
此内容为机器翻译的结果,若有异议的地方,建议查看原文。
机器翻译的一些注意点,比如:
- 纪元、时代 => epoch
- 工人 => worker
- 火车、培训、训练师 => train
目录
高效的数据加载器,用于对大型图形进行基于采样的GNN快速训
Abstract 摘要
Introduction 介绍
Background and Motivation 背景和动机
2.1 Graph Neural Networks 图神经网络
2.2 Sampling-Based Training With GPU 使用 GPU 进行基于采样的训练
2.3 Problems and Opportunities 问题与机遇
PaGraph
3.1 GNN Computation-Aware Caching GNN 计算感知缓存
3.2 Data Parallel Training and Partition 数据并行训练与分区
3.3 Pipelining Data Loading and GNN Computation 流水线数据加载和GNN计算
Implementation 实现
Computation-Balanced and Cross-Partition Access Free Graph Partition 计算平衡和跨分区访问自由图形分区
Evaluation 评估
5.1 Experimental Setup 5.1 实验设置
5.2 Single GPU Performance 单显卡性能
5.3 Effectiveness of Caching Policy 缓存策略的有效性
5.4 Multi-GPU Performance 多显卡性能
5.5 Implications of Graph Partition 图分区的含义
5.6 Effects of Pipelining 流水线的影响
5.7 Impact of Data Loading Volumes 数据加载量的影响
5.8 Supporting Other Sampling Method 支持其他采样方法
5.9 Training Convergence 训练收敛
Related Work 相关工作
Discussion and Future Work 讨论和今后的工作
Conclusion 结论
ACKNOWLEDGMENTS
高效的数据加载器,用于对大型图形进行基于采样的GNN快速训
Abstract 摘要
新兴的图神经网络(GNN)已经将深度学习技术针对图像和文本等数据集的成功扩展到更复杂的图形结构数据。通过利用 GPU 加速器,现有框架将小批量和采样相结合,在大型图形上进行有效和高效的模型训练。但是,此设置面临可扩展性问题,因为通过有限的带宽链接将丰富的顶点特征从 CPU 加载到 GPU 通常会主导训练周期。在本文中,我们提出了PaGraph,这是一种新颖,高效的数据加载器,支持在具有多GPU的单服务器上进行通用且高效的基于采样的GNN训练。PaGraph 通过利用可用的 GPU 资源将经常访问的图形数据保存在缓存中,从而显著缩短了数据加载时间。它还体现了一个轻量级但有效的缓存策略,该策略同时考虑了基于采样的GNN训练的图形结构信息和数据访问模式。此外,为了在多个GPU上横向扩展,PaGraph开发了一种快速GNN计算感知分区算法,以避免数据并行训练期间的跨分区访问,并实现更好的缓存效率。最后,它重叠了数据加载和GNN计算,以进一步隐藏加载成本。使用邻接和层分两种采样方法对两个具有代表性的GNN模型GCN和GraphSAGE的评估表明,PaGraph可以消除GNN训练管道的数据加载时间,并在最先进的基线上实现高达4.8×的性能加速。结合预处理优化,PaGraph 进一步提供了高达 16.0× 的端到端加速。
Introduction 介绍
[1] [2] [3] [4] 被提出将深度神经网络从处理图像和文本等非结构化数据扩展到结构化图数据,并已成功应用于各种重要任务,包括顶点分类 [2] 、、、 [3] 链接预测 [5] 、 [4] 关系提取 [6] 和神经机器翻译 [7] .然而,一方面,像PowerGraph [8] 这样的传统图形处理引擎缺乏自动微分和基于张量的抽象。另一方面,当前流行的深度学习框架(如TensorFlow [9] )对顶点规划抽象和图运算原语的支持不足。为了弥合这两个领域之间的差距,提出了新的系统,如DGL,Python [10] Geometric,MindSpore [11] GraphEngine [12] 和NeuGraph [13]
[14] 组成。除了图形结构数据之外,与顶点和边关联的高维特征(通常范围为 300 到 600)会导致更大的计算和存储复杂性。在时间和资源的限制下,将一个完整的巨型图列车完全作为一个批次将不再有效,甚至不可行。因此,典型的做法是采样 [2] , , ,它重复从原始图中采样子图作为小批量的输入, [15] 从而减少单个小批量计算, [16]
[17] 。例如,我们观察到,当使用单个GPU在LiveJournal [18] 数据集上训练GCN [3] 模型时,74%的训练时间花在数据加载上。主要原因是,与海量数据相比,GNN模型通常使用计算复杂度相对较低的深度神经网络。因此,在 GPU 中执行的 GNN 计算比数据加载花费的时间要短得多。更糟糕的是,当一台机器中的多个GPU用于加速训练时,对从CPU加载到GPU的数据样本的需求成比例增长。一些优化的策略,如预处理 [19]
