HTTP是一个基于TCP/IP通信协议来传递数据的协议,传输的数据类型为HTML文件、图片文件、查询结果等。HTTP协议一般用于B/S架构。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。
URI、URL、URN
HTTP使用统一资源标识符(Uniform Resource ldentifiers,URI)来传输数据和建立连接
URI:Uniform Resource ldentifier 统一资源标识符,用来唯一的标识一个资源。
URL:Uniform Resource Location 统一资源定位符,用来唯一的标识一个资源,而且还指明了如何去locate这个资源。
URN:Uniform Resource Name,统一资源命名,是通过名字来标识资源。
URI:统一资源标识符
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是由一个URI来定位的。
URI一般由三部组成:
- 访问资源的命名机制
- 存放资源的主机名
- 资源自身的名称,由路径表示,着重强调于资源
URI结构
HTTP使用统一资源标识符(URI)来传输据和建立连接。URL(统一资源定位符)是一种特殊种类的URI,包含了用于查找的资源的足够的信息,我们一般常用的就是URL。
一个完整的URL包含下面几部分:
- 协议部分:
- 域名部分:
- 端口部分:
- 虚拟目录部分:
- 文件名部分:
- 锚部分:
- 参数部分:
URL:统一资源定位符
URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上.采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部分组成:
协议(或称为服务方式)
存有该资源的主机IP地址(有时也包括端口号)
主机资源的具体地址。如目录和文件名等
HTTP URL包含了用于查找某个资源的详细信息,格式如: http://host["."port][abs path]
URN:统一资源命名
URN: Uniform Resource Name,统一资源命名,通过名字来标识资源。比如mailto:test@baidu.com
URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式,URL和URN都是一种URI。
笼统地说,每个URL都是URI,但不一定每个 URI都是 URL。这是因为 URI还包括一个子类即统一资源名称(URN),它命名资源但不指定如何定位资源。上面的 mailto、news和isbn URI都是URN的示例。
HTTP请求
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法: GET,POST和HEAD方法。
HTTP1.1新增了五种请求方法: OPTIONS,PUT,DELETE,TRACE和CONNECT方法。
HTTP请求方法
- GET:请求指定的页面信息,并返回实体主体。
- POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和或已有资源的修改。
- HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头。
- PUT:从客户端向服务器传送的数据取代指定的文档的内容。
- DELETE:请求服务器删除指定的页面。
- CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
- OPTIONS:允许客户端查看服务器的性能。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
HTTP请求方法:GET
GET /books/?sex=man&name=Professional HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive
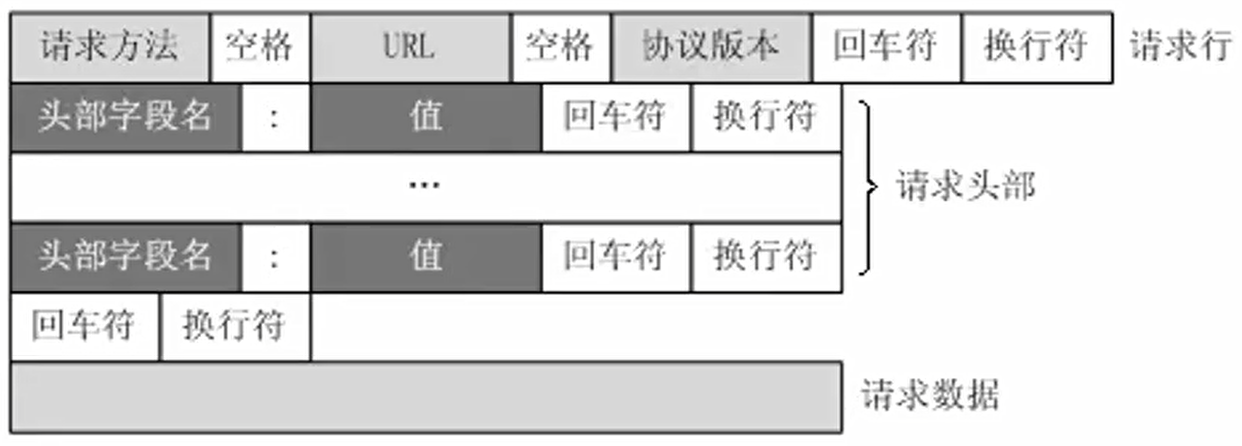
- 状态行由请求方式,路径、协议等构成,各元素之间以空格分隔。对应到图中即为 GET./books/?sex=man&name=Professional、 HTTP/1.1。
- 请求头提供一些参数比如: Cookie,用户代理信息,主机名等等。
- 请求正文就放一些发送的数据,一般 GET 请求会将参数放在URL中,也就是在请求头中而请求正文般为空,而POST请求将参数放在请求正文中。请求正文可以传一些json 数据或者字符串等等。
HTTP请求方法:GET适用场景
- GET一般用于信息获取,比如浏览某新闻首页,使用的就是GET方法。
- 它仅仅只是获取资源信息,就像数据库查询一样,不会修改、增加GET请求一般不会产生副作用,数据,不会影响资源的状态,并且对同一个 URL的多次GET请求应该返回相同的结果。
HTTP请求方法:POST
POST请求表示可能会修改服务器上的资源,比如把账号密码放入body中
POST / HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
sex=man&name=Professional
GET与POST请求方法区别
- GET和POST请求参数位置不同,从上面两个请求报文可以看出,GET 请求对应的参数放在URL中,而POST请求对应的参数放在HTTP 请求主体中。
- 虽然HTTP协议的RFC规范并没有详细规定URL的最大字符长度限制,但实际上,在浏览器或者服务器中总会存在限制的,这就导致了GET请求中参数数量是有限的,而POST没有。
- 处于安全考虑,在一些涉及安全的请求比如: 登录请求需要用POST 提交表单,而GET请求一般用来获取静态资源。
- GET 请求可以被缓存,可以被收藏为书签,但POST 可以被缓存,但不能被收藏为书签。
- GET请求的参数在URL中因此绝不能用GET 请求传输敏感数据。POST请求数据则写在HTTP的请求头中,安全性略高于GET请求。
特征 |
GET |
POST |
目的 |
从服务器获取数据 |
向服务器传输数据 |
请求参数的位置 |
URL中 |
请求的数据体中 |
请求参数的形式 |
