
前几天有粉丝问我想让我出一个微博评论
今天它来了
一键获取微博的所有评论




公众号回复 微博 获取源代码
先看效果
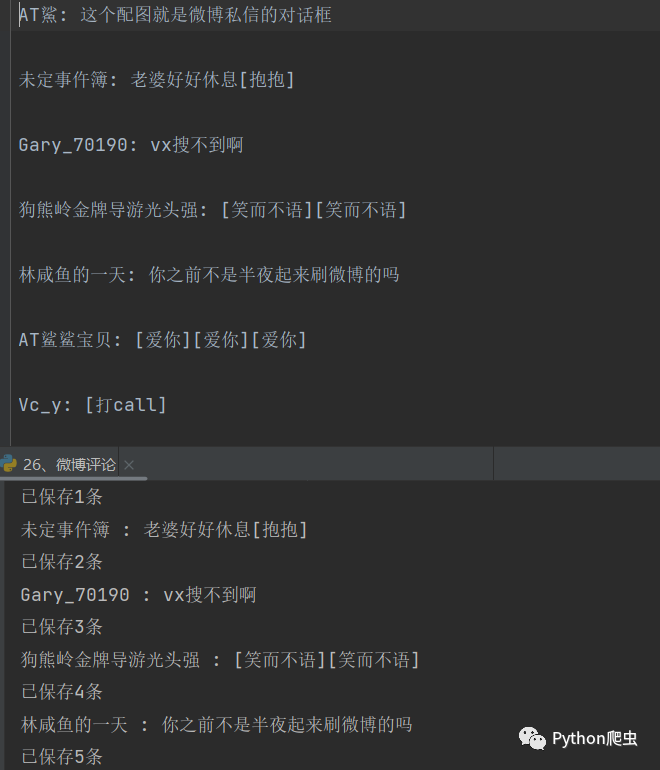
教程:
先打开微博
查看评论之后,一定要点击查看全部评论
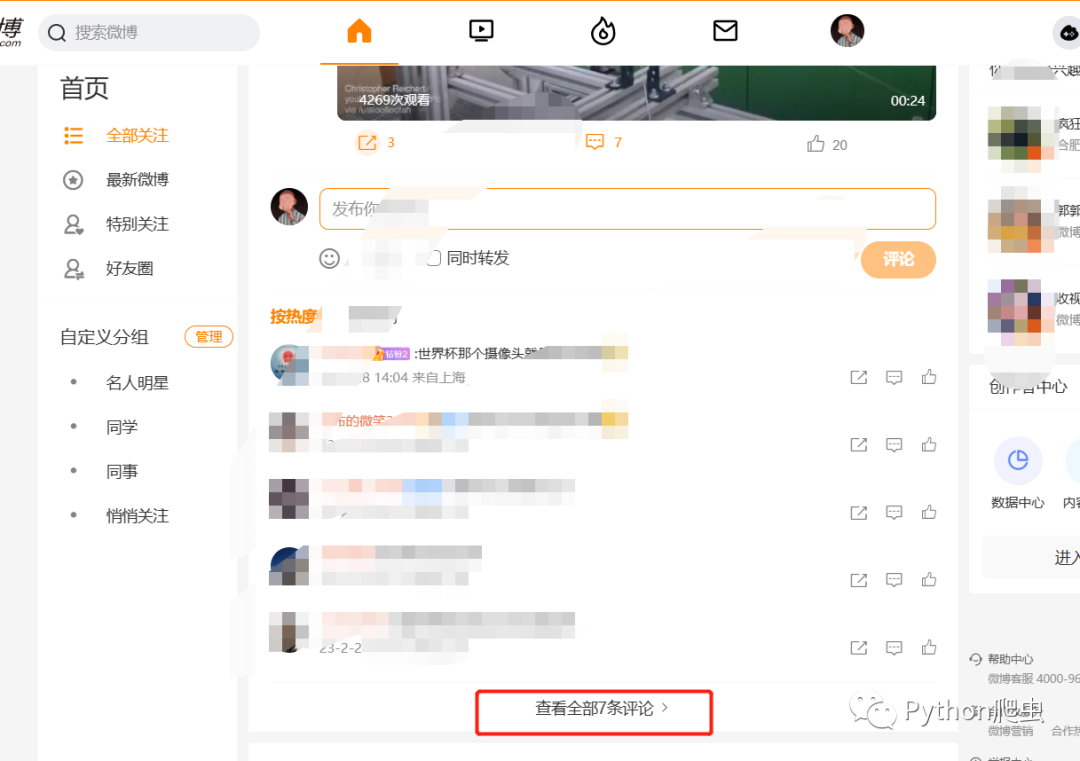
然后来到这个界面
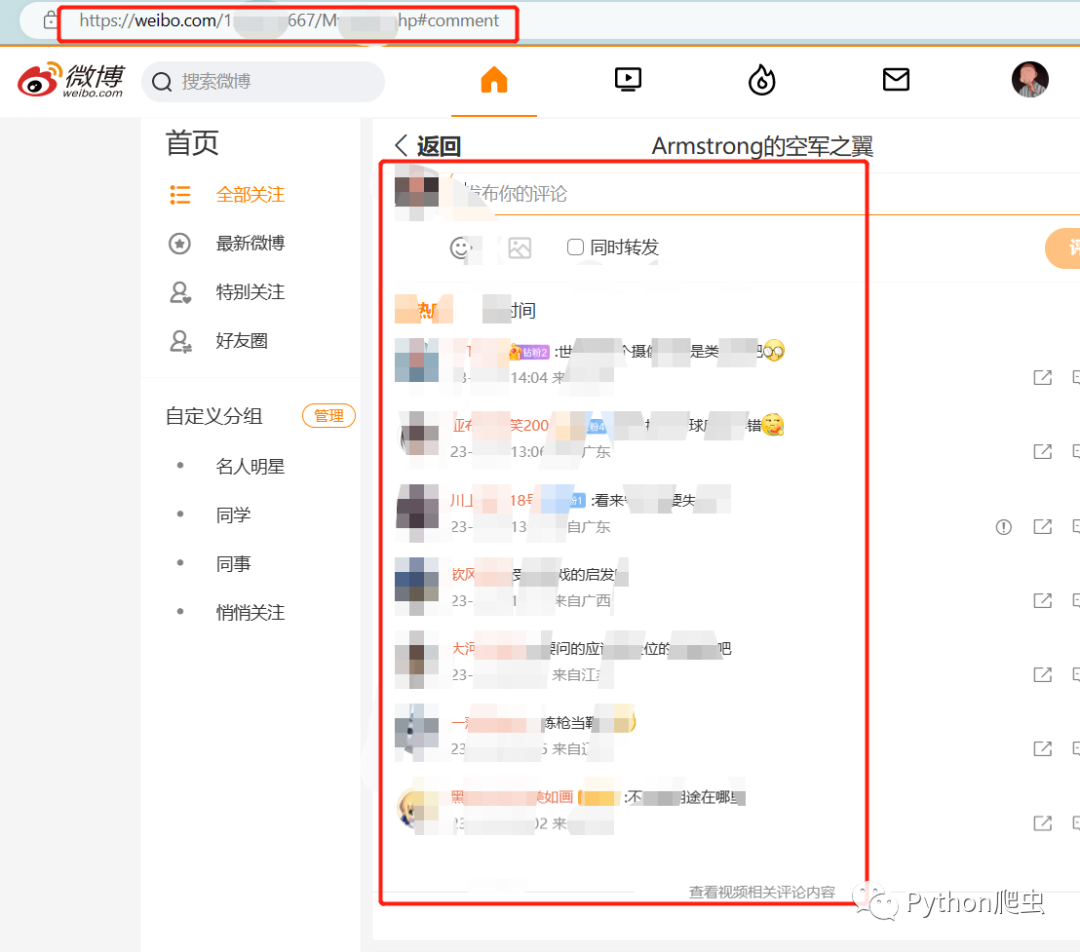
打开开发者模式
直接全局搜索评论的关键字
然后出来一个文件,这个文件就是存放评论的包
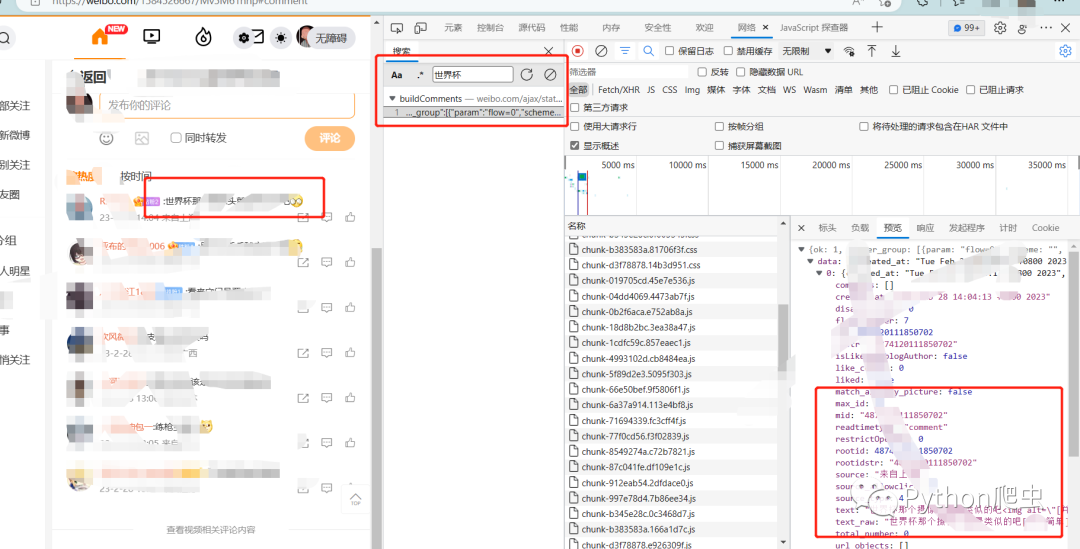
查看负载
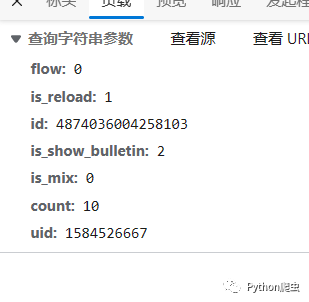
我们再打开另外一条评论数多的微博,然后看一下他们的负载参数
