
Few-Shot 3D Point Cloud Semantic Segmentation via Stratified Class-Specific Attention Based Transformer Network
基于分层类特定注意的Transformer网络的小样本三维点云语义分割
arXiv · Computer Vision and Pattern Recognition(2023)
摘要
3D点云语义分割旨在将所有点分组为不同的语义类别,这有利于点云场景重建和理解等重要应用。现有的监督点云语义分割方法通常需要大规模的注释点云进行训练,并且不能处理新的类别。虽然最近提出了一种小样本学习方法来解决这两个问题,但由于图的构建和池化操作的使用,它的计算复杂度很高,无法学习点之间的细粒度关系。在本文中,我们通过开发一种新的用于小样本点云语义分割的多层变换器网络来进一步解决这些问题。在所提出的网络中,基于不同规模的类特定支持特征来聚合查询点云特征。在不使用池化操作的情况下,我们的方法充分利用了支持样本中的所有像素级特征。通过更好地利用对小样本学习的支持特征,与S3DIS数据集和ScanNet数据集上现有的小样本3D点云分割模型相比,所提出的方法实现了新的技术性能,推理时间减少了15%。
引言
(3D)点云通常由3D扫描仪产生,在许多计算机视觉和计算机图形学应用中发挥着重要作用。在给定复杂场景的情况下,捕捉到的点云可能会混合许多不同的对象、结构和背景。为了更好地重建和理解场景,关键的一步是点云语义分割,将每个点分类到其底层语义类别中。最近最先进的点云语义分割方法主要基于监督深度学习(Li et al 2018;Qi et al 2016;Hu et al 2020a;Liu et al2019, 2021; Xu等人(2021)。然而,这些方法有两个主要的局限性:1)它们依赖于大规模的训练数据,这需要昂贵而费力的手动注释;2)训练后的模型无法分割训练过程中没有看到的新类别。
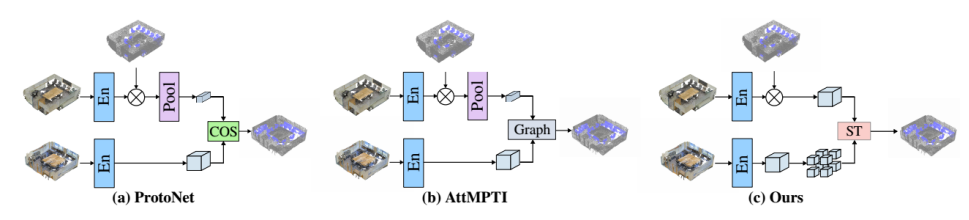
通过使用一些标记的支持示例作为指导,少镜头学习可以很好地解决这两个限制,并已被证明在图像分割中是有效的(Zhang等人2019;Wang等人2019a;Vinyals等人2016). 具体地说,通过将要分割的样本作为查询,可以使用标记的支持数据来计算原型,然后通过测量原型和类似的查询特征之间的距离来执行查询的分割。这可以扩展到点云分割,如图1(a)所示。最近,AttMPTI(Zhao、Chua和Lee,2021)首次尝试通过利用图形网络计算原型与查询中的点特征之间的距离来部署点云语义分割的fewshot方法,如图1(b)所示。然而,这种方法在计算上是昂贵的——在实践中,点云通常包含大量的点,从而导致非常大的图。该方法的另一个问题是使用池操作来计算原型——它限制了支持样本的表示(Zhang等人,2021)。由于全局特征和局部特征对于语义分割都是必不可少的,因此池化操作后的原型无法从支持中完全捕获不同的局部语义信息,并且当特征被挤压时可能会引入噪声。
