
本期文章通过三个动手实验从浅到深地解读和演示大语言模型(LLMs),如何结合 Amazon SageMaker 的模型部署、模型编译优化、模型分布式训练等方面。
实验一:使用 Amazon SageMaker 构建基于开源 GPT-J 模型的对话机器人应用
开发者可以使用以此来对大语言模型有更深刻的认知。
这一动手实验仅仅使用基于大语言模型的简单交互式人机对话。完成该实验的代码编写和模型部署预计需要
什么是GPT-J:
GPT-J 是一种生成式预训练(GPT)大语言模型,就其架构而言,它可与
本实验参考代码的GitHub 地址:
https://github.com/hanyun2019/aigc/blob/main/deploy-gptj.ipynb
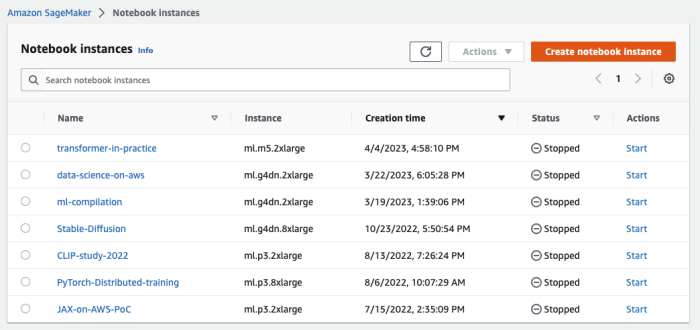
1. 创建 SageMaker Notebook 实例
在亚马逊云科技控制台(console.aws.amazon.com)上,输入 “Amazon SageMaker” 并点击进入,然后在左侧导航菜单中找到 “Notebook instances”,点击右上角的 “Create notebook instance” 开始创建。如下图所示:
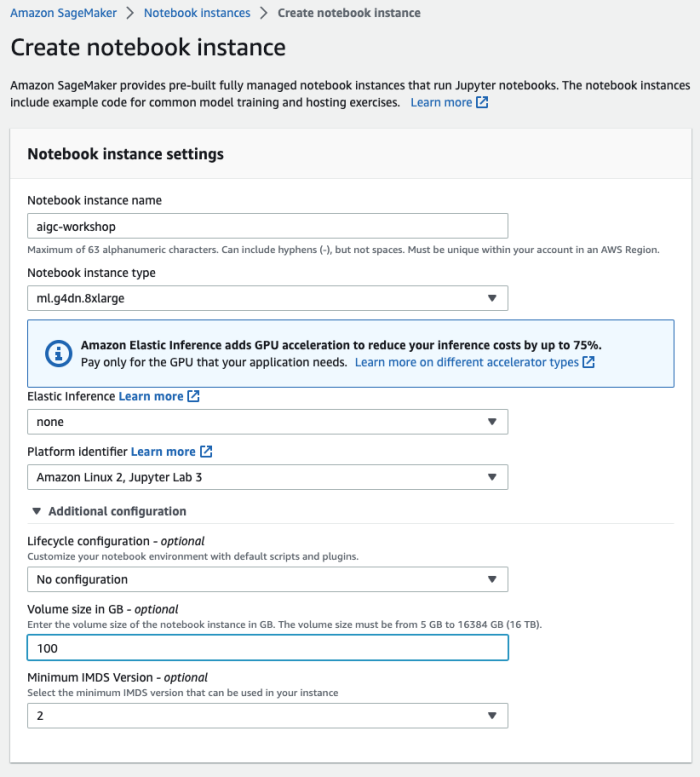
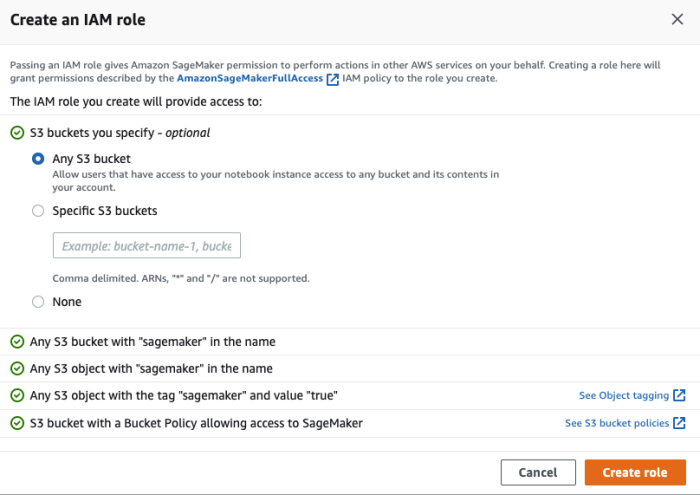
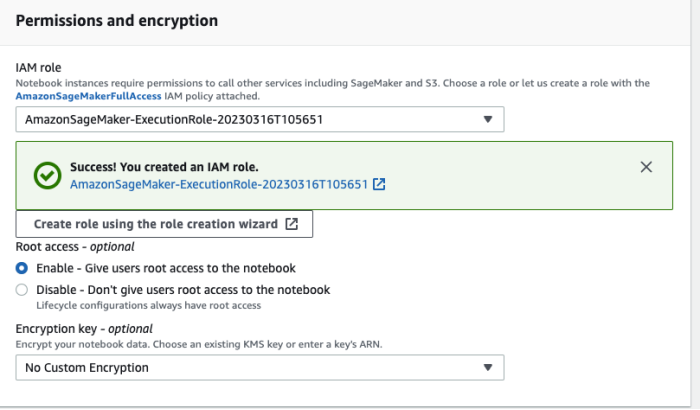
在创建Notebook instances 的过程中,需要指定在 Amazon SageMaker 中运行代码的角色(role)。由于需要访问 Amazon S3 等资源(存放模型训练需要的数据、模型构件等),因此必须设置合适的角色(role)使其具有访问相关 Amazon S3 的权限。如下图所示:
提交后等待几分钟,可以看到状态变成 “InService”,即表示该实例已经成功创建。如下图所示:

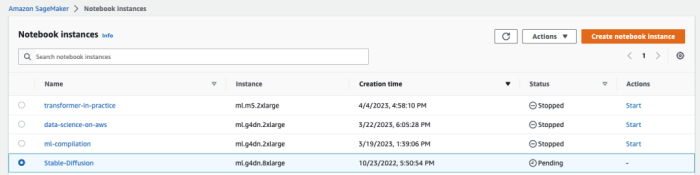
如果之前已经创建过(并且没有 delete),可以直接点击 ”Start” 重新启动实例。如下图所示:
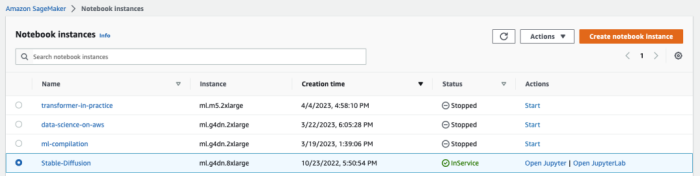
当状态从 “Pending” 变成 “InService”, 即表示该实例已经成功启动。如下图所示:
2. 进入 Open Jupyter/JupyterLab 环境
如下图,点击 Open Jupyter 或者 Open JupyterLab 环境。我个人更喜欢 Open JupyterLab,因此本文中会主要以 Open JupyterLab 来做讲解和演示:

点击 “Terminal”,以打开一个终端:
在打开的终端中输入以下命令:
$ pwd
$ cd SageMaker
