
3D-LLM: Injecting the 3D World into Large Language Models
3D-LLM:将 3D 世界注入大型语言模型
摘要
大语言模型 (LLM) 和视觉语言模型 (VLM) 已被证明在多项任务上表现出色,例如常识推理。尽管这些模型非常强大,但它们并不以 3D 物理世界为基础,而 3D 物理世界涉及更丰富的概念,例如空间关系、可供性、物理、布局等。在这项工作中,我们建议将 3D 世界注入大型语言模型中,并引入全新的 3D-LLM 系列。具体来说,3D-LLM 可以将 3D 点云及其特征作为输入,并执行一系列与 3D 相关的任务,包括字幕、密集字幕、3D 问答、任务分解、3D 基础、3D 辅助对话、导航和很快。使用我们设计的三种类型的提示机制,我们能够收集超过 30 万个涵盖这些任务的 3D 语言数据。为了有效地训练 3D-LLM,我们首先利用 3D 特征提取器从渲染的多视图图像中获取 3D 特征。然后,我们使用 2D VLM 作为骨干来训练 3D-LLM。通过引入 3D 定位机制,3D-LLM 可以更好地捕获 3D 空间信息。 ScanQA 上的实验表明,我们的模型大幅优于最先进的基线(例如,BLEU-1 分数超过最先进的分数 9%)。此外,对我们保留的 3D 字幕、任务组合和 3D 辅助对话数据集进行的实验表明,我们的模型优于 2D VLM。定性示例还表明,我们的模型可以执行超出现有 LLM 和 VLM 范围的更多任务。项目页面::https://vis-www.cs.umass.edu/3dllm/。
1 简介
在过去的几年中,我们目睹了大型语言模型(LLM)(例如 GPT4 [33])的激增,它们擅长多种任务,例如通信和常识推理。最近的工作探索了将图像和视频与LLM结合起来,以形成新一代多模态LLMs(例如,Flamingo [14]、BLIP-2 [30]),使LLM能够理解和推理 2D 图像。然而,尽管这些模型在通信和推理方面非常强大,但它们并不以真实的 3D 物理世界为基础,而真实的 3D 物理世界涉及更丰富的概念,例如空间关系、可供性、物理和交互等。因此,这样的LLM与科幻电影中描绘的机器人相比显得苍白无力——机器人是能够理解3D环境,并根据3D理解进行推理和规划的助手。
为此,我们建议将 3D 世界注入大型语言模型中,并引入全新的 3D-LLM 系列,它们可以将 3D 表示(即具有其特征的 3D 点云)作为输入,并执行一系列 3D 模型。相关任务。通过将场景的 3D 表示作为输入,LLM 具有双重优势:(1) 关于整个场景的长期记忆可以存储在整体 3D 表示中,而不是片段的部分视图观察中。 (2) 3D 属性(例如可供性和空间关系)可以从 3D 表示中推理出来,远远超出基于语言或基于 2D 图像的LLM的范围。
训练拟议的 3D-LLM 的一大挑战在于数据采集。与互联网上大量成对的 2D 图像和文本数据不同,3D 数据的稀缺阻碍了基于 3D 基础模型的开发。与语言描述配对的 3D 数据更难获得。为了解决这个问题,我们提出了一组独特的数据生成管道,可以生成与语言配对的大规模 3D 数据。具体来说,我们利用 ChatGPT [33] 设计了三种有效的提示程序用于 3D 数据和语言之间的通信。通过这种方式,我们能够获得涵盖各种任务的 30 万个 3D 语言数据,包括但不限于 3D 字幕、密集字幕、3D 问答、3D 任务分解、3D 基础、3D 辅助对话、导航和依此类推,如图1所示。
