
一、sqoop是什么
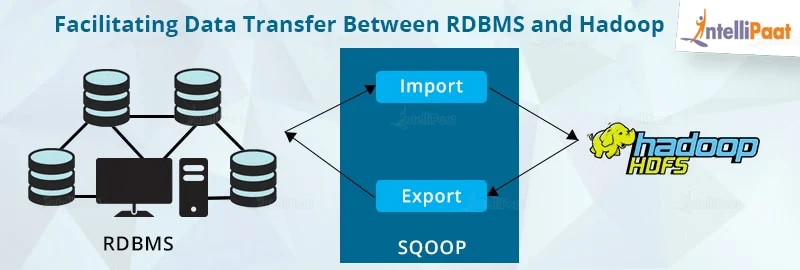
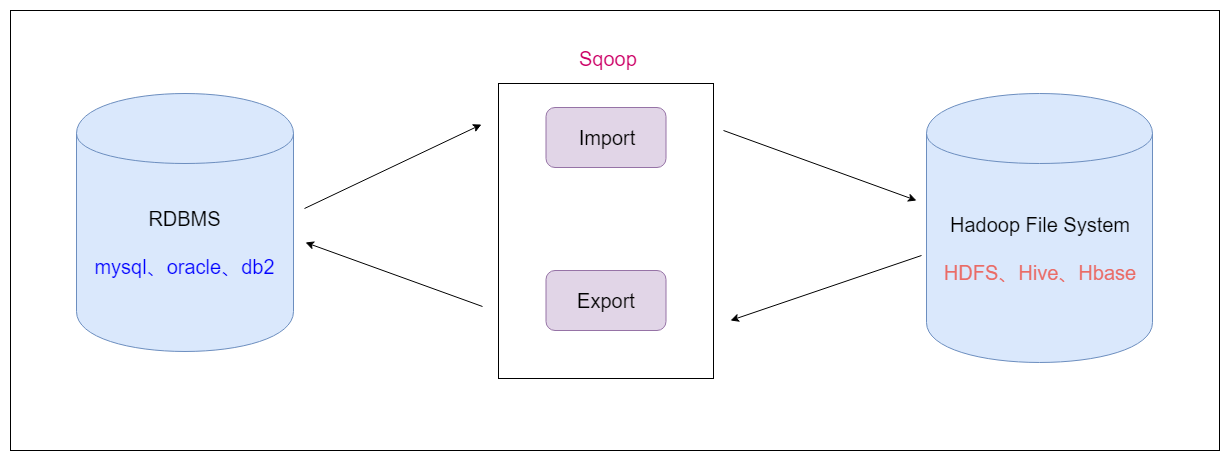
- Sqoop是apache旗下的一款 ”Hadoop和关系数据库之间传输数据”的工具
- 导入数据 import
- 将MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统
- 导出数据 export
- 从Hadoop的文件系统中导出数据到关系数据库
二、sqoop的工作机制
- 将导入和导出的命令翻译成mapreduce程序实现
- 在翻译出的mapreduce中主要是对inputformat和outputformat进行定制
三、sqoop的基本架构
- sqoop在发展中的过程中演进出来了两种不同的架构.架构演变史
- sqoop1的架构图(版本号为1.4.x0)
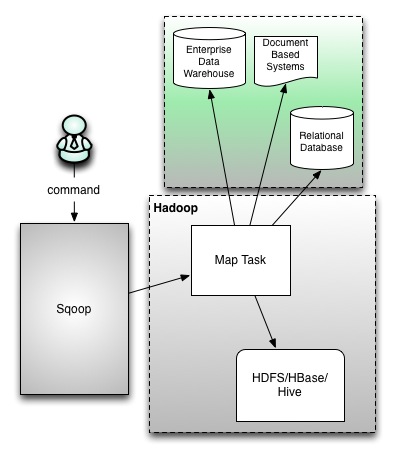
- sqoop2的架构图(版本号为1.99x为sqoop2 )
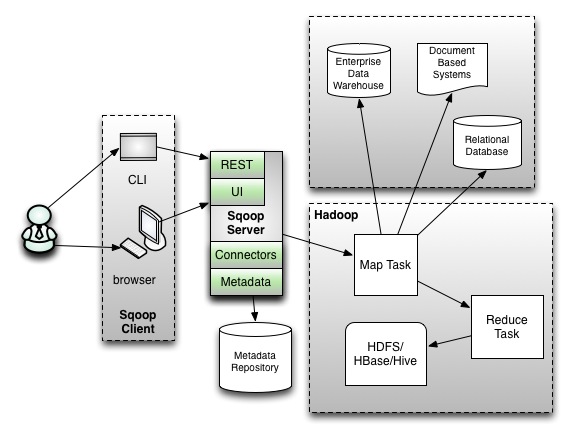
在架构上:sqoop2引入了sqoop server,对connector实现了集中的管理
访问方式:REST API、 JAVA API、 WEB UI以及CLI控制台方式进行访问
四、sqoop的安装部署
Sqoop安装很简单,解压好进行简单的修改就可以使用
- 1、下载安装包
- http://archive.cloudera.com/cdh5/cdh/5/sqoop-1.4.6-cdh5.14.2.tar.gz
- sqoop-1.4.6-cdh5.14.2.tar.gz
- 2、规划安装目录
- /kkb/install
- 3、上传安装包到服务器node03上
- sqoop就是一个工具,只需要安装一台就可以了,一般跟hive安装在同一台服务器上
- 4、解压安装包到指定的规划目录
- tar -zxvf sqoop-1.4.6-cdh5.14.2.tar.gz -C /kkb/install
- 5、修改配置
- 进入到sqoop安装目录下的conf文件夹中
- 先重命名文件
- mv sqoop-env-template.sh sqoop-env.sh
- 修改文件,添加java环境变量
- vim sqoop-env.sh
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2
#set the path to where bin/hbase is available
export HBASE_HOME=/kkb/install/hbase-1.2.0-cdh5.14.2
#Set the path to where bin/hive is available
export HIVE_HOME=/kkb/install/hive-1.1.0-cdh5.14.2- 6、添加mysql驱动jar包和json依赖包
- 把mysql的驱动jar包添加到sqoop的lib目录下
- 可以拷贝之前hive的lib目录下的mysql驱动
cp /kkb/install/hive-1.1.0-cdh5.14.2/lib/mysql-connector-java-5.1.38.jar /kkb/install/sqoop-1.4.6-cdh5.14.2/lib/- 把json依赖包添加到sqoop的lib目录下
- jar包在提供的资源目录中
- java-json.jar
- 7、配置sqoop环境变量
- vim /etc/profile
export SQOOP_HOME=/kkb/install/sqoop-1.4.6-cdh5.14.2
export PATH=:$SQOOP_HOME/bin:$PATH- 8、让sqoop环境变量生效
- source /etc/profile
五、sqoop数据的导入
导入单个表从RDBMS到HDFS。表中的每一行被视为HDFS的记录。所有记录都存储为文本文件的文本数据(或者Avro、sequence文件等二进制数据)
5.1 列举出所有的数据库
