
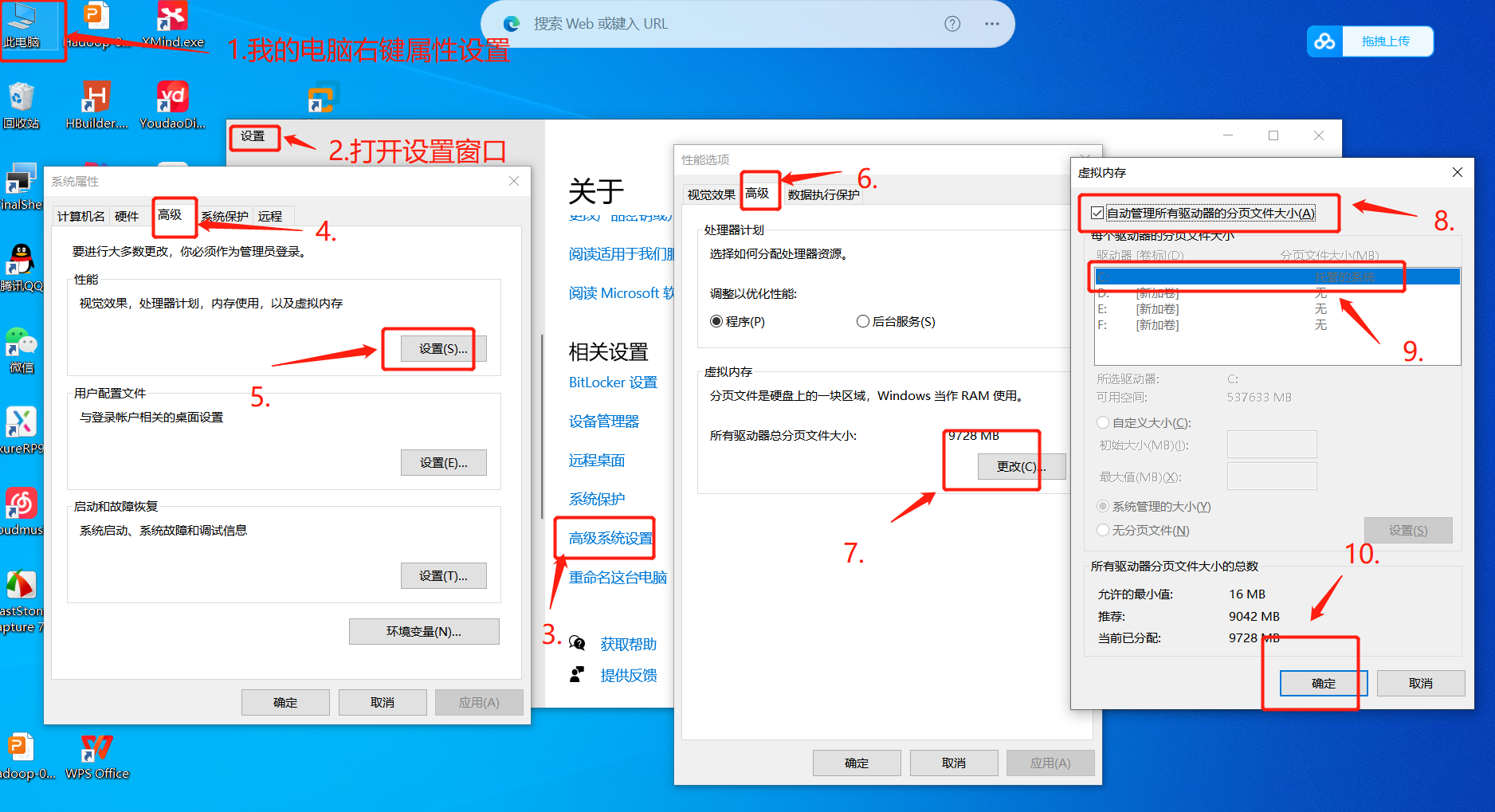
1、设置主机上的虚拟缓存
当本地内存不足时,可以使用虚拟内存将一些内存数据转移到硬盘上,从而扩展计算机的内存容量。这样可以让计算机运行更复杂、更占用内存的程序,不会出现内存不足的情况。减轻物理存储器不足的压力,设置虚拟内存可以在内存不够的情况下将缓存一时放在硬盘上,解决内存不足问题。
通过虚拟内存,操作系统可以将应用程序使用的内存空间转换为虚拟地址,从而允许应用程序访问不在物理内存中的数据。这样可以避免因为内存不足而导致系统性能下降的情况。虚拟内存可以及时从物理内存中调出数据放到虚拟内存空间中,以便在高负载情况下释放内存空间,提升程序的运行速度。
设置步骤如下
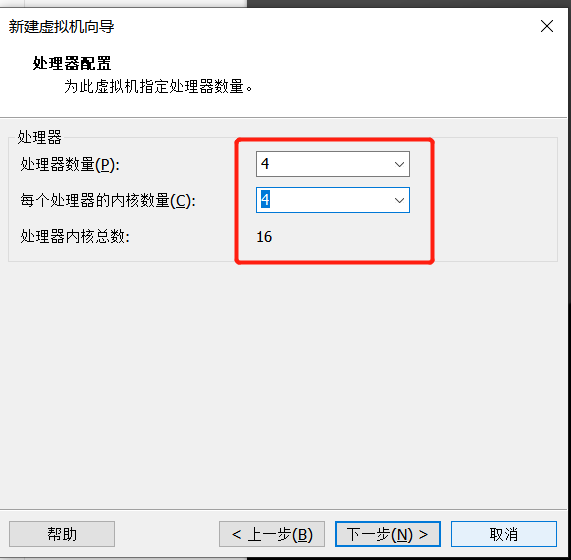
2、虚拟机在安装时CPU、内存、硬盘的参数设置
处理器核心数量:12核的处理器有12个核心,而16核的处理器有16个核心,核心数量的增加可以提高处理器的并行计算能力,从而能够更快地处理大量的数据和复杂的任务。
