

=============================================
这个论文保持着上世纪人工智能论文的特点,与其说是计算机类论文更不如说是偏生物科学方面的论文,这也可能是因为当时的人工智能的研究更加偏向于生物启发,
有些像Biology-Inspired Engineering。
这个论文是最古老的使用并结合计算机方法来进行研究的“元学习”算法之一的论文,可以说是元学习论文的始祖。
关于“元学习”一直没有太确定的定义,不过一般认为经过对多个学习任务的学习来提高对新任务的学习能力的方式叫做元学习;这其中也就包括了通过对其他任务的学习来提高对新任务的学习速度,也就是说通过对多个学习任务的学习提高算法对新任务的学习速度,这一点比较典型的场景就是小样本学习,这里只需要较少的新任务的样本进行1次或3、5次的学习就可以得到一个不错的性能表现,这里的主要特点就是对新任务的学习速度快;还有一种定义就是通过对多个任务的学习然后提高对新任务的学习能力的泛化性,这种的定义或者说是框架或者说是表现形式更注重对新任务的最终学习性能的表现。可以说上面两种对元学习的定义是极为相似的,区别就是对新任务的性能提升是体现上快速学习上还是最终的新任务的学习泛化性上,本blog介绍的这篇论文就是后者,对新任务的性能提升体现在新任务的最终学习泛化性上。
需要说明的是,由于该论文时间久远,很多论文细节已经不可考证,并且其中很多技术都已经被淘汰/不再被常用,不过这些并不重要,重要的是这篇论文所体现的元学习的思想。
=============================================
摘要:

内容:
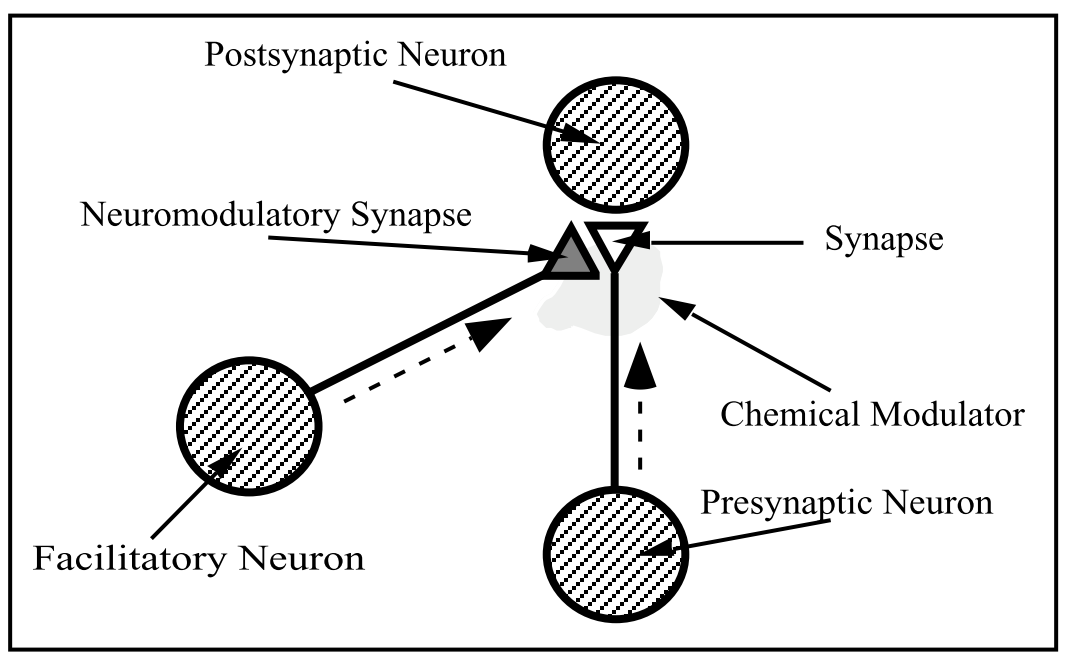
当时的神经网络训练很多都是采用Hebb规则进行训练,这也是MLP神经网络最原始的训练方法,当时的学术研究中类似的训练规则还有很多,其中也有当今最为常用的backward propogation,这个知识背景是preliminary。