为了解决这些问题,我们提出了一种新的使用transformer网络进行点云语义分割的小样本学习方法(Dosovitskiy et al 2020),该方法具有通过自我注意学习长期数据依赖性的强大能力。在从支持和查询点云中提取特征后,我们应用transformer来探索支持和查询之间特定于类的关系。在没有池化操作的情况下,我们可以获得所有支持类别点和查询中的点之间的密集关系。最近,基于CNN的模型(Huang et al 2017;Lotter、Sorensen和Cox 2017;Gong et al 2014)通过多尺度技术显示出更好的性能。按照这个想法,我们以三种不同的比例表示查询(点云),并将它们输入到三个转换器层中,如图1(c)所示。通过这种方式,以分层的方式计算查询和支持特性之间的距离,这有助于模型学习粗略和细粒度的关系。然后对结果特征进行聚合,以生成查询样本的最终条件。
对于绩效评估,我们进行全面的在各种少镜头设置中对广泛使用的S3DIS(Armeni等人,2017)和ScanNet(Dai et al,2017)数据集进行的实验。在S3DIS数据集上,我们提出的网络在单次设置中将平均IoU提高了约3%,在五次设置中提高了约1%。在ScanNet数据集上,我们的模型可以在一次拍摄设置中将平均IoU提高约2%,在五次拍摄设置中将平均IoU提高约1.5%。在相同的设置下,所提出的方法可以将CPU推理时间减少约15%。
总之,我们的贡献如下:•我们通过引入分层变换器网络,为3D点云语义分割引入了一种新的小样本学习方法。
•我们设计了一个网络来聚合查询的多尺度特征,条件是标记的支持样本,以更好地探索它们的关系。
•我们进行了全面的实验,以验证我们提出的方法比现有的小样本学习方法更高效,所有提出的网络设计都有助于提高性能。
2相关工作
点云语义分割3D点云由多个具有X、Y和Z坐标的单个点组成。有时,每个点还包含RGB颜色和强度信息,这取决于用于捕捉点云的传感器。众所周知的点云公共数据集包括ShapeNet(Chang等人2015)、ModelNet40(Wu等人2015)和KITTI(Geiger等人2013),以及各种手动注释。由于深度神经网络的快速发展,已经提出了许多有监督的点云处理方法(Atzmon,Maron,and Lipman 2018;Hu等人2020b年;Jiang等人2019;Landrieu和Simonovsky 2018;Lei、Akhtar和Mian 2020;Liu等人2019年、2021;Xu等人2021).
3D点云语义分割的目标是将点云场景划分为不同的有意义的语义部分,这引起了人工智能和视觉社区的极大兴趣。PointNet(Qi等人,2016)采用对称MLP层来聚合所有点信息,用于分类和分割。PointNet++(Qi等人,2017)使用度量空间距离随着上下文尺度的增加进一步学习局部特征。PointCNN(Li et al 2018)对与点相关的输入特征进行加权,并将点排列成规范顺序。
DGCNN(Wang et al 2019b)利用更了解基于CNN的高级任务的EdgeConv来促进点云分割,并且它可以迭代地学习局部和全局点云信息。RandLA-Net(Hu等人,2020a)使用轻量级神经网络来处理大规模点云数据,显著加快了推理时间。
所有这些方法都需要许多带有标记地面实况的点云来进行网络训练。不同的是,我们的方法遵循小样本学习的思想,只使用几个标记的3D点云样本作为训练和测试的样本。