性能表现:由于电脑的处理器是计算任务的核心,因此处理器性能的提高可以显著提高电脑的整体性能。由于16核处理器的处理能力更强大,因此在计算密集型应用程序中,16核相比12核的处理器会有更快的速度和更好的性能表现。
计划构建3个虚拟化的集群,因此至少设置CPU的内核总数为4,此处根据自己电脑性能来自行设置,为了提高性能,我此处将设置16核
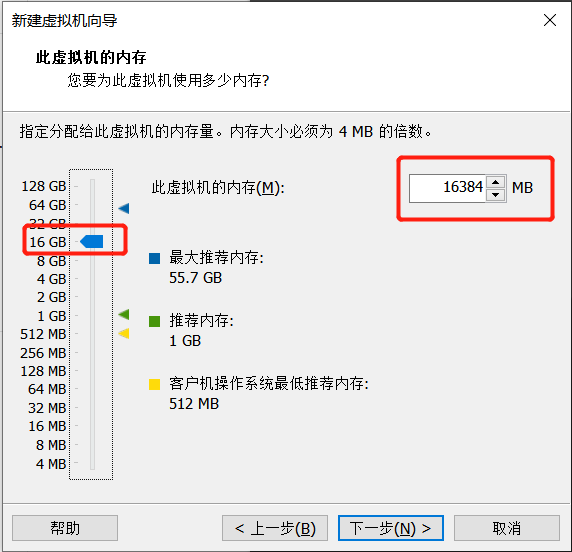
虚拟机内存设置至少8个G,可根据自己电脑配置设置,由于我电脑内存是64G,我这里给虚拟机分配设置16G内存
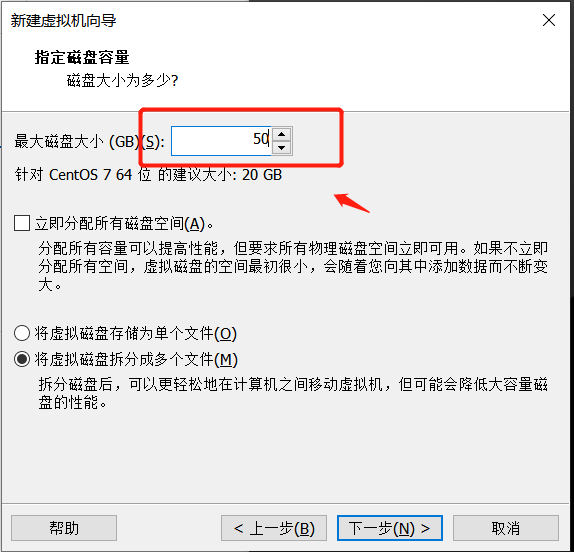
8个G的内存,建议虚拟机的磁盘空间设置为50G
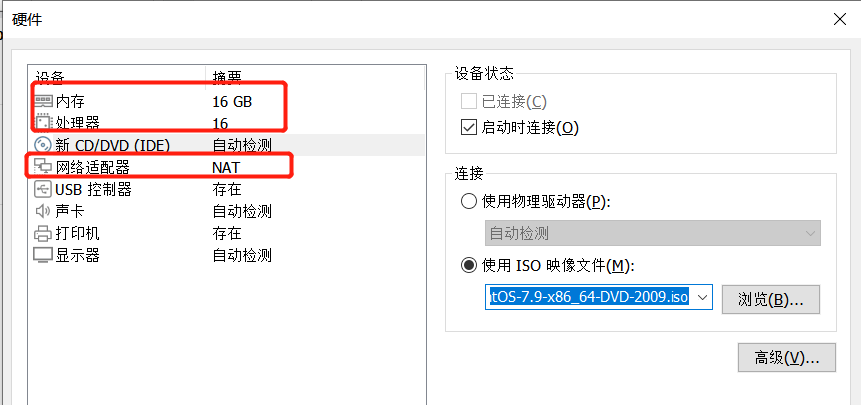
系统分区设置
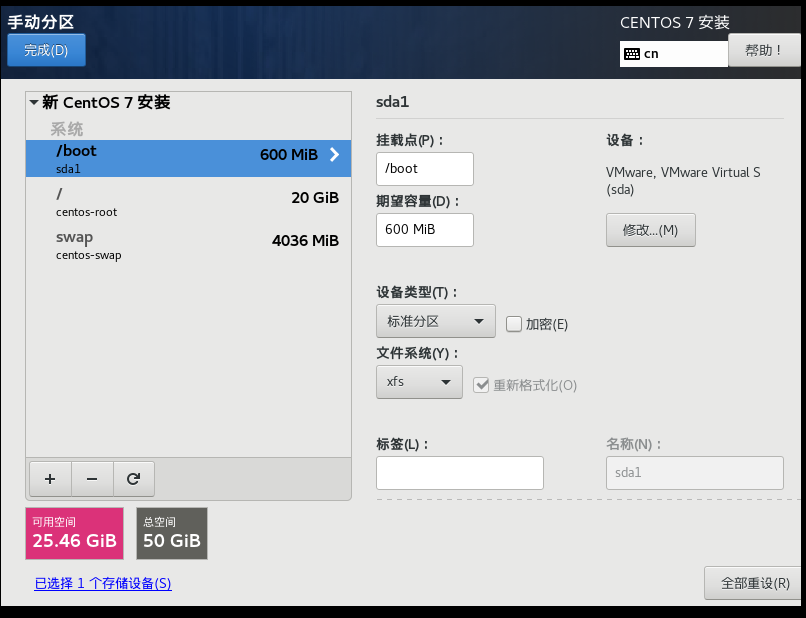
设置静态ip地址
虚拟机配置阿里镜像
使用wget从指定的路径下载镜像文件
[root@localhost ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo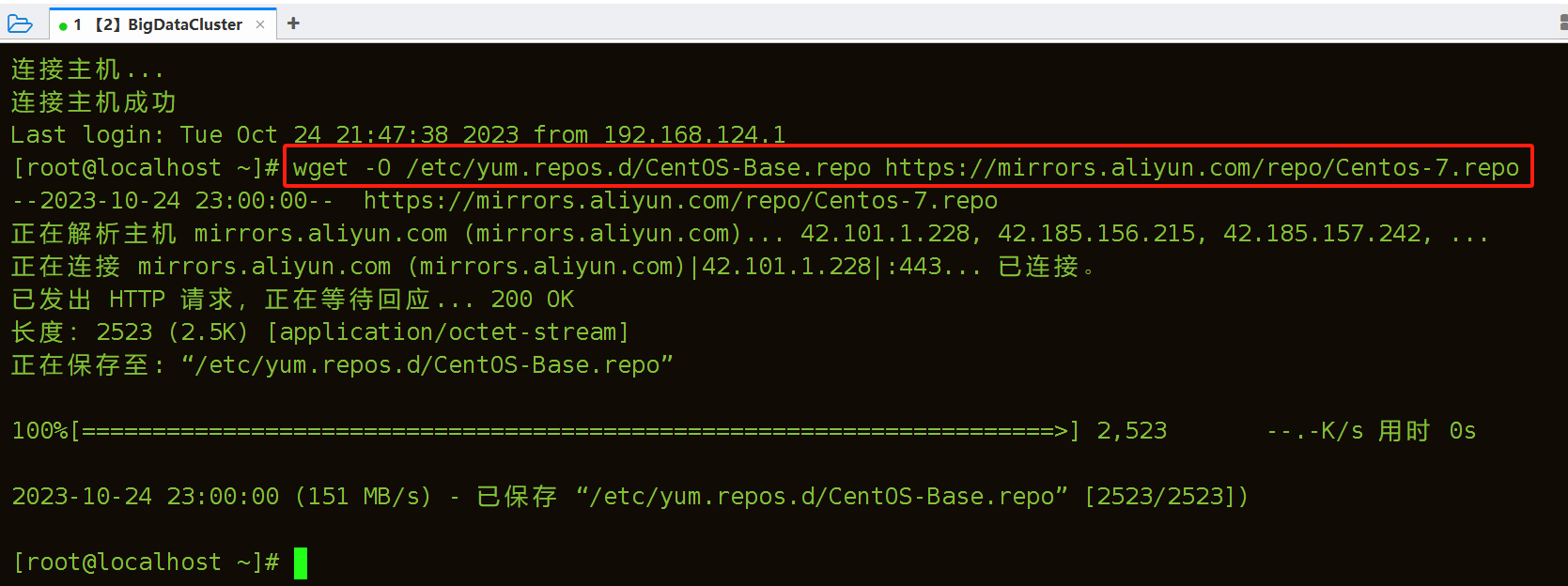