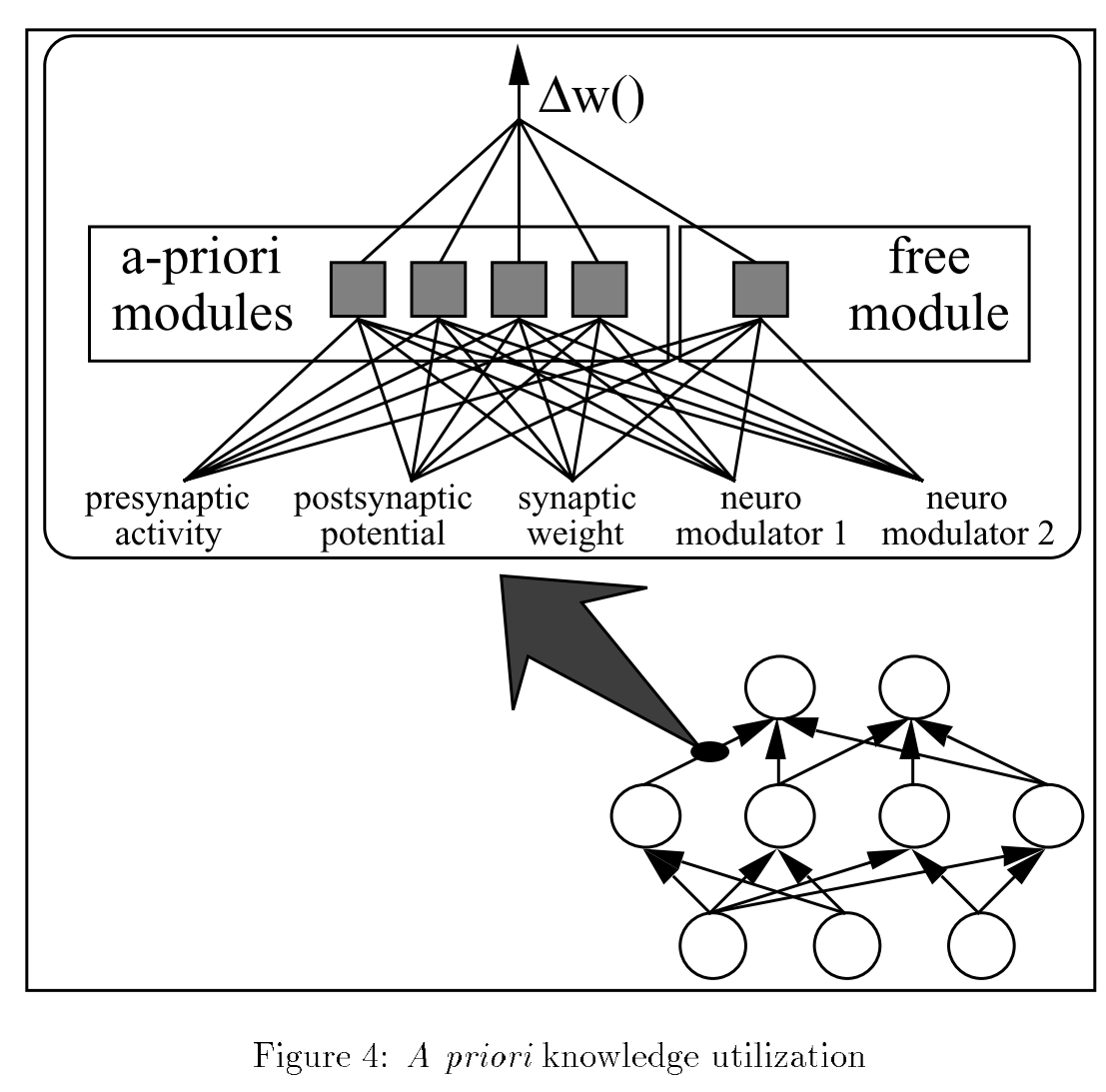
本文的一个想法就是现有的神经网络训练都是使用单一的训练规则,如Hebb规则,作者认为不同的学习任务应该有不同的训练规则,这种不同学习任务所具备的对应的学习规则应该可以用参数进行表示,这里使用θ参数,而该学习任务的神经网络使用参数x来进行表示,也就是说对新任务的训练不仅需要对其神经网络参数进行训练并且还要对其训练规则的参数进行训练。
biologically plausible synaptic mechanisms