variable=value,使用“?”和“&”连接 |
变量和值相对应,在数据体中传输 |
传输数据量限制 |
受URL长度限制,数据量小 |
无限制,可以传输大量数据 |
表单数据集值的字符限制 |
必须是ASCII字符 |
支持整个ISO10646字符集 |
幂等性 |
幂等,多次执行效果相同 |
非幂等,每次执行可能会产生不同的效果 |
默认方法 |
是Form的默认方法 |
不是Form的默认方法 |
安全性 |
不安全,数据在URL中明文传输,可能被第三方看到或记录在日志中 |
对用户不可见,但同样是明文传输,可能被开发者工具或抓包工具看到 |
注意:为了确保数据的安全性,应该使用加密通信协议,如HTTPS;尽管POST比GET更安全,但因为POST也是明文传输,所以并不是完全安全的。
HTTP响应
HTTP响应是服务器在客户端发送HTTP 请求后经过一些处理而做出的响应,HTTP 响应和HTTP 请求相似,也是由三个部分构成。分别是:
- 状态行
- 响应头: Response Header
- 响应正文
HTTP响应码
HTTP 响应中包含一个状态码,用来表示服务器对客户端响应的结果,状态码一般由3位构成。
状态码 |
含义 |
1xx |
表示请求已经接受了,继续处理 |
2xx |
表示请求已经处理掉了 |
3xx |
重定向。 |
4xx |
一般表示客户端有错误,请求无法实现。 |
5xx |
一般为服务器端的错误 |
HTTP常见响应码
常见状态码 |
含义 |
200 |
OK客户端请求成功。 |
301 |
Moved Permanently 请求永久重定向 |
302 |
Moved Temporarily 请求临时重定向。 |
304 |
Not Modified 文件未修改,可以直接使用缓存的文件 |
400 |
Bad Request由于客户端请求有语法错误,不能被服务器所理解 |
401 |
Unauthorized 请求未经授权,无法访问 |
403 |
Forbidden 服务器收到请求,但是拒绝提供服务。服务器通常会在响应正文中给出不提供服务的原因。 |
404 |
Not Found 请求的资源不存在,比如输入了错误的URL |
500 |
Internal Server Error 服务器发生不可预期的错误,导致无法完成客户端的请求 |
503 |
Service Unavailable 服务器当前不能够处理客户端的请求,在一段时间之后,服务器可能会恢复正常. |
HTTP头信息
HTTP消息由客户端到服务器的请求和服务器到客户端的响应组成。请求消息和响应消息都是由开始行(对于请求消息,开始行就是请求行,对于响应消息,开始行就是状态行),消息报头 (可选),空行(只有CRLF的行),消息正文(可选)组成。
HTTP消息报头包括通用头、请求头、响应头、实体头。
每一个报头域都是由名字+“:“+空格+值组成,消息报头域的名字是大小写无关的
HTTP消息包头注解
通用头部 |
是客户端和服务器都可以使用的头部,可以在客户端、服务器和其他应用程序之间提供一些非常有用的通用功能,如Date头部。 |
请求头部 |
是请求报文特有的,它们为服务器提供了一些额外信息,比如客户端希望接收什么类型的数据,如Accept头部。 |