本文重点介绍如何在多 GPU 机器上加速基于采样的大型图形 GNN 训练。我们的关键思想是减少 CPU 和 GPU 之间的数据移动开销。这项工作主要基于以下观察。首先,由于在GNN计算中引用顶点和图结构,不同的训练迭代可能会使用重叠的小批量数据并表现出冗余的顶点访问模式。如下面的案例研究 ( Section 2.3 ) 所示,与目标图的顶点种群相比,它可以加载多达 4× 个纪元期间的顶点数。其次,在每次迭代中,训练计算只需要保留与当前小批量对应的采样子图,这只消耗一小部分(例如,不超过 10%)的 GPU 内存。因此,GPU 内存的其余部分可用于免费缓存最常访问的顶点的特征,避免从主机内存重复加载。但是,当前的数据加载器尚未探索备用GPU内存的可用性来实现它。
引入缓存以加速基于采样的 GNN 训练面临以下系统挑战。首先,由于采样性质的随机访问模式,很难预测下一个小批量中将访问哪些图形数据。我们没有预测下一次访问的图形数据,而是利用了具有较高出度的顶点具有更高的概率被采样到小批量中的事实。在此之后,作为我们的第一个贡献,我们采用静态缓存策略将经常访问的图形数据保存在 GPU 内存中,并引入了一种新的支持缓存的数据加载机制。当采样的小批量到达 GPU 时,将从本地 GPU 缓存和原始图形存储服务器管理的主机内存中获取所需的特征数据。
[20] 在两个方面 [21]
[22]
[23]
总之,我们做出了以下贡献:
- 对具有多GPU的单服务器上基于采样的GNN训练的分析表明,训练性能已成为数据加载的瓶颈。
- 一种新颖的数据加载器 PaGraph,用于合并静态 GPU 缓存,从而减少从主机内存运送到 GPU 的数据量。通过 (1) 分区图以利用更好的数据局部性进行多 GPU GNN 训练,以及 (2) 流水线数据加载和 GNN 计算,从而减轻 GPU 缓存和计算之间潜在的 GPU 内存争用,进一步提高了其缓存效率。
- 与DGL(最先进的GNN库)相比,对PaGraph进行了深入评估,包括两个具有代表性的GNN模型和七个真实世界的图形。
- 对PaGraph的局限性、应用范围、泛化机遇和挑战以及未来方向进行了富有远见的讨论。
Background and Motivation 背景和动机
2.1 Graph Neural Networks 图神经网络
在这项工作中,我们以属性图为目标,除了图结构信息外,顶点或边还与大量特征(通常超过数百个)相关联。GNN 模型通常由多个层组成。 Fig. 1 显示了两层 GNN 模型的体系结构,其中蓝色和绿色分别表示第一层和第二层。
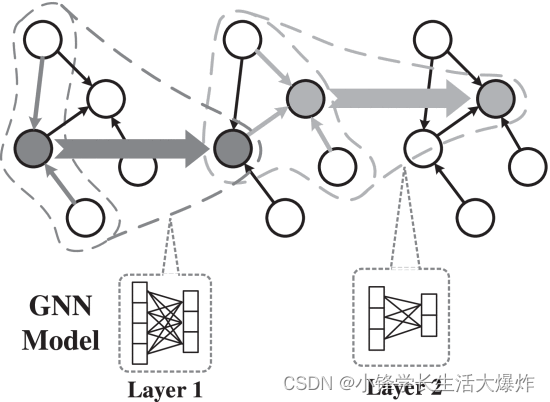
[8] 。 [24] 在每一层,每个顶点都遵循其传入的边来聚合来自邻居的特征(细箭头),然后使用神经网络将特征转换为输出特征(粗箭头),输出特征将作为输入特征 [2] 馈送到下一层。在同一层中,所有顶点共享相同的聚合神经网络和转换神经网络。单个GNN层只能实现从直接(1跳)邻域顶点传递的信息。对于 2 个 GNN 层,通过将前一层的输出作为输入摄取到下一层,我们可以连接 2 跳邻居。同样,在 L 层 GNN 中,顶点可以从 L 跳中的邻居收集信息。最后一层的输出可用于增强顶点分类 [2] 等任务, [3] 或用作关系提取 [6]
2.2 Sampling-Based Training With GPU 使用 GPU 进行基于采样的训练
训练GNN模型以达到理想的精度通常需要几十个epoch,每个epoch都定义为对目标图的所有训练顶点进行完全扫描。纪元由一系列迭代组成,在每次迭代期间,将随机选择一小批训练顶点来评估和更新该模型。但是,与每个数据样本都是独立的图像和句子等训练数据不同,图形数据是高度结构化连接的。因此,在顶点上进行训练不仅需要加载顶点相关数据,还需要加载其链接边和连接顶点的数据,这使得GNN中的数据加载与传统的机器学习训练有很大不同。
[2] [15] [16] . [19]
[23] [9] 和MXNet [25] ,使其成为深度学习训练的事实标准加速器。GPU 由大量强大的处理器和高带宽专用 GPU 内存组成,是执行张量相关计算的绝佳选择。因此,现有的GNN库(如DGL)遵循相同的实践,使用GPU进行训练加速。我们的实验表明,当通过LiveJournal [18] 数据集训练GCN [3]
Fig. 2 绘制了基于 GPU 的基于采样的 GNN 训练的工作流程。有一个全局图形存储服务器,它管理完整的图形结构以及CPU内存中的特征数据。每次训练迭代都涉及三个主要步骤,即采样((1))、数据加载((2)-(3))和模型计算((4))。在每次迭代中,数据采样器随机收集训练顶点的数量(小批量大小),然后遍历图形结构并对其 L-hop 邻居顶点进行采样以形成输入数据样本 ((1))。作为采样方法中的代表性示例,邻域采样 (NS) [2] 只是从当前访问的顶点中选取少量随机邻域。例如,在 2 个相邻采样中,如 所示 Fig. 3 ,对于训练顶点 v1 ,它 v2,v5 从其 1 跳入的相邻点中进行选择。然后,它 v6,v2,v9,v8 从选定的 1 跳顶点 v2,v5 的直接邻居中采样 2 跳内邻居。数据加载步骤为 GPU 计算准备特征数据。在这里,我们要强调的是,数据加载不仅仅是通过 PCIe 将数据从 CPU 传输到 GPU。相反,数据加载过程经历以下两个阶段。数据加载器选取一个小批量并查询图形存储以从该批次中收集所有顶点的特征 ((2)),并通过 PCIe 链接将这些样本加载到 GPU 内存中 ((3))。最后,CPU 上的训练器启动 GPU 内核,在加载的数据样本上在 GPU 上执行 GNN 计算 ((4))。该过程将迭代运行,直到目标模型收敛。
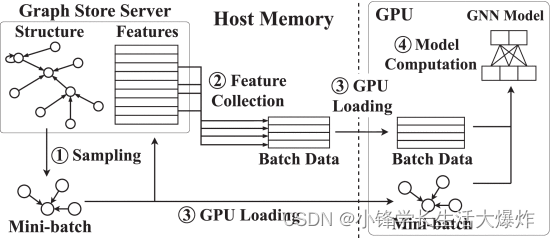
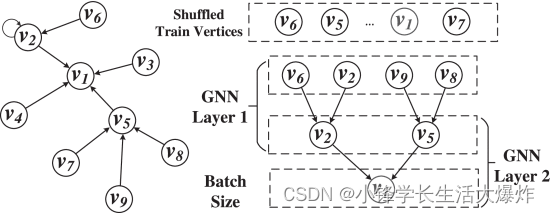
2.3 Problems and Opportunities 问题与机遇
