
LangChain大模型应用开发指南-AI问答系统概念串讲

上两节节课,我以传统应用编程设计模式和思维为入口和对比对象,介绍了LangChain应用开发架构中的六大核心概念与组件,并整理了LangChain为众多开发者内置的能力与工具。没有看过的小伙伴可以点击链接查看: AI课程合集
今天我将整合之前讲授的六大组件,以一个面向实际场景的AI问答系统的开发案例将所有内容整合串讲,帮助大家更加深刻的理解之前的理论和概念,话不说多,show me the code。
使用 LangChain 构建一个问答系统?
 在本节中,我将给您展示如何使用 LangChain 构建一个基于语言模型的问答系统,它可以根据用户提出的问题,判断解决用户问题是否需要使用检索工具或是本地文档,针对特定问题从网页或文档中检索相关信息,并生成简洁和准确的回答。我们将使用以下个核心概念和组件:
在本节中,我将给您展示如何使用 LangChain 构建一个基于语言模型的问答系统,它可以根据用户提出的问题,判断解决用户问题是否需要使用检索工具或是本地文档,针对特定问题从网页或文档中检索相关信息,并生成简洁和准确的回答。我们将使用以下个核心概念和组件:
- Conversational(Agent):用于与用户进行自然对话,并接收用户提出的问题,根据提问内容选择具体使用的处理工具。
- RetrievalQA(Retriever):用于从自定义资料集中检索相关内容。
- DuckDuckGoSearchRun(tool): 用于访问DuckDuckGoSearch搜索API。
- Prompts & Structured output parser(ModelIO):用于定义接收对话的模板以及结构化搜索引擎查询到的结果并生成一个简洁和准确的回答。
- SequentialChain(Chain):用于按照顺序执行以上组件,并将每个组件的输出作为下一个组件的输入。
- ConversationBufferMemory(Memory):用于在对话中记住以前的交互置,以便在后续的对话中使用。
- StdOutCallbackHandler:用于进行日志记录。
下面,我将给出代码示例及运行结果截图。
问答系统代码示例及运行截图
如下代码主要是为了让大家对langchain的相关组件与模块有一个整体的感受,形成使用LangChain进行AI应用开发的框架印象,因而将所有代码写在了一个文件之中并针对组件的创建进行了详细的注释,未按照工程化的要求进行模块化拆分。但代码配置好模型相关参数后是可以直接运行的,大家可以复制出来自行运行进行测试。
以下代码内容如果一时无法看懂了解也无需纠结,后续我会基于此案例,以组件为标准进行模块的逐一拆分,并提供可供测试运行的单一模块用例代码。
- 首先运行以下代码安装依赖
pip install langchain
pip install duckduckgo-search
pip install chromadb
- 项目需要引入以下包
from langchain.llms import OpenAI
from langchain.agents import Tool,AgentExecutor
from langchain.tools import DuckDuckGoSearchRun
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import LocalAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain import hub
from langchain.memory import ConversationBufferMemory
from langchain.tools.render import render_text_description
from langchain.agents.output_parsers import ReActSingleInputOutputParser
from langchain.agents.format_scratchpad import format_log_to_str
from langchain.callbacks import StdOutCallbackHandler
- 配置使用的模型相关参数并创建模型访问对象
# 大模型定义
# 你的key
api_key = ""
# 你的大模型服务api的url
api_url = ""
# 模型名称
modal= "Qwen"
llm = OpenAI(model_name=modal,openai_api_key=api_key,openai_api_base=api_url)
llm_with_stop = llm.bind(stop=["\nObservation"])
- 使用duckduckgo搜索引擎创建在线搜索工具
# 在线搜索工具
# pip install duckduckgo-search
search = DuckDuckGoSearchRun()
search_tool = Tool(
name = "Web Search",
func=search.run,
description="useful for when you need to answer questions about current events"
)
- 使用文本分词,向量存储,RetrievalQA完成文档智能检索工具创建
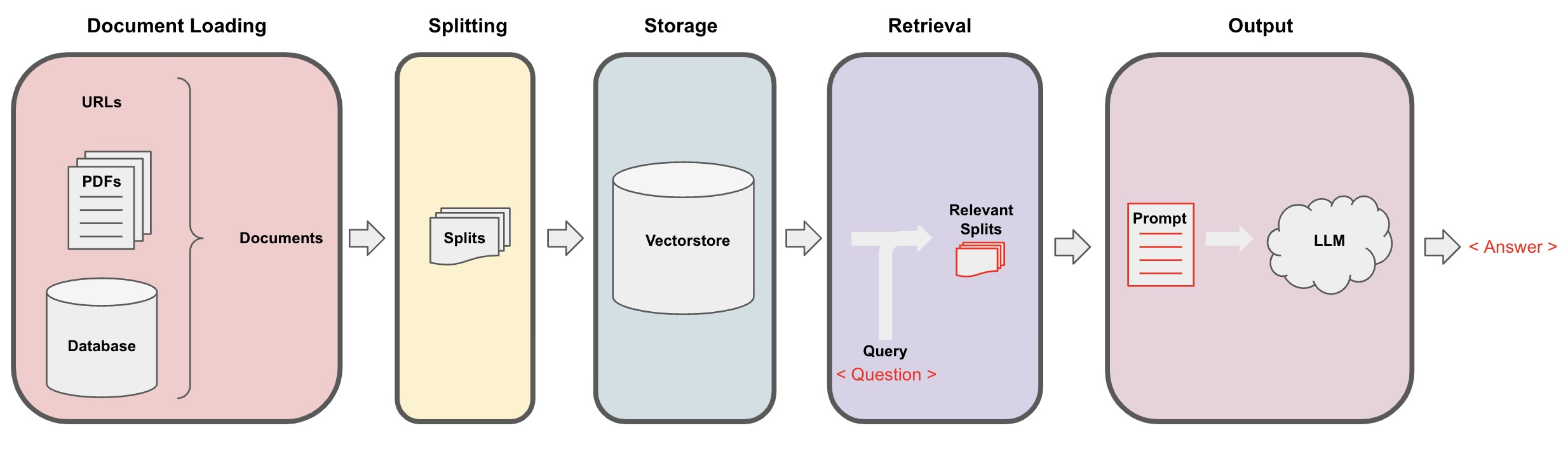