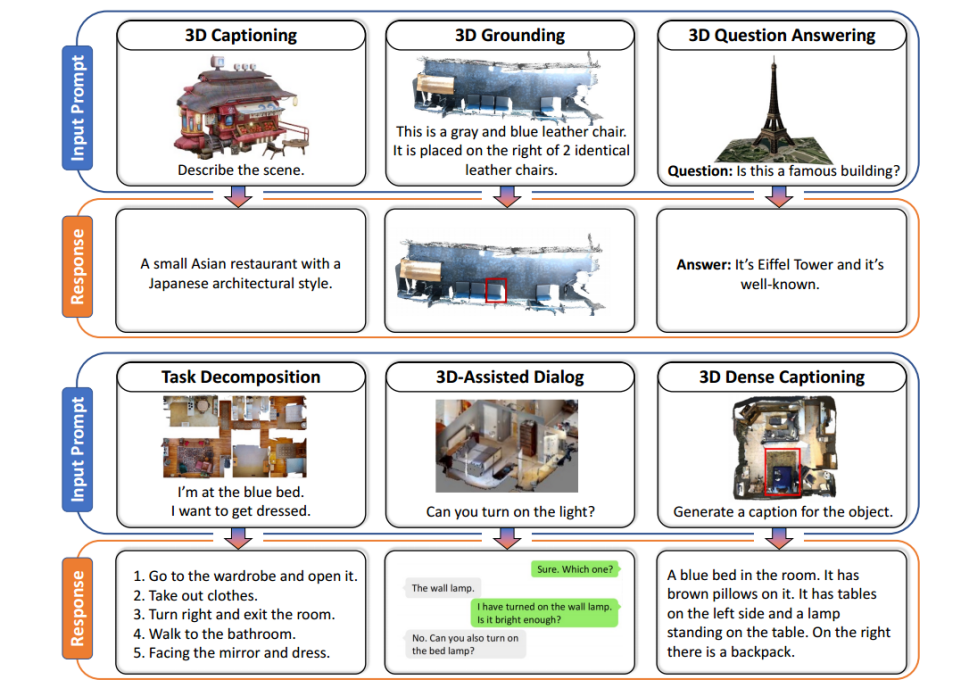
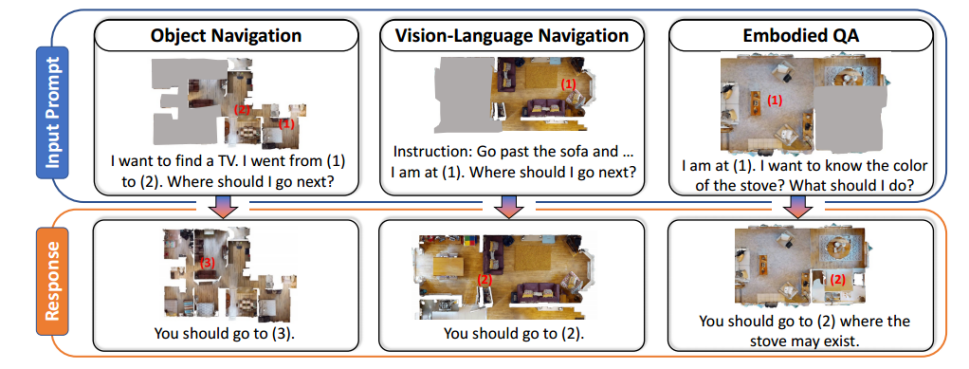
图 1:我们生成的 3D 语言数据的示例,涵盖多个 3D 相关任务。
下一个挑战在于如何获得有意义的 3D 特征,这些特征可以与 3D-LLM 的语言特征相一致。一种方法是使用类似的对比学习范式从头开始训练 3D 编码器,以实现 2D 图像和语言之间的对齐(例如 CLIP [37])。然而,这种范例会消耗大量的数据、时间和 GPU 资源。从另一个角度来看,最近有许多从 2D 多视图图像构建 3D 特征的工作(例如概念融合 [26]、3D-CLR [20])。受此启发,我们还利用 3D 特征提取器,从渲染的多视图图像的 2D 预训练特征构建 3D 特征。最近,也有不少视觉语言模型(例如 BLIP-2 [30]、Flamingo [14])利用 2D 预训练 CLIP 特征来训练其 VLM。由于我们提取的 3D 特征映射到与 2D 预训练特征相同的特征空间,因此我们可以无缝地使用 2D VLM 作为主干,并输入 3D 特征以高效训练 3D-LLM。
3D-LLM 与普通 LLM 和 2D VLM 不同的一个重要方面是,3D-LLM 预计具有潜在的 3D 空间信息感。因此,我们开发了一种 3D 定位机制,弥合了语言和空间位置之间的差距。具体来说,我们将 3D 位置嵌入附加到提取的 3D 特征中,以更好地编码空间信息。此外,我们将一系列位置标记附加到 3D-LLM,并且可以通过根据场景中特定对象的语言描述输出位置标记来训练定位。通过这种方式,3D-LLM 可以更好地捕获 3D 空间信息。
综上所述,我们的论文有以下贡献:
•我们引入了一系列新的基于 3D 的大型语言模型(3D-LLM),它可以将具有特征和语言提示的 3D 点作为输入,并执行各种 3D 相关的操作。任务。我们专注于普通LLM或 2D-LLM 范围之外的任务,例如有关整体场景理解、3D 空间关系、可供性和 3D 规划的任务。
•我们设计了新颖的数据收集管道,可以生成大规模3D语言数据。基于管道,我们收集了一个包含超过 30 万个 3D 语言数据的数据集,涵盖了各种 3D 相关任务,包括但不限于 3D 字幕、密集字幕、3D 问答、任务分解、3D 基础、3D - 辅助对话、导航等。
•我们使用3D 特征提取器从渲染的多视图图像中提取有意义的3D 特征。我们利用 2D 预训练 VLM 作为高效训练的支柱。我们引入了 3D 定位机制来训练 3D-LLM 以更好地捕获 3D 空间信息。
• 在保留的评估数据集ScanQA 上进行的实验优于最先进的基线。特别是,3D LLM 在 ScanQA 上的表现大幅优于基线(例如,BLEU-1 为 9%)。对 3D 字幕、任务组合和 3D 辅助对话的保留数据集进行的实验表明,我们的模型优于 2D VLM。定性研究进一步证明我们的模型能够处理多种任务。