[3] 作为我们的演练示例。我们使用广泛使用的邻居采样和逐层采样 (LS) [15] 为每个训练迭代创建小批量顶点。LS 与 NS 几乎相同,只是它将一个层视为一个整体,并限制每层而不是每个顶点的采样顶点总数,从而避免采样顶点的数量随着层的加深呈指数增长。正如现有工作 [15] 所建议的那样, [19] 这里的邻域采样方法为每个顶点选择 2 个邻域,而逐层采样方法将每层采样的顶点数限制为 2,400。如下,我们报告了我们对性能效率低下的主要观察结果,并揭示了它们的根本原因,这些原因共同激励了我们的工作设计。我们从流行的 DGL 库 [26]
[18] 、lj-large [27] 和 enwiki )的实验中 [22] ,我们发现从 CPU 到 GPU 的数据加载通常主导端到端 GNN 训练时间。在实验中,我们采用了具有代表性的GNN模型,即2层GCN [3] ,并使用广泛使用的邻域采样和逐层采样 [2]
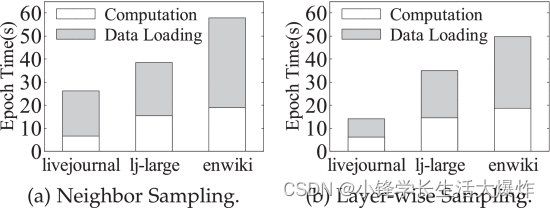
通过对结果的深刻理解,我们确定了以下严重减慢整个培训过程的因素。同时,它们还为我们提供了进一步提高基于 GPU 采样的 GNN 训练性能的机会。
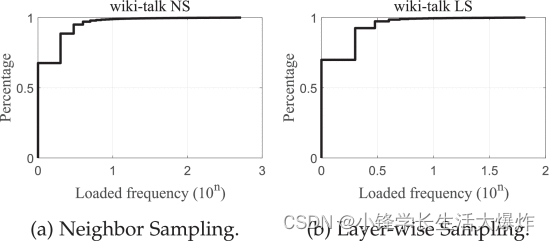
冗余顶点访问模式。我们继续了解从 CPU 发送到 GPU 以完成训练周期的数据总量。令人惊讶的是,加载的数据量可以超过我们实验中目标图顶点总数的 4×。这表示某些顶点被多次加载。为了验证这一点,我们收集不同训练作业的顶点访问跟踪,并计算每个顶点的访问次数。 Fig. 5 是一个 CDF 图,用于使用 NS 和 LS 采样方法时,用于在 wiki-talk 图上训练 GCN 的加载顶点的访问频率。我们观察到超过 32.4% 的顶点被重复使用了多达 519 次。这种冗余的顶点访问模式加剧了数据加载负担,并为每个纪元创建数十 GB 的数据加载。我们进一步发现,这些顶点比其他不常访问或未访问的顶点具有更高的出度。这是因为图中具有高出度的顶点可能与多个火车顶点相连,使其有机会被不同的小批量多次选择。
基于这一观察结果,我们得出了一个启示,即在GPU内存中缓存高出度顶点的特征信息将减少从CPU到GPU的数据加载量,从而加速基于采样的GNN训练。但是,这种优化会带来一些挑战,例如将 GPU 内存与 GNN 计算竞争,产生维护此类缓存的开销等。
GPU 资源未充分利用。由于数据加载阶段先于 GPU 训练阶段,因此我们进一步探讨了数据加载瓶颈的负面影响。我们总结了两个GNN模型(GCN和GraphSAGE)正在训练的资源利用率 Table 1 。令人惊讶的是,无论采用何种采样方法,GPU上只有一小部分计算和内存资源被利用。例如,使用邻居采样时,只有大约 20% 的 GPU 计算资源在使用中,内存消耗更少,例如不到 10%。这是因为 CPU 发送到 GPU 的小批量数据不足以充分探索 GPU 中的硬件并行性。同时,GPU 处于空闲状态,等待训练数据样本在大多数时间到达。

这一观察结果促使我们考虑利用备用 GPU 资源来缓存经常访问的顶点的特征信息,以便尽可能便宜地重复使用。从理论上讲,这种缓存解决方案可以消除应该收集并从CPU发送到GPU的特征信息量,从而消除基于采样的GNN训练中的CPU特征收集和PCIe数据传输瓶颈。
采样和特征收集之间的 CPU 争用很高。然后,我们分解了在数据加载过程的不同阶段所花费的时间,发现特征收集阶段是 CPU 密集型的,并且比 CPU-GPU 数据移动花费的时间要长得多。例如,对于三个使用的数据集,它分别占总数据加载时间的 50.4%、55.1% 和 56.3%。这个令人惊讶的结果导致:(1)使用单个GPU,我们实现了最大约8 GB / s的PCIe带宽利用率(容量为16 GB / s),而平均利用率较低;(2)对于多个 GPU,用于收集特征的并发工作线程将与采样器争用 CPU 资源,例如,采样和特征收集的时间分别比 1-GPU 情况增加了 88% 和 59%,而 GPU 计算时间保持不变。在 4-GPU 情况下,最大 PCIe 带宽利用率下降到一半,平均值甚至更糟。这表明 CPU 容量无法应对 GPU 计算需求,因为每次迭代都需要大量数据。因此,为了降低特征收集成本,我们必须考虑减少在此阶段应收集的数据量,以及隔离采样和特征收集的资源分配。
数据加载和GNN计算的顺序执行。使用占主导地位的库 DGL,尽管数据加载消耗 CPU 和 PCIe,并且 GNN 计算被调度到 GPU,但它们仍然以串行顺序执行。DGL不会利用训练管道中的两个阶段来重叠,主要是因为数据加载主导了整个训练空间,GNN计算运行得更快。然而,在我们的工作中,采用缓存会显著影响训练管道,因为它降低了数据加载成本,同时随着更多的数据样本被馈送而增加了计算密度。因此,新情况为我们提供了管道数据加载和GNN计算的机会,以将一个人的成本隐藏到另一个人的成本中,反之亦然。这种管道设计还引入了积极的效果,可以在面对大型图形时提高缓存效率,因为它可以减少需要在 GPU 内存中缓存的数据量。
PaGraph
在实验 Section 2.3 结果的激励下,我们提出了PaGraph,一种新颖,高效的数据加载器,可以在大型图上进行基于快速采样的GNN数据并行训练。我们向PaGraph介绍了三种关键技术:1)GNN计算感知缓存机制,用于减少从CPU加载到GPU的数据,2)缓存友好的数据并行训练方法,用于在多个GPU上扩展GNN训练,以及3)两阶段训练管道重叠数据加载和GNN计算。