响应头部 |
便于客户端提供信息,比如,客服端在与哪种类型的服务器进行交互,如Server头部。 |
实体头部 |
指的是用于应对实体主体部分的头部,比如,可以用实体头部来说明实体主体部分的数据类型,如Content-Type头部。 |
HTTP头信息:通用头
通用头域包含请求和响应消息都支持的头域,通用头域包含缓存头部Cache-Control、Pragma及信息性头部Connection、Date、 Transfer-Encoding、Update、Via。
Cache-Control指定请求和响应遵循的缓存机制。在请求消息或响应消息中设置 Cache-Control并不会修改另一个消息处理过程中的缓存处理过程。请求时的缓存指令包括no-cache、no-store、max-age.max-stale、min-fresh、only-if-cached,响应消息中的指令包括public、private、 no-cache、nostore、no-transform、must-revalidate、 proxy-revalidate、max-age。
- Pragma头域用来包含实现特定的指令,最常用的是Pragma:no-cache。在HTTP/1.1协议中,它的含义和Cache- Control;no-cache相同。
- Connection表示是否需要持久连接
- Date头域表示消息发送的时间,服务器响应中要包含这个头部,因为缓存在评估响应的新鲜度时要用到,其时间的描述格式由RFC822定义。
- Transfer-Encodinq表示WEB服务器表明自己对本响应消息体(不是消息体里面的对象)作了怎样的编码,比如是否分块 (chunked)。
- Upgrade可以指定另一种可能完全不同的协议。
- Via列出从客户端到OCS 或者相反方向的响应经过了哪些代理服务器,他们用什么协议(和版本)发送的请求。
HTTP头信息:请求头
请求头用于说明是谁或什么在发送请求、请求源于何处,或者客户端的喜好及能力。服务器可以根据请求头部给出的客户端信息,试着为客户端提供更好的响应。
请求头域可能包含下列字段Accept、Accept-Charset、Accept- Encoding、Accept-Language.Authorization、From、Host、lf-Modified-Since、 lf-Match、lf-None-Match、lf-Range、 lfRange、 lf-Unmodified-Since Max-Forwards、Proxy-Authorization、Range、 Referer、User.Agent。
对请求头域的扩展要求通讯双方都支持,如果存在不支持的请求头域,一般将会作为实体头域处理。
- Accept: 告诉WEB服务器自己接受什么介质类型。
- Accept-Charset: 浏览器告诉服务器自己能接收的字符集。
- Accept-Encoding: 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate)。
- Accept-Language: 浏览器申明自己接收的语言。