•我们计划发布我们的3D-LLM、3D 语言数据集以及数据集的语言对齐3D 功能,以供未来的研究开发。
2 相关著作
大型语言模型。我们的工作与大型语言模型[4,13,38,9,34](LLM)密切相关,例如GPT-3 [4]和PaLM [9],它们能够使用单个模型处理不同的语言任务并显示较强的泛化能力。这些模型通常在大量文本数据上进行训练,并具有自我监督的训练目标,例如预测下一个标记 [4, 38] 或重建屏蔽标记 [13, 39]。为了更好地将这些 LLM 的预测与人类指令保持一致,提高模型对未见过的任务的泛化能力,人们提出了一系列指令调整方法 [35, 44] 和数据集 [10, 12]。在这项工作中,我们的目标是将 3D 世界注入大型语言模型中,理解丰富的 3D 概念,例如空间关系、可供性和物理。
视觉语言预训练模型。我们的工作还涉及连接图像和自然语言的视觉语言预训练模型[31,32,17,37,27]。一些研究 [37, 27] 学习使用大量图像语言对从头开始训练模型,并将其应用于下游任务,例如视觉问答 [18, 51]、字幕 [7] 和通过微调的引用表达理解 [50]。其他研究人员将预训练的视觉模型和预训练的LLM与其他可学习的神经模块(例如感知器 [2] 和 QFormers [31])连接起来,利用预训练视觉模型中的感知能力以及LLM中的推理和泛化能力。受这些前期工作的启发,我们计划构建一个能够理解3D世界并进行相应3D推理和规划的AI助手。这不是小事,我们需要克服诸如如何处理数据稀疏问题、如何将 3D 世界与 2D 图像对齐以及如何捕获 3D 空间信息等障碍。
3D 和语言。与我们类似的另一项研究是 3D 和语言 [5, 49, 8, 20, 1, 15, 24, 49, 3, 21, 19]。 ScanQA [49] 需要一个模型来回答与 3D 世界相关的问题; ScanRefer [5] 要求模型定位文本表达式所指的区域; 3D 字幕 [8] 测试模型生成描述 3D 场景的字幕的能力。然而,这些 3D 任务及其相应的模型通常是特定于任务的,只能处理训练集相同分布内的情况,而无法泛化。与它们不同的是,我们的目标是构建一个可以同时处理不同任务的 3D 模型,并启用 3D 辅助对话和任务分解等新功能。
3 3D 语言数据生成
由于可以轻松访问互联网上的大量 2D 图像和文本对,社区见证了多模式数据的激增。然而,对于3D相关数据,获取多模态资源并不容易,不仅因为3D资产的稀缺性,而且因为3D资产提供语言数据的困难。有一些现有的数据集包含 3D 语言数据(例如 ScanQA [49]、ScanRefer [5])。然而,它们在数量和多样性方面都受到限制,每个数据集仅限于一项任务。如何生成可用于各种 3D 相关任务的 3D 语言数据集非常值得深入研究。
受到 GPT [33] 等大型语言模型最近成功的启发,我们建议利用此类模型进行 3D 语言数据收集。具体来说,如图7所示,我们有三种方式提示纯文本GPT生成数据。 1)基于框-演示-指令的提示。