Fig. 6 显示了 PaGraph 的整体架构。对于具有 GPU 的 N 单台计算机,整个图形被划分为 N 子图形。这些分区的图形结构信息以及顶点特征数据存储在 CPU 共享内存中的全局图形存储服务器中。有 N 独立的培训师。每个训练器负责在专用 GPU 上训练计算。它复制目标 GNN 模型,并且仅使用自己的数据分区。每个 GPU 都包含一个缓存,用于保存经常访问的顶点的要素。
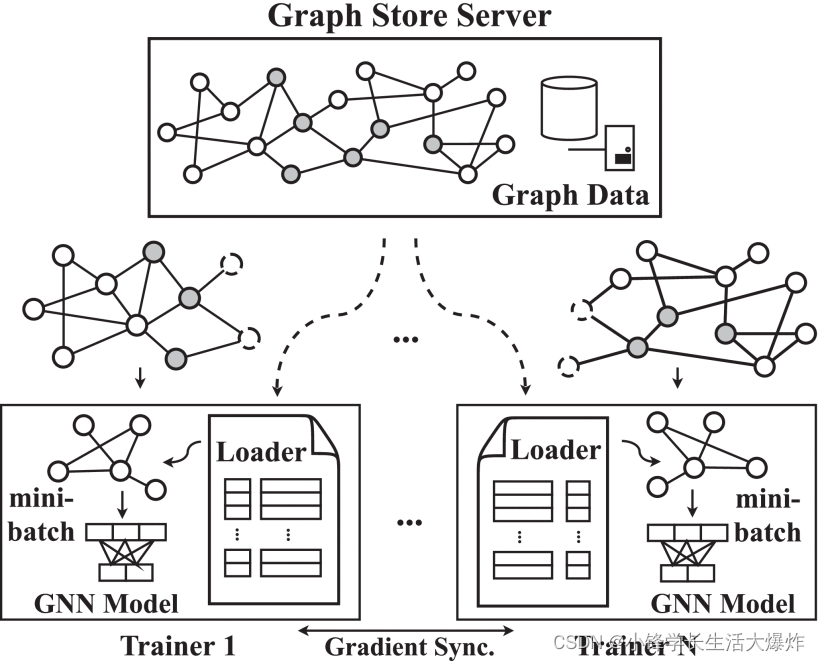
在每次训练迭代期间,每个训练器都会收到采样器生成的小批量的图形结构信息。如 所示 Fig. 7 ,它还通过直接从自己的 GPU 缓存中获取(如果缓存)的关联顶点要素(标记为绿色)或查询 Graph Store 服务器以查找缺失的要素(标记为黄色)来获取数据加载器收集的关联顶点要素。前一种情况节省了从 CPU 到 GPU 的数据复制开销,而后一种情况则不能。之后,该小批量的结构数据以及缓存和加载(来自主机)的顶点特征被馈送到GNN模型中以计算梯度。训练器之间除了在每次迭代结束时同步本地生成的梯度以更新模型参数外,不会相互交互。
3.1 GNN Computation-Aware Caching GNN 计算感知缓存
缓存策略。为了生成更好的模型,对于每个纪元,大多数训练算法都需要随机洗牌的训练样本序列,这使得无法在运行时预测每个小批量中的顶点。顶点的邻居也是随机选择的,因此在训练期间也是不可预测的。因此,很难预测哪个顶点最有可能在下一个小批量中被访问。但是,由于邻域采样方法的独特访问模式,顶点的出度表示在整个纪元中被选中的概率。这表示,随着出度越高,顶点更有可能是其他顶点的邻域,因此更有可能以小批量进行采样。因此,用高出度顶点填充缓存就足够了。
[1] 的,因此CPU内存和GPU内存之间的图形数据交换在训练期间具有无法忍受的开销(请参阅 Section 2.3 )。因此,我们不是即时决定要缓存的内容,例如 LRU [28]
缓存空间。为了避免高优先级训练计算的资源争用,我们需要估计缓存分配的最大可用 GPU 内存量。为了实现这一目标,我们利用了内存消耗在训练迭代中相似的事实。这是因为基于采样的小批量训练使用几乎相同数量的数据样本作为输入,并执行几乎相同的计算量来训练每次迭代的共享GNN模型。因此,通过对 GPU 内存使用情况进行一次性采样来确定正确的缓存大小就足够了。更详细地说,在第一次小批量训练之后,我们会在训练期间检查可用 GPU 内存的大小,并相应地分配可用的 GPU 内存来缓存图形数据(有关更多详细信息,请参阅 Section 4 )。
数据管理。在 GPU 缓存中,我们通过维护两个单独的空间来管理缓存的顶点要素。首先,我们为特征数据分配连续的内存块。顶点的缓存要素数据被组织为几个大 [N,Ki] 矩阵,其中 N 表示缓存顶点的数量, Ki 是 i 第绪个要素名称字段下的要素维度。其次,为了实现快速查找,我们将顶点元数据组织到一个哈希表中,以回答查询的顶点是否被缓存以及它的位置以供以后检索。元数据远小于缓存的特征数据,例如,对于具有 1000 万个顶点的分区,不超过 50 MB。
[8] [30] [29]
3.2 Data Parallel Training and Partition 数据并行训练与分区
[26]
[8] ,, [20] [21]
计算平衡。若要在不同训练器之间实现计算平衡,所有分区都应具有相似数量的训练顶点。假设我们需要 K 分区。我们扫描整个火车顶点集,并迭代地将扫描的顶点分配给其中一个 K 分区。在每次迭代中,一个训练顶点被分配一个维度分数向量 t ,其中第个元素表示将顶点 vt 分配给 i i 第1个分区的可行性 i∈[1,K] 。 K 分数由方程计算。 (1)
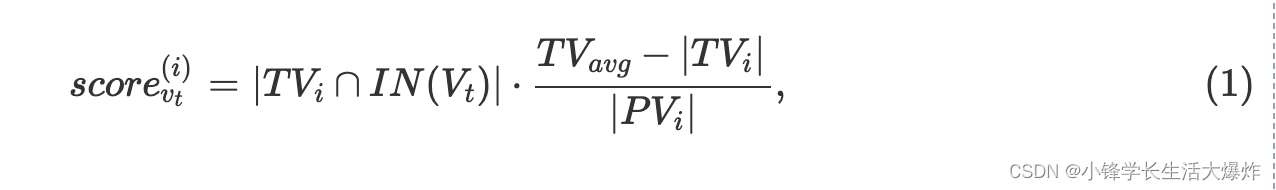
TVi 表示已分配给 i 第 th 个分区的训练顶点集。 IN(Vt) 表示火车顶点的 L -hop 邻域集 vt 。 PVi 控制工作负载平衡,并表示 i 第 th 分区中的顶点总数,包括复制的顶点。 vt 最有可能分配给具有最小 PV 的分区。 TVavg 是最后一个 i 分区中预期的火车顶点数。为了实现计算平衡,我们设置为 TVavg |TV|K ,这表示所有分区将获得几乎相同数量的训练顶点。
[31]
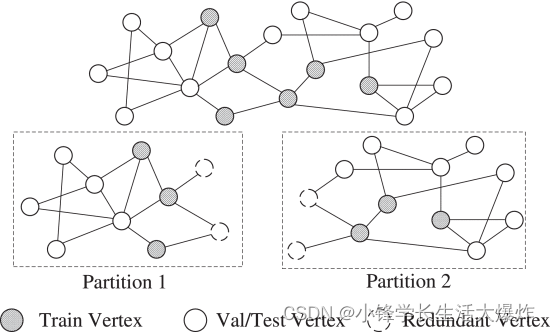
对于每个分区,PaGraph 使用冗余顶点和边扩展子图,以包括采样期间所需跃点的所有相邻顶点。对于具有GNN层的GNN模型,我们将为每个火车顶点包含 L -hops相邻顶点,例如,单层GNN模型只需要包含每个火车顶点的 L 直接邻中。PaGraph 仅为扩展顶点引入必要的边,以满足训练期间所需的消息流。请注意,扩展顶点可能包括训练顶点。这些扩展的列车顶点被视为镜 [8] 子,不会被训练。这样,分区彼此独立。每个训练器都可以完全从自己的子图对小批量进行采样,而无需访问全局图结构。
3.3 Pipelining Data Loading and GNN Computation 流水线数据加载和GNN计算
如前所述,缓存的性能改进与具有高出度的缓存顶点的数量成正比。尽管大多数真实世界的图形都表现出高偏度,但鉴于 GPU 内存大小通常限制为 10-30 GB,独立缓存机制可能不足以支持大型图形上的 GNN 计算,其中大多数顶点无法缓存。因此,在这些情况下,数据加载仍将是瓶颈。为了补充缓存和分区,我们进一步探索了将数据加载开销隐藏到计算时间中的机会。这要求我们设计一个新的管道来并行化当前的小批量计算和下一个小批量的预取图形数据。
Fig. 9a 展示了我们的两阶段训练管道设计,我们将原始的顺序执行分解为两个并行的流式执行,即加载和计算。我们使用消息队列来协调两个流的执行。通过从 Sampler 获取输入,加载流式执行器负责组织图形存储和 GPU 缓存中所选小批量顶点所需的特征信息(请参阅 Fig. 9b )。加载完成后,它会将一条就绪消息(包括批处理数据在 GPU 内存中的位置)发布到共享消息队列。另一方面,计算执行器位于循环中,并定期检查来自加载执行器的新消息的到达。它从共享队列的头部弹出一条消息,并计划相应的GNN计算,这将消耗已经预取的数据。