$ git clone https://github.com/hanyun2019/aigc.git输出如下:
这时你会看到左侧菜单栏增加了 “aigc” 目录:
该目录下的文件如下图所示:
双击“deploy-gptj.ipynb” 打开这个文件,即可开始逐步完成实验一:
3. 使用 Amazon SageMaker 构建基于开源 GPT-J 模型的对话机器人应用
以下逐行解释实验一的主要代码。
首先,需要安装SageMaker 的相关 SDK:
!pip install -U sagemaker然后import 实验需要的 HuggingFace API 和 SageMaker 的 API 包:
from sagemaker.huggingface import HuggingFaceModel
import sagemaker定义创建终端节点的IAM 角色权限:
# IAM role with permissions to create endpoint
role = sagemaker.get_execution_role()定义GPT-J 模型构件所在的 S3 桶:
# public S3 URI to gpt-j artifact
model_uri="s3://huggingface-sagemaker-models/transformers/4.12.3/pytorch/1.9.1/gpt-j/model.tar.gz"调用HuggingFace API 来创建模型相关参数,包括:模型构件文件名、transformers 的版本号、PyTorch 的版本号、Python 的版本号、角色名等:
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=model_uri,
transformers_versinotallow='4.12.3',
pytorch_versinotallow='1.9.1',
py_versinotallow='py38',
role=role,
)以上设置完毕后,即可部署模型到Amazon SageMaker 的终端节点了。可以在这里设置一些终端节点的参数,比如节点实例数量、节点类型等:
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1, # number of instances
instance_type='ml.g4dn.xlarge' #'ml.p3.2xlarge' # ec2 instance type
)运行以上“huggingface_model.deploy” 代码后,会在 Amazon SageMaker 控制台的 “EndPoints” 看到有实例正在创建(Creating)中,如下图所示:

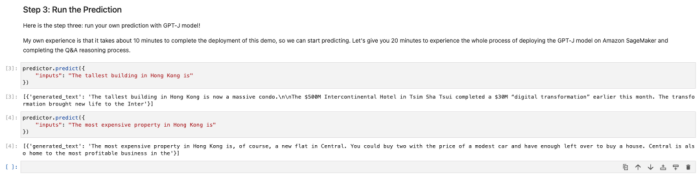
当看到实例创建完成(InService),即可开始进行推理,即开始和聊天机器人对话了!