更新虚拟机上的软件包,更新过程中有两次输入y,总更新文件数625个,所以如果你虚拟硬盘空间不够,就先别操作了
注意:
yum update是yum命令的一个选项,用于更新系统中的所有已安装的软件包到最新版本。
当执行yum update命令时,yum会先检查可用的软件包,确定哪些软件包需要更新,并将它们的最新版本下载到系统中。这个过程中,yum会自动检查所有软件包的依赖关系,并在必要时同时更新依赖关系。更新完成后,yum还会重新配置系统中的软件包,以确保它们都能够正常工作。
yum update的底层原理是基于yum的软件包仓库的工作原理,yum会从远程的yum软件包仓库中获取软件包的信息,包括软件包的版本、依赖关系等,并与本地系统上已安装的软件包进行比较,确定需要更新哪些软件包。更新软件包的过程中,yum会在本地缓存中保存软件包,以便在需要时再次使用,以减少下载时间和网络流量。
yum update的好处是可以方便地更新所有已安装的软件包,以保证系统的安全性和稳定性。但需要注意的是,更新软件包可能会带来一些风险,例如更新后可能会出现兼容性问题,因此在更新之前最好备份系统或测试更新效果,以避免数据丢失或系统崩溃等问题。
[root@localhost ~]# yum update
.......中间执行过程省略,625行太多了
......中间执行过程省略,625行太多了
3、安装Docker
先删除docker,执行以下脚本
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
docker的安装步骤参考我站内帖子的步骤,此处不在演示,链接如下:
4、拉取镜像
(1)搜索镜像hadoop的基础集群镜像
[root@localhost ~]# docker search hadoop-base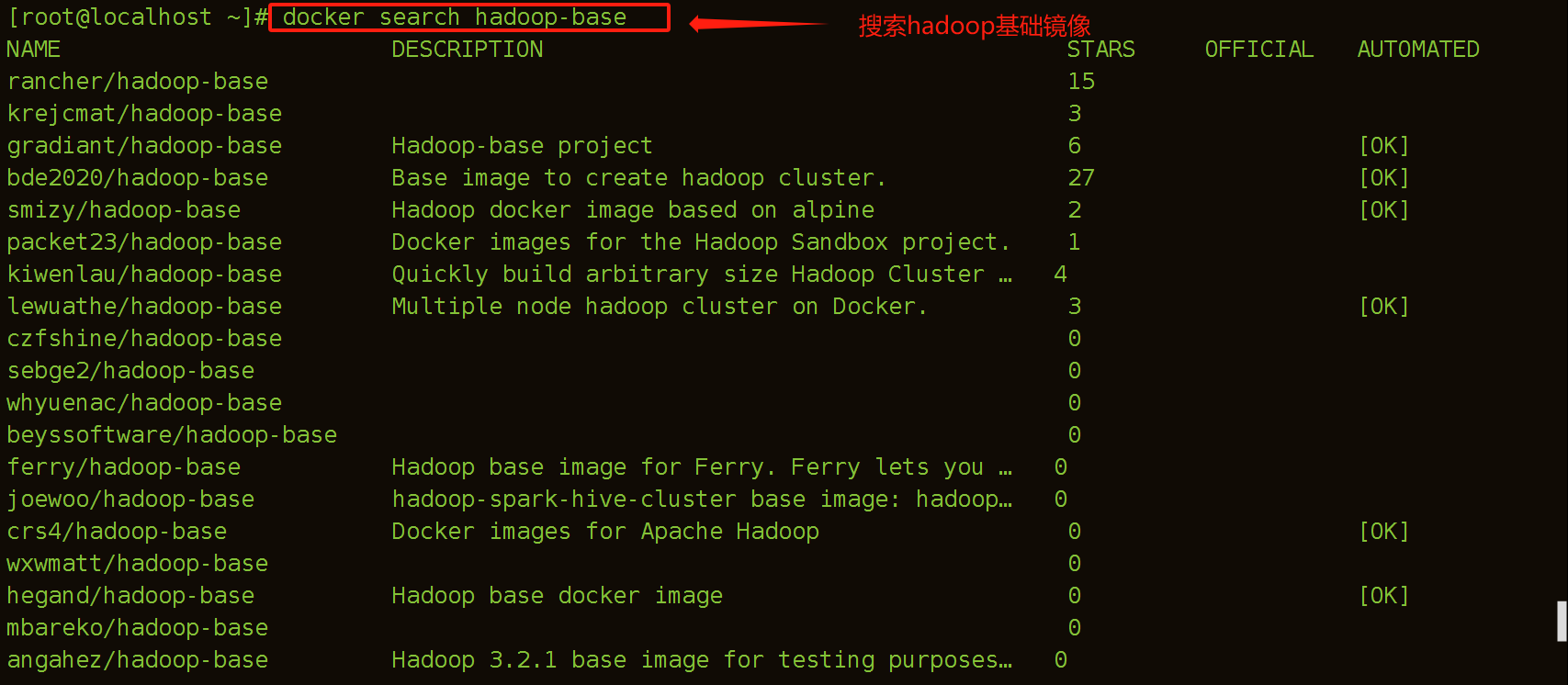

(2)拉取镜像hadoop-base镜像
[root@localhost ~]# docker pull bde2020/hadoop-base:2.0.0-hadoop3.2.1-java8
(3)拉取hadoop-namenode镜像