# 文档搜索工具
# create the open-source embedding function
# pip install sentence-transformers
embedding_function = LocalAIEmbeddings(model=modal,openai_api_key=api_key,openai_api_base=api_url)
# 文档Initialize,加载与分词
loader = TextLoader("./doc/wikiofcompanyfxx.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# Vectorstore向量存储
# pip install chromadb
docsearch = Chroma.from_documents(texts ,embedding=embedding_function)
# 文档检索工具创建
docqa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever(search_kwargs={"k": 1}))
# 封装为agents可调用的tool类型
doc_tool = Tool.from_function(
name = "fxx company wiki",
func=docqa.run,
description="useful for when you need to answer any questions about company fxx"
)
tools=[search_tool,doc_tool]
- 从langchain官方仓库加载prompt对话模板

# 定义对话模板
# https://smith.langchain.com/hub/hwchase17/react-chat
prompt = hub.pull("hwchase17/react-chat")
prompt = prompt.partial(
tools=render_text_description(tools),
tool_names=", ".join([t.name for t in tools]),
)
- 定义对话记忆缓存对象及agent输入格式定义
# 定义对话记忆memory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent_input = {
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_log_to_str(x['intermediate_steps']),
"chat_history": lambda x: x["chat_history"]
}
- 将以上内容整合为agent链,配置标准输出回调用于打印日志后封装为可执行Agent
# 定义agent链
agent_chain = agent_input | prompt | llm_with_stop | ReActSingleInputOutputParser()
# 定义标准输出回调用于打印日志
handler = StdOutCallbackHandler()
agent_executor = AgentExecutor(agent=agent_chain, tools=tools, verbose=True, memory=memory,
handle_parsing_errors="Check your output format and make sure it conforms!",callbacks=[handler])
- 执行调用测试
question_0 = agent_executor.invoke( {"input": "What is the main business of company fxx by the wiki?"})
print(question_0['output'])
question_1 = agent_executor.invoke( {"input": "What is Lu Xun's real name?"})
print(question_1['output'])
运行结果如下图所示: 
总结
在这篇文章中,我给您介绍了如何使用 LangChain 的六大核心概念和组件,构建一个基于语言模型的问答系统,它可以根据用户提出的问题从网页及私有文档中检索相关信息,并生成简洁和准确的回答。我还给您展示了相应的代码示例及运行结果截图。我希望您能从中获得一些启发和收获,也欢迎您在评论区留下您的反馈和建议。谢谢您的阅读!😊
下一节课开始我们将基于本节课的QA机器人案例,逐一按组件模块拆解,封装为各自可独立运行的能力模块,对于代码及组件接口的讲解将更加详细,请大家持续关注。