小样本语义分割为了减轻像素级的标注负担,小样本学习已被广泛用于二维图像的语义分割。OSLSM(Shaban等人,2017)使用完全卷积网络来分割新类别的图像,使用很少的支持数据作为指导。PANet(Wang et al 2019a)将小样本分割视为一个度量学习问题,并使用原型对准网络来探索支持图像背后的信息。CANet(Zhang等人2019)使用密集比较模块来获得基于支持图像的粗略预测,以及使用几个迭代优化模块来细化该预测。
最近,小样本学习技术也被用于三维点云语义分割——AttMPTI(Zhao、Chua和Lee,2021)提出了一种基于图的小样本网络来分割点云。受AttMPTI的启发,本文通过开发一种从不同维度聚合点云特征的新方法,进一步推进了小样本点云语义分割。
我们的方法
概述
给定很少的支持点云(支持),很少的查询点云语义分割旨在分割查询点云中相应的语义类别。在训练过程中,我们的模型试图学习用于构建支持和查询之间的语义关系的最佳参数。在测试过程中,经过训练的模型可以适应新的类别,并在几个标记的支持点云的帮助下对查询点云进行分割。
为了方便起见,我们首先在one-shot(即一个支持点云)、one-way(即一种感兴趣的语义类和背景)设置中介绍了我们提出的方法,并在稍后讨论了它对更通用的multi-shot, multi-way设置的扩展。如图2所示,整个模型的输入由查询点云P Q∈R Nq×C和支持点云P S∈R Ns×C组成,对应的标签为MS∈{0,1}Ns×1,其中Nq和Ns是每个点云中的点数,C是每个点的特征数,包括坐标和可能的颜色通道。
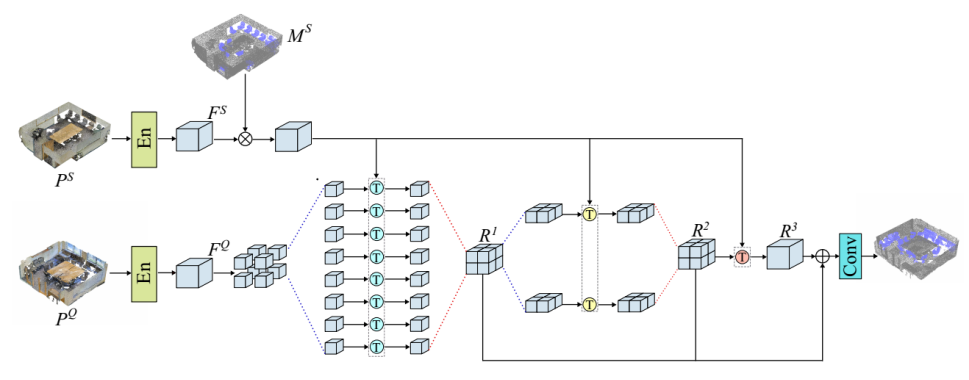
查询点云标签MQ∈R Nq×1是用于训练和评估的基本事实。在第一步中,使用两个权重共享编码器分别生成支持点云特征FS∈RN×D和查询点云特征F Q∈R Nq×D,其中D是编码特征的通道数。
在我们的实验中,我们选择了DGCNN(Wang等人2019b)作为我们的编码器,它由三个EdgeConv层组成,用于聚合点特征,可以迭代学习局部和全局3D信息。然后,新提出的分层变换网络在不同尺度上的类特定支持特征MS F S和F Q之间建立类特定注意力。在接下来的部分中,我们首先介绍了分层体系结构,然后详细介绍了基于类特定注意力的转换器。最后,我们将所提出的方法扩展到多镜头和多路设置。
分层Transformer架构
在小样本点云分割中,现有工作(Zhao、Chua和Lee 2021)仅在支持分支和查询分支之间建立了单层关联,这不足以构建准确的关联。在我们的工作中,从不同的角度来看,我们通过使用分层转换器架构来利用支持和查询之间的细粒度和粗粒度关系,如图2所示。
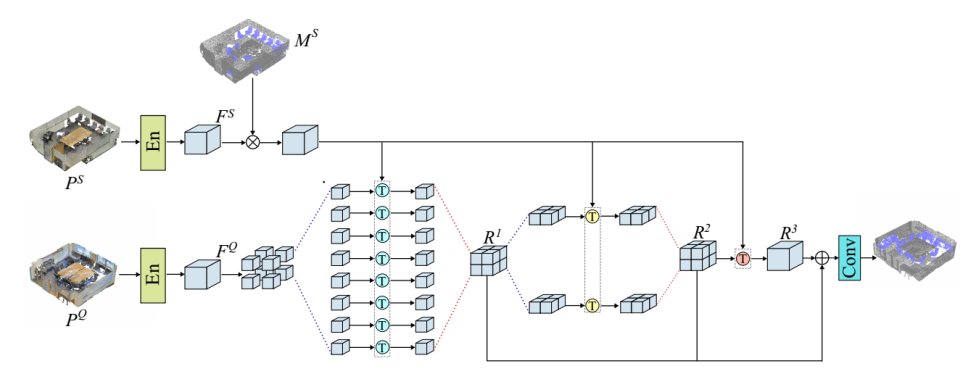
更具体地说,根据点的空间位置,查询点云被划分为几个小的点云,然后是三个Transformer层,以在多个尺度上聚合点云特征。在每一层中,Transformer块都是权重共享的,以减少参数的数量并提高训练速度。
为了分割查询点云,我们首先计算XYX轴对齐的三维矩形边界框,该边界框紧密覆盖所有查询点。然后,我们在每一边的中点处将这个盒子均匀地划分为2×2×2=8个较小的盒子。位于每个较小框中的查询点形成一个新的点云,具有相应的特征F1 i∈R Ni×D,i=1,2。。。,8,其中Ni是第i个小方框中的点数。第一层中的Transformer将每个划分的点云特征F1 i与特定于类的支持特征MS F S聚合,以生成特定于类关注,从而产生特定于类表示。然后,根据它们的原始3D位置将所有类别特定的表示R1i级联,以获得输出R1。之后,级联表示R1沿z轴(即高度)等分为两部分,得到F2 i∈R Ni×D,i=1,2,分别对应于捕获场景的上半部分和下半部分。