[root@localhost ~]# docker pull bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
(4)拉取hadoop-datanode镜像
[root@localhost ~]# docker pull bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
(5)拉取hadoop-resourcemanager镜像
[root@localhost ~]# docker pull bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
(6)拉取hadoop-nodemanager镜像
[root@localhost ~]# docker pull bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8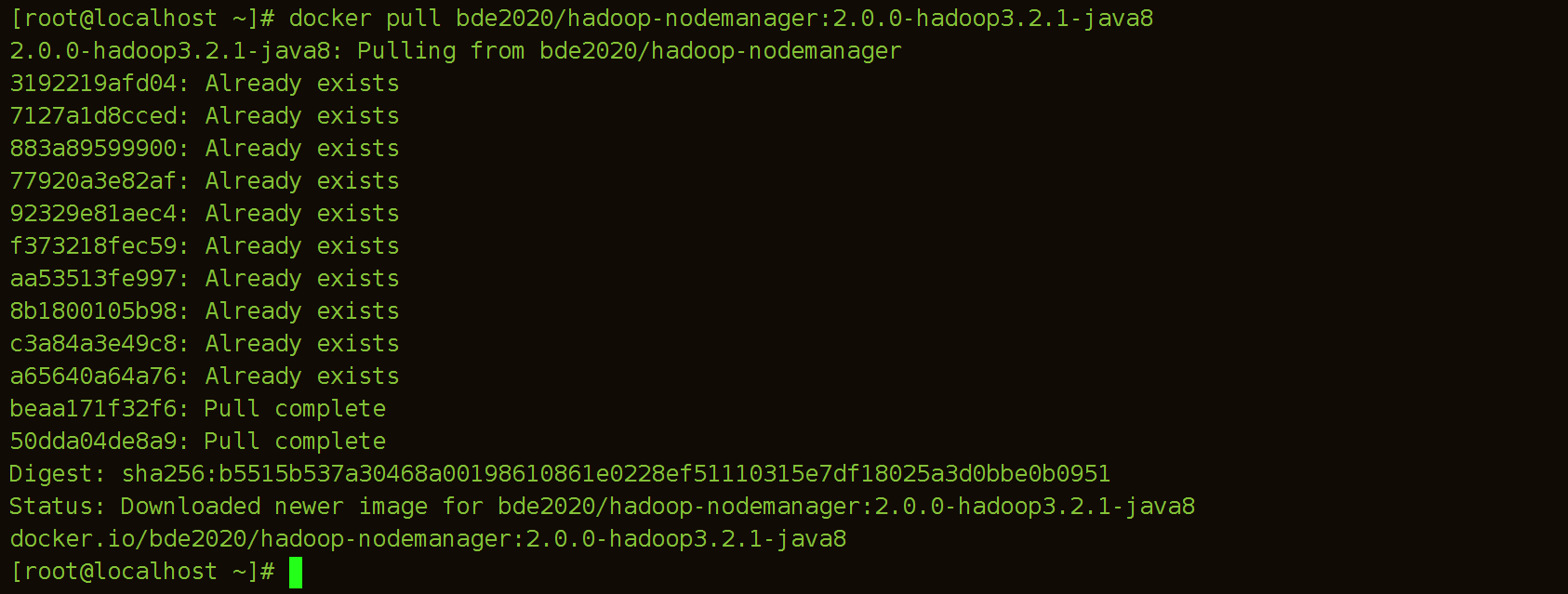
(7)拉取hadoop-historyserver镜像
