
[BSidesSF2019]zippy
用wireshark打开pcapng文件,追踪TCP流可知数据流中有flag.zip文件,解压缩密码为supercomplexpassword
binwalk提取出来压缩包后解压得到flag
binwalk -e ./attachment.pcapng

[SWPU2019]Network
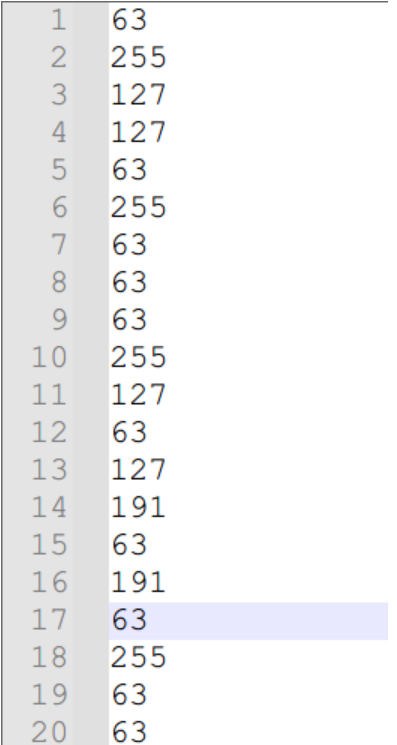
文本文件内容是一堆数字,可以注意到63=64-1,127=128-1,191=192-1,255=256-1
将这些十进制数字转换成二进制可以发现是利用高两位进行数据隐写
63=00111111
127=01111111
191=10111111
255=11111111
后来了解到这是TTL隐写
——TTL隐写
IP数据报的TTL(Time To Live)字段有8bit,可以表示0-255的范围,IP数据报每经过一个路由器,TTL字段就会减1,当TTL减为0的时候,该报文就会被丢弃,但是在大多数情况下通常只需要经过很小的跳数就能完成报文的转发, 远远比上限255小得多,所以我们可以用TTL值的前两位来进行传输隐藏数据。

写个脚本将数据提取出来拼接,8个bit一组进行ascii解码输出是16进制字符,需要再编码写入文件

最终脚本如下
with open("attachment.txt",'r') as fr:
with open("out","wb") as fw:
s=''
for i in fr.readlines():
if int(i[:-1])==63:
s+='00'
if int(i[:-1])==127:
s+='01'
if int(i[:-1])==191:
s+='10'
if int(i[:-1])==255:
s+='11'
for i in range(0,len(s),16):
data=chr(int(s[i:i+8],2))+chr(int(s[i+8:i+16],2)) #将源文件的每个字节还原出来,如该文件的第一个字节是0x50,则ddata="50"
tmp=int(data,16).to_bytes(1, 'big', signed=False) #将每个字节编码后写入文件
fw.write(tmp)
看文件头发现是一个压缩包

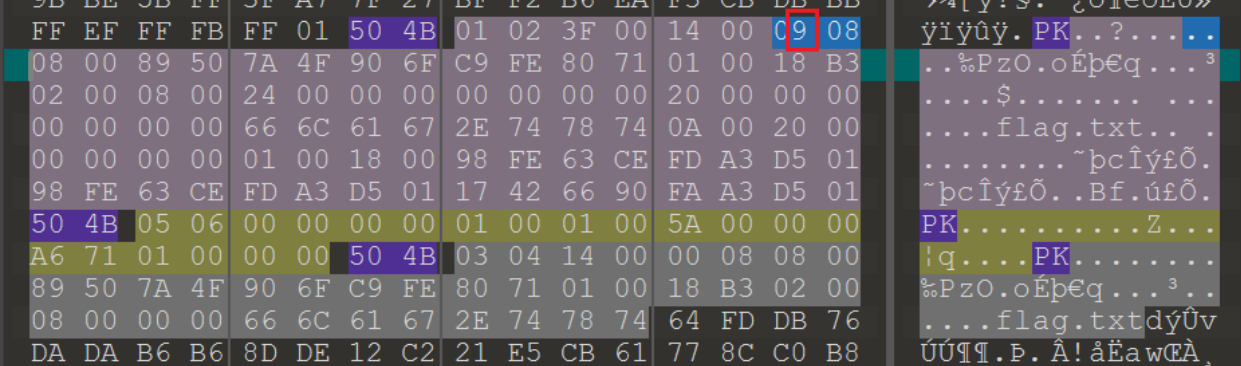
没有给密码信息,那么看看是不是伪加密,实在不行暴破,找到标志位,第二个数字是奇数,改成0后可解压成功
文件内容是经过base64编码后的

找了个在线网站后发现这是经过了多次base64编码后的结果,写个脚本破解得到flag
import base64
with open("flag.txt",'r') as fr:
s=fr.read()
for i in range(100):
try:
s=base64.b64decode(s)
print(s)
except:
break
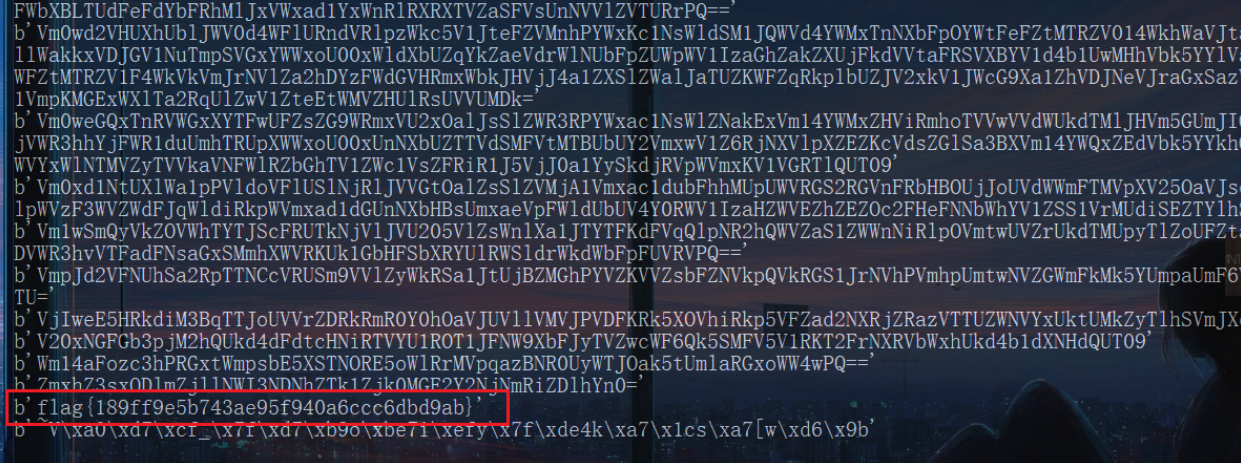
flag{189ff9e5b743ae95f940a6ccc6dbd9ab}
[UTCTF2020]basic-forensics
010 editor打开发现是个文本文件
字符串搜索得到flag
flag{fil3_ext3nsi0ns_4r3nt_r34l}
[RCTF2019]draw
给的是logo编程语言编写的代码,扔进在线编辑器中执行一下得到flag
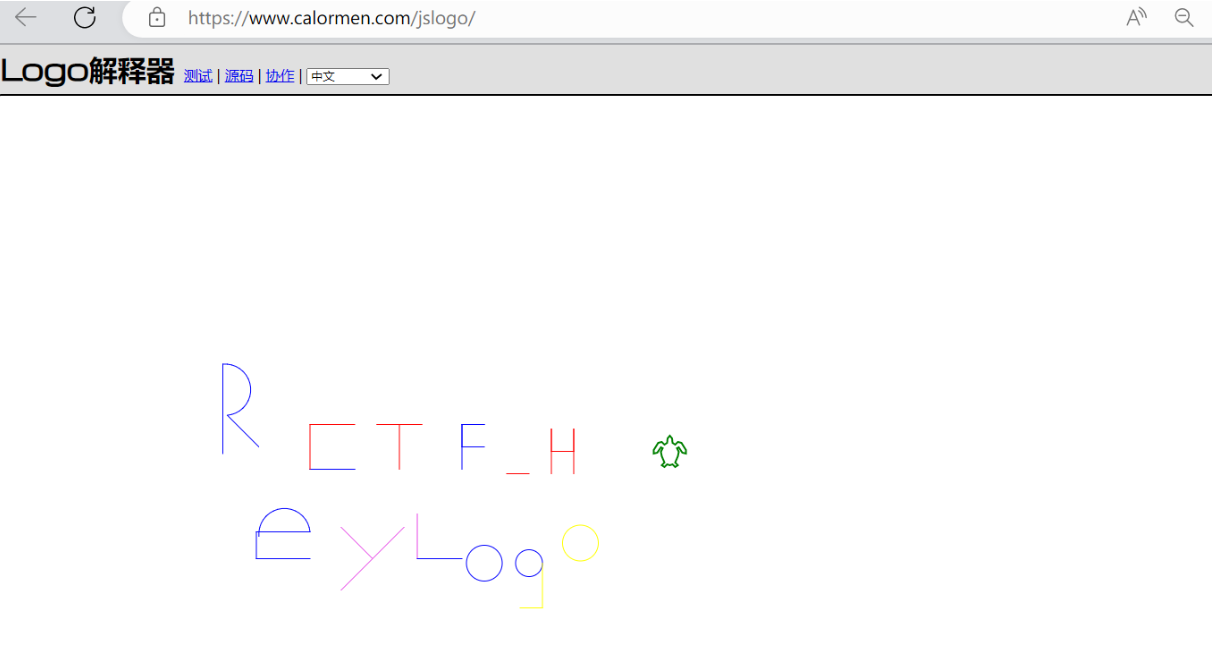
flag{RCTF_HeyLogo}
[ACTF新生赛2020]明文攻击
得到一个图片和一个加密的压缩包
从图片入手,一个完整的 JPG 文件由 FF D8 开头,FF D9结尾,而图片浏览器会忽略 FF D9 以后的内容,因此可以在 JPG 文件中加入其他文件,需要尤其注意。
图片末尾可以看出来图片里面藏了一个压缩包,但文件头应该是0x50 0x4B 0x03 0x04,少了50和4B
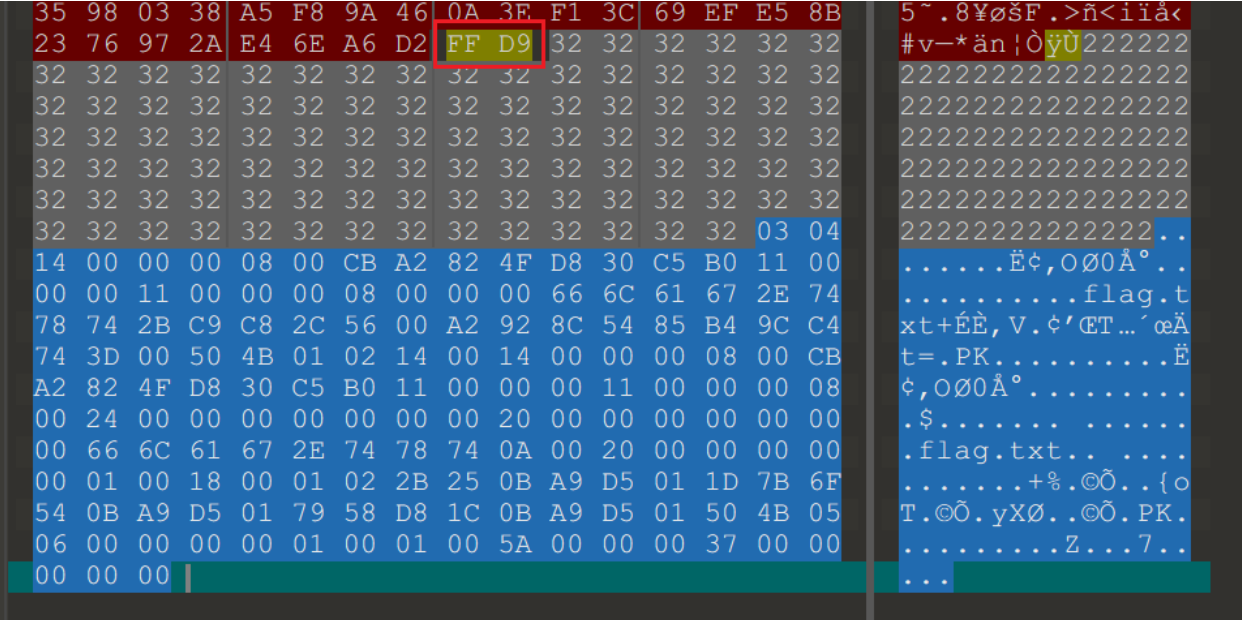
将这部分数据提取出来之后手动修复如下
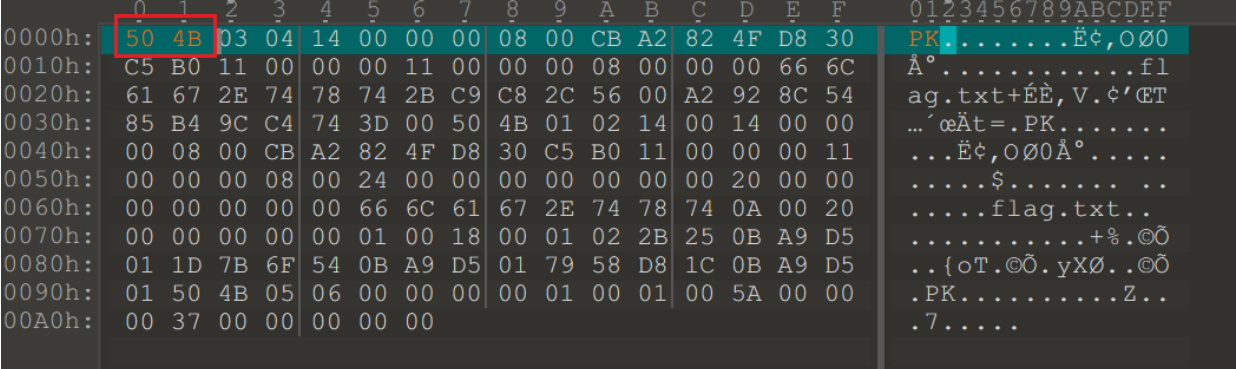
解压缩可以得到flag.txt
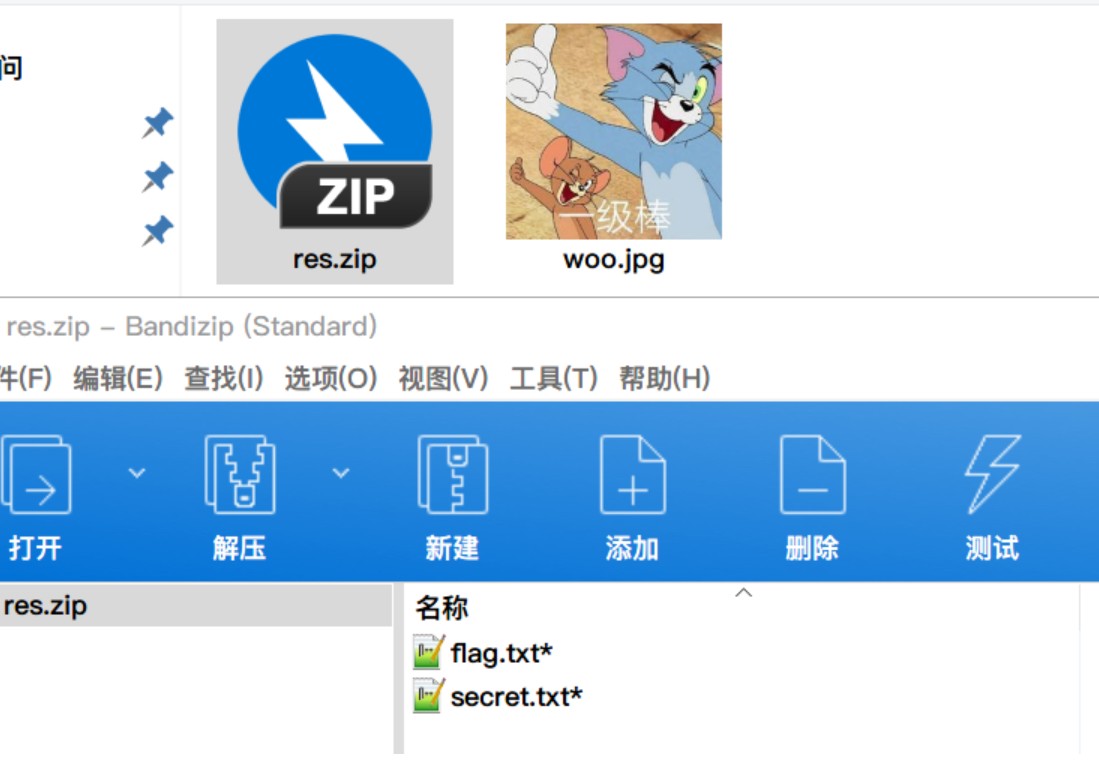
先尝试将其作为解压密码但解压失败,根据题目提示,比对一下res.zip和out.zip的目录可以发现res.zip的flag.txt和out.zip的flag.txt二者的名称、大小还有CRC(甚至是修改日期!)均一致(如下图),于是可以得出下面结论:
- out.zip里的flag.txt就是res.zip的flag.txt,
- res.zip与out.zip采用同一方式(ZipCrypto Deflate)压缩