如下图所示,我们询问的是中国香港地区的最高建筑、最贵物业等信息。你可以自己定义问题,从中获得和大模型(GPT-J)聊天机器人对话的乐趣!
特别提醒:完成该实验后,记得删除终端节点,以避免不必要的终端节点收费。如下图所示:

实验二:使用 Amazon SageMaker 优化 GPT-2 模型的编译训练
该动手实验的目标是使用Amazon SageMaker 训练编译器(Training Compiler)的功能,在 Stanford Sentiment Treebank v2 (SST2) 数据集上优化 GPT-2 模型的编译和训练。
大语言模型基本都由复杂的多层神经网络组成,具有数十亿以上的参数,可能需要数千个GPU 小时甚至更多时间才能完成训练。因此,在训练基础架构上优化此类模型需要丰富的深度学习和系统工程知识。尽管有些编译器的开源实现可以优化训练过程,但它们可能缺乏与某些硬件(例如 GPU 实例)集成的灵活性。Amazon SageMaker 训练编译器可以将深度学习模型从其高级语言表示形式转换为经过硬件优化的指令,从而加快大语言模型的训练速度,帮助减少总计费时间。
在该动手实验中,我们将一起体验如何在 Amazon SageMaker 中设置环境,包括权限设置、配置设置等。然后,我们将体验如何使用 Amazon SageMaker 训练编译器,在 SST2 数据集上训练 GPT-2 模型。Amazon SageMaker 训练编译器已集成到 Amazon 深度学习容器(DLC)中,使用这些容器在 GPU 实例上编译和优化 GPU 实例上的训练作业,只需对代码进行最少的更改。通过此实验,可以对大语言模型进行进一步的理解。
Amazon SageMaker 训练编译器参考文档:
https://docs.aws.amazon.com/sagemaker/latest/dg/training-compiler.html
本实验参考代码的GitHub 地址:
https://github.com/hanyun2019/aigc/blob/main/gpt-2.ipynb
1. Amazon SageMaker 训练编译器(Training Compiler)概述
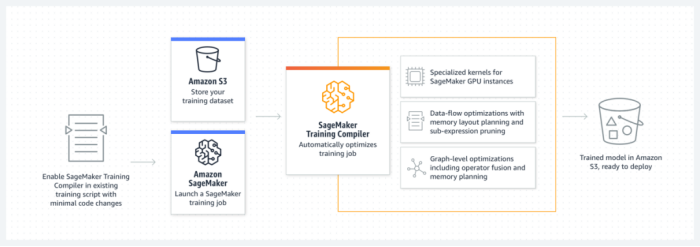
Amazon SageMaker 训练编译器是 SageMaker 的一项优化功能,该优化功能可以帮助缩短 GPU 实例上的训练时间,该编译器通过更高效地使用 GPU 实例来加速训练过程。Amazon SageMaker Training Compiler 在 SageMaker 中是免费提供的,它可以加快训练速度,从而帮助减少总计费时间。
SageMaker 训练编译器已集成到 Amazon 深度学习容器 (DLC) 中。使用支持 SageMaker 训练编译器的 Amazon DLC,您可以在 GPU 实例上编译和优化 GPU 实例上的训练作业,只需对代码进行最少的更改。
有关更多信息,请参阅《Amazon SageMaker 开发者指南》中的 SageMaker 训练编译器部分:
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/training-compiler.html
2. 实验准备和数据集
在本实验中,你将使用 Hugging Face 的 transformers 和数据集库,与 Amazon SageMaker Training Compiler 在 Stanford Sentiment Treebank v2 (SST2) 数据集上训练 GPT-2 模型。请注意,使用此 notebook 将从 https://huggingface.co/datasets/sst2 下载 SST2 数据集,并可以在那里查看数据集信息和条款。
首先,我们需要通过一些先决步骤来设置环境,例如权限、配置等。
注意:
你可以在 Amazon SageMaker Studio、Amazon SageMaker notebook 实例(即现在我们在使用的方式)或设置了 Amazon CLI 的本地计算机上运行这个实验代码。如果使用 Amazon SageMaker Studio 或 Amazon SageMaker notebook 实例,请确保分别选择基于 PyTorch 的内核之一,即 PyTorch 3 或 conda_pytorch_p38
本 notebook 使用了 2 个具有多个 GPU 的 ml.g4dn.12xlarge 实例。如果您没有足够的配额,请参阅以下链接的文档,申请增加 SageMaker 资源的服务配额:
3. 实验开发环境设置
首先,需要安装SageMaker Python SDK。这个实验需要安装 SageMaker Python SDK v2.108.0,如下代码所示:
`!pip install "sagemaker>=2.108.0" botocore boto3 awscli pandas numpy –upgrade
import botocore