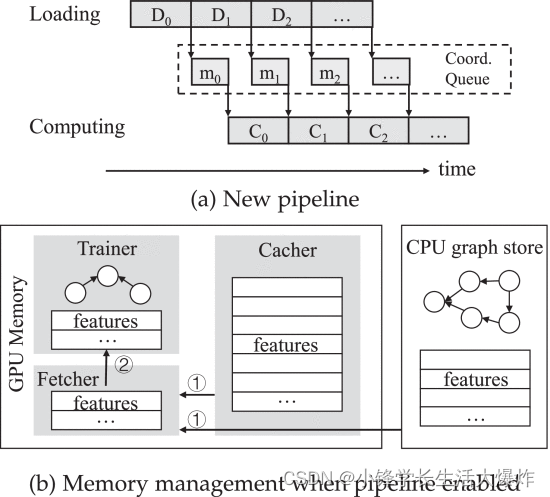
新的流水线设计使我们进一步将 GPU 内存分为三个部分,分别用于 GNN 计算、图形数据缓存和缓冲预取数据(请参阅 Fig. 9b )。但是,由于以下原因,我们声称预取缓冲区不会加剧 GPU 内存紧张。首先,每个小批量数据占用的内存空间不到 900 MB,在我们评估中使用的一台设备上仅占用 GPU 内存的 8%。其次,我们限制了预取任务的最大数量,以避免内存争用。我们还使用消息队列的长度作为反馈来指导加载执行器自适应减慢或加快预取速度。
Implementation 实现
[10] 和PyTorch(v1.3) [23] 的顶部构建了PaGraph。由于梯度同步不是GNN训练中的主要关注点,我们只是采用现有的解决方案NCCL RingAllReduce来实现数据并行GNN训练 [32] 。我们使用 DGL 实现的图形存储服务器将图形结构数据和特征数据存储在 CPU 共享内存中。 1 我们将完整的图结构存储为 CSC 格式 [33]
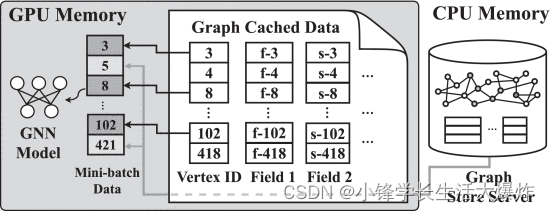
缓存初始化和维护。我们扩展了数据加载器以合并简单的 Python API,用于从本地 GPU 内存或 CPU 内存获取所需的数据,如 所示 Fig. 10 。首先,我们通过将数据加载器连接到 Graph Store Server 并使其了解数据并行训练配置来初始化数据加载器,例如,使用了多少 GPU,它为哪个 GPU 服务等。在第一次小批量训练期间,数据加载器将检查总 GPU 内存(表示为 total_mem )和 PyTorch 分配的峰值 GPU 内存(表示为 used_mem )。我们还保留了一定大小的 GPU 内存,未用于训练期间的内存波动(表示为 preserved_mem ),我们发现在实践中 1.0 GB 就足够了。之后,我们调用 loader.auto_cache,它计算可用内存的大小,并通过减 used_mem 去和 preserved_mem from total_mem 来将此内存量分配给缓存。分配缓存后,数据加载器将持续加载到具有最高出度的折点的缓存要素(由 field_names 指定)中,直到缓存已满。为了减少此初始化过程的时间成本,我们离线分析子图结构,并根据顶点的出度对顶点进行排名。从第二次迭代开始,数据加载器通过调用 loader.fetch_data 从 Graph Store Server 和本地 GPU 缓存获取数据,mini_batch 对此进行参数化。此新加载流对训练作业是透明的。

Computation-Balanced and Cross-Partition Access Free Graph Partition 计算平衡和跨分区访问自由图形分区
[20] 的分区算法,这是一种基于流的分区解决方案。我们只评估训练顶点(第 3 行),根据 scores 计算(第 4-5 行)将它们分配给具有索引 ind 的目标分区(第 6 行),并且还将它们的 L -hop 邻域(第 7 行)包含在分区中。为 GNN 模型训练准备分区是训练前的脱机作业。尽管此步骤引入了额外的时间成本并消耗了额外的资源,但由于以下原因,它是可以接受的。首先,分区是一次性脱机作业,因此不会阻塞训练过程。其次,最近的研究发现 [34] , [35]
为了减轻分区的存储负担,我们删除了在训练期间没有贡献的冗余顶点和边。对于给定 L 的层图神经网络,我们检查 val/test 顶点 L 是否远离所有训练顶点。如果是这样,我们从子图中删除此顶点及其相关边。此外,我们删除冗余边缘以避免低效的消息流。如果不需要其中一个消息流方向,那么非有向边将转换为有向边。随着图结构的细化,与冗余顶点和边相关的图数据也被移除。
流水线。由于 DGL 已经将小批量采样与数据加载路径上的其余步骤重叠,因此我们只考虑将数据加载成本隐藏到计算中。最初,我们引入了一个守护进程线程,用于在当前小批处理正在计算时预取下一个小批处理。不幸的是,这个版本效率低下,因为python的传统GIL(全局解释器锁)功能序列化了多个线程。为了避免这种不必要的序列化,我们启动一个守护进程来执行目标预取任务,并通过 PyTorch 队列管理进程之间的通信。但是,由于进程隔离,这种多进程解决方案也带来了额外的成本,用于将预取的小批量数据从共享队列复制到计算进程的内存空间。为了进一步隐藏这种不可忽略的成本,我们另外从主进程生成一个守护进程线程,以将数据从队列异步复制到后台的主进程。
[36]
[37] ,需要对数据样本进行洗牌。可以跨分区(全局)或在每个分区(本地)内进行随机排序,其中前一种情况可能会导致更快的收敛,但比后一种情况成本更高。然而,局部洗牌在现实世界的实践中被广泛采用,最近的研究表明,在收 [38]
讨论。目前,PaGraph 在单个多 GPU 服务器上工作,但缓存、图分区和流水线的核心思想可以直接应用于分布式 GNN 训练,以利用更多的 GPU 来处理无法放入单个服务器内存的更大图。在该扩展中唯一需要仔细设计的是有效地同步服务器之间的梯度,以避免同步瓶颈。
Evaluation 评估
我们使用具有代表性的GNN模型和真实世界数据集对PaGraph的性能进行了深入评估。特别是,我们探索了单GPU性能和多GPU的扩展效率,对分区算法在不同条件和质量下的缓存性能进行了细分分析,并了解了缓存和流水线在面对大型图时的联合效应。
