
文本分类是否能用逻辑回归的方法?
文本分类可以使用逻辑回归的方法。
逻辑回归是一种用于二元分类的统计学习方法,它可以将输入的特征映射到一个概率值,用于判断输入数据属于哪一类。在文本分类中,我们可以将文本的特征表示为词袋模型或者TF-IDF向量,然后使用逻辑回归算法对这些特征进行建模,预测文本的分类。
当然,如果分类问题是多类别的,我们也可以使用多类逻辑回归或者一对多(OvR)逻辑回归来解决这个问题。
值得注意的是,逻辑回归虽然可以用于文本分类,但是它在处理高维稀疏特征时可能会遇到一些问题,例如过拟合等。因此,我们可能需要使用正则化技术,如L1或L2正则化来解决这个问题。此外,我们也可以考虑使用更复杂的模型,例如支持向量机(SVM)或者深度学习模型,以获得更好的性能。
能不能用词嵌入向量和逻辑回归结合起来做文本分类?
词嵌入向量和逻辑回归可以结合起来用于文本分类。
词嵌入向量是一种将单词映射到低维向量空间的技术,可以将文本中的单词转换为密集的向量表示。这种向量表示可以捕捉到单词之间的语义和语法关系,从而更好地表示文本。
在使用词嵌入向量进行文本分类时,我们可以先将文本中的单词转换为对应的向量,然后使用逻辑回归对这些向量进行建模,从而进行文本分类。具体地,我们可以将一个文本中所有单词的词嵌入向量求平均,得到一个文本的向量表示,然后使用逻辑回归对这个向量进行分类。
使用词嵌入向量可以避免使用传统的词袋模型或TF-IDF向量表示文本时的高维稀疏问题,同时也能够更好地表示单词之间的关系。与传统的词袋模型或TF-IDF向量相比,使用词嵌入向量和逻辑回归的方法通常可以获得更好的性能。
需要注意的是,要使用词嵌入向量和逻辑回归进行文本分类,我们需要先准备好一个预训练的词嵌入模型,或者使用现有的词嵌入模型进行训练。常见的预训练词嵌入模型包括Word2Vec、GloVe和FastText等。
词嵌入和逻辑回归结合做文本分类的torch案例
以下是一个使用PyTorch实现词嵌入和逻辑回归结合进行文本分类的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.data import Field, TabularDataset, BucketIterator
# 定义模型类
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.fc = nn.Linear(embedding_dim, output_dim)
def forward(self, text):
embedded = self.embedding(text)
pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1)
output = self.fc(pooled)
return output
上述代码定义了一个文本分类模型类TextClassifier,该类继承了nn.Module。它包含了三个组成部分:
nn.Embedding层:用于将输入的文本索引转换为词嵌入向量。nn.Linear层:用于将词嵌入向量压缩到输出维度的大小。forward方法:前向传播方法,将输入的文本经过nn.Embedding层得到词嵌入向量,然后通过平均池化层(F.avg_pool2d)将词嵌入向量转换为一个固定大小的向量,最后将其送入nn.Linear层输出分类结果。
其中,nn.Embedding层的输入是一个整数张量,表示输入文本中每个单词在词汇表中的索引,输出是一个张量,每个元素是相应单词的词嵌入向量。
nn.Linear层的输入是nn.Embedding层输出的向量,输出是一个大小为output_dim的向量。
在forward方法中,我们首先将输入文本送入nn.Embedding层得到词嵌入向量,然后通过平均池化层(F.avg_pool2d)将词嵌入向量转换为一个固定大小的向量,最后将其送入nn.Linear层输出分类结果。
# 定义训练函数
def train(model, iterator, optimizer, criterion):
model.train()
epoch_loss = 0
epoch_acc = 0
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
# 定义测试函数
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
epoch_acc = 0
with torch.no_grad():
for batch in iterator:
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
# 定义计算精度函数
def binary_accuracy(preds, y):
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float()
acc = correct.sum() / len(correct)
return acc
# 设置随机种子,保证实验的可重复性
SEED = 1234
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
# 定义文本字段和标签字段
TEXT = Field(tokenize = 'spacy', tokenizer_language='en_core_web_sm')
LABEL = Field(dtype = torch.float)
# 加载数据集
datafields = [('text', TEXT), ('label', LABEL)]
train_data, test_data = TabularDataset.splits(
path='.', train='train.csv', test='test.csv', format='csv',
skip_header=True, fields=datafields)
# 构建词汇表
TEXT.build_vocab(train_data, max_size=25000, vectors='glove.6B.100d')
LABEL.build_vocab(train_data)
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 构建数据迭代器
BATCH_SIZE = 64
train_iterator, test_iterator = BucketIterator.splits(
(train_data, test_data),