- 命令行查看帮助文档
sqoop list-databases --help- 列出node03上mysql数据库中所有的数据库名称
sqoop list-databases --connect jdbc:mysql://node03:3306/ --username root --password 123456- 查看某一个数据库下面的所有数据表
sqoop list-tables --connect jdbc:mysql://node03:3306/hive --username root --password 123456- emp建表语句
CREATE DATABASE `userdb`
USE `userdb`;
/*Table structure for table `emp` */
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`id` int(11) NOT NULL,
`name` varchar(20) DEFAULT NULL,
`deg` varchar(20) DEFAULT NULL,
`salary` double DEFAULT NULL,
`dept` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `emp` */
insert into `emp`(`id`,`name`,`deg`,`salary`,`dept`) values
(1201,'gopal','manager',50000,'TP'),
(1202,'manisha','Proof reader',50000,'TP'),
(1203,'khalil','php dev',30000,'AC'),
(1204,'prasanth','php dev',20000,'AC'),
(1205,'kranthi','admin',10000,'TP'),
(1206,'tom','admin',50000,'TP');
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for emp
-- ----------------------------
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`id` int(11) NOT NULL,
`name` varchar(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL,
`deg` varchar(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL,
`salary` double(255, 2) NULL DEFAULT NULL,
`dept` varchar(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of emp
-- ----------------------------
INSERT INTO `emp` VALUES (1201, 'gopal', 'manager', 50000.00, 'Tp');
INSERT INTO `emp` VALUES (1202, 'manisha', 'Proof', 50000.00, 'TP');
INSERT INTO `emp` VALUES (1203, 'khalil', 'php', 30000.00, 'AC');
INSERT INTO `emp` VALUES (1204, 'prasanth', 'php', 20000.00, 'AC');
INSERT INTO `emp` VALUES (1205, 'kranthi', 'admin', 10000.00, 'TP');
INSERT INTO `emp` VALUES (1206, 'tom', 'admin', 50000.00, 'TP');
INSERT INTO `emp` VALUES (1207, 'job', 'proof', 40000.00, 'AC');