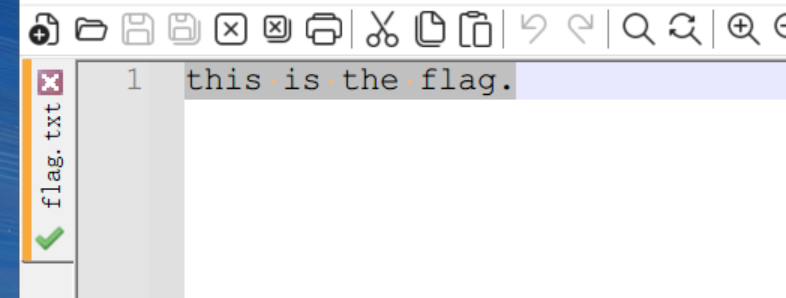
既然res.zip的flag.txt对我们来说是已知的,由此本能想到采用已知明文攻击,用ARCHPR按如下设置后点击开始即可
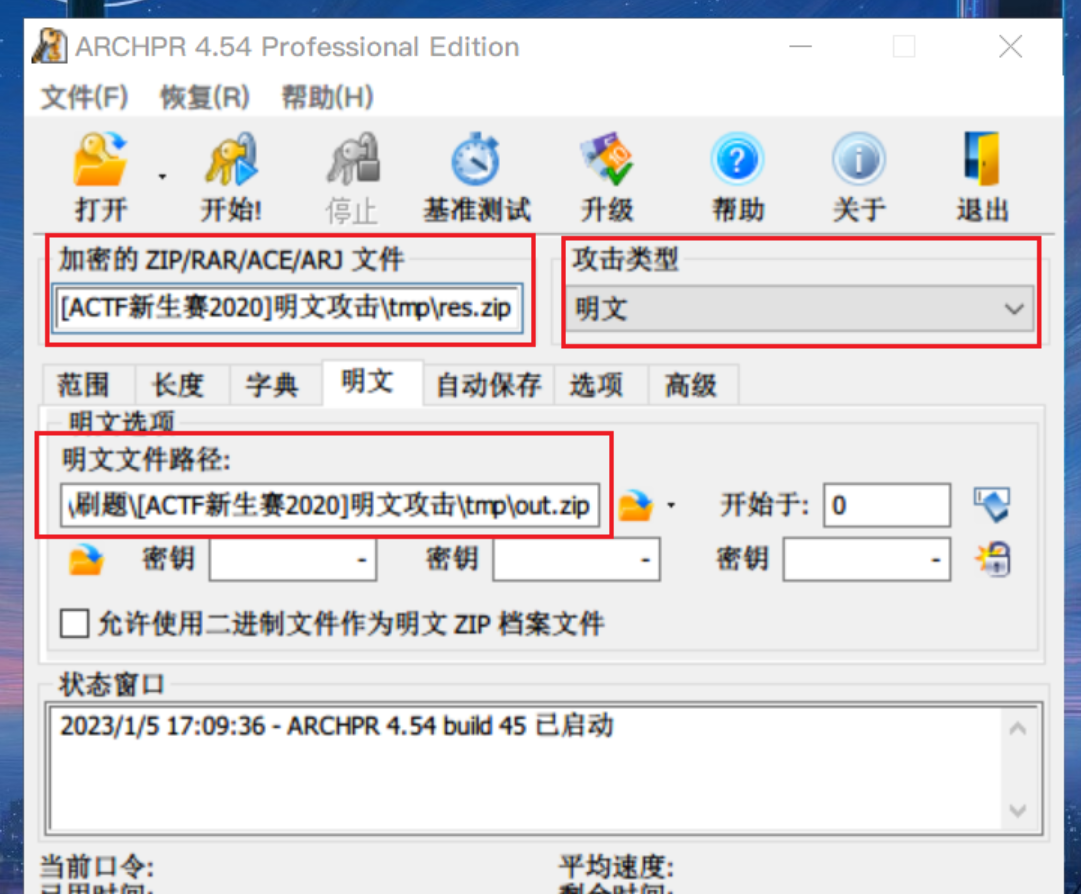
一开始会显示“搜索密钥”,等待一段时间(10分钟左右)后,当提示“尝试找回口令”便可以停止了,没必要找回口令,因为我们的目的是破解出文件。

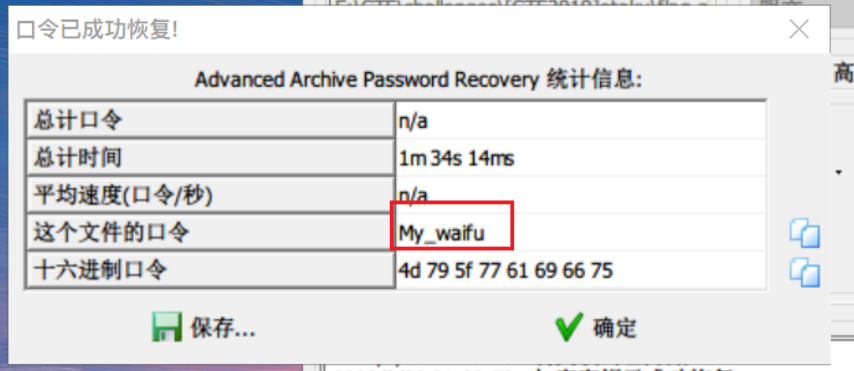
点击停止之后弹出提示框提示成功恢复加密密钥,此时点击确认会提示选择保存输出文件,正常保存即可
将该输出文件解压便得到secret.txt,里面就是flag
ACTF{3te9_nbb_ahh8}
[MRCTF2020]Hello_ misc
一个加密rar压缩包,一个png图片,文件名提示我们修复
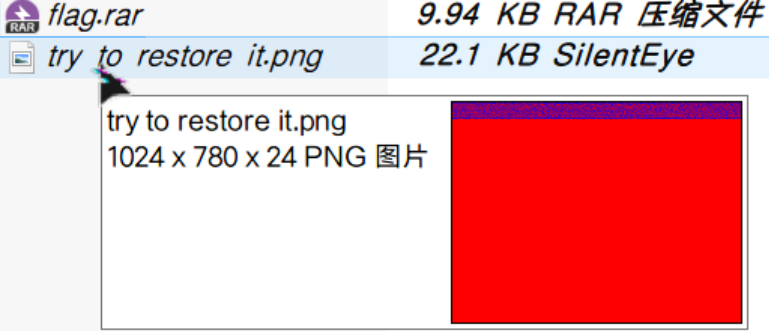
010 editor查看这个png文件,可以看到IEND块后面藏了个加密过的压缩包
——知识储备
PNG文件有一个图像结束数据IEND(image trailer chunk),用来标记PNG文件或者数据流已经结束,并且必须要放在文件的尾部,且其值固定为
“00 00 00 00 49 45 4E 44 AE 42 60 82”这是因为由于数据块结构的定义,IEND数据块的长度总是0(00 00 00 00,除非人为加入信息),数据标识总是IEND(49 45 4E 44),因此,CRC码也总是
AE 42 60 82。同时在IEND块后面添加任何的字符都对文件的打开造成不了影响,那我们就可以在这里藏一些数据(除了ios系统会直接提示),所以一些MISC题经常会把信息隐写在后面。
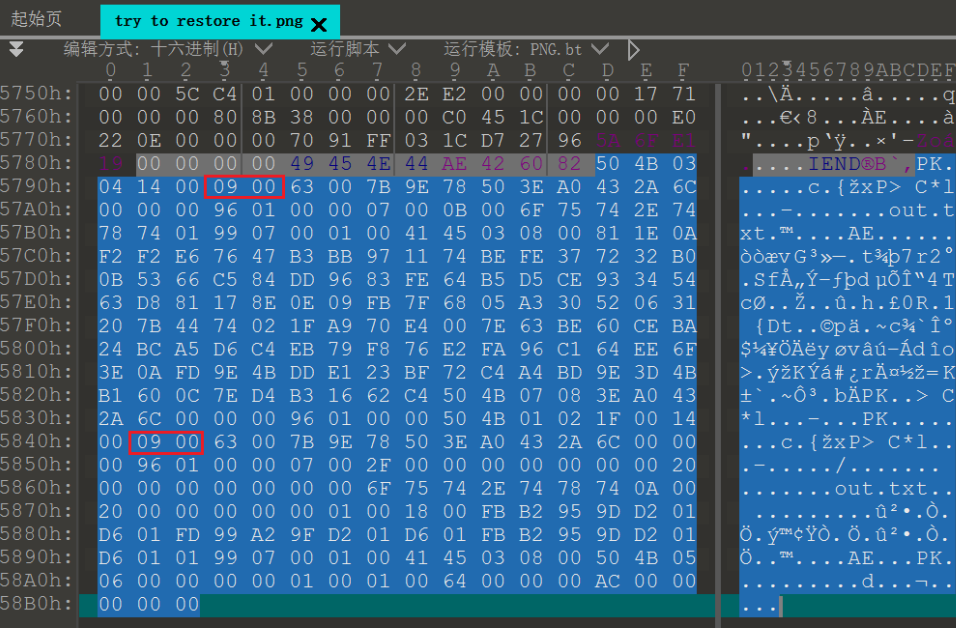
只能再从图片本身入手,R通道最底层有个图片
导出后得到压缩包密码:!@#$%67*()-+

解压缩后得到一个文本文件,想到TTL隐写
写个脚本提取
with open("out.txt",'r') as fr:
s=''
out=''
for i in fr.readlines():
if int(i[:-1])==63:
s+='00'
if int(i[:-1])==127:
s+='01'
if int(i[:-1])==191:
s+='10'
if int(i[:-1])==255:
s+='11'
for i in range(0,len(s),8):
try:
data=chr(int(s[i:i+8],2))
print(data,end='')
except:
continue
得到rar压缩包的密码
rar-passwd:0ac1fe6b77be5dbe
解压后根据压缩包内部结构特征可以发现这其实是doc文件

改后缀后打开发现一些空白,感觉是用白色字隐藏,改字体颜色显示出内容。

MTEwMTEwMTExMTExMTEwMDExMTEwMTExMTExMTExMTExMTExMTExMTExMTExMTExMTAxMTEwMDAwMDAxMTExMTExMTExMDAxMTAx
MTEwMTEwMTEwMDAxMTAxMDExMTEwMTExMTExMTExMTExMTExMTExMTExMTExMTExMTExMTAxMTExMTExMTExMTExMTEwMTEwMDEx
MTEwMDAwMTAxMTEwMTExMDExMTEwMTExMTExMTAwMDExMTExMTExMTExMDAxMDAxMTAxMTEwMDAwMDExMTExMDAwMDExMTExMTEx
MTEwMTEwMTAwMDAxMTExMDExMTEwMTExMTExMDExMTAxMTExMTExMTEwMTEwMTEwMTAxMTExMTExMTAwMTEwMTExMTExMTExMTEx
MTEwMTEwMTAxMTExMTExMDExMTEwMTExMTAxMDExMTAxMTExMTExMTEwMTEwMTEwMTAxMTAxMTExMTAwMTEwMTExMTExMTExMTEx
MTEwMTEwMTAwMDAxMTAwMDAwMTEwMDAwMDAxMTAwMDExMTAwMDAwMTEwMTEwMTEwMTAxMTEwMDAwMDAxMTExMDAwMDExMTExMTEx
将这组字符串每一行都用base64解码,脚本如下
import base64
with open('1.txt','r') as file:
for i in file.readlines():
line = str(base64.b64decode(i),'utf-8')
print(line)
是一个字符图形
用空白代替1会显示得更明显些,最终脚本如下
import base64
with open('1.txt','r') as file:
for i in file.readlines():
line = str(base64.b64decode(i),'utf-8')
print(line.replace('1',' '))
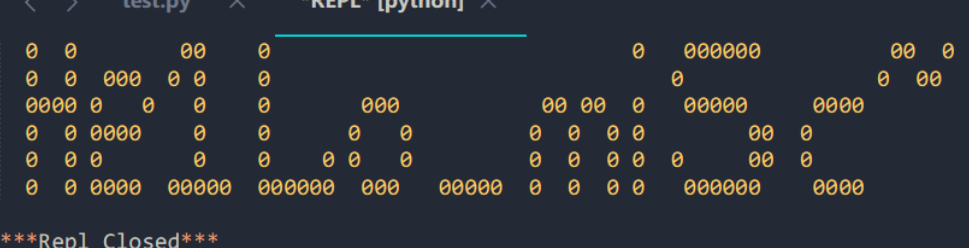
得到flag
flag{He1Lo_mi5c~}
[SCTF2014]misc400b
拿到手是个png图片
图片末尾没有附加其他文件,但有冗余的IDAT块,因为倒数第二个IDAT块的大小还没满10000H,理论上最后两个IDAT块应该合并,推断最后一个数据块中含有隐藏数据。
——IDAT隐写
图像数据块 IDAT(image data chunk)是PNG文件中很重要的一种数据块
- 它用于储存图像实际的像素数据
- 在图像数据流中可包含很多个连续顺序的IDAT块,若写入一个多余的IDAT也不会明显影响肉眼对图片的观察。
- 数据采用 LZ77 算法的派生算法进行压缩,可以用 zlib 对数据进行解压缩
值得注意的是,通常IDAT 块只有当上一个块充满时,才会继续一个新的块。一旦出现不符合这个规律的情况(有一块IDAT还没填满但紧跟其后的是一个新的块),那么就是人为添加了数据块。利用PNGcheck软件可以对其验证,利用pngcheck -v a.jpg可以对图片的文件结构进行检测。此外文件结构中可能会存在size=0的IDAT块,这说明相应的块是无法用肉眼看到的,也即隐藏的内容。
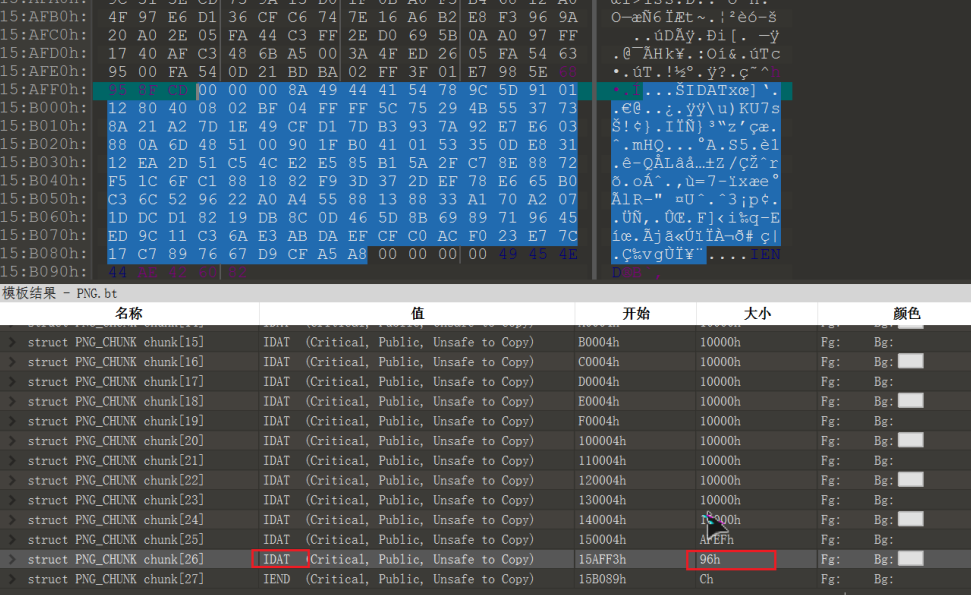
那么只要将数据块的数据部分(下图中选中的部分)提取出来用写个zlib脚本解压缩就好
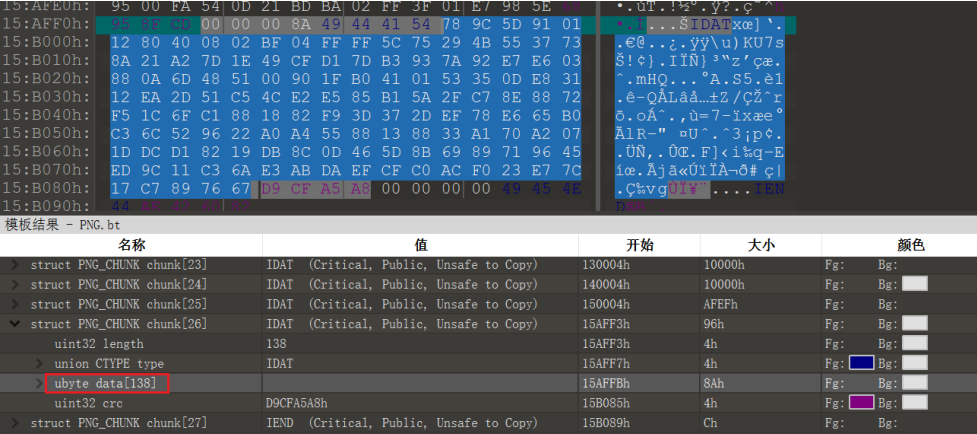
python2下运行如下脚本
import zlib
import binascii
data="78 9C 5D 91 01 12 80 40 08 02 BF 04 FF FF 5C 75 29 4B 55 37 73 8A 21 A2 7D 1E 49 CF D1 7D B3 93 7A 92 E7 E6 03 88 0A 6D 48 51 00 90 1F B0 41 01 53 35 0D E8 31 12 EA 2D 51 C5 4C E2 E5 85 B1 5A 2F C7 8E 88 72 F5 1C 6F C1 88 18 82 F9 3D 37 2D EF 78 E6 65 B0 C3 6C 52 96 22 A0 A4 55 88 13 88 33 A1 70 A2 07 1D DC D1 82 19 DB 8C 0D 46 5D 8B 69 89 71 96 45 ED 9C 11 C3 6A E3 AB DA EF CF C0 AC F0 23 E7 7C 17 C7 89 76 67".replace(" ","")
IDAT = data.decode('hex') #填入dump出的IDAT的数据部分
result = binascii.hexlify(zlib.decompress(IDAT))
print (result.decode('hex'))
print (len(result.decode('hex')))
输出一堆长度为625B的01字串,可以尝试用这个绘制二维码

