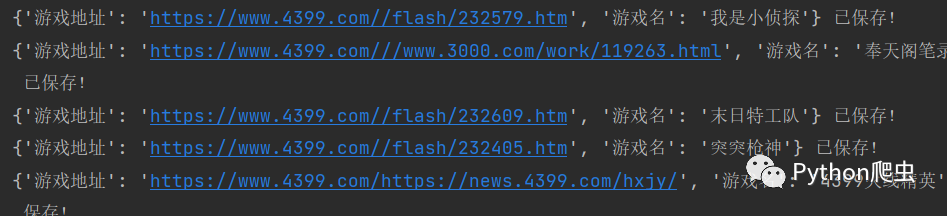
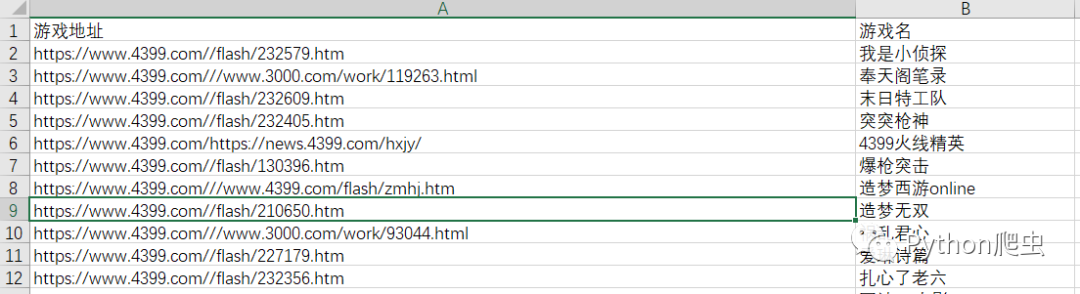
print(dit,'已保存!')并且保存到csv
看效果:
公众号回复 4399 获取源代码
感谢观看!
欢迎分享