
架构
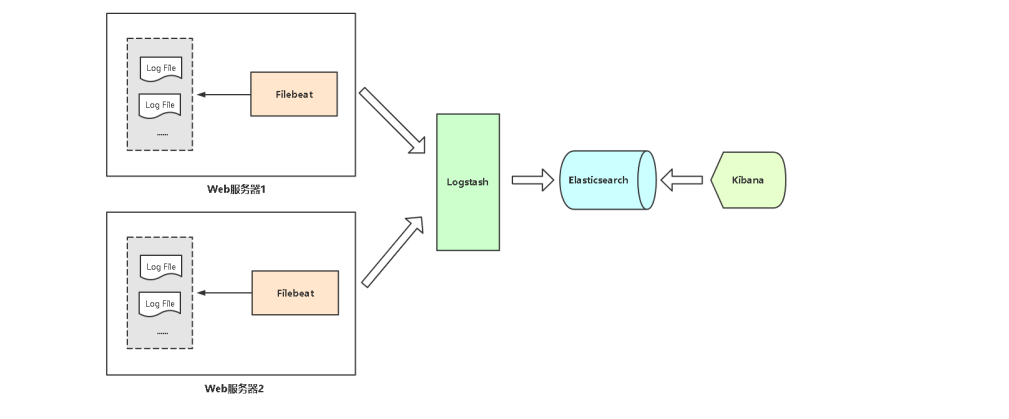
Elasticsearch(简称ES)是java语言开发,是一个分布式、RESTful 风格的搜索和数据分析引擎,用于集中存储日志数据。
图中elasticsearch我是用3台服务器做的集群,logstash也是3台服务
需求背景:
• 业务发展越来越庞大,服务器越来越多
• 各种访问日志、应用日志、错误日志量越来越多
• 开发人员排查问题,需要到服务器上查日志,效率低、权限不好控制
• 运维需实时关注业务访问情况
ELK介绍
ELK 是三个开源软件的缩写,提供一套完整的企业级日志平台解决方案。
分别是:
• Elasticsearch:搜索、分析和存储数据
• Logstash :采集日志、格式化、过滤,最后将数据推送到Elasticsearch存储
• Kibana:Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。
• Beats :集合了多种单一用途数据采集器,用于实现从边缘机器向 Logstash 和Elasticsearch 发送数据。里面应用最多的是Filebeat,是一个轻量级日志采集器。
第一章 elasticsearch部署
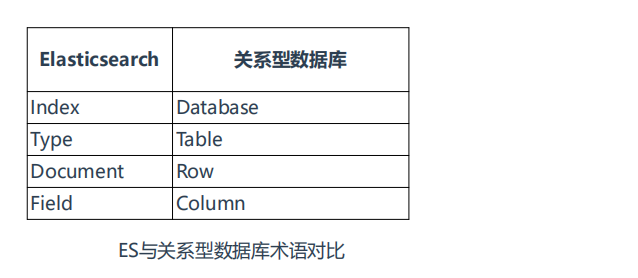
1.1 术语:
• Index:索引是多个文档的集合
• Document:Index里每条记录称为Document,若干文档构建一个Index
• Type:一个Index可以定义一种或多种类型,将Document逻辑分组
• Field:ES存储的最小单元
- 文档,document
一个 对象 是基于特定语言的内存的数据结构。为了通过网络发送或者存储它,我们需要将它表示成某种标准的格式。 JSON 是一种以人可读的文本表示对象的方法。 它已经变成 NoSQL 世界交换数据的事实标准。当一个对象被序列化成为 JSON,它被称为一个 JSON 文档 。
Elastcisearch 是分布式的 文档 存储。它能存储和检索复杂的数据结构—•序列化成为JSON文档—•以 实时 的方式。 换句话说,一旦一个文档被存储在 Elasticsearch 中,它就是可以被集群中的任意节点检索到。
#大多数人把一个文档document比作一行(在kibana看到时候就像是一行数据),我觉得可以叫做个json文件,因为es存在在本地的就是文件数据,这些文件就是一个个json文档。
- 文档元数据
_index 文档在哪存放
_type 文档表示的对象类别
索引中对数据进行逻辑分区。不同 types 的文档可能有不同的字段,但最好能够非常相似,type就像写代码的类,不同类有不同属性。
_id 文档唯一标识,基于 Base64 编码且长度为20个字符的 GUID 字符串
#这3个字段确定一个文档数据,后面介绍api的时候,会根据这个3个字段返回一个文档。
- 索引
命名规范:(2.x版本中,新版本中不知道)这个名字必须小写,不能以下划线开头,不能包含逗号。我们用 website 作为索引名举例。
一个索引仅仅是逻辑上的命名空间, 这个命名空间由一个或者多个分片组合在一起。 然而,这是一个内部细节,我们的应用程序根本不应该关心分片,对于应用程序而言,只需知道文档位于一个 索引 内。
- 分布式理解
主机a有2份数据(主机a是master),主机a把它的数据复制一份放到主机b上,当主机a死机了,他的数据不会丢失;此时,来了另外主机c,主机a会把主机b存的两份数据,分一份给主机c,此时主机a有2份数据,主机b和c分别的各存了其中一份(注意主机b,c不是全部复制主机a的所有数据),这样就成了分布式保存,他和同步复制不一样,效率比同步的高。
副本是只读,不可以删除修改,写入要经过master来操作,操作完成后再分发到各副本。
- 官方推荐文档
这里推荐一个官方的文档,里面主要讲一些术语、原理,以及一些重要的设置,文档虽然是2.x版本,但是术语这些词,以及一些原理永远不变。这个文档是中文的,权威的官方文档,其它的版本没有出中文版。
1.2 集群内部原理
#官方文档: https://www.elastic.co/guide/cn/elasticsearch/guide/current/_add-an-index.html 如果你想搞懂es的集群切换原理,一定要看这个文章,完全的去理解一遍,还是很有用的。
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为 主 节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。
作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知道任意文档(理解为行)所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
- 集群健康
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 集群健康 , 它在 status 字段中展示为 green 、 yellow 或者 red 。
green,表示所有的主分片和副本分片都正常运行。
yellow,表示所有的主分片都正常运行,但副本分片有的不正常运行。这时候可以继续使用不影响,这种情况就类似某个节点断开了,集群会临时变为yellow,但是随着master会把切片重新自动分配,一两分钟后就又变为green了,当集群下架某个节点的时候能看到此现象。
red,表示有一些主分片没能正常运行。
总结:集群的状态是看分片的状态。如果所有分片在一个机器,分片停止了,表示集群就是red(通常es不会把所有主分片放在一个主机器,他们的副本分片也会分开放)。
#这3个状态一定要记住。集群是yellow没事可以继续工作,如果出现red就不能工作了。
Elasticsearch 添加数据时需要用到 索引 —— 保存相关数据的地方。 索引实际上是指向一个或者多个物理 分片 的 逻辑命名空间 。
一个 分片 是一个底层的 工作单元 ,它仅保存了全部数据中的一部分。 在分片内部机制中,我们将详细介绍分片是如何工作的,而现在我们只需知道一个分片是一个 Lucene 的实例,以及它本身就是一个完整的搜索引擎。 我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
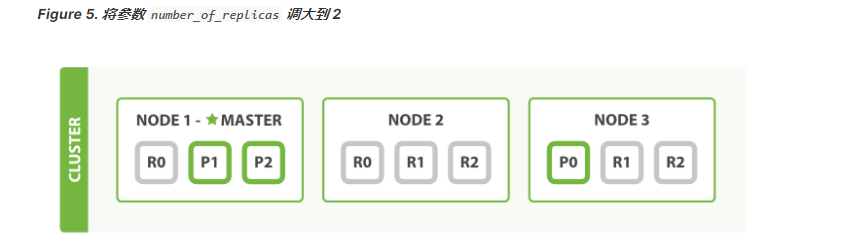
主分片的数目在索引创建时就已经确定了下来,下图所示:
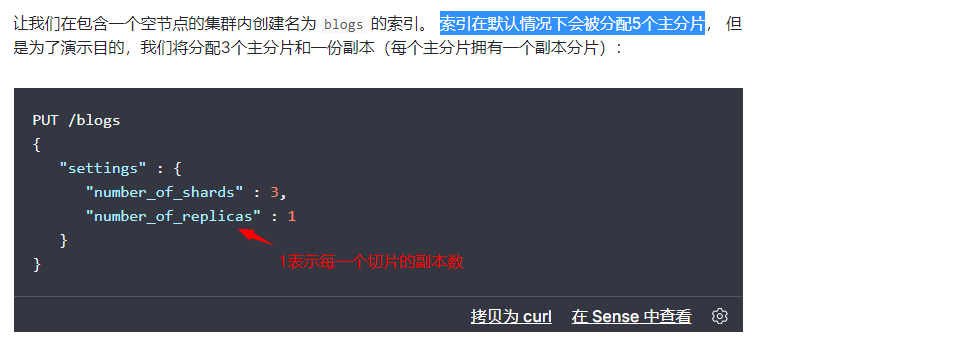
- 集群内部原理图示
注意观察:主切片数,副本数,总切片数。
3个主切片,每个切片1个副本,在2个机器的集群分布上:此时总切片数量=6

3个主切片,每个切片1个副本,在3个机器的集群分布上:总切片数量=6
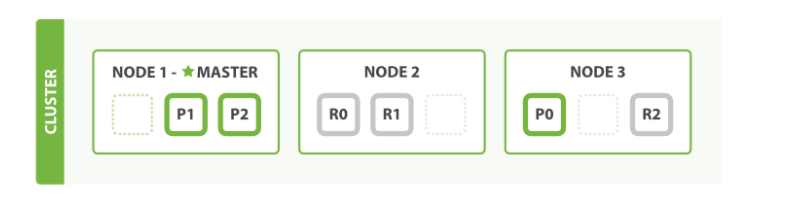
3个主切片,每个切片2个副本,在3个集群机器的分布上:总切片数量=9
1.2 安装方法
安装方式很多,yum,apt安装,二进制包安装,docker安装,这里我们使用二进制安装。
最新版下载地址:https://www.elastic.co/cn/downloads/elasticsearch
其它版本地址点击 View past releases,或地址:https://www.elastic.co/downloads/past-releases#elasticsearch
1.3 安装版本,机器环境
3台centos7服务器,ip地址如下,都是用来安装es
192.168.68.19,
192.168.68.128,
192.168.68.129
安装lrzsz,ntpdate对时自己对好,关闭防火墙,selinux
[root@elk1 config]# cat /etc/ntp/step-tickers
# List of NTP servers used by the ntpdate service.
0.centos.pool.ntp.org
[root@elk1 config]# ntpdate 0.centos.pool.ntp.org #对时
软件版本:
1.4 ES 部署
#3台机器都要操作
cd /opt/elk
tar zxvf elasticsearch-7.9.3-linux-x86_64.tar.gz
mv elasticsearch-7.9.3 elasticsearch
useradd es # 出于安全考虑,默认不能用root账号启动,启动的时候,看日志会报错。es可以不要密码
chown -R es:es elasticsearch
chage -M 99999 es
#调整进程最大打开文件数数量
ulimit -n 65535
vi /etc/security/limits.conf #永久设置
* hard nofile 65535
* soft nofile 65535
#调整进程最大虚拟内存区域数量
sysctl -w vm.max_map_count=262144
echo "vm.max_map_count=262144" >> /etc/sysctl.conf #永久设置
sysctl -p
1.5 ES 集群部署
es集群部署配置在配置文件里面 config/elasticsearch.yml,配置文件官方介绍很详细:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/important-configuration-changes.html
#3台es节点机器按照如下配置,稍微有小的区别:
[root@elk2 elasticsearch]# cat config/elasticsearch.yml
cluster.name: elk-cluster #集群名字,一定修改成自己的,以免别人不小心加入集群,同一个网段具有多个elasticsearch集群时cluster.name就成为同一个集群的标识。
node.name: elk1 #每个节点不一样,其实写一样也是可以的,写一样在查看集群的时候你会自己都搞不清楚。
#path.data: /path/to/data #默认不动就好了,日志会保存在安装目录下的logs目录。数据可以保存到多个不同的目录,如果将每个目录分别挂载不同的硬盘,,这可是一个简单且高效的办法。
#path.logs: /path/to/logs #不动
network.host: 0.0.0.0 #如果你的网卡有多个地址可以这么写,如果只想绑定到某个地址就写具体的,否则写每个节点自己的地址,写具体ip地址吧。
http.port: 9200
#transport.tcp.port: 9300 #默认使用9300,不写也可以。
discovery.seed_hosts: ["elk1", "elk2", "elk3"] #我写的别名,前提我写在/etc/hosts了
cluster.initial_master_nodes: [“node-1”] #首次启动指定的Master节点
注意:在节点2或节点3不启用cluster.initial_master_nodes参数,注释掉。其实配置好节点1之后,
配置系统服务管理:
# cat /usr/lib/systemd/system/elasticsearch.service
[Unit]
Description=elasticsearch
[Service]
User=es #前面我们创建的es用户用到了
LimitNOFILE=65535
ExecStart=/opt/elk/elasticsearch/bin/elasticsearch
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
# systemctl daemon-reload
# systemctl start elasticsearch
# systemctl start elasticsearch #启动elasticsearch
看日志方法:
#用systemd接管的服务,启动后,可以在journalctl看到日志了。
journalctl -u elasticsearch -f
journalctl -xe #也可以看到日志
systemctl status elasticsearch #也可以看到日志
项目文件夹logs目录下也可以看到日志,总共看日志就这么几个地方。
1.6 查看集群节点,状态:
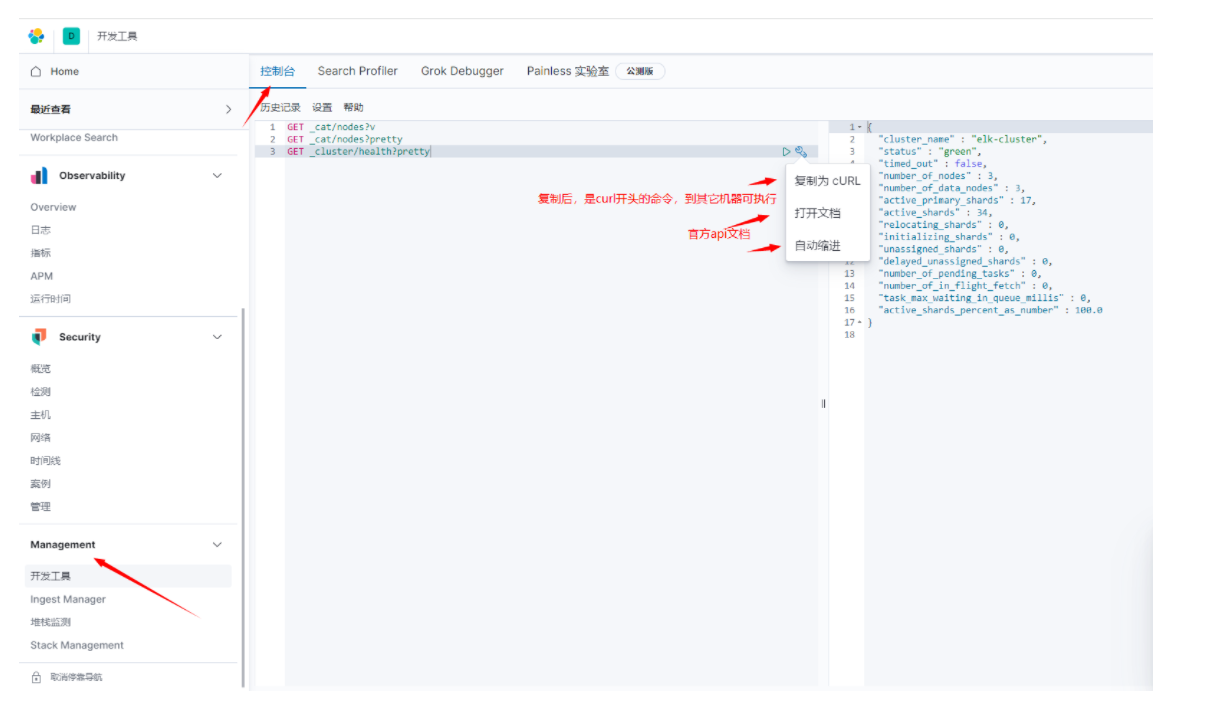
查看集群节点:curl -XGET 'http://127.0.0.1:9200/_cat/nodes?pretty'
查询集群状态: curl -i -XGET http://127.0.0.1:9200/_cluster/health?pretty
查看哪台是主节点:
[root@elk1 ~]# curl -XGET 'http://127.0.0.1:9200/_cat/nodes?v'
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.68.128 41 83 0 0.06 0.05 0.05 dilmrt * elk2
192.168.68.129 39 92 0 0.00 0.02 0.05 dilmrt - elk3
192.168.68.19 14 96 1 0.30 0.14 0.09 dilmrt - elk1
这是通过api的方式查看。
[root@elk1 elasticsearch]# curl -i -XGET http://127.0.0.1:9200/_cluster/health?pretty
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 464
{
"cluster_name" : "elk-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
[root@elk1 elasticsearch]#
[root@elk1 elasticsearch]# curl -XGET 'http://127.0.0.1:9200/_cat/nodes?pretty'
192.168.0.104 15 96 0 0.02 0.03 0.12 dilmrt * elk1 #因为我服务器有多个ip地址,配置文件绑定地址我写的是0.0.0.0,所以这里随机获取了一个ip。
192.168.68.129 40 96 0 0.01 0.04 0.05 dilmrt - elk3
192.168.68.20 8 75 0 0.17 0.11 0.09 dilmrt - elk2
- 在kibana查看如下。
1.7 图形界面管理集群
两种方法,下面我们用elastichd试试
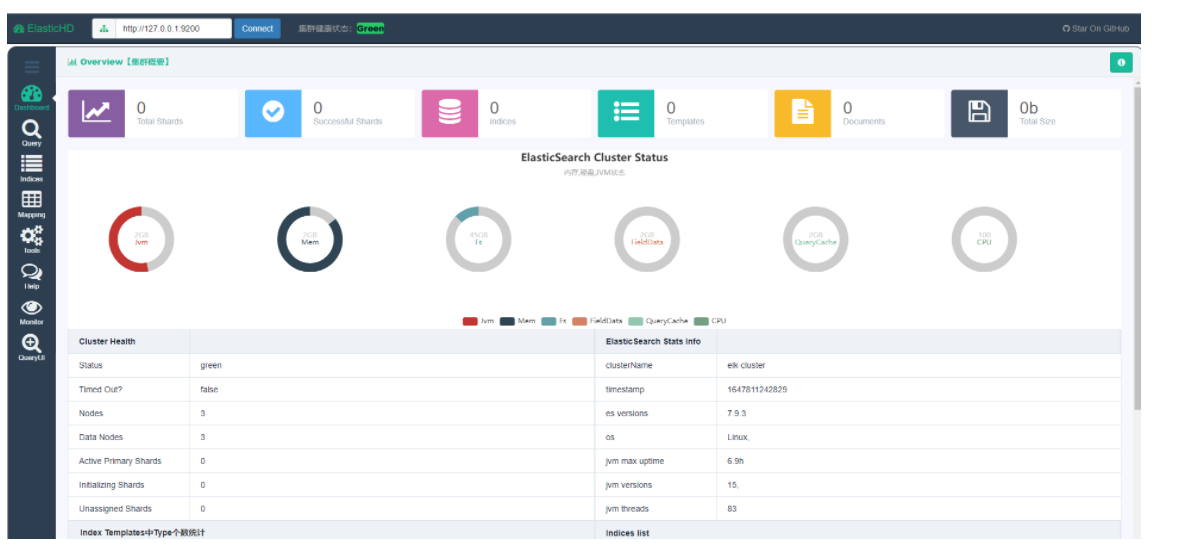
1、ElasticHD
ElasticHD 是一款 ElasticSearch的可视化应用。不依赖ES的插件安装,更便捷;导航栏直接填写对应的ES IP和端口就可以操作Es了。目前支持如下功能:
- ES 实时搜索
- ES DashBoard 数据可视化
- ES Index Template (在线修改、查看、上传)
- SQL Converts to DSL
- ES 基本查询文档
linux and MacOs用法
下载对应的elasticHD版本,unzip xxx_elasticHd_xxx.zip
修改权限 chmod 0777 ElasticHD
可指定ip端口运行elastichd,执行 ./ElasticHD -p 127.0.0.1:9800 默认ip和端口也是这个。放到后台加个nohup &
windows
直接下载对应windows版本,解压,双击运行。当然想指定端口的话同linux
[root@elk1 elk]# unzip elasticHD_linux_amd64.zip
Archive: elasticHD_linux_amd64.zip
inflating: ElasticHD
[root@elk1 elk]#
[root@elk1 elk]# ls
ElasticHD elasticHD_linux_amd64.zip elasticsearch elasticsearch-7.9.3-linux-x86_64.tar.gz
[root@elk1 elk]#
[root@elk1 elk]# ls -l
total 327908
-rwxr-xr-x 1 root root 22871350 Jun 29 2017 ElasticHD
-rw-r--r-- 1 root root 6464861 Nov 4 2020 elasticHD_linux_amd64.zip
drwxr-xr-x 10 es es 167 Mar 20 22:20 elasticsearch
-rw-r--r-- 1 root root 306436527 Oct 22 2020 elasticsearch-7.9.3-linux-x86_64.tar.gz
[root@elk1 elk]#
[root@elk1 elk]# ./ElasticHD
To view elasticHD console open http://0.0.0.0:9800 in browser
exec: "xdg-open": executable file not found in $PATH
也可以到后台启动:
[root@elk1 elk]# nohup ./ElasticHD &
[1] 46517
[root@elk1 elk]# nohup: ignoring input and appending output to ‘nohup.out’
[root@elk1 elk]#
[root@elk1 elk]# tail nohup.out
To view elasticHD console open http://0.0.0.0:9800 in browser
exec: "xdg-open": executable file not found in $PATH
2、cerebro
还有其它工具,自己可以去github上找,上面这两个也可以去github找得到。
1.8 集群的扩容、缩容
官方文档:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html #中文版,集群解释。
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/index.html #配置相关
- 新增一台服务器加入到集群中,
配置同样的集群名字,开启es服务即可。
- 集群缩容一台服务器(多台服务器关闭一台恢复到green后,再关闭下一台)
这里有好几种情况:
1、直接关闭服务器即可,关闭服务器后实时观察集群健康状态,它会变yellow,然后过个1分钟又会变为green。原因是因为关闭节点后,一些副本切片不能访问(此时变为yellow),集群会自动分配切片,分配完成后变为green,分配的时间取决于数据的大小。
2.1 如果你关闭的节点是master节点,并且所有的主切片都在这台服务器,那么它会重新选择master,在选举的时候,集群状态是red的,因为主分片已经失去了。当你选举好master后,又变回gred。
2.2 如果关闭的节点master节点,且只是部分的主切片放在这台服务器,关闭过程中是red-->yellow-->green(原因看下面文档链接),过几分钟后恢复到green(其实默认情况下主切片不会放在同一个服务器,这是es内部机制)。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_coping_with_failure.html
3、如果关闭的旧master重新开机后,还会恢复到master吗?不会了,master被其它机器当了,你只有等下次重新选举才能当上master。
#官方说法:当集群只有一台服务器master,没有副本切片,此时集群状态是一直yellow,不会变为green,因为它的副本分片都访问不到。但是我亲测,只有一台服务器的时候,集群状态显示未连接(图形界面看到的,,用curl命令访问集群状态是卡主的,访问不了),也就说一台服务器不叫集群了;当我把其它机器的es服务开起来后,集群又自动恢复green。
1.9 拓展:
1、es配置文件
Elasticsearch 有三个配置文件:
-
elasticsearch.yml用于配置 Elasticsearch -
jvm.options用于配置 Elasticsearch JVM 设置 -
log4j2.properties用于配置 Elasticsearch 日志记录
一个较常用的配置文件示例:
[root@elk1 ~]# grep -v '#' /opt/elk/elasticsearch/config/elasticsearch.yml
cluster.name: elk-cluster
node.name: elk1
network.host: 0.0.0.0 #绑定本机所有ip地址
http.port: 9200
discovery.seed_hosts: ["elk1", "elk2", "elk3"] #种子提供机器ip
cluster.initial_master_nodes: ["elk1"] #第一次启动集群的时候要加此参数,后面加入的节点都不需要加了。
#discovery.seed_providers: file.txt #从文件读取种子机器
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"] #单播方式
#下面这几个参数,通常默认就可以
node.master: true #默认true,是否可以作为master候选
node.data: true #是否作为数据节点
index.number_of_shards: 5 #索引分片个数,默认是5
index.number_of_replicas: 1 #每个分片的副本个数
path.conf: #配置文件路径
path.data: /data/es/data #数据目录路径
path.work: /data/es/work #工作目录路径
path.logs: #日志文件路径
path.plugins: /data/es/plugins #插件路径
bootstrap.mlockall: true #内存不向swap交换
http.enabled: true #启用http
2、怎么查看一个机器分片数
curl "https://127.0.0.1:9200/_settings"
#每个索引有自己的分片,副本数,如果有很多索引这里会显示很多
curl -XGET "http://192.168.68.128:9200/beat-2022.03.25/_settings" #查询单个索引
#分片所在位置怎么查询 后面再扩展
3、两个master,设置最小master数量。
没有最小同时在线的master,只有下面这个参数,
discovery.zen.minimum_master_nodes: 2
#discovery.zen.minimum_master_nodes的作用是只有足够的master候选节点时,才可以选举出一个master,而不是说平常有两个master存活。用来防止脑裂的。
4、可以设置某台机器不成为主节点,有参数设置。
node.master:这个属性表示节点是否具有成为主节点的资格,false的话就只是data节点一个意思了。默认是true
node.data:这个属性表示节点是否存储数据。默认是true
5、API相关
- 返回一个文档
从接口返回一个文档document数据
#根据_type,_index,_id 3个字段可以返回一个文档。
weizhi-2022是索引名字,
_doc是默认文档类型,在kibana可以看到的;
k9pI438BvSvcH7Q3p7iJ是id
-i 参数可以不加,不加不显示包头200状态码等。
[root@elk1 ~]# curl -i -XGET http://localhost:9200/weizhi-2022/_doc/k9pI438BvSvcH7Q3p7iJ?pretty
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 2071
{
"_index" : "weizhi-2022",
"_type" : "_doc",
"_id" : "k9pI438BvSvcH7Q3p7iJ",
"_version" : 1,
"_seq_no" : 5369,
"_primary_term" : 7,
"found" : true,
"_source" : {
"ziduan1" : "vvv",
"event" : {
"dataset" : "nginx.access",
"timezone" : "+08:00",
"module" : "nginx"
},
"tags" : [
"beats_input_codec_plain_applied"
],
"fileset" : {
"name" : "access"
},
"body_bytes_sent" : "0",
"request_time" : "0.000",
"@timestamp" : "2022-04-01T04:01:03.000Z",
"service" : {
"type" : "nginx"
},
"http_x_forwarded_for" : "-",
"http_referrer" : "-",
"remote_addr" : "192.168.68.1",
"status" : "304",
"host" : {
"name" : "filebeat68.22"
},
"test" : {
"field11" : 11,
"field22" : 22
},
"agent" : {
"hostname" : "filebeat1",
"name" : "filebeat68.22",
"type" : "filebeat",
"id" : "04ed5dc3-8ca5-4882-a0e1-8c348b96feba",
"version" : "7.9.3",
"ephemeral_id" : "ba67af3c-0088-4c6e-9a59-4c420a72949a"
},
"@version" : "1",
"http_user_agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36",
"fingerprint" : "f4c8eaa805275417fa30fac2c1c2053091d421355ea5784a07440fa4974851a5",
"remote_user" : "-",
"message" : "{ \"@timestamp\": \"2022-04-01T12:01:03+08:00\", \"remote_addr\": \"192.168.68.1\", \"remote_user\": \"-\", \"body_bytes_sent\": \"0\", \"request_time\": \"0.000\", \"status\": \"304\", \"request_uri\": \"/\", \"request_method\": \"GET\", \"http_referrer\": \"-\", \"http_x_forwarded_for\": \"-\", \"http_user_agent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36\"}",
"request_uri" : "/",
"request_method" : "GET",
"log" : {
"offset" : 7539,
"file" : {
"path" : "/var/log/nginx/access.log"
}
},
"input" : {
"type" : "log"
},
"ecs" : {
"version" : "1.5.0"
}
}
}
- 返回文档的某个字段,或多个字段
[root@elk1 ~]# curl -XGET http://localhost:9200/weizhi-2022/_doc/k9pI438BvSvcH7Q3p7iJ?_source=ziduan1,agent.name
{"_index":"weizhi2022","_type":"_doc","_id":"k9pI438BvSvcH7Q3p7iJ","_version":1,"_seq_no":5369,"_primary_term":7,"found":true,"_source":{"agent":{"name":"filebeat68.22"},"ziduan1":"vvv"}}
#json解析后
{
"_index":"weizhi-2022",
"_type":"_doc",
"_id":"k9pI438BvSvcH7Q3p7iJ",
"_version":1,
"_seq_no":5369,
"_primary_term":7,
"found":true,
"_source":{
"agent":{
"name":"filebeat68.22"
},
"ziduan1":"vvv"
}
}
- 查文档是否存在
如果只想检查一个文档是否存在--根本不想关心内容—那么用 HEAD 方法来代替 GET 方法。 HEAD 请求没有返回体,只返回一个 HTTP 请求报头:
[root@elk1 ~]# curl -I -XHEAD http://localhost:9200/weizhi-2022/_doc/k9pI438BvSvcH7Q3p7iJ
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 1614
如果文档存在, Elasticsearch 将返回一个 200 ok 的状态码
若文档不存在, Elasticsearch 将返回一个 404 Not Found 的状态码
- 更新,创建,删除文档,这里不说了,自己看官方文档
https://www.elastic.co/guide/cn/elasticsearch/guide/current/delete-doc.html #这是2.x版本的,不一定适用,但只有2.x是中文版
- 配置集群的时候,根据官方文档的重要配置做一些系统参数的设置。
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/setting-system-settings.html

