
目标检测(Object Detection),也叫目标提取,是一种基于目标几何和统计特征的图像分割。它将目标的分割和识别合二为一,其准确性和实时性是整个系统的一项重要能力。
尤其是在复杂场景中,需要对多个目标进行实时处理时,目标自动提取和识别就显得特别重要。

1. 什么是目标检测
1.1 目标检测的定义:
识别图片或者视频中有哪些物体以及物体的位置(坐标位置)。
什么是物体(物体的定义):
图像(或者视频)中存在的对象,但是能检测哪些物体会受到人为设定限制。
目标检测中能检测出来的物体取决于当前任务(数据集)需要检测的物体有哪些。假设我们的目标检测模型定位是检测动物(例如,牛、羊、猪、狗、猫五种),那么模型对任何一张图片输出结果不会输出鸭子、鹅、人等其他类型结果。
什么是位置(位置的定义):
目标检测的位置信息一般有2种格式(以图片左上角为原点(0,0)):
极坐标表示:(xmin,ymin,xmax,ymax)
xmin,ymin:x,y坐标的最小值
xmax,ymax:x,y坐标的最大值
中心点坐标:(x_center,y_center,w,h)
x_center,y_center:目标检测框的中心点坐标
w,h:目标检测框的宽,高
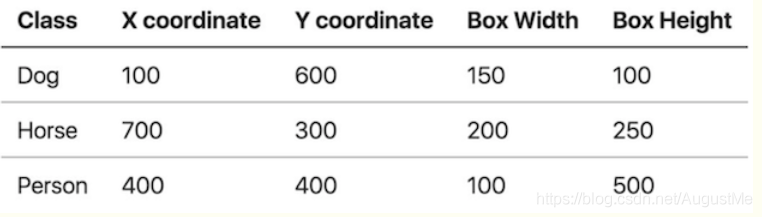
例:
假设一张图片是100*800,所有这些坐标都是构建在像素层面上:

中心点坐标结果为:
2. 目标检测技术的发展历史
