
#此帖为本人备考计算机三级数据库的总结#
主要结合原博主计算机三级数据库技术_浮沉叹的博客-CSDN博客的内容,因为原作者中存在部分问题以及题目侧重点有略微偏差。进行总结和叙述,并主要针对考点和关键词进行加深标注,并加入我个人学习中的总结和理解
数据库应用系统开发方法
数据类型
临时性数据、持久性数据
数据库组成
数据库(数据)
数据库管理系统(软件)
数据库管理人员(DBA)
硬件平台:计算机和网络
软件平台:操作系统、数据库系统
典型的软件开发模型
瀑布模型、快速原型模型、螺旋模型(引入风险的模型)等
DBAS生命周期模型
周期阶段:项目规划---需求分析---系统设计(概念设计、逻辑设计、物理设计
)-----系统实现与部署------运行管理与维护
消耗时间时间最长的阶段:运行与维护
1.项目规划
系统的规划与定义:任务陈述、确定任务目标、确认范围和边界、确认用户视图,不包含成本
可行性分析:经济可行性、技术可行性、操作可行性、开发方案可行性
论证是否具备数据库应用系统开发所需的人力资源,这属于数据库应用系统的操作可行性分析
项目规划:项目团队、环境、活动、成本、预算
需求分析
流程:了解用户的情况和业务情况,熟悉业务活动,明确用户需求,确定系统边界
主要工作:
数据需求分析
数据项、数据结构、数据流、数据存储和处理
功能需求分析
数据处理需求分析(事务规范、数据流图)、业务规则需求分析(应用程序)
性能需求分析
操作响应时间、系统吞吐量(单位时间内完成的数据库事务数量)、允许并发访问的最大用户量
其他需求
存储需求、安全性需求、备份和恢复需求
系统设计
概念设计:概念模型设计、系统总体设计
逻辑设计:应用程序概要设计、事务概要设计(read和write)
物理设计:数据库事务详细设计、应用程序详细设计。
系统实现与部署(或实施)
建立数据库结构
数据加载
事务与应用程序的编码与测试
系统集成
测试与运行
系统部署
5.运行与维护
日常维护、系统监控与分析、系统性能优化与调整、系统进行升级,这些主要由DBA(管理员)进行
三层服务器结构:浏览器服务器、应用服务器(业务规则)、数据库服务器
需求分析
需求是指用户对软件的功能和性能的要求,描述待开发的系统所要完成的功能。
目标:
深入描述软件的功能和性能,确定软件设计的约束和软件和系统其他元素的接口。
需求分析的困难:
1.软件功能复杂、需求的可变性、软件产品的不可见性
2.解决办法:加强分析人员与用户不断地交互沟通
需求获取方法
面谈、实地考察、问卷调查、查阅资料
1.面谈流程:准备访谈、计划和安排访谈日程、访谈开始和结束、引导访谈、访谈整理工作
2.实地考察:现场观察、询问法
3.问卷调查:适用使用情况、问题细节、问卷尽量简短、选择题
4.查阅资料:收集用户材料、书面需求文档、业务操作流程
需求分析过程
标识问题
建立需求模型
描述需求
确认需求
需求分析方法
结构化分析与建模方法
建立分析模型(主要包括功能模型、数据模型和行为模型)-----编写需求规格说明书----结构化分析的指导思想(抽象与分解)
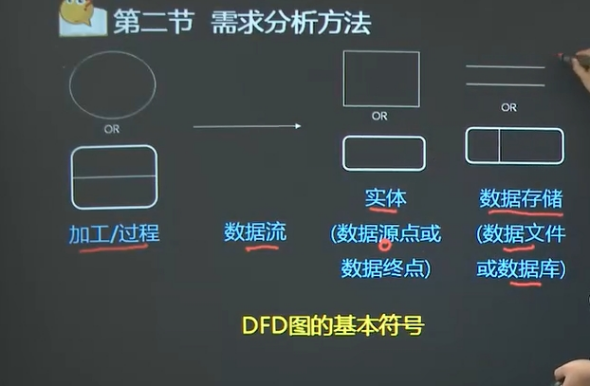
DFD(数据流图,Data Flow Diagram)建模
符号表示:
建模步骤或 建模过程:DFD主要为功能建模,业务流程
明确目标,确定系统范围----建立顶层DFD图------- 对顶层DFD分解-------开发DFD层次结构图------检查DFD图
DFD的组成:数据流、处理、数据存储、外部项:(数据源或数据终点)
DFD图规则:
父图中描述过的数据流必须在相应子图中出现。
一个处理至少有一个输入流和输出流
一个存储必定有流入的数据流和流出的数据流
一个数据流至少有一端是处理框
表达描述的信息是全面、完整、正确和一致的
IDEF(ICAM DEFinition Method) 建模
IDEF0-IDEF14(包括IDEF1X在内)共有16套方法
IDEF0:描述系统功能及相互关系
IDEF1:系统信息及数据之间联系
IDEF2:系统模拟,动态建模
IDEF3:过程描述及获取方法
IDEF4 :面向对象设计
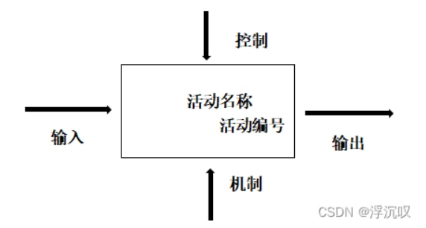
IDEF0图 功能需求建模
IDEF0需求建模由箭头和矩形或方框或活动两种元素组成
面向对象分析与建模方法
UML建模
用例图由系统、角色、用例三种模型元素及之间的关系构成
数据库结构设计
1.数据库概念设计
目标及步骤
概念设计目标
定义数据范围、数据属性特征、数据之间的关系、数据的约束
确定事务需求
概念设计步骤
确定建模目标----定义实体集-----定义联系----建立信息模型-----确认实体属性----对信息模型进行集成与优化
依据与过程
依据:
以需求分析的结果为依据,即需求说明书、DFD图及相关报表为依据。
过程:
明确建模目标---定义实体集------定义联系------建立信息模型(ER,Entity -Relationship Model,实体联系模型)模型-------确定实体属性集--------对信息模型进行集成和优化
关键词:
实体(Entity),实体集,属性,域,码或键(key),联系
结果
(概念模型)ER图与需求说明书
IDEF1X建模方法(数据建模方法)
特点:
IDEF1X侧重分析、抽象和概括应用领域中的数据需求。
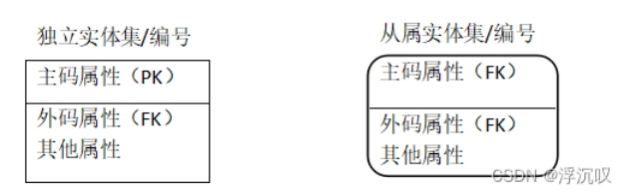
独立实体集:一个实体集的每一个实例都能被唯一地标识而不决定于它与其他实体集的联系
从属实体集:实体集的一个实例的唯一标识依赖于该实体集与其他实体集联系
标定型联系:子女实体集中的每个实例都是由它与双亲的联系而确定的 (强关联)
(学生,课程) 成绩--->完全函数依赖--->n:1
非标定型联系:子女实体集中的每一个实例都是被唯一地确认而无需了解与之相联系的双亲实体集的实例 (系) 学生--->1:n ,不会产生从属实体集
分类联系:两个或多个实体集之间的联系,每一个实例都恰好与一个且仅一个分类实体集的一个实例相联系 (月薪职工,计时职工) 职工
非确定联系(多对多):两个实体集之间,任一实体集的一个实例都将对应另一实体集的0个、1个或多个实例;可通过引入第三个实体集将非确定关系转化为确定关系
学生(课程)--->m:n
两个实体集间存在多对多联系,利用引入的第三个实体集,转化后得到的两个一对多的联系,符合标定型联系的定义
如果子女实体集中的每一个实例都能被唯一的确认而无需了解与之相联系的双亲实体集的实例,该联系就被称为"非标定型联系",不会产生从属实体集。
ER图表示方法
实体集:矩形框
联系:菱形框
属性:椭圆或圆角矩形
2.数据库逻辑设计(对关系模式进行规范化)
目标
将ER图转化为DBMS支持的数据模型,并对其进行优化
相关概念
关系模型
实质二维表格
表示为R(U,D,DOM,F)
R:关系名
U:组成该关系的属性名集合
D:属性组U中的域
DOM:属性到域的映射
F:属性组U上的一组数据依赖
R<U,F> 当且仅当U上的一关系R满足
数据依赖:关系内部属性之间的一种约束关系
完整性约束的表现形式: X ---> Y
函数依赖(Functional Dependency,FD):唯一确定关系
多值依赖(Multivalued Dependency ,MD):不能唯一确定
#原博主这里有问题,进行修改#
平凡函数依赖:如果 x-->y ,且y⊆x
非平凡函数依赖:如果x-->y,且y ⊈x
完全函数依赖f、部分函数依赖p
数据库完整性约束条件的作用对象分为列、元组和关系或表三种级别。元组对应于行,关系对应于表。
传递函数依赖(传递)
候选码、超码、主码、外码(Foreign key)
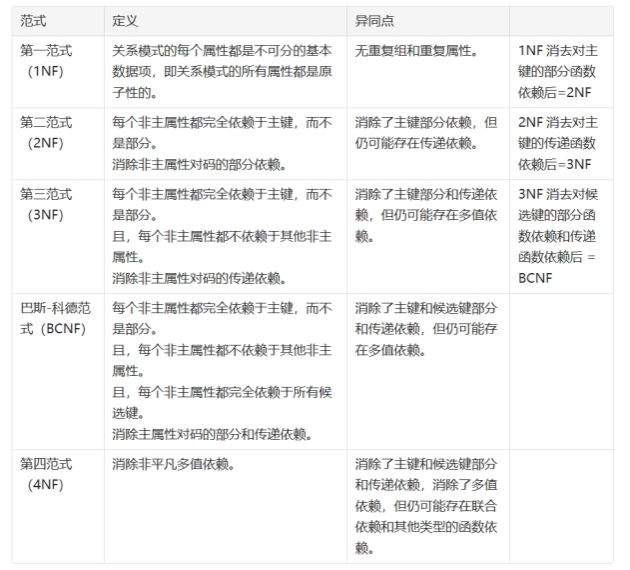
数据规范化(范式):1NF,2NF,3NF,BCNF,4NF,5NF
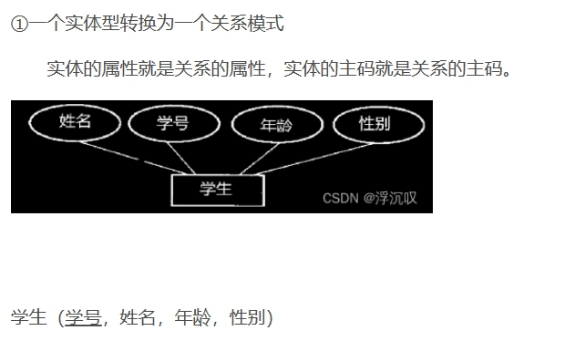
ER图转换为关系模式
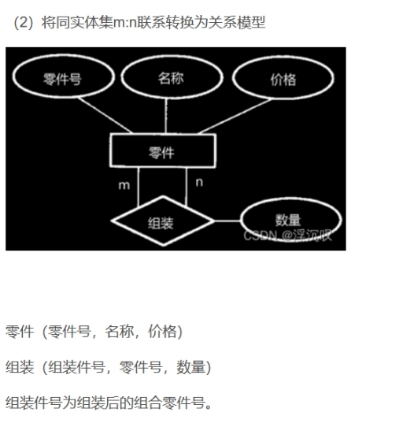
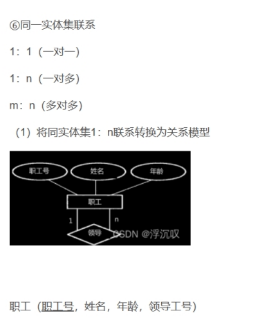
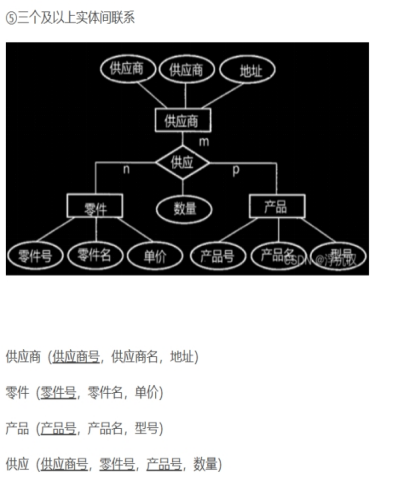
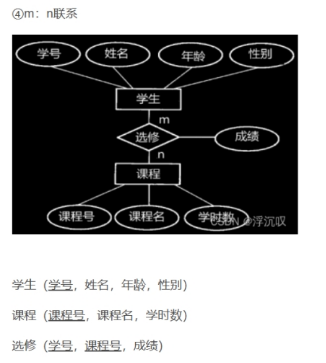
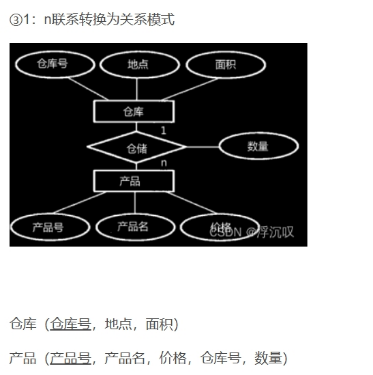
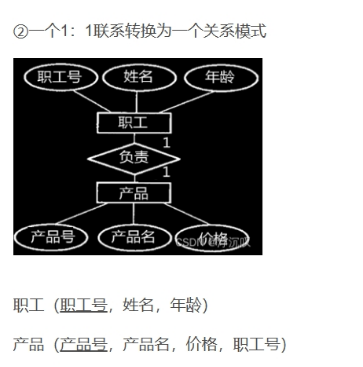
3.数据库物理设计:对关系模式进行去规范化处理
SQL Server 采用T-SQL语言
物理设计:数据库的存储结构和物理实现方法,将数据的逻辑描述转换为实现技术规范,设计存储方案以便保证数据库数据的完整性、安全性、可靠性。
解决问题:文件组织、文件结构、文件存取、索引技术
堆文件:数据库中的一个基本表中的数据量很少,并且插入、删除、更新等非常频繁
顺序文件:基于查找码的顺序访问,快速的二分查找
散列文件:用户查询基于散列域值等值匹配,访问顺序随机
步骤
数据库逻辑模式描述:将关系模式及视图转换为基本表和视图,为基本表选择合适的文件结构。
文件组织与存取设计:将易变部分与稳定部分、存取频率高低部分分开存放。根据事务访问特性设计文件结构
影响因素:存取时间、存储空间利用率、维护代价
解决办法:适当冗余、增加聚簇功能
存取路径:实际上就是确定如何建立索引
常用存取方法:索引方法(目前主要是B+树索引方法)、聚簇方法、哈希方法
数据分布设计
*根据数据的使用特征划分(频繁程度)
*根据时间地点划分(时间或地点)
*分布式数据库系统(DDBS)中数据划分:水平划分或垂直划分
水平划分:将基本表划分为多张具有相同属性、结构完全相同的子表,子表包含的元组是基本表中元组的子集。
垂直划分:将基本表划分为多张子表,每张子表包含的属性为原基本表的自己,且包含主码
*派生属性数据划分(增加派生列或不定义派生属性)
*关系模式的去规范化(降低规范化提高查询效率)
确定系统配置
确定产品分配存储参数:同时使用的用户数、打开数据库对象数、缓冲区长度、时间片大小、数据库大小、装填因子、锁的数目
物理模型评估
从存取时间、存储空间、维护代价进行评估,重点是时间和空间效率。
索引技术
关键:建立记录域取值到记录的物理地址间的映射关系
索引文件机制:利用索引文件(记录索引的组成文件)实现记录域取值到记录物理地址间的映射关系。
数据文件(主文件)、索引文件(索引记录或索引项集合的文件)
有序索引
聚集(或聚簇)索引(索引项与数据记录排列一致的,索引顺序文件)和非聚集索引。一个数据文件只可建立一个聚集索引,但可以建立多个非聚集索引
稠密索引(数据文件中每个查找码都对应索引的记录)和稀疏索引(部分对应)
主索引(主码属性集上建立的索引)与非主索引或辅索引(非主属性上建立的索引)
唯一索引(索引列不包含重复值),唯一索引的作用是保证索引键值的不重复。
单层索引(线性索引,每个索引值的顺序排列直接指向数据文件中的数据记录)和多层索引(大数据量文件中的采取多层索引(B+树))
散列索引
哈希索引
建立索引原则
一个属性经常在操作条件中出现
一个属性经常在连接操作的连接操作中出现
一个属性经常作为聚集函数的参数
Select后面的一定不要建索引
建立聚簇索引原则
检索数据时,常以某个(组)属性作为排序、分组条件
检索数据时,常以某个(组)属性作为检索限制条件,并返回大量数据
表中某个(组)的重复性较大
数据库应用系统功能设计与实施
DBAS功能设计包括应用软件中的数据库事务设计和应用程序设计
SQL Sever中的五种约束,主键约束、外键约束、唯一性约束、缺省约束和检查约束
软件体系结构与设计过程
(1)软件体系架构
组成:构件、连接件、约束
体系要求:普适、高效、稳定
风格和类型:分层体系结构、模型-视图-控制器(MVC)体系结构、客户端/服务器体系结构
(2)软件设计过程
过程:设计(概要设计和详细设计)、实现、测试
概要设计任务:进行软件总体结构设计,可采取层次结构图建立软件总体结构图。
详细设计任务:进行数据设计、过程设计、过程设计及人机界面设计