我们输入 3D 场景中房间和对象的轴对齐边界框 (AABB),提供有关场景的语义和空间位置的信息。然后,我们向 GPT 模型提供具体指令以生成不同的数据。我们提供了 0-3 个 GPT 模型的小样本演示示例,展示了它被指示生成什么样的数据。 2)基于ChatCaptioner的提示。我们利用类似于[52]的技术,其中ChatGPT被提示询问一系列有关图像的信息性问题,BLIP-2 [30] 回答了这些问题。为了收集3D相关数据,我们将不同视图的图像输入BLIP-2,并指示ChatGPT提出问题并收集不同区域的信息,以形成整个场景的全局3D描述。 3)基于修订的提示。它可用于将一种类型的 3D 数据传输到另一种类型。
给定提示管道,GPT 能够生成各种类型的 3D 语言数据,如图 1 所示。我们在附录中显示了生成所有类型数据的详细提示。
我们主要在几个 3D 资产上建立我们的 3D 语言数据集:
• Objaverse 是一个由 800K 3D 对象组成的宇宙。然而,由于语言描述是从在线资源中提取的,并且未经人类检查,因此大多数对象都有非常嘈杂的描述(例如,带有 url)或没有描述。我们利用基于 ChatCaptioner 的提示来生成场景的高质量 3D 相关描述。
• Scannet [11] 是一个包含约 1k 3D 室内场景的注释丰富的数据集。它提供场景中对象的语义和边界框。
• Habitat-Matterport (HM3D) [41] 是体现人工智能的 3D 环境数据集。 HM3DSem [47]进一步为HM3D的200多个场景添加了语义注释和边界框。
4 3D-LLM
4.1 概述
在本节中,我们介绍如何训练 3D-LLM。我们认为从头开始训练 3D-LLM 很困难,因为我们收集的 3D 语言数据集仍然没有用于训练 2D VLM 的十亿级图像语言数据集的大小。此外,对于 3D 场景,没有像 2D 图像那样的可用预训练编码器(例如 CLIP ViT 编码器)。因此,从头开始重新训练 3D 语言模型的数据效率低且资源繁重。最近,研究人员提出从 2D 多视图图像中提取 3D 特征 [26, 20]。使用这些对齐方法,我们可以使用预训练的图像编码器来提取图像特征,然后将特征映射到 3D 数据。由于预训练的图像特征作为 2D VLM 的输入,因此相同特征空间的映射 3D 特征也可以无缝地输入到预训练的 2D VLM 中,我们将其用作训练 3D-LLM 的骨干。我们还提出了一种 3D 定位机制来提高模型捕获 3D 空间信息的能力。图 3 显示了我们的框架。
4.2 3D 特征提取器
训练 3D-LLM 的第一步是构建可以与语言特征对齐的有意义的 3D 特征。对于 2D 图像,存在像 CLIP 这样的特征提取器,它可以从语言监督中学习视觉模型。这些模型是使用十亿级图像语言对的互联网数据进行预训练的。从头开始预训练这样的特征学习器是很困难的,因为在数量和多样性方面没有可与互联网规模的图像语言对相媲美的 3D 语言资产。
相反,人们提出了多种方法从 2D 多视图图像中提取 3D 特征 [26,20,16,23]。受这些作品的启发,我们通过在几个不同的视图中渲染 3D 场景来提取 3D 点的特征,并从渲染的图像特征构建 3D 特征。我们首先按照[26]提取渲染图像的像素对齐密集特征。然后,我们利用三种方法从渲染图像特征构建 3D 特征。这些方法是针对不同类型的 3D 数据而设计的。