1111111000100001101111111100000101110010110100000110111010100000000010111011011101001000000001011101101110101110110100101110110000010101011011010000011111111010101010101111111000000001011101110000000011010011000001010011101101111010101001000011100000000000101000000001001001101000100111001111011100111100001110111110001100101000110011100001010100011010001111010110000010100010110000011011101100100001110011100100001011111110100000000110101001000111101111111011100001101011011100000100001100110001111010111010001101001111100001011101011000111010011100101110100100111011011000110000010110001101000110001111111011010110111011011
长度为625,那么生成的应该是25$\times$25的二维码,脚本如下,Python3下运行得到二维码
from PIL import Image
data="1111111000100001101111111100000101110010110100000110111010100000000010111011011101001000000001011101101110101110110100101110110000010101011011010000011111111010101010101111111000000001011101110000000011010011000001010011101101111010101001000011100000000000101000000001001001101000100111001111011100111100001110111110001100101000110011100001010100011010001111010110000010100010110000011011101100100001110011100100001011111110100000000110101001000111101111111011100001101011011100000100001100110001111010111010001101001111100001011101011000111010011100101110100100111011011000110000010110001101000110001111111011010110111011011"
width = 25
height = 25
im = Image.new("RGB", (width, height)) # 创建图片
for i in range(0, width):
line = data[width*i:width*(i+1)] # 获取一行
for j in range(0, height):
if line[j] == '0':
im.putpixel((i, j), (255, 255, 255)) # rgb转化为像素
else:
im.putpixel((i, j), (0, 0, 0)) # rgb转化为像素
im.save("out_CQR.png")
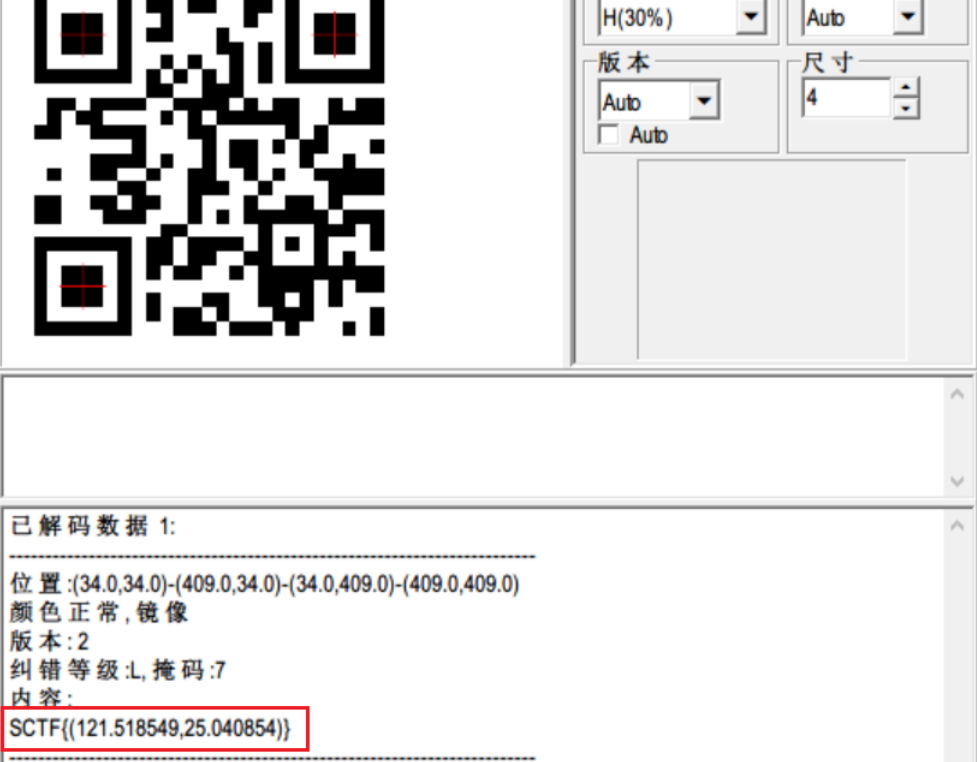
扫描提取出flag
SCTF{(121.518549,25.040854)}
[WUSTCTF2020]spaceclub
文本内容由长度为6和12两种空格字串组成,可以对应两种不同状态,试着将每一行对应一个二进制位,长空格是1,短空格是0,全部替换掉并进行字符编码,脚本如下
with open("attachment.txt",'r') as fr:
s=''
for line in fr.readlines():
if len(line)>9:
s+='1'
else:
s+='0'
for i in range(0,len(s),8):
try:
data=chr(int(s[i:i+8],2))
print(data,end='')
except:
continue
得到flag
wctf2020{h3re_1s_y0ur_fl@g_s1x_s1x_s1x}
[UTCTF2020]zero
根据标题想到零宽字符隐写,用在线工具解码得到flag
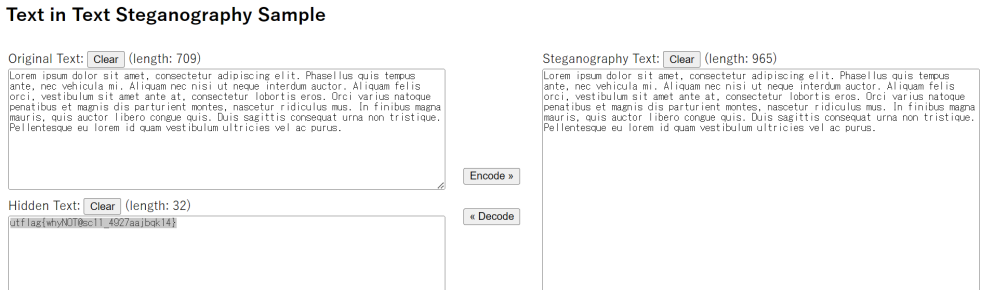
utflag{whyNOT@sc11_4927aajbqk14}
[MRCTF2020]Unravel!!

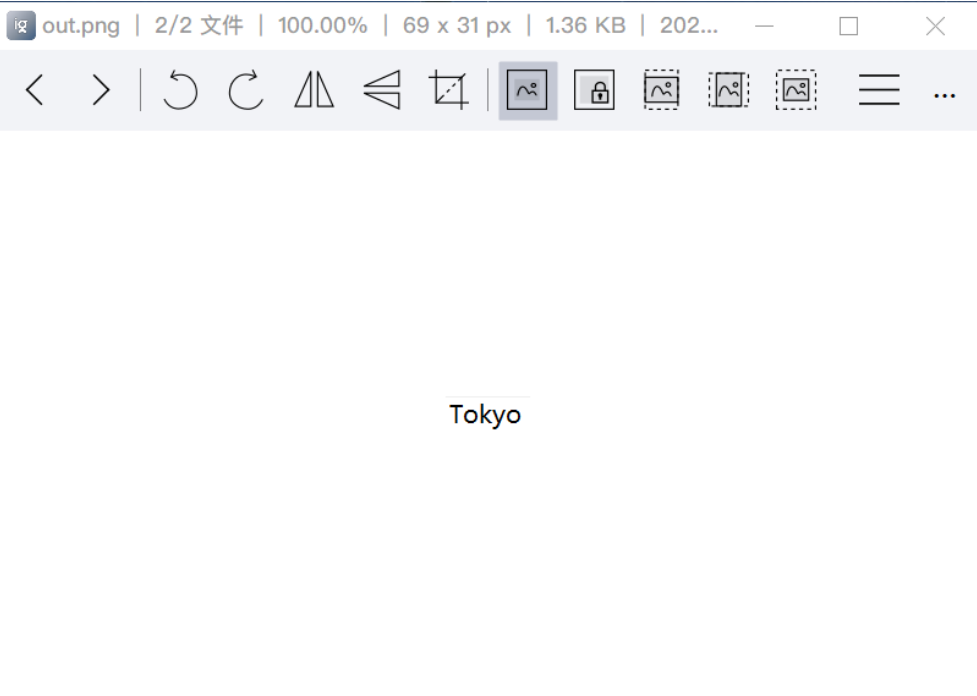
010 editor打开JM.png图片发现这个图片后面还藏了个图片
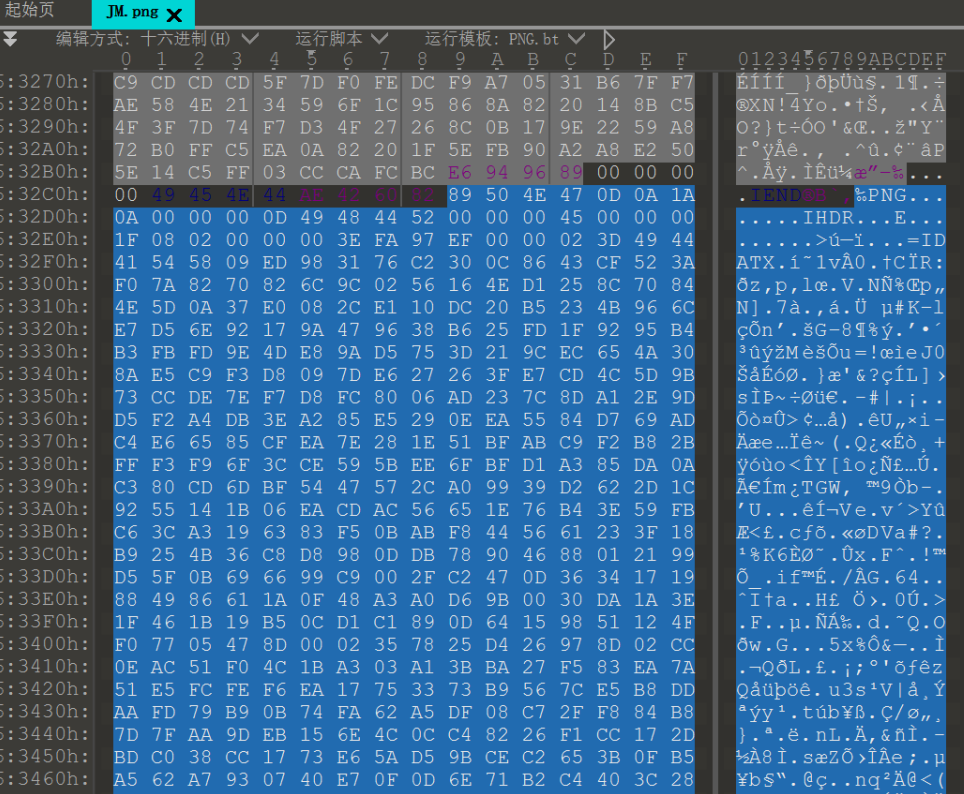
导出后得到Tokyo字串,推测可能是win-win.zip压缩包的口令,但尝试过解压发现并不是
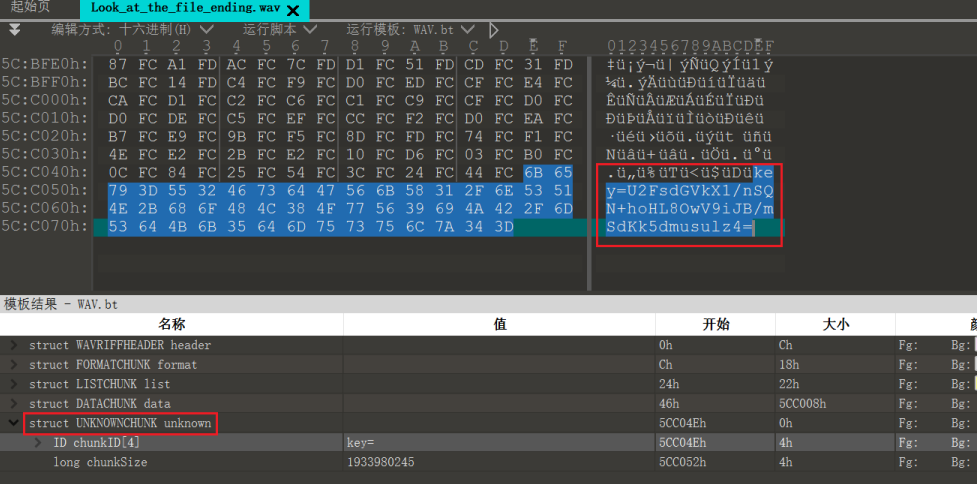
wav文件后有一个key,内容为U2FsdGVkX1/nSQN+hoHL8OwV9iJB/mSdKk5dmusulz4=,根据U2F可以推测这个是经过对称加密过后的密文
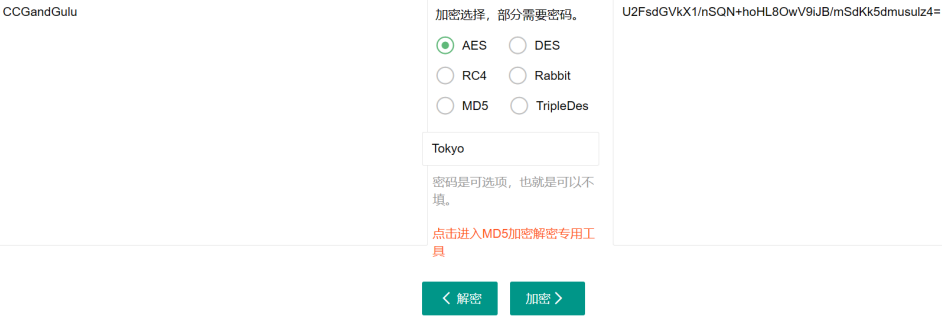
试着用Tokyo作为密钥,用这个在线工具解密得到CCGandGulu
再它来解压win-win.zip发现可以解压成功并得到Ending.wav,这个文件后并未隐藏数据,进一步推测可能是SilentEye隐写,提取得到flag
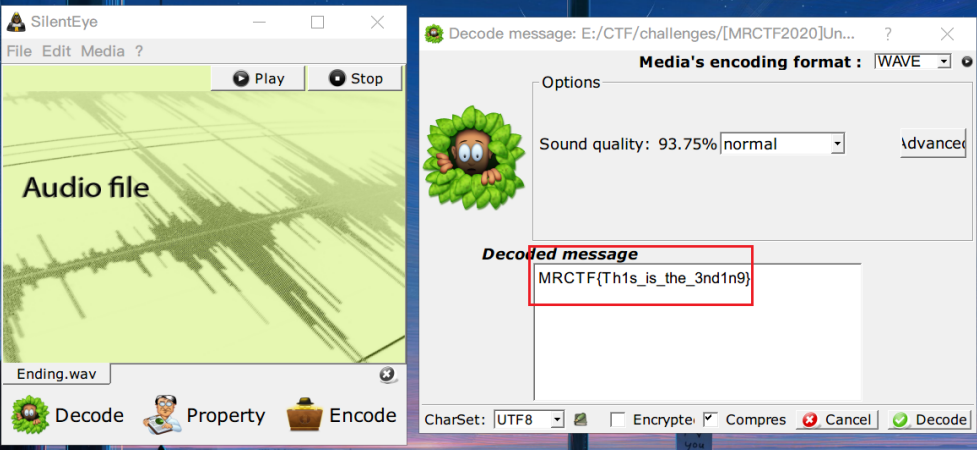
MRCTF{Th1s_is_the_3nd1n9}
[ACTF新生赛2020]music
得到一个无法正常打开的音频文件,用010 Editor打开;
正常的音频文件开头三个字节是00 00 00,但这个文件打开后前三个字节是0xA1,0与任何数进行与(&)运算得到的还是0,0与任何数进行或(|)运算或者是异或(^)运算得到的是这个数本身,推测这个文件可能是原文件整体与0xA1异或后得到的文件,根据异或运算的性质——\(A\bigoplus B\bigoplus B=A\),那么只需要再将整个文件与0xA1异或即可还原出原来的文件。
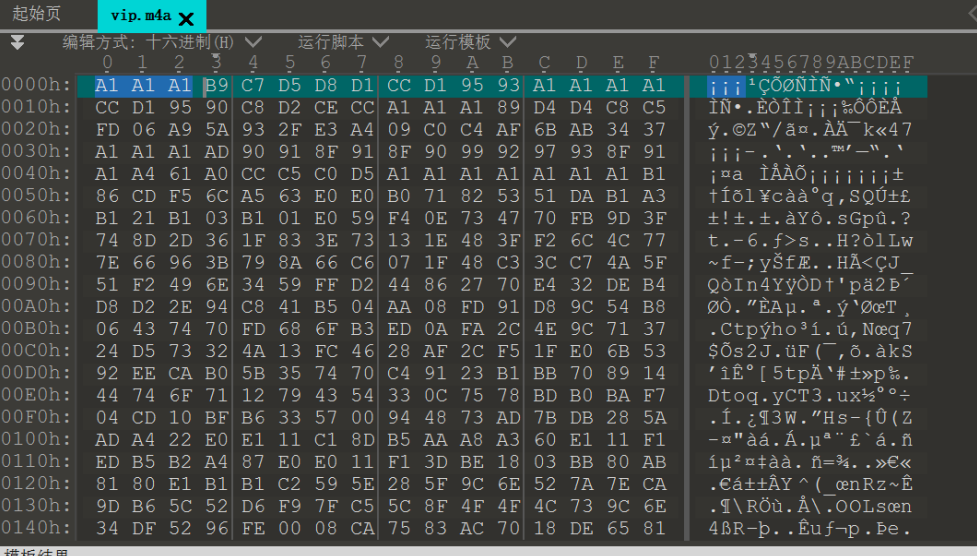
用010 Editor内置的计算工具进行异或运算(工具>十六进制运算>二进制异或)
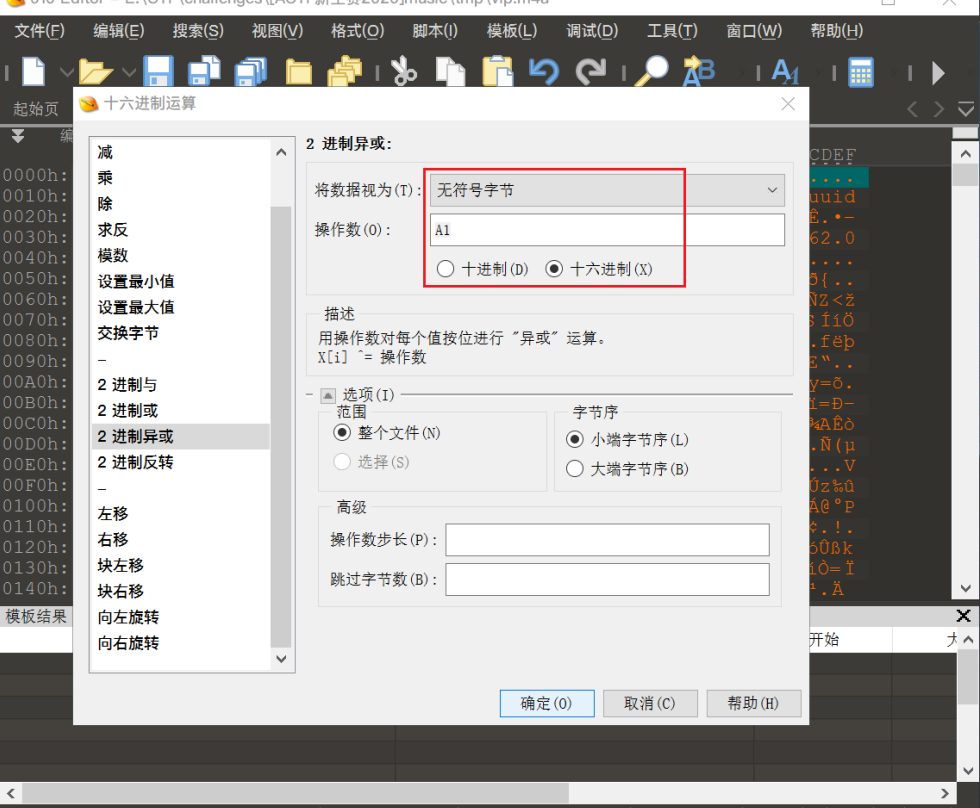
点击确定之后就可以还原出原始文件
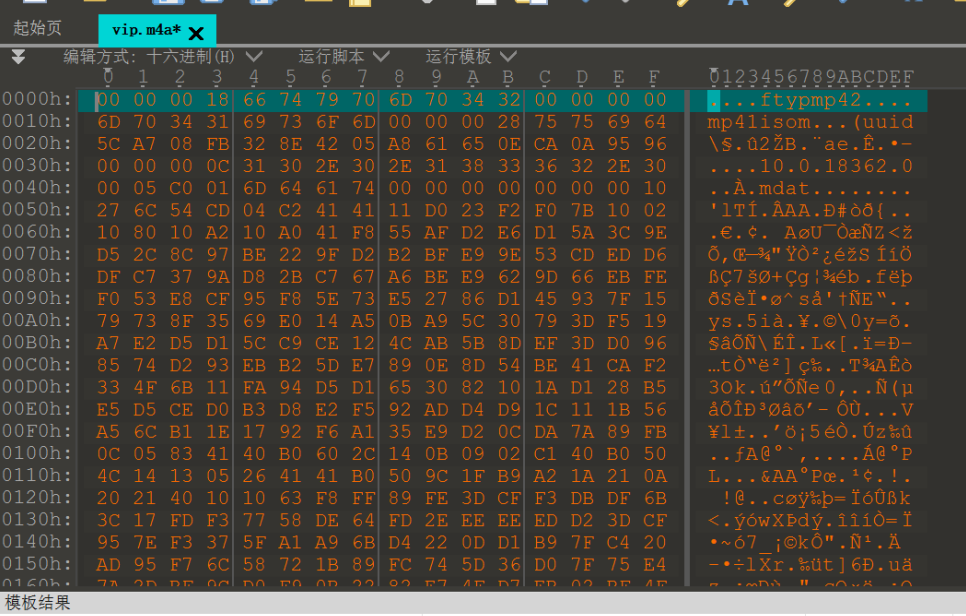
听内容得到:actfabcdfghijk
flag{abcdfghijk}
buu-二维码
得到的是被撕破的二维码