import boto3
import sagemaker
import pandas as pd
print(f"sagemaker: {sagemaker.__version__}")
print(f"boto3: {boto3.__version__}")
print(f"botocore: {botocore.__version__}")其次,需要设置Amazon SageMaker 的运行环境:
import sagemaker
sess = sagemaker.Session()
# SageMaker session bucket -> used for uploading data, models and logs
# SageMaker will automatically create this bucket if it does not exist
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")4. 数据集加载
如果你关注数据集在何时加载的, 可以在 notebook 代码里查找 “dataset_config_name” 值为 “sst2”;如果你对照到 HuggingFace estimator 的 entry_point 文件(本例定义的是 run_clm.py),里面的代码是这样写的:
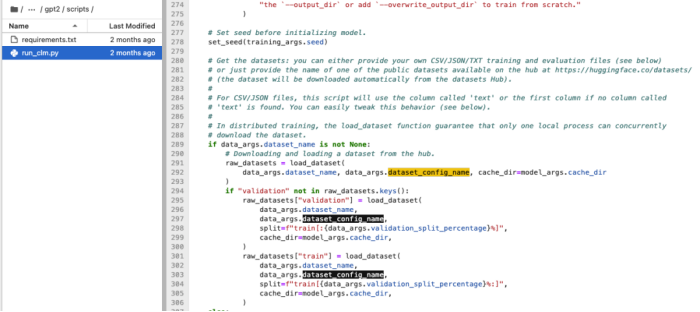
其代码注释里解释的很清楚,列出如下,供你参考:
“获取数据集:你可以提供自己的 CSV/JSON/TXT 训练和评估文件(见下文),也可以只提供数据集 Hub 上可用的一个公共数据集的名称,网址为https://huggingface.co/datasets/(该数据集将自动从数据集 Hub 下载)…”
5. Amazon SageMaker 训练任务设置
要创建大语言模型训练作业,我们使用估算器(estimator)。我们将在 Amazon SageMaker 训练编译器中使用 HuggingFace 估算器。使用估算器,你可以通过 entry_point 定义 Amazon SageMaker 应该使用的训练脚本、参与训练的实例类型(instance_type)、传递的超参数等。
当Amazon SageMaker 训练作业开始时,Amazon SageMaker 负责启动和管理所有必需的机器学习实例,挑选相应的 HuggingFace 深度学习容器,上传训练脚本,然后将数据从指定的数据集所在 S3 桶(sagemaker_session_bucket)下载到 /opt/ml/input/data 的容器中。
首先,将定义一些所有估算器共有的基本参数(如果只是实验用途,建议关闭 Amazon SageMaker Debugger 的性能分析和调试工具,以避免额外的开销):
estimator_args = dict(
source_dir="scripts",
entry_point="run_clm.py",
instance_type="ml.g4dn.12xlarge",
instance_count=1,
role=role,
py_versinotallow="py38",
volume_size=100,
disable_profiler=True, # Disabling SageMaker Profiler to avoid overheads during benchmarking
debugger_hook_cnotallow=False, # Disabling SageMaker Debugger to avoid overheads during benchmarking
base_job_name="trcomp-pt-example",
metric_definitinotallow=[
{"Name": "summary_train_runtime", "Regex": "'train_runtime': ([0-9.]*)"},
{
"Name": "summary_train_samples_per_second",
"Regex": "'train_samples_per_second': ([0-9.]*)",
},
{"Name": "summary_train_steps_per_second", "Regex": "'train_steps_per_second': ([0-9.]*)"},
{"Name": "summary_train_loss", "Regex": "'train_loss': ([0-9.]*)"},
{"Name": "epoch", "Regex": "'epoch': ([0-9.]*)"},
{"Name": "train_loss", "Regex": "'loss': ([0-9.]*)"},
{"Name": "learning_rate", "Regex": "'learning_rate': ([0-9.]*)"},
],
)