设计原则:模块化、信息隐藏、抽象与逐步求精
方法:结构化设计方法、面向对象设计方法、面向数据设计方法等
DBAS总体设计
(1)DBAS体系结构设计
将系统从功能、层次/结构、地理分布等角度进行分解,划分为多个子系统,定义各子系统功能;设计系统的全局控制,明确各子系统间的交互和接口关系。
常见结构:
客户/服务器体系结构(C/S)client/service
三层C/S架构
浏览器/服务器体系结构(B/S)browser/service
(2)软件体系结构设计
操作系统、数据库管理系统、开发环境中间件、应用软件(数据库事务和应用程序)
(3)软件硬件选型与配置设计
考虑因素:数据规模、系统性能、安全可靠性、用户需求、项目预算情况。
(4)业务规则初步设计
从系统的角度,规划DBAS的业务流程,使之符合客户的实际业务需要。
(5)DBAS软件总体设计
模块结构图:模块、调用、数据、控制、转接
DBAS功能概要设计
将DBAS应用软件细化为模块/子模块,组成应用软件的系统-子系统-模块-子模块层次结构,并从结构、行为、数据三方面进行设计。
(1)表示层概要设计
人机界面设计,设计原则:‘自主控制’;反馈及时,上下感知;容错与恢复;界面常规;输入灵活;界面简洁、交互及时、交互友好
(2)业务逻辑层概要设计
设计原则:高内聚低(松)耦合,即构件单一原则;构件独立功能;接口简单明确;构件间关系简单,过于复杂,就细化,分解。
设计内容:结构,行为,数据,接口,故障处理、安全设计,系统维护和保障等(存储过程)
(3)数据访问层概要设计
任务:针对DBAS的数据处理需求设计用于操作数据库的各类事务。
事务概要设计核心在于辨识和设计事务自身处理逻辑,注重流程,不考虑与平台相关、具体操作方法和事务实现机制。
一个完整的事务概要设计包括事务名称、访问的关系表及其数据项、事务逻辑(事务描述)、事务用户(使用、启动、调用该事务的软件模块和系统)。
事务(transaction):事务是访问并可能更新数据库中各种数据项的一个程序执行单元,事务的特性ACID。
事务规范包括了事务名称、事务描述、事务所访问的数据项、事务用户
原子性(atomicity):一个不可分割的工作单位。要么做,要么不做
一致性(consistency):从一个一致性状态变到另一个一致性状态。如果一个事务执行失败,则已做过的更新被恢复原状,像整个事务从未执行
隔离性(isolation):执行不能被其他事务干扰。一个事务执行过程中,正在访问的数据被其他事务修改,导致处理结果不正确
持久性(durability):永久性,指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。某系统运行过程异常,已提交事务所影响的数据未能正确写入磁盘且无法恢复
(4)数据持久层概要设计
负责保存和管理应用系统数据,数据存取有关,包含索引设计
DBAS功能详细设计
表示层详细设计
人机界面采用原型迭代法合适,三个步骤:
(1)初步设计:设计人机交互命令系统并优化。(总体设计)
(2)用户界面细节设计:如组织形式、风格、彩色,操作方式。(概要设计)
(3)原型设计与改进:(详细设计)
业务逻辑层详细设计
设计各模块内部处理流程和算法、具体数据结构、对外详细接口等。
应用系统安全架构设计
数据安全设计
(1)安全性保护
数据库层面
用户身份鉴别、权限控制、视图机制
(2)完整性保护
设置完整性检查,作用于列(类型、范围、精度、排序)、元组(属性)、关系(集合)
对列的约束:对其值的类型、范围、精度、排序等约束
对元组的约束:对记录中各个属性之间的联系约束
对关系的约束:对若干个记录之间(一个关系的各个元组之间)、关系集合以及之间联系的约束
(3)并发性控制
封锁技术:排它锁(写锁eXclusive),共享锁(读锁Share)
避免死锁原则:同一顺序访问资源、避免事务交互性、小事务缩短长度和时间、记录级别锁(行锁)、绑定连接
降低事务隔离级别可以提高事务的吞吐量,提高活锁的可能性,降低发生死锁、发生阻塞的可能性。
事务的隔离性是指多个并发事务同时访问一个数据库时,一个事物不应被另一个事物所干扰,即保证并发读取数据的正确性,降低发生数据不一致的可能性。
在没有建立聚集索引的表上定义主键,系统会自动在主键上建立聚集索引
加锁协议规定了事务的加锁时间,持锁时间和释放锁时间
三级加锁协议可以完全保护并发数据事务的一致性
由于死锁导致事务回滚属于数据库故障的事务内部故障
两阶段的加锁协议可以保证事务调度的可串行性
为避免活锁现象的发生,先来先服务策略处理事务的加锁请求
数据库管理系统一般通过周期性检查事务等待图来实现死锁检测
(4)数据备份与恢复
策略:双机热备、数据转储(数据备份)、数据加密存储
(5)数据加密传输
手段:数字安全证书、对称密钥加密、数字签名、数字信封
环境安全设计:
与补丁(查找更新)、计算机病毒防护(杀毒监控)、网络环境安全(防火墙)、物理环境安全(UPS电源)
制度安全设计
管理层面安全措施
DBAS实施
(1)创建数据库
因素:初始空间 数据增量大小、访问性能
(2)数据装载
步骤:筛选数据——转换数据格式——输入数据——校验数据
(3)编写与调试应用程序
(4)数据库系统运行
(5)功能测试与性能测试
功能测试:白盒测试;性能测试:黑盒测试
UML(Unified Modeling Language)与数据库应用系统
在UML中,用类图来描述系统的静态结构,而用顺序图和通信图来表示系统的动态结构。
类图主要表达的是问题领域的概念模型,在这个抽象的概念中,除了表达该抽象概念的名称外,另外需要表达该抽象概念的"属性"和"行为"。
顺序图的目的在于说明对象的协作如何达到系统的目标,主要用于描述系统内对象之间的消息发送和接收序列。
通信图是交互图的一种,也被称为协作图。通信图中包含一组对象,并在图中展示这些对象之间的联系以及对象间发送和接收的消息。
顺序图和通信图都描述交互,但是顺序图强调的是时间,通信图强调的是空间。
DBAS建模
DB文件组织与存取设计的步骤是:使用事物-基本表交叉引用矩阵,分析系统内数据库事务对各个基本表的访问情况;估计各事务的执行频率;对每张基本表,汇总所有作用于该表上的各事物的操作频率信息;根据分析结果,对基本表设计成更为有效地文件组织和索引方式。
UML由语义和表示法组成;语义用自然语言描述,表示法是可视化标准表示符号。
四层:元元模型层(代表要定义的所有事物)、元模型层(事物实例)、模型层(UML的模型,类或类型模型)、用户模型层(UML的实例)。
结构图→静态结构建模:类图、对象图、复合结构图、包图、组件图、部署图
行为图→动态行为建模:用例图、交互图(顺序图、通信图、交互概述图、时间图)、状态图、活动图
DBAS业务流程与需求表达
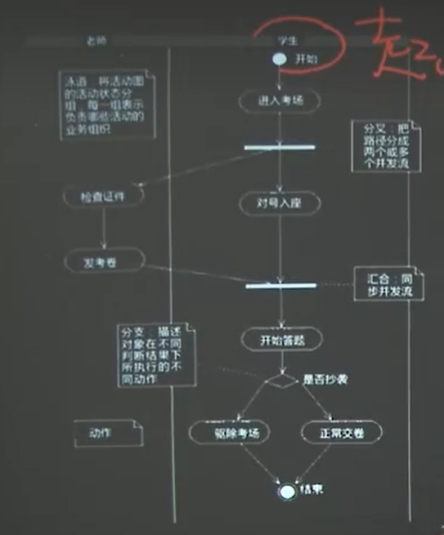
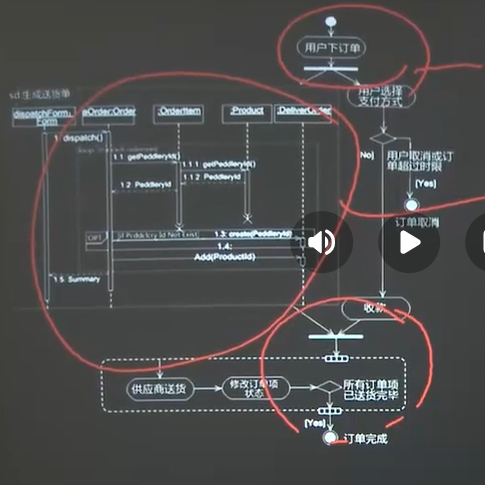
(1)活动图(识别就行)
箭头线:活动之间的转换 箭头:执行方向 圆角矩形:活动
菱形:分支、判断 标注:执行下一个活动条件 加粗直线:同步条
目的:表达流程规范性,表达明确、简单、逻辑清晰
只能有一个起点,可有多个结束点
活动图主要用于描述系统、用例和程序模块中逻辑流程的先后执行次序,并行次序。
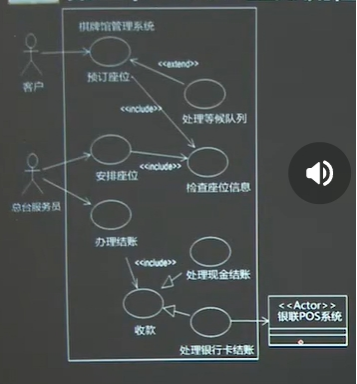
(2)用例图 (功能建模)属于用例视图
系统功能需求是用户想要的,本质最终是捕捉用户心中的期望。
用例模型:用例、角色、系统。
系统:长方框表示,系统名字写在方框上或下面。
角色:与系统交互的人或其他实体。角色是与系统进行交互的外部实体,可以是系统用户也可以是其他系统或者硬件设备。
通用化关系:把某些角色共同行为抽取出来作为通用行为,通用行为构成超类。
角色之间:通用化关系用带空心三角形(作为箭头)的直线表示。
用例:一个完整的功能,是所有动作的集合。
用例:椭圆形表示,就是功能
关联关系:带箭头直线
扩展和使用是继承关系,组合把相关用例打成包。
扩展关系:构造型(sterotype)<<extend>>
使用关系:构造型 <<uses>>
用例之间存在关系,包括扩展、使用、组合
DBAS系统内部结构的表达
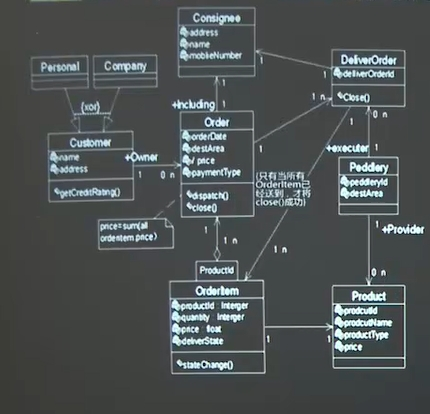
(1)类图(描述系统静态结构)
类图技术是面向对象方法的核心技术。
1.属性
可见性:公有、受保护、私有,分别用“+”,“#”,“-”表示
名称:表示属性的名称
类型:定义属性的种类
缺省值:属性的初始值
约束性:列出该属性所有可能取值
操作
可见性、名称、参数表、返回类型表达式、约束性
2.关联关系
两个类之间存在某种语义上的联系
导航关系: 类与类之间的关联是单向的;实线箭头
多重性参与对象的数目上下界限制,“*”代表0~∞,“1”是1..1的简写
如果图中没有明确标识关联的重数,就意味着是1
3.聚集
共享聚集:部分可以参加多个整体;空心菱形
组成:整体拥有各部分,部分与整体共存,整体不存在,部分也会消失;实心菱形
继承(泛化)关系
元素与特殊元素之间的分类关系;继承表示为一头为空心三角形的连线。
依赖关系
元素Y依赖元素X
精化关系
同一事物的两种描述之间的关系;带空心三角形的虚线表示
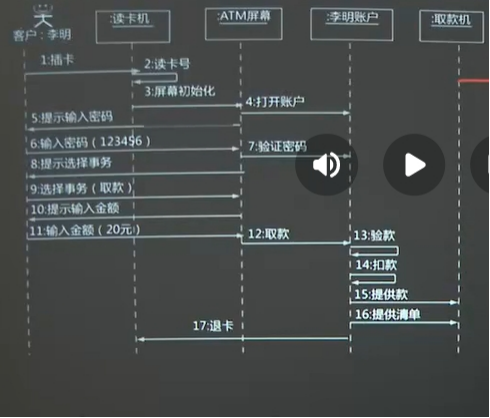
(2)顺序图 属于行为视图
描述系统内对象之间的消息发送和接收序列
横向:对象,用矩形框表示 纵向:时间持续的过程
对象间的通信用对象生命线之间的水平消息表示;
消息线的箭头说明消息的类型,如同步、异步或简单
消息/方法名字:标注在消息线的上面
浏览顺序图的方法:从上到下查看对象间交换的信息
各分支的条件不互相排斥,消息可能会并行发出
条件之间互相排斥,一次只能发送一条消息
当一个对象被销毁时,用一个大“X”标记
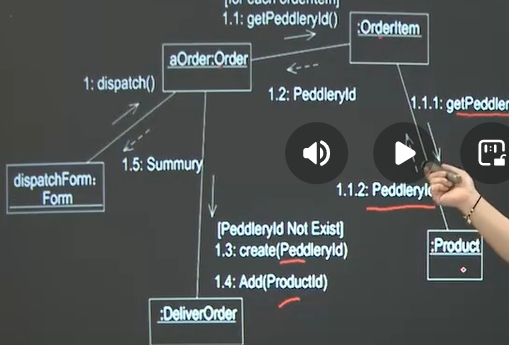
(3)通信图(协作图)
对象之间的联系以及对象之间发送和接收的消息 空间
特别表达消息的传递是由哪一个对象到另一个对象
描述对象在空间中如何交互、链接,没有时间轴,按序编号
DBAS系统微观设计与表达
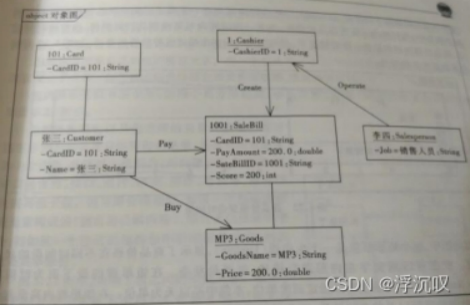
(1)对象图(描述细节,是类图的一个实例,是描述特定时间中所有对象在系统中的结构,是一个快照)
概念模型中必须要利用比较抽象的表示法,来同时表达概念在各种不同情况下的呈现
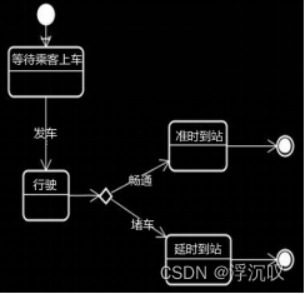
(2)状态图 属于行为视图
某个对象或某一个事件非常复杂的状态转换;只能有一个起始状态
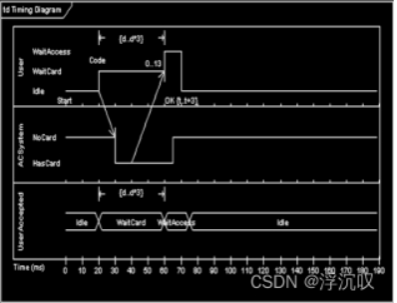
(3)时间图
当状态持续了多长时间后,就会转移到另一个状态;状态转移中牵涉时间因子
DBAS系统宏观设计与表达
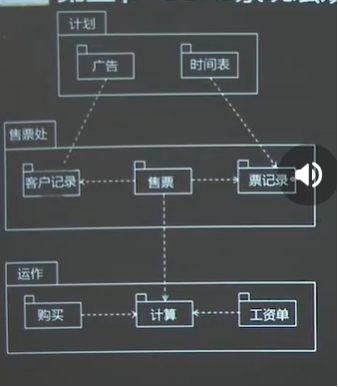
(1)包图
包图可以表达系统中不同的元素彼此间的关系,
包与包之间允许建立的关系有依赖、精化和通用化;保证低耦合,高内聚
可见性:私有、保护、公有、实现,缺省的可见性为公有
(2)交互概述图
主要元素和活动图完全一致,唯一不同的是交互框用来取代活动图中的活动框
顺序图与活动图结合
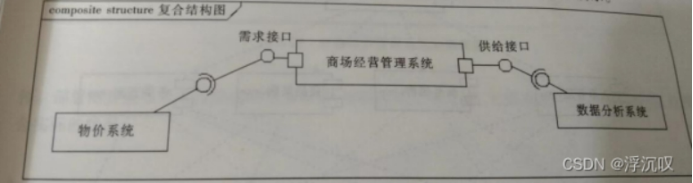
(3)复合结构图
最主要元素是部件
部件与外部的部件连接时,必须通过端口,用正方形图示。
供给接口:某个特定的部件提供服务个外部的部件
需求接口:某个特定的部件需要外部的部件提供服务
DBAS系统实现与部署的表达
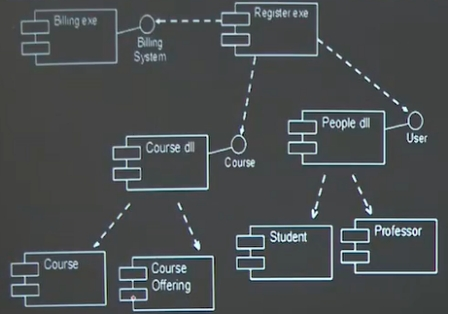
(1)组件图
一组组件之间的组织和依赖,用于对源代码、可执行任务的发布、物理数据库等的建模。
组件是逻辑设计中定义的概念和功能在物理架构中实现。
典型情况下,组件是开发环境中的实现文件
(2)部署图或配置图
系统中的硬件和软件对的物理配置情况和系统体系结构;结点表示实际的物理设备。
高级数据查询
一般数据查询功能拓展