拼接一下得到flag
flag{7bf116c8ec2545708781fd4a0dda44e5}
[GKCTF 2021]签到
得到一个流量包,用wireshark打开,发现解析出很多TCP与HTTP报文,分析的侧重点应放在数据部分。
过滤栏输入tcp.stream eq <编号>(编号从0开始)获取指定编号的TCP流记录,也可以选中一个TCP报文记录右击追踪TCP流。
我们从0号TCP流(即对应命令tcp.stream eq 0)开始分析,其实前3个TCP连接(编号0 \(\sim\) 2)并没有传输数据信息,到3号TCP流(tcp.stream eq 3)开始才有数据信息。追踪HTTP流可以看到客户端向服务器发送了ls指令用于显示当前目录下的所有文件名,服务端随机向客户端返回结果634768774c6d78735a57687a6347313043673d3d
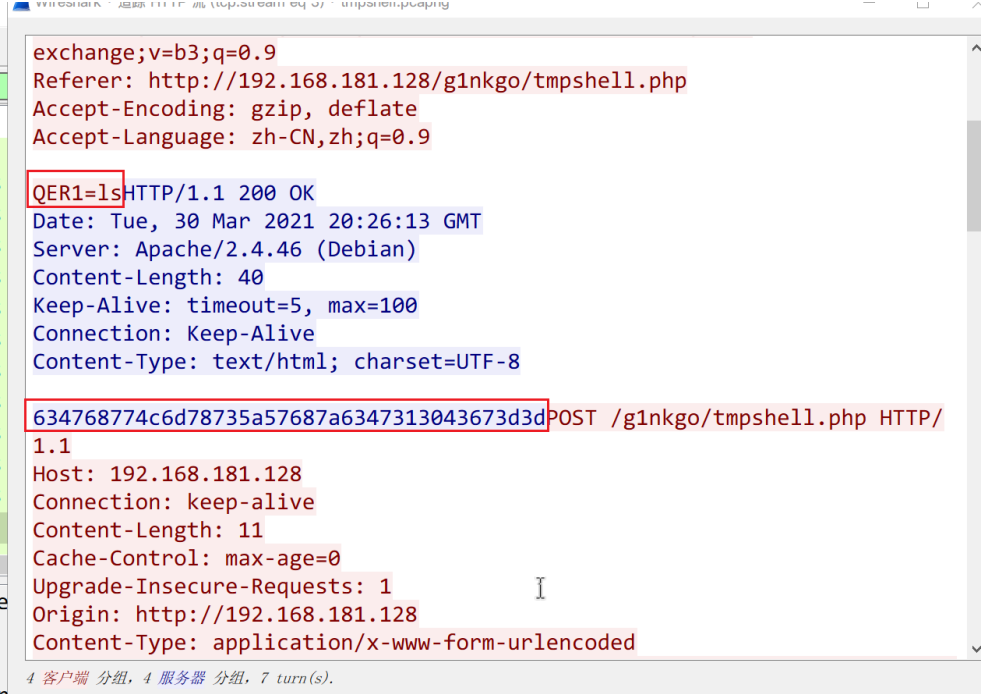
写个脚本将这串数字解码一下
s='634768774c6d78735a57687a6347313043673d3d'
out=''
for i in range(0,len(s),2):
out+=chr(int('0x'+s[i:i+2],16))
print(out)
发现输出结果是base64编码,解码之后还是逆序输出的
修改后最终脚本如下
import base64
s='634768774c6d78735a57687a6347313043673d3d'
out=''
for i in range(0,len(s),2):
out+=chr(int('0x'+s[i:i+2],16))
#print(out)
print(base64.b64decode(out).decode()[::-1])
输出结果为tmpshell.php(下面的分析都可以用这个脚本将服务端返回的数据解码)
那我们接着分析,客户紧接着发出whoami的指令,服务端返回的是www-data,然后客户端再次发出了ls来查询目录,返回的文件名中可以注意到有f14g这个文件,里面的内容应该就是flag,至此第4个TCP流分析完毕,下面只需要注意是否有某个TCP流对这个文件有过诸如显示文件内容的操作即可定位该文件内容(即flag)的位置
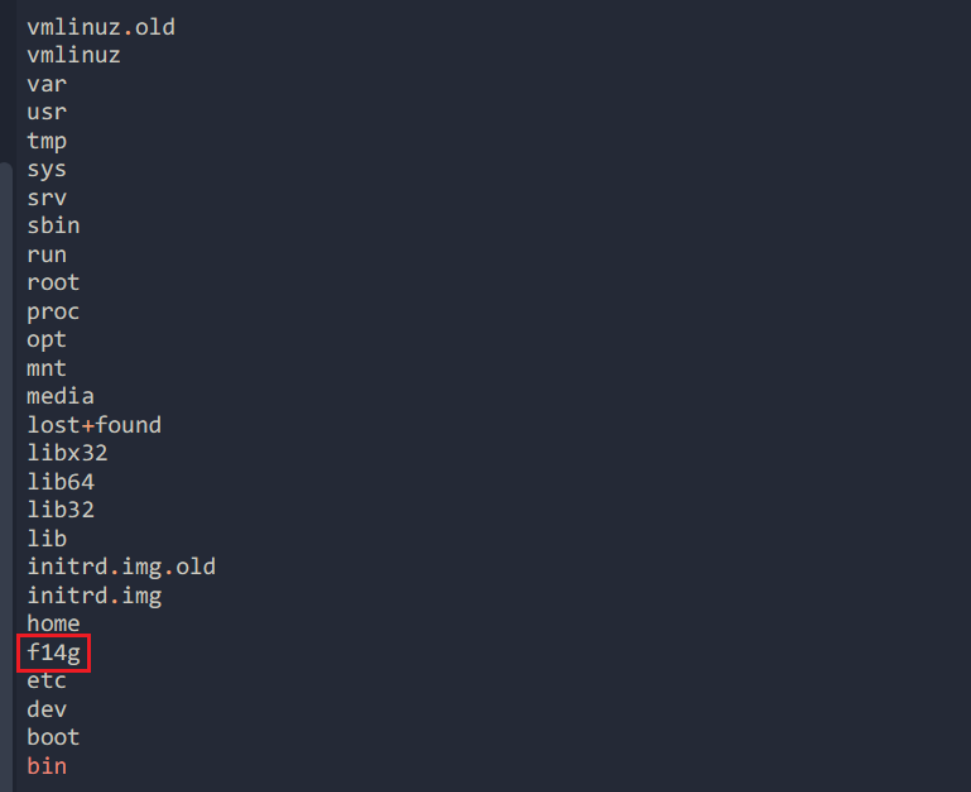
接着排除了4号TCP流(客户在这个流的操作仅仅是显示了一些无关紧要的文件),直到5号TCP流(如下,%2F对应/),客户试图让服务器返回f14g文件的内容
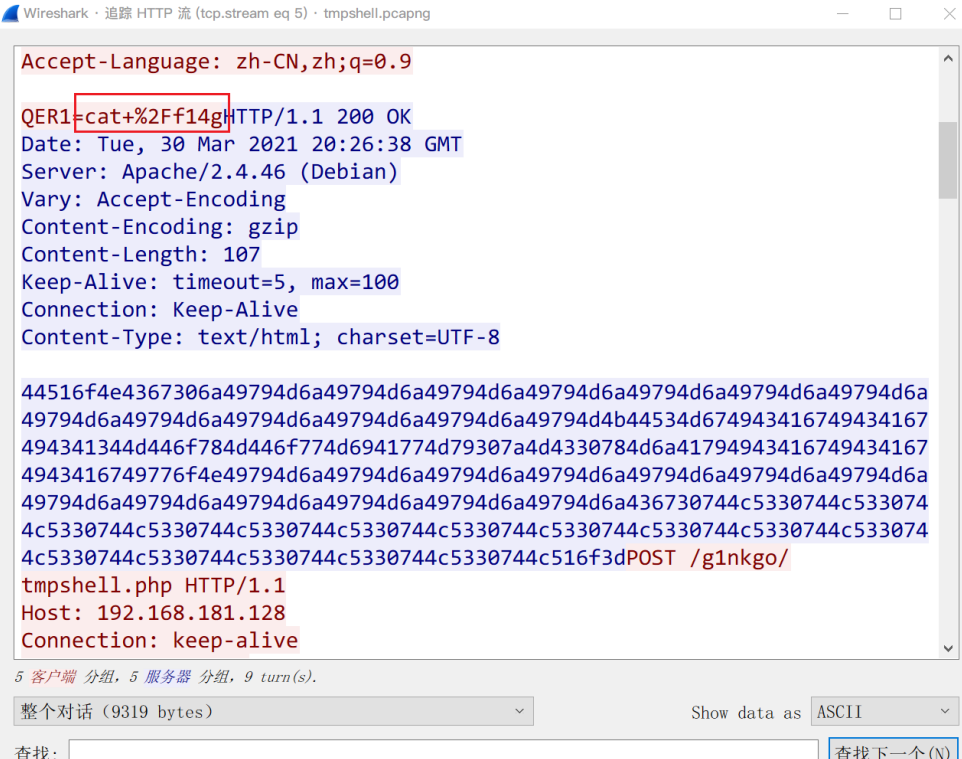
将服务器返回的数据解码得到的是如下的结果,显然不是flag
--------------------------------------------------
#######################################
# 2021-03-30 20:01:08 #
#######################################
忽略一些多余的数据传输,继续向下翻可以发现客户紧接着再次令服务端返回f14g文件的内容,但这次貌似是让服务端先base64编码后再传送(%7C对应|),也就是说这部分数据进行了两次base64编码(因为原来传输时就需要一次base64编码)。
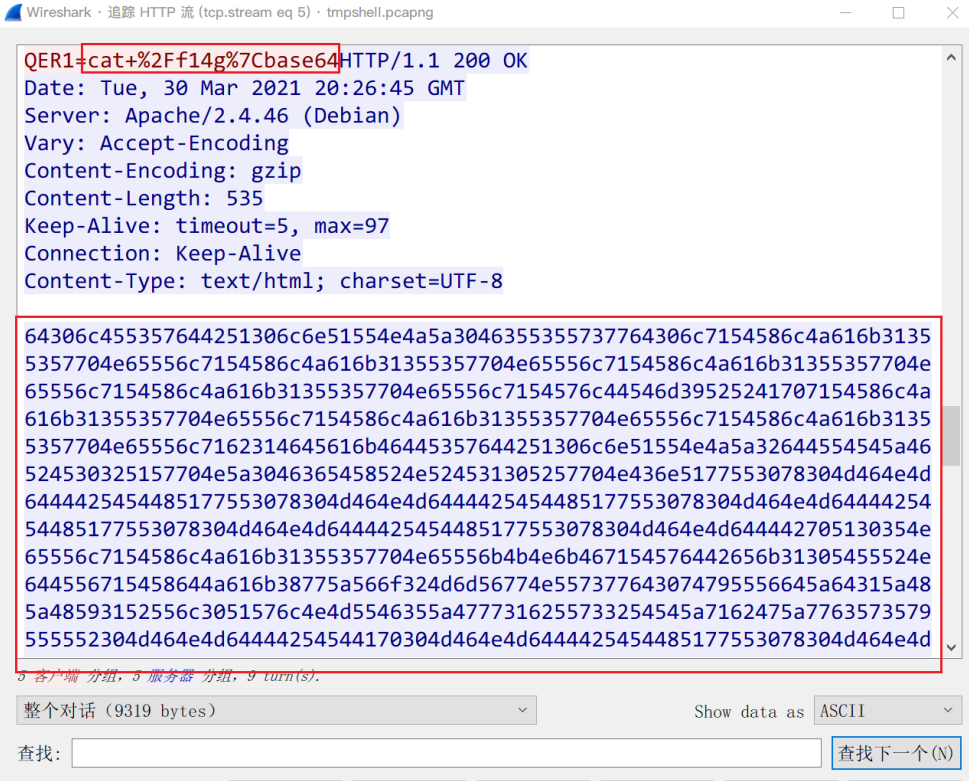
将这部分先进行一次解码,得到结果如下
Q0NDQ0MhIQ==
Y2MpKVvliKDpmaRdIFvliKDpmaRdIDAwbW1lZV9fR0dra0NDNDRGRl9fbW0xMXNzaWlDQ0NDQ0ND
MCAyMDowMToxMw0KW+Wbnui9pl0gW+Wbnui9pl0gW+Wbnui9pl0gZmZsbGFhZ2d7e319V1dlZWxs
LS0tLS0tLS0tLS0NCueql+WPozoqbmV3IDUyIC0gTm90ZXBhZCsrDQrml7bpl7Q6MjAyMS0wMy0z
MDE6MTMNClvlm57ovaZdIA0KLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0t
LS0tLS0tDQrnqpflj6M6Km5ldyA1MiAtIE5vdGVwYWQrKw0K5pe26Ze0OjIwMjEtMDMtMzAgMjA6
IyMjIyMjIyMjIyMNCi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0t
MjEtMDMtMzAgMjA6MDE6MDggICAgICAgICAjDQojIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMj
DQoNCiMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIw0KIyAgICAgICAgIDIw
再次进行base64解码
import base64
s=['Q0NDQ0MhIQ==',
'Y2MpKVvliKDpmaRdIFvliKDpmaRdIDAwbW1lZV9fR0dra0NDNDRGRl9fbW0xMXNzaWlDQ0NDQ0ND',
'MCAyMDowMToxMw0KW+Wbnui9pl0gW+Wbnui9pl0gW+Wbnui9pl0gZmZsbGFhZ2d7e319V1dlZWxs',
'LS0tLS0tLS0tLS0NCueql+WPozoqbmV3IDUyIC0gTm90ZXBhZCsrDQrml7bpl7Q6MjAyMS0wMy0z',
'MDE6MTMNClvlm57ovaZdIA0KLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0t',
'LS0tLS0tDQrnqpflj6M6Km5ldyA1MiAtIE5vdGVwYWQrKw0K5pe26Ze0OjIwMjEtMDMtMzAgMjA6',
'IyMjIyMjIyMjIyMNCi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0t',
'MjEtMDMtMzAgMjA6MDE6MDggICAgICAgICAjDQojIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMj',
'DQoNCiMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIw0KIyAgICAgICAgIDIw'
]
for i in s[::-1]:
print(base64.b64decode(i).decode(),end='')
#######################################
# 2021-03-30 20:01:08 #
#######################################
--------------------------------------------------
窗口:*new 52 - Notepad++
时间:2021-03-30 20:01:13
[回车]
--------------------------------------------------
窗口:*new 52 - Notepad++
时间:2021-03-30 20:01:13
[回车] [回车] [回车] ffllaagg{{}}WWeellcc))[删除] [删除] 00mmee__GGkkCC44FF__mm11ssiiCCCCCCCCCCCC!!
于是根据输出结果简单分析(重复字母去除)得到flag
flag{Welc0me_GkC4F_m1siCCCCCC!}
[MRCTF2020]pyFlag
得到的是三个图片,在010 Editor中打开可以看到图片的结尾附加额外的数据
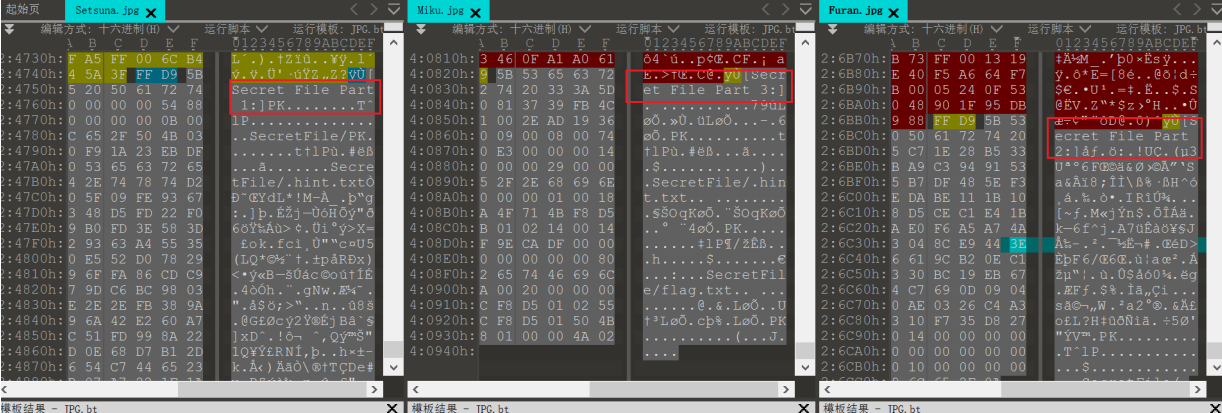
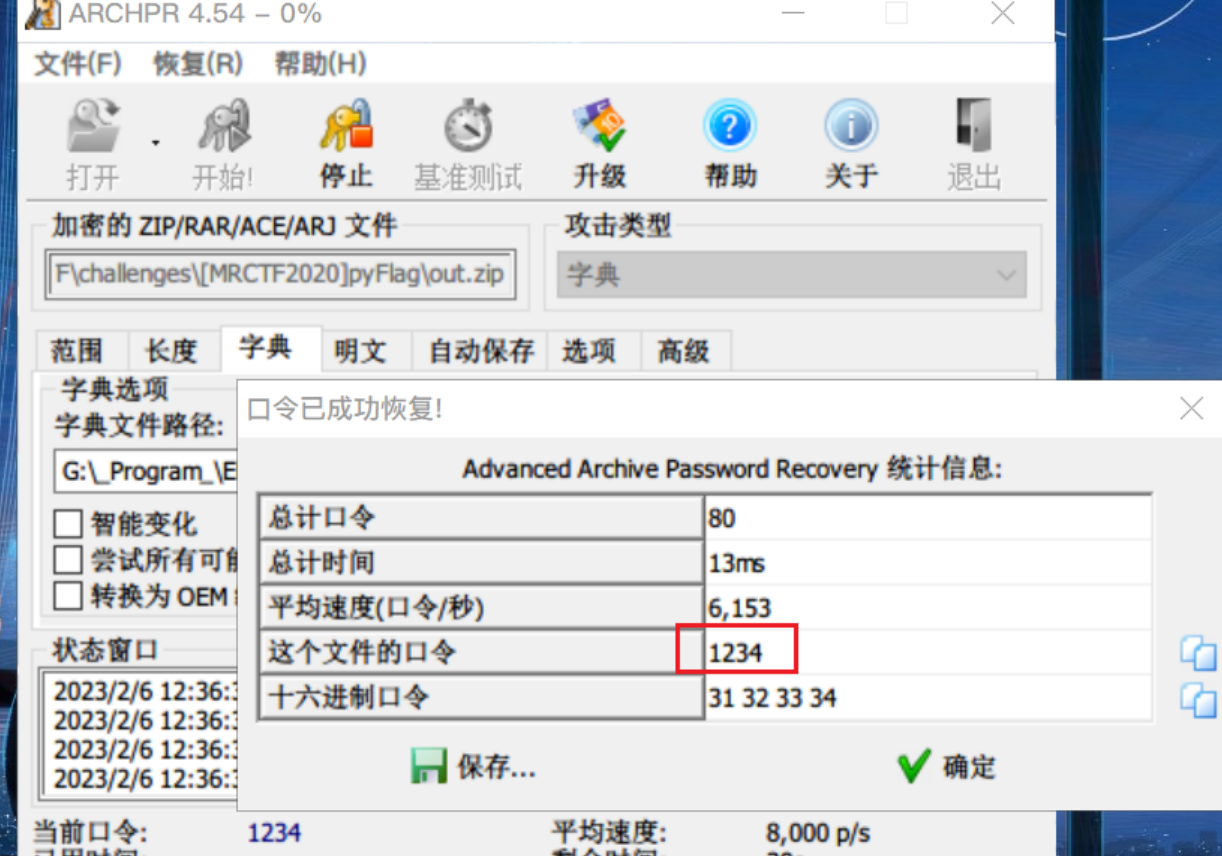
按照编号的顺序可以将这些数据拼接成一个压缩包,但需要口令才能解压缩
我们可以排除伪加密的可能,同时也无法进行已知明文攻击,所以只能尝试字典暴破,最终也是成功得到口令1234
解压后其实得到的是两个文件,有一个文件是隐藏状态的(查看压缩文件目录可以看出来)
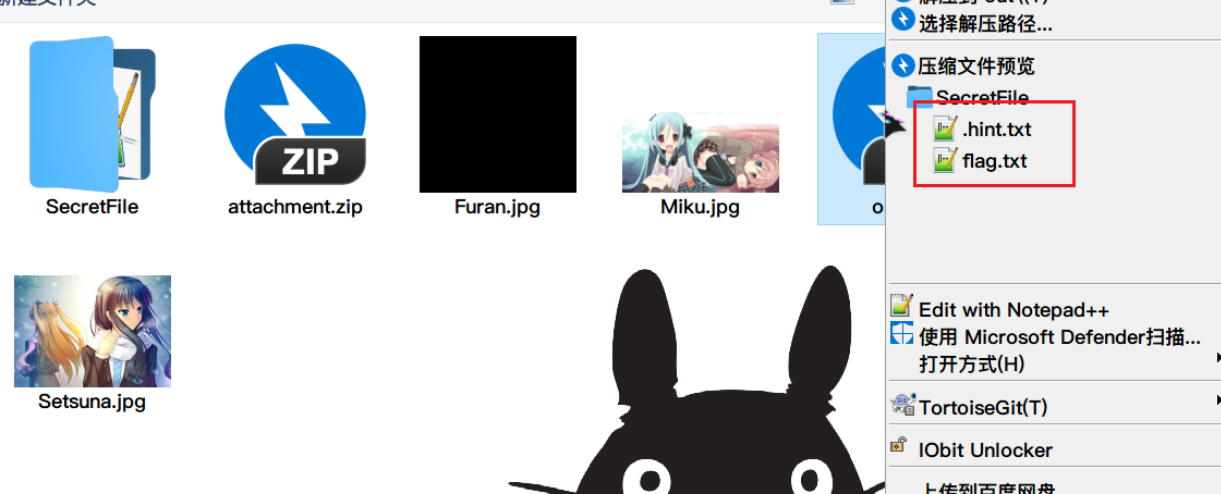
两个文件内容一个是提示,一个是flag的码文