目标检测算法分类:
角度一:
a. 传统目标检测方法(候选区域+手工特征提取+分类器)
HOG+SVM、DPM
b. region proposal+CNN提取分类的目标检测框架
R-CNN,SPP-NET,Fast R-CNN,Faster R-CNN
c. 端到端(End-to-End)的目标检测框架
YOLO系列,SSD
传统目标检测(缺点、弊端)
1)基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余
2)手工设计的特征对于多样性的变化没有很好的鲁棒性
角度二:
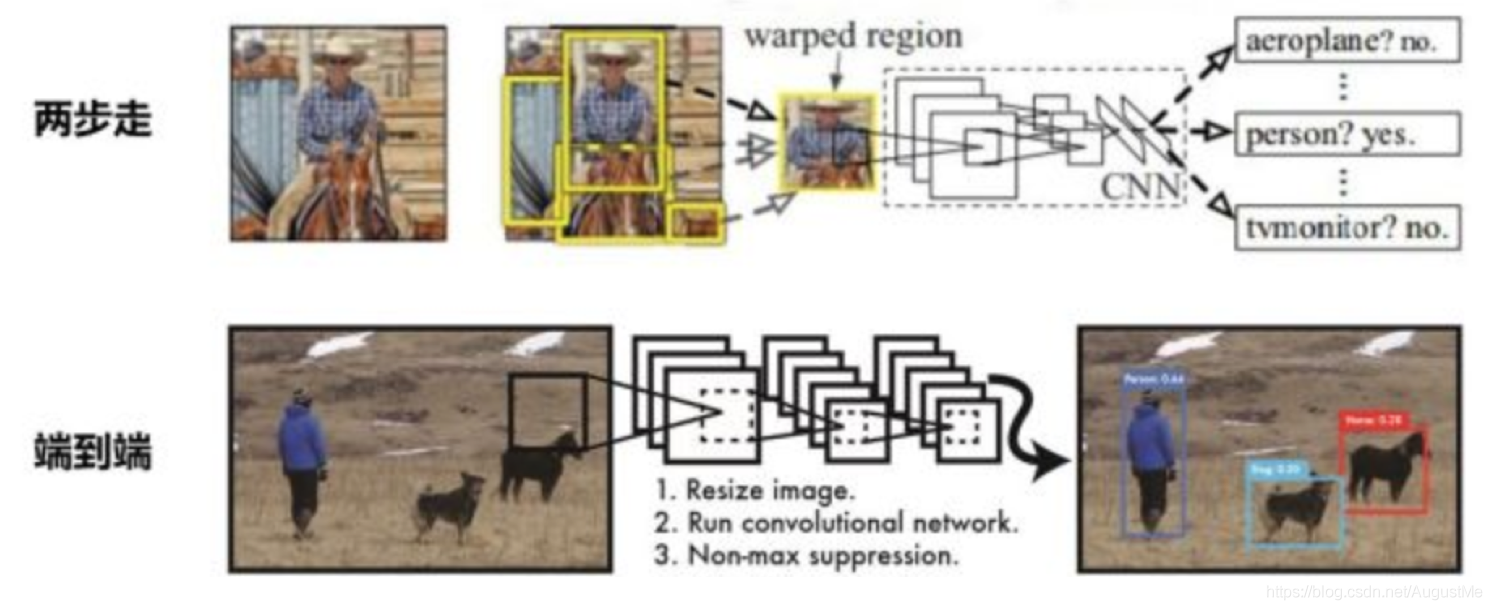