Group by 查询结果的分组条件
Having 聚合查询的条件
Order by 查询结果排序asc升序/desc降序
Compute 对查询结果集进行汇总生成末尾数据行
Distinct:去除重复项
使用TOP限制结果集
语法格式:TOP n [percent] [WITH TIES]
①TOP n:取查询结果的前n行数据;
②TOP n percent:取查询结果的前n%行数据;
③WITH TIES:表示包括最后一行取值并列的结果
注意:用TOP谓语,与ORDER BY子句一起使用
用WITH TIES选项,必须使用ORDER BY子句
使用CASE函数

分情况显示不同数据类型的目的
简单CASE函数
语法格式: CASE 测试表达式
WHEN 简单表达式1 THEN结果表达式1
WHEN 简单表达式2 THEN结果表达式2
......
WHEN 简单表达式n THEN结果表达式n
[ELSE 结果表达式n+1]
END
搜索CASE函数
语法格式: CASE
WHEN 布尔表达式1 THEN结果表达式1
WHEN 布尔表达式2 THEN结果表达式2
......
WHEN 布尔表达式n THEN结果表达式n
[ELSE 布尔表达式n+1]
END
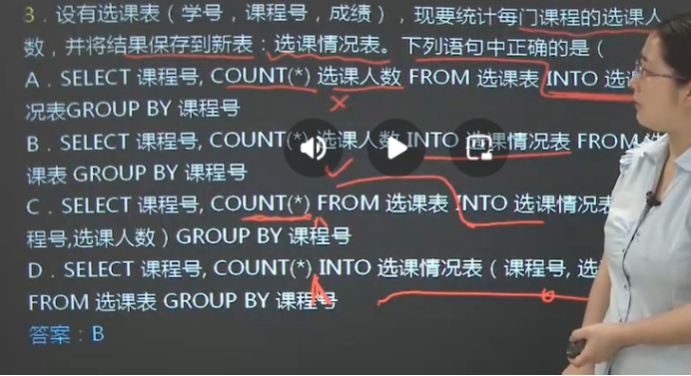
将查询结果保存到新表中
语法格式: SELECT 查询列表序列INTO [# 局部临时表/ ##全局临时表] <新表名>
只有表名为永久表
FROM 数据源
功能:
①查询语句列出的列以及其类型创建一个新表
②执行查询语句
③将查询结果插入新表
局部临时表标识“#”,全局临时表标识“##”。
查询结果的并、交、差运算
并运算 UNION
语法格式: SELECT 语句1
UNION [ALL]
SELECT 语句2
UNION [ALL]
SELECT 语句n
JOIN是垂直合并数据(添加更多的列),UNION是水平地合并数据(添加更多的行)
注意:
①列的个数,语义相同
②列的数据类型与其他列的数据类型隐式兼容
③合并后采用第一个SELECT语句列标题
④结果进行排序,ORDER BY写在最后一个查询语句
交运算 INTERSECT
语法格式: SELECT 语句1
INTERSECT
SELECT 语句2
INTERSECT
SELECT 语句n
交运算返回两个查询结果集中各个列的值均相同,并用这些记录构成交运算的结果
差运算 EXCEPT
语法格式: SELECT 语句1
EXCEPT
SELECT 语句2
EXCEPT
SELECT 语句n
差运算将返回在第一个集合中有但第二个集合中没有的数据
相关子查询
子查询进行基于集合的测试 [NOT] IN
WHERE表达式[NOT] IN(子查询)
注意:先执行子查询,然后在子查询的结果基础上再执行外层查询
子查询进行比较测试
WHERE表达式 比较运算符(子查询)
比较运算符:=、<>、<、>、<=、>=
运算结果为True,则返回True;运算结果为False,则为False。
注意:子查询先得到聚合函数的结果,再执行外层查询的比较。
子查询进行存在性测试 [NOT] EXISTS
WHERE [NOT] EXISTS(子查询)
注意:①先执行外层查询,再执行内层查询。
②只返回真或假值,子查询目标列通常用“*”
其他形式的子查询
替代表达式的子查询
在SELECT语句的选择列表中嵌入一个只返回一个标量值的语句
例:查询G001顾客姓名、地址以及顾客购买商品的次数
SELECT Cname,Address
(SELECT COUNT(*) FROM Table_SaleBill a
JION Table_Customer b ON a.CardID=b.CardID
WHERE CustomerID=’G001’) AS Totaltimes
FROM Table_Customer
WHERE CustomerID=’G001’
派生表
将子查询作为一个表来处理;简化查询,避免使用临时表
SELECT * FROM(SELECT * FROM T1) AS temp
其他形式的子查询
开窗函数 OVER
将OVER子句与聚合函数结合使用
语法格式: <OVER_CLAUSE> : : =
OVER ( [PARTITION BY value_expression] )
PARTITION BY :将结果集划分为多个分区
value_expression:指定对行集进行分区所依据的列
例:SELECT Cno,Semester,Credit,
SUM(Credit) OVER (PARTITION BY Semester) AS ‘Total’
将OVER子句与排名函数一起使用
语法格式: OVER ( [ < partition_by_clause > ]
< order_by_clause> )
partition_by_clause :将FROM子句生成的结果集划分成排名函数使用的分区
order_by_clause :指定应用于分区中的行时所基于的排序依据列
RANK():每行数据在每个分区内的排名;若值有相同的行,则值相同的行具有相同排名
DENSE_RANK():排名中间没有任何间断,该函数返回的是一整个连续的值
NTILE:有序分区中的行划分到指定数目的组中,返回分区编号
ROW_NUMBER():返回结果集中每个分区内行的序列号
例:SELECT 列名RANK() OVER
(PARTITION BY 列名ORDER BY 列名[DESC | ASC ] )
FROM 表名ORDER BY 列名
公用表达式
将查询语句产生的结果集指定一个临时命名的名字
好处:
①定义递归公用表达式
②操作数据代码清晰简洁
③GROUP BY子句作用在子查询的标量列上
④在一个语句中多次引用共用表达式
语法格式: WITH <common_table_expression> [...n]
<common_table_expression>: :=
expression_name [ ( column_name [...n] ) ]
AS
(SELECT 语句)
expression_name :公用表达式标识符
column_name:公用表达式指定列名
SELECT 语句:指定一个用其结果集填充到公用表达式的SELECT语句
例:WITH BuyCount(CardID,Counts) AS
SELECT CardID,COUNT(*) FROM Table_SaleBill
GROUP BY CardID)
SELECT CardID,Counts FROM BuyCount
ORDER BY Counts
数据库及数据库对象
创建及维护数据库
维护工作主要包括:数据库的转储和恢复;数据库的安全性和完整性控制;数据库性能的监控分析和改进;数据库的重组和重构。
SQL Server数据库概述
1.系统数据库(自动创建)
master:记录实例的所有系统级信息,包括实例范围。
msdb:代理服务调度报警和作业以及记录操作员时使用
model:实例上创建的所有数据库模板
tempdb:临时数据库
resource::只读数据库
2.用户数据库
数据库的组成
数据文件包含数据和对象,日志文件包含恢复数据库中的所有事务需要的信息
数据文件
主要数据文件:扩展名 .mdf 只能有一个主要数据文件,大小不小于3MB(main)
次要数据文件:扩展名 .ndf 可以不包含次要数据文件,也可以包含多个次要数据文件
可以建立在一个磁盘上,也可以分别建立在不同磁盘上
在主要数据文件建立之后建立的所有文件都是次要数据文件
事务日志文件log
扩展名 .ldf 存放恢复数据库的所有日志信息,必须至少一个日志文件, 也可以多个日志文件
数据存储空间的分配
①数据的分配单位是数据页,一页是一块8KB(8×1024B,用8060B存放数据,另外132B存放信息)的连续磁盘,每MB有128页
②行不能跨页存储,表中一行数据大小不能超过8060B
③创建用户数据库时,model数据库自动复制到新建数据库中,且复制到主数据文件中
数据库文件组
主文件组(primary 由系统定义):包含主要数据文件和其他数据文件,系统所有页均分配在主文件组中
用户定义文件组:用户可以创建自己的文件组,将数据库文件组织起来,便于管理和数据分配
日志文件为空为前提,它才可以被删除
①日志文件不包括在文件组内,日志空间与数据空间分开管理
,日志文件主要以记录为单位的日志文件和以数据块为单位的日志文件。
②一个文件可以是多个文件组的成员
③文件组中有多个文件,在所有文件被填满之前不会自动增长,填满后文件会循环增长
文件加入数据库后,不能移动到其他文件组
只能指定一个文件组为默认文件组
数据库文件属性
文件名及其位置:具有一个逻辑文件名和物理文件名,逻辑文件名必须是唯一。
多个数据文件,建议将文件分散存储在多个物理磁盘上
初始大小:指定主要数据文件的初始大小时,其大小不能小于model数据库主要数据文件的大小
增长方式:可指定文件是否自动增,默认配置为自动增长
最大大小:文件增长的最大空间限制,默认是无限制
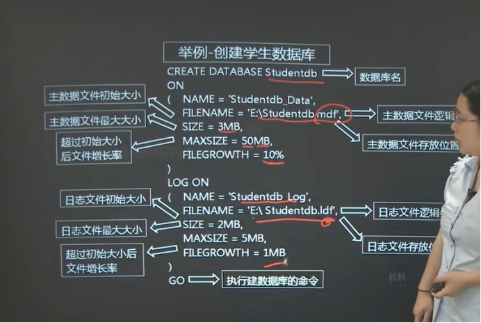
用T-SQL语句创建数据库
语法格式: CREATE DATABASE database_name
[ ON
[ PRIMARY ] [ <filespec> [, ...n]
[ ,<filegroup> [, ...n]
[ LOG ON { <filespec> [, ...n] } ]
]
]
< filespec > : : ={
(NAME = logical_file_name ,
FILENAME={ ‘ os_file_name’ | ‘filestream_path’
[ , SIZE = size [ KB | MB | GB | TB ] ]
[ , MAXSIZE = max_size [ KB | MB | GB | TB ] | UNLIMITED ]
[ , FILEGROWTH= growth_increment [ KB | MB | GB | TB | % ] ]
) [ , ...n] }
< filegroup > : : = {
FILEGROUP filegroup_name [ DEFAULT ]
< filespec > [ , ...n ] }
Database_name:新数据库名
ON:指定数据文件
PRIMARY:指定关联数据文件的主文件组
LOG ON:指定日志文件
<filespec>:定义文件属性
NAME=logical_file_name:指定文件的逻辑名称
FILENAME= ‘ os_file_name’:指定操作系统(物理)文件名
SIZE = size:指定文件的初始大小
MAXSIZE = max_size :指定文件可增大最大大小
UNLIMITED:指定文件的增长无限制
FILEGROWTH=growth_increment:指定文件的自动增量
growth_increment :每次文件添加的空间量
< filegroup > :文件组属性
FILEGROUP filegroup_name:文件组的逻辑名称
修改数据库 modify修改