- Authorization: 当客户端接收到来自WEB服务器的 WWW-Authenticate 响应时,用该头部来回应自己的身份验证信息给WEB服务器。
- Host:客户端指定自己想访问的WEB服务器的域名/P 地址和端口号。
- User-Agent:用户请求的代理软件,包括用户的操作系统,浏览器等相关属性。
- Referer:代表当前访问的URL的上一个URL,也就是用户是从什么地方转到本页面的。Cookie: Cookie是个非常重要的请求头,常用来表示请求者的身份。比如有些会话信息(Sesssionld)会存在Cookie中
- Range:请求实体内容的一部分,多线程下载一定会用到该请求头
- Proxy-Authenticate:代理服务器响应浏览器,要求其提供代理身份验证信息
- Proxy-Authorization: 浏览器响应代理服务器的身份验证请求,提供自己的身份信息
HTTP头信息:响应头
响应头向客户端提供一些额外信息,比如谁在发送响应、响应者的功能,甚至与响应相关的一些特殊指令。这些头部有助于客户端处理响应,并在将来发起更好的请求。
响应头域包含Age、Location、Proxy-Authenticate、Public、Retry- After、Server、Vary.Warning、WWW-Authenticate
对响应头域的扩展要求通讯双方都支持,如果存在不支持的响应头域,一般将会作为实体头域处理。
- Age:当代理服务器用自己缓存的实体去响应请求时,用该头部表明该实体从产生到现在经过多长时间。
- Server: 服务器所使用的Web服务器名称。攻GJ击者可以通过查看该头信息,来探测Web服务器名称。所以一般服务器端会对该头信息进行修改。
- Accept-Ranges:WEB服务器表明自己是否接受获取其某个实体的一部分(比如文件的一部分)的请求。bytes:表示接受,none: 表示不接受。
- Vary: WEB服务器用该头部的内容告诉 Cache 服务器,在什么条件下才能用本响应所返回的对象响应后续的请求。
HTTP头信息:实体头
实体头部提供了有关实体及其内容的大量信息,从有关对象类型的信息,到能够对资源使用的各种有效的请求方法。总之,实体头部可以告知接收者它在对什么进行处理。
请求消息和响应消息都可以包含实体信息,实体信息一般由实体头域和实体组成。
实体头域包含关于实体的原信息,实体头包括信息性头部Allow、Location,内容头部Content-Base.Content-Encoding、Content-Language、 Content-Length、 Content-Location、 Content-MD5Content-Range、Content-Type,缓存头部Etag、Expires、 Last-Modified、extension-header。
- Allow:服务器支持哪些请求方法(如GET、POST等)。
- Location: 服务器通过该头信息告诉浏览器去访问那个页面,浏览器接收到这样的响应信息后,通常会立刻访问Location头所指向的页面。这个头通常配合302重定向状态码使用。