(1)两步走(two stage)的目标检测:先进行区域推荐,而后进行目标分类
主要算法:R-CNN,SPP-NET,Fast R-CNN,Faster R-CNN
(2)端到端(one stage)的目标检测:采用一个网络一步到位
主要算法:YOLO系列(YOLO v1,YOLO v2等),SSD
目标检测的任务
分类原理:
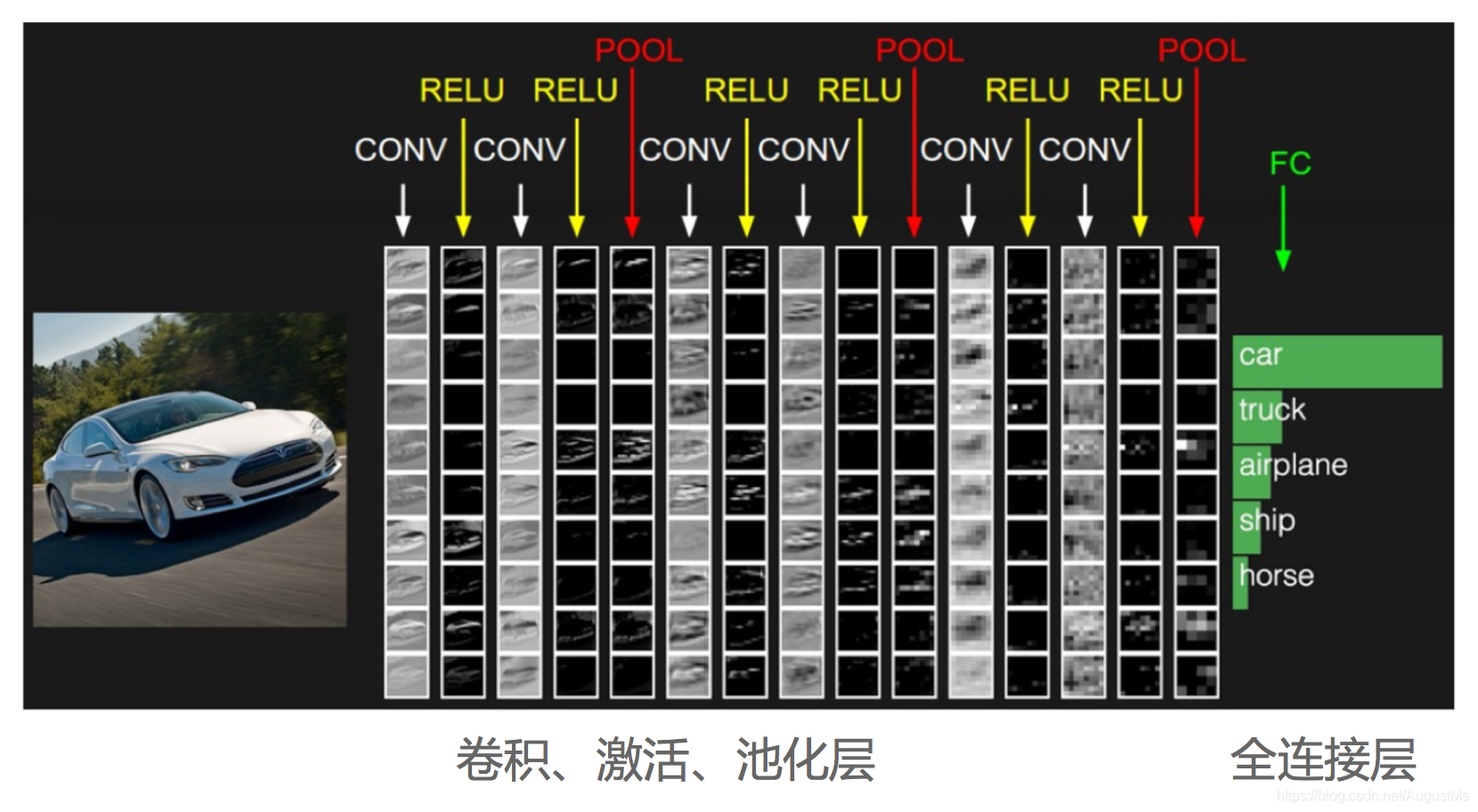
先来回顾下分类原理,这是一个常见的CNN组成图,输入一张图片,经过其中的卷积、激活、池化相关层,最后加入全连接层达到分类概率的效果。
分类的损失与优化:
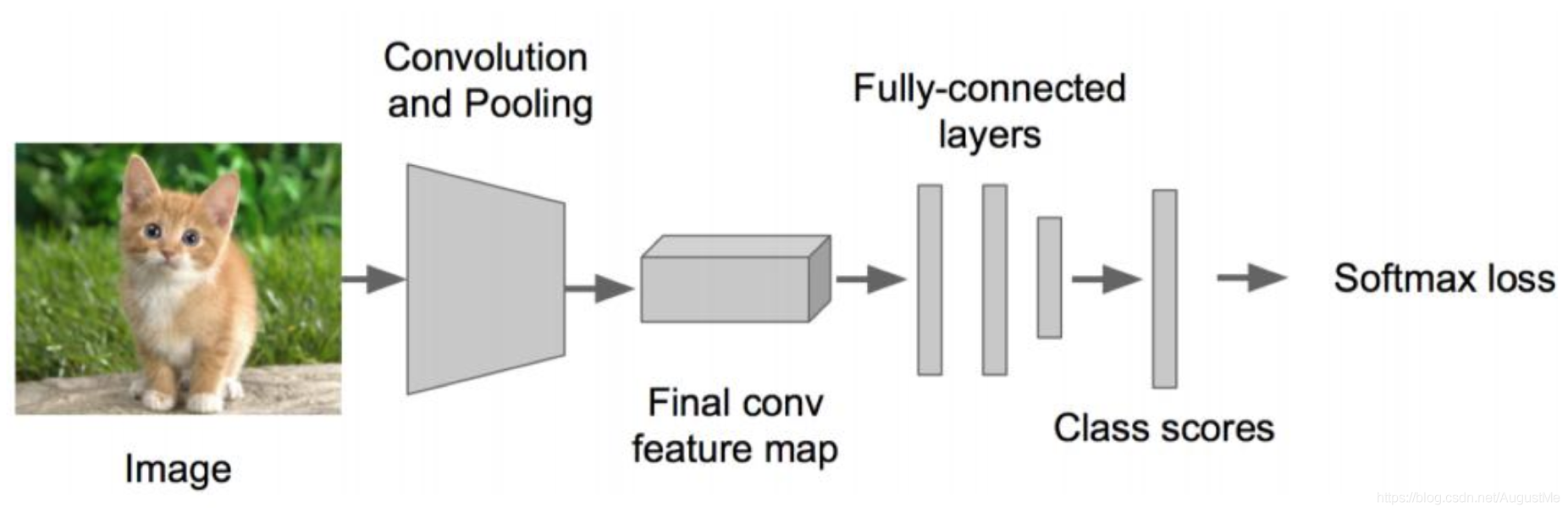