6、不要kibana,es也可以界面展示?
es配置文件有个参数http.enabled=true 的时候,可以界面打开es,自己有时间拓展一下。还要安装个head插件什么的。
1.10 es集群问题记录
1、日志提示:xception: java.lang.RuntimeException: can not run elasticsearch as root
答:不能用root启动,前面我们创建了es,用es启动即可。
2、日志报错:
elasticsearch.service: main process exited, code=exited, status=217/USER
答:没创建es用户
3、日志报错:
elasticsearch.service: main process exited, code=exited, status=1/FAILURE
答:上面elasticsearch的服务文件写的是es用户启动,但是elasticsearch文件夹没有所属用户不是es,执行
chown -R es:es elasticsearch
4、提示main ERROR Unable to create file /path/to/logs/elk-cluster_index_indexing_slowlog.json java.io.IOException: Could not create directory /path/to/logs
答:在elasticsearch.yml配置文件,我添加了参数path.logs: /path/to/logs,但是泥实际这个目录是不存在的,把参数注释掉,日志就会默认保存在安装包的elasticsearch/logs文件夹下了。
5、Failed at step EXEC spawning /opt/elk/elasticsearch/bin/elasticsearch: No such file
答:我是通过 systemctl status elasticsearch.service 看到服务文件elasticsearch.service,执行启动文件的路径和实际的项目路径不对,项目路径写错了,调整一致即可。
curl -i -XGET http://127.0.0.1:9200/_cluster/health?pretty看到,我只有2个节点,实际上我有3个节点机器,答:防火墙没关闭。
HTTP/1.1 200 OK content-type: application/json; charset=UTF-8 content-length: 464
{ "cluster_name" : "elk-cluster", "status" : "green", "timed_out" : false, "number_of_nodes" : 3, "number_of_data_nodes" : 3, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
第二章 logstash
2.1 logstash介绍
Logstash能够将采集日志、格式化、过滤,最后将数据推送到Elasticsearch存储。
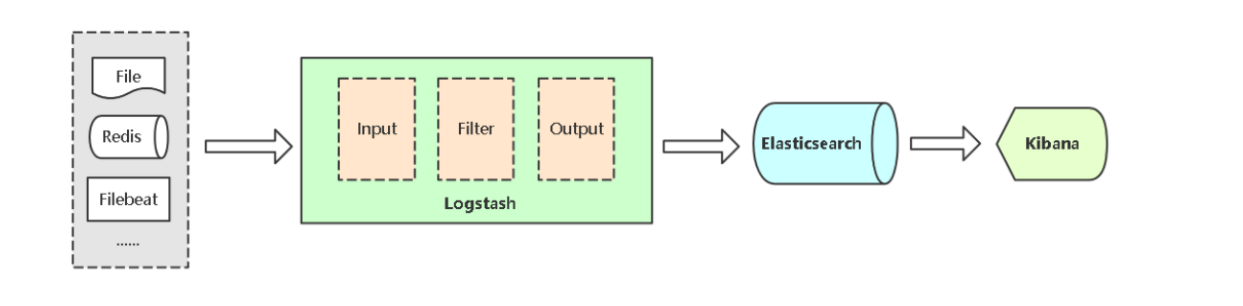
Input:输入,输入数据可以是Stdin、File、TCP、Redis、Syslog等。
Filter:过滤,将日志格式化。有丰富的过滤插件:Grok正则捕获、Date时间处理、Json编解码、Mutate数据修改等。
Output:输出,输出目标可以是Stdout、File、TCP、Redis、ES等
- logstash原理
Logstash 事件处理管道具有三个阶段:输入→过滤器→输出。输入生成事件,过滤器修改它们,输出将它们发送到其他地方。输入和输出支持编解码器,使您能够在数据进入或退出管道时对其进行编码或解码,而无需使用单独的过滤器。
2.2 logstash部署
二进制方式部署:
yum install java-1.8.0-openjdk –y #logstash不像es自带jdk,所以这里我们需要安装jdk
cd /opt/elk
tar zxvf logstash-7.9.3.tar.gz
mv logstash-7.9.3 logstash
#把logstash也做成服务方式。
# vi /usr/lib/systemd/system/logstash.service
[Unit]
Description=logstash
[Service]
ExecStart=/opt/elk/logstash/bin/logstash
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
#修改配置文件。 vim config/logstash.yml
pipeline: # 管道配置
batch:
size: 125
delay: 5
path.config: /opt/elk/logstash/conf.d #conf.d目录自己创建
# 定期检查配置是否修改,并重新加载管道。也可以使用SIGHUP信号手动触发
# config.reload.automatic: false
# config.reload.interval: 3s
# http.enabled: true
http.host: 0.0.0.0
http.port: 9600-9700
log.level: info
path.logs: /opt/elk/logstash/logs
#其它说明
[root@elk1 logstash]# ls /opt/elk/logstash/logs #里面有3个文件,如果报错error会在logstash-plain.log显示
logstash-deprecation.log logstash-plain.log logstash-slowlog-plain.log
#查看日志方式:
1、做成服务了可以用journalctl -u logstash -f看日志。
2、也可以到上面logs里面看报错的信息,因为做成服务了,不报错没显示。
2.3 Logstash 基本使用
示例:从标准输入获取日志并打印到标准输出
# /opt/elk/logstash/bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}' #这里logstash写绝对路径,相对路径感觉有问题。
hello world
{
"@version" => "1",
"message" => "hello world ",
"@timestamp" => 2020-11-05T09:23:44.025Z, "host" => "localhost"
}
命令行参数:
• -e 字符串形式写配置
• -f 指定配置文件
• -t 测试配置文件语法
默认给日志加的三个字段:
• "@timestamp" 标记事件发生的时间点
• "host" 标记事件发生的主机名
• "type" 标记事件的唯一类型
#从命令行形式输入输出实操
[root@elk1 conf.d]# /opt/elk/logstash/bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}' #启动要等会儿,启动时间有点久,等个30s,然后看到Successfully started Logstash API endpoint表示启动成功。
[2022-03-21T10:51:15,447][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
hello python #手动输入字符串
{
"@version" => "1",
"host" => "elk1",
"@timestamp" => 2022-03-21T02:53:16.237Z,
"message" => "hello python"
}
hello elk logstash #手动输入字符串
{
"@version" => "1",
"host" => "elk1",
"@timestamp" => 2022-03-21T02:53:26.207Z,
"message" => "hello elk logstash"
}
#从文件读取
[root@elk1 config]# cat /opt/elk/logstash/conf.d/test.yml
input{
stdin{}
}
output{
stdout{
codec=>rubydebug
}
}
[root@elk1 config]/opt/elk/logstash/bin/logstash -f /opt/elk/logstash/conf.d/test.yml #然后会提示输入字符串。
#检测test配置文件的语法,发现type有多个值的时候,只能写一个type。
[root@elk1 conf.d]# /opt/elk/logstash/bin/logstash -t test.yml
Sending Logstash logs to /opt/elk/logstash/logs which is now configured via log4j2.properties
[2022-03-21T12:28:52,400][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"7.9.3", "jruby.version"=>"jruby 9.2.13.0 (2.5.7) 2020-08-03 9a89c94bcc OpenJDK 64-Bit Server VM 25.322-b06 on 1.8.0_322-b06 +indy +jit [linux-x86_64]"}
[2022-03-21T12:28:53,365][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2022-03-21T12:28:55,897][INFO ][org.reflections.Reflections] Reflections took 60 ms to scan 1 urls, producing 22 keys and 45 values
[2022-03-21T12:28:56,307][ERROR][logstash.inputs.file ] Invalid setting for file input plugin:
input {
file {
# This setting must be a string
# Expected string, got ["access", "error"]
type => ["access", "error"] #这里只可以写一个
...
}
}
2.4 输入插件(Input,file)
1、input输入阶段:从哪里获取日志
常用插件:
• Stdin(一般用于调试)
• File
• Redis
• Beats(例如filebeat)
2、File插件:用于读取指定日志文件
常用字段:
• path 日志文件路径,可以使用通配符
• exclude 排除采集的日志文件
• start_position 指定日志文件什么位置开始读,默认从结尾
开始,指定beginning表示从头开始读
3、输入插件都支持的字段:
• add_field 添加一个字段到一个事件,放到事件顶部,一般用于标记日志来源。例如属于哪个项目,哪个应用
• tags 添加任意数量的标签,用于标记日志的其他属性,例如表明访问日志还是错误日志
• type 为所有输入添加一个字段,例如表明日志类型
#可以直接拿来用的配置文件。
#input,output,filter都是插件名,file也是。
[root@elk1 conf.d]# vi test.yml
input{
file {
path => "/var/log/test/*.log"
exclude => "error.log"
tags => "web"
tags => "nginx"
type => "access"
add_field => {
"app" => "product"
"description" => "test"
}
}
}
filter{}
output{
file{
path => "/temp/test.log"
}
}
2.5 日常使用(重要):
1、修改输入输出配置文件conf.d目录,里的文件后,需重新执行kill -SIGHUP 20396 加载配置(20396是ps aux|grep logstash看到的进程id,是Main PID。systemctl status logstash也可以看到进程id;或者用 systemctl reload elasticsearch 重新加载,为什么这句可以重新加载,因为服务的文件里面定义了,看服务文件就知道,这种方法不要进程id。)。
如果加载后没生效就看日志journalctl -u logstash -f,有时候配置conf.d目录下文件格式写错,不会生效的,需先修改配置文件,再重新加载。
2、修改logstash.yml配置文件需要重启服务才生效,不是kill -SIGHUP 进程id。亲测看了日志的。
3、修改conf.d目录文件让其自动加载,有个参数写在logstash.yml文件的,不需手动去加载。
config.reload.automatic: true #默认是false
config.reload.interval: 3s
4、type字段的值只可以有一个;tags可以有多个。
#常用语句
vi conf.d/test.yml
kill -SIGHUP 20396 #也有人写成kill -HUP 20396
echo "666">> /var/log/test/access.log
tail -f /temp/test.log
journalctl -u logstash -f
#从一个文件读取,输出到另外一个文件示例如下:
[root@elk1 logstash]# grep -v '^#' config/logstash.yml
pipeline.ordered: auto
pipeline: # 管道配置
batch:
size: 125
delay: 5
path.config: /opt/elk/logstash/conf.d # conf.d目录自己创建,用的绝对路径。
http.host: 0.0.0.0
http.port: 9600-9700
log.level: info
path.logs: /opt/elk/logstash/logs
[root@elk1 logstash]# cat conf.d/test.yml #查看输入文件,里面用到file插件
input{
file {
path => "/var/log/test/*.log" #读取/var/log/test/*.log的文件,*表示通配符,排除error.log;
exclude => "error.log"
}
}
filter{}
output{
file{
path => "/temp/test.log" #路径不存在会自动创建,看日志发现的
}
}
[root@elk1 conf.d]# echo "333">> /var/log/test/access.log #往里面写数据可以看到test.log几乎是1秒刷一次
[root@elk1 conf.d]# echo "333">> /var/log/test/access.log
[root@elk1 test]# tail /temp/test.log -f #下面的文件是json格式,可以用json在线解析器解析,格式就好看点。
{"message":"222","host":"elk1","@version":"1","@timestamp":"2022-03-21T04:02:59.661Z","path":"/var/log/test/access.log"}
{"message":"333","host":"elk1","@version":"1","@timestamp":"2022-03-21T04:03:18.724Z","path":"/var/log/test/access.log"}
json解析器截图:
2.6 加载conf.d的配置文件方法
#方法1:自动加载
平常我们修改conf.d里的文件,都会手动加载,logstash.yml有个参数会自动加载如下。
config.reload.automatic: true #默认是false
config.reload.interval: 3s
#方法2。常用这个方法
systemctl status logstash 查看进程id
ps aux|grep logstash 查看进程id
kill -HUP 进程id
kill -SIGHUP 进程id
#方法3。
#和方法2一样的原理,只不过是方法2把命令单独执行。
#因为在logstash的服务文件定义了ExecReload=/bin/kill -HUP $MAINPID参数,所以可以用。如果没定义这个参数就用不了。
systemctl reload logstash
[root@elk1 conf.d]# cat /usr/lib/systemd/system/logstash.service
[Unit]
Description=logstash
[Service]
ExecStart=/opt/elk/logstash/bin/logstash
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
2.7 beat插件
Beats插件:接收来自Beats数据采集器发来的数据,例如Filebeat
常用字段:
• host 监听地址
• port 监听端口
这里还没有讲到到filebeat,后面讲到了再说。