扩大数据空间
语法格式: ALTER DATABASEdatabase_name
{ < add_or_modify_files > }
< add_or_modify_files >: : =
{
ADD FILE < filespec > [ , ...n ]
[ TO FILEGROUP{ filegroup_name | DEFAULT } ]
|ADD LOG FILE <filespec> [ , ...n ]
| MODIFY FILE < filespec >
database_name:要修改的数据库名
< add_or_modify_files >:在数据库中添加新的数据库文件
TO FILEGROUP { filegroup_name | DEFAULT }:将指定文件添加到文件组
<filespec>:文件属性
ADD LOG FILE:在数据库中添加新的日志文件
MODIFY FILE:指定要修改的文件
收缩数据空间shrinkdatabase 收缩
收缩整个数据库大小
语法格式: DBCC SHRINKDATABASE
(‘ database_name’ | database_id | 0 ‘)
[ ,target_percent ]
[ ,{ NOTRUNCATE | TRUNCATEONLY ]
)
‘database_name’ | database_id | 0 :要收缩的数据库名称和ID;指定0,则表示收缩当前正在使用的数据库
target_percent:数据库收缩后文件所需的剩余空间百分比
NOTRUNCATE:数据库文件保留释放的文件空间;若未指定,则释放给操作系统
TRUNCATEONLY:将文件中任何未使用的空间均释放给操作系统,收缩到最后分配大小
收缩指定文件大小
语法格式: DBCC SHRINKDATABASE
( ‘file_name’
{ [ ,EMPTYFILE ]
| [ [ ,target_size ] [ , [ {NOTRUNCATE | TRUNCATEONLY } ] ]
}
)
file_name:要收缩的文件逻辑名
target_size:指定收缩后目标文件大小
EMPTYFILE:指定将文件中的所有数据迁移到同一个文件组的其他文件中
NOTRUNCATE:数据库文件保留释放的文件空间;若未指定,则释放给操作系统
TRUNCATEONLY:将文件中任何未使用的空间均释放给操作系统,收缩到最后分配大小
添加和删除数据库文件
语法格式: ALTER DATABASEdatabase_name
REMOVE FILElogical_file_name
database_name:要删除的数据库名
logical_file_name:被删除文件的逻辑名
分离和附加数据库
分离数据库
语法格式: sp_detach_db[ @ dbname= ] ‘ dbname ’
[ , [ @ skipchecks= ] ‘ skipchecks ’
[ @ dbname= ] ‘ dbname ’ :要分离的数据库名称
[ @ skipchecks= ] ‘ skipchecks ’ :指定跳过还是运行 “更新统计信息”;
若跳过,则true;若显示运行,则false
附加数据库
语法格式: CREATE DATABASE database_name
ON <filespec> [ , ...n]
FOR { ATTACH | ATTACH_REBUILD_LOG }
database_name:要附加的数据库名称
<filespec> :指定要附加的数据库的主要数据文件
FOR ATTACH_REBUILD_LOG:指定附加现有的操作系统文件创建数据库
只限于读/写的数据库;若缺少日志文件,重新生成
架构(或模式SCHEMA)
架构(Schema,也称为模式)是数据库下的一个逻辑命名空间,可以存放表、视图等数据库对象。一个数据库可以包含一个或多个架构,架构由特定的授权用户所拥有;在同一个数据库中,架构名必须唯一;架构名可以是显示的,也可以由DBMS提供默认名。
定义架构
架构:数据库下的逻辑命名空间,可存放数据库对象
一个数据库可以包含一个或多个架构,由特定的授权用户拥有。
同一数据库中架构名必须唯一;一个架构由零个或多个架构对象组成。
定义架构可同时定义表TABLE、视图VIEW、用户授权GRANT
语法格式: CREATE SCHEMA [ <架构名> ] AUTHORIZATION <用户名>
若未指定<架构名>,则<架构名>隐含为<用户名>
删除架构
语法格式: DROP SCHEMA <架构名> { <CASCADE> | <RESTRICT> }
CASCADE:删除架构的同时将该架构中的所有架构对象一起全部删除
RESTRICT:如果被删除的架构中包含架构对象,则拒绝删除此架构
批处理语句
BEGIN TRANSACTION ....... COMMIT TRANSACTION
分区表
创建分区函数
SQL语句:CREATE PARTITION FUNCTION partition_function_name (input_parameter_type)
AS RANGE [ LEFT | RIGHT ]
FOR VALUES ( [ boundary_value [ , ...n ] ] )
[ ; ]
partition_function_name:分区函数名
input_parameter_type:用于分区的列的数据类型
boundary_value:为每个分区指定边界
...n:提供值的数目,n≦999
LEFT | RIGHT:指定间隔值由数据库引擎按升序从左到右排序;若未指定,则默认为LEFT
说明:
①分区函数的作用域仅限于创建该分区的数据库
②分区列空值的所有行在最左侧;最左侧分区为空分区,NULL值被放置在后面分区中
左分区
例:CREATE PARTITION FUNCTION myRangeF1(int)
AS RANGE LEFT FOR VALUES(1,100,1000)
分区
1 coll<=1
2 coll>1 AND coll<=100
3 coll>100 AND coll<=1000
4 coll>1000
右分区
例:CREATE PARTITION FUNCTION myRangeF2(int)
AS RANGE RIGHT FOR VALUES(1,100,1000)
分区
1 coll<1
2 coll>=1 AND coll<100
3 coll>=100 AND coll<1000
4 coll>=1000
创建分区方案
SQL语句:CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ , ...n ] )
[ ; ]
partition_scheme_name:分区方案名
partition_function_name:分区函数名
ALL:指定所有分区映射到file_group_name中提供的文件组
{ file_group_name | [ PRIMARY ] } [ , ...n ]:指定分区的文件组名
创建分区表
CREATE TABLE table_name(
列名 数据类型,
...
)
ON schema_name(列名)
索引