在训练的时候需要计算每个样本的损失,那么CNN做分类的时候使用softmax函数计算结果,损失为交叉熵损失。
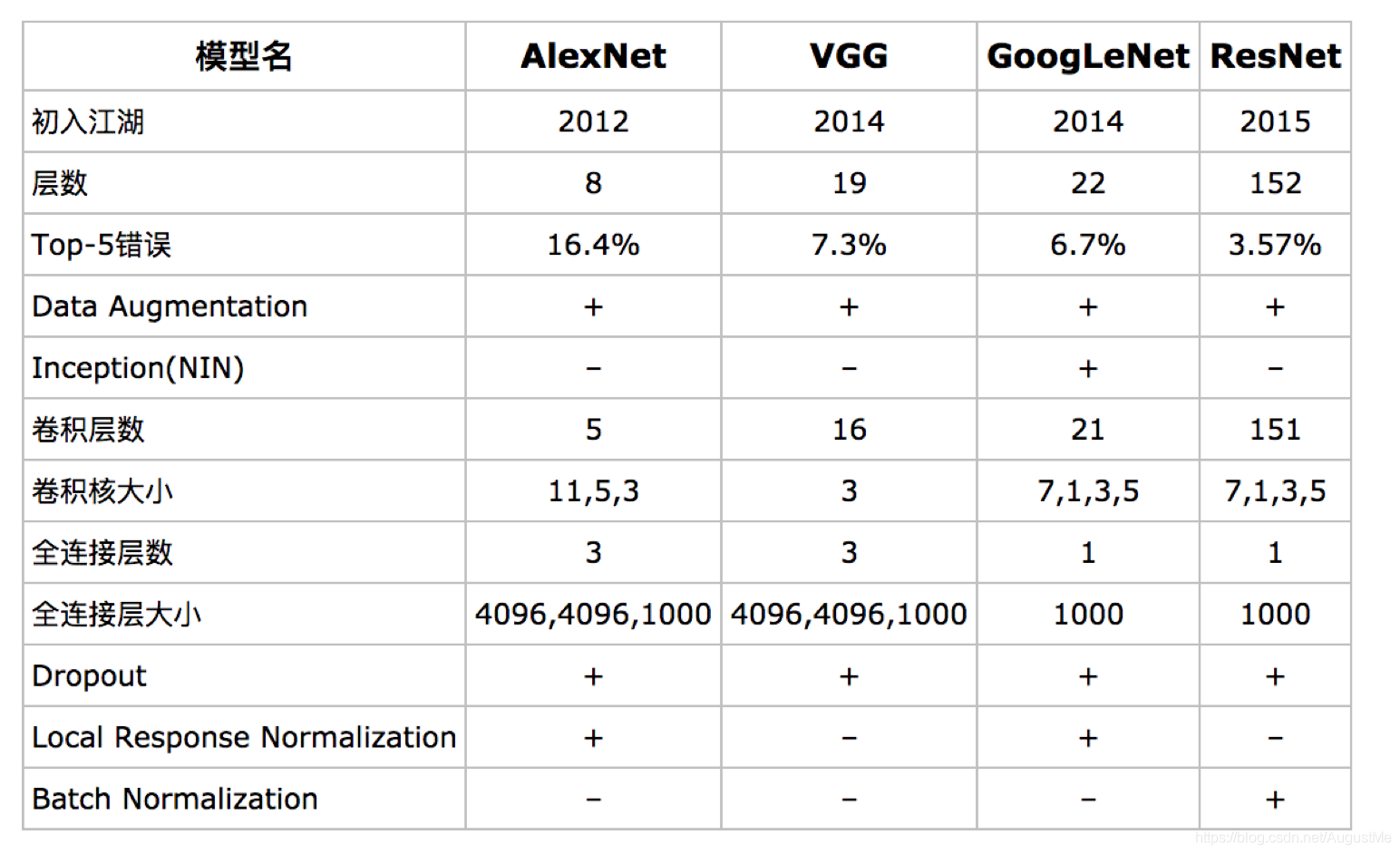
常见的CNN模型:
对于目标检测来说不仅仅是分类这样简单的一个图片输出一个结果,而且还需要输出图片中目标(物体)的位置信息,所以从分类到检测,过程如下:
分类:

分类+定位(只有一个目标的时候)

目标检测的任务
分类:
1)N个类别
2)输入:图片
3)输出:类别标签
4)评估指标:Accuracy

定位:
1)N个类别
2)输入:图片
3)输出:物体的位置坐标
4)主要评估指标:IOU

