

问题描述:
通过Azkaban调Sqoop,将Mysql数据导入Hive,报Bad connect ack with firstBadLink as ×.×.×.×:50010(×.×.×.×为Hadoop集群其中一个DataNode的IP,我这里隐去了实际值)错误,如下:
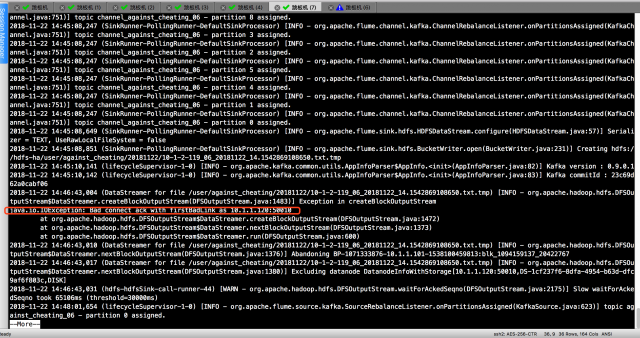
26-04-2023 19:17:52 PDT run_get_result_diff INFO - Diagnostic Messages for this Task:
26-04-2023 19:17:52 PDT run_get_result_diff INFO - Error: java.lang.RuntimeException: Hive Runtime Error while closing operators: java.io.IOException: Bad connect ack with firstBadLink as ×.×.×.×:50010
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.hive.ql.exec.mr.ExecReducer.close(ExecReducer.java:295)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.mapred.ReduceTask.runOldReducer(ReduceTask.java:453)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:392)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at java.security.AccessController.doPrivileged(Native Method)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at javax.security.auth.Subject.doAs(Subject.java:422)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: java.io.IOException: Bad connect ack with firstBadLink as ×.×.×.×:50010
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.hive.ql.exec.FileSinkOperator$FSPaths.closeWriters(FileSinkOperator.java:191)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.hive.ql.exec.FileSinkOperator.closeOp(FileSinkOperator.java:980)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:598)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:610)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:610)
26-04-2023 19:17:52 PDT run_get_result_diff INFO - at org.apache.hadoop.hive.ql.exec.mr.ExecReducer.close(ExecReducer.java:287)这个错误会一直重复报,大概五六次后,程序又可以正常跑完。
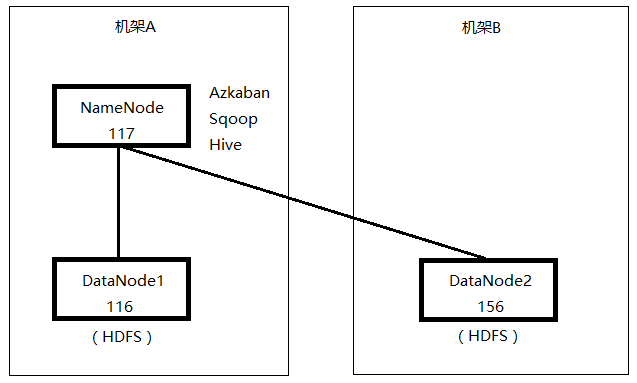
