
简单的爬取一个网站
文案网--不烂大街的救赎文案精选
获取文案
效果:

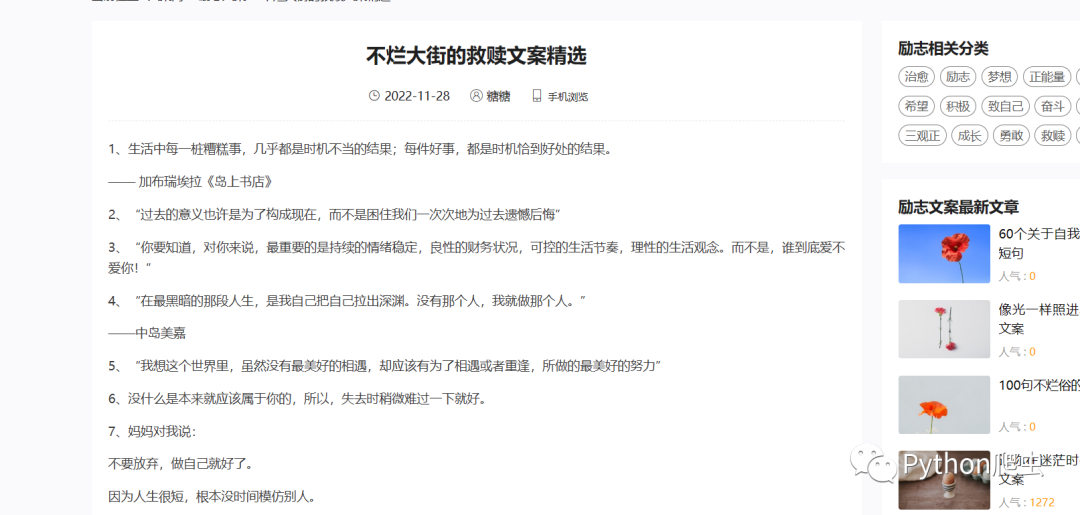
网站地址:
https://www.wenanwang.com/lz/1764.html内容就放在源文件当中
所以比较简单
直接访问
url = 'https://www.wenanwang.com/lz/1764.html'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50'
}
# 访问
res = requests.get(url=url,headers=headers)拿到源代码之后
用bs4解析提取
bs4解析方法就是通过标签名和属性值来定位的
意思是:定位到第一个标签为div,class属性值为content 的所有的p标签
lis = soup.find_all('div',class_='content')[0].find_all_next('p')
soup = BeautifulSoup(text,'html.parser')
# 提取所有的文案
lis = soup.find_all('div',class_='content')[0].find_all_next('p')返回一个列表
循环打印
# 逐个打印
for li in lis:
print(li.text)看效果
以下是完整代码
import requests
from bs4 import BeautifulSoup
url = 'https://www.wenanwang.com/lz/1764.html'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50'
}
# 访问
res = requests.get(url=url,headers=headers)
# 设置编码
res.encoding='utf8'
text = res.text
# 使用bs4解析
soup = BeautifulSoup(text,'html.parser')
# 提取所有的文案
lis = soup.find_all('div','content')[0].find_all_next('p')
# 逐个打印
for li in lis:
print(li.text)