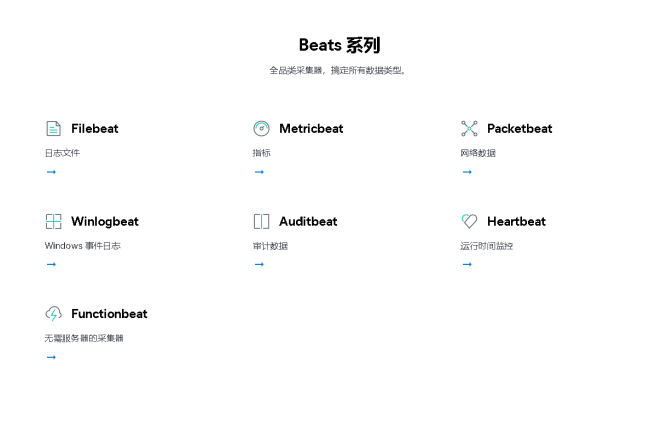
目前Beats包含六种工具:
- Packetbeat:网络数据(收集网络流量数据)
- Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
- Filebeat:日志文件(收集文件数据)
- Winlogbeat:Windows事件日志(收集Windows事件日志数据)
- Auditbeat:审计数据(收集审计日志)
- Heartbeat:运行时间监控(收集系统运行时的数据)这个也会用到,
2.8 扩展
- 常用config/logstash.yml 示例
定期检查配置是否修改,并重新加载管道。也可以使用SIGHUP信号手动触发试试
图中配置的就一个logstash,可否配置多个,或者主备模式。
- 输出 /var/log/messages文件
#官方文档
https://www.elastic.co/guide/en/logstash/7.9/config-examples.html
#我做的实验,输出到本地显示。
[root@elk1 ~]# cat logstash-syslog.conf #配置文件
input {
file {
path => "/var/log/messages"
type => syslog
}
}
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
[root@elk1 bin]# ./logstash -f /root/logstash-syslog.conf #启动。如果messages有程序在生成日志就会一直跑。这里不要断开,等会儿会从这里输出日志。
[root@elk1 ~]# yum install tcpdump #因为我本地没生成日志,这里我安装一个包试试
[root@elk1 bin]# ./logstash -f /root/logstash-syslog.conf #输出日志如下
{
"received_from" => "elk1",
"syslog_timestamp" => "Apr 6 17:24:03",
"message" => "Apr 6 17:24:03 elk1 yum[15338]: Installed: 14:libpcap-1.5.3-12.el7.x86_64",
"type" => "syslog",
"syslog_message" => "Installed: 14:libpcap-1.5.3-12.el7.x86_64",
"host" => "elk1",
"received_at" => "2022-04-06T09:24:04.109Z",
"syslog_hostname" => "elk1",
"syslog_program" => "yum",
"syslog_pid" => "15338",
"path" => "/var/log/messages",
"@timestamp" => 2022-04-06T09:24:03.000Z,
"@version" => "1"
}
{
"received_from" => "elk1",
"syslog_timestamp" => "Apr 6 17:24:03",
"message" => "Apr 6 17:24:03 elk1 yum[15338]: Installed: 14:tcpdump-4.9.2-4.el7_7.1.x86_64",
"type" => "syslog",
"syslog_message" => "Installed: 14:tcpdump-4.9.2-4.el7_7.1.x86_64",
"host" => "elk1",
"received_at" => "2022-04-06T09:24:04.123Z",
"syslog_hostname" => "elk1",
"syslog_program" => "yum",
"syslog_pid" => "15338",
"path" => "/var/log/messages",
"@timestamp" => 2022-04-06T09:24:03.000Z,
"@version" => "1"
}
- 输入插件文档列表清单:
https://www.elastic.co/guide/en/logstash/7.9/input-plugins.html
输入插件,有空研究一下,我们重点是学习过滤插件:
exec,http,java_stdin,stdin,rabbitmq,syslog,kafka
#exec定时任务插件,类似crond,文档:https://www.elastic.co/guide/en/logstash/7.9/plugins-inputs-exec.html
[root@elk1 ~]# cat logstash-syslog.conf
input {
exec {
command => "ls"
type => syslog
interval => 30 #30s执行一次ls
}
}
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
[root@elk1 bin]# ./logstash -f /root/logstash-syslog.conf
第三章 logstash强大的过滤系统
logstash强大的过滤系统,其实是有很多插件,每个插件支持不同格式的数据,配置文件支持条件判断,环境变量,对每个事件添加删除字段等等。
3.1 过滤插件
过滤阶段:用来将日志格式化处理
常用插件: • json #处理json格式的文件 • kv #key,value存储的数据 • grok #通过正则匹配日志 • geoip #解析ip所属地址 • date #将指定的日期替换成为一定的格式
3.2 过滤插件都支持的字段:
• add_field 如果过滤成功,添加一个字段到这个事件
• add_tags 如果过滤成功,添加任意数量的标签到这个事件
• remove_field 如果过滤成功,从这个事件移除任意字段
• remove_tag 如果过滤成功,从这个事件移除任意标签
3.3 过滤插件:json
JSON插件:接收一个json数据,将其展开为Logstash事件中的数据结构,放到事件顶层。
常用字段:
• source 指定要解析的字段,一般是原始消息message字段
• target 将解析的结果放到指定字段,如果不指定,默认在事件的顶层
json插件的作用:
- 可以读取一个json格式的文件,然后把里面的json字段一 一解析出来。这样在kibana的时候展示,可以根据解析出的字段来查找了,这个插件是特别针对json格式的文件。
- 如果不是json格式也能读取到,只是json解析失败而已。
模拟数据:
{"remote_addr": "192.168.1.10","url":"/index","status":"200"}
示例:解析HTTP请求
input {
file {
path => "/var/log/test/*.log"
}
}
filter {
json {
source => "message"
}
}
output {
file {
path => "/tmp/test.log"
}
}
#输入输出文件
[root@elk1 conf.d]# vi test.yml
input{
file {
path => "/var/log/test/*.log"
exclude => "error.log"
tags => "web"
tags => "nginx"
type => "access6"
add_field => {
"app" => "product"
"description" => "test"
}
}
}
filter{
json{
source => "message"
}
}
output{
file {
path => "/temp/test.log"
}
}
#往文件写一行json格式数据
echo {\"remote_addr\": \"192.168.1.100\",\"url\":\"/index.html\",\"status\":\"400\"} >> /var/log/test/access.log
#输出后效果如下,把message字段的信息一一解读出来,放到下面对应的层级。
{
"@timestamp":"2022-03-23T11:53:21.735Z",
"description":"test",
"message":"{\"remote_addr\": \"192.168.1.10\",\"url\":\"/index\",\"status\":\"200\"}",
"path":"/var/log/test/access.log",
"url":"/index", #解析出来了
"status":"200", #解析出来了
"@version":"1",
"remote_addr":"192.168.1.10", #解析出来了
"tags":[
"web",
"nginx"
],
"host":"elk1",
"app":"product",
"type":"access6"
}
指定target参数
#指定target参数
[root@elk1 conf.d]# vi test.yml
input{
file {
path => "/var/log/test/*.log"
exclude => "error.log"
tags => "web"
tags => "nginx"
type => "access6"
add_field => {
"app" => "product"
"description" => "test"
}
}
}
filter{
json{
source => "message"
target => "app"
}
}
output{
file {
path => "/temp/test.log"
}
}
#输出后效果
{
"@timestamp":"2022-03-23T12:04:53.444Z",
"description":"test",
"@version":"1",
"message":"{\"remote_addr\": \"192.168.1.100\",\"url\":\"/index.html\",\"status\":\"400\"}",
"tags":[
"web",
"nginx"
],
"path":"/var/log/test/access.log",
"host":"elk1",
"app":{
"status":"400", #它门放在app标签下了。
"remote_addr":"192.168.1.100",
"url":"/index.html"
},
"type":"access6"
}
3.4 过滤插件:kv
kv插件:接收一个键值数据,按照指定分隔符解析为Logstash事件中的数据结构,放到事件顶层。
使用场景是打开网页的时候,网页地址。
常用字段:
• field_split 指定键值分隔符,默认空
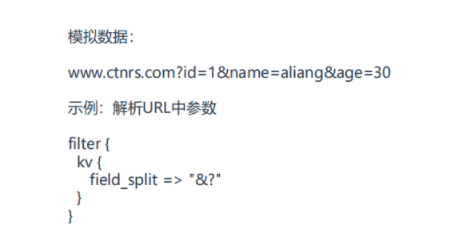
#执行:echo "https://edu.51cto.com/center/course/lesson/index?id=270587&name=51cto&passwd=pwd" >> /var/log/test/access.log
#配置文件
[root@elk1 conf.d]# cat test.yml
input{
file {
path => ["/var/log/test/access.log","/var/log/test/key.log"]
exclude => "error.log"
tags => "web"
tags => "nginx"
type => "access6"
add_field => {
"app" => "product"
"description" => "test"
"author" => "shiliang"
}
}
}
filter{
json{
source => "message"
}
kv{
field_split => "&?" #分隔符是&,或者?
}
}
output{
elasticsearch{
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
#输出效果
{
"@timestamp": "2022-03-23T15:45:55.343Z",
"description": "test",
"name": "51cto", #解析到了
"message": "https://edu.51cto.com/center/course/lesson/index?id=270587&name=51cto&passwd=pwd",
"path": "/var/log/test/access.log",
"passwd": "pwd",#解析到了
"author": "shiliang",
"id": "270587", #解析到了
"@version": "1",
"tags": [
"web",
"nginx",
"_jsonparsefailure"
],
"host": "elk1",
"app": "product",
"type": "access6"
}
3.5 过滤插件:grok
- 如果采集的日志格式是非结构化的,可以写正则表达式提取,grok是正则表达式支持的实现。
- Logstash里面系统自带了一些正则表达式,如果不满足也可以自己写正则。
常用字段:
• match 正则匹配模式
• patterns_dir 自定义正则模式文件
#Logstash内置的正则匹配,在安装目录下可以看到,路径:
/opt/elk/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns
#查看上面的文档发现有时间类的年月日,syslog,主机名,ipv4,ipv6,电话号码,uuid,mac地址,路径类url等等。
#正则匹配模式语法格式:%{SYNTAX:SEMANTIC}
• SYNTAX 模式名称,上面系统带的模式文件中的第一列(或者你自定义的文件,写路径)
• SEMANTIC 匹配文件的字段名(匹配上之后在kibana显示的字段名,其实就是保存在es 的字段名)
例如: %{IP:client}
模拟数据:
192.168.1.10 GET /index.html 15824 0.043
示例:正则匹配HTTP请求日志。IP,WORD等都是logstash内置的正则
filter {
grok {
match => {
"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"
}
}
}
正则表达式很重要,很多时候都会用到,抽个2天时间多写写:比如年月日,ip地址,电话号码,主机名等等。
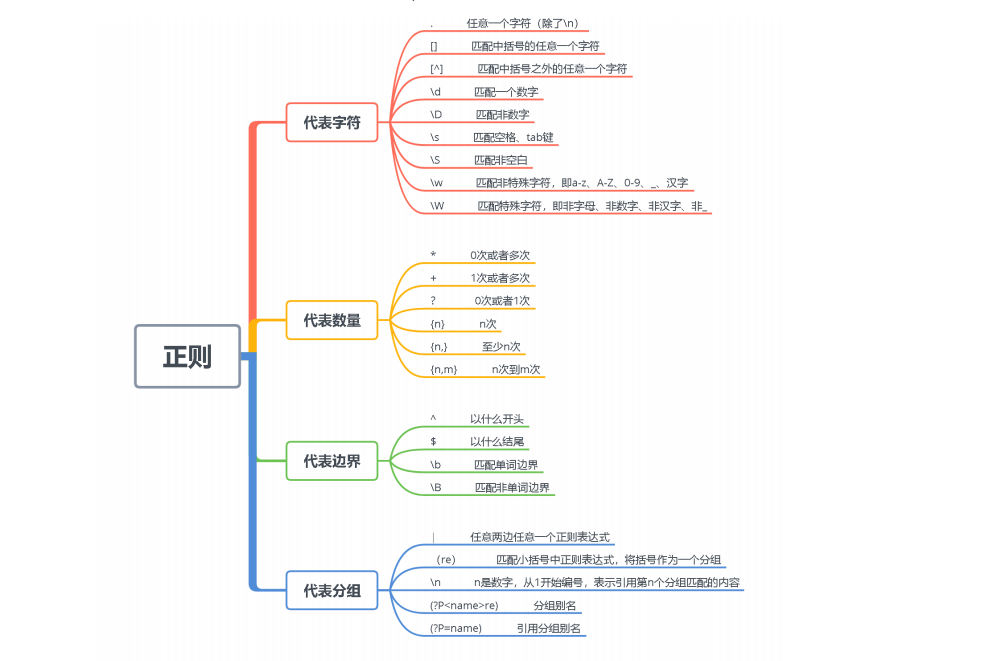
自定义正则
如果内置匹配模式中没有你想要的,可以自定义正则模式。
例如:
#模拟数据:
192.168.1.10 GET /index.html 15824 0.043 123456
# cat /opt/patterns
CID [0-9]{5,6}
#配置文件
filter {
grok {
patterns_dir =>"/opt/patterns"
match => {
"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{CID:cid}"
}
#写法2
#match => [
#"message","%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{CID:cid}"
#]
}
}
自定义正则写多个
如果一个日志文件下有多个日志格式怎么办?例如项目新版本添加一个日志字段,需要兼容旧日志匹配,使用多模式匹配,写多个正则表达式,只要满足其中一条就能匹配成功。
#配置文件
[root@elk1 conf.d]# cat zhengze.yml
input{
file {
path => "/var/log/test/reg.log"
tags => "nginx"
add_field => {
"app" => "product"
"description" => "test"
"author" => "shiliang"
}
}
}
filter{
grok{
patterns_dir => "/opt/patterns"
match => [ #这里是[]了,只写一个参数是大括号{}
"message","%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{CIDEND:cid}",
"message","%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{CID:cid} %{EID:eid}"
]
}
}
output{
elasticsearch{
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
#自定义的正则文件
[root@elk1 conf.d]# cat /opt/patterns
CID [0-9]+
CIDEND [0-9]+$
EID \w+
#模拟数据
[root@elk1 conf.d]# echo "192.168.1.10 GET /index.html 15824 0.043 123456 aaa" >> /var/log/test/reg.log
[root@elk1 conf.d]# echo "192.168.1.10 GET /index.html 15824 0.043 123456" >> /var/log/test/reg.log
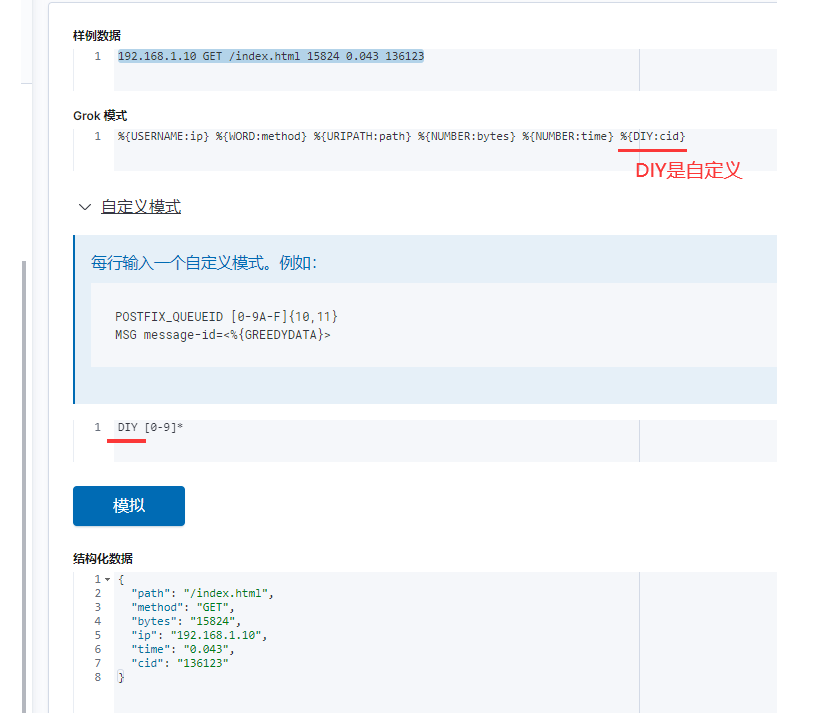
grok模式写法1
在kibana上验证正则,如下图所示(多用这种方式):
grok模式写法2
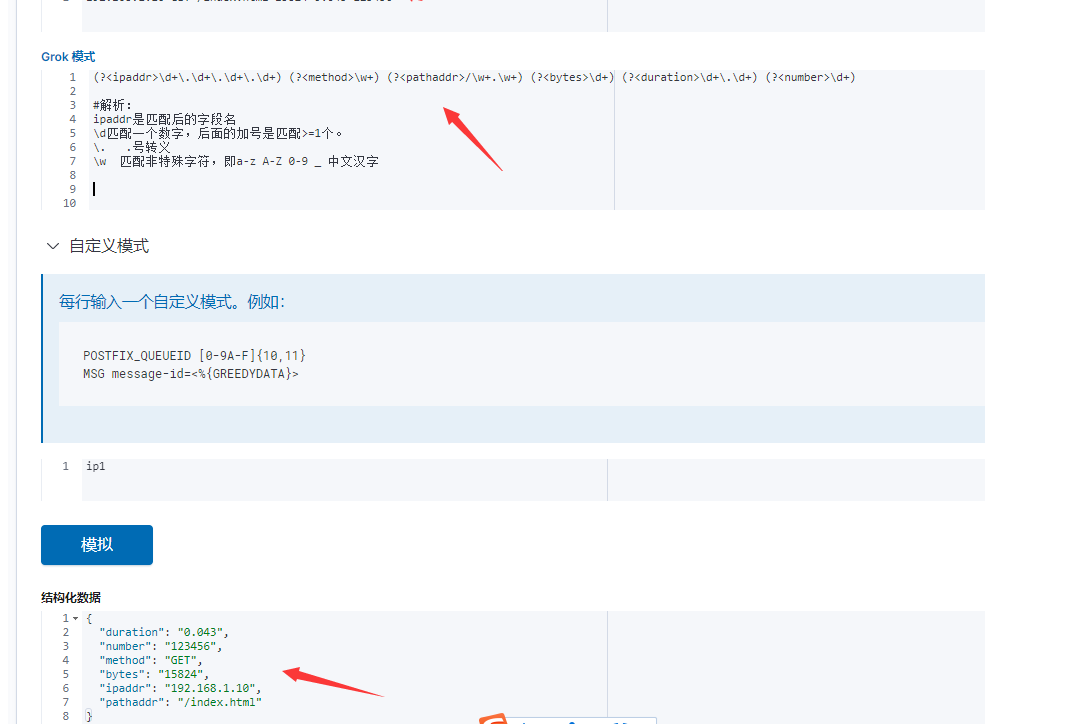
在kibana的grok调试工具,grok模式还有一种写法2,就是用正则分组别名的方式(用小括号括起来)如下所示:
3.6 过滤插件:geoip
GeoIP插件:根据Maxmind GeoLite2数据库中的数据添加有关IP地址位置信息。使用多模式匹配,写多个正则表达式,只要满足其中一条就能匹配成功。
Maxmind 公司发布了两个,一个是收费版本,一个是免费版,可以自己去官网下载,免费版本只可以找到国家,时区,经纬度,没有显示是哪个城市。。
常用字段:
• source 指定要解析的IP字段,结果保存到geoip字段
• database GeoLite2数据库文件的路径
• fields 保留解析的指定字段
下载地址: https://www.maxmind.com/en/accounts/436070/geoip/downloads(需要登录)
#示例1:默认保留geoip的所有字段