顶部-底部划分的动机是室内点云特征,即顶部和底部通常包含不同的对象。每个F2 i通过第二变换器层与MS F S聚合,然后将场景的上半部分和下半部分的输出级联,以获得第二类特定表示R2。
转换器的最后一层将R2和MS F S作为输入,并生成第三查询聚合表示R3。通过以上三个变换器层,R1、R2和R3实际上代表了多尺度的特征。我们将它们加在一起,并进一步应用两个1D卷积层和一个softmax层来获得最终的预测P预测∈RN×1。在训练中,我们采用了交叉熵CE损失:
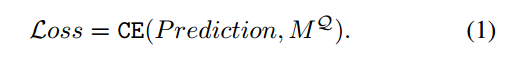
基于类特定注意力的Transformer Block少镜头语义分割的核心是找到查询和支持特征之间的匹配区域。以前的作品(赵、蔡、李2021)在进行池操作后,只使用了单个原型,忽略了大量匹配信息。在这项工作中,我们使用transformer块来构建支持和查询点云特征之间的逐点关系,以实现更好的匹配。
首先,每个生成的查询点云特征F∈{F1 1,F1 2,··,F1 8,F2 1,F2 2,F3}将像标准变换器中一样经过一个自注意层(Vaswani et al 2017). 这个自注意层可以帮助我们的模型关注每个生成的F内部的特征分布。然后,所提出的基于特定类别注意的变换器将处理后的F和特定类别的支持特征MS F S作为输入。对于基于类别特定注意力的块,我们使用三个不同的线性层来构造Q、K和V:
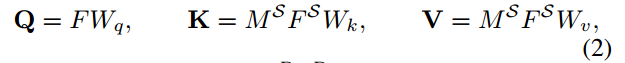
其中Wq,Wk,Wv∈RD×Da是可学习的参数,用于将输入特征投影到潜在空间中,Da是变换器块中的通道数。
在每个头部中,transformer将Q和K相乘以获得注意力图,该注意力图可以表示类特定特征和输入查询特征之间的相似性。将注意力图乘以V以将注意力图转移到原始特征维度。从数学上讲,第h个头可以通过以下公式计算:
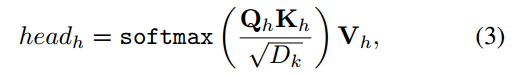
其中Dk是Kh的信道号,softmax表示用于注意力归一化的逐行softmax层。所有头的输出被组合在一起,并与原始输入点云特征F相加。最终的类特定表示R通过以下公式计算:
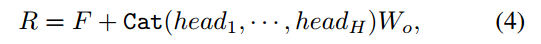
其中H是头的数量,Wo∈R-Da×D是可学习的,它将输出投影到原始形状,Cat是级联运算。
多镜头多路设置
为了将所提出的方法从one-shot设置扩展到multi-shot设置,我们所需要做的就是更新特定类别的支持功能MS F S,以适应所有的支持点云。更具体地说,我们将每个支撑的特征乘以其对应的掩码,然后将所有这些特征连接起来,即,我们得到MS F S∈RW×D,其中W是所有支撑的点数总和。除此之外,所提出的方法的所有其他步骤以及损失函数与前面讨论的一次性设置完全相同。
对于多路分割,即从查询点云中分割多个语义类别,我们独立地考虑每个类别。对于每个类别,我们计算其特定类别的特征,并应用我们的方法来获得其分割预测——变换器对不同类别采用不同的K和V。然后将所有类别的预测连接在一起,并通过softmax层来获得最终的多路分割预测。