创建索引
语法格式: CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX INDEX_NAME
ON <object> (column [ASC | DESC ] [ , ...n ] )
[ INCLUDE ( column_name [ , ...n ] ) ]
[ WHERE <file_predicate> ]
[ ON { partition_scheme_name ( column_name )
| filegroup_name
| default
}
]
[ FILESTREAM_ON { filestream_filegroup_name | partition_scheme_name | “NULL” } ]
[ ; ]
<object> : :=
{
[database_name. [ schema_name ]. | schema_name. ] table_or_view_name
}
UNIQUE:为表或视图创建唯一索引
CLUSTERED:创建聚集索引 clustered 簇
NONCLUSTERED:默认选项,创建一个非聚集索引
Index_name:索引名
Column:索引所基于的一个列或多列
[ ASC | DESC ]:ASC为升序,DESC为降序
INCLUDE ( column [ , ...n ] ):指定要添加非聚集索引的叶级别的非键列。
WHERE< filter_predicate >:指定筛选条件后系统满足筛选条件的数据行上建立索引
ON partition_scheme_name (column_name):指定分区方案
ON filegroup_name:指定文件组索引
ON “ default”:默认文件组索引
删除索引
语法格式: DROP INDEX { index_name ON <object> [, ...n] }
{
[database_name. [ schema_name ]. | schema_name. ] table_or_view_name
}
视图索引
建立唯一聚集索引的视图,称为索引视图,也称为物化视图。 “建立索引后,视图的结果集存放在数据库中,对基本表的修改会反映到索引视图存储的数据中。”
适合建立视图索引的场合:
①很少更新基础数据
②以批处理的形式更新,只读数据进行处理
提高性能:
①处理大量行的连接和聚合
②许多查询经常执行的连接和聚合操作
不能提高性能:
①具有大量写操作的OLTP系统
②具有大量更新操作的数据库
③不涉及聚合或连接的查询
④GROUP BY列具有高基数度的数据聚合
定义索引视图:
①视图只能引用基本表
②基本表与视图位于同一个数据库
③必须使用SCHEMABINDING选项创建视图
④引用的函数必须正确
⑤第一个索引必须是唯一聚集索引
数据库后台编程技术
存储过程:存储在数据库中供所有用户程序调用的子程序
系统存储过程、用户自定义存储过程、扩展存储过程
存储过程的好处:
①允许模块程序化设计
②改善性能,批处理
③减少网络流量
④增强应用程序安全设计
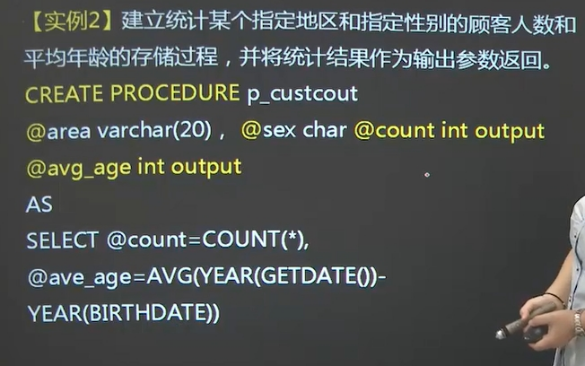
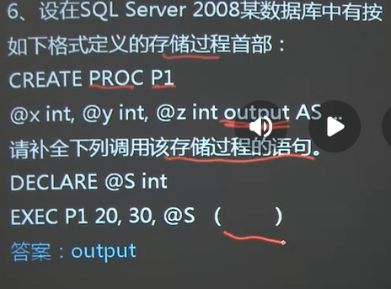
创建存储过程procedure AS
语法格式: CREATE { PROC | PROCEDURE }[ schema_name. ] procedure_name
[ { @parameter [ type_schema_name. ] data_type }
[ =default ] [ OUT | OUTPUT ]
] [ , ...n ] [ WITH RECOMPILE ]
AS{ <sql_statement> [ ; ] [ ...n ] }
[ ; ]
<sql_statement> : : ={ [ BEGIN ] statements [ END ] }
schema_name:过程所属架构名
procedure_name:存储过程名
@parameter:存储过程的参数
[ type_schema_name. ] data_type:参数以及所属架构的数据类型
default:参数的默认值
OUTPUT:输出参数
RECOMPILE:数据库引擎不缓存该计划,在运行时被重新编译

执行存储过程 execute
语法格式: [ {EXEC | EXECUTE } ]
{
[ @return_status= }
{ proc_name }
[ [ @parameter_name= ] { value
| @variable [ OUTPUT ]
| [DEFAULT ]
}
]
[ , ...n ]
[ WITH RECOMPILE ]
}
[ ; ]
return_status:可选的整型标量,存储过程的返回状态
proc_name:要调用的存储过程名
@variable:用来存储参数或返回参数的变量
Parameter:存储过程的参数,必须与存储过程中定义的相同
删除存储过程
语法格式: DROP { PROC | PROCEDURE } { [schema_name. ] procedure } [ , ...n ]
用户定义函数begin end
创建和调用标量函数
语法格式: CREATE FUNCTION [ schema_name. ] function_name
( [ { @parameter_name [ AS ] [ type_schema_name. ] parameter_data_type
[ =default ] }
[ , ...n ]
]
)
RETURNS return_data_type
[ AS ]
BEGIN
function_body
RETURN scalar_expression
END
[ ; ]
schema_name:用户自定义函数所属构架的名称
function_name:用户定义的函数名称
@parameter_name :用户定义的函数参数
[ type_schema_name. ] parameter_data_type:参数的数据类型及其所属的架构
return_data_type:用户定义函数返回的标量值
scalar_expression:指定标量函数返回的标量值
调用标量函数: 例 SELECT dbo.CubicVolume(4,6,8)