根据提示知道是base家族那就好办了,直接用Basecrack,用这个工具命令行输入python basecrack.py --magic后粘贴码文按回车,可以得到flag
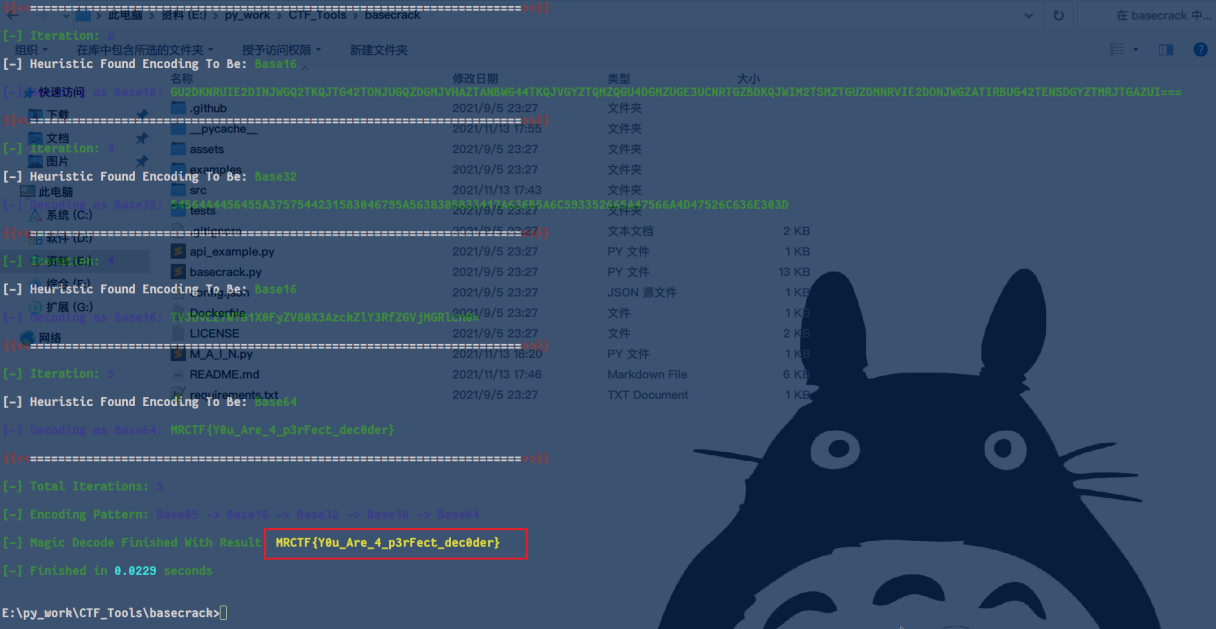
MRCTF{Y0u_Are_4_p3rFect_dec0der}
[MRCTF2020]不眠之夜
一共121张图片,注意到有一个图片无法正常预览,010 Editor中打开后发现是一张无效图片,直接删除
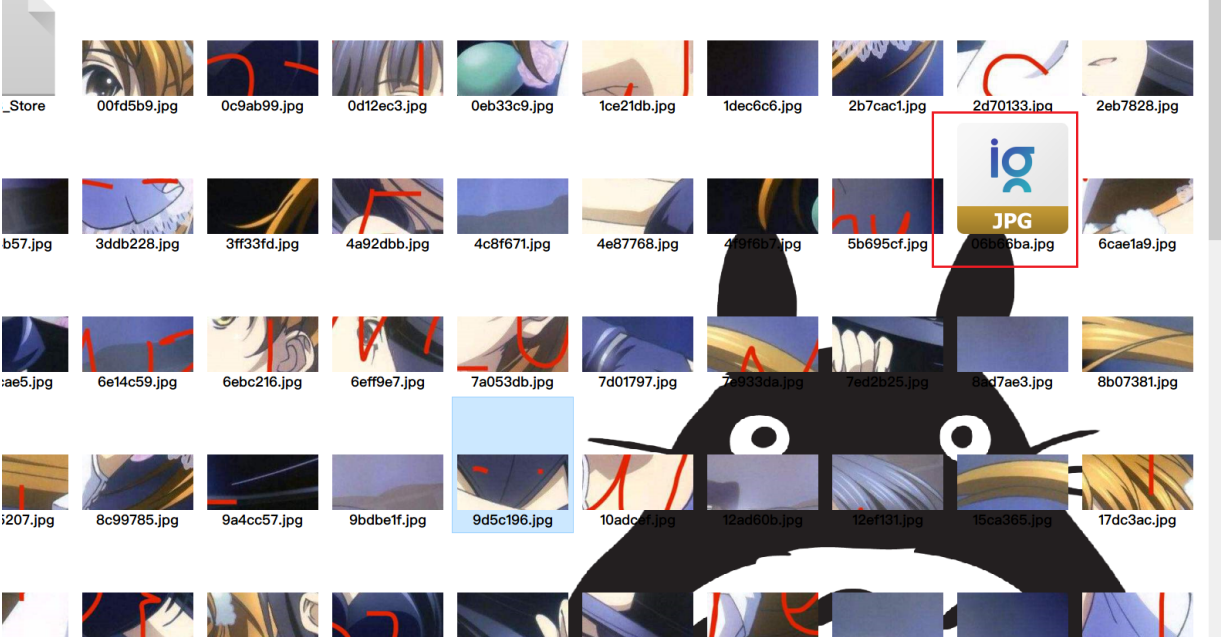
接着就是用montage和gaps工具进行图片拼接
montage和gaps的安装详见《CTF-MISC总结 - Em0s_Erit - 博客园 (cnblogs.com)》的“十四”
montage *.jpg -tile 10x12 -resize 4000x2400 -geometry +0+0 out.jpg #把图片碎片合成一个图片
gaps --image=out.jpg --generations=120 --population=120 --size=200 #还原原图片