-- ----------------------------
-- Table structure for fromhdfs
-- ----------------------------
DROP TABLE IF EXISTS `fromhdfs`;
CREATE TABLE `fromhdfs` (
`id` int(11) NULL DEFAULT NULL,
`name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`age` int(11) NULL DEFAULT NULL,
`address` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of fromhdfs
-- ----------------------------
INSERT INTO `fromhdfs` VALUES (1, 'zhangsan', 20, 'hubei');
INSERT INTO `fromhdfs` VALUES (2, 'lisi', 30, 'hunan');
INSERT INTO `fromhdfs` VALUES (3, 'wangwu', 40, 'beijing');
INSERT INTO `fromhdfs` VALUES (4, 'xiaoming', 50, 'shanghai');
-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL,
`createTime` datetime(0) NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP(0),
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 11 CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (1, 'lisi', '2019-11-19 16:29:15');
INSERT INTO `user` VALUES (2, 'wangwu', '2019-11-19 16:30:24');
INSERT INTO `user` VALUES (3, 'zhangsan', '2019-11-19 16:30:36');
INSERT INTO `user` VALUES (4, 'tom', '2019-11-19 16:31:00');
INSERT INTO `user` VALUES (5, 'jerry', '2019-11-19 16:31:11');
INSERT INTO `user` VALUES (6, 'lan', '2019-11-19 16:31:25');
INSERT INTO `user` VALUES (7, 'belli', '2019-11-19 16:31:28');
INSERT INTO `user` VALUES (8, 'kkb', '2019-11-19 16:40:21');
INSERT INTO `user` VALUES (9, '007', '2019-11-19 16:43:58');
INSERT INTO `user` VALUES (10, 'a', '2019-11-25 21:16:12');
SET FOREIGN_KEY_CHECKS = 1;5.2 导入数据库表数据到HDFS
- 在MySQL数据库服务器中创建一个数据库userdb, 然后在创建一张表 emp,添加点测试数据到表中
- 从MySQL数据库服务器中的userdb数据库下的emp表导入HDFS上
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp \
--m 1
#参数解释
--connect 指定mysql链接地址
--username 连接mysql的用户名
--password 连接mysql的密码
--table 指定要导入的mysql表名称
--m: 表示这个MR程序需要多少个MapTask去运行,默认为4
默认路径是/user/hadoop下- 提交之后,会运行一个MR程序,最后查看HDFS上的目录看是否有数据生成
