
一张图生成一个视频 大模型公开
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
为任何人制作动画:用于角色动画的一致且可控的图像到视频合成;
论文地址:https://arxiv.org/pdf/2311.17117.pdf
项目地址:https://github.com/HumanAIGC/AnimateAnyone
官网:https://humanaigc.github.io/animate-anyone/
论文总结
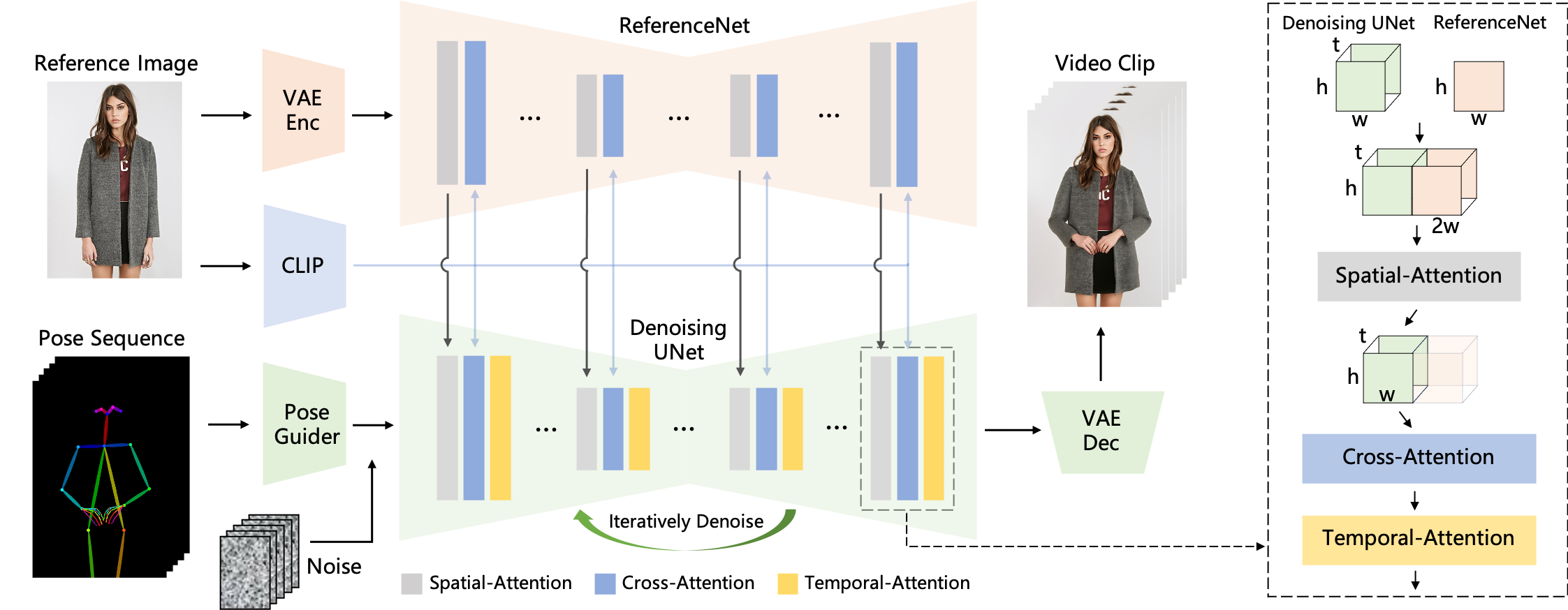
这篇论文的第一部分介绍了一个用于角色动画的图像到视频合成的新方法,称为Animate Anyone。该方法的主要贡献有以下几点:
- ReferenceNet:一个用于提取参考图像中角色的细节特征的网络,通过空间注意力机制将这些特征融合到去噪UNet中,从而保持角色外观的一致性。
- Pose Guider:一个用于编码姿态控制信号的轻量级模块,通过与噪声潜在特征相加的方式将姿态信息注入到去噪过程中,从而实现角色运动的可控性。
- Temporal Layer:一个用于建模多帧之间的时序关系的层,通过时序注意力机制保证角色运动的连续性和平滑性。
- Two-stage Training Strategy:一个分为两个阶段的训练策略,第一阶段使用单帧图像训练去噪UNet,ReferenceNet和Pose Guider,第二阶段引入Temporal Layer并只训练该层。
该方法在两个具体的人类视频合成的基准数据集上进行了评估,分别是UBC fashion video dataset和TikTok dataset,并与其他图像动画的方法进行了定量和定性的比较,展示了其在角色动画方面的优越性能和泛化能力。
欢迎关注公-众-号【TaonyDaily】、留言、评论,一起学习。
Don’t reinvent the wheel, library code is there to help.
文章来源:刘俊涛的博客
若有帮助到您,欢迎点赞、转发、支持,您的支持是对我坚持最好的肯定(^_^)