
用python爬虫下载虎牙舞蹈区视频

公众号回复虎牙获取源代码
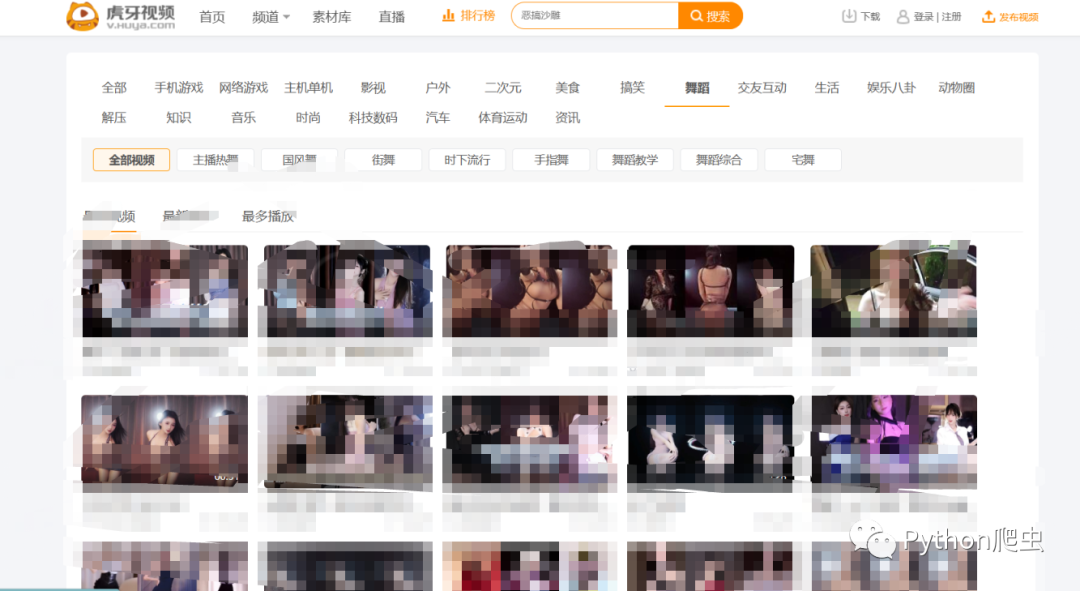
先看效果:
打开网站
点击一个视频,打开开发者模式
全局搜索一下标题
然后找到这个getM开头的文件
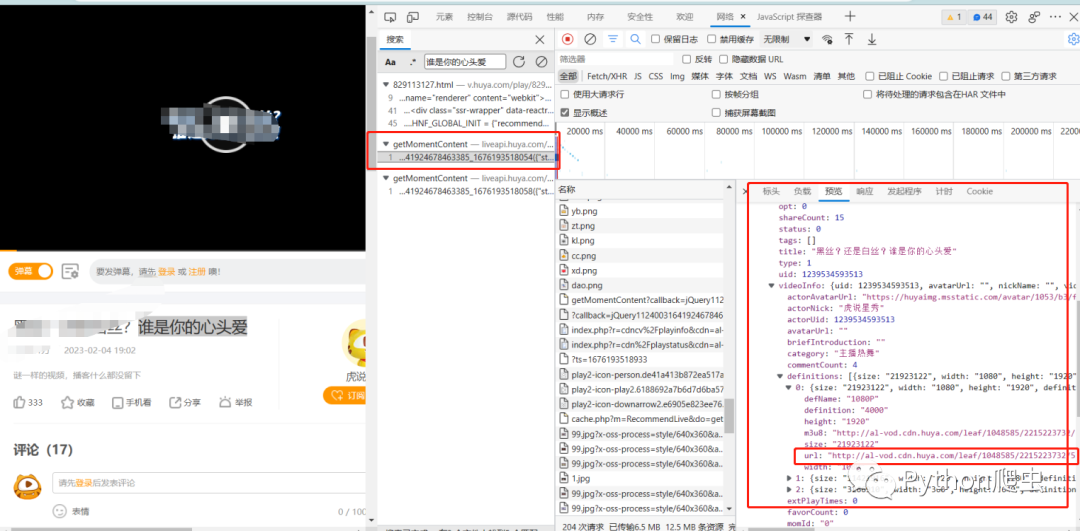
发现里面的信息就包含视频地址
然后查看它的负载信息和请求地址
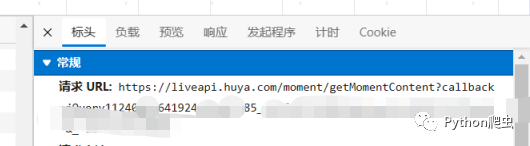
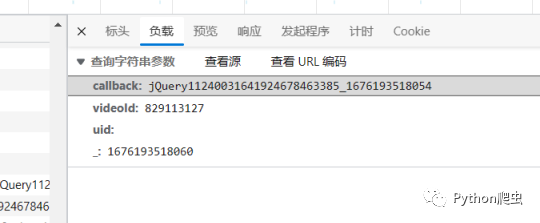
这几个参数不用管,videoid是视频id
可以改变它的参数获取不同的视频信息
接下来开始写代码
data_url = f'https://liveapi.huya.com/moment/getMomentContent?&videoId={vid}&uid=&_=1675864353143'
res = requests.get(url=data_url,headers=headers).json()
data = res
