
Abstract:
并行算法下的参数同步方式一般有同步更新和异步更新两种方式,本文在此基础之上提出了一种新的参数同步方式——半异步更新方式。
Introduction:
这里用神经网络举例子,也就是神经网络的并行中的参数同步的情况,给出同步、异步方式:
同步:
各个客户端分别各自运行神经网络的前向和后向操作,计算出梯度;各个客户端把计算出的梯度发送给服务器端,并且进入阻塞状态,等待服务器发送回新的参数;服务器需要收到所有客户端的梯度参数,汇总后计算出新的参数,然后再发送给所有客户端,因此每一个batch的计算中所有的客户端都进行了同步。
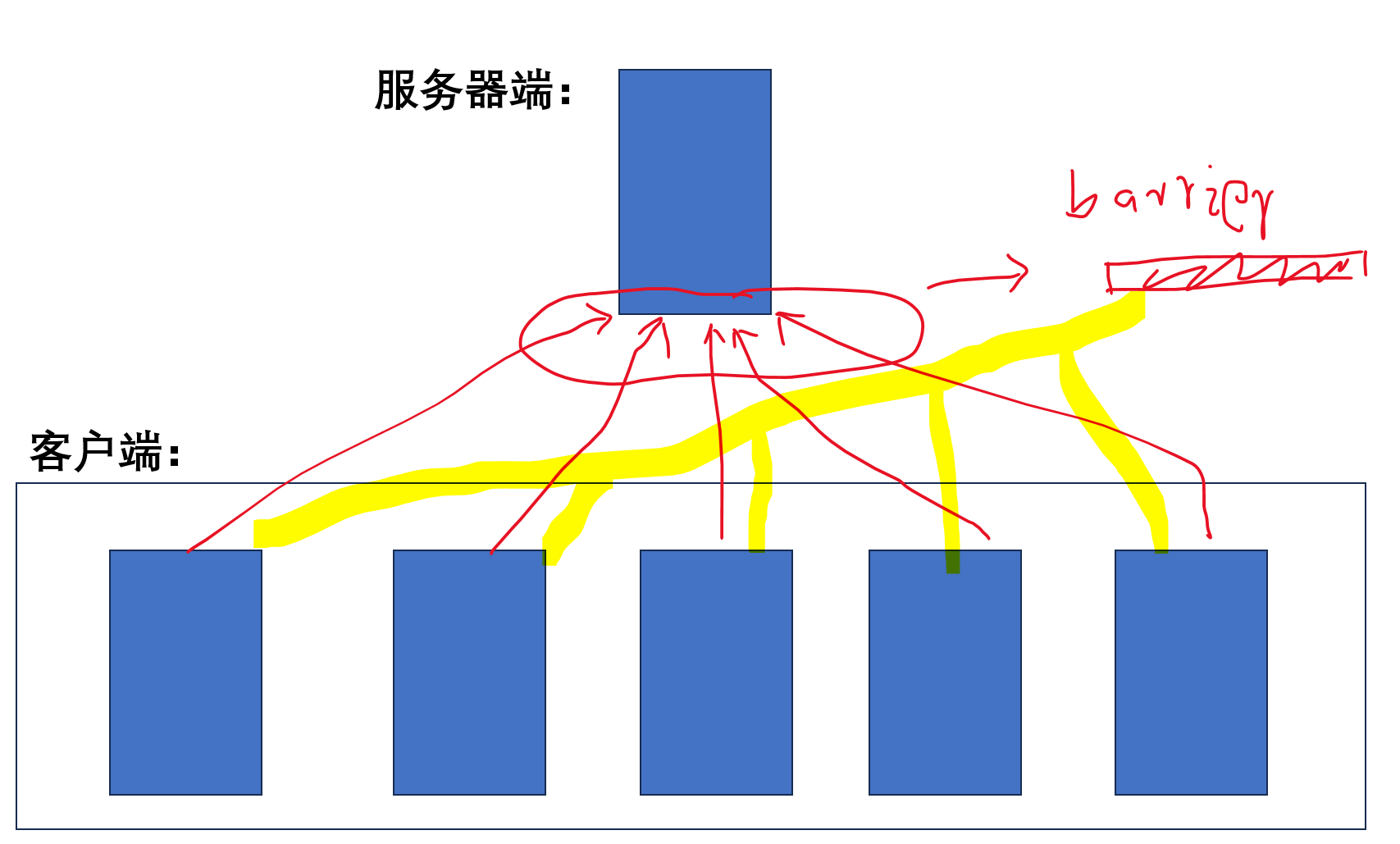
==========================================
异步:
各个客户端分别各自运行神经网络的前向和后向操作,计算出梯度;各个客户端把计算出的梯度发送给服务器端,并且进入阻塞状态,等待服务器发送回新的参数;服务器不需要进入阻塞以等待收到所有客户端的梯度参数而是每收到一个客户端发送的梯度参数就可以进入汇总计算并得出新的参数,然后再发送给当前的客户端,因此所有客户端在和服务器端同步的同时其实各个客户端是在异步运行的。
同步的更新方式:
优点:运行稳定,可复现性高;缺点:计算效率低,吞吐量低,大量时间都花费在了各个客户端的同步阻塞上了。
异步的更新方式:
优点:计算效率高,吞吐量高; 缺点:运行不稳定,可复现性不高,多次试验的结果往往有较大差异,各个客户端完全异步运行,硬件利用率更高。
个人观点:
由于同、异步更新方式的不同,应用场景也不同;对于性能比较稳定的算法,为了得到更快的运算,往往使用异步方式并行,但是对于一些本身运行效果不稳定(串行情况下)的算法就难以使用异步更新的方式,因为这样虽然可以提高计算吞吐量,但是由于加剧了算法的不稳定性,往往导致算法难以收敛,甚至会导致算法无法收敛;因此,在很多的并行软件中并没有支持异步更新方式,比如pytorch框架,在很长的时间里(7、8年)都是不支持异步更新的,而往往异步更新也更加的复杂,对工程技术方面要求的也更加高,比如深度学习框架中也只有Google推出的TensorFlow才原生支持异步更新。
对于监督学习这类比较稳定的算法,我们在并行时往往可以采用异步更新的方式,但是由于其复现性较差,因此在学术界往往也不太会使用,而使用的一般也都是工业界。
对于强化学习算法这样往往本身就不稳定,收敛困难的算法,使用异步的方式虽然增加了计算吞吐量但是会导致算法难以收敛,甚至训练失败,这也是经典的强化学习算法A3C由异步改为同步的A2C后就获得了几倍运行速度的提升,虽然单位时间的计算吞吐量变小了,但是收敛更快了,反而使同步的强化学习算法表现远远高于异步情况。
------------------------------------------------
Our proposed algorithm:
半异步更新