创建和调用内联表值函数
内联表值函数的返回值是一个表,该表的内容是一个查询语句的结果
语法格式: CREATE FUNCTION [ schema_name. ] function_name
( [ { @parameter_name [ AS ] [ type_schema_name. ] parameter_data_type
[ =default ] }
[ , ...n ]
]
)
RETURNS TABLE
[ AS ]
RETURN [ ( ] select_stmt [ ) ]
[ ; ]
调用内联表值函数:SELECT * FROM dbo.f_GoodsInfo(‘服装’)
创建和调用多语句表值函数
语法格式: CREATE FUNCTION [ schema_name. ] function_name
( [ {@parameter_name [ AS ] [ type_schema_name. ] parameter_data_type
[ =default ] }
[ , ...n ]
]
)
RETURNS @return_variable TABLE <table_type_definition>
[ AS ]
BEGIN
INSERT INTO @return_variable
function_body
RETURN
END
[ ; ]
<table_type_definition> : : =
( { <column_definition> <column_constraint>
| <computed_column_definition> }
[ <table_constraint> ] [ , ...n]
)
function_body:T-SQL语句,用于填充TABLE返回变量
table_type_definition:定义返回表的结构
调用多语句表值函数:例 SELECT * FROM dbo.f_GoodsType (‘家用电器’)
触发器AS begin end

触发器场合:
①完成比CHECK约束更复杂的数据约束
②为保证数据库性能而维护的非规范化数据
③可实现复杂的商业规则
④可以评估数据修改前后的表状态,并根据其差异采取对策
语法格式: CREATE TRIGGER [ schema_name. ] trigger_name
ON [ table | view ]
{ FOR | AFTER | INSTEAD OF
{ [ INSERT ] [ , ] [ UPDATE ] [ , ] [ DELETE ] }
AS { sql_statement }
[ ; ]
schema_name:触发器所属架构名称
trigger_name:触发器名称
table | view:关联的表或视图
FOR | AFTER :不能在视图上定义AFTER触发器
INSTEAD OF :指定执行触发器
INSERT UPDATE DELETE :引发触发器执行的操作
DELETED表 :用于存储DELETE和UPDATE语句所影响的行复本
INSERTED表 :用于存储INSERT语句所影响的行复本
UPDATE :类似于在删除之后执行插入
创建后触发型触发器
ALTER类型同一操作可建立多个触发器,INSTEAD OF 类型一张表同一数据操作上可建立一个触发器,DROP语句在触发器中禁止使用,触发器不反回任何结果
使用FOR或AFTER选项定义的触发器为后触发型触发器
只有在引发触发器执行的语句中的操作已成功执行,且所有约束检查成功后,才执行触发器
创建前触发型触发器
使用INSTEAD OF选项定义的触发器以前触发型触发器
指定执行触发器而不是执行引发触发器执行的SQL语句,从而代替引发语句的操作
删除触发器
DROP TRIGGER schema_name. Trigger_name [ , ...n ] [ ; ]


游标** FOR
实现对SELECT结果集的逐行处理
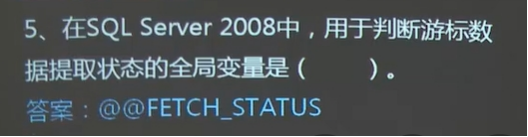
在对游标数据进行提取的过程中,可以使用@@FETCH_STATUS全局变量判断数据提取的状态。由于@@FETCH_STATUS对于在一个连接上的所有游标是全局性的,不管是对哪个游标,只要执行一次FETCH语句,系统都会对@@FETCH_STATUS赋一次值,以表明该FETCH语句的执行情况。
声明游标:
语法格式:DECLARE cursor_name [ INSENSITIVE ] [ SCROLL ] CURSOR
FOR select_statement
[ FOR { READ ONLY | UPDATE [ OF column_name [, ...n ] ] } ]
cursor_name:服务器游标名
INSENSITIVE:定义一个游标,创建将由该游标使用的数据临时复本
SCROLL:指定的所有提取项
select_statement:定义游标结果集的标准SELECT语句
READ ONLY:禁止通过该游标更新数据
UPDATE:定义游标中可更新的列、
打开游标:
OPEN cursor_name
Cursor_name:游标名
提取数据:FETCH
语法格式: FETCH [ [ NEXT | PRIOR | FIRSE | LAST
| ABSOLUTE n
| RELATIVE n ]
FROM
]
cursor_name [ INTO @variable_name [ , ...n ]
NEXT:返回紧跟当前行之后的数据行,并且当前行递增为结果行
PRIOR:返回紧临当前行前面的数据行,并且当前行递减为结果行
FIRST:返回游标中的第一行将其作为行
LAST:返回游标中的最后一行将其作为行
ABSOLUTE[n]:提取游标中的第n行
RELATIVE[n] | [-n] :提取当前行的后边的第n行| 提取当前行前边的第n行
cursor_name:从中进行提取数据的游标名
INTO @variable_name:将提取的列数据保存到局部变量中
@@FETCH_STATUS:返回的数据类型是int
关闭游标:
CLOSE cursor_name
释放游标:deallocate
DEALLOCATE cursor_name
安全管理
Oracle的安全控制可分为数据库级、表级、行级和列级
安全控制概述
安全性:保护数据以防止不合法用户故意造成破坏
完整性:保护数据以防止合法用户无意中造成破坏
数据安全控制目标:保护数据免受意外或故意的丢失、破坏或滥用
数据库安全威胁:可用性损失、机密性 私密性数据损失、偷窃和欺诈、意外损害
安全控制:身份验证——操作权限控制——文件操作控制——加密存储与冗余
认证:鉴定用户身份的机制
存取控制
自主存取控制
权限种类:维护权限、操作权限(语句、对象权限)、隐含权限
用户分类:系统管理员(SA)、数据库对象拥有者、普通用户
强制存取控制
主体:活动实体 许可证级别
客体:被动实体 密级
敏感度标记(Label):绝密(Top Secret)、秘密(Secret)、可信(Confidential)、公开(Public)
仅当主体许可证级别大于或等于客体密级,主体可以读取相应客体
仅当主体许可证级别等于客体密级,该主体才能写相应客体。
安全性分级模式:D类最小保护、C类自主保护、B类强制保护、A类验证保护
SQL Seriver安全控制
身份验证模式:Windows身份验证、混合身份验证
登陆账户:自身负责身份验证、Windows网络(组/用户)只能连接SQL Server数据库服务器,并不具有访问任何用户数据库权限
建立登录账户:CREATE LOGIN login_name WITH PASSWORD=’****’
| FROM (域) | MUST_CHANGE (必须更改密码)
修改登录帐户属性:ALTER LOGIN login_name WITH PASSWORD=’****’ (修改密码)
| ENABLE (启用) | WITH NAME=*** (改名)
删除登录帐户:DROP LOGIN login_name
数据库用户:默认情况,新建立的数据库只有一个用户:database owner,数据库的拥有者
登录账户成为数据库用户的操作称为“映射”
每个数据库中均已存在guest用户,默认禁用状态,授予CONNECT启用
先删除或转移安全对象的所有者,再删除拥有这些对象的数据库用户
创建数据库用户:
CREATE USER user_name [|FOR|FROM]
LOGIN login_name
Guest用户:
GRANT CONNECT TO guest 启用
REVOKE CONNECT TO guest 禁用
删除数据库用户:DROP USER user_name
权限管理
对象级别权限:SELECT、INSERT、UPDATE、DELETE、REFERENCES(引用)、EXECUTE
语句级别权限:CREATE DATABASE、PROCEDURE、TABLE、VIEW、FUNCTION、
BACKUP DATABASE、LOG
语句权限:授予语句级别权限使用GRANT语句
拒绝权限:拒绝用户具有某权限使用DENY语句
收权语句:将已授权用户权限收回来,语句使用REVOKE语句
角色
一组具有相同权限的用户就是角色;角色分为预定义的系统角色(又分为固定服务器角色和固定数据库角色)和用户角色是数据库级别角色
固定服务器角色:作用域属于服务器范围,可以将登录账户添加到固定服务器角色
Bulkadmin:执行BULK INSERT语句权限。
Dbcreator:创建、修改、删除还原数据库权限。
Diskadmin:具有管理磁盘文件的权限
Processadmin管理运行进程权限。
Securtyadmin:专门管理登录账户、读取错误日志执行CREATE DATABASE 权限的账户,便捷。
Serveradmin:服务器级别的配置选项和关闭服务器权限。
Setupadmin:添加删除链接服务器。
Sysadmin:系统管理员 ,Windows超级用户自动映射为系统管理员。
Public:系统预定义服务器角色,每个登录名都是这个角色的成员。没有授予或拒绝特定权限,则将具有这个角色权限。
添加成员:EXEC Sp_addsrvrolemember ‘user1’ (登录名),‘sysadmin’(角色名)
删除成员:EXEC Sp_dropsrvrolemember‘user1’,‘sysadmin’
固定数据库角色:存在于每个数据库中,具有数据库角色权限
Db_accessadmin:添加或删除数据库权限
Db_backupoperator:备份数据库、日志权限
Db_datareader:查询数据库数据权限
Db_datawriter:具有插入、删除、更改权限
Db_ddladmin:执行数据定义的权限
Db_denydatareader:不允许具有查询数据库中所有用户数据的权限。
Db_denydatawriter:不允许具有插入、删除、更改数据库中所有用户数据权限。
Db_owner:具有全部操作权限,包括配置、维护、删除数据库。
Db_securityadmin:具有管理数据库角色、角色成员以及数据库中语句和对象的权限。
用户定义角色:数据库一级角色,可以是用户定义角色或数据库用户
创建用户定义的角色:CREATE ROLE MathDept [AUTHORIZATION (拥有者) Software]
删除用户定义角色:DROP ROLE MathDept
注意: 角色中的成员拥有的权限=成员自身权限+所在角色权限
但若某个权限在角色中被拒绝,则成员不再拥有。
数据库运行维护与优化
保证数据库系统安全、可靠且高效率地运行
数据库运行维护基本工作
数据库的转储与恢复
数据库的安全性、完整性控制
检测并改善数据库的性能
数据库的重组和重构
重组:不修改数据库原有设计的逻辑和物理结构;存储空间分配零散
重构:部分修改数据库的模式和内模式;数据库设计不能满足新的需求
数据库重组是指按照系统设计要求对数据库存储空间进行全面调整,如调整磁盘分区方法和存储空间、重新安排数据的存储、整理回收碎块等,以提高数据库性能。
数据库的重构是指由于数据库应用环境的不断变化,增加了新的应用或新的实体,取消了某些应用,有的实体与实体间的联系也发生了变化等,使得原有的数据库设计不能满足新的需求,此时需要调整数据库的模式和内模式。
运行状态监控与分析
自主监控机制手动监控机制
对数据库构架体系的监控:空间使用率与剩余大小的空间、空间扩展
对数据库性能的监控:数据缓冲区的命中率、用户锁、回滚段、临时段、索引、事件
数据库存储空间管理
空间使用情况问题:降低数据库系统服务性能 空间溢出导致灾难停机事故
数据存储结构:逻辑存储结构、物理存储结构
DBMS对空间的管理包括:创建数据库空间、更改空间大小、删除空间、修改空间状态,新建、移动、关联数据文件等。
数据库性能优化***
数据库运行环境与参数调整
外部调整:CPU性能和网络传输
调整内存分配:调整相关参数控制数据库的内存分配
调整磁盘I/O:性能优劣度量是时间;令I/O时间最小化,减少磁盘文件竞争
调整竞争:
①修改参数以控制连接到数据库的最大进程
②减少调度进程竞争
③减少多线程服务进程竞争
④减少重做日志缓冲竞争
⑤减少回滚段竞争
模式调整与优化
规范化过程:高效率利用存储空间,减少数据冗余,减少数据的不一致
反规范化:将规范化关系转换成非规范化的关系的过程;破坏数据完整性
增加派生性冗余列:增加的列由表中的一些数据项经过计算生成。提高查询统计速度,空间换时间;减少连接操作,避免使用聚合函数
增加冗余列:在多个表中增加具有相同语义的列;避免连接操作。
重新组表:用户查看的某些数据由多个表连接之后得到,把这些数据重组成一个表
分割表:①水平分割:表结构相同,存储数据不同,需要union操作
②垂直分割:除了主码外其他列不相同,常用列与不常用列分别放在不同表中
查询减少I/O次数,缺点是使用连接Join操作
新增汇总表:频繁使用的统计操作的中间结果或最终结果存储在汇总表,降低数据访问量和汇总操作的CPU计算量
存储优化
物化视图:包括一个查询结果的数据库对象,预先计算并保存耗时较多的操作结果
可以进行远程数据的本地复制
聚集:物理存储表中数据的可选择的方法;可最小化必须执行的I/O次数
聚集表的插入、更新、删除性能差
将经常一起使用的具有公共列值的多个表中的数据行存储在一起的数据库存储方法被称为聚集。
查询优化:
将数据文件和索引文件放置在同一磁盘上不利于提高查询效率。
1.合理使用索引:索引提高查询效率,增加系统开销
建立原则:是否为一个属性建索引
在哪些属性建立索引
是否建立聚簇索引 适合范围查询
使用散列还是树索引,散列索引适合等值查询,B+树索引适合等值查询和范围查询
使用原则:
经常在查询中作为条件被使用的列
频繁进行排序或分组的列
一个列的值域很大时
待排列的列有多个
数据表更新大量数据后,删除并重建索引
调整和修改原因:
缺少索引,某些查询语句执行时间过长
索引没有使用,占用较多磁盘空间
索引建立在被频繁改变的属性上,导致系统开销过大
2.避免或简化排序
影响:
现有索引不足,导致排序索引中不包括一个或几个待排序的列
Group by和Order by子句中列的次序与索引次序不一致
排列的列来自不同的表
3.消除对大型表数据的顺序存取:对连接列进行索引,或使用并集来避免顺序存取。
4.避免复杂正则表达式:消耗较多CPU资源进行字符串匹配
5.使用临时表加速查询:将表的一个子集进行排序并创建临时表
6.用排序来取代非顺序磁盘存取:非顺序磁盘存取最慢
7.不充分的连接条件:左(右)外连接包含与NULL数据匹配,相比内连接,代价可能很高。
8.存储过程:尽量使用自带返回参数,减少不必要参数,避免数据冗余
9.不要随意使用游标:占用较多系统资源
10.事务处理:将频繁操作的多个可分割的处理过程放入多个存储过程中
SQL Seriver 性能工具
SQL Server Profiler:监视SQL Server事件的工具,存储在跟踪文件中,分析文件诊断问题
数据库引擎优化顾问:测试数据库工作负荷,给出优化建议。