• 直接重建。我们使用地面实况相机矩阵直接从 3D 数据渲染的 RGB 图像重建点云。这些特征直接映射到重建的 3D 点。该方法适用于渲染具有完美相机姿态和内在特性的 RGBD 数据。
• 功能融合。与[26]类似,我们使用gradslam[28]将2D特征融合到3D地图中。与密集映射方法不同,除了深度和颜色之外,还融合了特征。此方法适用于具有噪声深度图渲染或噪声相机姿势和内在特征的 3D 数据。
• 神经场。我们利用[20],它使用神经体素场构建 3D 紧凑表示[43]。具体来说,场中的每个体素除了密度和颜色之外还有一个特征。然后,我们使用 MSE 损失对齐光线中的 3D 特征和像素中的 2D 特征。此方法适用于具有 RGB 渲染但没有深度数据以及嘈杂的相机姿势和内在特征的 3D 数据。这样,我们就能够获得每个3D场景的<N,Dv>-dim 3D特征,其中N是点云中的点数,Dv是特征维度。
4.3 训练 3D-LLM
4.3.1 2D VLM 作为骨干
除了特征提取器之外,从头开始训练 3D-LLM 也很重要。事实上,根据 [30, 14],2D VLM 的训练在消耗了 5 亿张图像后才开始显示“生命迹象”。他们通常使用冻结和预先训练的图像编码器(例如 CLIP)来提取 2D 图像的特征。考虑到使用 3D 特征提取器,3D 特征可以映射到与 2D 图像相同的特征空间,因此使用这些 2D VLM 作为我们的主干是合理的。[25]提出的感知器架构利用不对称注意机制将输入迭代地提炼到紧密的潜在瓶颈中,使其能够处理任意输入大小的非常大的输入,从而可以处理不同的模态。这种架构被用在像 Flamingo [14] 这样的 VLM 中。 BLIP-2 [30] 也利用了称为 QFormer 的类似结构。从冻结图像编码器输出的 2D 图像特征被展平并发送到感知器以生成固定大小的输入。鉴于我们的 3D 特征与 3D 特征提取器的 2D 特征位于相同的特征空间中,并且感知器能够处理相同特征维度的任意输入大小的输入,因此也可以将任意大小的点云特征输入到感知者。因此,我们使用 3D 特征提取器在与冻结图像编码器的特征相同的特征空间中提取 3D 特征。然后,我们使用预训练的 2D VLM 作为主干,输入对齐的 3D 特征,以使用我们收集的 3D 语言数据集训练 3D-LLM。
4.3.2 3D 定位机制
除了构建与语言语义一致的 3D 特征外,捕获 3D 空间信息也很重要。为此,我们提出了一种 3D 定位机制,可以增强 3D LLM 吸收空间信息的能力。它由两部分组成: 使用位置嵌入增强 3D 特征 除了从 2D 多视图特征聚合的 3D 特征之外,我们还向特征添加位置嵌入。假设特征暗淡是Dv。我们生成三个维度的 sin/cos 位置嵌入,每个维度都有一个嵌入大小 Dv/3。我们连接所有三个维度的嵌入,并将它们连接到 3D 特征。使用位置标记增强 LLM 词汇表为了将 3D 空间位置与 LLM 对齐,我们建议按照 [6] 和 [45] 在词汇表中嵌入 3D 位置。具体来说,要接地的区域可以表示为以 AABB 形式表示边界框的离散标记序列。边界框的连续角坐标被统一离散化为体素整数,作为位置标记 ⟨xmin, ymin, zmin, xmax, ymax, zmax⟩。添加这些额外的位置标记后,我们在语言模型的输入和输出嵌入中解冻这些标记的权重。