batch_size=BATCH_SIZE,
device=device,
sort_key=lambda x: len(x.text),
sort_within_batch=False
)
# 定义模型超参数
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
OUTPUT_DIM = 1
N_EPOCHS = 10
LR = 1e-3
上述代码定义了模型的超参数:
INPUT_DIM:词汇表的大小,即词汇表中唯一标记的数量。EMBEDDING_DIM:词嵌入向量的维度。OUTPUT_DIM:输出的维度,即二元分类问题的输出维度为1。N_EPOCHS:训练轮数。LR:学习率,控制优化器更新模型参数的速度。
在定义这些超参数时,我们需要根据具体问题进行调整。例如,如果我们的词汇表很大,则需要增加词嵌入向量的维度,以便能够充分表达单词的语义信息。类似地,如果我们的训练数据集很大,则可能需要增加训练轮数,以便让模型有足够的时间学习文本的特征。
接下来实例化
# 实例化模型、损失函数和优化器
model = TextClassifier(INPUT_DIM, EMBEDDING_DIM, OUTPUT_DIM)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=LR)
# 将模型和损失函数移动到设备上
model = model.to(device)
criterion = criterion.to(device)
# 训练模型
for epoch in range(N_EPOCHS):
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Epoch: {
epoch+1:02}')
print(f'\tTrain Loss: {
train_loss:.3f} | Train Acc: {
train_acc*100:.2f}%')
print(f'\t Val. Loss: {
test_loss:.3f} | Val. Acc: {
test_acc*100:.2f}%')
# 保存模型
torch.save(model.state_dict(), 'text_classifier.pth')
上述代码中,我们首先实例化了模型、损失函数和优化器,然后将模型和损失函数移动到设备上。接着,我们使用训练数据集对模型进行训练,并使用测试数据集对模型进行测试。最后,我们保存了模型的参数到文件中,以便以后可以加载模型并使用它来进行预测。
在上述代码中,我们使用了torchtext库来加载和处理数据集。torchtext库提供了一组方便的工具,可以大大简化文本数据的预处理过程。具体来说,我们使用TabularDataset类加载CSV格式的数据集,使用Field类定义了文本和标签的字段,并使用BucketIterator类创建了数据迭代器,以便我们可以对数据进行批处理。我们还使用了预训练的GloVe词嵌入向量来初始化嵌入层。通过使用预训练的词嵌入向量,我们可以在不需要大量训练的情况下,快速获得有用的文本特征。
最后,我们使用逻辑回归模型对文本进行分类。逻辑回归是一种简单但有效的二元分类算法,它可以对输入的特征进行线性组合,并使用sigmoid函数将结果转换为0到1之间的概率值。在这个示例中,我们使用了一个简单的全连接层来实现逻辑回归,并使用平均池化层来压缩文本中的特征。我们还使用了BCEWithLogitsLoss损失函数,该损失函数结合了二元交叉熵损失函数和sigmoid函数,可以在处理二元分类问题时提供更好的数值稳定性。
上面的代码在哪里体现了逻辑回归?
在上述代码中,逻辑回归的部分体现在使用nn.Linear层将词嵌入向量压缩到输出维度大小时,仅仅使用了一层线性变换,而没有使用任何非线性激活函数。这样的做法可以看作是一个简单的逻辑回归模型,它将输入的文本表示为一个向量,然后通过一个线性变换将其压缩到输出维度大小,并最终通过sigmoid函数将结果映射到0-1之间,以得到二元分类问题的预测结果。
因此,可以将上述模型看作是一个简单的基于词嵌入向量和逻辑回归的文本分类模型,它的训练和推理过程与标准的逻辑回归模型类似。
逻辑回归在神经网络中的应用
逻辑回归在神经网络中的应用通常指的是单层感知机模型,即单层神经网络模型,它可以用来解决二分类问题。在单层感知机模型中,输入数据经过一层线性变换后再经过一个sigmoid函数,输出一个0-1之间的概率值,作为样本属于正类的概率。该模型的输出可以看做是输入数据在一个超平面上的投影结果。
然而,单层感知机的分类能力比较有限,只能处理线性可分的问题。为了解决这个问题,可以使用多层神经网络,通过多层非线性变换,将样本在高维空间中分离开来。在多层神经网络中,每一层都通过一个非线性的激活函数将上一层的输出进行变换,并将变换后的结果传递给下一层。常见的激活函数有sigmoid函数、ReLU函数、tanh函数等。
在神经网络中,逻辑回归通常被看作是一种特殊的神经网络模型,它只有一层,且激活函数为sigmoid函数。当多层神经网络中的每一层都使用sigmoid函数作为激活函数时,整个神经网络就变成了一个逻辑回归模型。因此,逻辑回归可以看作是神经网络的基础,它是神经网络的一个重要组成部分。
逻辑回归与sigmoid函数的联系与区别
逻辑回归与sigmoid函数有着密切的联系。在二分类问题中,逻辑回归是一种经典的分类算法,它的主要思想是使用一个sigmoid函数将数据映射到一个0-1之间的值,作为该样本属于正类的概率。
sigmoid函数是逻辑回归模型中的激活函数,也称为Logistic函数。它的数学表达式为:
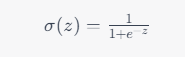
其中, z z z为输入的实数, σ ( z ) \sigma(z) σ(z)为对应的输出值,取值范围在0和1之间。sigmoid函数的图像呈现为一条S形曲线。
逻辑回归的模型可以看作是一个输入层和一个输出层组成的神经网络,其中,输出层只有一个神经元,使用sigmoid函数作为激活函数。在训练过程中,逻辑回归模型通过最小化交叉熵损失函数来优化模型参数,从而达到分类的目的。
虽然逻辑回归与sigmoid函数密切相关,但它们之间也存在一些区别。sigmoid函数本身是一种激活函数,而逻辑回归则是一种分类算法。sigmoid函数可以用于神经网络中的任何层,而逻辑回归只能用于输出层。此外,逻辑回归模型还包括模型参数、损失函数等,它是一种完整的分类算法,而sigmoid函数只是神经网络中的一种激活函数。