5.3 导入数据库表数据到HDFS指定目录
- 在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。
- 使用参数 --target-dir来指定导出目的地,
- 使用参数--delete-target-dir来判断导出目录是否存在,如果存在就删掉
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp --target-dir /sqoop/emp --delete-target-dir --m 1- 提交查看HDFS上的目录看是否有数据生成
5.4 导入数据库表数据到HDFS指定目录并且指定数据字段的分隔符
- 这里使用参数
- --fields-terminated-by 分隔符
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--delete-target-dir \
--table emp \
--target-dir /sqoop/emp1 \
--fields-terminated-by '#' \
--m 1- 提交查看HDFS上的目录看是否有数据生成
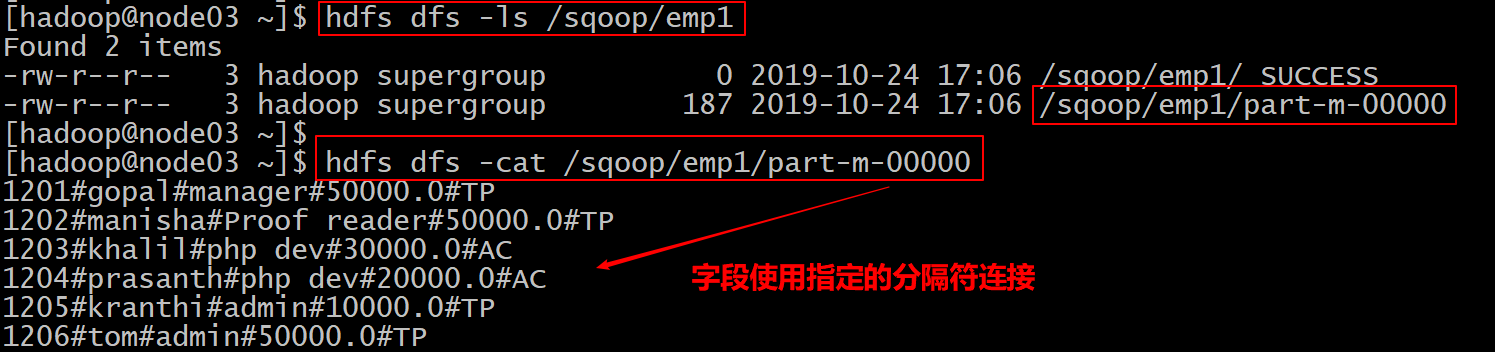
5.5 导入关系表到Hive中
- (1) 将我们mysql表当中的数据直接导入到hive表中的话,需要将hive的一个叫做==hive-exec-1.1.0-cdh5.14.2.jar==包拷贝到sqoop的lib目录下
cp /kkb/install/hive-1.1.0-cdh5.14.2/lib/hive-exec-1.1.0-cdh5.14.2.jar /kkb/install/sqoop-1.4.6-cdh5.14.2/lib/- (2) 准备hive数据库与表
- 在hive中创建一个数据库和表
create database sqooptohive;
create external table sqooptohive.emp_hive(id int,name string,deg string,salary double ,dept string) row format delimited fields terminated by '\001';- (3) 把mysql表数据导入到hive表中
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp \
--fields-terminated-by '\001' \
--hive-import \
--hive-table sqooptohive.emp_hive \
--hive-overwrite \
--delete-target-dir \
--m 1
##参数解释
--hive-table 指定要导入到hive表名
--hive-import 导入数据到hive表中
--hive-overwrite 覆盖hive表中已存有的数据分为两步
- (4) 执行完成了查看hive中表的数据
- select * from sqooptohive.emp_hive;

5.6 导入数据库表数据到hive中(并自动创建hive表)
- 可以通过命令来将我们的mysql的表直接导入到hive表当中去,不需要事先创建hive表
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp \
--hive-database sqooptohive \
--hive-table emp1 \
--hive-import \
--m 1
drop table emp1- 执行完成了查看hive中表的数据
- select * from sqooptohive.emp1;
5.7 导入表数据子集
- 我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
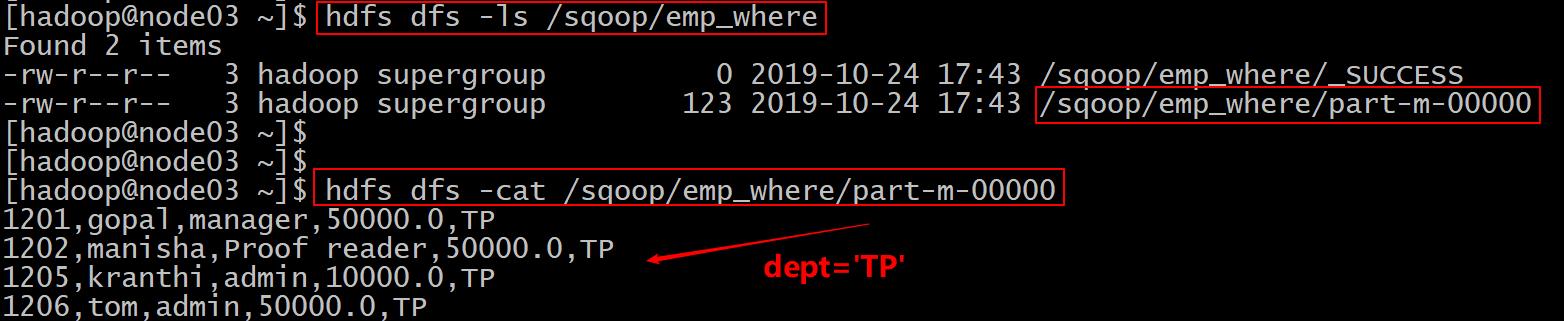
- 按照条件进行查找,通过--where参数来查找表emp当中dept字段的值为 TP的所有数据导入到hdfs上面去