# Since ml.g4dn.12xlarge instance has 4 GPUs, we set num_gpus_per_instance to 4
num_gpus_per_instance = 4
接下来,定义一些要传递给训练脚本的基本参数。
# Hyperparameters are passed to the training script as arguments.
hyperparameters = {
"model_type": "gpt2",
"tokenizer_name": "gpt2",
"dataset_name": "glue",
"dataset_config_name": "sst2",
"do_train": True,
"do_eval": False,
"fp16": True,
"per_device_eval_batch_size": 8,
"num_train_epochs": 100,
"block_size": 512,
"overwrite_output_dir": True,
"save_strategy": "no",
"evaluation_strategy": "no",
"logging_strategy": "epoch",
"output_dir": "/opt/ml/model",
"dataloader_drop_last": True,
}在以下各节中,将创建估算器并开始训练。
6. 使用原生的 PyTorch 代码进行模型训练
下面的 per_device_train_batch_size 定义了可放入 ml.g4dn.12xlarge 实例内存中的最大批次。如果您想更改大语言模型训练任务的模型、实例类型、序列长度或其他影响内存消耗的参数,则需要找到相应的最大批次大小。
另外,请注意该示例代码设置了 PyTorch 数据并行方式:
distributinotallow={“pytorchddp”: {“enabled”: True}}在 Amazon SageMaker 上设置数据并行 PyTorch 数据并行方式,就是这么方便和高效!对此感兴趣的话,可以通过以下文档链接进一步了解:
此示例使用 HuggingFace 训练脚本 run_clm.py,你可以在脚本文件夹中找到它。
from sagemaker.pytorch import PyTorch
# The original learning rate was set for a batch of 32. Here we scale learning rate linearly with an adjusted batch size
per_device_train_batch_size = 10
global_batch_size = (
per_device_train_batch_size * num_gpus_per_instance * estimator_args["instance_count"]
)
learning_rate = float("5e-5") / 32 * global_batch_size
# Configure the training job
native_estimator = PyTorch(
framework_versinotallow="1.11",
hyperparameters=dict(
**hyperparameters,
**{
"per_device_train_batch_size": per_device_train_batch_size,
"learning_rate": learning_rate,
},
),
distributinotallow={"pytorchddp": {"enabled": True}},
**estimator_args,
)
# Start the training job
native_estimator.fit(wait=False)
native_estimator.latest_training_job.name7.使用编译优化的 PyTorch 代码进行模型训练
Amazon SageMaker 训练编译器(Training Compiler) 的功能可以进行这些优化,以缩短 GPU 实例上的训练时间。编译器优化 DL 模型,通过更高效地使用 SageMaker 机器学习 (ML) GPU 实例来加速训练。SageMaker Training Compiler 无需额外付费即可使用 SageMaker,它可以加快大语言模型的训练速度,从而帮助减少总计费时间。
以下代码示例了如何使用分布机制 pytorchxla,这是一种可识别编译器的分布式训练方法。
通过 Amazon SageMaker 训练编译器进行编译会更改模型的内存占用。最常见的是,这表现为内存利用率降低,随之而来的是可容纳 GPU 的最大批量大小增加。请注意,更改批量大小时,必须适当调整学习率。以下的代码将展示:随着批次规模的增加,我们对学习率如何进行线性调整。
from sagemaker.huggingface import HuggingFace, TrainingCompilerConfig
# The original learning rate was set for a batch of 32. Here we scale learning rate linearly with an adjusted batch size
new_per_device_train_batch_size = 20
global_batch_size = (
new_per_device_train_batch_size * num_gpus_per_instance * estimator_args["instance_count"]
)
learning_rate = float("5e-5") / 32 * global_batch_size
# Configure the training job
optimized_estimator = HuggingFace(
compiler_cnotallow=TrainingCompilerConfig(),