故障管理
故障管理概述
事务内部故障
预期:事务程序本身发现的事务内部故障,事务回滚
非预期:事物内部故障不能由事务程序处理,
并发死锁属于非预期的事务内部故障
对于非预期的事物内部故障,在保证该事务对其他事务没有影响的条件下,利用日志文件撤销其对数据库的修改,使数据库恢复到该事物运行之前的状态。事务故障的恢复是由系统自动完成的,对用户是透明的。
系统(软)故障
由于硬件故障、突然停电等情况,导致系统停止运行
需要系统重新启动;回滚(或撤销UNDO)未完成的事务,重做(REDO)已提交的事务
介质(硬)故障
由于磁盘损坏、强磁干扰等情况,导致数据部分丢失或全部丢失
故障发生可能性小,但破坏大
软件容错:备份与日志文件,只能恢复到备份数据库后的某个时间点
硬件容错:双物理存储设备,达到数据库完全恢复效果
计算机病毒故障(网络安全)
防火墙、杀毒软件、数据库备份文件
数据库技术恢复概述
把数据库从错误状态恢复到某一已知的正确状态
在DBMS中,数据库恢复子系统占10%以上
恢复机制涉及两个问题:
建立冗余数据
利用这些冗余数据实施数据库恢复

数据转储
定期复制数据库,并将数据存放其他介质中,被称为后援副本或后备副本
静态转储和动态转储
静态转储:不能运行其他事务;转储前后系统必须处于一致的状态
保证数据有效性,但降低数据库可用性
动态转储:允许转储操作和用户事务并发进行;在数据库进行存取和修改操作
提高数据库可用性,但数据有效性不能保证
动态转储+日志文件:记录转储期间各事务对数据库的修改活动记录
保证数据一致性,提高数据库可用性
数据转储机制
完全转储:对数据库所有数据进行转储,占据时间和空间,恢复时间最短
增量转储:只复制上次转储之后发生变化的文件或数据块,比完全转储恢复时间长
差量转储:对近一次数据库完全转储发生的数据变化进行转储,占用较小空间,比增量转储恢复速度快
仅使用完全转储:大量数据移动,占用时间和空间
完全转储加增量转储:每隔一段时间进行一次完全转储,在其中间执行多次增量转储,避免大量数据移动,恢复时间长,转储出问题导致失败
完全转储加差量转储:操作简单、时间比较短
差量转储和增量转储相比速度慢、占用空间多,但是恢复速度快。
日志文件
日志文件概念
作用:事务故障恢复和系统故障恢复必须使用日志文件
在动态转储方式中必须建立日志文件
在静态转储方式中也可使用日志文件
故障恢复的操作:
①UNDO () 撤销事务(开始记录:删除、插入)已经开始但未提交
②REDO () 重做事务(提交记录:更新)已完成并提交
日志文件的格式与内容
①以记录为单位的的日志文件
开始标记:BEGIN TRANSACTION
结束标记:COMMIT OR ROLLBACK
各个事务的所有更新操作
②以数据块为单位的日志文件
事务标识和被更新的数据块
更新前的整个块和更新后的整个块
日志记录:开始标记、结束标记、更新操作
登记日志文件原则
①登记的次序严格按并行事务的执行时间次序
②必须先写日志文件,后写数据库
检查点
作用:最大限度的减少数据库完全恢复时必须执行的日志部分
检查点的引入
①检查点记录的内容(事务清单、地址、)
②重新开始文件记录的内容
③动态维护日志文件的方法:建立检查点,保存数据库状态
硬件容错方案
相关度最紧密的技术:数据库存储保护技术、服务器容错技术、数据库镜像与容灾技术
磁盘保护技术
RAID:廉价冗余磁盘阵列,多块磁盘构成一个整体
镜像冗余:把所有数据复制到其他设备上或其他地方;开销大
校验冗余:对成员磁盘上的数据执行异或(XOR)操作,其校验值放在另外校验磁盘
RAID-0:将多个磁盘合并一个大的磁盘,不具有冗余,并行I/O,速度最快
RAID-1:两组以上的N个磁盘相互作镜像;并行传输,提高读速度,加强可靠性
RAID-5:把分块数据和奇偶校验信息写入硬盘阵列;至少需要三颗硬盘,RAID5的读取性能与RAID0接近,但写入速度比单个磁盘稍慢,而数据的可靠性高于RAID0。
RAID-10:RAID0与RAID-1的组合体;前者的快速,后者的安全,冗余度为50%
RAID卡做成RAID5,需一块硬盘用来存储奇偶校验信息,因此当RAID5磁盘损坏,不会 影响数据的完整性
RAID1相对于RAID0来说提高了读速度,加强了系统的可靠性,但是写效率没有提高。
服务器容错技术
引入服务器容错原因:解决服务器硬件异常问题
服务器容错技术简介:采用两台相同的服务器,共享存储设备
双机热备,Active-Standby
两台服务器之间会有私有网络进行心跳检测
其他服务器容错技术 :硬件、软件级别
数据库镜像与数据库容灾
数据库镜像分类:
①双机互备援模式;均为工作机,互相监视对方
②双机热备份模式:工作机和备份机,备份机监视工作机
SQL Server数据库镜像:将数据库事务处理从一个数据库移到不同的数据库
实现方式:
①高可用性:同步事务写入,自动错误恢复
②高保护性:同步事务写入,手动错误恢复
③高性能:不同步写入,手动错误恢复
章备份与恢复数据库
备份与恢复概念
造成数据丢失的原因:存储介质故障、用户的操作失误、服务器故障、病毒侵害、自然灾害
恢复数据库:
①介质故障恢复:还原最近的数据库副本并利用备份日志重做已提交的操作
②非介质故障,在数据库系统重启之后,进行REDO和UNDO操作
备份与恢复机制

SQL Server 2008支持数据库、数据文件两个级别的数据恢复。
在SQL Server 2008系统数据库中,只有tempdb数据库不需要备份,其他的都需要备份。tempdb只是一个临时数据库,每次SQL Server启动时都会重新新建tempdb数据库。
备份策略的制定包括定义备份的类型和频率、备份所需硬件的特性和速度、备份的测试方法以及备份媒体的存储位置和方法。
1.简单恢复模式:简略地记录大多数事务,不备份事务日志 SIMPLE
减少事务日志的管理开销,只能恢复到最新备份状态
简单恢复模式只用于测试和开发数据库,或用于主要包含只读数据的数据库(如数据仓库),这种模式并不适合生产系统,因为对生产系统而言,丢失最新的更改是无法接受的。
2.完整恢复模式:完整地记录了所有的事务,并保留所有的事务日志记录 FULL
支持还原单个数据页,可以恢复到故障点
3.大容量日志恢复模式:只对大容量操作进行最小记录 BULK_LOGGED
提供最佳性能并占用最小日志空间 不支持时点恢复
备份内容及时间:
用户数据:周期性备份
系统数据:修改之后进行备份
立刻备份:创建数据库、索引之后,清理事务日志、大容量数据操作之后
备份机制
备份方式:
①永久备份设备:先建立备份设备,再将数据库被分到备份设备
②临时备份设备:直接将数据库备份到物理文件上
远程备份:启动数据库引擎时对远程计算机有写的权限
使用差异备份时,应定期进行完整备份
备份类型:
①数据库备份:完整数据库备份、差异数据库备份(DIFFERENTIAL)
②文件备份:文件备份、差异文件备份
③事务日志备份:纯日志备份,大容量操作日志备份,结尾日志备份(有损坏)
结尾日志备份在出现故障时进行,用于防止丢失数据,可以包含纯日志记录或者大容量操作日志记录。
纯日志备份只包括一定时间间隔内的事务日志,不包含大容量操作日志记录 结尾日志备份是恢复计划中的最后一个相关备份。
事务日志备份仅用于完整恢复模式和大容量日志恢复模式
备份策略:
完整备份:数据库数据不大,更改不频繁
完整备份 + 日志备份:不允许丢失太多数据,不希望经常完整备份
完整备份 + 差异备份+ 日志备份:备份和恢复速度快、数据丢失少
实现备份:
BACKUP DATABASE | LOG database_name
FILEFROUP=’ ***’ (辅助文件组)
TO 备份设备名| {DISK |TAPE} (磁盘 磁带)
WITH INIT (覆盖) | NOINIT (追加) | DIFFERENTIAL (差异数据库备份)
恢复机制
数据库:数据库完整还原
数据文件:文件还原
还原顺序:
1.恢复最近的完全备份
2. 恢复最近的差异备份
3. 恢复自差异备份之后的所有日志备份
4. 恢复数据库