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp \
--target-dir /sqoop/emp_where \
--delete-target-dir \
--where "dept = 'TP'" \
--m 1- 提交查看HDFS上的目录看是否有数据生成
5.8 sql语句查找导入hdfs
- 我们还可以通过 -–query参数来指定我们的sql语句,通过sql语句来过滤我们的数据进行导入
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--target-dir /sqoop/emp_sql \
--delete-target-dir \
--query 'select * from emp where salary >30000 and $CONDITIONS' \
--m 1- 提交查看HDFS上的目录看是否有数据生成

- 补充
$CONTITONS是linux系统的变量,如果你想通过并行的方式导入结果,每个map task需要执行sql查询后脚语句的副本,结果会根据sqoop推测的边界条件分区。query必须包含$CONDITIONS。这样每个sqoop程序都会被替换为一个独立的条件。同时你必须指定 --split-by '字段',后期是按照字段进行数据划分,最后可以达到多个MapTask并行运行。
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--target-dir /sqoop/emp_sql_2 \
--delete-target-dir \
--query 'select * from emp where salary >30000 and $CONDITIONS' \
--split-by 'id' \
--m 2
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--target-dir /sqoop/emp_sql_2 \
--delete-target-dir \
--query 'select * from emp where id >1 and $CONDITIONS' \
--split-by 'salary' \
--m 2
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--target-dir /sqoop/emp_sql_2 \
--delete-target-dir \
--query 'select * from emp where id >1 and $CONDITIONS' \
--split-by 'id' \
--m 7
--split-by '字段': 后期按照字段进行数据划分实现并行运行多个MapTask。5.9 增量导入
- 在实际工作当中,数据的导入很多时候都是==只需要导入增量数据即可==,并不需要将表中的数据全部导入到hive或者hdfs当中去,肯定会出现重复的数据的状况,所以我们一般都是选用一些字段进行增量的导入,为了支持增量的导入,sqoop也给我们考虑到了这种情况并且支持增量的导入数据
- 增量导入是仅导入新添加的表中的行的技术。
- 它需要添加 ‘incremental’, ‘check-column’, 和 ‘last-value’选项来执行增量导入。
--incremental <mode>
--check-column <column name>
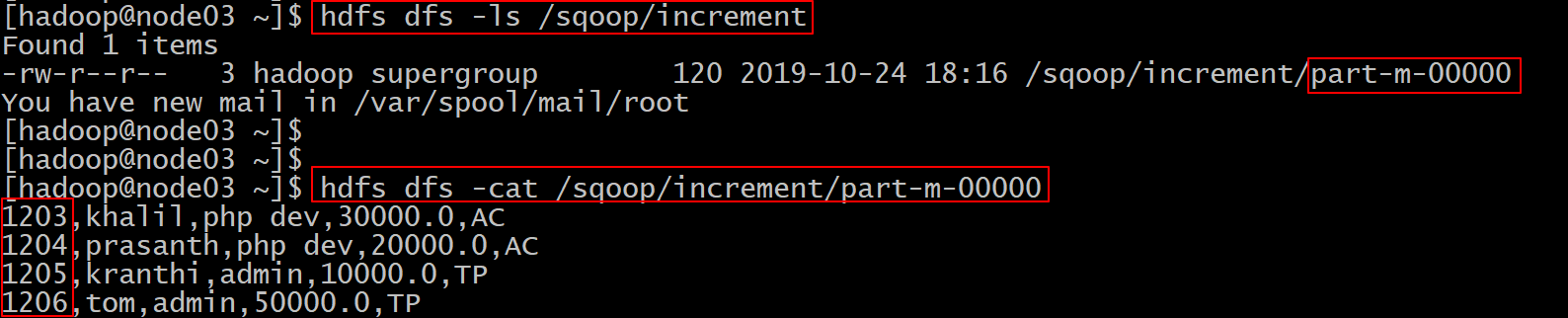
--last value <last check column value>- 第一种增量导入实现
- 基于递增列的增量数据导入(Append方式)
- 导入emp表当中id大于1202的所有数据
- 注意:这里不能加上 --delete-target-dir 参数,添加就报错
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp \
--incremental append \
--check-column id \