=============================================





=============================================
元学习中每个学习的样本instance并不是一对输入和标签,而是一个学习任务task;直白的说,元学习就是要学习一套参数,这套参数通过对多个任务的学习过程中获得,然后把这套得到的参数放到新的任务上进行重新学习,然后使新的任务的学习性能得到提升。
元学习最直观的形式就是用一个比较大的task数来进行学习,比如用1000000个task,每次从中取32个task来进行minibatch训练,而模型结构采用标准的单任务情况下的形式即可,这样只要训练的task足够多,比如甚至远大于这里的1000000个tasks,那么这样训练出来的模型自然可以在新的任务上获得很好的性能表现,这也是该论文中所提及的,但是现实问题是在实际情况中我们往往没有这样足够多的相似任务来进行训练,在该篇论文的最后实验过程中往往也都只是使用了5个task,不过要注意,随着发展在现在的deep learning中我们可以轻松构建成千上万个相似任务。
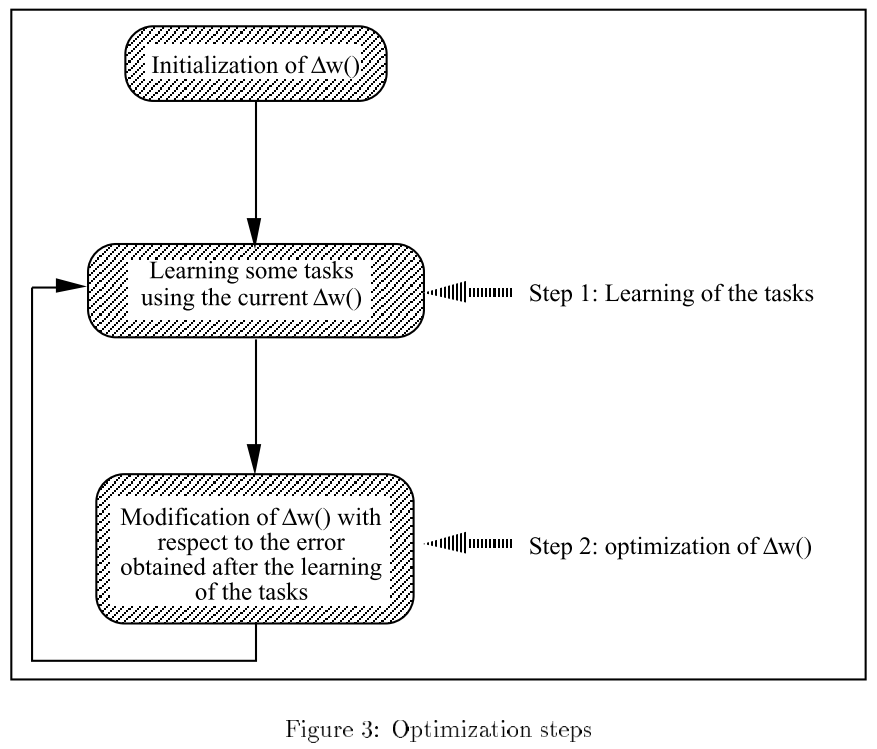
本篇论文中算法的实际流程是按照训练轮circle来进行的,这里也可以看做是一次迭代;这里假设使用5个任务tasks来进行元学习的训练,这里每次迭代开始时都采用5个相同结构的神经网络,每个task对应一个神经网络,在每次迭代开始时对这5个神经网络的参数进行随机初始化,然后每个task都单独进行训练,这里的训练规则使用的是多个Hebb类似的规则并使用θ参数进行线性组合后的更新规则,这样每个task单独进行一点次数的训练后其参数时关于θ参数的形式,这时候我们可以再对θ参数进行训练,同理,其他task也是如此的进行单独学习,先对自身神经网络参数进行训练,得到关于θ参数的神经网络参数,然后再对θ参数进行训练;最后在更新θ参数时使用这5个神经网络的θ参数更新均值。这里需要注意,在每次迭代的开始时都需要对5个task所对应的神经网络参数进行随机初始化,可以说在该文所提元学习的训练过程中5个task对应的5个神经网络的参数并不是所要计算的最终形式,这些神经网络参数只是临时使用的间接值,其目的就是为了训练更新规则中θ参数的。
通过该文所提方法训练出的θ参数可以很好的应用在新task上,在新task上这些θ参数可以作为初始值,采用元学习训练过程中的形式进行微调,即每次迭代时先使用θ参数的更新规则来更新新task的神经网络参数,然后根据更新后的关于θ参数的神经网络参数来对θ参数进行训练,采用该种方式进行对新task的训练时是不在首次迭代后对新task的神经网络参数进行初始化的。
该篇论文所提方法的一个假设就是对于不同的task应该有特定的更新规则,这样才对性能有利,从而通过对多个task的训练获得到一个θ参数的更新规则,将这个元学习训练得到的θ参数更新规则放到新的task上后可以使新task得到更好的性能表现:训练速度更快、最终泛化性能表现更优。
可以说,这篇始祖元学习论文所构建的scheme和现在的深度元学习也是相似的,并且该论文所体现的思想更贴近“元思想”,即通过对多个任务的学习获得到知识,从而对新任务有更好的性能表现。
=============================================