实现还原:RESTORE DATABASE | LOG database_name
FROM 备份设备名
WITH FILE | RECOVER | NORECOVER | STANDBY
使用with recovery选项后,数据库将不能再使用后续备份进行恢复
大规模数据库架构
分布式数据库
分布式数据库系统:数据分布在物理位置不同的计算机,由通信网络连接
场地既能独立处理,也可和其他场地协同工作。物理上分散、逻辑上集中。
分布式数据库:分布式数据库系统中各个场地上数据库的逻辑集合
分配模式是描述个片段到物理存放的映像
分布式数据库目标:
本地自治、非集中式管理、高可用性 (最基本特征)
位置独立性、数据分片独立性、数据复制独立性 (分布透明性)
分布式查询处理、分布式事务管理 (复杂性)
硬件独立性、操作系统独立性、网络独立性、数据库管理系统独立性
采用半连接操作可以减少场地之间的数据传输量
位置独立性、数据分片独立性和数据复制独立性是使分布式数据库具有分布式透明性的主要因素。
数据分布策略
数据分片:
① 水平分片;数据行的子集合,每一行至少属于一个片段
② 垂直分片;数据列的子集合,各片段包含关系主码属性
③ 导出分片;导出水平分片
④ 混合分片:以上三中的混合

数据分配:
① 集中式;所有数据片段都在安排在一个场地上
② 分割式:被分割若干份,每个片段被分配在特定场地
② 全复制式:有多个副本,每个场地有一个完整数据副本
④ 混合式:被分若干个数据子集,子集被安排一个或多个不同场地
分布式数据库的参考模式架构
外顶层
全局外模式:全局应用的用户视图
中间层
全局概念模式:描述全体数据的逻辑结构和特征
分片模式:全局数据的逻辑划分视图
分配模式:片段到物理存放地的映像
底层
局部概念模式:物理片段的逻辑结构和特征
局部内模式:局部概念涉及本场地的物理存储
分布透明性

分片透明性:最高级别透明性,无需考虑数据分片(全局概念与分片模式之间)
位置透明性:只需考虑数据分片情况,无需考虑数据分片位置
局部数据模型透明性:了解全局数据、副本复制及位置分配(分配与局部概念)
分布式数据库管理系统
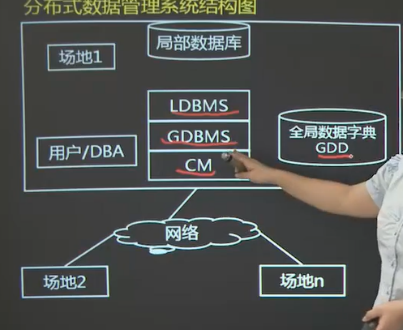
全局数据库管理系统 GDBMS 核心
全局数据字典 GDD
局部数据库管理系统 LDBMS
通信管理 CM
分布式查询
集中式数据库查询代价是CPU和I/O
分布式数据库查询代价是通信
分布式查询优化考虑:
操作执行顺序
操作执行算法(连接和并操作)
不同场地数据流动顺序
分布式事务管理
恢复控制:基于两阶段的提交协议
并发控制:基于封锁协议
并行数据库
并行数据库结构:
共享内存结构 内存冲突 互联网共享一个公共的主存储器
共享磁盘结构 通信代价 独立的主存储器,通过互联网共享磁盘
无共享结构 访问代价 拥有独立的主存储器和磁盘,不共享任何资源
无共享结构通过最小化共享资源来降低资源竞争的概率
层次结构 顶层无共享结构,底层共享内存/磁盘结构
一维划分:将大数据集水平划分到多个磁盘上,可以通过并行读写有效地利用多磁盘的I/O带宽

轮转法 扫描整个关系,负载均衡,并行性,降低查询效率
散列划分 哈希索引,点查询,数据扫描,数据划分不均衡
范围划分 记录排序,范围查询,点查询,数据分布不均匀,并行能力下降
多维数据划分:CMD多维划分、BERD多维划分法、MAGIC多维划分法
并行算法
并行顺序:
①重新按排序属性进行范围划分,然后划分排序,最后将结果合并
②并行外排序归并算法
并行连接:划分连接、分片—复制连接
云计算数据库架构
云:公共云、私有云、混合云
Saas:软件即服务
PaaS:平台即服务
IaaS:硬件即服务
云计算平台:Amazon的AWS、Google的GAE、开放云Hadoop
云计算通过集中所有的计算资源,采用硬件虚拟化技术,为云计算使用者提供强大的计算能力、存储和带宽等资源
云数据库体系结构:
文件系统Google File System
分布式编程环境Map/Reduce
分布式锁机制Chubby
大规模分布式数据库Big Table
云数据库缺点:数据安全、云管理、因特网依赖
Big Table数据模型:行关键字(Row Key)、列关键字(Column Key)、时间戳(Timestamp)
特点:表中的行关键字可以是任意字符串,列族是由列关键字组成的集合,是访问控制的基本单元。时间戳记录BigTable每一个数据项包含不同版本数据的时间标识。在BigTable中,不仅可以随意地增减行的数量,同在一定的约束条件下,还可以对列的数量进行扩展。
XML数据库
XML:可扩展标识语言,用标签来描述数据;标记电子文件,具有结构性

XML数据库三种类型:
XML (能处理XML的数据库)
NXD (纯XML数据库)
HXD (混合XML数据库)
优势:
能够对半结构化数据进行处理。
提供对标签和路径的操作。
能清晰地表达数据的层次特征
XML数据库适合管理复杂数据结构的数据集。
现阶段在现实环境中,一边使用的是原有的关系数据库厂商在其传统商业产品中进行了相关的扩充,使其能够处理XML数据的产品。
加入FOR XML子句实现XML格式返回查询结果
数据仓库与数据挖掘
决策支持系统的发展
数据仓库是核心
操作型系统是基本数据源
决策支持系统是数据的需求者
两类数据:原始数据(操作)、导出数据(分析)
数据仓库技术概述
数据仓库的特性:面向主题、集成、非易失的、随时间变化的
主题与面向主题
主题称为分析主题或分析领域
数据主题仓库的实现采用关系型数据库技术
数据仓库的其他特征

集成是最为重要的特性,分为数据抽取、转换、清理、装载
不可更新 随时间变化
数据集成:抽取、转换、清理、装载
ETL(Extract Transfrom Load)是实现数据集成的主要技术,即填充更新数据仓库的数据抽取、转换、装载的数据采集过程
ETL工具指从OLTP系统或其他数据环境中抽取数据的工具,主要解决分析型应用程序与OLTP应用程序之间的性能冲突问题。
数据仓库的体系结构与环境
层次结构划分:操作型数据、操作型数据存储、数据仓库、数据集市、个体层数据
功能结构划分:数据处理、数据管理、数据应用
数据仓库的数据组织
数据组织结构:早期细节级、当前细节级、轻度综合级、高度综合级
粒度:粒度越大,表示综合程度越高;粒度越小,细节程度越高,能回答的查询越多
数据分区
1.按照时间标准划分
2.
系统层分区 数据库系统提供的机制(逻辑上是表,物理上是不同分区)
应用层分区 应用代码实现(不同分区在逻辑和物理上是不同的表)
如何分区:开发者和程序员控制
元数据:描述数据的结构、内容、链和索引

描述数据的结构、内容、链和索引等
技术元数据 细节
业务元数据 业务
操作型数据存储
ODSⅠ:数据更新频率秒级。
ODSⅡ:数据更新频率小时级。
ODSⅢ:数据更新频率天级。
ODSⅣ:根据数据来源方向和类型区分
基本特点:面向主题的、集成的、可变的、 当前或接近当前的。
目的是支持:即时(up-to-sencond)联机分析应用、全局型PLTP应用
设计与建造数据仓库
数据仓库的需求设计
传统的系统开发生命周期 SDLC是典型的需求驱动开发生命周期
数据仓库环境的系统开发生命周期 CLDS是典型的数据驱动开发生命周期
数据仓库的数据模型
概念(E-R图)
逻辑(关系模型或多维数据模型)
物理三级:
①不包含纯操作型数据
②需要扩充关键字,加入时间属性
③需要增加导出数据
数据仓库的设计步骤
概念模型设计
技术评估与环境准备工作
逻辑模型设计
物理模型设计
数据生成与应用实现
数据仓库运行与维护
数据仓库的运行与维护
基本思路:根据某种维护策略,在一定条件下触发维护操作;维护操作捕捉到数据源中的数据变化;通过一定策略对数据仓库中的数据进行相应的更新操作,以保持两者的一致性。
维护策略
实时维护:立即更新数据仓库的数据
延时维护:视图被查询完成更新
在数据仓库的导出数据或物化视图(实视图)的维护策略中,只在用户查询时发现数据已经过期才进行更新的策略称为延时维护策略。
快照维护:触发条件是时间
增量维护:在原有数据基础上进行完善修改叫做增量维护
捕捉数据源变化
触发器、修改数据源应用程序、通过日志文件、快照比较法
导出数据的刷新
方法:①维护对象的数据源对其进行重新计算。
②数据源的变化量在维护对象原有数据的基础上进行添加和修改,增量维护
用户不可存取数据仓库时间的长短是衡量数据维护效率的重要指标。
将维护分为“聚集”和“更新”两个部分
元数据
采用元数据库来存储和管理元数据
联机分析与多维数据模型

联机分析处理或在线分析处理(OLAP)特点: 快速、可分析和多维
多维分析基本操作
钻取与卷起 对某一维向更细节层方向观察数据,卷起则反之
切片 局部数据的显示
旋转 改变维方向,不同视角数据;数据交叉
OLAP实现方式
多维数据库(MOLAP) 多维数组为基本存储结构。
关系数据库(ROLAP) 关系表表示和存储。(星形模式或雪花模式)
混合型的(HOLAP) 结合MOLAP与ROLAP。具有最好的查询性能。
数据挖掘技术
数据挖掘可以简单地理解为从大量数据中提取或挖掘知识,是数据库知识发现的一个步骤
建立数据仓库的主要目的在于根据决策需求对企业的数据采取适当的手段进行集成,形成一个综合的、面相分析的数据环境,用于支持企业的信息型、决策型的分析应用。
数据挖掘步骤
数据准备:数据选取、数据预处理、数据变换
数据挖掘:先确定挖掘的任务,其次决定挖掘算法
结果解释评估:剔除冗余或无关的模式
常见的挖掘任务:分类预测任务(决策树、贝叶斯),描述型任务(聚类、关联)
关联规则挖掘
阶段一:寻找高频项目组
阶段二:由高频项目组中产生关联规则
支持度:定义了属性在整个数据库中所占的比例
置信度:定义了发现规则的轻度
分类挖掘
预测数据对象的离散类别
①建立分类函数,构造分类器
②将分类函数对未知类别标记的数据项进行分类操作
聚类挖掘
聚类(无监督):对集中的数据进行分组,组内的数据尽量相似而不同组间的数据尽可能不同。
方法:统计(贝叶斯法和非参数法)、机器学习(决策树法和规则归纳法)、分类算法(训练集、测试集、验证集)、网络(BP算法)、
面向数据库
聚类算法(K-means算法)
时间序列分析
用时间排序的一组随机变量(数据演变分析)
角度:①一元时间序列和多元时间序列
②等间隔时间序列和不等间隔时间序列平时间序列和非平稳时间序列