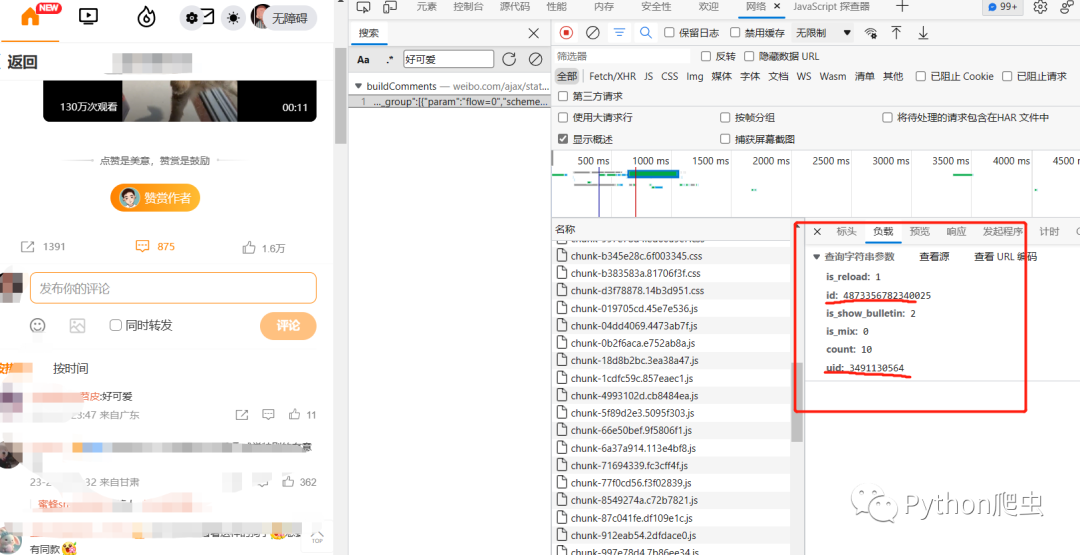
发现id和uid不一样
应该就是作者的id和作品id了
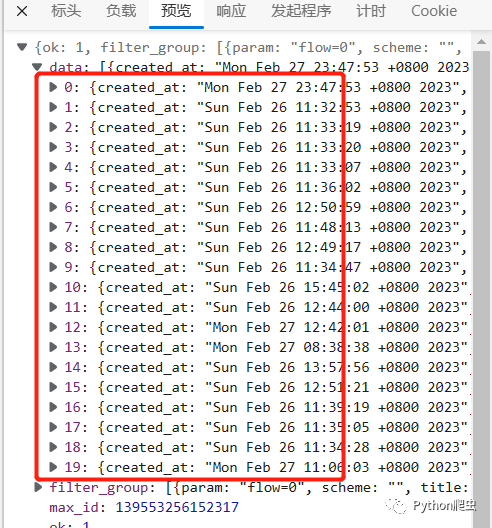
而且这一个文件里就存放了19条评论
这是因为浏览器页面没有滑到下面,没有加载后面的评论,
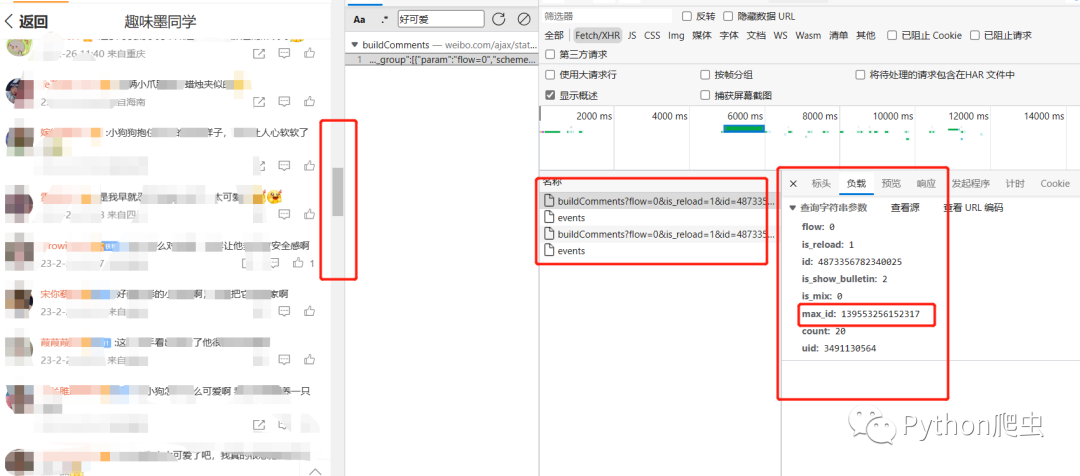
现在滑到下面,发现多了几个存放评论的文件,然后点进去,发现多了一个参数,max_id,这个参数应该就是控制评论的一个参数
经过观察发现
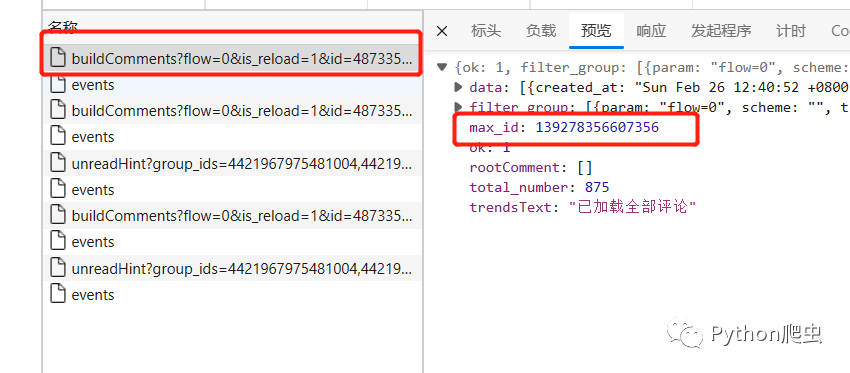
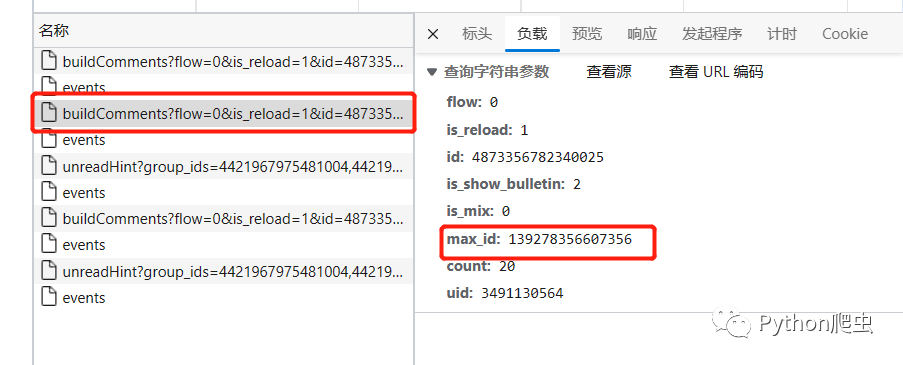