--last-value 1202 \
--target-dir /sqoop/increment \
--m 1
##参数解释
--incremental 这里使用基于递增列的增量数据导入
--check-column 递增列字段
--last-value 指定上一次导入中检查列指定字段最大值
--target-dir 数据导入的目录- 提交查看HDFS上的目录看是否有数据生成
- 第二种增量导入实现
- 基于时间列的增量数据导入(LastModified方式)
- 此方式要求原有表中有time字段,它能指定一个时间戳
- user表结构和数据

sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table user \
--incremental lastmodified \
--check-column createTime \
--last-value '2019-10-01 10:30:00' \
--target-dir /sqoop/increment2 \
--m 1
##参数解释
--incremental 这里使用基于时间列的增量导入
--check-column 时间字段
--last-value 指定上一次导入中检查列指定字段最大值
--target-dir 数据导入的目录
如果该目录存在(可能已经有数据)
再使用的时候需要添加 --merge-key or --append
--merge-key 指定合并key(对于有修改的)
--append 直接追加修改的数据- 提交查看HDFS上的目录看是否有数据生成

5.10 mysql表的数据导入到hbase中
- 实现把一张mysql表数据导入到hbase中
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp \
--hbase-table mysqluser \
--column-family f1 \
--hbase-create-table \
--hbase-row-key id \
--m 1
#参数说明
--hbase-table 指定hbase表名
--column-family 指定表的列族
--hbase-create-table 表不存在就创建
--hbase-row-key 指定hbase表的id
--m 指定使用的MapTask个数
list
scan 'mysqluser'
disable 'mysqluser'
drop 'mysqluser'
# mysql导入hbase 不同的列族
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--columns id,salary,dept \
--table emp \
--hbase-table mysqluser2 \
--column-family f1 \
--hbase-create-table \
--hbase-row-key id \
--m 1
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--columns id,name,deg \
--table emp \
--hbase-table mysqluser2 \
--column-family f2 \
--hbase-create-table \
--hbase-row-key id \
--m 1六、sqoop数据导出
- 将数据从HDFS把文件导出到RDBMS数据库
- 导出前,目标表必须存在于目标数据库中。
- 默认操作是从将文件中的数据使用INSERT语句插入到表中
- 更新模式下,是生成UPDATE语句更新表数据
6.1 hdfs文件导出到mysql表中
- 1、数据是在HDFS当中的如下目录/user/hive/warehouse/hive_source,数据内容如下
1 zhangsan 20 hubei
2 lisi 30 hunan
3 wangwu 40 beijing
4 xiaoming 50 shanghai- 2、创建一张mysql表
- 注意mysql中的这个表一定要先创建! 不然报错!