5 实验
我们首先介绍架构、训练和评估协议。在第 5.1 节中,我们分析了 ScanQA 数据集上的保留实验。第 5.2 节涵盖了对保留评估和定性示例的更多分析。由于页数限制,我们将以下内容放入附录: 1)3DMV-VQA 和对象导航的 Held-Out 实验; 2)关于接地和密集字幕的保留实验; 3)更多的消融研究; 4)更多定性例子。
架构 我们对 3D-LLM 的三个主干 2D VLM 进行了实验:Flamingo 9B、BLIP-2 Vit-g Opt2.7B、BLIP-2 Vit-g FlanT5-XL。对于 BLIP-2,在预训练 3D-LLM 期间,我们从 LAVIS 库 [29] 中发布的 BLIP-2 检查点初始化模型,并微调 QFormer 的参数。 3D 特征是 1408-dim 特征,与 BLIP-2 使用的 EVA_CLIP 隐藏特征暗淡相同。我们保持 LLM 的大部分部分(即 Opt 和 FlanT5)冻结,除了输入和输出嵌入中新添加的位置标记的权重。对于 Flamingo,我们从 OpenFlamingo 存储库 [2] 中发布的 Flamingo9B 检查点初始化模型。我们微调感知器的参数、门控交叉注意层以及输入和输出嵌入中附加位置标记的权重。 3D 特征是 1024-dim 特征,与 Flamingo 使用的 CLIP 隐藏特征暗淡相同。
训练和评估数据集和协议我们将数据集分为两种类型:保留数据集和保留数据集。具体来说,我们的 3D 语言数据生成管道生成多个任务的保留数据集。我们将数据集分成训练/验证/测试集 (8:1:1)。我们利用保留数据集的训练集进行预训练基础 3D-LLM,其验证和测试集可用于保留评估。在预训练期间,我们混合所有任务的保留数据集。这些模型使用标准语言建模损失来训练输出响应。另一方面,保留的数据集不用于训练基础 3D-LLM。我们使用两个保留的 3D 问答数据集进行保留评估:ScanQA 和 3DMV-VQA。我们将3DMV-VQA[20]的实验分析放在补充材料中。
5.1 保留评估 我们在 ScanQA 数据集上微调我们预训练的 3D-LLM,并与基线模型进行比较。
基线和评估指标我们在基准测试中包含了代表性的基线模型。特别是,ScanQA 是基准测试中最先进的方法,它使用 VoteNet 获取对象提案,然后将其与语言嵌入融合。 ScanRefer+MCAN 是识别所引用对象的基线,并且 MCAN 模型应用于局部对象周围的图像。 VoteNet+MCAN 检测 3D 空间中的对象,提取其特征,并将其用于标准 VQA 模型。值得注意的是,这些基线模型都从预训练的定位模块中提取显式的对象表示。除了这些基线之外,我们还设计了几个基于法学硕士的基线。 LLaVA 是一种视觉指令调整,连接视觉编码器和 LLM 以实现通用视觉和语言理解。我们使用其预训练模型并对我们的数据集进行零样本评估。