[root@localhost ~]# docker pull bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8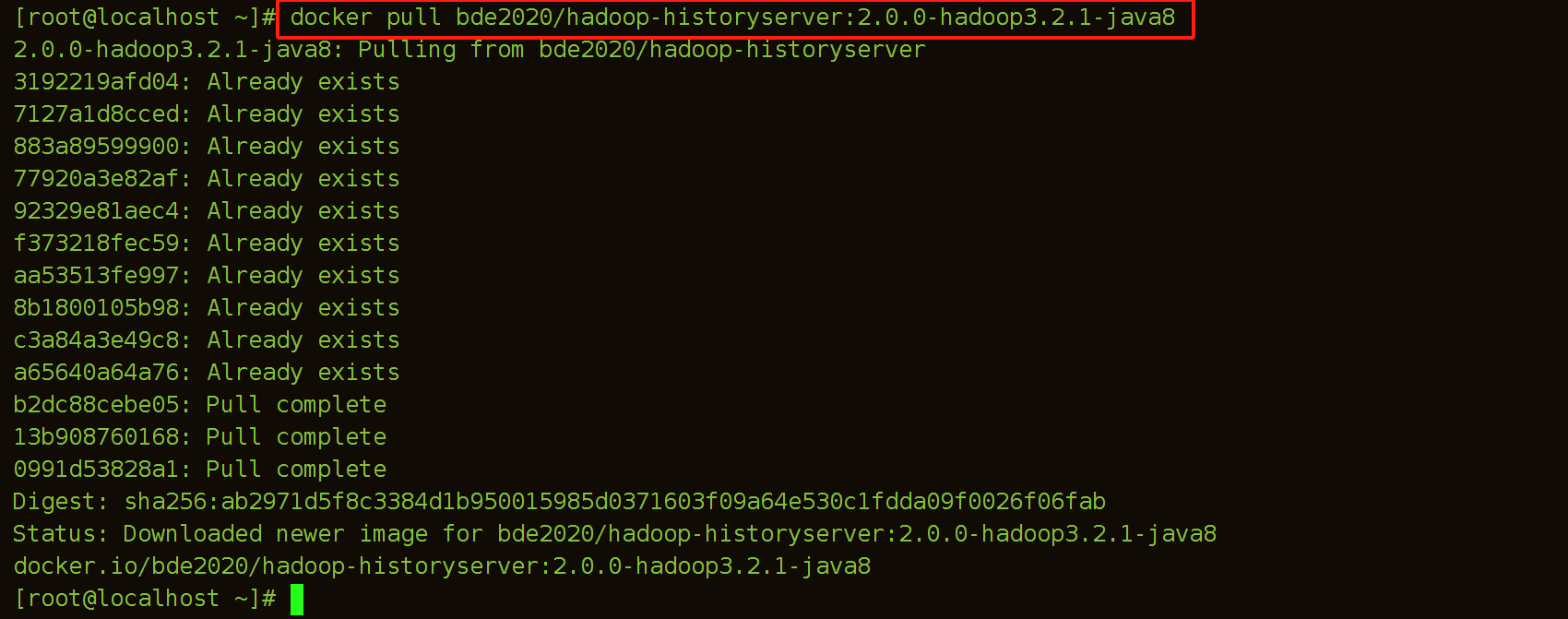
5.运行容器
(1)指定docker内部网络
查看子网ip地址和网关地址
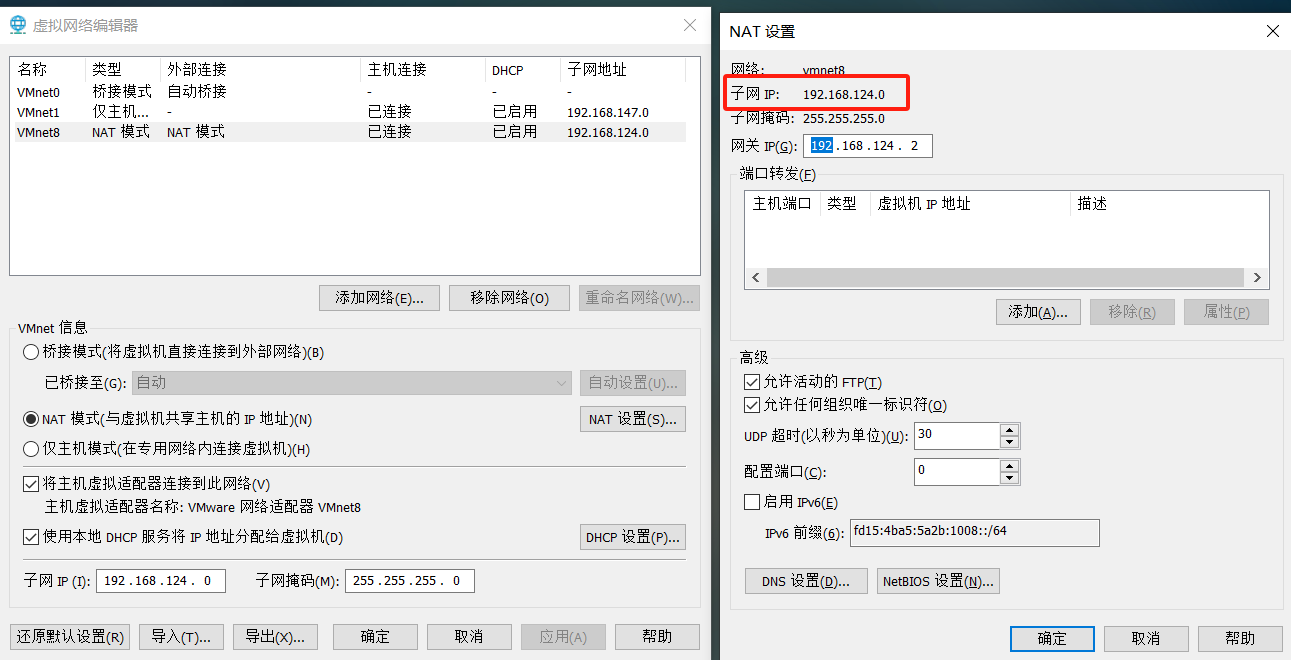
指定docker的桥接网络模式,docker网络是为了让容器和容器之前通信的
创建时最好指定容器端口号映射。10000端口为hiveserver端口,后面本地客户端要通过beeline连接hive使用,有其他组件要安装的话可以提前把端口都映射出来,毕竟后面容器运行后再添加端口还是有点麻烦的。
[root@localhost ~]# docker network create --driver=bridge --subnet=192.168.124.0/16 hadoop
要删除构建的网络可以通过docker network rm 网络名称
(2)建立Master容器