一个NameNode,两个DataNode。可以当做117和116在同一机架,156在另外机架。Azkaban、Sqoop和Hive都部署在NameNode。从报错信息来看,是DataNode2的50010端口不通。50010是DataNode服务端口,用于数据传输。
我先在NameNode上telnet DataNode2的50010端口,是通的。于是觉得奇怪,难道是网络不稳定?但是从telnet的数据来看,网络是稳定的。
后来去查看Sqoop导入到Hive的表对应的HDFS文件块信息,发现文件块只存放在NataNode1。(HDFS的文件副本数设置的是2)
最后发现,虽然NameNode和两台DataNode的50010端口都是通的,但是DataNode1到DataNode2的50010端口不通。将DataNode2的50010端口对DataNode1开放后,再执行Azkaban调度就不报错了。
思考:
NameNode和两台DataNode的50010端口都通,但两台NataNode之间的50010端口不通,为什么会报无法连接DataNode2的50010端口的错误,然后重复十多次之后,又会将数据写到DataNode1。
通常情况下,当启动一个容器用于处理HDFS数据块(为了在MapReduce中运行一个map任务)时,应用将会向这样的节点申请容器:存储该数据块副本的所有节点,或是存储这些副本的机架中的一个节点。如果都申请失败,则申请集群中的任意节点。
我猜测数据处理流程是这样的:
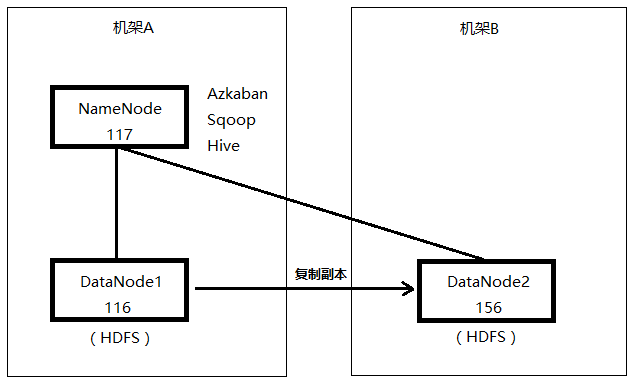
1、Sqoop程序在NameNode上启动后,先从其他源库获取到数据。
2、应用启动程序处理HDFS块,准备将数据写入HDFS。因为HDFS副本数设置的是2,现在只有DataNode1和DataNode2两个DataNode,所以应用会向这两个DataNode申请容器。由于NameNode和两个DataNode之间的网络端口都是通的,所以没有问题。
3、因为Sqoop程序运行在NameNode,而DataNode1和NameNode在同一机架,会优先将数据写入离客户端执行程序最近的DataNode的HDFS,所以数据先写入DataNode1,同时也会复制一份存放到DataNode2。
4、DataNode1通过访问DataNode2的50010端口来复制副本,但由于端口不通,所以会报错,但不是报错一次后就马上停止,而是会重复多次执行。
5、直到报错次数达到一定限制,确认DataNode1无法向DataNode2写数据,这时就不再向DataNode2复制副本,只在DataNode1存储数据。
6、数据同步完后,查看Hive表对应的HDFS文件块位置,只存放在NataNode1,没有存放在DataNode2。
7、在DataNode2开放50010端口给DataNode1访问后,再次同步数据,发现HDFS文件块在DataNode1和2都存在。
方法二:
百度了一下原因:
Datanode往hdfs上写时,实际上是通过使用xcievers这个中间服务往linux上的文件系统上写文件的。其实这个xcievers就是一些负责在DataNode和本地磁盘上读,写文件的线程。DataNode上Block越多,这个线程的数量就应该越多。然后问题来了,这个线程数有个上线(默认是配置的4096)。所以,当Datenode上的Block数量过多时,就会有些Block文件找不到。线程来负责他的读和写工作了。所以就出现了上面的错误(写块失败)。
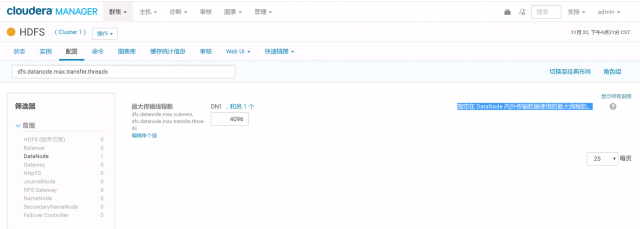
解决方案:
将DataNode 内外传输数据使用的最大线程数增大,比如:65535。
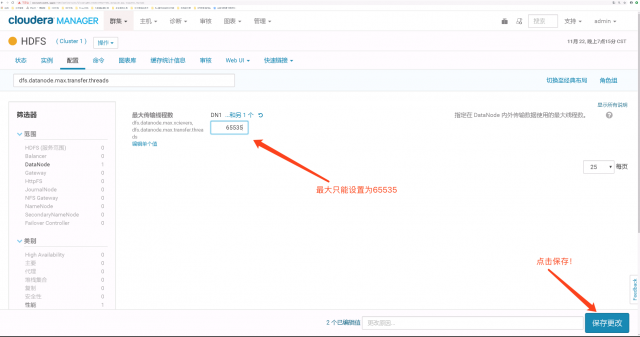
思考 :综合以上两种方式进行排查成功解决Bad connect ack with firstBadLink 报错