MRCTF{Why_4re_U_5o_ShuL1an??}
buu-派大星的烦恼
派大星最近很苦恼,因为它的屁股上出现了一道疤痕!我们拍下了它屁股一张16位位图,0x22,0x44代表伤疤两种细胞,0xf0则是派大星的赘肉。还原伤疤,知道是谁打的派大星!(答案为32位的一串字符串) 注意:得到的 flag 请包上 flag{} 提交
可打印字符的ASCII码最高位不可能是1,所以只有可能0x22代表的是0,0x44代表1
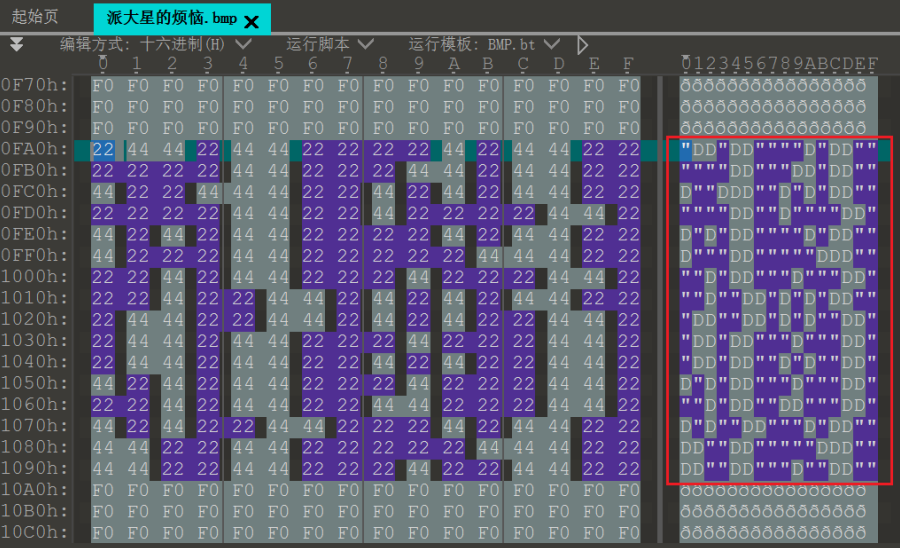
将这部分数据提取出来
"DD"DD""""D"DD""""""DD"""DD"DD""D""DDD""D"D"DD""""""DD""D""""DD"D"D"DD""""D"DD""D"""DD"""""DDD""""D"DD"""D"""DD"""D""DD"D"D"DD"""DD""DD"D"D""DD""DD"DD"""D"""DD""DD"DD""D"D""DD"D"D"DD"""D"""DD"""D"DD""DD"""DD"D"D""DD"""D"DD""DD""DD"""""DDD""DD""DD"""D""DD""
写脚本过程中发现数据需要逆序解码得到的才不是乱码,此外解码出来的字符还要再逆置才是最终的flag
s='"DD"DD""""D"DD""""""DD"""DD"DD""D""DDD""D"D"DD""""""DD""D""""DD"D"D"DD""""D"DD""D"""DD"""""DDD""""D"DD"""D"""DD"""D""DD"D"D"DD"""DD""DD"D"D""DD""DD"DD"""D"""DD""DD"DD""D"D""DD"D"D"DD"""D"""DD"""D"DD""DD"""DD"D"D""DD"""D"DD""DD""DD"""""DDD""DD""DD"""D""DD""'
tmp=flag=''
for i in s:
if ord(i)==0x22:
tmp+='0'
else:
tmp+='1'
tmp1=tmp[::-1]
for i in range(0,len(tmp1),8):
flag+=chr(int(tmp1[i:i+8],2))
print('flag{'+flag[::-1]+'}')
flag{6406950a54184bd5fe6b6e5b4ce43832}
[UTCTF2020]File Carving
拿到手是一个图片文件
图片文件的末尾附加了一个压缩包
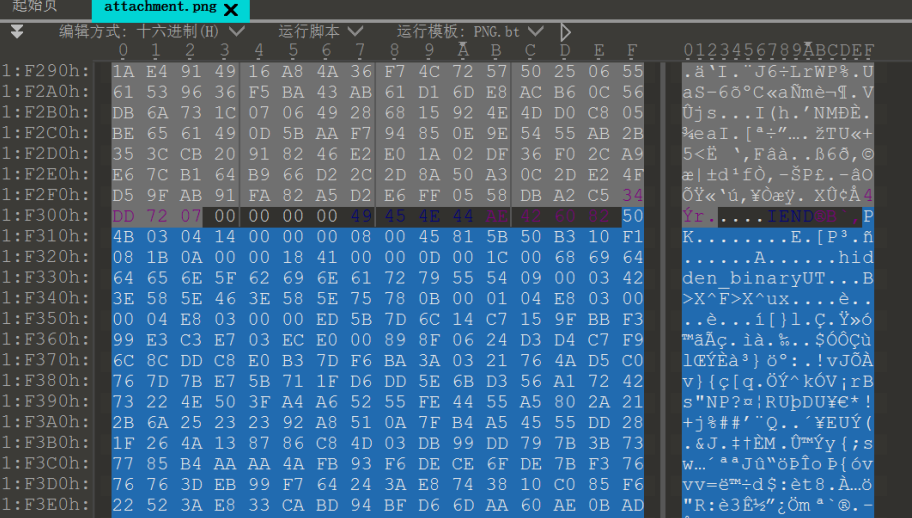
解压得到一个64位可执行文件
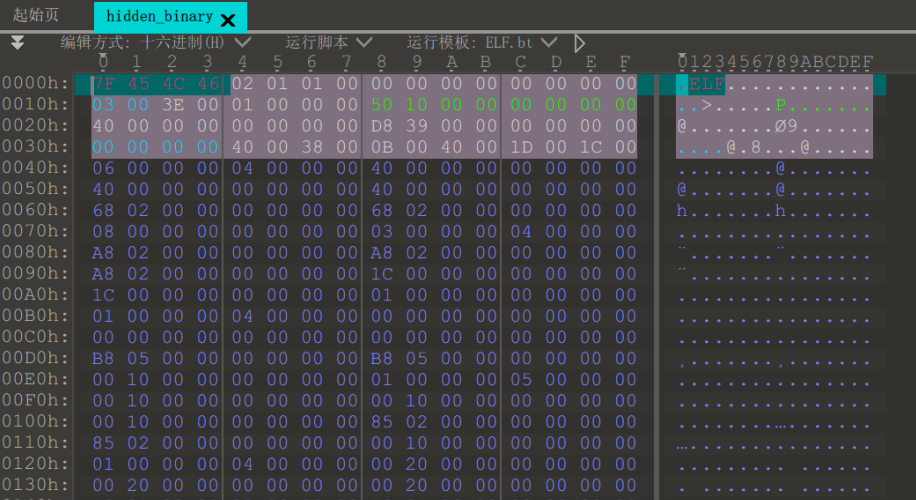
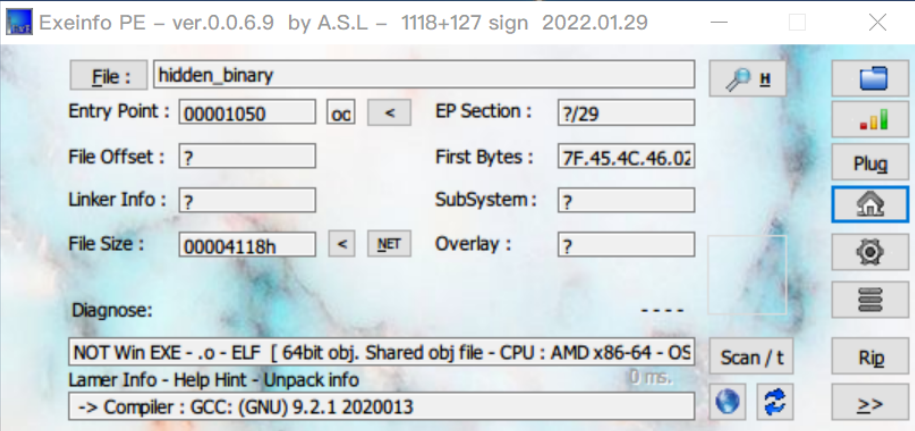
IDA64中打开,main函数处F5反编译可以看到明文形式的flag
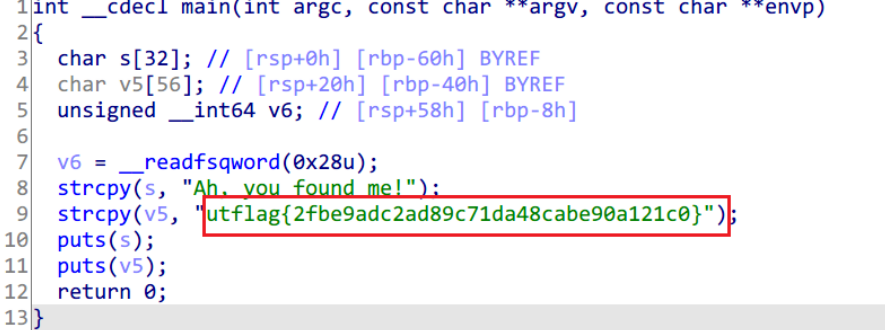
utflag{2fbe9adc2ad89c71da48cabe90a121c0}
[GKCTF 2021]excel 骚操作
拿到一个excel文档,点击一些空白单元格可以发现有些单元格看似空白,其实选中后可以显示内容
全选所有的单元格(点击A1左上角的那个箭头即可)右击打开设置单元格格式
调整为“G/通用格式”即可还原出隐藏的内容
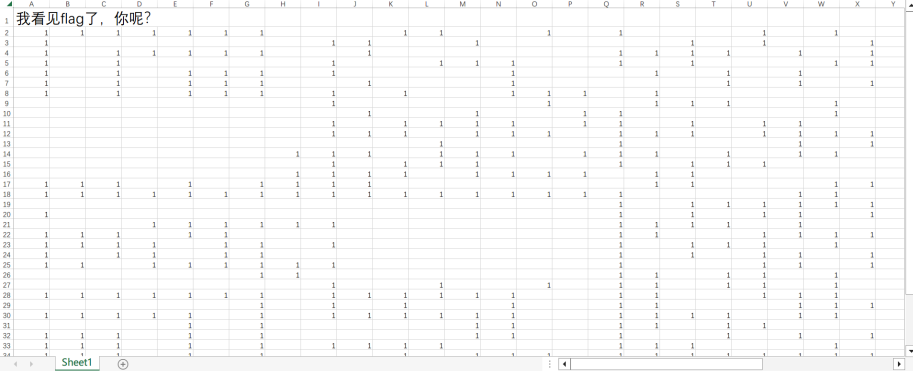
想到这些数值似乎可以组成图片?文本?
尝试将这些1都替换( Ctrl + h )为黑色填充
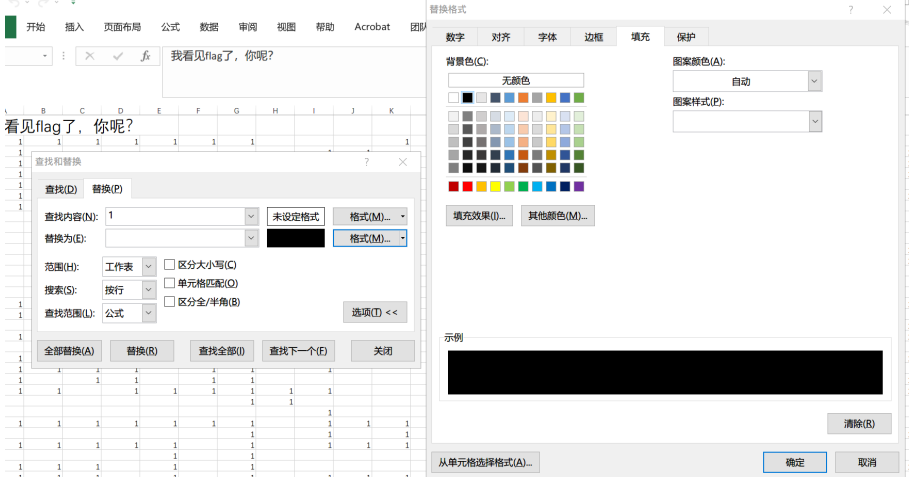
然后可以发现这其实是一个汉信码

下面我们需要调整单元格的行和宽使之变成一个正方形从而更利于识别,但单元格的高和宽采用的不同的单位,因而将两者数值设置成一致不能使之变成正方形,我试下来用行高38,列宽6.58刚好近似为正方形
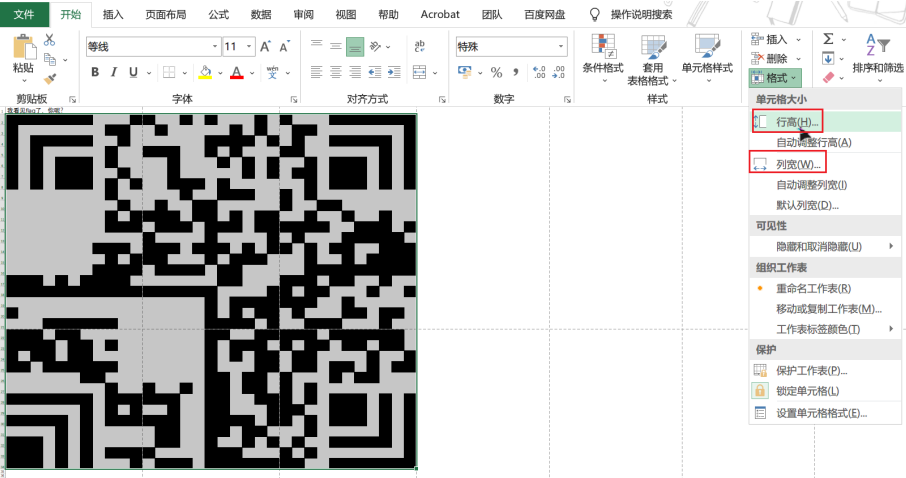
找个汉信码在线解码网站解码得到flag
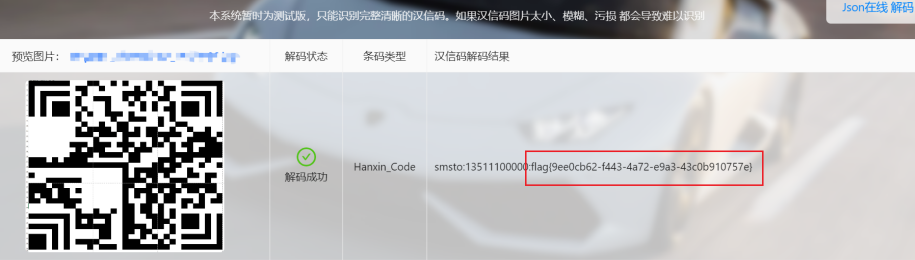
flag{9ee0cb62-f443-4a72-e9a3-43c0b910757e}
buu-蜘蛛侠呀
流量包中有很多ICMP报文,且每个报文携带了数据,用tshark将这些数据提取出来
tshark -r test.pcap -T fields -e data > data.txt