上一个文件的响应信息里的max_id就是下一个文件的max_id的负载参数
现在搞定了一个参数,还差id和uid
我们全局搜索一下id
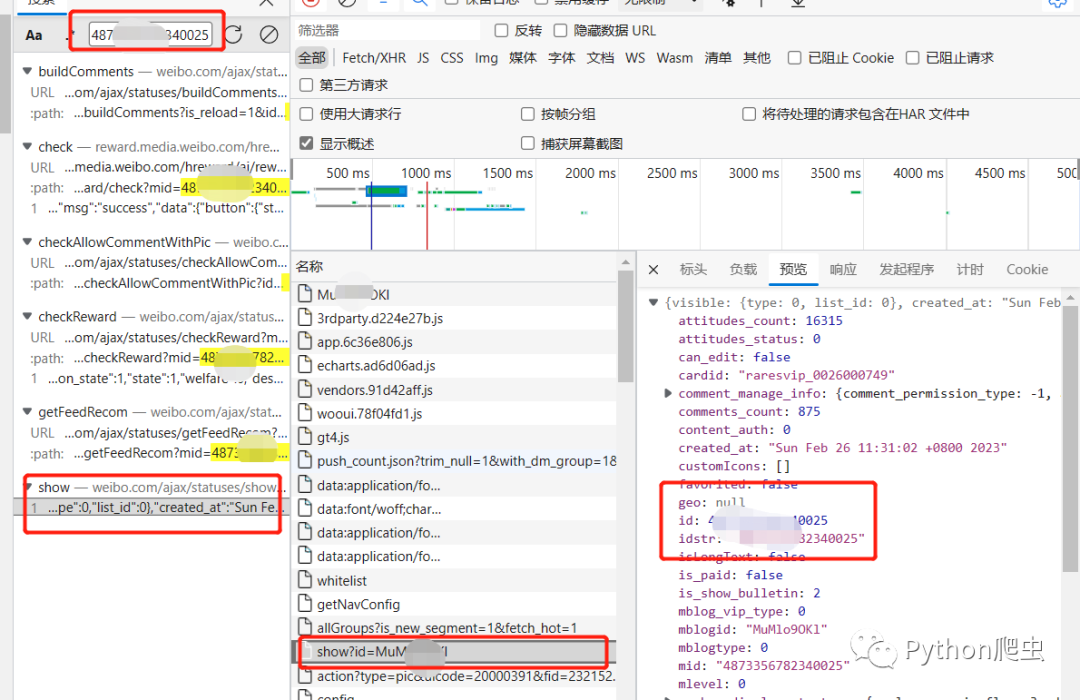
找到这个文件,里面存放着id和uid
现在就已经把所有不固定参数搞定了
接下来写代码的思路就是
1、先访问这个文件,获取id和uid
2、得到id和uid后,在访问评论文件,获取评论
开敲
这部分是第一步,访问获取id和uid
url = f'https://weibo.com/ajax/statuses/show?id={id}'
header = {
'user-agent':UserAgent().random
}
# 获取id和uid
res = requests.get(url=url,headers=header)
json_data = res.json()
id = json_data['id']
user_id = json_data['user']['idstr']然后开始访问存放评论的那个文件
因为第一个评论的文件是没有max_id那个参数的
所以写空
然后把max_id提取出来
把所有评论提取出来到一个列表
# 获取评论
max_id = ''
while max_id != 0:
pl_url = f'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id={id}&is_show_bulletin=2&is_mix=0&max_id={max_id}&count=10&uid={user_id}'
resp = requests.get(url=pl_url,headers=header)
json_data = resp.json()
max_id = json_data['max_id']
lis = json_data['data']
# print(len(lis))
p = 1然后for循环开始提取每一个评论
for li in lis:
user = li['user']['screen_name']
# text = li['text']
text_raw = li['text_raw']
print(user,':',text_raw)
f.write(user+': '+text_raw+'\n\n')
print(f'已保存{p}条')
p+=1然后还有保存

包装了一个函数
这里可以输入不同文章的链接的id来获取不同的评论

看效果:
公众号回复 微博 获取源代码
制作不易,欢迎分享,感谢观看