5.1 Experimental Setup 5.1 实验设置
[10] v0.4、PyTorch [23]
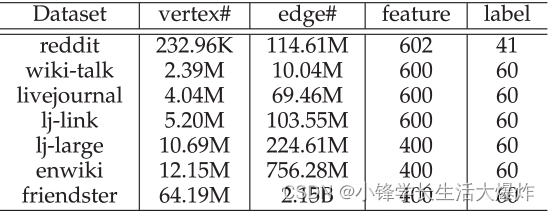
数据。我们使用中 Table 2 列出的七个真实世界图形数据集进行评估,包括reddit [2] 社交网络,wiki-talk [39] page版本历史网络,livejournal的三种变体,通信网络( [27] livejournal,lj-link,lj-large [40] [18] )和enwiki维 [22]
抽样方法。我们采用邻域采样和逐层采样
[2] [15] 结合跳过连接 [16] 来评估PaGraph。最近的一项工作 [19] 已经表明,基于邻域的采样训练可以实现与全图训练相当的模型性能,其中每个邻域层仅采样两个邻域。因此,在我们的评估中,我们选择遵循他们的建议,即对每层中的一个顶点对两个随机邻居进行采样,以形成一个小批量。根据 DGL [26]
[3] 和GraphSAGE [2] 来评估PaGraph,并在中 Table 3 进行了详细配置。GCN 对图的卷积操作进行推广如下。GCN 图层中的每个折点都使用 sum 操作聚合其相邻折点的要素。然后,聚合要素通过全连接层和 ReLU 激活以生成输出表示。GCN在分类 [3] 和神经机器翻译 [7]

基线。我们将原始 DGL 部署为第一个基线。此外,我们运行一个高级 DGL,其中预处理 [19] 优化作为另一个基线启用,表示为“DGL+PP”。预处理背后的想法是通过离线聚合相应的特征来删除GNN模型的第一层。尽管如此,数据加载仍然主导着支持预处理的训练的性能,并使其无法充分利用这种优化。除非另有说明,否则所有性能数字都是 10 个时期的结果的平均值。
5.2 Single GPU Performance 单显卡性能
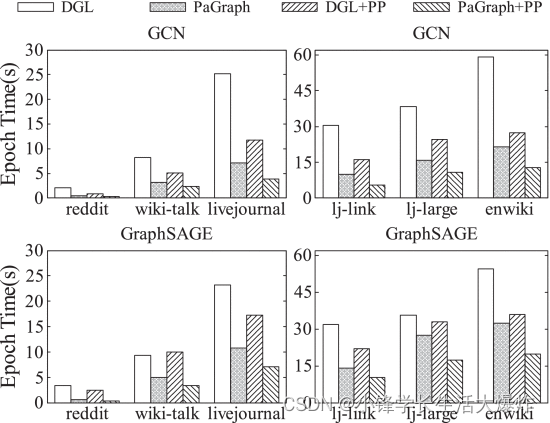
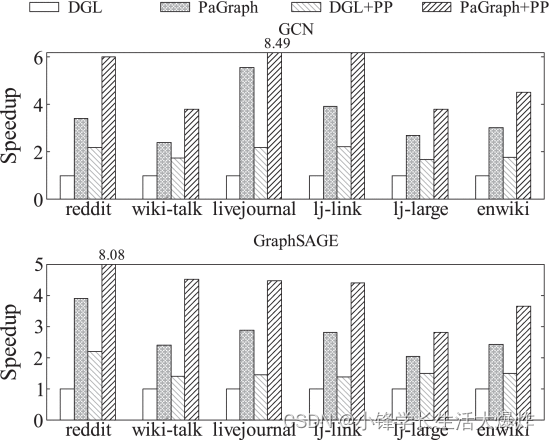
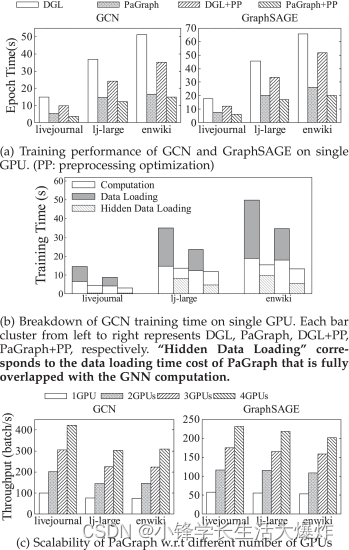
我们首先评估PaGraph在单个GPU上的训练性能。 Fig. 11 显示了GCN和GraphSAGE在不同数据集上的训练性能。总体而言,与DGL相比,PaGraph在GCN的训练性能加速从2.4×(lj-large)提高到3.9×(reddit),在GraphSAGE上从1.3×(lj-large)加速到4.9×(reddit)。我们观察到预处理和DGL(DGL+PP)的组合在两个GNN模型中表现不同,即通过预处理实现的GCN性能加速优于GraphSAGE。这是由于GCN和GraphSAGE中使用的不同转发过程。在 GCN 中转发期间,每个折点聚合来自其相邻要素的要素,并将这些要素求和为一个要素。与GCN不同,对于相应小批量中的每个顶点,GraphSAGE必须保存自己的特征和来自其邻居的聚合特征。与GCN相比,这导致GraphSAGE有更多的CPU-GPU数据传输。相比之下,我们进一步观察到,除了普通DGL之外,我们在PaGraph中的优化可以更好地利用预处理优化的潜力。例如,PaGraph+PP将GCN和GraphSAGE在前6个数据集中的DGL+PP性能提高了2.1×至3.0×和1.8×至6.2×。
[41] 和PyTorch Profiler [42]
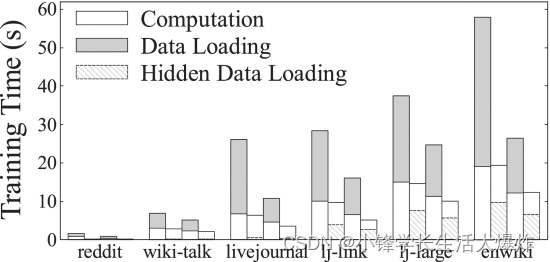
与基线数据加载器相比,由于缓存和流水线的共同努力,PaGraph 完全重叠了数据加载阶段和 GPU 计算阶段,从而消除了原始 GNN 模型及其启用预处理的变体的训练管道的加载成本。我们发现独立缓存足以在前三个数据集上训练目标模型。这是因为这些数据集很小,可以完全缓存到 GPU 内存中,并且数据加载时间可以忽略不计。与此不同的是,尽管通过缓存,后三个更庞大的数据集的数据加载时间已经从 65.7% 减少到 78.7%,但它仍然占整个训练时间的 34.9%。在这种情况水线数据加载和计算可以完全将前一种情况的成本隐藏到后一种情况下。有趣的是,在某些情况下,计算时间略有减少,例如 lj-large 数据集的“PaGraph+PP”,因为我们小心翼翼地避免了并行训练作业之间的 CPU 争用。但是,在某些情况下,计算时间略有增加,例如enwiki数据集的“PaGraph”。这是因为后台预取过程会花费一些 CPU 周期,这可能会影响 GPU 内核的启动。
5.3 Effectiveness of Caching Policy 缓存策略的有效性
[43]
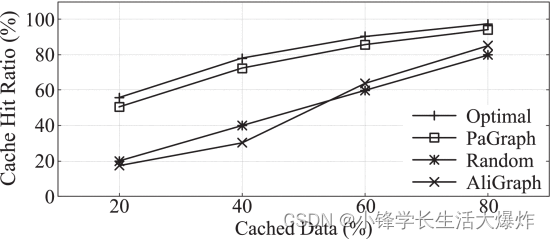
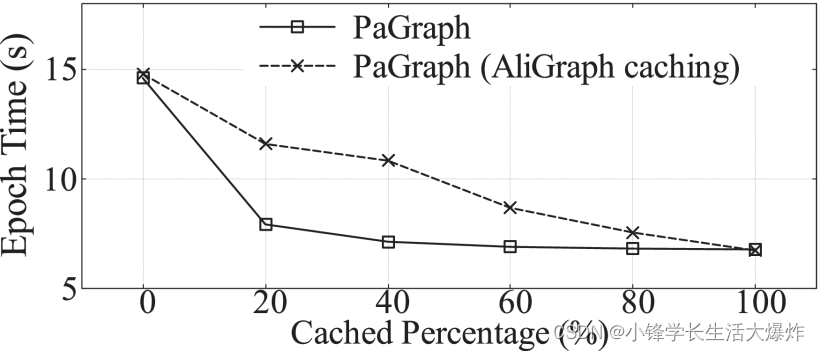
Fig. 13 分别显示了使用单个 GPU 的不同缓存比率下的缓存命中率。我们观察到,当只有 20% 的图形被缓存时,我们可以实现超过 50% 的命中率,这是其他策略性能的 200% 以上。更有趣的是,它表明我们的缓存策略并不复杂,但非常有效,非常接近最佳情况。我们还在其他数据集上实现了类似的接近最优缓存命中率。此外,我们还探讨了PaGraph和AliGraph实现的不同缓存命中率的性能影响。如 所示 Fig. 14 ,随着缓存图数据比例的增加,DGL 和 PaGraph 实现的每纪元训练时间不断下降,并在缓存所有必需数据时收敛到 6.7 秒。但是,当缓存大小受到限制时,PaGraph的缓存策略比AliGraph的策略实现了高达1.5×的性能加速。更有趣的是,当缓存百分比达到 40% 时,训练性能变得稳定,并且当使用更多缓存空间时,没有观察到进一步的改进。这是因为在那个关键点,数据加载时间减少到比 GPU 计算时间短,我们的流水线机制可以完全重叠这两个阶段。这进一步揭示了结合缓存和流水线的额外好处,这使得我们的解决方案适用并在 GPU 内存限制下提供良好的性能。