[root@elk1 conf.d]# cat zhengze.yml
input{
file {
path => "/var/log/test/reg.log"
tags => "nginx"
add_field => {
"app" => "product"
"description" => "test"
"author" => "shiliang"
}
}
}
filter{
grok{
patterns_dir => "/opt/patterns"
match => {
"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{CID:cid}"
}
}
geoip{
source => "client"
database => "/opt/elk/GeoLite2-City.mmdb"
}
}
output{
elasticsearch{
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "test-%{+YYYY.MM.dd}"
}
# file {
# path => "/temp/test.log"
#}
}
[root@elk1 conf.d]# cat /opt/patterns
CID [0-9]+
CIDEND [0-9]+$
EID \w+
#输出效果
{
"@timestamp": "2022-03-24T04:47:36.471Z",
"description": "test",
"client": "183.232.231.172",
"message": "183.232.231.172 GET /index.html 15824 0.043 868686",
"path": "/var/log/test/reg.log",
"cid": "868686",
"author": "shiliang",
"bytes": "15824",
"duration": "0.043",
"geoip": {
"location": {
"lat": 34.7725,
"lon": 113.7266
},
"ip": "183.232.231.172",
"country_name": "China",
"country_code2": "CN",
"continent_code": "AS",
"country_code3": "CN",
"latitude": 34.7725,
"longitude": 113.7266,
"timezone": "Asia/Shanghai"
}
示例2:保留解析的指定字段
#配置文件
[root@elk1 conf.d]# cat zhengze.yml
input{
file {
path => "/var/log/test/reg.log"
tags => "nginx"
add_field => {
"app" => "product"
"description" => "test"
"author" => "shiliang"
}
}
}
filter{
grok{
patterns_dir => "/opt/patterns"
match => {
"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{CID:cid}"
}
}
geoip{
source => "client"
database => "/opt/elk/GeoLite2-City.mmdb"
target => "geoip"
fields => ["country_name","ip","CITY_NAME"] #保留2个字段,其它不保留
}
}
output{
elasticsearch{
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
#自己写的正则
[root@elk1 conf.d]# cat /opt/patterns
CID [0-9]+
CIDEND [0-9]+$
EID \w+
#输出效果
{
"cid": "868686",
"tags": [
"nginx",
"_jsonparsefailure"
],
"method": "GET",
"description": "test",
"author": "shiliang",
"geoip": { #下面就保留了2个值
"ip": "112.48.132.101",
"country_name": "China"
},
"app": "product",
"host": "elk1",
"path": "/var/log/test/reg.log",
"@version": "1",
"duration": "0.043",
"bytes": "15824",
"request": "/index.html",
"message": "112.48.132.101 GET /index.html 15824 0.043 868686",
"@timestamp": "2022-03-24T04:56:50.255Z",
"client": "112.48.132.101"
},
3.7 问题累积
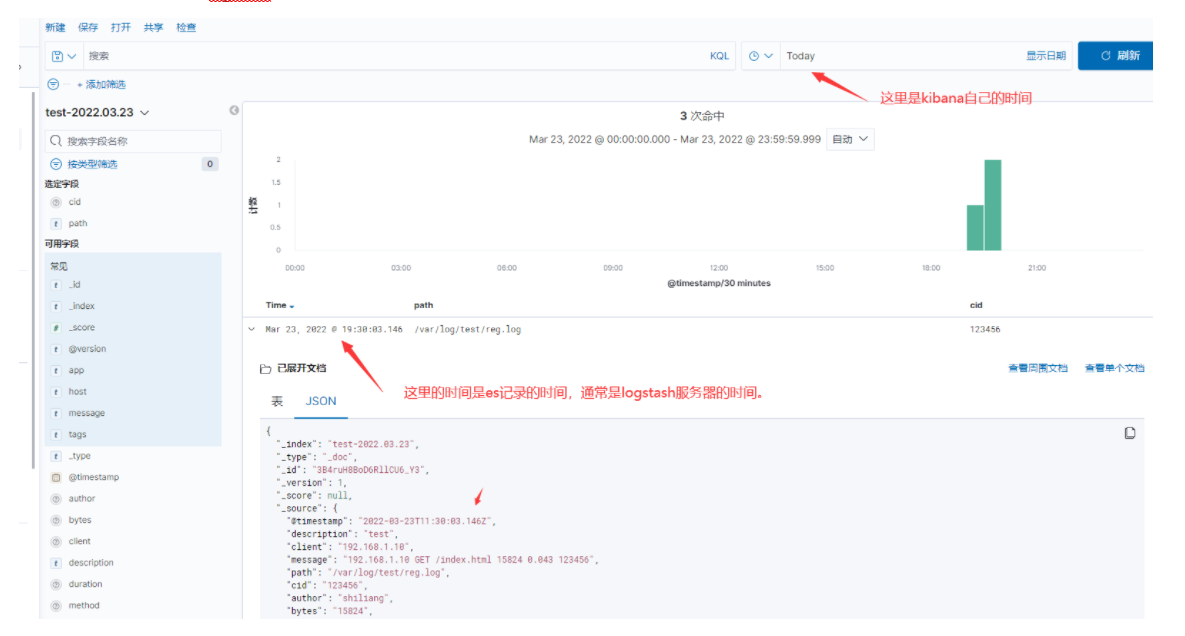
1、logstash和kibana时间不一致。超级容易碰到这个情况。
logstash读取时间是timedatectl显示的Local time( Local time: Thu 2022-03-24 02:57:50 CST)
kibana显示时间是他自己程序有个自己的时间(个人发现),
(如果是filebeat,也是以客户端服务器的时间为准,kibana界面time字段显示的时间就是客户端服务器的时间。)
当两个时间不一致的时候(通常Local time比普通时间快8个小时),这时候就会出现kibana搜索框选择当天日期,刷新页面显示不出上传的日志,你以为是没传上来,而实际是es已经有数据,只是时间不对而已(kibana展示搜索框时间和es数据记录的时间不一致),当你把kibana的显示时间选择本周后,就可以看到了,或者选择下一天时间。或者你根据服务器时间来找记录。
答:解决此问题最好方法是logstash服务器时间显示是对的,这样就不会错。
2、练习geoip的时候,日志一直报如下错误,检查了配置文件,没有配置错误。
答:后面发现模拟数据用的是私有ip地址192.168.1.10,要用公网地址,私有地址在geoip库是查不到的。
echo "8.8.8.8 GET /index.html 15824 0.043 868686" >> /var/log/test/reg.log
Mar 24 12:38:43 elk1 logstash[7589]: [2022-03-24T12:38:43,461][WARN ][logstash.filters.json ][main][52637a3b7f41aee764ac7312e433d91844f6f0618275cd215585f49d0171ac29] Error parsing json {:source=>"message", :raw=>"192.168.1.10 GET /index.html 15824 0.043 868686", :exception=>#<LogStash::Json::ParserError: Unexpected character ('.' (code 46)): Expected space separating root-level values
3.8 扩展
- 过滤配置文件示例
https://www.elastic.co/guide/en/logstash/7.9/event-dependent-configuration.html
https://www.elastic.co/guide/en/logstash/7.9/config-examples.html
#官方配置文件示例,里面有if判断,嵌套字段引用,sprintf格式,插件引用,单位填写,等
filter {
if [foo] in [foobar] {
mutate { add_tag => "field in field" }
}
if [foo] in "foo" {
mutate { add_tag => "field in string" }
}
if "hello" in [greeting] {
mutate { add_tag => "string in field" }
}
if [foo] in ["hello", "world", "foo"] {
mutate { add_tag => "field in list" }
}
if [missing] in [alsomissing] {
mutate { add_tag => "shouldnotexist" }
}
if !("foo" in ["hello", "world"]) {
mutate { add_tag => "shouldexist" }
}
}
#filter扩展,里面可以写if条件判断,看下能否写for等其它的。
答:没看到官方文档说可以写for循环的。
my_bytes => "1113" # 1113 bytes,默认字节
my_bytes => "10MiB" # 10485760 bytes
my_bytes => "100kib" # 102400 bytes
my_bytes => "180 mb" # 180000000 bytes
请注意,字符串值用双引号或单引号括起来。
默认情况下,转义序列未启用。如果您希望在带引号的字符串中使用转义序列,则需要 config.support_escapes: true在logstash.yml时true,带引号的字符串(双引号和单引号)将具有以下转换。
@metadata当您需要临时字段但不希望它出现在最终输出中时,请随时使用该字段。
#注释与 perl、ruby 和 python 中的相同。注释以#字符开头,并且不需要位于行首。
- 在配置文件中使用环境变量
https://www.elastic.co/guide/en/logstash/7.9/environment-variables.html
#里面有说怎么用环境变量,变量设置缺省默认值。
- logstash被处理数据过程中,数据保存在内存中,此时机器若异常中断,如果保持数据不丢失
官方文档:https://www.elastic.co/guide/en/logstash/7.9/persistent-queues.html
默认情况下,Logstash 在管道阶段(输入→过滤器和过滤器→输出)之间使用内存中的有界队列来缓冲事件。如果 Logstash 不安全地终止,则存储在内存中的任何事件都将丢失。为了帮助防止数据丢失,您可以启用 Logstash 以将正在进行的事件持久保存到磁盘。
#在logstash的配置文件设置:
queue.type:指定persisted启用持久队列。默认情况下,持久队列被禁用(默认值:queue.type: memory)。
path.queue:将存储数据文件的目录路径。默认情况下,文件存储在path.data/queue.
queue.page_capacity:队列页面的最大大小(以字节为单位)。队列数据由称为“页面”的仅附加文件组成。默认大小为 64mb。更改此值不太可能带来性能优势。
queue.drain:指定true是否希望 Logstash 等到持久队列耗尽后再关闭。排空队列所需的时间取决于队列中累积的事件数。因此,您应该避免使用此设置,除非队列(即使已满)相对较小并且可以快速耗尽。
queue.max_events:队列中允许的最大事件数。默认值为 0(无限制)。
queue.max_bytes:队列的总容量,以字节数表示。默认值为 1024mb (1gb)。确保磁盘驱动器的容量大于您在此处指定的值。
如果同时指定queue.max_events和 queue.max_bytes,Logstash 将使用首先达到的条件。有关达到这些队列限制时的行为,请参阅处理背压。
#当队列已满时,Logstash 会对输入施加压力以停止流入 Logstash 的数据。这种机制有助于 Logstash 在输入阶段控制数据流的速率,而不会像 Elasticsearch 这样压倒输出。
#指定这些设置后,Logstash 将在磁盘上缓冲事件,直到队列大小达到 8gb。当队列充满未确认的事件,并且达到大小限制时,Logstash 将不再接受新事件。
#每个输入独立处理背压。例如,当 beats输入遇到背压时,它不再接受新的连接并等待直到持久队列有空间接受更多事件。在过滤器和输出阶段完成对队列中现有事件的处理并确认它们之后,Logstash 会自动开始接受新事件。
#这里有原理解释,以及一些可能遇到的情况,影响性能的情况,具体请查看下方官方文档说明:
https://www.elastic.co/guide/en/logstash/7.9/persistent-queues.html
- 如何保证处理事件的排序
当维护事件顺序很重要时,使用单个工作人员并设置 pipeline.ordered ⇒ true
- logstash事件默认保留的字段
@metadata
@timestamp
@version
tags
#filebeat也有保留的字段,区分这里是否一样
- 过滤插件扩展
下面是一些常用的,有空再研究一下:
clone ,http,kv,xml,alter(和mutate功能相似)
- mutate插件
#mutate 过滤插件:允许在事件中,对字段修改,删除,替换,重命名,大小写转换等操作。
文档:https://www.elastic.co/guide/en/logstash/7.9/plugins-filters-mutate.html#plugins-filters-mutate-remove_field
capitalize #把字段替换为首字母大写
#示例
[root@elk1 ~]# cat logstash-syslog.conf
input {
tcp {
port => 5000 #会生成5000端口
type => syslog
id => "myid888"
add_field => { "foo" => "foo_value" "foo2" => "foo_value2" "foo3" => "foo_value3" }
}
}
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
mutate {
rename => { "foo" => "foo_rename" }
uppercase => [ "host","foo_rename" ]
replace => { "foo_rename" => "My new message" } #replate和update有点区别,但是replace支持%{foo}
update => { "foo2" => "My new message2" }
capitalize => [ "foo3" ]
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
[root@elk1 bin]# ./logstash -f /root/logstash-syslog.conf #启动
[root@elk1 ~]# telnet localhost 5000 #telnet端口
Trying ::1...
Connected to localhost.
Escape character is '^]'.
Apr 6 21:01:01 elk2 systemd: Started Session 13 of user root #粘贴值
[root@elk1 bin]# ./logstash -f /root/logstash-syslog.conf #显示如下
{
"received_from" => "localhost",
"syslog_hostname" => "elk2",
"@version" => "1",
"received_at" => "2022-04-06T14:22:01.480Z",
"port" => 43194,
"syslog_message" => "Started Session 13 of user root\r",
"foo3" => "Foo_value3",
"type" => "syslog",
"syslog_timestamp" => "Apr 6 21:01:01",
"syslog_program" => "systemd",
"foo_rename" => "MY NEW MESSAGE",
"message" => "Apr 6 21:01:01 elk2 systemd: Started Session 13 of user root\r",
"@timestamp" => 2022-04-06T13:01:01.000Z,
"foo2" => "My new message2",
"host" => "LOCALHOST"
}
[20220406-21:49:48]{
[20220406-21:49:48] "host" => "LOCALHOST",
[20220406-21:49:48] "@version" => "1",
[20220406-21:49:48] "message" => "syslog_hostname\r",
[20220406-21:49:48] "type" => "syslog",
[20220406-21:49:48] "tags" => [
[20220406-21:49:48] [0] "_grokparsefailure" #注意一下,这个是grok插件解析失败的时候,打的标签。如果是date插件,默认值为["_dateparsefailure"]
[20220406-21:49:48] ],
[20220406-21:49:48] "@timestamp" => 2022-04-06T13:48:59.984Z,
[20220406-21:49:48] "port" => 40674
[20220406-21:49:48]}
- date插件
日期过滤器用于从字段中解析日期,然后使用该日期或时间戳作为事件的logstash 时间戳。
#https://www.elastic.co/guide/en/logstash/7.9/plugins-filters-date.html 里面介绍了其它一些特殊的情况,
#它拥有字段列表
locale #此设置没有默认值。
match
tag_on_failure #tags没有成功匹配时将值附加到字段。默认值为["_dateparsefailure"]
target #将匹配的时间戳存储到给定的目标字段中。如果未提供,则默认更新@timestamp的字段,其实可以理解date插件默认是更新@timestamp字段时间。
timezone #指定用于日期解析的时区规范 ID。有效 ID 列在Joda.org 可用时区页面上。
#如果您的时间字段有多种可能的格式,您可以这样做:
date {
match => [ "logdate", "MMM dd yyyy HH:mm:ss","MMM d yyyy HH:mm:ss","MMMM dd yy HH:mm:ss","ISO8601" ]
}
对于非格式化语法,您需要在值周围加上单引号字符。例如,如果您正在解析 ISO8601 时间,“2015-01-01T01:12:23”那个小“T”不是有效的时间格式,而您想说“字面意思是 T”,您的格式将是这个:“yyyy-MM-dd'T'HH:mm:ss” ,也可以看上面的文档。
#字段里的日期识别,以及时区转换,生成date
date {
match => [ "mydate", "MM/dd/yyyy HH:mm:ss" ]
target => "date"
locale => "en"
timezone => "+00:00"
}
#查看时区地址
http://joda-time.sourceforge.net/timezones.html
#示例。
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss","EEE MMM d HH:mm:ss 'CST' yyyy" ]
#date插件没写target字段,如果syslog_timestamp和后面的格式匹配,就会把@timestamp字段(它的时区是UTC)替换为syslog_timestamp字段的时间。
}
}
mutate {
rename => { "foo" => "foo_rename" }
uppercase => [ "host","foo_rename" ]
replace => { "foo_rename" => "My new message" }
update => { "foo2" => "My new message2" }
capitalize => [ "foo3" ]
}
}
#匹配后的效果
{
"foo_rename" => "MY NEW MESSAGE",
"host" => "LOCALHOST",
"port" => 52092,
"foo3" => "Foo_value3",
"received_at" => "2022-04-07T01:59:07.758Z",
"message" => "Apr 7 12:55:01 elk2 systemd: Started Session 17 of user admin\r",
"type" => "syslog",
"syslog_message" => "Started Session 17 of user admin\r",
"@timestamp" => 2022-04-07T04:55:01.000Z, #它的时间不是采集的时间了,而是日志内容里面截取到的时间替换过去的,是syslog_timestamp减去8小时(因为时区的问题)。
"foo2" => "My new message2",
"syslog_timestamp" => "Apr 7 12:55:01",
"syslog_program" => "systemd",
"received_from" => "LOCALHOST",
"syslog_hostname" => "elk2",
"@version" => "1"
}
根据上面的例子,解决timestamp时区问题:让syslog_timestamp字段和@timestamp显示的时间一致。
方法1:date插件时间当做utc时间,这样和timestamp就一致了。
建议也是用此方法,而不修改timestamp内部的时区,因为内部时区引用不仅仅在这个地方,比如Elasticsearch 内部,对时间类型字段,是统一采用 UTC 时间,存成 long 长整形数据的!对日志统一采用 UTC 时间存储,内部的东西最好不要去修改它,它在最准确,而你本地的时间还经常会出现时间误差。
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss","EEE MMM d HH:mm:ss 'CST' yyyy" ]
timezone => "UTC" #它默认是CST
locale => "en"
}
#修改后示例
{
"@timestamp" => 2022-04-07T12:55:01.000Z,
"type" => "syslog",
"@version" => "1",
"message" => "Apr 7 12:55:01 elk2 systemd: Started Session 17 of user admin\r",
"syslog_timestamp" => "Apr 7 12:55:01",
"foo3" => "Foo_value3",
"foo2" => "My new message2",
"port" => 53876,
"received_at" => "2022-04-07T02:22:00.815Z",
"syslog_program" => "systemd",
"received_from" => "localhost",
"syslog_hostname" => "elk2",
"foo_rename" => "MY NEW MESSAGE",
"host" => "LOCALHOST",
"syslog_message" => "Started Session 17 of user admin\r"
}
第四章 logstash输出插件
4.1 输出插件
输出阶段:将处理完成的日志推送到远程数据库存储
常用插件:
• file #file插件可以输出到另外一个文件
• Elasticsearch 将数据推送到ES存储。
Elasticsearch常用字段:
hosts 指定ES主机地址
index 指定写入的ES索引名称,一般按日期ec 划分
示例:
output{
elasticsearch{
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "test-%{+YYYY.MM.dd}"
}
filter下可以写操作符,再结合output插件根据日志来源写入不同索引名称:
比较操作符:==,!= , < , > , <= ,>=
正则匹配操作符:=~(匹配正则) ,!~(不匹配正则)
成员操作符:in(包含) , not in(不包含)
逻辑操作符:and(与),or(或), nand(非与) , xor(非或)
一元运算符:!(取反) ,()(复合表达式) ,!()(对复合表达式结果取反)
语法结构:
if [log_type] in ["test","dev"]{
代码块
} else if [log_type] == "prod" {
代码块
} else {
代码块
}
典型的应用场景:
#根据日志来源(例如项目名称,应用名)字段写入不同索引名称
#根据日志来源(例如测试环境,生产环境)字段写入不同索引名称(其实这种方式,也可以写多个yml文件,一个yml对应一个log文件)
[root@elk1 conf.d]# cat out.yml
input{
file{
path => "/var/log/test/test.log" #文件1
add_field => {
"log_type" => "test"
}
}
file{
path => "/var/log/test/prod.log" #文件2
add_field => {
"log_type" => "prod"
}
}
}
filter{
if [log_type] in ["test","dev"]{ #条件判断
mutate{
add_field => {
"[@metadata][target_index]" => "test-%{+YYYY.MM.dd}" #test开头
}
}
} else if [log_type] == "prod" {
mutate {
add_field => {
"[@metadata][target_index]" => "prod-%{+YYYY.MM.dd}" #prod开头
}
}
} else {
mutate{
add_field => {
"[@metadata][target_index]" => "unknown-%{+YYYY.MM.dd}"
}
}
}
}
output{
elasticsearch {
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"] #这里随机写入一个es库。
index => "%{[@metadata][target_index]}" #输出上面定义的字段名
}
}
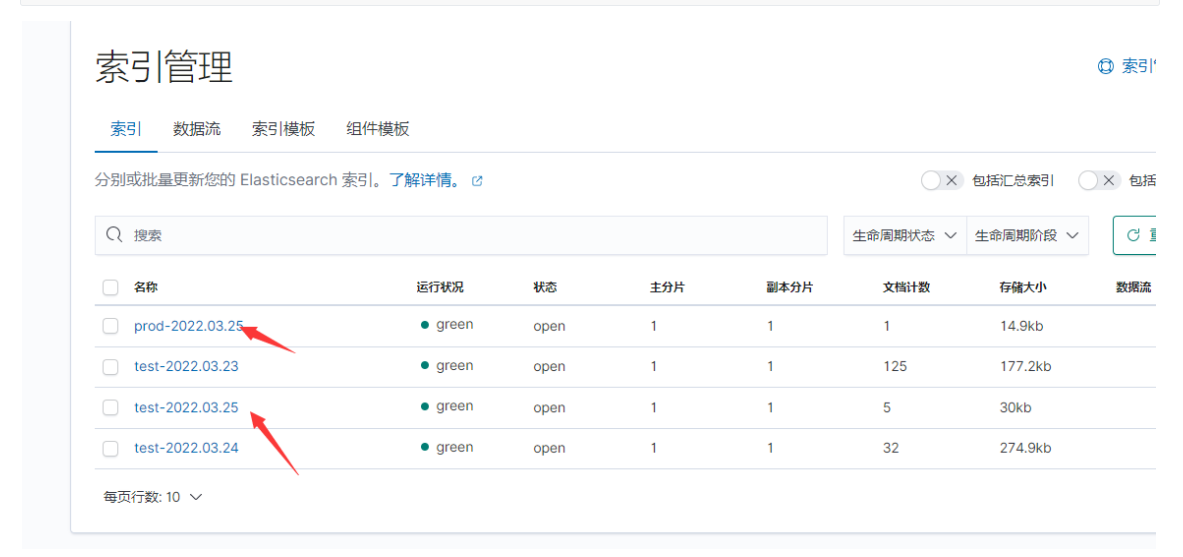
[root@elk1 conf.d]# kill -HUP 7780 #重载配置
[root@elk1 conf.d]# echo "testtest" >> /var/log/test/prod.log
[root@elk1 conf.d]# echo "testtest" >> /var/log/test/test.log
#看到下面kibana截图索引
4.2 扩展:
4.2.1常用插件扩展
有空再拓展:编码解码插件codec
- file插件
此输出将事件写入磁盘上的文件。默认情况下,此输出以json格式每行写入一个事件,你也可以修改格式。
https://www.elastic.co/guide/en/logstash/7.9/plugins-outputs-file.html#plugins-outputs-file-path
output {
file {
path => ...
codec => line { format => "custom format: %{message}"}
id => "my_plugin_id"
}
}
- Stdout输出插件
打印到运行 Logstash 的 shell 的 STDOUT 的简单输出,在调试插件配置时,此输出非常方便,允许在事件数据通过输入和过滤器后立即访问它。这个调试的时候经常用到,非常合适调试。
output {
stdout {
codec => rubydebug #这句话可省略,编码解码器默认就是rubydebug
}
}
output {
stdout { }
}
- statsd 插件
对于默认没有的插件,运行bin/logstash-plugin install logstash-output-statsd进行安装。
[root@elk1 bin]# ./logstash-plugin install logstash-output-statsd
Validating logstash-output-statsd
Installing logstash-output-statsd
Installation successful
官方文档:https://www.elastic.co/guide/en/logstash/7.9/plugins-outputs-statsd.html#plugins-outputs-statsd-count
#描述
statsd 是一个网络守护进程(不是简单的一个插件,从文档有链接到github,他是一个程序,后面空了研究),用于聚合统计信息,例如计数器和计时器,并通过 UDP 传送到后端服务,例如 Graphite 或 Datadog。一般的想法是,您将指标发送到 statsd,每隔几秒钟它就会将聚合值发送到后端。示例聚合是总和、平均值和最大值、它们的标准偏差等。这个插件可以很容易地根据 Logstash 事件中的数据发送这些指标。
#场景:计算什么命中数之类
如何将其与 Logstash 一起使用的典型示例包括通过响应代码计算 HTTP 命中、汇总所服务流量的总字节数以及跟踪请求处理时间的第 50 个和第 95 个百分位数。
过渡章节 ES,Logstash,Kibana汇总
重启汇总
systemctl start elasticsearch
systemctl start logstash
systemctl start kibana
配置文件路径,端口
#es
config/elasticsearch.yml
端口:["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
http.port: 9200
#transport.tcp.port: 9300 #集群之间
#logstash
conf.d/test.yml #输入输出定义的文件目录
config/logstash.yml #全局配置文件
端口: 9600-9700
#kibana
[root@elk2 kibana]# cat config/kibana.yml
server.port: 5601
客户端访问http://192.168.68.128:5601/app/home#/
查看日志汇总
journalctl -u logstash -f #做成了服务才可以这个方法
journalctl -u elasticsearch -f
journalctl -u kibana -f
journalctl -xe #查看系统日志,如果没定义服务
systemctl status logstash #可以看到部分日志
systemctl status elasticsearch
systemctl status kibana
到项目文件夹下/logs文件看logstash-plain.log日志,前提是你配置文件输出日志参数默认是这个,如果修改了,那么会在其他地方。
重载配置文件汇总
#方法1,不重启服务的情况下。
kill -HUP $MAINPID
#方法2:
以logstash为例,在logstash的服务文件定义了ExecReload=/bin/kill -HUP $MAINPID参数,所以可以用这个,前提是定义了这个参数。
[root@elk1 conf.d]# cat /usr/lib/systemd/system/logstash.service
[Unit]
Description=logstash
[Service]
ExecStart=/opt/elk/logstash/bin/logstash
ExecReload=/bin/kill -HUP $MAINPID #参数
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
#汇总语句
systemctl reload elasticsearch
systemctl reload logstash
systemctl reload kibana
注意:后面学到的filebeat不支持reload,他的服务文件没有写相关参数,知道一下就行了,可能是他本身不支持。
配置文件示例汇总
1,elasticsearch
[root@elk1 conf.d]# cat /opt/elk/elasticsearch/config/elasticsearch.yml | grep -v "^#"
cluster.name: elk-cluster
node.name: elk1
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["elk1", "elk2", "elk3"]
cluster.initial_master_nodes: ["elk1"] #master要写,其他节点不写
#服务文件
[root@elk1 conf.d]# cat /usr/lib/systemd/system/elasticsearch.service
[Unit]
Description=elasticsearch
[Service]
User=es
LimitNOFILE=65535
ExecStart=/opt/elk/elasticsearch/bin/elasticsearch
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
2,logstash
#配置文件
[root@elk1 conf.d]# cat ../config/logstash.yml |grep -v '^#'
pipeline.ordered: auto
pipeline: # 管道配置
batch:
size: 125
delay: 5
path.config: /opt/elk/logstash/conf.d
http.host: 0.0.0.0
http.port: 9600-9700
log.level: info
path.logs: /opt/elk/logstash/logs
#服务文件
[root@elk1 conf.d]# cat /usr/lib/systemd/system/logstash.service
[Unit]
Description=logstash
[Service]
ExecStart=/opt/elk/logstash/bin/logstash
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
3,kibana
[root@elk2 kibana]# cat config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.68.128:9200"]
i18n.locale: "zh-CN"
#服务文件
[root@elk2 kibana]# cat /usr/lib/systemd/system/kibana.service
[Unit]
Description=kibana
[Service]
ExecStart=/opt/elk/kibana/bin/kibana --allow-root
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
第五章 Kibana
Kibana 是一个图形页面系统,用于对 Elasticsearch 数据可视化。他的配置文件设置直接连接es地址。
5.1 部署
#二进制方式部署:
cd /opt/elk
tar zxvf kibana-7.9.3-linux-x86_64.tar.gz
mv kibana-7.9.3-linux-x86_64 kibana
# vi config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.31.61:9200"]
i18n.locale: "zh-CN" #使用的语言
#配置系统服务管理:
# vi /usr/lib/systemd/system/kibana.service
[Unit]
Description=kibana
[Service]
ExecStart=/opt/elk/kibana/bin/kibana --allow-root
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
5.2 数据搜索
索引模式:将ES索引关联到Kibana,然后就可以再Discover菜单查看
kibana有两种查询语法:Lucene和KQL,默认KQL是打开的,在查询栏,点击KQL可以关闭。Lucene是一种老方式查询,两种语法要小区别,用到的时候再说,建议用KQL。
Kibana 搜索语法:两种方式都是以Key:Value的形式构建查询条件
1、KQL方式(多用这种方式)
KQL官方文档:https://www.elastic.co/guide/en/kibana/7.9/kuery-query.html
#KQL,用大于小于的时候,不要冒号,也支持时间范围。
message:"quick brown fox" #精确查找
message:quick #精确查找
#支持逻辑符and ,or,not(没有&& ||)
response:200 or extension:php
response:(200 or 404)
response:200 and extension:php
response:200 and (extension:php or extension:css)
not response:200 #取反
response:200 and not (extension:php or extension:css)
tags:(nginx and _jsonparsefailure)
account_number >= 100 and items_sold <= 200
@timestamp < "2021-01-02T21:55:59"
@timestamp < "2021-01"
@timestamp < "2021"
#通配符*
machine.os:win* #win开头
machine.os*:windows 10 #*号也可以写在前面字段名
#结果取反查询:
• 匹配状态码不是200:
not response: 200
not geoip.ip: (8.8.8.8 or 112.48.132.101) #取反
#复合查询:我个人理解就是用小括号,括起来里面写表达式。
• 查询状态码200并且URL是/index.html或者/login.html
response:200 and (request: "/index.html" or request: "/login.html")
• 查询状态码200或者301
response:(200 or 301)
geoip.ip: (8.8.8.8 or 112.48.132.101)等价于geoip.ip: 8.8.8.8 or geoip.ip: 112.48.132.101
#还有一种嵌套式,这里不写了,自己看官方文档。
2、Lucene方式。是一种老方式查询
#范围
status:[400 TO 499] #查找所有介于 400-499 之间的状态代码
status:[400 TO 499] AND extension:PHP #查找状态代码 400-499 以及扩展名 php
#查找状态代码 400-499 以及扩展名 php 或 html
status:[400 TO 499] AND (extension:php OR extension:html)
•判断大于小于的时候
duration:<=1 #Lucene可以加冒号,可以不加
bytes>=158
#其它我不写了,和KQL大同小异
5.3 kibana可视化和仪表盘
这一节应该在日志案例章节的,因为目前还没有数据可以显示。
比较常用的图表:指标、折线图、饼图、数据表
操作:
- 添加指标类型
Visualize-->创建可视化-->选择折线图,选择索引模式-->创建,可以定制标签,然后更新,保存。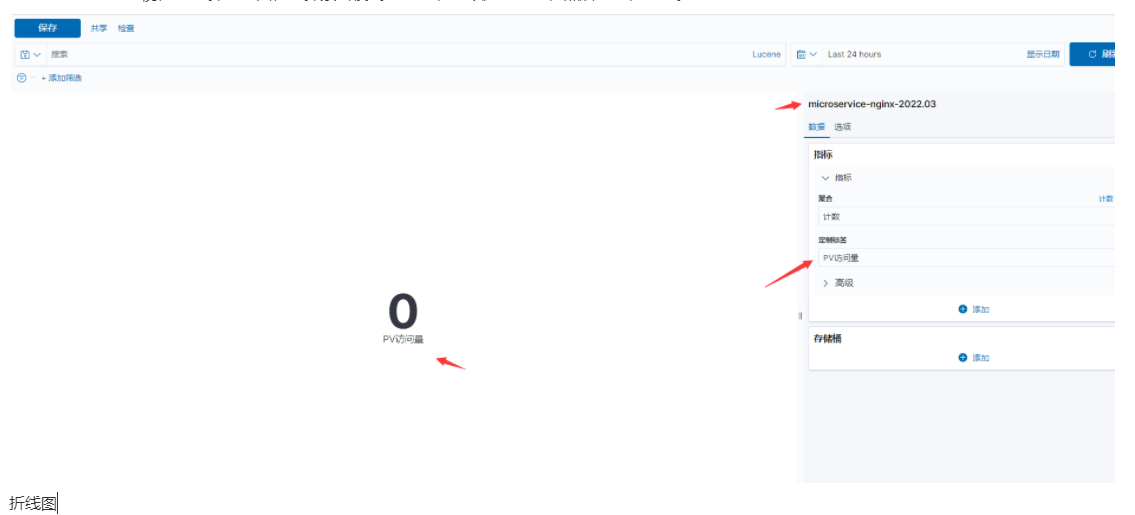
- 折线图
Visualize-->创建可视化-->选择折线图,选择索引模式-->创建,添加存储桶,选择x轴,选择聚合,选择时间@timestamp做为x轴。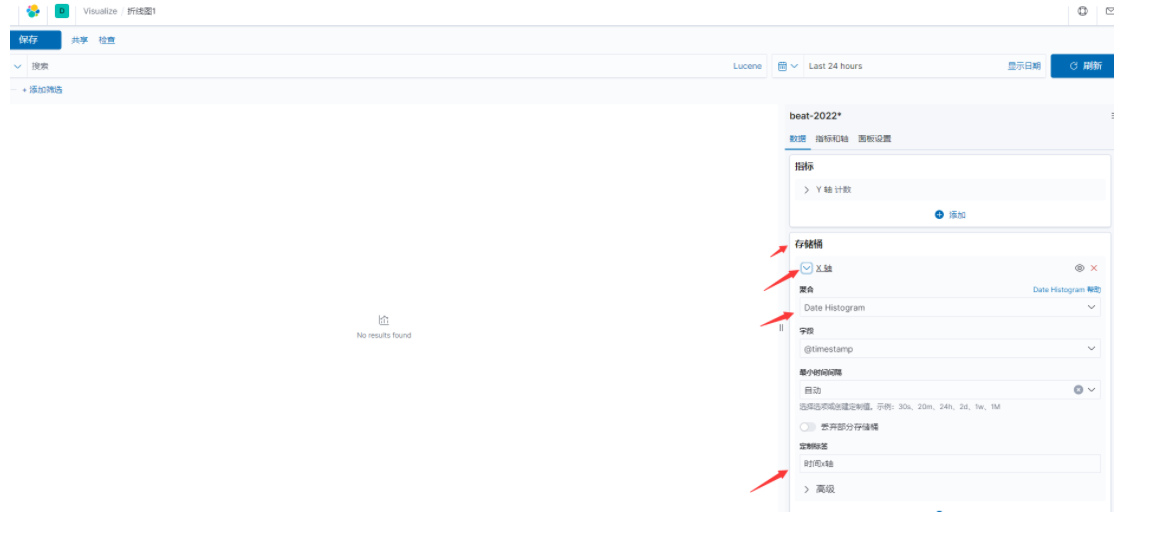