- Last-Modified: 服务器通过该头信息告诉浏览器,资源最后的修改时间。从而让客户端及时地更新缓存内容。
- Expires:WEB服务器表明该实体将在什么时候过期,对于过期了的对象,只有在跟WEB服务器验证了其有效性后,才能用来响应客户请求
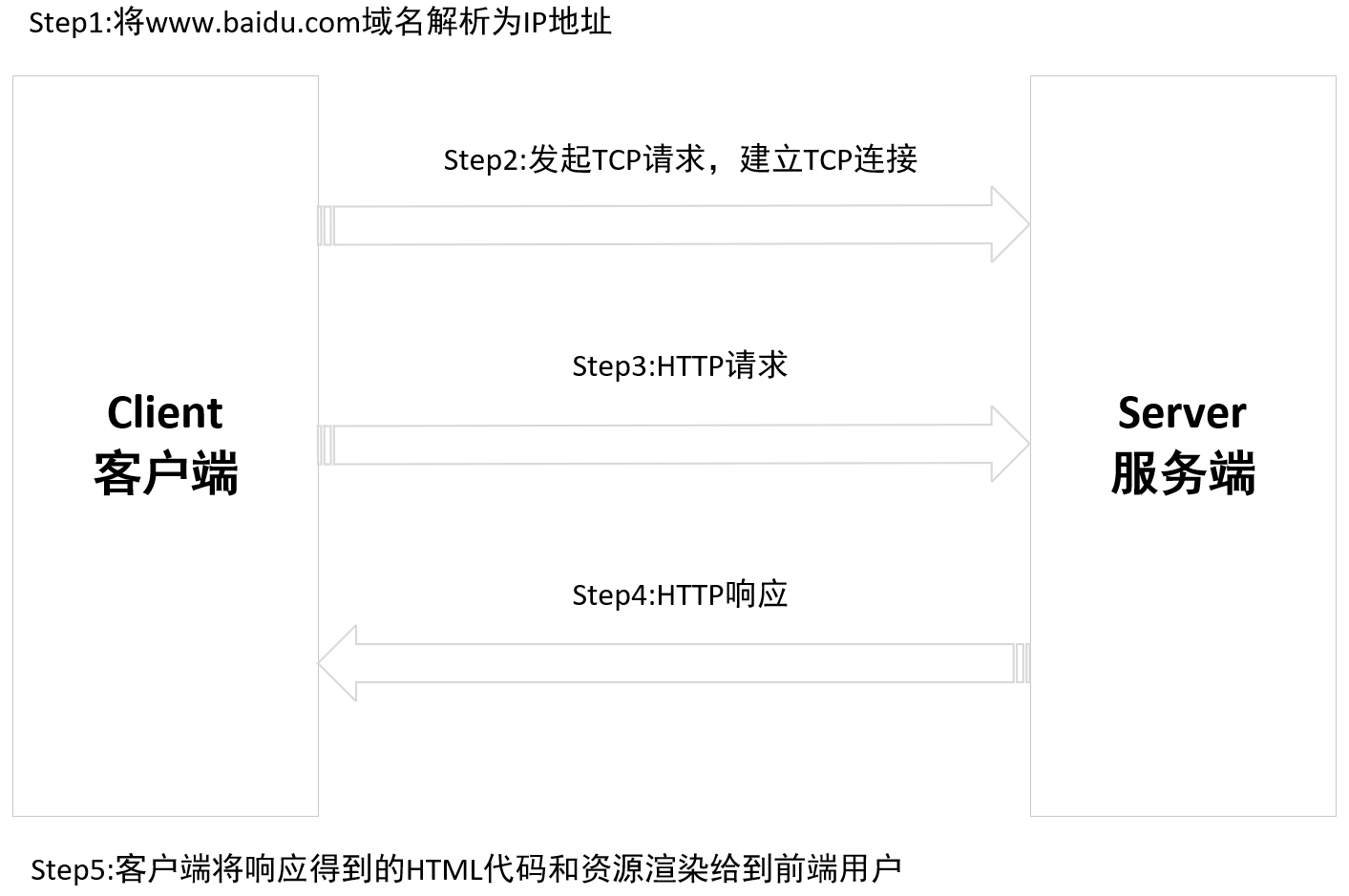
HTTP工作原理
HTTP会话跟踪
会话:客户端向服务器端发起请求到服务端响应客户端请求的全过程。
会话跟踪:会话追踪指的是服务器对用户响应的监视。
- URL重写:URL重写技术就是在URL 结尾添加一个附加数据以标识该会话,把会话D 通过 URL的信息传递过去,以便在服务器进行识别不同的用户
- 隐藏表单域:将会话ID添加到HTML表单元素中提交到服务器,此表单元素并不在客户端显示。
- Cookie: Cookie是We 服务器发送给客户端的一小段信息,客户端请求时可以读取该信息发送给服务器端,进而进行用户的识别,对于客户端的每次请求,服务器都会将 Cookie 发送到客户端,客户端保存下来,以便下次使用。
- Session: 在服务器端会创建一个 session 对象,产生一个 sessionlD 来标识这个 session 对象,然4后将这个 sessionID 放入到 Cookie 中发送到客户端,下一次访问时,sessionD 会发送到服务器在服务器端进行识别不同的用户。
HTTP持久连接
在实际的应用中,客户端往往会发出一系列请求,接着服务器端对每个请求进行响应。对于这些请求响应,如果每次都经过一个单独的TCP连接发送,称为非持久连接。反之,如果每次都经过相同的TCP连接进行发送,称为持久连接。
非持久连接给服务器带来了沉重的负担,每台服务器可能同时面对数以百计甚至更多的请求。持久连接就是为了解决这些问题,其特点是一直保持TCP连接状态,直到遇到明确的中断要求之后再中断连接。持久连接减少了通信开销,节省了通信量。
HTTP缓存机制
HTTP条件GET是HTTP 协议为了减少不必要的带宽浪费,提出的一种方案
HTTP条件GET 使用时机:客户端之前已经访问过某网站,并打算再次访问该站点。
HTTP 条件GET 使用的方法:客户端向服务器发送一个包询问是否在上一次访问网站的时间后是否更改了页面,如果服务器没有更新,显然不需要把整个网页传给客户端,客户端只要使用本地缓存即可,如果服务器对照客户端给出的时间已经更新了客户端请求的网页,则发送这个更新了的网页给用户。
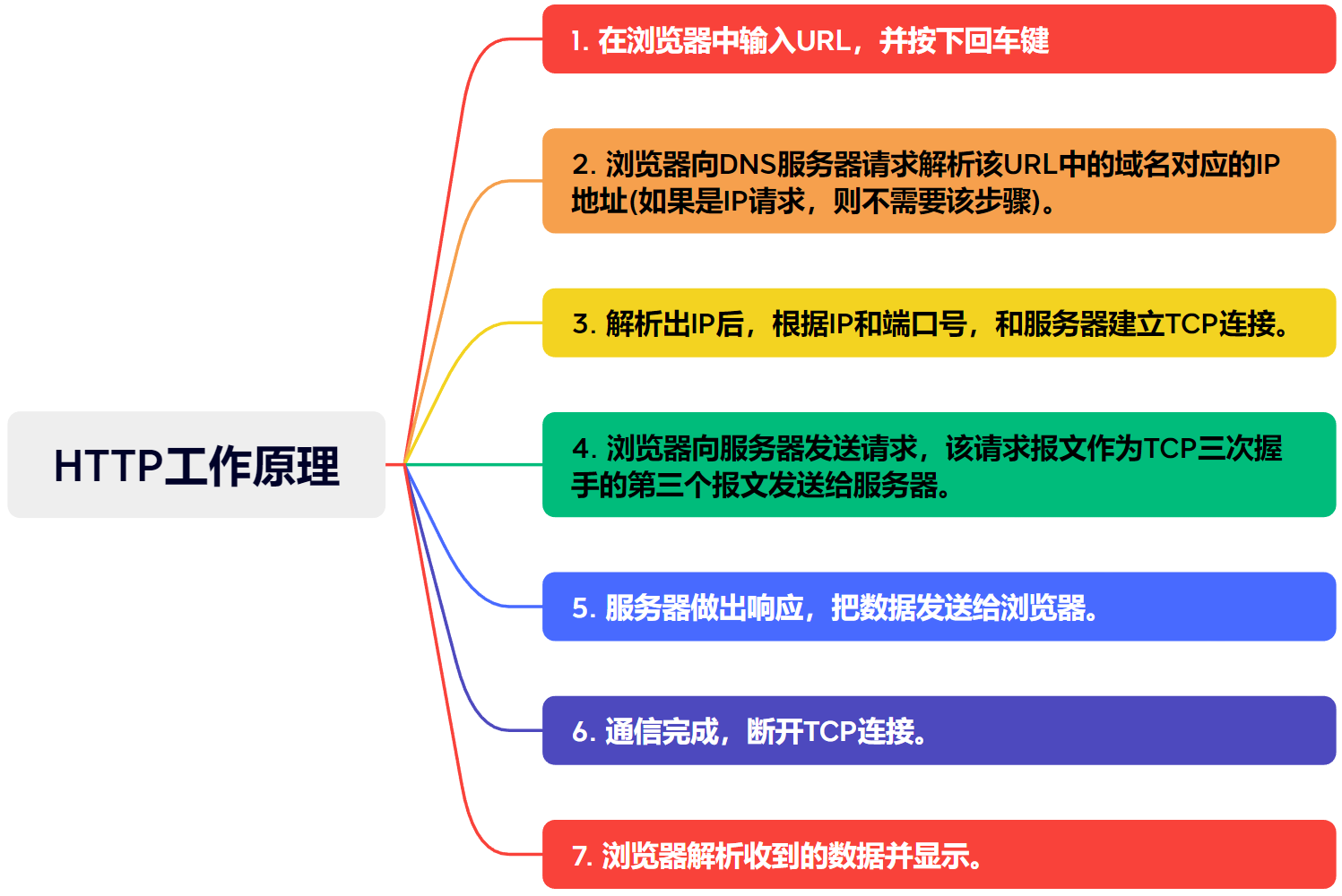
HTTP工作原理
HTTP协议采用请求/响应模式,客户端向服务器发送一个请求报文,然后服务器响应请求。一次HTTP请求的过程:
- 在浏览器中输入URL,并按下回车键
- 浏览器向DNS服务器请求解析该URL中的域名对应的IP地址(如果是IP请求,则不需要该步骤)。
- 解析出IP后,根据IP和端口号,和服务器建立TCP连接。
- 浏览器向服务器发送请求,该请求报文作为TCP三次握手的第三个报文发送给服务器。
- 服务器做出响应,把数据发送给浏览器。
- 通信完成,断开TCP连接。
- 浏览器解析收到的数据并显示。