通过我们的缓存策略,与DGL相比,PaGraph在大型图形上实现了大量的数据加载减少。 Table 4 显示了 GCN 训练期间每个训练器中每个 epoch 的平均减少数据加载量。总体而言,我们分别实现了 lj-link、lj-large 和 enwiki 数据集的 91.8%、80.9% 和 81.0% 的负载减少。

5.4 Multi-GPU Performance 多显卡性能
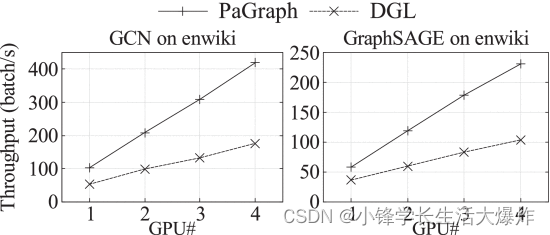
我们评估不同数量 GPU 的可扩展性。 Fig. 15 显示了针对具有不同数量 GPU 的真实数据集 enwiki 训练 GCN 和 GraphSAGE 的实验结果。当使用更多的GPU时,DGL和PaGraph都能实现更高的吞吐量。然而,一般来说,PaGraph的性能优于DGL,并且在不同的硬件配置下显示出更好的可扩展性,例如,PaGraph的性能优于DGL高达2.4×(GCN为4个GPU)。我们进一步评估了PaGraph在多个GPU上的性能,以显示其在不同算法优化上的有效性。为此,我们放大了使用 2 个 GPU 时的性能数字,并在 中 Fig. 16 总结了结果。PaGraph在所有数据集上实现了2.1×至5.6×的DGL性能。通过预处理优化,PaGraph 可以在 DGL 上实现从 2.8× 加速到 8.5×。显著加速的原因有两个。首先,多个GPU为缓存提供更多可用内存,从而实现更高的缓存命中率和更低的数据加载成本。为了确认这一点,我们还在 enwiki 上测试了 GCN 的性能,在四个 GPU 上总缓存大小固定为 6 GB。它表明 4-GPU 上的加速比仅为 3.7×,比在没有缓存大小限制的情况下实现的加速比低 23%。其次,在所有测试案例中,数据加载比计算运行得更快,因此,我们的管道机制将其完全隐藏在计算中。
5.5 Implications of Graph Partition 图分区的含义
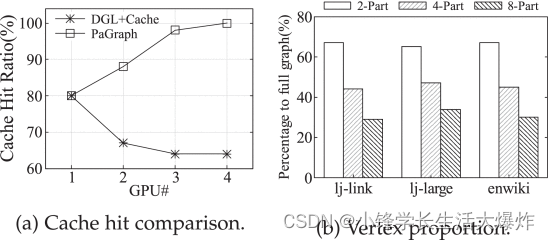
为了验证图分区支持的数据并行训练的好处,我们首先调整 DGL 以使用我们的缓存机制,表示为“DGL+Cache”,然后将 PaGraph 与 DGL+Cache 进行比较,唯一的区别是只有前者使用分区图数据,而后者使用非分区的完整图。 Fig. 17a 说明了不同数量 GPU 下的缓存命中率。由于 DGL+Cache 中的训练器共享相同的全局图形存储,该存储保持完整的图形结构,因此每个训练器访问的 GPU 缓存中的缓存部分是相同的。但是,在 PaGraph 中,随着训练器数量的增加,每个训练器都会使用从较小的训练顶点集采样的顶点,并表现出更好的数据局部性。因此,当使用更多的 GPU 时,PaGraph 实现的缓存命中率不断提高,而 DGL+Cache 观察到缓存命中率下降。这种差异可以直接转化为 Fig. 18 性能差距(使用 4 个 GPU)。通过将缓存与分区相结合,PaGraph的性能分别比DGL+Cache和DGL高出25%和52%。流水线机制可以进一步将GCN的训练速度提高27%。
[44]

5.6 Effects of Pipelining 流水线的影响
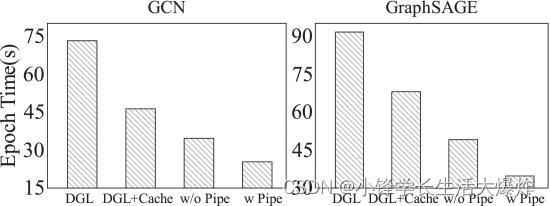
接下来,我们将注意力转移到理解流水线数据加载和计算的影响上。在这里,我们选择 friendster 数据集,它比 中的 Table 2 其他六个数据集大得多。这个大型数据集消耗 358 GB CPU 内存,即使使用 4 个 GPU,也只能缓存其顶点要素的 25%。因此,有了这个数据集,我们可以将流水线的性能优势与缓存隔离开来。为此,我们通过增量添加 中 Section 3 介绍的每个优化来训练 GCN 和 GraphSAGE,并在 中 Fig. 18 报告训练速度数字。在这里,我们使用邻居采样方法并启用预处理。与原版DGL相比,由于缓存机制,GCN和GraphSAGE的“DGL+Cache”实现了1.4×和1.3×的加速。除了缓存之外,启用图形分区还可以将两个 GNN 模型的性能分别提高 25.1% 和 28.1%。但是,在这种情况下,将缓存和分区组合在一起不足以充分探索训练加速机会,因为降低但未消除的数据加载成本仍然会对整体性能产生负面影响。因此,最后,打开流水线可以进一步将GCN和GraphSAGE的每个epoch训练时间分别减少27.3%和29.3%。
5.7 Impact of Data Loading Volumes 数据加载量的影响
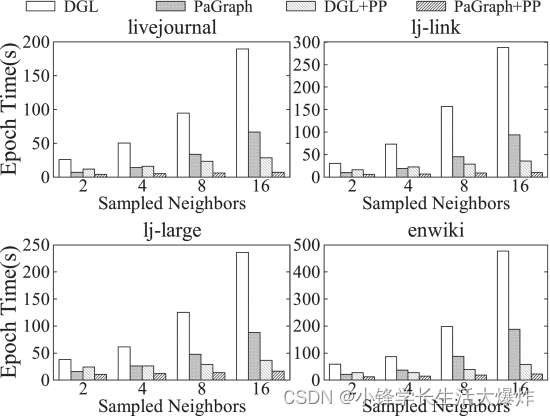
为了验证 PaGraph 的鲁棒性,我们评估了每次训练迭代所需的图形数据量的性能加速。 Fig. 19 显示了在 DGL、DGL+PP、PaGraph 和 PaGraph+PP 上不同数量的采样邻居的训练性能。随着采样邻居数量的增加,GNN 计算将消耗更多的 GPU 内存,例如,在 GCN 中将邻居大小从 2 更改为 16 时,从 1 GB 增加到 5 GB,从而导致缓存容量降低。由于缓存的图形功能较少,这可能会限制 PaGraph 带来的性能改进。然而,如 所示 Fig. 19 ,PaGraph 的性能不断优于 DGL,其变体与预处理相结合可以实现均匀幅度的加速(例如,在 16 个采样邻居中,livejournal 的 27.6× 和 lj-link 的 29.2×)。当面对更大的邻居尺寸时,PaGraph 的性能大幅提升有三个原因。首先,对于DGL基线,采样邻居的数量更大,数据加载和计算之间的不平衡更严重。其次,尽管空间减少,但 GPU 上的缓存仍然会显著缩小数据加载量,因为缓存策略更喜欢保留具有较高出度的顶点。第三,流水线可以补偿具有较小缓存的性能改进损失,正如对缓存有效性的评估所证明的那样(请参阅 Fig. 14 和 Section 5.3 )。