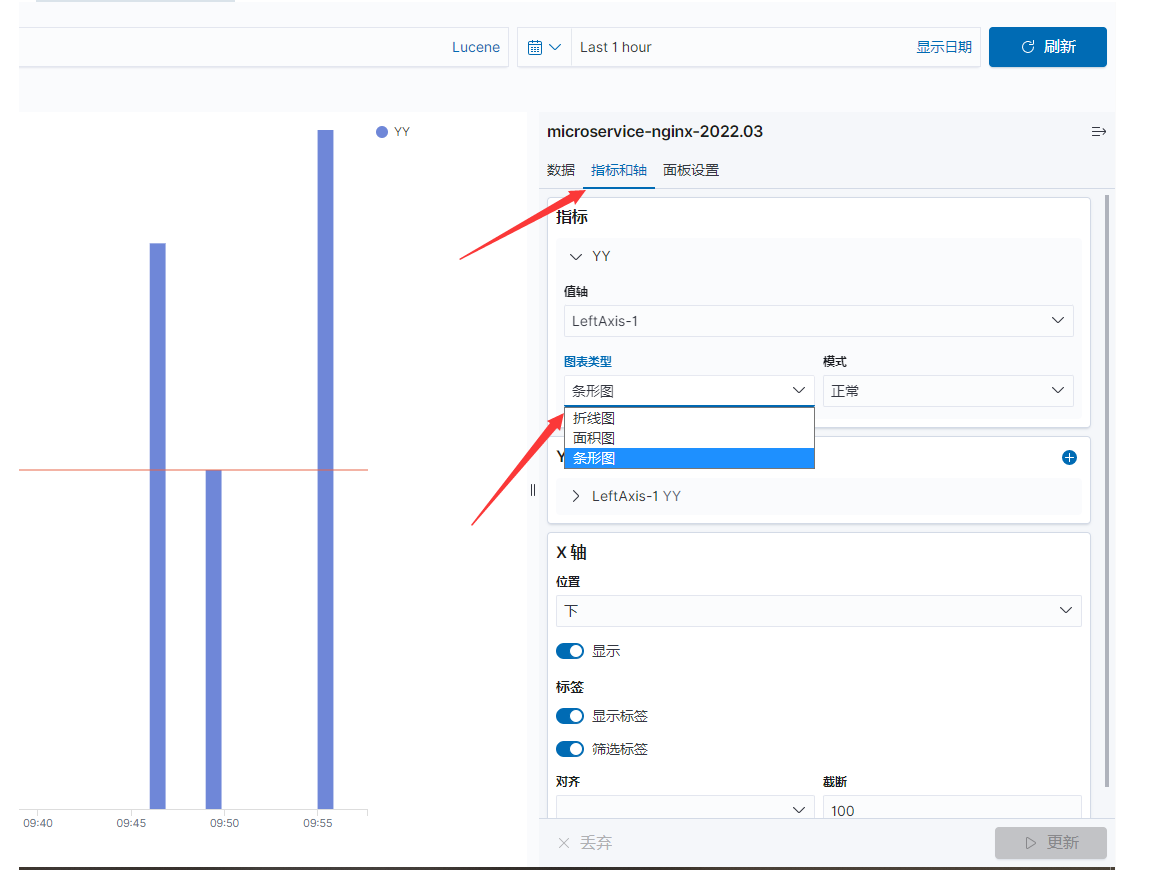
折线图里面,图表类型可以选择:面积图,条形图,折线图。

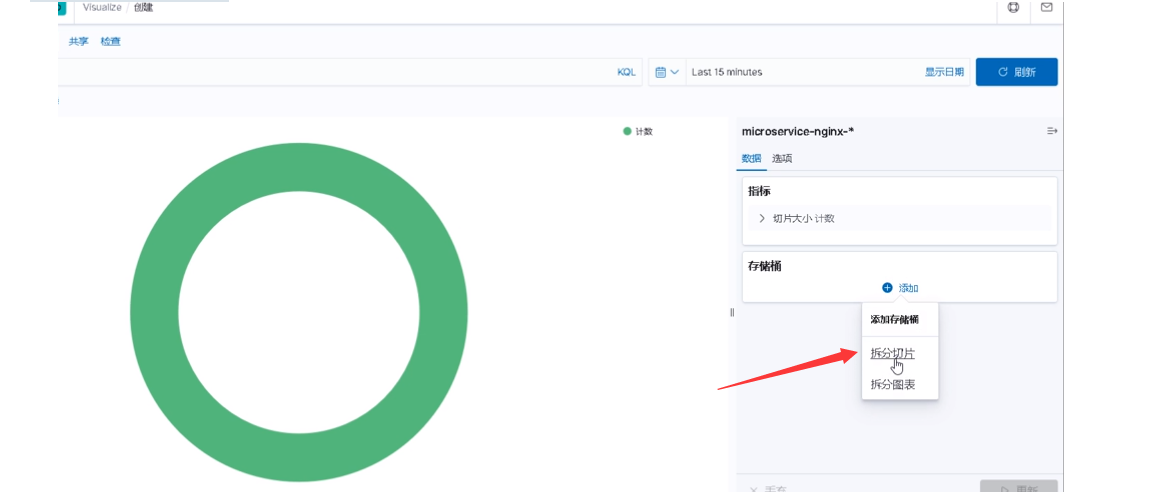
- 饼图
1、百分之占比的时候,用饼图是最好的。
2、创建饼图后,在存储桶,添加拆分切片---》聚合选择:词,字段选择status.keyword,更新。
注意:如果字段选择status.keyword,发现找不到这个字段,需要在索引模式,找到那个索引,点击右上角刷新字段列表,这样就可以找到了(没刷新的字段,在Discover界面,字段前面会显示一个问号)。