CREATE TABLE userdb.fromhdfs (
id INT DEFAULT NULL,
name VARCHAR(100) DEFAULT NULL,
age int DEFAULT NULL,
address VARCHAR(100) DEFAULT NULL
) ENGINE=INNODB DEFAULT CHARSET=utf8;- 3、执行导出命令
sqoop export \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table fromhdfs \
--export-dir /user/hive/warehouse/hive_source \
--input-fields-terminated-by " "
##参数解释
--table 指定导出的mysql表名
--export-dir 指定hdfs数据文件目录
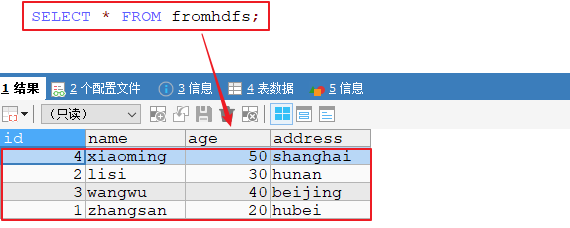
--input-fields-terminated-by 指定文件数据字段的分隔符- 4、验证mysql表数据
七、sqoop作业
- 将事先定义好的数据导入导出任务按照指定流程运行
- 语法
sqoop job (generic-args) (job-args)
[-- [subtool-name] (subtool-args)]7.1 创建作业
- --create
- 创建一个名为myjob,实现从mysql表数据导入到hdfs上的作业
- 注意
- 在创建job时,命令"-- import" 中间有个空格
sqoop job --help
##创建一个sqoop作业
sqoop job \
--create myjob1 \
-- import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp \
--target-dir /sqoop/myjob \
--delete-target-dir \
--m 1
##创建一个sqoop增量导入的作业
sqoop job \
--create incrementJob1 \
-- import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table user \
--target-dir /sqoop/incrementJob \
--incremental append \
--check-column createTime \
--last-value '2019-11-19 16:40:21' \
--m 1
# incremental.last.value7.2 验证作业
- --list
- 验证作业是否创建成功
- 执行如下命令
sqoop job --list
最后显示:
Available jobs:
myjob7.3 查看作业
- --show
- 查看作业的详细信息
- 执行如下命令
sqoop job --show myjob17.4 执行作业
- --exec
- 用于执行保存的作业
sqoop job --exec myjob1- 解决sqoop需要输入密码的问题
- 修改配置文件
- vi /kkb/install/sqoop-1.4.6-cdh5.14.2/conf/sqoop-site.xml
<property>
<name>sqoop.metastore.client.record.password</name>
<value>true</value>
<description>If true, allow saved passwords in the metastore.