5.8 Supporting Other Sampling Method 支持其他采样方法
为了验证PaGraph设计对其他采样方法的有效性,我们选择逐层采样方法作为另一个案例研究,该方法与相邻采样的不同之处在于固定每层的大小以避免感受野呈指数增长。 Fig. 20a 显示了GCN和GraphSAGE使用单个GPU在三个数据集上的训练性能。在没有预处理的情况下,PaGraph实现了GCN从2.5×(lj-large)到3.1×(enwiki)的训练加速,以及GraphSAGE从2.3×(lj-large)到2.5×(enwiki)的训练加速。启用预处理后,对于GCN和GraphSAGE,PaGraph+PP的训练速度分别提高了1.9×至2.7×和1.9×至2.6×。这些结果表明PaGraph也适用于其他采样方法,并带来类似的性能加速。我们通过预测 中的 Fig. 20b 分解时间成本来进一步了解对训练加速的贡献。我们观察到,PaGraph比DGL减少了高达93.5%的数据加载时间,PaGraph+PP比DGL+PP减少了高达91.3%。同时,数据加载时间可以通过计算隐藏,这将进一步减少高达34.1%的训练时间。最后,我们研究使用PaGraph进行GNN训练的可扩展性。 Fig. 20c 表明,与之前评估的邻居采样方法类似,PaGraph 还可以通过分层采样实现线性扩展,以便在最多 4 个 GPU 上的三个数据集上训练 GCN 和 GraphSAGE。
5.9 Training Convergence 训练收敛
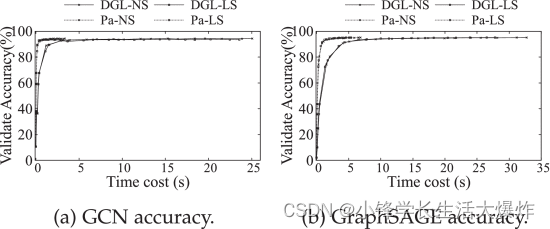
为了确认我们实现的正确性以及洗牌的影响,我们评估了在PaGraph(启用预处理)之上使用邻居采样和逐层采样(NS)以及4个GPU上的reddit数据集上的DGL库训练两个执行的GNN模型的验证准确性。DGL采用全局洗牌,而PaGraph采用局部洗牌。如 所示 Fig. 21a ,无论使用哪种采样方法,在 GCN 模型上,PaGraph 收敛到与原始 DGL 大致相同的精度,但在收敛速度上优于 DGL 7.4× (NS) 和 8.5× (LS)。这是因为与DGL相比,PaGraph需要相同的迭代次数才能达到相同的精度,但迭代速度更快。我们可以根据 得到 Fig. 21b GraphSAGE 模型的类似结论。我们没有对Reddit以外的数据集进行类似的实验,因为这些数据集中的顶点特征是随机初始化的。
Related Work 相关工作
[23] [25] 和TensorFlow [9] 这样的深度学习框架已经在学术界和工业界被广泛采用。但是,这些框架没有提供 GNN 所需的足够图操作。因此,近年来,它推动了一些专门框架 [10] [11] [13] [43] [45] [46] [47] [48]
[19]
缓存。缓存图数据有利于许多图处理任务 [43] , [48] 。 [49] 预选 [49] 应用静态缓存策略来加速类似 BFS 的计算。AliGraph [43] 为分布式计算场景缓存顶点及其数据,以避免训练器和远程存储之间的通信成本。但是,正如我们在 中 Section 5.3
[8] 、 [20] [21] [50] [51] 在 [52]
[53]
Discussion and Future Work 讨论和今后的工作
虽然我们相信PaGraph可以使广泛的GNN模型和系统受益,但在使其更加普遍和适用于更广泛的环境之前,仍有一些开放的挑战需要解决。
[4] [54] 和diffpool [55] 。这里的初步结论是,与看起来类似于GCN和GraphSAGE的GAT和GIN相比,diffpool的计算量更大。因此,预计PaGraph比其他四种模型受益更少的diffpool。然而,GNN计算优化的出现 [56]
[19] 。最后,尽管大多数现有工作都集中在静态图上,但通过动态图训练GNN模型吸引了越来越多的兴趣 [57] 。 [58]
[59] 。这些方法可以为小型图形提供最高的性能加速,其功能可以完全适合GPU内存。在这种情况下,不仅可以消除繁琐的CPU到GPU数据加载阶段,还可以利用GPU的高处理密度和内存带宽进行快速采样。然而,对于较大的图形来说,这仍然具有挑战性,因为涉及 GPU 的 CPU 外数据访问和有限的 PCIe 带宽可能会抵消 GPU 采样的好处。幸运的是,新的 GPU irect 存储技术 [60]
Conclusion 结论
为了加速GNN在大型图上的训练性能,我们提出了PaGraph,这是一种基于采样的通用训练方案,它利用了GNN计算感知缓存和图分区的组合。我们在DGL和PyTorch上实现了PaGraph,并使用两种广泛使用的采样方法,在7个图数据集上使用2个代表性GNN模型对其进行评估。实验结果表明,PaGraph完全隐藏了数据传输成本,与DGL相比,性能提升高达4.8×。通过预处理,PaGraph甚至可以实现16.0×的性能提升。
ACKNOWLEDGMENTS
作者衷心感谢所有匿名审稿人的深刻反馈。这项工作部分得到了中国国家重点研发计划(2018YFB1003204)的支持,部分得到了中国国家自然科学基金(61 802 358)和61 772 484的资助,部分得到了中国科学技术大学双一流项目研究基金“YD2150002006的支持,部分得到了华为和Microsoft的支持。