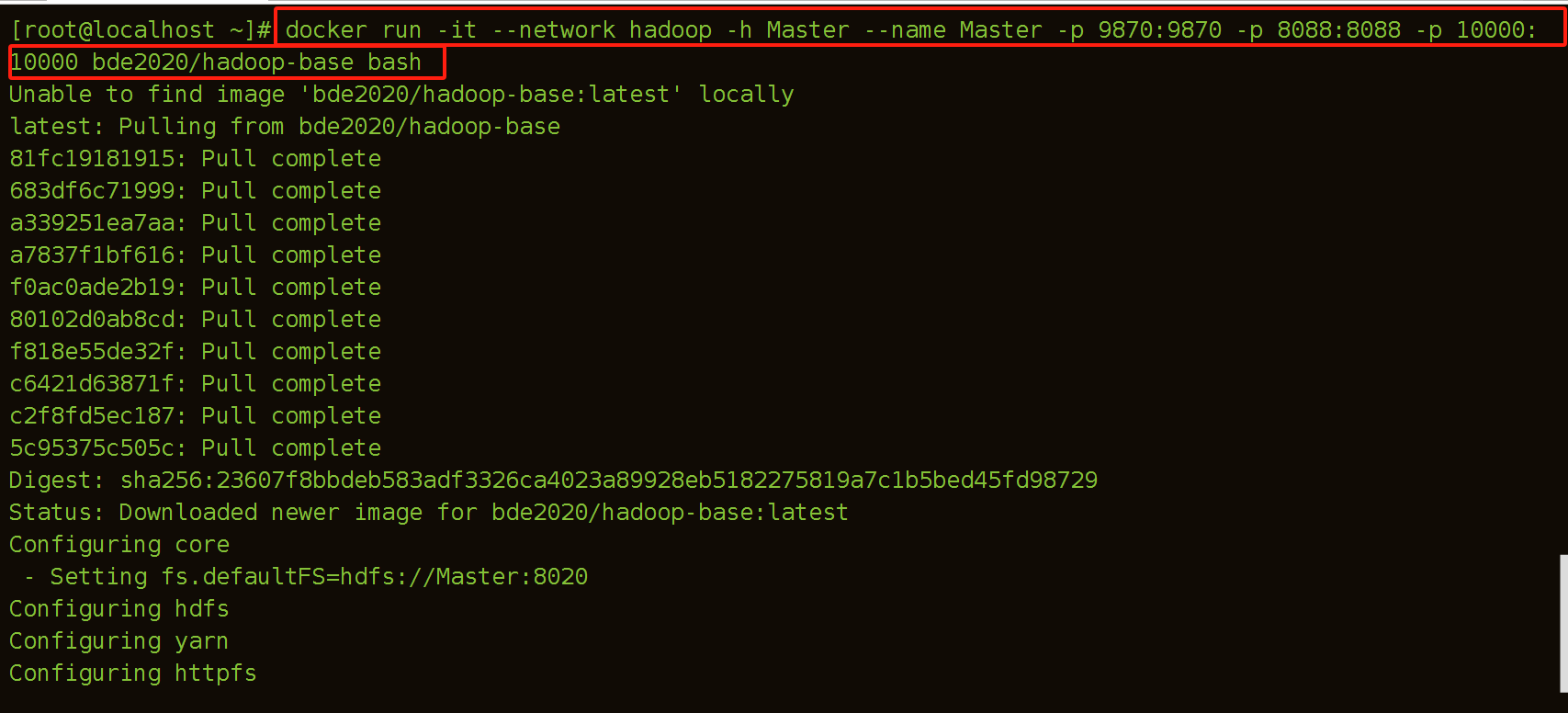
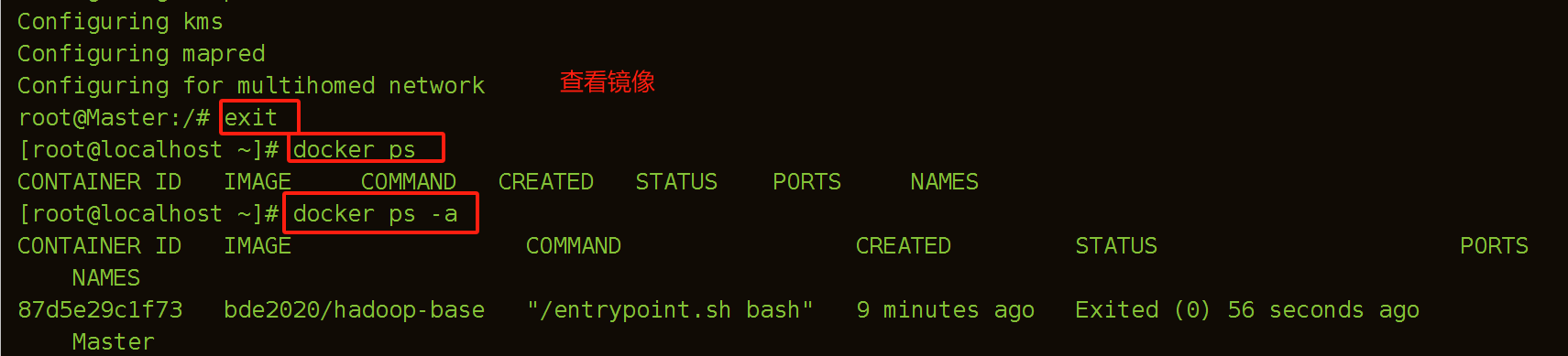
退出容器指令:ctrl+d
进入容器:docker exec -it 容器名 bash
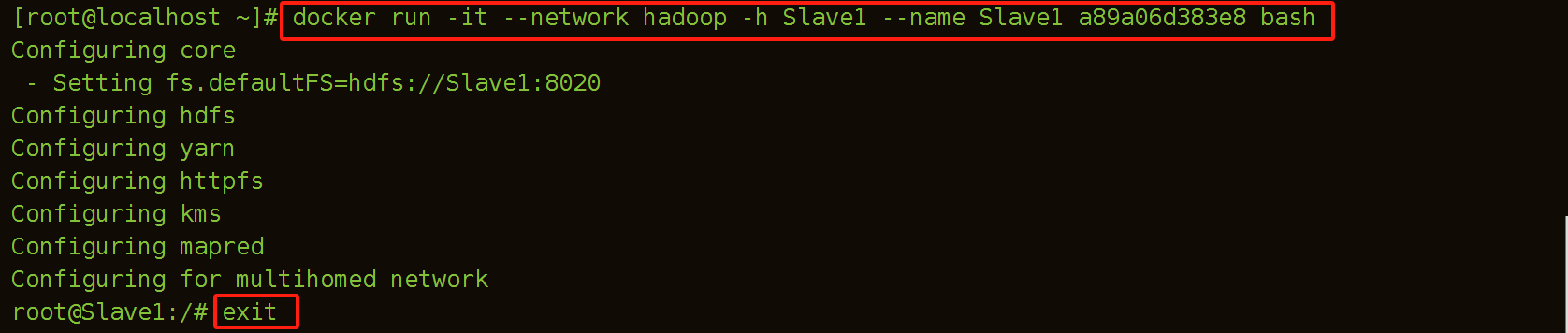
(3)建立Slave1容器
[root@localhost ~]# docker run -it --network hadoop -h Slave1 --name Slave1 bde2020/hadoop-base bash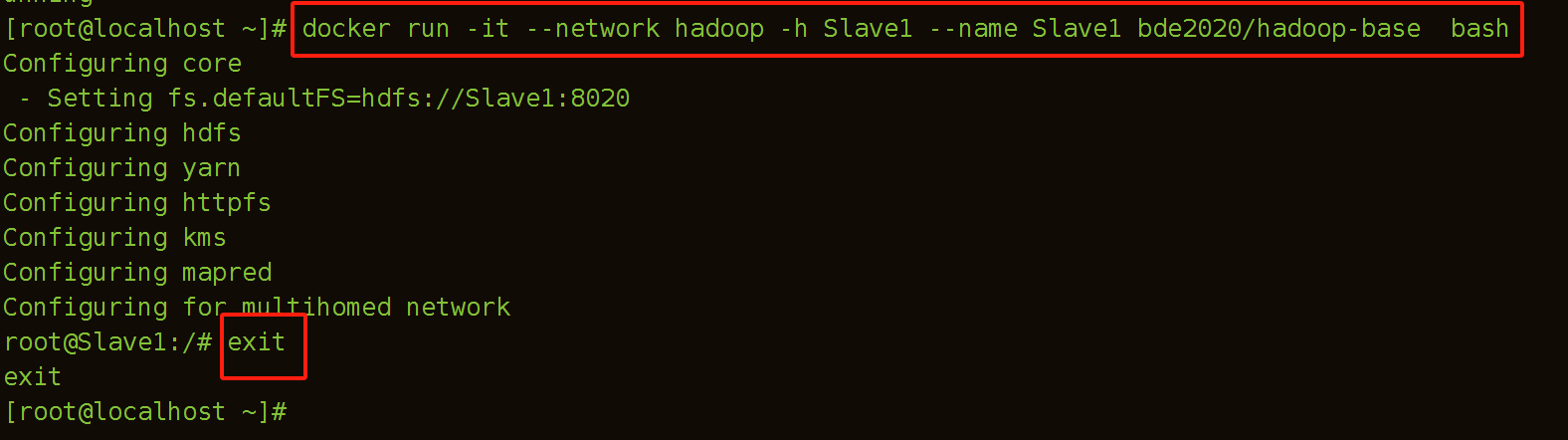
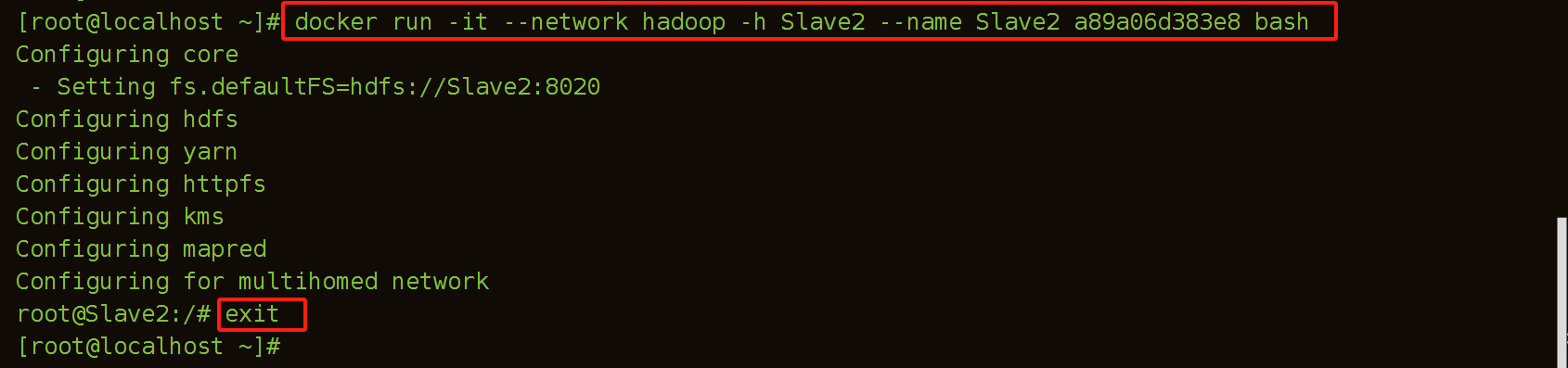
(4)建立Slave2容器
[root@localhost ~]# docker run -it --network hadoop -h Slave2 --name Slave2 bde2020/hadoop-base bash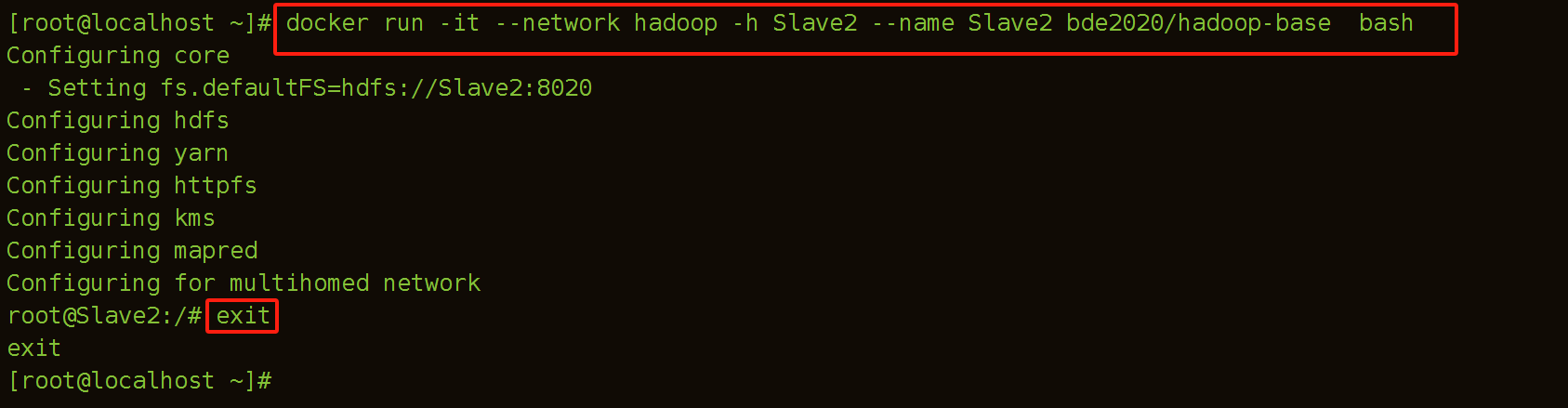