其中我们得出来的(x,y,w,h)有一个专业的名词,叫做bounding box(bbox)
两种Bounding box名称:
在目标检测当中,对bbox主要由两种类别名称
(1)Ground-truth bounding box:图片中真实标记框
(2)Predicted bounding box:预测的标记框
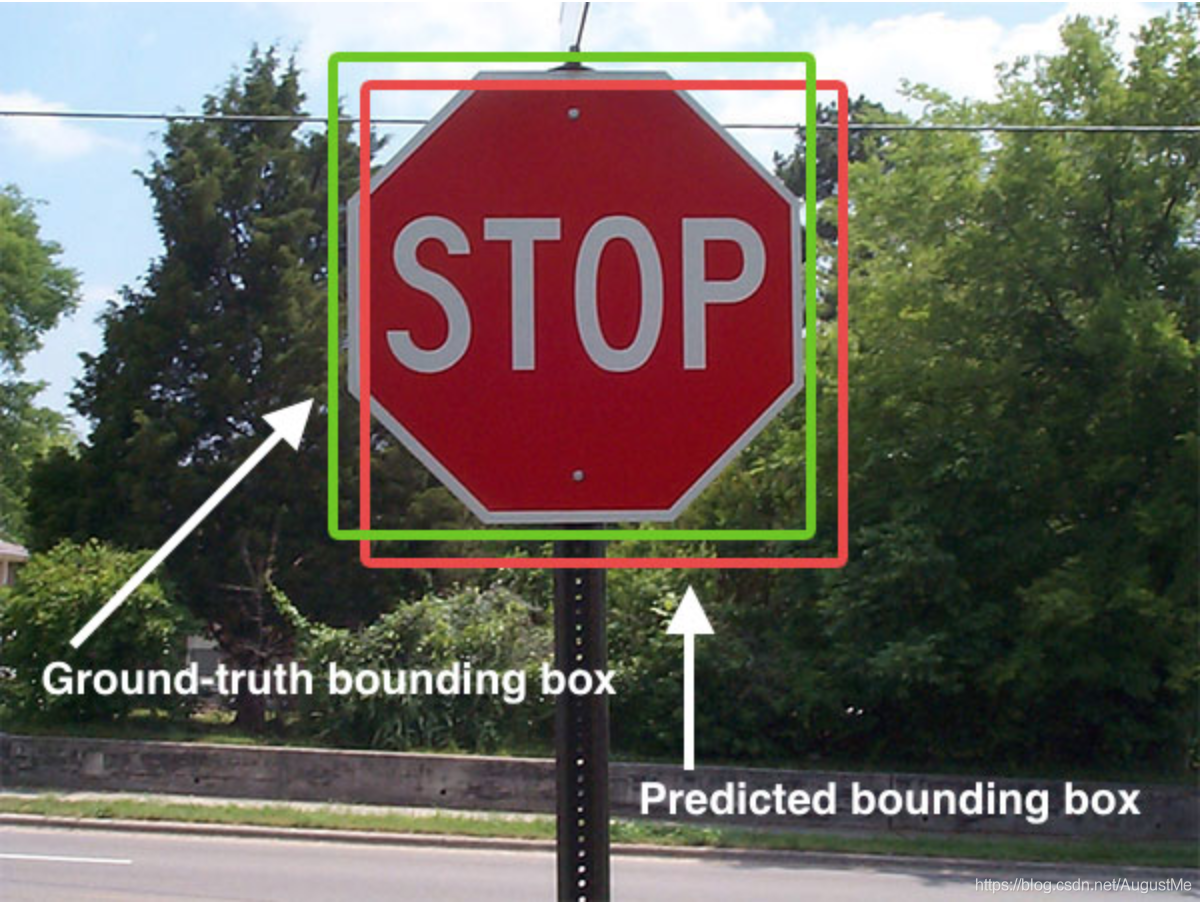
一般在目标检测任务当中,我们预测的框有可能很多个,真实的框GT也有很多个
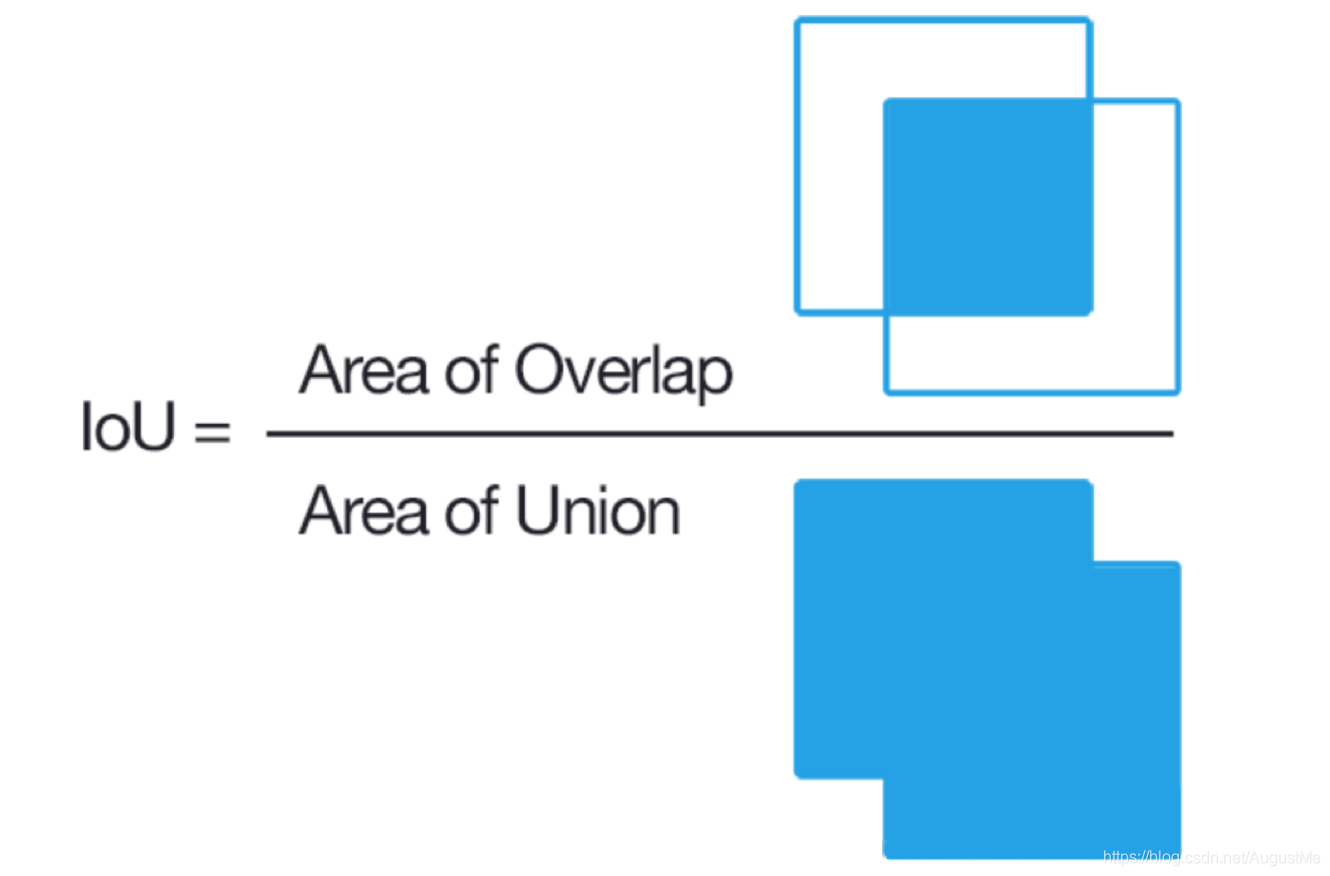
检测任务的评价指标:

IoU(交并比):
两个区域的重叠程度overlap:候选区域和标定区域的IoU值