得到的数据中有很多冗余数据,写个脚本去重顺便ASCII解码
import binascii
with open('data.txt','r') as fr:
s=fr.readlines()
tmp=sorted(set(s), key = s.index) #去重
out=[]
for i in tmp:
out.append(binascii.unhexlify(i[:-1]).decode()[9:-1]) #将定界字符$$START$$以及换行符去除
print(out[-1])
得到的是base64编码

先对第一行解码可以发现这是一个压缩包
以字节流写入,最终代码如下
import binascii
import base64
with open('data.txt','r') as fr:
with open('out.zip','wb') as fw:
s=fr.readlines()
tmp=sorted(set(s), key = s.index)
for i in tmp:
try:
a=base64.b64decode(binascii.unhexlify(i[:-1]).decode()[9:-1])
except:
continue
fw.write(a)
解压后得到一个GIF
这个GIF动态的播放不连贯,判断是时间轴隐写,通过identify工具将GIF帧间的时间间隔输出
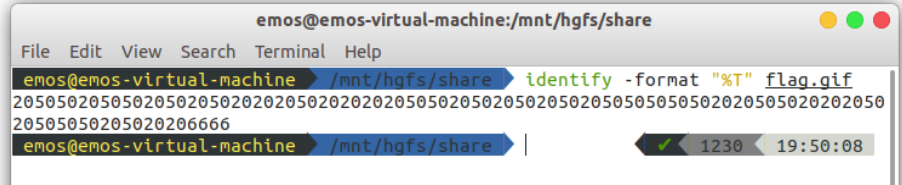
2050502050502050205020202050202020205050205020502050205050505050202050502020205020505050205020206666
将20转换为0,50转换为1二进制转字符得到mD5_1t
md5后得到flag
flag{f0f1003afe4ae8ce4aa8e8487a8ab3b6}
[QCTF2018]X-man-A face
得到一个破损的二维码

用修图工具将右上角的那个定位点补到左上角和左下角即可

手机扫描得到如下码文(CQR扫描不出来?。)
KFBVIRT3KBZGK5DUPFPVG2LTORSXEX2XNBXV6QTVPFZV6TLFL5GG6YTTORSXE7I=
没有小写字母且含有F往后的大写字母,大概率就是base32了,解码得到flag
QCTF{Pretty_Sister_Who_Buys_Me_Lobster}
[watevrCTF 2019]Evil Cuteness
末尾附加了一个压缩包
提取出来之后解压得到flag
watevr{7h475_4c7u4lly_r34lly_cu73_7h0u6h}
[安洵杯 2019]easy misc

read文件夹下有一堆文本文件,里面是英文文章,推测应该就是需要我们词频统计了,其中还有个hint.txt是提示(一开始用notepad++打开这个文件是乱码。。。改编码格式为ANSI后才正常显示),应该是指取频率最高的前16个字符
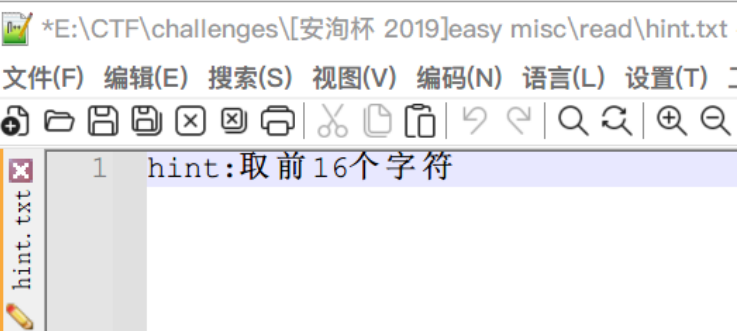
查看压缩文件,可以看到压缩文件注释提供了一串代码,推测是压缩包的口令提示
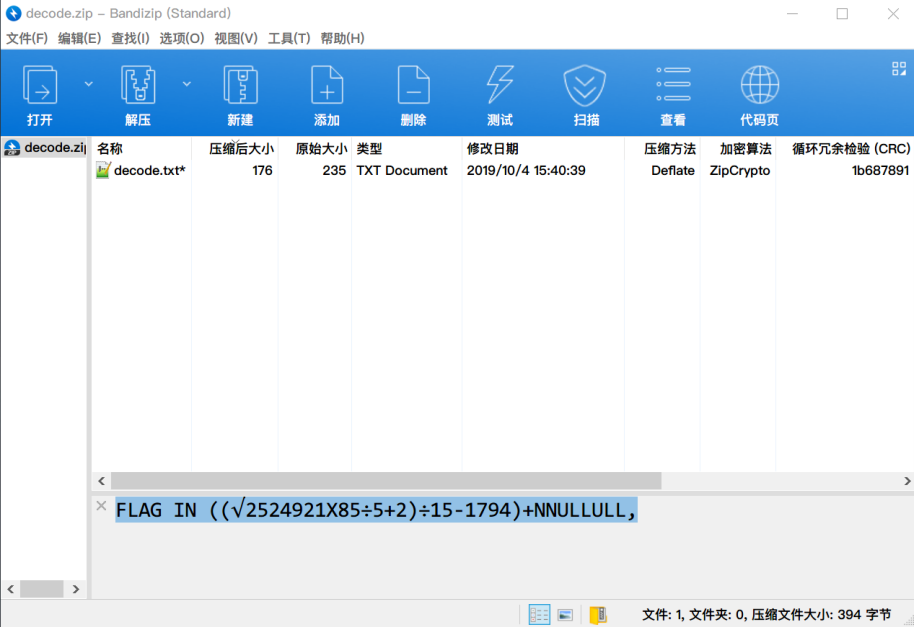
用Python计算一下得到7

那就应该是7+NNULLULL,?还是7NNULLULL,?看了别人的wp后才知道这个提供给我们的其实是压缩包口令的掩码——???????NNULLULL,(7个?代表7个数字)。
破解得到口令2019456NNULLULL,
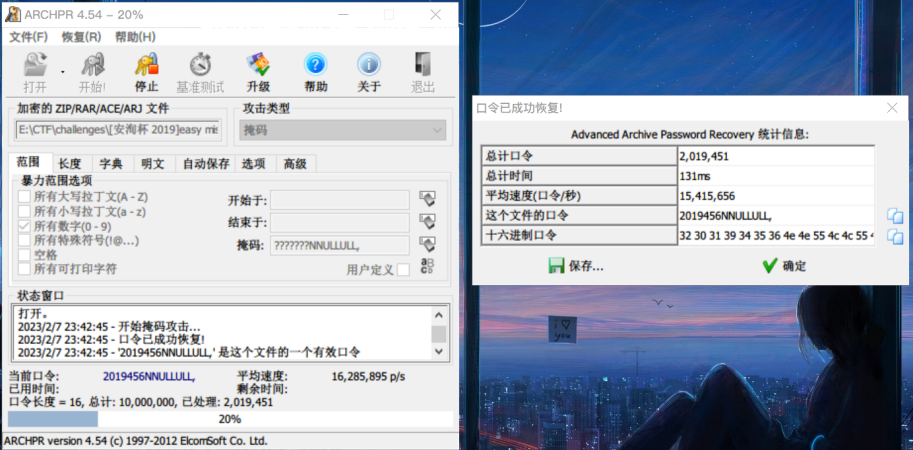
解压缩出来得到如下的替换表
a = dIW
b = sSD
c = adE
d = jVf
e = QW8
f = SA=
g = jBt
h = 5RE
i = tRQ
j = SPA
k = 8DS
l = XiE
m = S8S
n = MkF
o = T9p
p = PS5
q = E/S
r = -sd
s = SQW
t = obW
u = /WS
v = SD9
w = cw=
x = ASD
y = FTa
z = AE7
接着从图片入手,这个图片末尾还附加了一个图片
提取出来之后看上去与原图片一样,推测是盲水印
用BlindWaterMark可以提取信息,这里还是把文件名改成英文或数字吧(小姐姐1.png改成1.png,小姐姐2.png改成2.png),尝试了一下中文名称会报错;此外这里命令格式如下
#python3下
python bwmforpy3.py decode <原图> <带水印的图> <输出水印图>
#python2下
python bwm.py decode <原图> <带水印的图> <输出水印图>
一开始用
python bwmforpy3.py decode 1.png 2.png out.png得到的是如下的水印,需要加--oldseed参数才能正常提取。
通常带水印的图的文件大小更大些,所以最后我们输入如下命令
python bwmforpy3.py decode 1.png 2.png out.png --oldseed
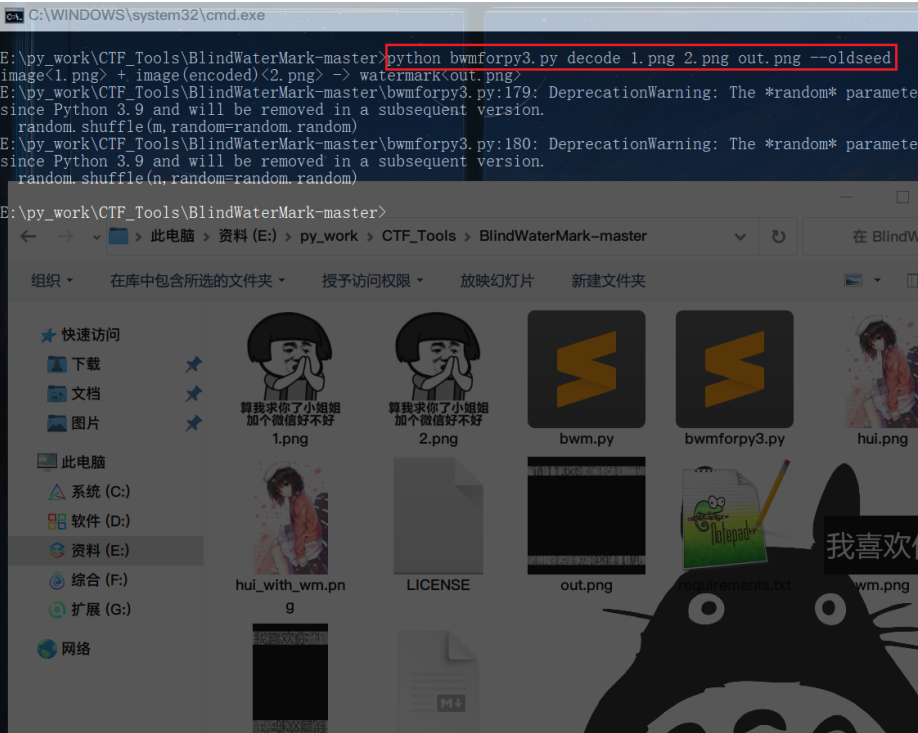
得到的水印图提示我们需要处理的是11.txt
于是写个词频统计的脚本
import re
path=r'E:\CTF\challenges\[安洵杯 2019]easy misc\read\11.txt'
with open(path,'r') as file:
line = file.readlines()
file.seek(0,0)
result = {}
for i in range(97,123):
count = 0
for j in line:
find_line = re.findall(chr(i),j)
count += len(find_line)
result[chr(i)] = count
res = sorted(result.items(),key=lambda item:item[1],reverse=True)
flag=''
for x in res:
flag+=x[0]
print(flag[:16]) #输出频率最高的16个字符
etaonrhisdluygwm
将这16个字符根据之前得到的码表替换得到码文
QW8obWdIWT9pMkFSQWtRQjVfXiE/WSFTajBtcw=
这个码文貌似是经过多次base家族编码后得到的,可以用Basecrack破解得到flag
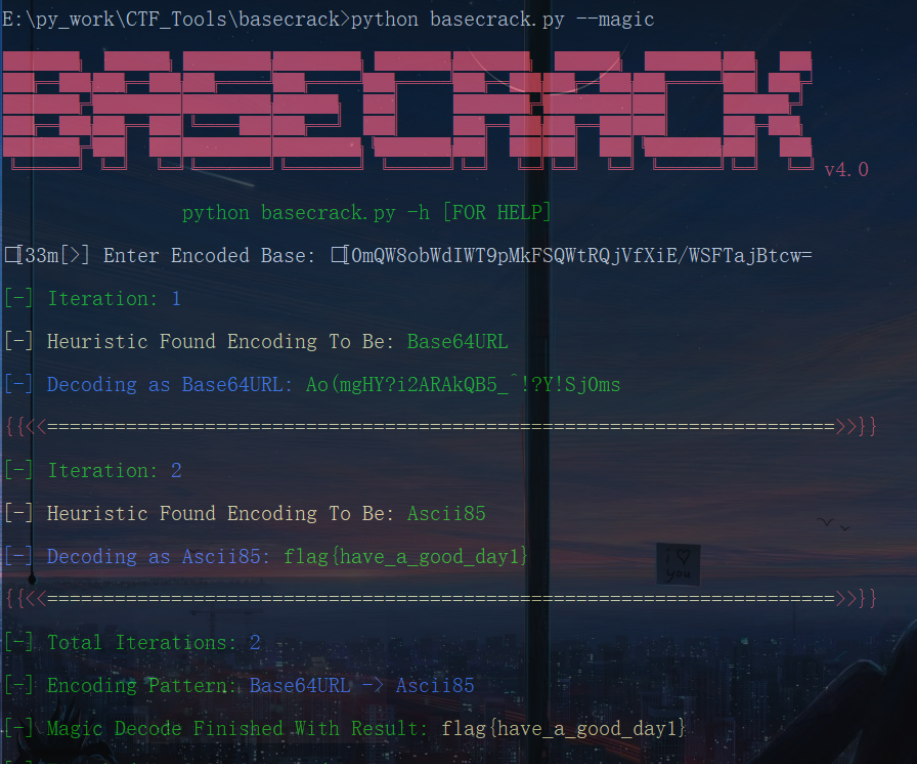
flag{have_a_good_day1}
buu-粽子的来历
曹操的私生子曹小明因为爸爸活着的时候得罪太多人,怕死后被抄家,所以把财富保存在一个谁也不知道的地方。曹小明比较喜欢屈原,于是把地点藏在他的诗中。三千年后,小明破译了这个密码,然而却因为担心世界因此掀起战争又亲手封印了这个财富并仿造当年曹小明设下四个可疑文件,找到小明喜欢的DBAPP标记,重现战国辉煌。(答案为正确值(不包括数字之间的空格)的小写32位md5值)

这是4个损坏的压缩包,每个里面有一些奇怪的字串,将这些字串都替换成0xff就可以正常打开这些文件
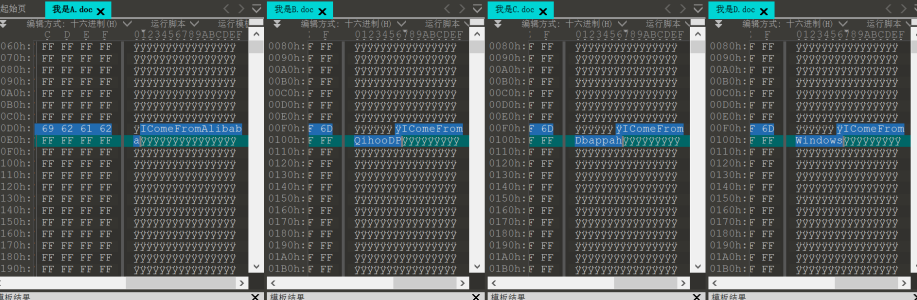
改成这样。。
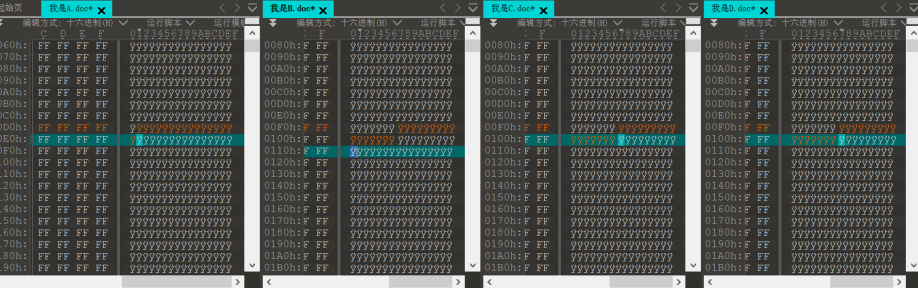
4个文档内容都是一样的诗,但比对可以发现,这些诗句行间距不一样,都是1.5倍或者单倍,将1.5倍记作1,单倍记作0(不要直接看句子间距大小,而是逐行选中打开“段落”窗口来获取行间距信息并对应替换)可以提取出信息,根据题目知,只有一个文档中隐写信息才是正确的信息。

