
用python爬虫爬取acfun上的视频
公众号回复acfun获取源代码
看效果:
打开网站
随便点一个视频
打开开发者模式
然后搜素m3u8,找到文件,查看url
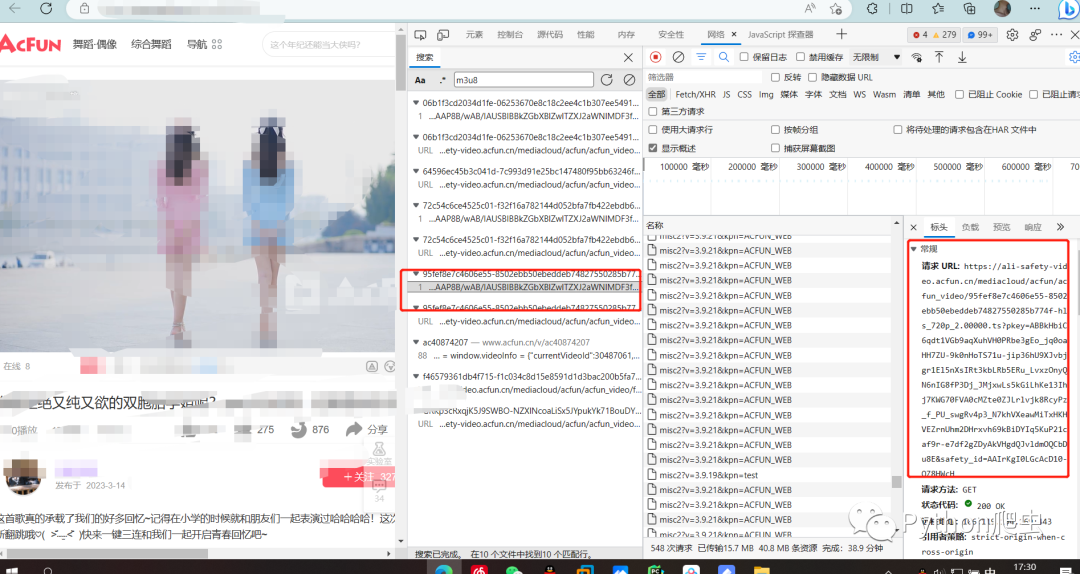
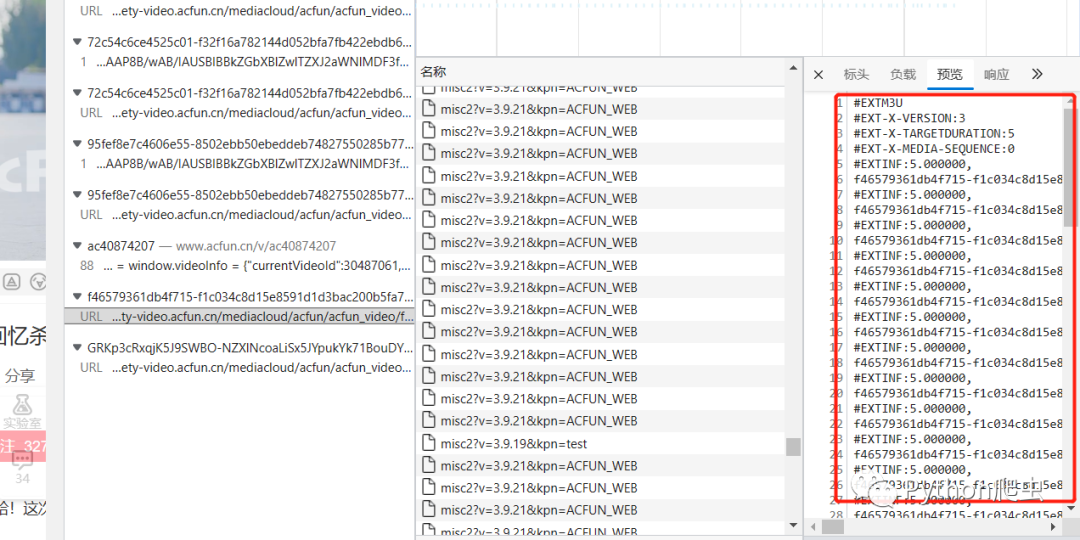
这些就是一个一个的分割出来的ts片段
全局搜素url可以发现再页面源代码中就可以找到这个m3u8文件
所以思路是
1、访问视频页面
2、提取m3u8文件地址
3、访问下载文件中的ts片段
第一部分
访问视频页面,获取源码
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.44",
'Referer': 'https: // www.acfun.cn /'
}
# 访问视频页获取源码
response = requests.get(url=html_url,headers=headers)
html_data = response.text
# print(html)第二部分
从源码中获取标题,m3u8文件
# 从源码中获取m3u8文件
title = ''.join(re.findall('<title >(.*?) - AcFun弹幕视频网 - 认真你就输啦 \(\?ω\?\)ノ- \( ゜- ゜\)つロ</title>',html_data))
print(title)
html = etree.HTML(html_data)
json_data = re.findall('window.pageInfo = window.videoInfo = (.*?);{1}',html_data)[0]
j1 = json.loads(json_data)
m3u8_url = json.loads(j1["currentVideoInfo"]["ksPlayJson"])['adaptationSet'][0]['representation'][0]['backupUrl'][0]
m3u8_data = requests.get(url=m3u8_url,headers=headers).text
# print(m3u8_data)
m3u8_data = re.sub('#E.*','',m3u8_data).split()
# print(m3u8_data)第三部分
循环下载.ts文件,保存
for ts in m3u8_data:
ts_url = 'https://ali-safety-video.acfun.cn/mediacloud/acfun/acfun_video/'+ts
ts_content = requests.get(url=ts_url,headers=headers).content
with open(f'acfun/{title}.mp4',mode='ab') as f:
f.write(ts_content)
print('已保存完成!')最后看效果
没问题
公众号回复acfun获取源代码
感谢观看