</description>
</property>7.5 删除作业
- --delete
- 用于删除保存作业
sqoop job --delete myjob八、经验总结
Sqoop并行化是启多个map task实现的,-m(或--num-mappers)参数指定map task数,默认是四个。并行度不是设置的越大越好,map task的启动和销毁都会消耗资源,而且过多的数据库连接对数据库本身也会造成压力。在并行操作里,首先要解决输入数据是以什么方式负债均衡到多个map的,即怎么保证每个map处理的数据量大致相同且数据不重复。--split-by指定了split column,在执行并行操作时(多个map task),Sqoop需要知道以什么列split数据,其思想是:
1、先查出split column的最小值和最大值
2、然后根据map task数对(max-min)之间的数据进行均匀的范围切分
例如id作为split column,其最小值是0、最大值1000,如果设置4个map数,每个map task执行的查询语句类似于:SELECT * FROM sometable WHERE id >= lo AND id < hi,每个task里(lo,hi)的值分别是 (0, 250), (250, 500), (500, 750), and (750, 1001)。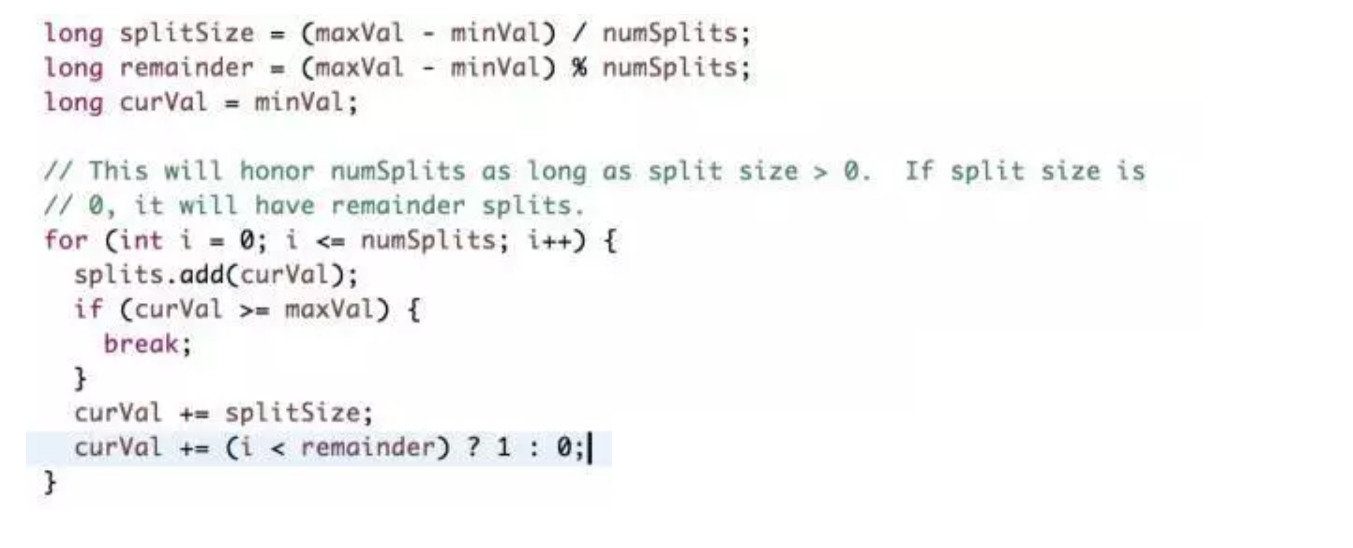
Sqoop不能在多列字段上进行拆分,如果没有索引或者有组合键,必须显示设置splitting column;默认的主键作为split column,如果表里没有主键或者没有指定--split-by,就要设置num-mappers 1或者--autoreset-to-one-mapper,这样就只会启动一个task。
从上面的分析过程可以看到Sqoop以理想化方式根据split column将数据切分成多个范围,如果split键的值不是均匀分布,每个任务分配的数据量可能相差很大、导致数据倾斜。