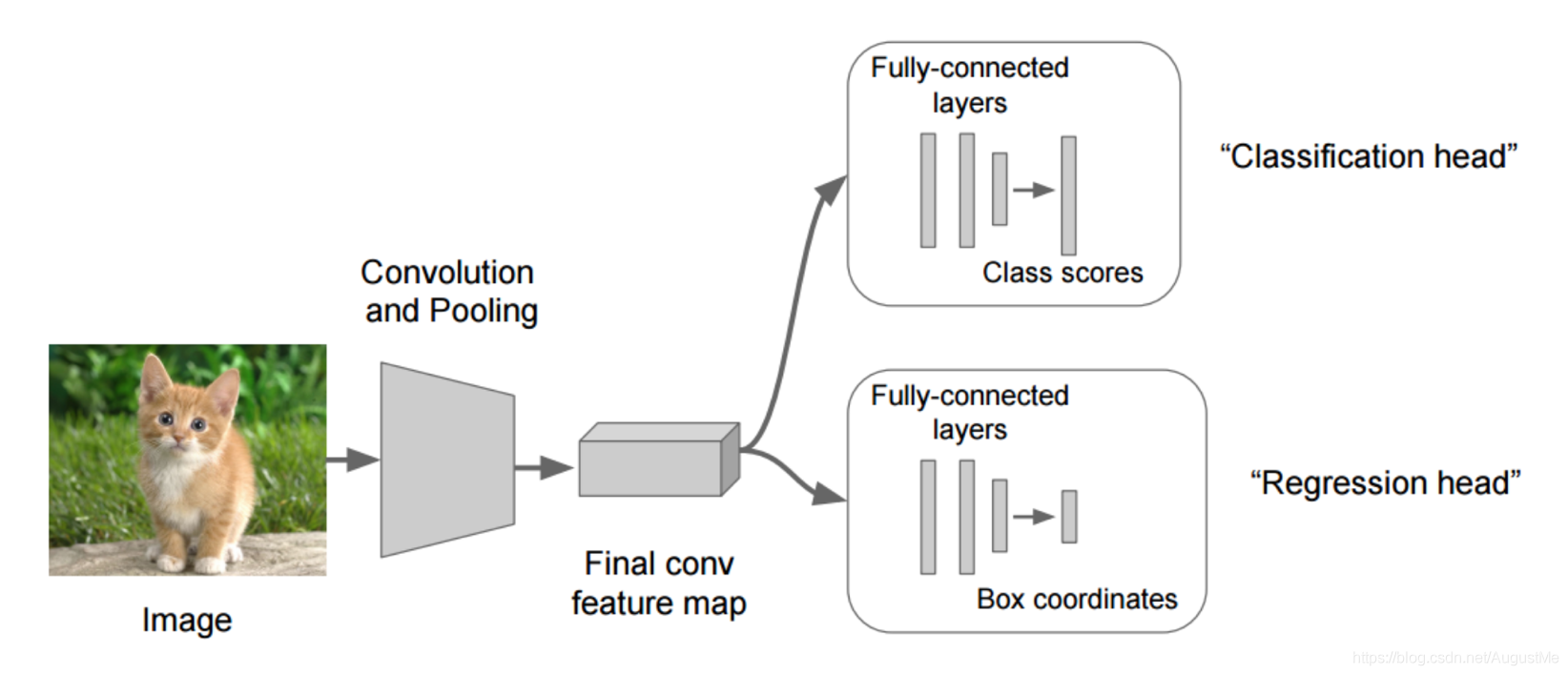
目标定位的简单实现:
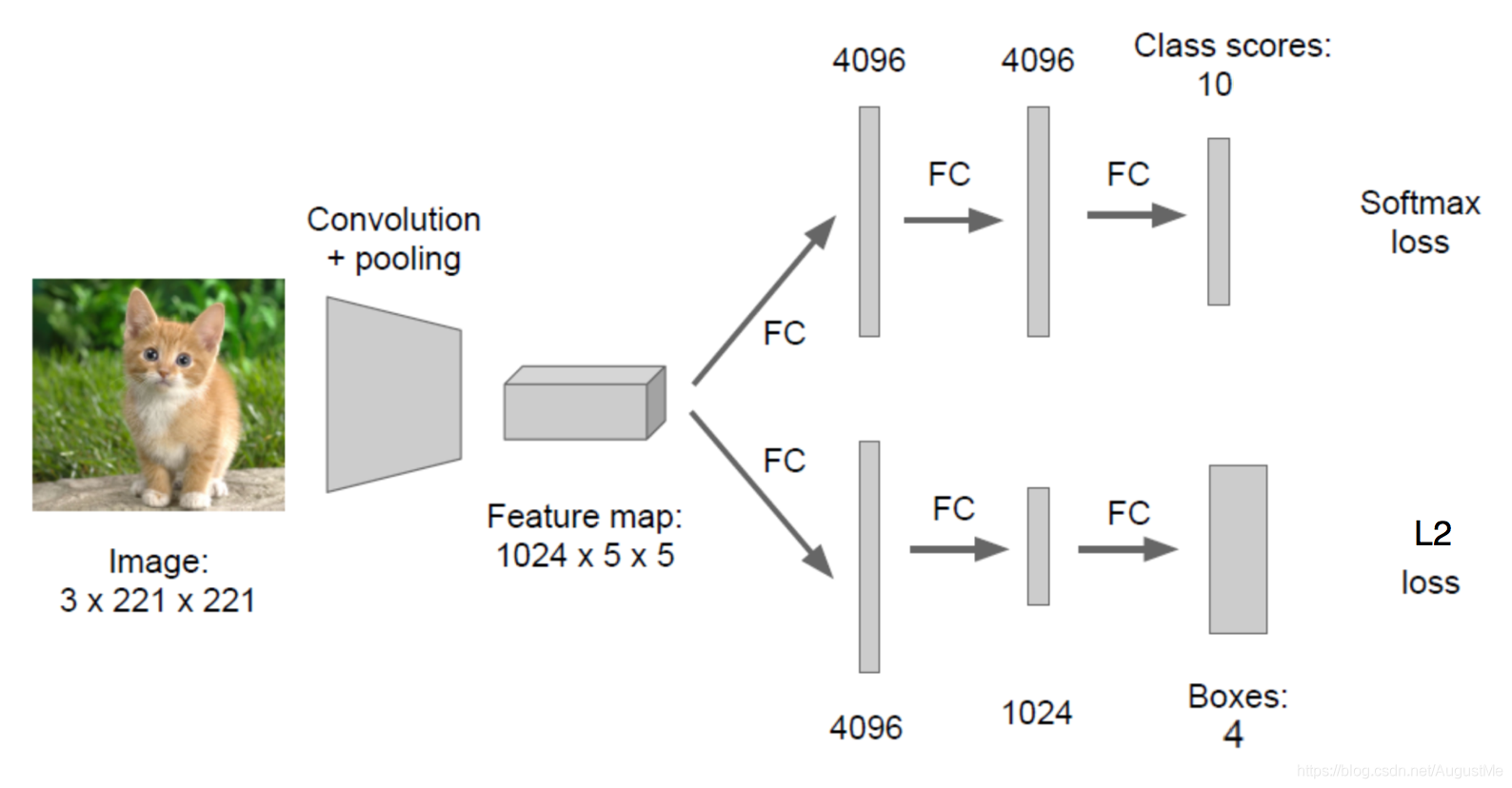
在分类的时候我们直接输出各个类别的概率,如果再加上定位的话,我们可以考虑在网络的最后输出加上位置信息。
回归位置:
增加一个全连接层,即为FC1、FC2
1)FC1:作为类别的输出
2)FC2:作为整个物体位置数值的输出
假设有10个类别,输出[p1,p2,p3,…,p10],然后输出这一个对象的四个位置信息[x,y,w,h]。同理知道要网络输出什么,如何衡量整个网络的损失。
对于分类的概率,还是使用交叉熵损失
位置信息具体的数值,可使用MSE均方误差损失(L2损失)
位置数值的处理:
对于输出的位置信息是四个比较大的像素大小值,在回归的时候不适合。目前统一的做法是,每个位置除以图片本身像素大小。
假设以中心坐标方式,那么x = x/x_image,y/y_image, w/x_image,h/y_image,也就是这几个点最后都变成了0~1之间的值(归一化)。
REF
https://zhuanlan.zhihu.com/p/34142321
https://blog.51cto.com/u_15279692/5521747
https://www.zhihu.com/question/509466878/answer/2699724857