transformers_versinotallow="4.21",
pytorch_versinotallow="1.11",
hyperparameters=dict(
**hyperparameters,
**{
"per_device_train_batch_size": new_per_device_train_batch_size,
"learning_rate": learning_rate,
},
),
distributinotallow={"pytorchxla": {"enabled": True}},
**estimator_args,
)
# Start the training job
optimized_estimator.fit(wait=False)
optimized_estimator.latest_training_job.name8. 实验结果对比分析
让我们比较一下使用和不使用 Amazon SageMaker 训练编译器的各种训练指标。其中包括:大语言模型的训练数据吞吐量对比、训练损失收敛性对比、训练耗时对比、训练成本对比等。
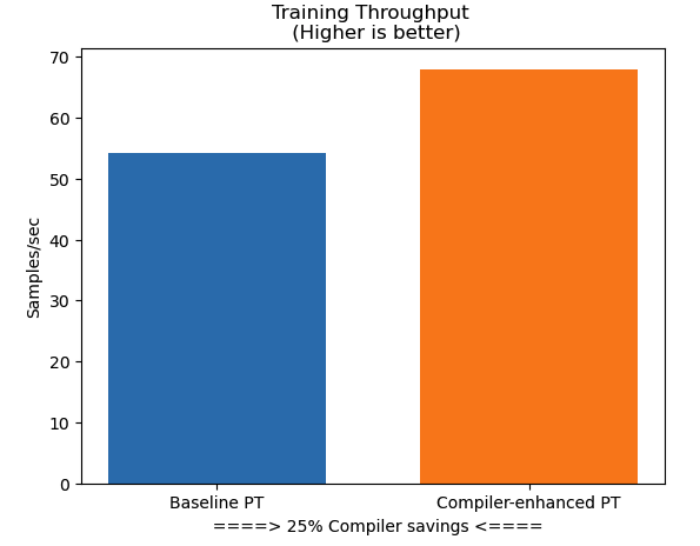
训练数据吞吐量对比图
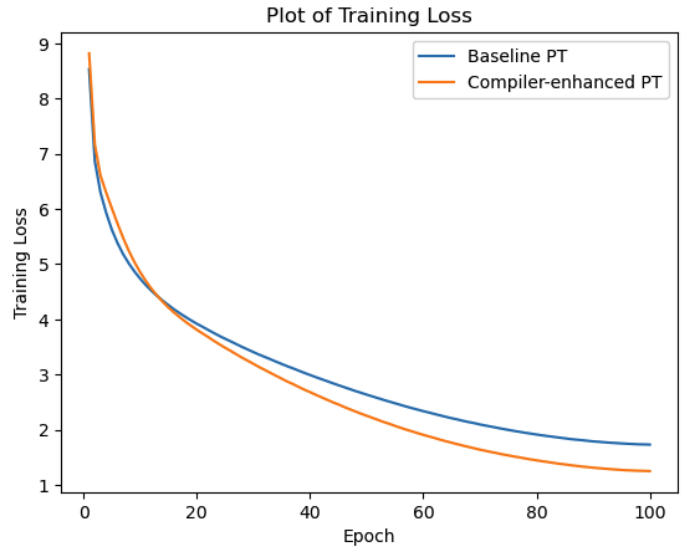
训练损失收敛性对比图

训练成本对比图
由多个维度的实验数据对比可见,Amazon SageMaker 训练编译器可提高训练吞吐量,这意味着减少了大语言模型的总训练时间。而且,总训练时间的减少也会导致 Amazon SageMaker 的计费秒数减少,从而帮助企业节省机器学习训练所需的成本等。
实验三:使用 Amazon SageMaker 实现 BERT 模型的模型并行(Model Parallelization)训练
该动手实验的目标是使用 Amazon SageMaker 的模型并行库(Model Parallelism Library),来实现例如 BERT 这样的大语言模型的模型分布式并行训练。
模型并行性是一种训练无法容纳在单个 GPU 上的大语言模型的方法。如果你正在研究从 70 亿个参数到 1750 亿个参数不等的大语言模型,那么模型并行性就是实现这个目的的方法,这些模型太大了,不能放在单个 GPU 上。因此,我们需要一个并行策略来利用它们。使用 Amazon SageMaker 的模型并行库,可以训练由于 GPU 内存限制而难以训练的大语言模型。该库可自动高效地将相应大语言模型拆分为多个 GPU 和实例。使用该库,开发者可以高效地训练具有数十亿或数万亿个参数的大语言模型,从而更快地实现目标预测精度。
Amazon SageMaker 的模型并行库参考文档:
https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel.html
本实验参考代码的 GitHub 地址:
1. 实验环境和代码结构
Sagemaker 分布式模型并行 (SMP) 是一个模型并行库,用于训练大语言模型,这些大语言模型以前由于 GPU 内存限制而难以训练。SMP 可自动高效地将模型拆分为多个 GPU 和实例,并协调模型训练,允许你通过创建具有更多参数的更大模型来提高预测精度。
此 notebook 配置 SMP 使用 PyTorch 1.6.0和Amazon SageMaker Python SDK 训练模型。
在该 notebook 中,将在 SMP 中使用 BERT 示例训练脚本。示例脚本基于 Nvidia 深度学习示例,要求下载数据集并将其上传到 Amazon S3。这是一个大型数据集,因此根据你的连接速度,此过程可能需要数小时才能完成。
Nvidia 深度学习示例:
https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/LanguageModeling/BERT
此 notebook 依赖于以下文件:
1. bert_example/sagemaker_smp_pretrain.py:这是一个入口点脚本,在 notebook 指令中传递给 Pytorch 估算器。该脚本负责使用 SMP 对 BERT 模型进行端到端训练。
2. bert_example/modeling.py:这包含 BERT 模型的模型定义。
3. bert_example/bert_config.json:这允许对模型进行额外配置,由 modeling.py 使用。其他配置包括 dropout 概率、pooler 和编码器大小、编码器隐藏层的数量、编码器中间层的大小等。
4. bert_example/schedulers.py:包含用于端到端训练 BERT 模型 (bert_example/sagemaker_smp_pretrain.py) 的学习率调度器(learning rate schedulers)的定义。
5. bert_example/utils.py:它包含用于端到端训练 BERT 模型 (bert_example/sagemaker_smp_pretrain.py) 的不同辅助实用函数。
6. bert_example/file_utils.py:包含模型定义中使用的不同文件实用程序函数 (bert_example/modeling.py)。
2. 实验准备和扩展学习资源
实验扩展学习资源:
如果你是 Amazon SageMaker 的新用户,你可能会发现以下内容对进一步了解 SMP 和在 PyTorch 上使用Amazon SageMaker 很有帮助:
有关 SageMaker 模型并行度库的更多信息,请参阅使用 SageMaker 分布式对并行分布式训练进行建模;
有关在 PyTorch 上使用 SageMaker Python SDK 的更多信息,请参阅如何使用PyTorch和SageMaker Python SDK;
了解如何使用自己的训练镜像(image)在 Amazon SageMaker 中启动训练任务,请参阅使用自己的训练算法。
使用 SageMaker 分布式对并行分布式训练进行建模:
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/model-parallel.html