这里依旧以神经网络举例,我们可以在异步更新的方式上进行改进。以往的异步更新都是收到一个客户端的参数梯度后并和服务器上的参数进行合并然后得到新的参数更新给客户端和自身,但是这种方式在提高计算效率的同时造成了收敛性受损的问题,因此我们可以设置某个数值n,假设共有100个客户端,我们可以设置n=20,也就是说服务器在收到20个客户端的梯度后才进行合并和更新;更加详细的说,就是第0-18号客户端的参数发送给服务器端后并不进入阻塞,而是直接使用现有参数进行后续的计算,只有当第20个客户端,也即19号客户端发送给服务器梯度后服务器才进行汇总计算,此时第19号客户端也进入阻塞并等待服务器更新后的参数;此后的所有客户端发送给服务器梯度后都会比较下自己的参数是否比服务器上的参数落后,如果落后则进入阻塞等待服务器发送给自己更新的参数,而服务器的参数更新都是需要等待n=20个客户端参数后才进行更新。
该种算法设计必然会导致各别客户端参数远远落后于服务器端参数,我们假设服务器端现有的参数更新次数为C,客户端持有的参数为X,X<=C,如果C-X<=3,那么服务器上记录收到的参数副本个数的参数R则自加1,即R++;如果C-X<=5,那么已然对收到的参数进行合并操作,但是此时不对R值进行操作,依然需要等待R==20时才汇总计算并更新服务器参数;当C-X>5时,则意味着该客户端的参数已远远落后于服务器端,因此只返回给该客户端最新参数,但是不对R值进行任何操作,并且将该客户端发送的梯度弃用。这个算法就是本文所提的半异步更新方式,在使并行算法具备异步更新的高吞吐量的同时也使算法具备一定同步更新算法的稳定性。
----------------------------------------------------------
--------------------------------------------------
parameter:客户端数量N=100,服务器端进行梯度合并和更新参数时接收客户端参数数量n=20,客户端参数更新的计数值X,服务器端参数更新的计数值C,服务器端已接受的客户端参数副本数量值R;
----------------------------------------
服务器端:
while True:
receive (客户端id,客户端梯度,客户端参数的更新计数X);客户端进入阻塞状态;
if C-X<=3: 接收客户端梯度,R++;
elif C-X<=5: 接收客户端梯度;
elif C-X>5: 拒绝接收客户端梯度;
if R==20: 将收集到的客户端梯度汇总并计算,更新服务器端参数;C++;R重新赋值为0;
if X<C:将服务器端参数更新给客户端;
结束客户端的阻塞状态;
----------------------------------------
客户端:
while True:
send (客户端id,客户端梯度,客户端参数的更新计数X);客户端进入阻塞状态;
接收服务器端指令,如果结束阻塞继续计算;如果接收服务器参数,则X++,更新参数,然后继续计算;
继续计算任务,得到新的梯度值;
----------------------------------------
扣下题:
这个算法的出发点就是因为强化学习是很难使用传统监督学习中的异步更新的并行方式的,虽然就目前来看对于强化学习算法并行化来说同步更新方式一定是优于异步方式的,但是同步方式过程中的硬件利用率较低的问题却一直无法解决,这里提出的这种半异步更新的算法就是为了在传统同步更新和异步更新之中寻找到一个中间方法。
PS:
至于本文所提算法的性能是没有作具体代码上的实现的,这里只是提出了一个想法,当然具体实现也是根据这个算法来进行也是比较简单的,这里由于精力有限也就只作idea的提出。
==========================================