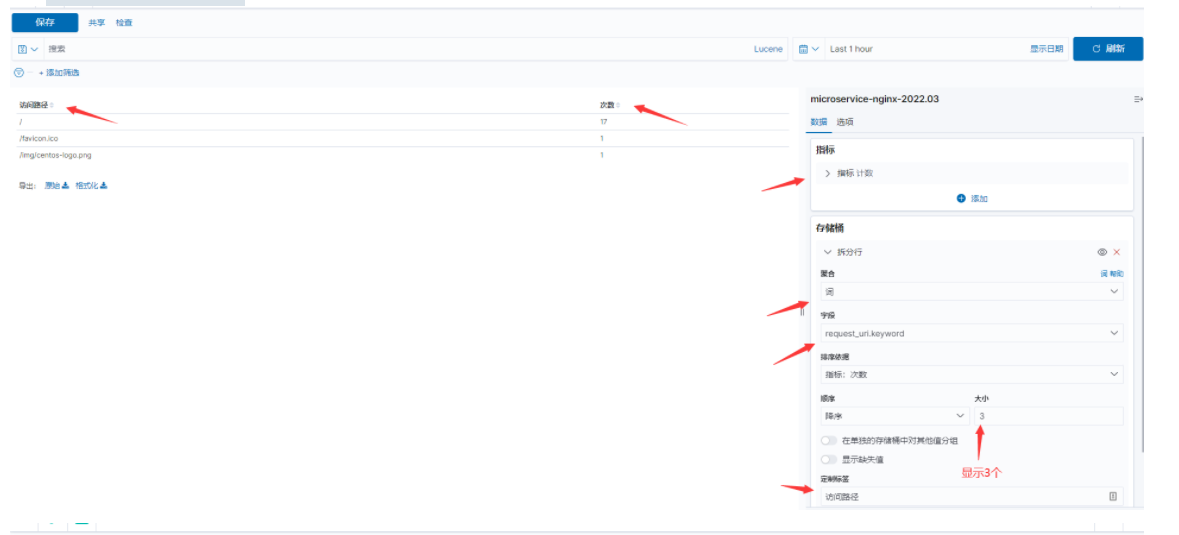
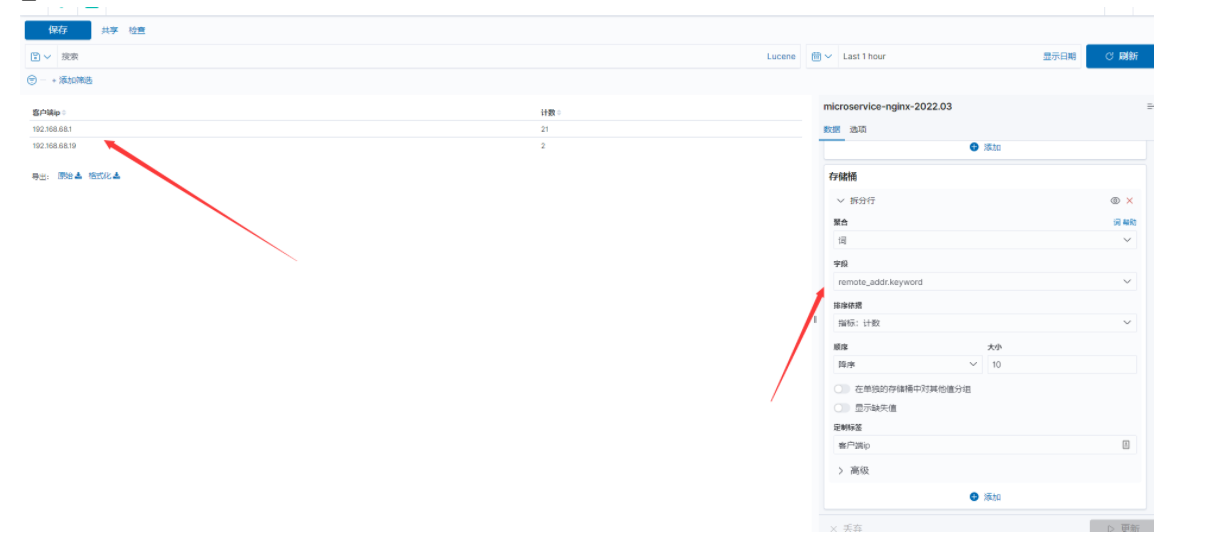
- 数据表
表格的形式展示,需求是访问排行榜。比如我们想统计uri访问top10次数统计,截图如下:
- 仪表盘
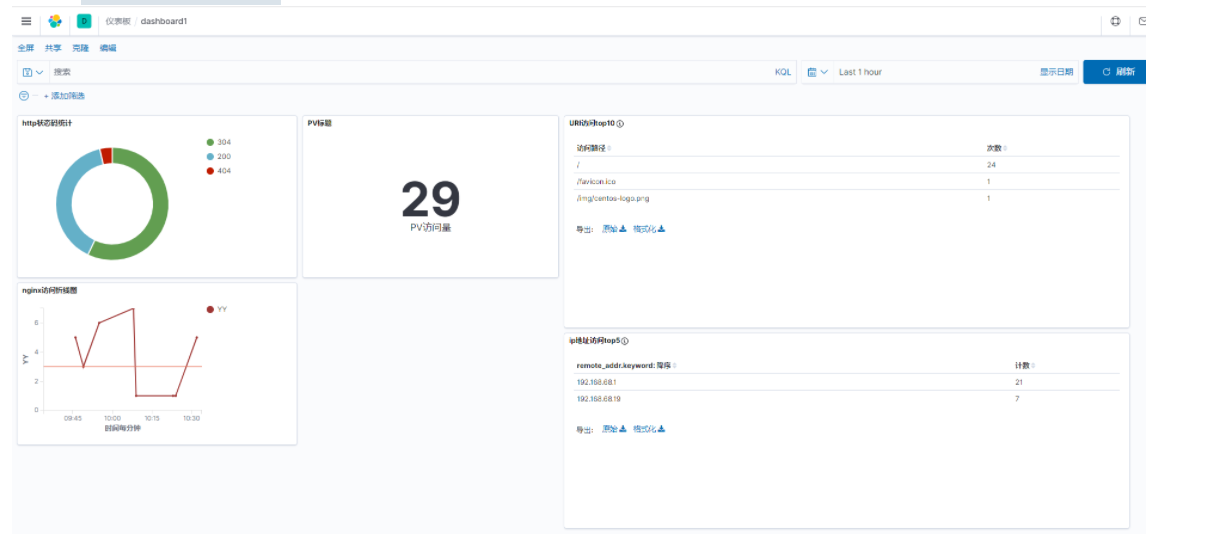
最后把所有图表放到仪表盘dashboard
5.4 问题扩展:
配置文件elasticsearch.hosts可以同时连接多个es地址吗,或者主备,当一个es挂了,自动连接另外一个。
第六章 Filebeat
6.1 Filebeat介绍、安装、配置
术语:harvesters (直译:收割机,采集器)
Filebeat是一个轻量级日志采集器,将采集的数据推送到Logstash、或ES存储(它可以直接推送到es,只是常用我们把它推送到logstash。)
filebeat也有简单的过滤,写在配置文件里面,如果复杂一点的,通常采用logstash。
早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、CPU、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
官方配置的文档:https://www.elastic.co/guide/en/beats/filebeat/7.9/logstash-output.html#_ssl_5
安装方式
有二进制安装,rpm包安装,因为是一个轻量级的采集器,我们通常采用rpm包安装。
rpm -ivh filebeat-7.9.3-x86_64.rpm
[root@filebeat1 elk]# rpm -ql filebeat | head -n 20
/etc/filebeat/fields.yml
/etc/filebeat/filebeat.reference.yml #配置示例文件,有时候不记得参数就到这里看
/etc/filebeat/filebeat.yml #配置文件
/etc/filebeat/modules.d/activemq.yml.disabled
/etc/filebeat/modules.d/apache.yml.disabled
/etc/filebeat/modules.d/auditd.yml.disabled
/etc/filebeat/modules.d/aws.yml.disabled
配置采集指定日志
vi /etc/filebeat/filebeat.yml #yml文件尤其要注释缩进
# 配置不同的输入
- type: log
# 是否启用该输入配置
enabled: false
# 采集的日志文件路径,可以通配
paths:
- /var/log/*.log
# 正则匹配要排除的行,这里以DBG开头的行都过滤掉
#exclude_lines: ['^DBG']
# 正则匹配要采集的行,这里以ERR/WARN开头的行都采集
#include_lines: ['^ERR', '^WARN']
# 排除的文件,默认采集所有
#exclude_files: ['.gz$']
# 添加标签
#tags: ["nginx"]
# 下面fields添加的字段默认是在fields.xxx,可以设置在顶级对象下。此选项设置为 true,则自定义字段将作为顶级字段存储在输出文档中,而不是分组在fields子字典下。如果自定义字段名称与其他字段名称冲突,则自定义字段会覆盖其他字段。
# fields_under_root: true
# 自定义添加的字段,一般用于标记日志来源
#fields:
# level: debug
# review: 1