使用PyTorch和SageMaker Python SDK:
https://sagemaker.readthedocs.io/en/stable/frameworks/pytorch/using_pytorch.html
使用自己的训练算法:
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/your-algorithms-training-algo.html
实验准备
您必须创建 S3 存储桶来存储用于训练大语言模型的输入数据。此存储桶必须位于您启动训练任务的同一亚马逊云科技的海外区域中。要了解如何操作,请参阅 Amazon S3 文档中的创建存储桶。
您必须从 Nvidia 深度学习示例中下载用于训练的数据集并将其上传到您创建的 S3 存储桶。要详细了解为预处理和下载数据集而提供的数据集和脚本,请参阅在 Nvidia 深度学习示例存储库 README 中获取数据。您也可以使用快速入门指南来学习如何下载数据集。存储库由三个数据集组成。或者你也可以使用 wiki_only 参数来仅下载维基百科数据集。
创建存储桶:
https://docs.aws.amazon.com/AmazonS3/latest/gsg/CreatingABucket.html
Nvidia 深度学习示例:
https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/LanguageModeling/BERT
在 Nvidia 深度学习示例存储库 README 中获取数据:
3. Amazon SageMaker 的初始化
初始化 notebook 实例。获取亚马逊云科技的区域信息、SageMaker 执行角色的亚马逊资源名称 (ARN)、以及使用的缺省 Amazon S3 桶等信息。
import sagemaker
from sagemaker import get_execution_role
from sagemaker.estimator import Estimator
from sagemaker.pytorch import PyTorch
import boto3
import os
role = (
get_execution_role()
) # provide a pre-existing role ARN as an alternative to creating a new role
print(f"SageMaker Execution Role:{role}")
client = boto3.client("sts")
account = client.get_caller_identity()["Account"]
print(f"AWS account:{account}")
session = boto3.session.Session()
region = session.region_name
print(f"AWS region:{region}")
sagemaker_session = sagemaker.session.Session(boto_sessinotallow=session)
import sys
print(sys.path)
# get default bucket
default_bucket = sagemaker_session.default_bucket()
print()
print("Default bucket for this session: ", default_bucket)4.在 Amazon S3 中准备训练数据
如果您还没有 BERT 数据集在 S3 存储桶中,请参阅 Nvidia BERT 示例中的说明,下载该数据集并将其上传到 S3 存储桶。有关详细信息,请参阅 3.2 章节的实验准备。替换以下 “None” 以设置预处理数据的 S3 存储桶和前缀。例如,如果你的训练数据在 s3://your-bucket/training 中,请设置 s3_bucket 的值为 your-bucket,设置前缀 prefix 的值为 training,作为前缀。输出数据也将存储在同一个存储桶中,位于 output/ 前缀下。
- Nvidia BERT 示例:
https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/LanguageModeling/BERT
s3_bucket = None # Replace None by your bucket
prefix = None # Replace None by the prefix of your data如果您继续使用 s3_bucket 和 prefix 的 None 值,则程序会从公共 S3 存储桶 sagemaker-sample-files 下载一些模拟数据并将其上传到您的默认存储桶。
if s3_bucket is None:
# Donwload some mock data from a public bucket in us-east-1
s3 = boto3.resource("s3")
bucket_name = "sagemaker-sample-files"
# Phase 1 pretraining
prefix = "datasets/binary/bert/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikicorpus_en_abstract"
local_dir = "/tmp/data"
bucket = s3.Bucket(bucket_name)
for obj in bucket.objects.filter(Prefix=prefix):
target = os.path.join(local_dir, obj.key)
if not os.path.exists(os.path.dirname(target)):
os.makedirs(os.path.dirname(target))
bucket.download_file(obj.key, target)