我们使用单个随机图像作为输入。我们使用 LLaVA 13B 模型。单图像 + 预训练 VLM 使用我们的 2D VLM 主干(即 flamingo 和 BLIP-2),用单图像特征替换 3D-LLM 的 3D 输入来训练模型,然后在 ScanQA 数据集上进行微调。多视图图像 + 预训练 VLM 使用我们的 2D VLM 主干,用多视图图像的串联特征替换 3D-LLM 的 3D 输入来训练模型,然后在 ScanQA 数据集上进行微调。我们报告 BLEU、ROUGE-L、METEOR、CIDEr,以实现稳健的答案匹配。我们还使用精确匹配 (EM) 指标。
结果分析
我们在表 1 中报告了 ScanQA 验证集的结果,在表 2 中报告了测试集的结果。我们观察到评估指标显着增加。例如,对于 BLEU-1,我们的模型在验证集上比最先进的 ScanQA 模型高出约 9%,在测试集上比最先进的 ScanQA 模型高出约 7%。对于 CIDER,我们报告与 ScanQA 相比提高了 ∼5%,并且远高于其他基于 3D 的基线。这些结果表明,通过将 3D 注入法学硕士,模型可以生成与真实答案更加相似的答案。此外,基于 3D 的基线使用 VoteNet 等对象检测器来分割对象,然后将每个对象的特征发送到模型中,而我们的输入是没有显式对象表示的整体 3D 特征。这表明,即使没有明确的对象表示,我们的模型也可以对对象及其关系进行视觉推理。然后我们检查 2D VLM 是否具有相同的能力。我们发现,以单视图图像或多视图图像作为输入,与 3D-LLM 相比,性能下降很多。具体来说,多视图图像还包含有关整个场景的信息。然而与 3D-LLM 相比,它们的性能要低得多,可能是因为多视图图像的特征是杂乱的,从而丢失了 3D 相关信息。
5.2 更广泛的评估 保留评估 我们对三个任务的保留数据集进行了实验:3D 字幕、3D 辅助对话和任务分解。基线包括用于保留评估的 2D VLM。我们添加了一种仅限语言的基线:FlanT5,它检查法学硕士在没有任何视觉输入的情况下完成这些任务的能力。为了评估回复的质量,我们将 BLEU、ROUGEL、METEOR、CIDEr 作为指标。我们在表 3 中报告了保留的评估表现。从表中我们可以看到 3D-LLM 可以生成高质量的回复,优于 2D VLM 和纯语言 LLM。
定性示例 在图 4 中,我们展示了 3D-LLM 预测的定性示例。我们可以看到我们的 3D-LLM 能够执行各种任务。
6 结论 在本文中,我们提出了一个新的 3D-LLM 系列,它可以将 3D 表示作为输入并生成响应。我们引入了一系列 3D 语言数据生成管道来生成 30 万个 3D 语言对的数据集来训练我们的 3D-LLM,包括密集字幕、3D 问答、任务分解、3D 基础、3D 辅助对话、导航和很快。我们的 3D-LLM 利用 2D 预训练 VLM 作为骨干和新颖的 3D 定位机制。
实验表明,我们的 3D-LLM 在 ScanQA 数据集上的性能优于最先进的基线模型,并且可以执行多种 3D 相关任务。一个限制是 3D 特征提取器依赖于 2D 多视图图像,因此需要渲染所有 3D 场景,以便可以在 3D-LLM 中训练它们,这引入了额外的渲染过程。