video_url = data['data']['moment']['videoInfo']['definitions'][0]['url']
content = requests.get(url=video_url,headers=headers).content
with open(f'虎牙/{title}.mp4','wb') as f:
f.write(content)
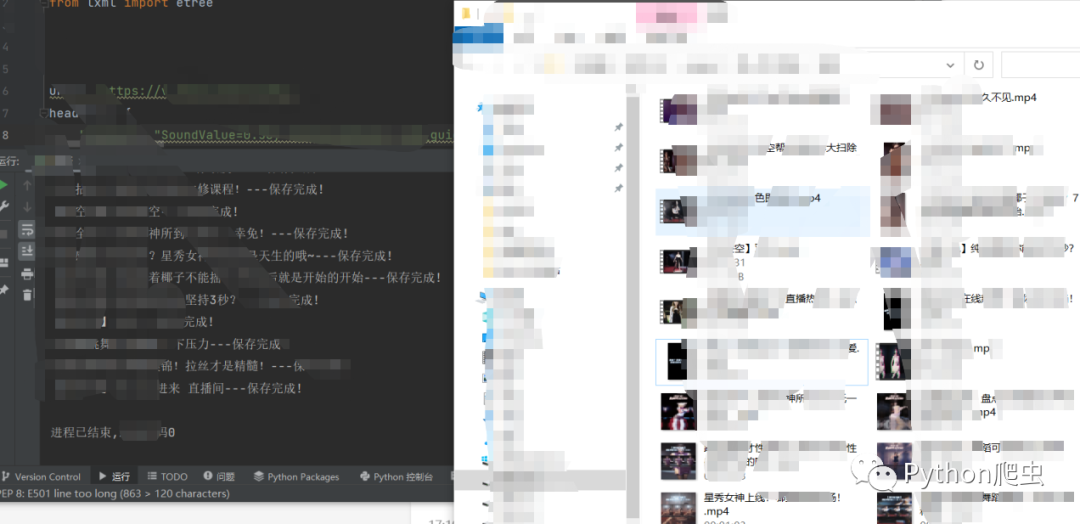
print(f'{title}''---保存完成!')这部分代码只能保存一个视频
我们需要
改变video的参数保存不同的视频
所以去首页提取所有的videoid
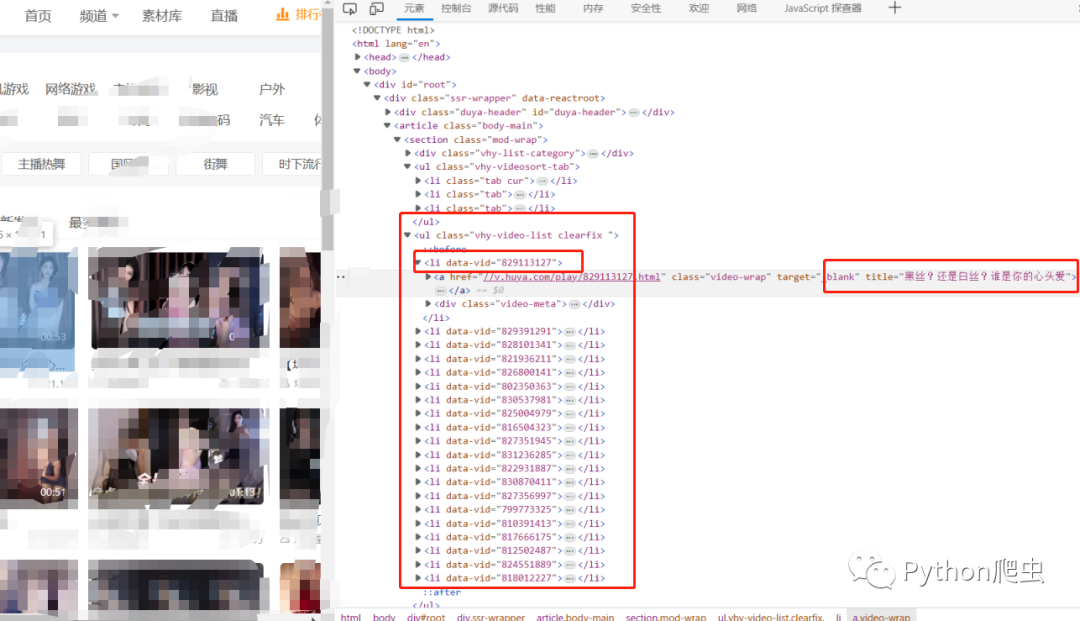
首页页面源码里包括了videoid和链接和标题
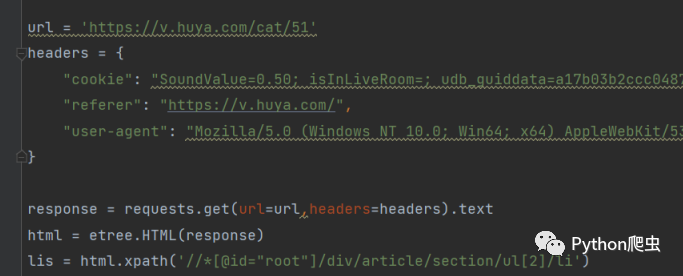
进行访问,获取源代码,
用xpath提取出来videoid和title
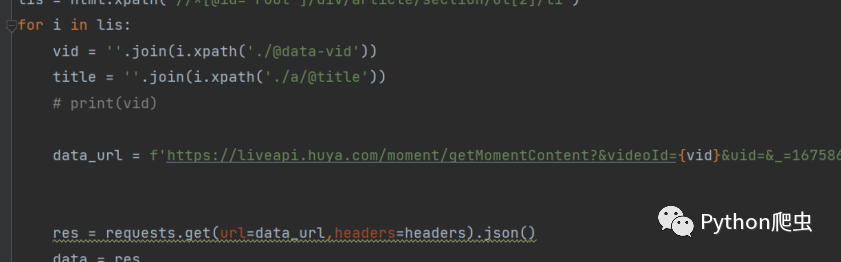
然后在开始访问就可以保存更多的视频了

公众号回复虎牙获取源代码
代码仅供学习参考
感谢观看!