(5)查看所有构建的容器
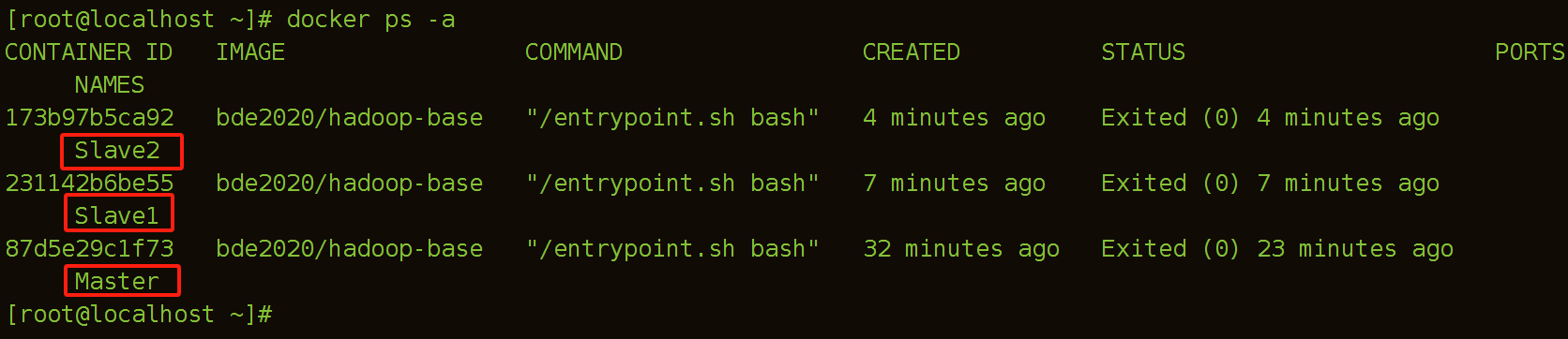
(6)三台机器修改hosts
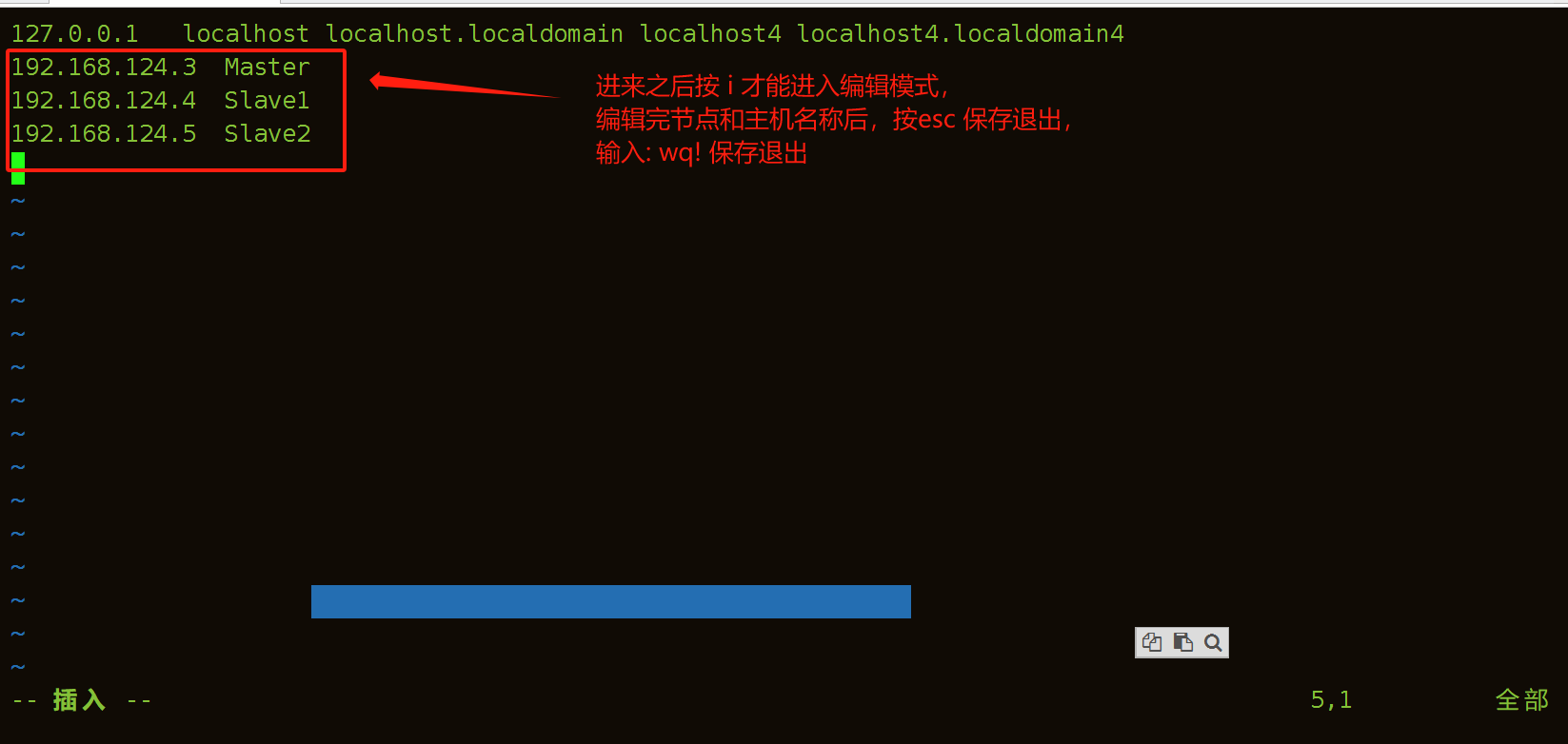
第一种脚本直接编辑方法:
[root@localhost ~]# vim /etc/hosts
//修改为以下格式
192.168.124.3 Master
192.168.124.4 Slave1
192.168.124.5 Slave2
第二种finalshell快捷工具编辑模式:
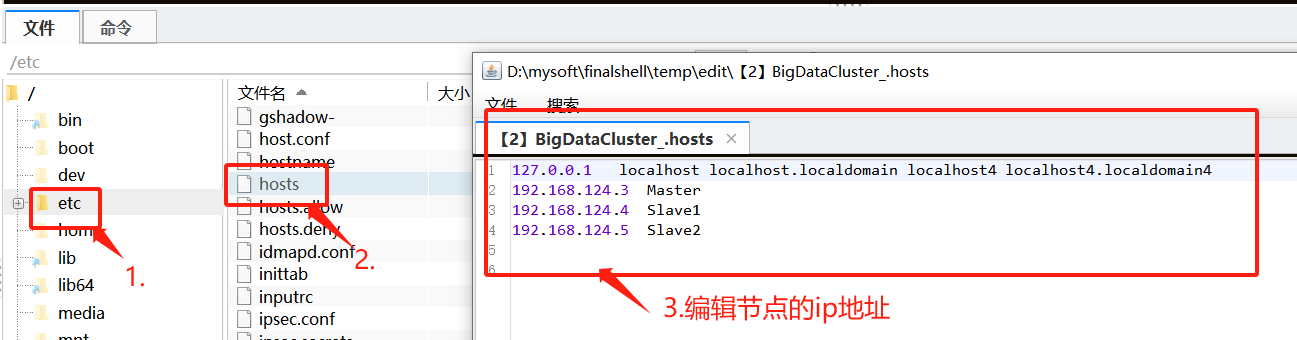
提示:每个容器的ip都需要通过命令ifconfig查看,或者在创建的时候通过‘ --ip ’指定ip地址
(7)查看运行中的容器
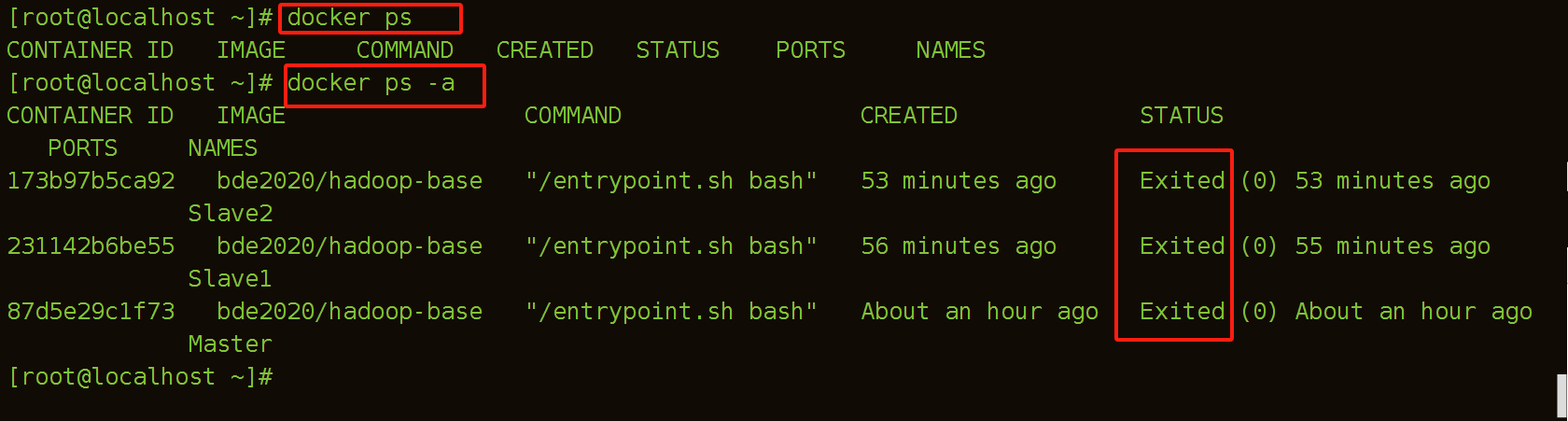
由于容器是退出状态,没有启动,因此我们可以先启动容器


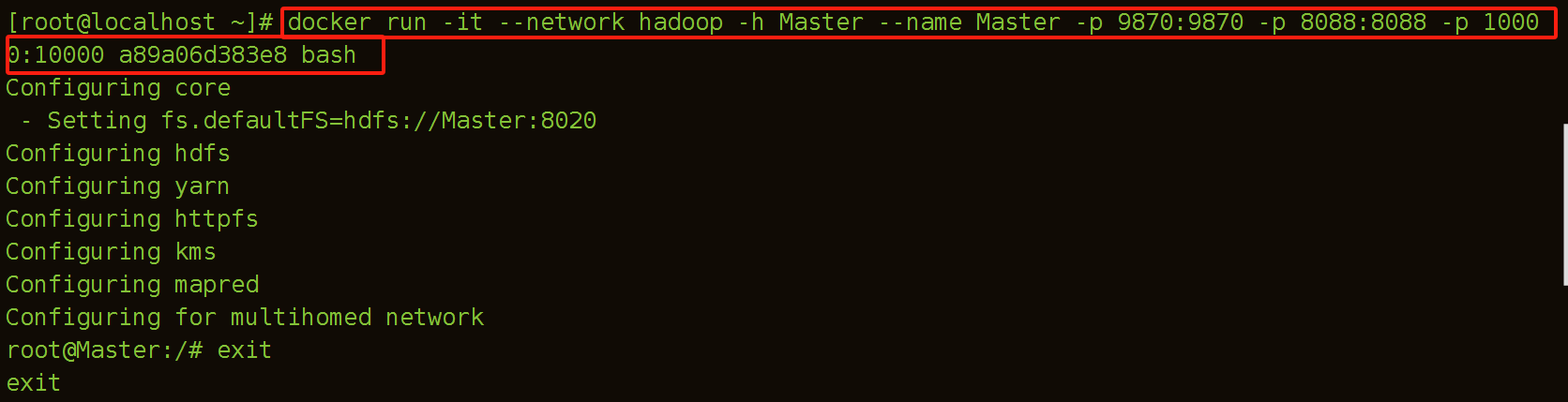


(8) 启动容器