推送到Logstash
output.logstash:
hosts: ["192.168.31.62:5044"]
推送到ES:
setup.ilm.enabled: false
setup.template.name: "microservice-product"
setup.template.pattern: "microservice-product-*"
output.elasticsearch:
hosts: ["localhost:9200"]
index: "microservice-product-%{+yyyy.MM.dd}"
#示例
/etc/filebeat/filebeat.yml 解析扩展,了解常用的参数,进行测试。
6.2 示例
示例1:推送到Logstash
#操作步骤
1、logstash的conf.d目录的配置文件开启beats插件,端口。
2、filebeat设置推送的目的地址,设置采集的参数。
#filebeat服务器
[root@filebeat1 elk]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/test/microservice-nginx.log
tags: ["nginx"]
fields_under_root: true #指定下面字段在顶级位置,默认在fields字段下,比如fields.app
fields:
project: microservice
app: product
output.logstash:
hosts: ["192.168.68.19:5044"]
#logstash服务器
[root@elk1 conf.d]# cat beattest.yml
input{
beats{
host => "0.0.0.0"
port => 5044 #beats插件用5044端口
}
}
filter{
}
output{
elasticsearch {
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "beat-%{+YYYY.MM.dd}"
}
}
示例2:采集多个log文件
#写多个-type;paths下面也可以写多个,还可以用通配符。
[root@filebeat1 ~]# vi /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/test/microservice-nginx.log
- /var/log/test/microservice-mysql.log
tags: ["nginx"]
fields_under_root: true
fields:
project: microservice
app: product
- type: log
enabled: true
paths:
- /var/log/test/microservice-tomcat.log
tags: ["tomcat"]
#fields_under_root: true
fields:
project: microservice
app: product
output.logstash:
hosts: ["192.168.68.19:5044"]
示例3:filebeat采集,logstash过滤判断再输出。
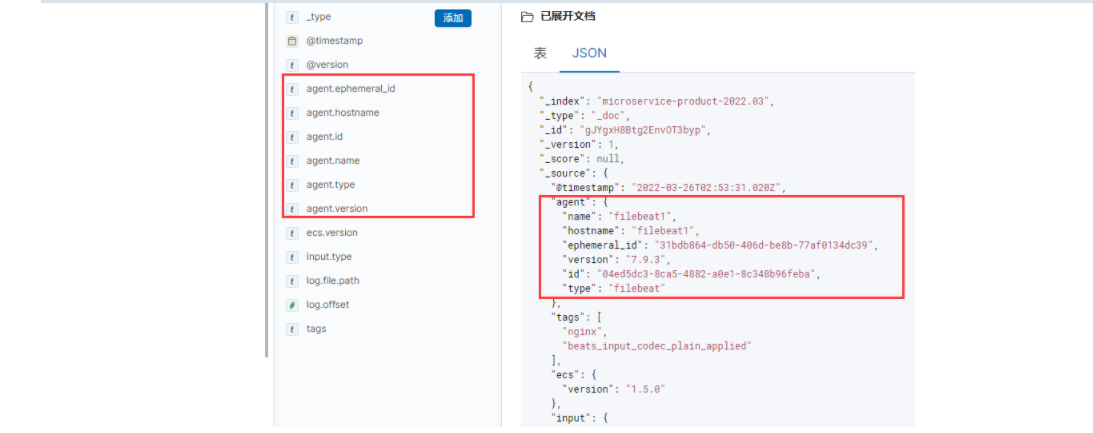
注意:其实filebeat会默认给采集的数据添加一些字段,比如filebeat.hostname,filebeat.name,在kibana的采集上来的图形界面可以看到。
[root@filebeat1 ~]# cat /etc/filebeat/filebeat.yml #filebeat采集数据的配置文件
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/test/microservice-nginx.log
tags: ["nginx"]
fields_under_root: true
fields:
project: microservice #添加标签,在logstash的时候好做判断
app: product
output.logstash:
hosts: ["192.168.68.19:5044"]
#filebeat模拟数据
[root@filebeat1 ~]# echo "192.168.168.168 GET /index.html abd 13454666 " >> /var/log/test/microservice-nginx.log
[root@elk1 conf.d]# cat beattest.yml #logstash过滤的配置文件
input{
beats{
host => "0.0.0.0"
port => 5044
#client_inactivity_timeout => 36000
}
}
filter{
if [app] == "product" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-product-%{+YYYY.MM}"
}
}
} else if [app] == "gateway" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-gateway-%{+YYYY.MM.dd}"
}
}
} else {
mutate {
add_field => {
"[@metadata][target_index]" => "weizhi-%{+YYYY}"
}
}
}
}
output{
elasticsearch {
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "%{[@metadata][target_index]}"
}
}
#下面是kibana截图
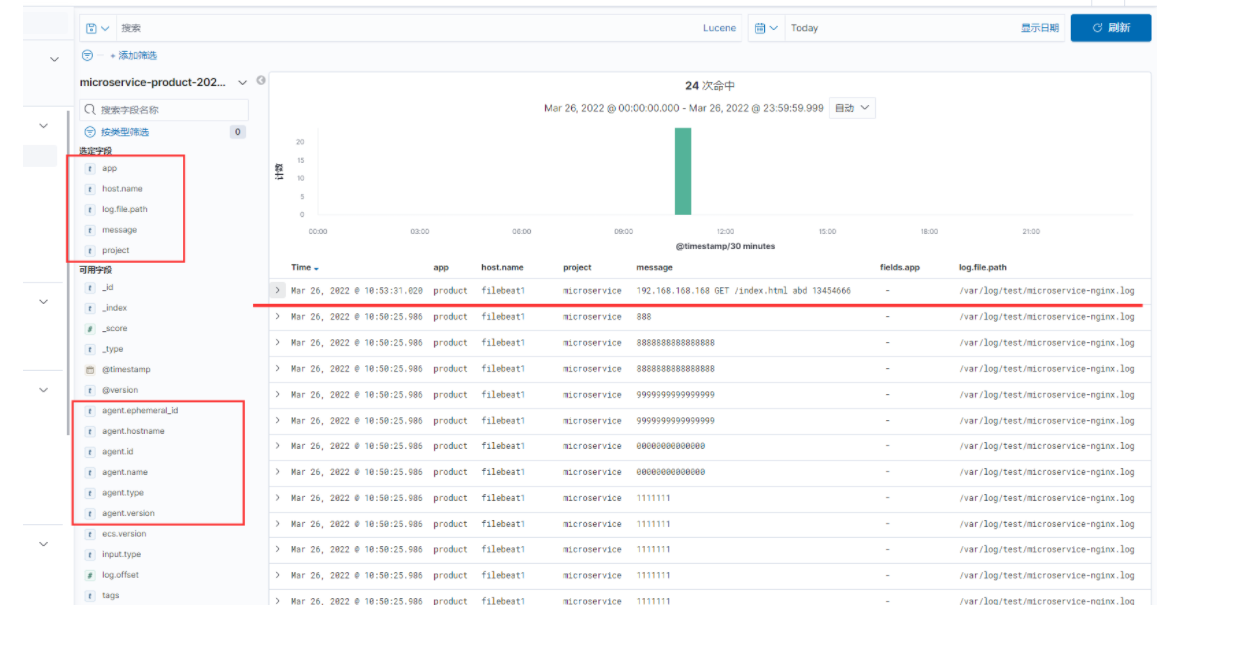
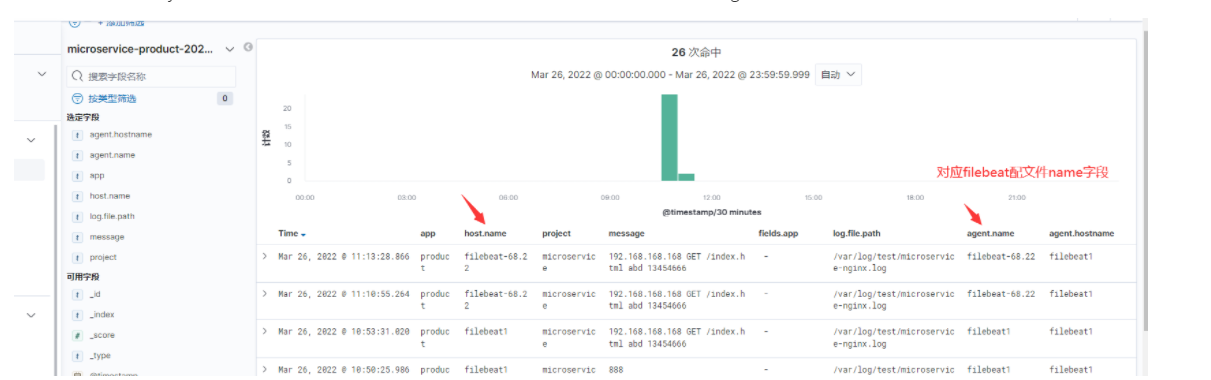
示例4:filebeat.yml 配置文件和kibana输出字段对应。
/etc/filebeat/filebeat.yml 配置文件的name: "filebeat-68.22",对应kibana输出后盾host.name字段和agent.name字段,默认是机器的主机名。
示例5:推送到es
[root@filebeat1 ~]# cat /etc/filebeat/filebeat.yml #配置文件
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/test/microservice-nginx.log
tags: ["nginx"]
fields_under_root: true
fields:
project: microservice
app: product
#output.logstash:
# hosts: ["192.168.68.19:5044"]
setup.ilm.enabled: false
setup.template.name: "microservice-product"
setup.template.pattern: "microservice-product-*"
output.elasticsearch:
hosts: ["192.168.68.19:9200"]
index: "microservice-product-%{+yyyy.MM.dd}"
name: "filebeat-68.22"
#模拟数据
[root@filebeat1 ~]# echo "192.168.168.168 GET /index.html abd 13454888 " >> /var/log/test/microservice-nginx.log
#es端不用做啥设置,把es开起来就可以了。
#推送数据后,然后就去看索引管理,有索引后,创建索引。
示例5:一个较完整的yml配置文件示例
name: filebeat68.22
fields: #这个字段在- type块下也可以写,我这里是在general区域下写,是全局的。
ziduan1: vvv
fields_under_root: true #添加的字段放在根目录
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.logstash:
hosts: ["192.168.68.19:5044"]
processors:
- add_id: ~
- add_fields:
target: test #没写,添加的字段就默认在fields字段下,比如fields.field11。
fields:
field11: 11
field22: 22
- fingerprint:
fields: ["test.field11", "test.field22"] #如果字段没找到的,不能生成指纹,那么日志都会不上传到logstash,注意哦。
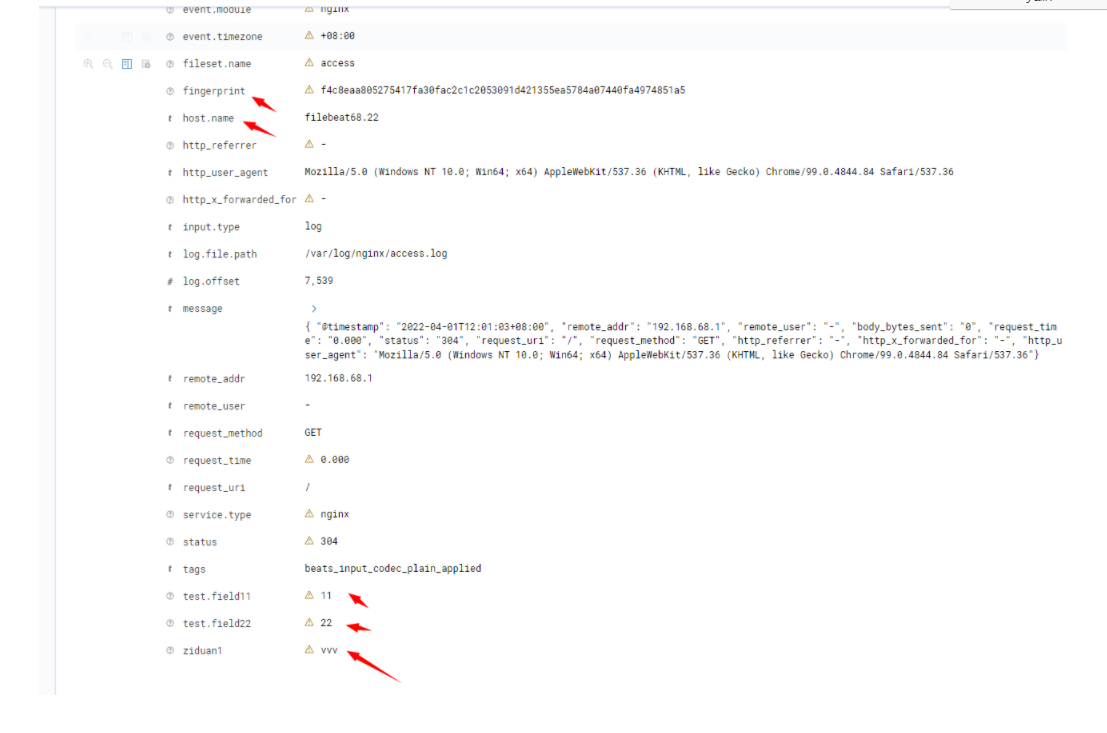
6.3 filebeat运行原理
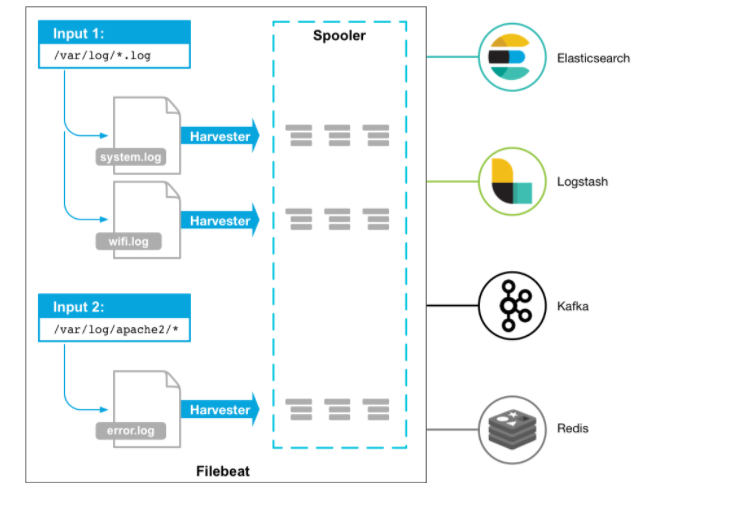
Filebeat的工作原理如下:当您启动Filebeat时,它会启动一个或多个输入,在您为日志数据指定的位置中查找。 对于Filebeat定位的每个日志,Filebeat启动一个收割机,收割机逐行读取一个文件内容,并将内容发送到输出。
为每个文件启动一个收割机。收割机负责打开和关闭文件,这意味着在收割机运行时文件描述符保持打开状态。 每个采集器读取一个新内容的日志,并将新的日志数据发送到libbeat, libbeat聚合事件并将聚合的数据发送到您为Filebeat配置的输出。 如果文件在收集过程中被删除或重命名,Filebeat 会继续读取该文件。这样做的副作用是保留磁盘上的空间,直到收割机关闭。默认情况下,Filebeat 会保持文件打开,直到close_inactive到达。
如果 Filebeat 在发送事件的过程中关闭,它不会在关闭前等待输出确认所有事件。任何发送到输出但在 Filebeat 关闭之前未确认的事件,在 Filebeat 重新启动时会再次发送。这可确保每个事件至少发送一次,但最终可能会将重复的事件发送到输出。shutdown_timeout您可以通过设置选项将 Filebeat 配置为在关闭之前等待特定的时间。可以通过shutdown_timeout设置,收到关闭命令时,多久之后才关闭harvester,然后可以看下日志harvester是否有关闭。
官方文档:
https://www.elastic.co/guide/en/beats/filebeat/7.9/how-filebeat-works.html
6.4 filebeat模块
filebeat的采集数据有两种方式, 一种是使用内置的模块;当没有内置模块的时候,就只采集,让logstash去过滤这些数据。这里我们用内置的模块也是一个很好的方法。
nginx模块只是把nginx日志格式结构化为json格式,在logstash的那里你要用json插件过滤,才会截取到各个字段的信息;其它模块也类似,模块功能只是把各个日志格式话成为json。
filebeat内置的模块,比如采集Nginx,mysql,HAProxy Module,AWS,tomcat,IIS Module,Iptables Module ,MySQL Module的日志,直接用就可以了,模块写好了采集这些日志的格式,在filebeat的yml配置文件可以配置。
#官方模块清单,模块怎么写,参数记不住可以看文档
https://www.elastic.co/guide/en/beats/filebeat/7.9/filebeat-modules.html
#模块默认都是关闭的,需要用要自己去开启。
[root@filebeat1 ~]# vi /etc/filebeat/filebeat.yml #设置模块路径
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
#开启nginx模块(多个用逗号隔开)。
#会把配置目录的/etc/filebeat/modules.d/nginx.yml.disabled文件开启来,文件名去掉最后的disabled字段
[root@filebeat1 ~]# filebeat modules enable nginx
[root@filebeat1 ~]# filebeat modules disable nginx
Disabled nginx
#列出启用和未启用的模块
[root@filebeat1 ~]# filebeat modules list
Enabled:
nginx
Disabled:
activemq
apache
#测试配置文件格式是否正确
[root@filebeat1 ~]# filebeat test config
Config OK
6.4.1 nginx内置模块配置示例:
1、filebeat部分。
[root@filebeat1 ~]# cat /etc/filebeat/filebeat.yml
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.logstash:
hosts: ["192.168.68.19:5044"]
[root@filebeat1 ~]# filebeat modules enable nginx #开启nginx模块
[root@filebeat1 ~]# filebeat modules list
Enabled:
nginx
[root@filebeat1 ~]# cat /etc/filebeat/modules.d/nginx.yml #因为nginx的日志在默认路径,所以这个配置文件没修改。
# Module: nginx
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.9/filebeat-module-nginx.html
- module: nginx
# Access logs
access:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths: ["/var/log/nginx/access.log"]
2、logstash部分。用json插件过滤下日志,截取各个字段。
[root@elk1 conf.d]# cat beattest.yml
input{
beats{
host => "0.0.0.0"
port => 5044
#client_inactivity_timeout => 36000
}
}
filter{
json { #要用json插件过滤下
source => "message"
}
if [component] == "nginx" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-nginx-%{+YYYY.MM}"
}
}
} else if [app] == "gateway" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-gateway-%{+YYYY.MM.dd}"
}
}
} else {
mutate {
add_field => {
"[@metadata][target_index]" => "weizhi-%{+YYYY}"
}
}
}
}
output{
elasticsearch {
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "%{[@metadata][target_index]}"
}
}
3、在浏览器访问nginx,在es就可以看到数据了。
截图如下
6.4.2 redis内置模块配置示例:
redis模块作用是:把redis的日志,由不是json格式的,转成json格式;这样logstash再用json插件解析一下就可以了。
#安装redis,redis来自epel源
yum install -y epel-release
yum install -y redis
systemctl start redis
systemctl status redis
[root@filebeat1 ~]# filebeat modules enable redis #开启redis模块
Enabled redis
[root@filebeat1 ~]# filebeat modules list
Enabled:
nginx
redis
#开启了模块之后,/etc/filebeat/filebeat.yml只要把模块的路径目录指定就好了,其它不设置。凡是开启的模块,filebeat会根据模块的yml文件自动采集日志,推送到logstash;没有用的模块disable掉,以免把日志采集了。
[root@filebeat1 ~]# vi /etc/filebeat/filebeat.yml
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.logstash:
hosts: ["192.168.68.19:5044"]
6.5 filebeat配置文件
less /etc/filebeat/filebeat.reference.yml 配置文件有所有的参数,大概有几千行,你找不到的参数,或者忘记参数怎么写的可以去找。
#filebeat.yml分几部分:
module #模块部分
Filebeat inputs
General
Filebeat global options
Processors
Outputs #输出部分,支持文件输出,es,logstash,redis等等。
#filebeat接受输入类型:
从配置文件看出有:Stdin input,tcp,udp,redis输入,Syslog input, Container input等等,还有很多。
从stdin输入,然后输出到文件,如下:
#直接贴配置
[root@filebeat1 ~]# vi /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: stdin
enabled: true
output.file:
path: "/tmp/filebeat/"
filename: "fb-test" #文件名字
enabled: true
rotate_every_kb: 10000 #达到10000KB的时候轮询日志大小
number_of_files: 2 #目录下只可以小于两个的文件
permissions: 0600 #创建文件的权限
name: "filebeat-68.22"
#filebeat.shutdown_timeout: 10s
beat.yml" 17L, 301C written
[root@filebeat1 ~]# filebeat test config #检查配置文件是否ok
[root@filebeat1 ~]# systemctl stop filebeat.service #停止服务,否则会用命令启动filebeat会冲突。
[root@filebeat1 ~]# /usr/bin/filebeat #启动
wo is yi ge bing
[root@filebeat1 ~]# ll /tmp/filebeat/fb-test
-rw-------. 1 root root 448 Mar 28 21:14 /tmp/filebeat/fb-test
6.6 filebeat多久采集一次数据?
答:这里面有4个参数scan_frequency、backoff、max_backoff 、backoff_factor。
默认情况下几乎是实时的,如果网络正常1s采集一次。
情况1:
scan_frequency:Filebeat以多快的频率去指定的目录下面检测是否有新文件,如果设置为0s,则Filebeat会尽可能快地感知更新(占用的CPU会变高)。默认是10s。
情况2:当情况1检测到有新文件,这时候就在新文件的内容做检查的时候,就进入了情况2,情况如下:
backoff:当 filebeat 采集完一个文件的日志(一直读到文件结尾)时,它会隔一段时间再看看有没有新的日志 append 进来。这个一段时间就是 backoff 的值。如果 filebeat 再次查看时依然没有新的日志,那么它会隔 backoff * backoff_factor 也就是默认 2 秒之后才继续查看,直到整个 backoff 的时间达到 max_backoff 也即是 10 秒为止。当到达max_backoff,后面每次都会是等待max_backoff时间,一直到文件有更新才会重置为等待backoff。
max_backoff:Filebeat检测到某个文件到了EOF之后,等待检测文件更新的最大时间,默认是10秒。
backoff_factor:backoff的因子参数。定义到达max_backoff的速度,默认因子是2,到达max_backoff后,变成每次等待max_backoff那么长的时间才会backoff一次了,直到文件有更新才会重置为backoff。比如: 如果设置成1,意味着去使能了退避算法,每隔backoff那么长的时间退避一次。
6.7 拓展
1、filebeat配置输出到多个logstash主机,他是随机发送吗,还是负载均衡发送?
默认是随机,可以修改参数作为负载均衡loadbalance参数发送。超时是timeout参数,默认是30s
output.logstash:
hosts: ["localhost:5044", "localhost:5045"]
loadbalance: true #配置使用负载均衡
官方文档:
https://www.elastic.co/guide/en/beats/filebeat/7.9/logstash-output.html#loadbalance
2、官方文档查看说明

3、 filebeat如何对日志增加唯一标识的id?
配置文档的processor部分配置,有add_id或fingerprint字段配置; 另外本身filebeat就有代唯一标识的id了。
processor部分还有对事件的处理功能,比如重命名等等,自己去看文档。
输出示例:
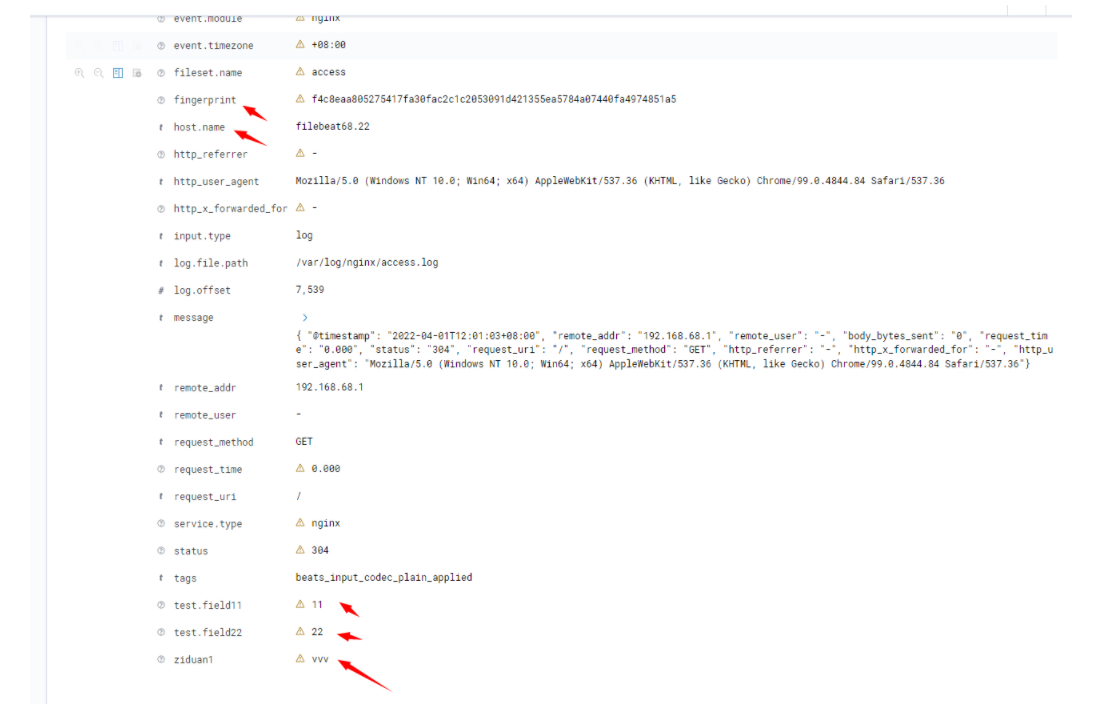
4、 如何增加自定义的一些属性?
通过general options中的tags,fields;或namespace里的tags,fields,建议使用fields_under_root将属性解析为根属性;或processor的add_field也是可以。
name: filebeat68.22
fields: #这个字段在- type块下也可以写,我这里是在general区域下写,是全局的。
ziduan1: vvv
fields_under_root: true #添加的字段放在根目录
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.logstash:
hosts: ["192.168.68.19:5044"]
processors:
- add_id: ~
- add_fields:
target: test #没写,添加的字段就默认在fields字段下,比如fields.field11。
fields:
field11: 11
field22: 22
- fingerprint:
fields: ["test.field11", "test.field22"] #如果字段没找到的,不能生成指纹,那么日志都会不上传到logstash,注意哦。

4、elk启动和停止顺序
启动(后端到前端):elasticserach-->logstash或kafka-->filebeat或kibana
停止(前端到后端顺序):filebeat/kibana--->kafka/logstash--->elasticsearch
6.8 问题积累
1、报错如下:Error while initializing input: No paths were defined
答:/etc/filebeat/filebeat.yml文件paths参数写错了,写成了pahts,哈哈。
[root@filebeat1 elk]# journalctl -u filebeat.service -f
-- Logs begin at Fri 2022-03-25 19:26:16 CST. --
Mar 25 22:47:53 filebeat1 filebeat[24856]: Exiting: Failed to start crawler: starting input failed: Error while initializing input: No paths were defined for input accessing 'filebeat.inputs.0' (source:'/etc/filebeat/filebeat.yml') #没有paths定义,其实这里已经说明了。
Mar 25 22:47:53 filebeat1 systemd[1]: filebeat.service: main process exited, code=exited, status=1/FAILURE
Mar 25 22:47:53 filebeat1 systemd[1]: Unit filebeat.service entered failed state.
Mar 25 22:47:53 filebeat1 systemd[1]: filebeat.service failed.
Mar 25 22:47:53 filebeat1 systemd[1]: filebeat.service holdoff time over, scheduling restart.
Mar 25 22:47:53 filebeat1 systemd[1]: Stopped Filebeat sends log files to Logstash or directly to Elasticsearch..
Mar 25 22:47:53 filebeat1 systemd[1]: start request repeated too quickly for filebeat.service
Mar 25 22:47:53 filebeat1 systemd[1]: Failed to start Filebeat sends log files to Logstash or directly to Elasticsearch..
2、采集了数据,在kibana看不到。
答:还是时间问题,filebeat服务器的时间不准,推送到es后,kibana展示es也看的时间不准。
3、以前创建的索引,比如带通配符的,比如beat-2022*,后面如果有新增加的索引,好像不会把数据写入到这里面来。
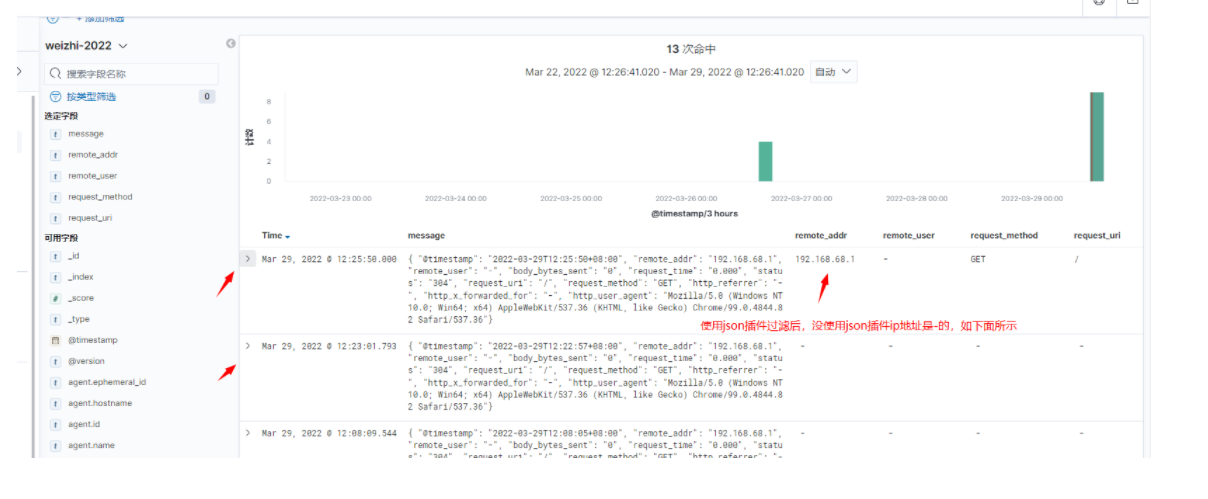
后自己去确认一下。
4、修改了filebeat.yml文件的内容,增加一个- module: nginx等好几行数据,提示如下:
Mar 29 10:54:58 filebeat1 filebeat[19879]: Exiting: error loading config file: yaml: line 6: did not find expected ke
答:启用nginx模块,修改它的路径等不应该在filebeat.yml文件修改,而应该在modules.d/nginx.yml模块文件上修改这个参数,修改的位置不对导致一直语法错误。这个问题卡了我很久,害。
第七章 日志收集案例
7.1 收集Nginx访问日志
两种方式:
1,nginx是默认日志格式,采用写正则的方式。
2、nginx是json格式的文件(要在nginx配置文件修改为json格式),logstash用json插件就可以解决。
#安装nginx
yum install epel-release
yum repolist
yum install -y nginx
/var/log/nginx/是nginx的日志文件目录有access.log error.log,
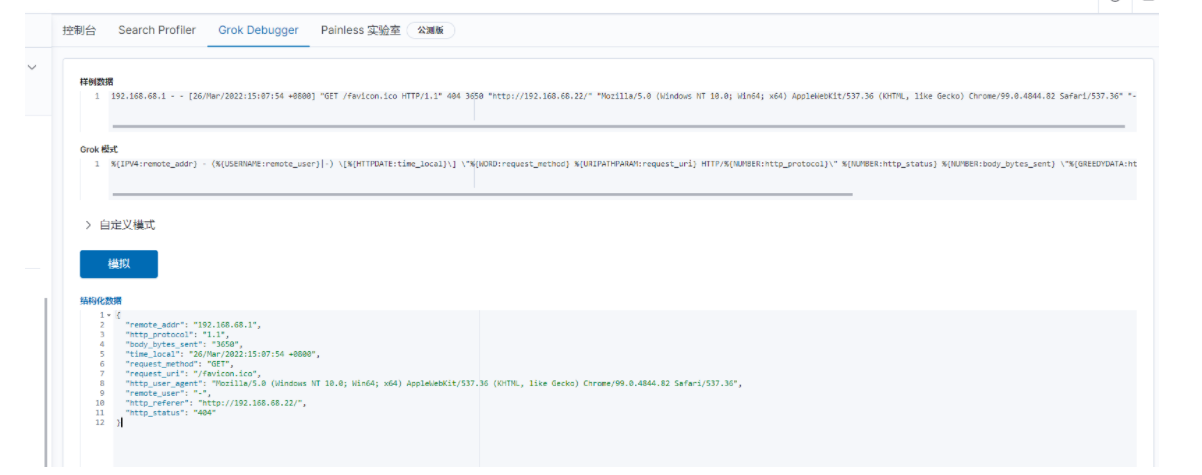
方法1、写Grok正则匹配:
1,先到grok debugger验证下,写的正则对不对,截图
#filebeat配置文件1
[root@filebeat1 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*.log
tags: ["nginx"]
fields_under_root: true
fields:
project: microservice
app: product
component: nginx #这里加个标签,后面要做判断。
output.logstash:
hosts: ["192.168.68.19:5044"]
#setup.ilm.enabled: false
3setup.template.name: "microservice-product"
#setup.template.pattern: "microservice-product-*"
#output.elasticsearch:
# hosts: ["192.168.68.19:9200"]
# index: "microservice-product-%{+yyyy.MM.dd}"
name: "filebeat-68.22"
############################################
#logstash配置文件2
[root@elk1 conf.d]# cat beattest.yml
input{
beats{
host => "0.0.0.0"
port => 5044
#client_inactivity_timeout => 36000
}
}
filter{
grok {
match => {
"message" => "%{IPV4:remote_addr} - (%{USERNAME:remote_user}|-) \[%{HTTPDATE:time_local}\] \"%{WORD:request_method} %{URIPATHPARAM:request_uri} HTTP/%{NUMBER:http_protocol}\" %{NUMBER:http_status} %{NUMBER:body_bytes_sent} \"%{GREEDYDATA:http_referer}\" \"%{GREEDYDATA:http_user_agent}\" \"(%{IPV4:http_x_forwarded_for}|-)\""
}
}
if [component] == "nginx" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-nginx-%{+YYYY.MM}"
}
}
} else if [app] == "gateway" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-gateway-%{+YYYY.MM.dd}"
}
}
} else {
mutate {
add_field => {
"[@metadata][target_index]" => "weizhi-%{+YYYY}"
}
}
}
}
output{
elasticsearch {
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "%{[@metadata][target_index]}"
}
}
#3,在网页访问下nginx就可以打印出日志了。
方法2、将Nginx访问日志格式改为JSON:

#1、先把nginx配置文件修改为json格式。
[root@filebeat1 ~]# cat /etc/nginx/nginx.conf #直接截取一部分
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format json '{ "@timestamp": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"request_uri": "$request_uri", '
'"request_method": "$request_method", '
'"http_referrer": "$http_referer", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent"}';
access_log /var/log/nginx/access.log json; #这里json代表引用前面取名的json,而不是man
[root@filebeat1 ~]# systemctl restart nginx.service
[root@filebeat1 ~]# systemctl status nginx.service
配置文件
#2、filebeat
[root@filebeat1 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*.log
tags: ["nginx"]
fields_under_root: true
fields:
project: microservice
app: product
component: nginx
output.logstash:
hosts: ["192.168.68.19:5044"]
#setup.ilm.enabled: false
#setup.template.name: "microservice-product"
#setup.template.pattern: "microservice-product-*"
#output.elasticsearch:
# hosts: ["192.168.68.19:9200"]
# index: "microservice-product-%{+yyyy.MM.dd}"
name: "filebeat-68.22"
#3、修改lgostash过滤文件。
[root@elk1 conf.d]# cat beattest.yml
input{
beats{
host => "0.0.0.0"
port => 5044
#client_inactivity_timeout => 36000
}
}
filter{
json {
source => "message" #用json插件,他会自动解析
}
if [component] == "nginx" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-nginx-%{+YYYY.MM}"
}
}
} else if [app] == "gateway" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-gateway-%{+YYYY.MM.dd}"
}
}
} else {
mutate {
add_field => {
"[@metadata][target_index]" => "weizhi-%{+YYYY}"
}
}
}
}
output{
elasticsearch {
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "%{[@metadata][target_index]}"
}
}
#4、在浏览器访问nginx,查看kibana就有数据了。
7.2 收集Java堆栈日志
一般应用记录的日志,每行表示一个事务(document),但有些日志是多行表示一个事务。
例如,常见的Java堆栈日志:
Exception in thread "main" java.lang.NullPointerException
at com.example.myproject.Book.getTitle(Book.java:16)
at com.example.myproject.Author.getBookTitles(Author.java:25)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
上面文档表示四行,在Kibana里也视为四个单独的文档,但实际这是一个异常日志,如果分开阅读会脱离上下文关系,不利于分析。因此,为了避免此问题,可以让filebeat启用多行处理,将这四行作为一个事件发送。
filebeat多行参数(写在type字段下):
• multiline.pattern: '^\s' 正则表达式,匹配行
• multiline.negate: false 否定正则匹配模式,正则取反效果。例如false时将匹配的
行合并到上一行,true时将不匹配的行合并到上一行。默认false
• multiline.match: after 合并到上一行的末尾还是开头(before)
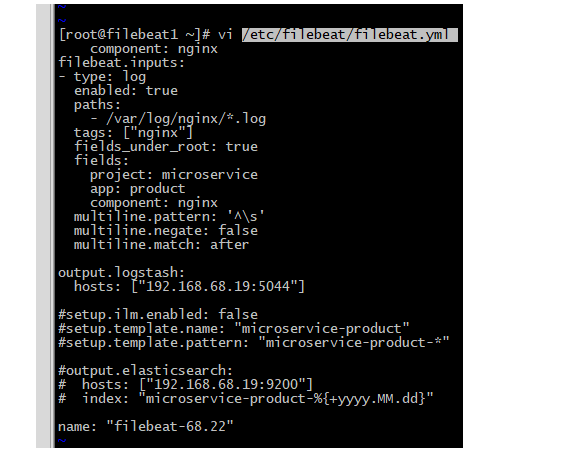
未加参数前,截图所示,日志是分行的,在kibana的时候一行做一个事件了。
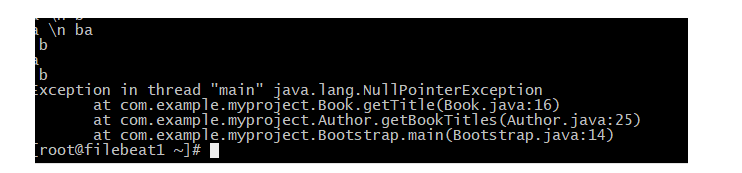

加上参数后截图:

negate和match值,对于关系图:

示例:
#这里我们没有java日志,手写的模拟
[root@filebeat1 ~]# cat /etc/filebeat/filebeat.yml #filebeat配置文件
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*.log
tags: ["nginx"]
fields_under_root: true
fields:
project: microservice
app: product
component: nginx
multiline.pattern: '^\s'
multiline.negate: false
multiline.match: after
output.logstash:
hosts: ["192.168.68.19:5044"]
#setup.ilm.enabled: false
#setup.template.name: "microservice-product"
#setup.template.pattern: "microservice-product-*"
#output.elasticsearch:
# hosts: ["192.168.68.19:9200"]
# index: "microservice-product-%{+yyyy.MM.dd}"
name: "filebeat-68.22"
[root@elk1 ~]# cat /opt/elk/logstash/conf.d/beattest.yml #logstash配置文件
input{
beats{
host => "0.0.0.0"
port => 5044
#client_inactivity_timeout => 36000
}
}
filter{
#json {
# source => "message"
#}
if [component] == "nginx" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-nginx-%{+YYYY.MM}"
}
}
} else if [app] == "gateway" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-gateway-%{+YYYY.MM.dd}"
}
}
} else {
mutate {
add_field => {
"[@metadata][target_index]" => "weizhi-%{+YYYY}"
}
}
}
}
output{
elasticsearch {
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "%{[@metadata][target_index]}"
}
}
[root@filebeat1 ~]# cat javalog.txt #模拟的日志
Exception in thread "main" java.lang.NullPointerException
at com.example.myproject.Book.getTitle(Book.java:16)
at com.example.myproject.Author.getBookTitles(Author.java:25)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
[root@filebeat1 ~]# cat javalog.txt >> /var/log/nginx/access.log #把日志直接写到日志文件
7.3 收集Kubernetes日志
这里我没有k8s环境,只做一个思路的笔记。
容器特性给日志采集带来的难度:
• K8s弹性伸缩性:导致不能预先确定采集的目标
• 容器隔离性:容器的文件系统与宿主机是隔离,导致日志采集器读取日志文件受阻
K8S应用程序日志记录体现方式分为两类:
• 标准输出:输出到控制台,使用kubectl logs可以看到的日志
• 日志文件:写到容器的文件系统的文件
针对标准输出:以DaemonSet方式在每个Node上部署一个日志收集程序,采集
/var/lib/docker/containers/目录下所有容器日志
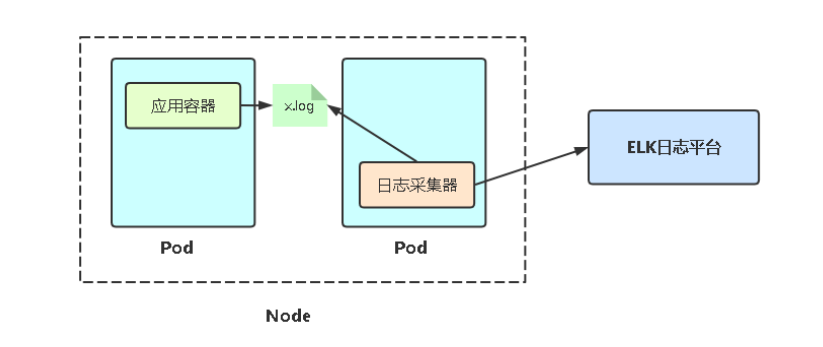
针对容器中日志文件:在Pod中增加一个容器运行日志采集器,使用emtyDir共享日志目录让日志采集器读取到日志文件
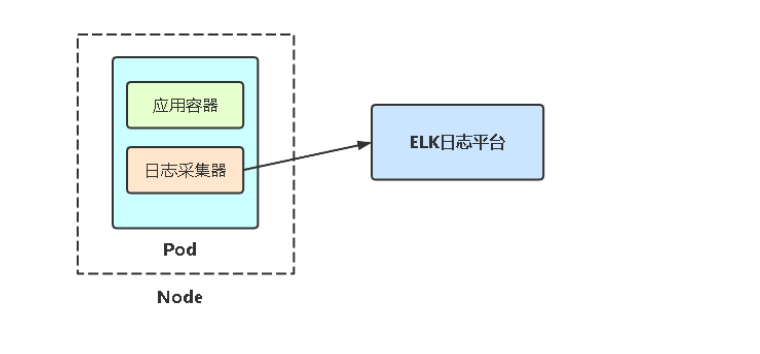
第八章 架构优化
8.1引入消息队列redis,保证日志安全与缓解高并发
架构优化
• 这里我们用redis,增加数据缓冲队列,
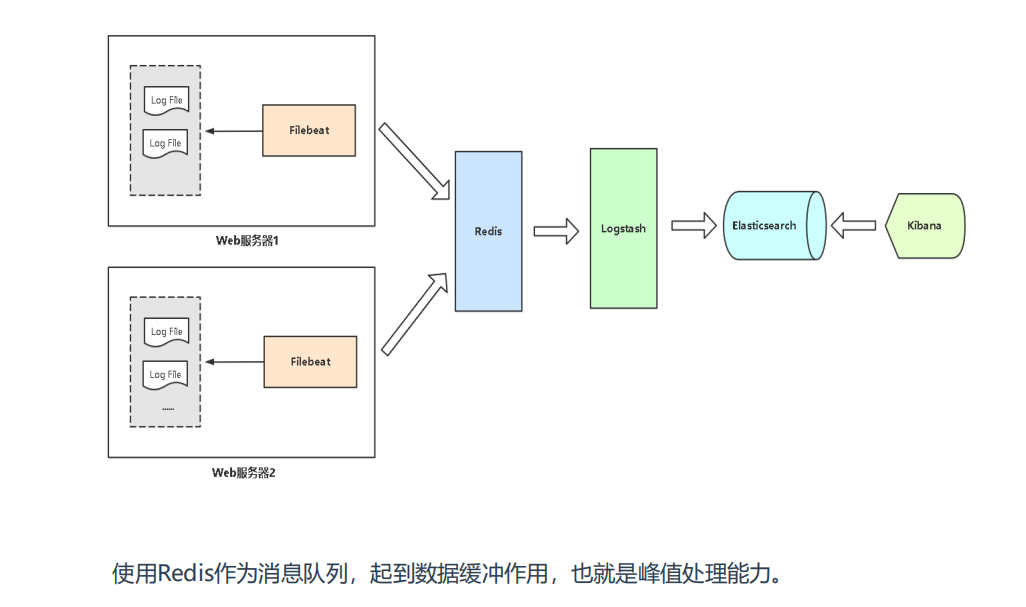
示例:
#安装redis,redis来自epel源
yum install -y epel-release
yum install -y redis
[root@filebeat1 ~]# systemctl start redis
[root@filebeat1 ~]# systemctl status redis
示例配置文件:
#redis配置文件
[root@elk1 ~]# cat /etc/redis.conf | grep -e bind -e requirepass
bind 0.0.0.0
requirepass 123456 #密码
[root@elk1 ~]# redis-cli -a 123456 #检查redis是否有数据。当redis的数据被logstash独取走之后,这里的数据就会消失;redis是发布订阅键值数据库,发布的信息被取走了,就会消失,他只是一个缓冲的作用。
127.0.0.1:6379> keys *
1) "filebeat2"
2) "filebeat"
#filebeat配置文件
[root@filebeat1 ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*.log
tags: ["nginx"]
fields_under_root: true
fields:
project: microservice
app: product
component: nginx
multiline.pattern: '^\s'
multiline.negate: true
multiline.match: after
output.redis:
hosts: ["192.168.68.19:6379"]
password: "123456" #redis的密码
key: "filebeat2" #key值是多少
db: 0 #数据库
datatype: "list" #类型
name: "filebeat-68.22"
#logstash配置文件
[root@elk1 conf.d]# vi beattest.yml
input{
redis { #redis插件
host => "192.168.68.19"
port => 6379
password => "123456"
key => "filebeat2"
db => 0
data_type => "list"
}
}
filter{
if [component] == "nginx" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-nginx-%{+YYYY.MM}"
}
}
} else if [app] == "gateway" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-gateway-%{+YYYY.MM.dd}"
}
}
} else {
mutate {
add_field => {
"[@metadata][target_index]" => "weizhi-%{+YYYY}"
}
}
}
}
output{
elasticsearch {
hosts => ["192.168.68.19:9200","192.168.68.128:9200","192.168.68.129:9200"]
index => "%{[@metadata][target_index]}"
}
}

8.2 未来架构扩容思路
如果日志量每天100G以上,还需要增加更多的服务器支撑。
例如扩容:
• Logstash
• Elasticsearch
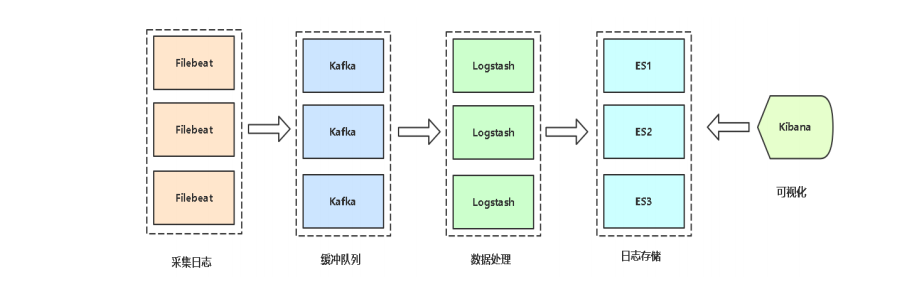
8.3 其它优化点
• 在预算充足情况下,服务器硬件配置尽量高。
• 索引管理。索引类似数据库,根据业务规划好索引,不用的索引可以删除或者关闭,这里对索引的操作可以用api,如下
例如:
curl -XPOST "http://127.0.0.1:9200/microservice-gateway-2020.11*/_close?pretty" # 开启用_open。将没用的索引关闭掉,这样就不出查询到了,也可以在kibana图形界面关闭。
curl -XDELETE "http://127.0.0.1:9200/microservice-gateway-2020.11* " #这里是用api删除索引mcroservice-gateway-2020.11*,索引模式不会删除,类似只是删除了数据库。
#关闭索引,打开索引示例
[root@elk1 ~]# curl -XPOST "http://192.168.68.128:9200/weizhi-2022/_close?pretty"
{
"acknowledged" : true,
"shards_acknowledged" : true,
"indices" : {
"weizhi-2022" : {
"closed" : true
}
}
}
[root@elk1 ~]#
[root@elk1 ~]# curl -XPOST "http://192.168.68.128:9200/weizhi-2022/_open?pretty"
{
"acknowledged" : true,
"shards_acknowledged" : true
}
#删除示例
[root@elk1 ~]# curl -XDELETE "http://192.168.68.128:9200/test-2022.03.25"
{"acknowledged":true}
[root@elk1 ~]#
[root@elk1 ~]# curl -XDELETE "http://192.168.68.128:9200/unknown-2022.03.25"
{"acknowledged":true}
截图
第九章 heartbeat
Hearthbeat,顾名思义心跳,面向运行状态监测的轻量型采集器,Hearthbeat可以用来定时探测服务是否正常运行。
支持ICMP、TCP 和 HTTP,也支持TLS、身份验证和代理。
Heartbeat 是 Elastic Stack 的一部分,因此能够与 Logstash、Elasticsearch 和 Kibana 无缝协作。安装Hearthbeat,添加需要监控的服务,配置好Elasticsearch和Kibana,即可将结果输出到Elasticsearch,并在Kibana显示出来。Kibana无须再配置Dashboard,直接点击Uptime菜单即可看到结果。
官方文档:https://www.elastic.co/guide/en/beats/heartbeat/current/index.html
官方下载:https://www.elastic.co/cn/downloads/past-releases#heartbeat
heartbeat自带一个dashboard,空了练习一下:https://www.elastic.co/guide/en/beats/heartbeat/current/heartbeat-installation-configuration.html
- 安装
#手动下载包rpm包,本地安装。
[root@filebeat1 elk]# rpm -iv heartbeat-7.9.3-x86_64.rpm
[root@filebeat1 elk]# rpm -ql heartbeat-elastic
/etc/heartbeat/fields.yml
/etc/heartbeat/heartbeat.reference.yml
/etc/heartbeat/heartbeat.yml
/etc/heartbeat/monitors.d/sample.http.yml.disabled
/etc/heartbeat/monitors.d/sample.icmp.yml.disabled
/etc/heartbeat/monitors.d/sample.tcp.yml.disabled
/etc/init.d/heartbeat-elastic
/lib/systemd/system/heartbeat-elastic.service
[root@filebeat1 elk]# cat /lib/systemd/system/heartbeat-elastic.service #服务文件,我们看到有环境变量path.config,path.data
[Unit]
Description=Ping remote services for availability and log results to Elasticsearch or send to Logstash.
Documentation=https://www.elastic.co/products/beats/heartbeat
Wants=network-online.target
After=network-online.target
[Service]
Environment="BEAT_LOG_OPTS="
Environment="BEAT_CONFIG_OPTS=-c /etc/heartbeat/heartbeat.yml"
Environment="BEAT_PATH_OPTS=--path.home /usr/share/heartbeat --path.config /etc/heartbeat --path.data /var/lib/heartbeat --path.logs /var/log/heartbeat"
ExecStart=/usr/share/heartbeat/bin/heartbeat --environment systemd $BEAT_LOG_OPTS $BEAT_CONFIG_OPTS $BEAT_PATH_OPTS
Restart=always
[Install]
WantedBy=multi-user.target
[root@filebeat1 elk]# heartbeat test config
Config OK
[root@filebeat1 elk]# heartbeat test config -e