# upload to default bucket
mock_data = sagemaker_session.upload_data(
path=os.path.join(local_dir, prefix),
bucket=sagemaker_session.default_bucket(),
key_prefix=prefix,
)
data_channels = {"train": mock_d
然后,继续设置输出数据路径。这是存储模型工件的地方。
s3_output_location = f"s3://{default_bucket}/output/bert"
print(f"your output data will be stored in: s3://{default_bucket}/output/bert")5. 定义 SageMaker 训练任务
接下来,你将使用 SageMaker Estimator API 来定义 SageMaker 训练作业。
本例使用 PyTorchEstimator 来定义 Amazon SageMaker 用于训练的 EC2 实例的数量和类型,以及连接到这些实例的卷的大小。
PyTorchEstimator:
https://sagemaker.readthedocs.io/en/stable/frameworks/pytorch/sagemaker.pytorch.html
需要配置的参数包括:
实例数量
实例类型
卷的大小
在 instance_type 和 instance_count 中指定的实例类型和实例数量,将决定 Amazon SageMaker 在训练期间使用的 GPU 数量。为 instance_type 和 instance_count 指定值,这样可用于训练的 GPU 总数等于训练脚本中 smp.init 配置中的分区。
如果将 ddp 设置为 True,则必须确保可用的 GPU 总数可被分区整除。除法的结果被推断为用于 Horovod(数据并行度)的大语言模型副本数量。
另外,还需要为 SMP 设置参数字典并设置自定义 mpioptions。
参数字典可配置的内容包括:微批次数量、分区数量、是否将数据并行与 ddp 一起使用、流水线策略、放置策略和其他特定于 BERT 的超参数。
mpi_options = "-verbose --mca orte_base_help_aggregate 0 "
smp_parameters = {
"optimize": "speed",
"microbatches": 12,
"partitions": 2,
"ddp": True,
"pipeline": "interleaved",
"overlapping_allreduce": True,
"placement_strategy": "cluster",
"memory_weight": 0.3,
}
timeout = 60 * 60
metric_definitions = [{"Name": "base_metric", "Regex": "<><><><><><>"}]
hyperparameters = {
"input_dir": "/opt/ml/input/data/train",
"output_dir": "./checkpoints",
"config_file": "bert_config.json",
"bert_model": "bert-large-uncased",
"train_batch_size": 48,
"max_seq_length": 128,
"max_predictions_per_seq": 20,
"max_steps": 7038,
"warmup_proportion": 0.2843,
"num_steps_per_checkpoint": 200,
"learning_rate": 6e-3,
"seed": 12439,
"steps_this_run": 500,
"allreduce_post_accumulation": 1,
"allreduce_post_accumulation_fp16": 1,
"do_train": 1,
"use_sequential": 1,
"skip_checkpoint": 1,以下代码将演示:如何在启用 SMP 的情况下实例化 PyTorch 估算器。
pytorch_estimator = PyTorch(
"sagemaker_smp_pretrain.py",
role=role,
instance_type="ml.p3.16xlarge",
volume_size=200,
instance_count=1,
sagemaker_sessinotallow=sagemaker_session,
py_versinotallow="py36",
framework_versinotallow="1.6.0",
distributinotallow={
"smdistributed": {"modelparallel": {"enabled": True, "parameters": smp_parameters}},
"mpi": {
"enabled": True,
"processes_per_host": 8,
"custom_mpi_options": mpi_options,
},
},
source_dir="bert_example",
output_path=s3_output_location,
max_run=timeout,
hyperparameters=hyperparameters,最后,你将使用这个估算器启动 SageMaker 训练作业,如下代码所示:
pytorch_estimator.fit(data_channels, logs=True)本期文章,我们重点讨论了大语言模型(LLMs)在亚马逊云科技上的动手实践,解读和演示大语言模型(LLMs),如何结合 Amazon SageMaker 的模型部署、模型编译优化、模型分布式训练等方面的一些实际例子及实现代码,希望这些例子和实现代码对于正在探索大语言模型精彩世界的你,会有所启发和帮助。