C中的是正确的,即100100100001,32bit小写md5哈希所得即为flag
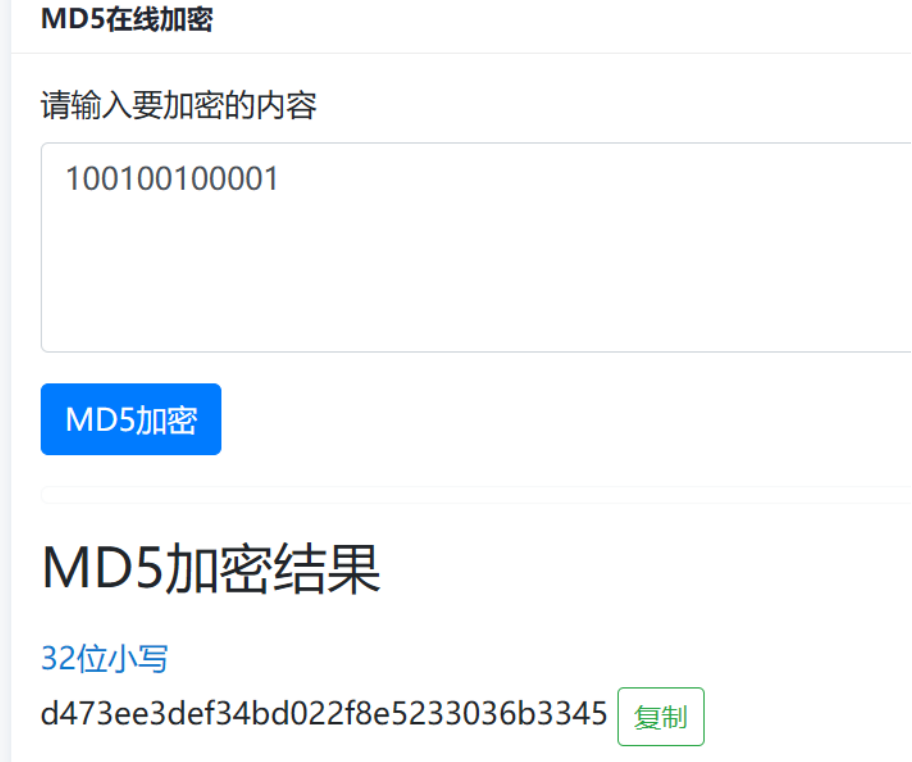
flag{d473ee3def34bd022f8e5233036b3345}
buu-hashcat
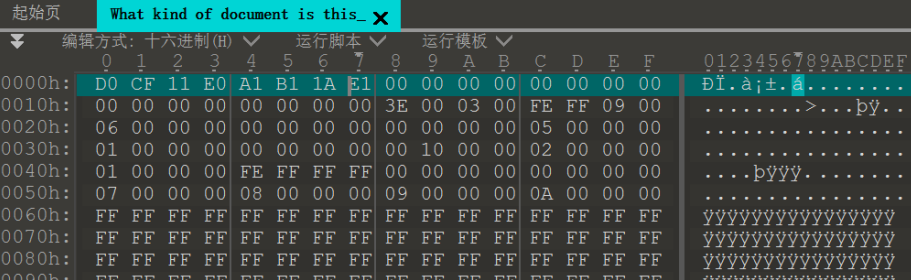
得到一个未知类型的文件,文件头为 D0 CF 11 E0 A1 B1 1A E1,注意到这是 OLESS 文档格式文件头,推测是某个Office文档
——知识储备
office文件格式根据版本可以分为Office2007之前的版本和Office2007之后的版本。
Office 2007之前的版本为OLE复合格式,如doc、dot、xls、xlt、pot、ppt;
Office 2007 之前的版本可以看作二进制文件,可以用OffVis工具解析其文档结构。其中十六进制文件头为 D0 CF 11 E0 A1 B1 1A E1,这是固定的 OLESS 文档格式文件头。
Office 2007之后的版本为OpenXML格式,如docx、docm、dotx、xlsx、xlsm、xltx、potx
Office 2007 之后的版本本质上是一个压缩包。由于文档中包含 ooxml 文件,因此不能用 offvis 进行解析,按下 offvis 的 Parser 按钮确实无法解析文件,这类文档可以通过解析出 .xml 和 .rels 来获取内容和逻辑关系。
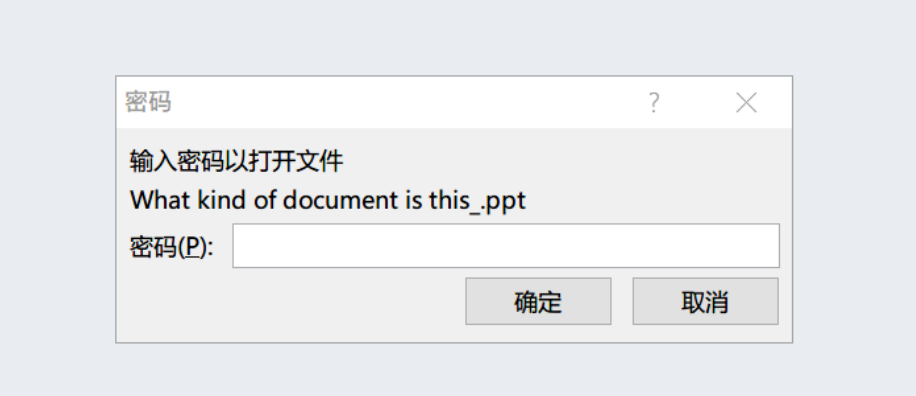
添加后缀为doc或者ppt,双击打开但提示要输入密码
接着用john暴破即可,步骤如下
-
先用
office2john.py提取该文件的哈希值输出到hashpython office2john.py What kind of document is this_.ppt > hash -
然后准备一个字典
zidian.txt用john破解(Ubuntu下可能会报错,建议用Kali)john --wordlist=zidian.txt hash -
显示破解出来的密码
john --show hash
得到密码9919,然后打开后在第7张幻灯片可以找到flag
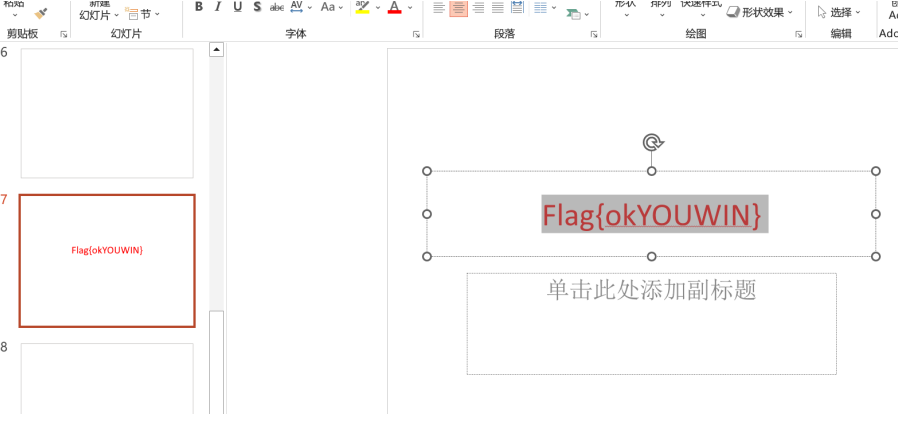
flag{okYOUWIN}
[SCTF2019]电单车
用Audacity打开这个文件
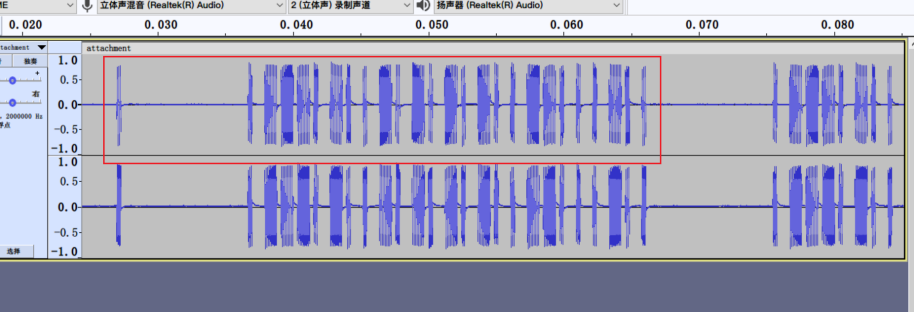
然后以短的为 0,长的为 1进行替换,考察的是PT2242信号
0...01110100101010100110 0010 0
最后的flag就是信号的地址码
flag{01110100101010100110}
[DDCTF2018]流量分析
——hint
流量分析
200pt
提示一:若感觉在中间某个容易出错的步骤,若有需要检验是否正确时,可以比较
MD5:90c490781f9c320cd1ba671fcb112d1c提示二:注意补齐私钥格式
-----BEGIN RSA PRIVATE KEY----- XXXXXXX -----END RSA PRIVATE KEY-----
这是个流量分析题,通过这个题可以学会这几个协议的基本分析方法
Wireshark打开后可以看到很多包,缩小分析范围可以框定有这样几个需要重点分析的协议——FTP、SMTP、TLS,根据提示,要想获取flag就需要用到私钥来解密TLS包,可能从另外两个协议中可以获取到私钥
首先分析FTP协议
在进行文件传输时,FTP 的客户和服务器之间要建立两个并行的TCP连接 ——“控制连接”和“数据连接”。FTP客户所发出的传送请求,通过控制连接发送给服务器端的控制进程,但控制连接并不用来传送文件。实际用于传输文件的是“数据连接”。
先从控制连接入手,过滤ftp包,右键追踪对应的TCP流可以看到整个控制连接客户端与服务器端通信的全过程
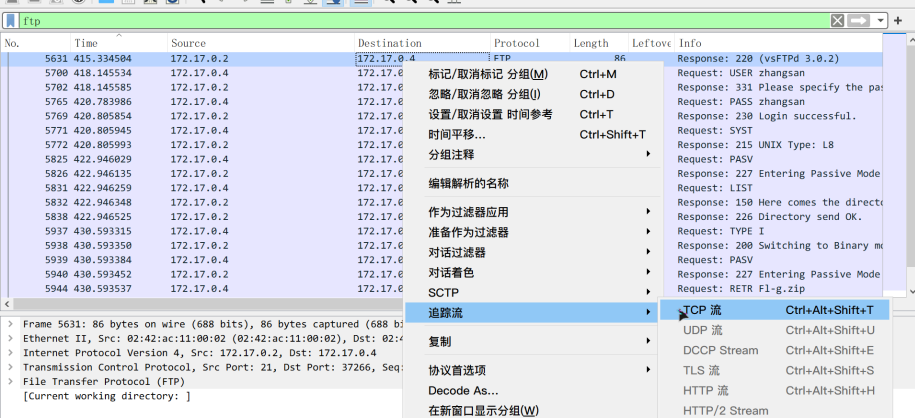
可以看到验证的用户名和密码zhangsan,然后是SYST查明服务器上操作系统的类型、PASV选用被动模式、LIST让服务器发送文件列表,以及RETR下载命令,并从FTP服务器上面下载了Fl-g.zip和sqlmap.zip,后来在同一个服务器上传(STOR)了profile文件。
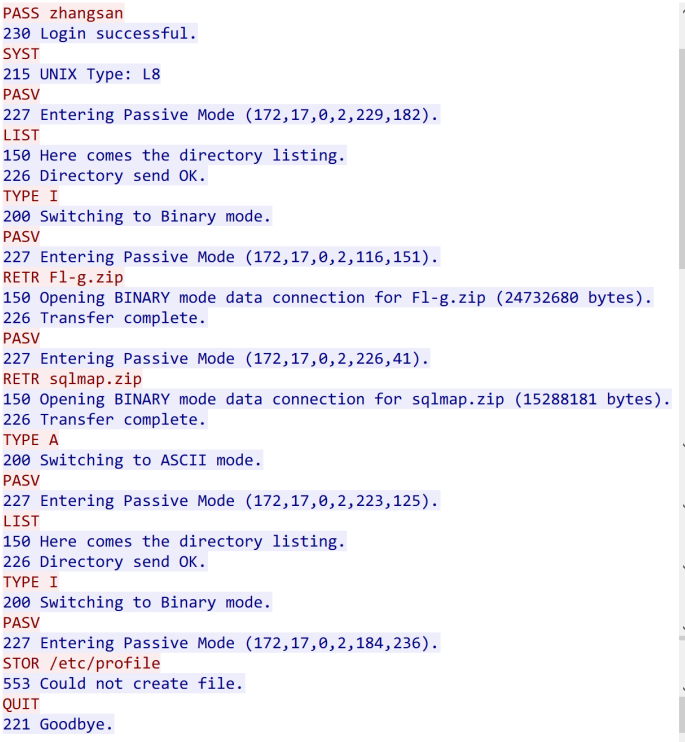
显然这个Fl-g.zip文件需要我们尝试提取出来,这就需要过滤数据连接
过滤表达式为ftp-data可以看到所有数据连接传输的数据,同时可以看到所传输的文件名
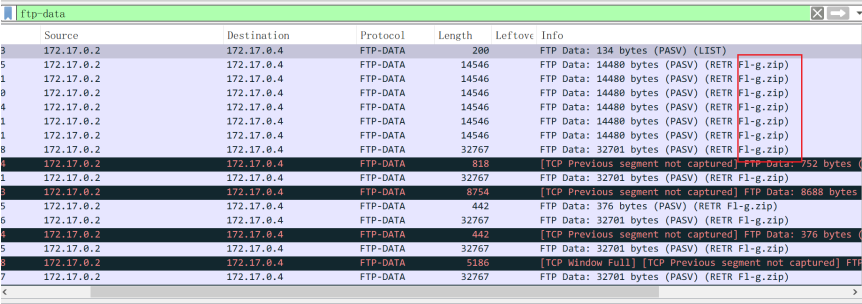
选中其中一个传输Fl-g.zip文件的记录,追踪对应的TCP流,呈现的便是Fl-g.zip的数据
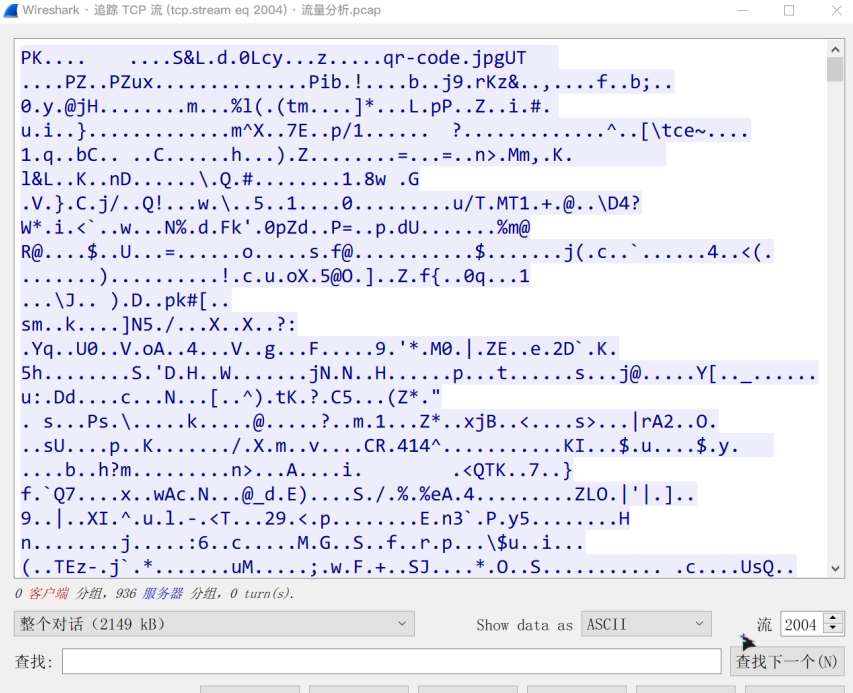
将底部的“Show data as”更改为“原始数据”后窗口显示十六进制字符,而不是ASCII字符,然后使用窗口底部的另存为按钮将其保存为原始二进制文件便可以成功导出
里面看起来是个二维码,但文件本来就是损坏的,无法解压
然后只能从SMTP协议入手,重点关注的是传输的邮件内容,所以我们可以直接导出IMF对象
>关于IMF
IMF(Internet Message Format):因特网消息格式。因特网消息格式是指文本消息在因特网上传输的格式。若SMTP等价于邮件信封,则IMF等价于信封中的信件,它包含发起者、接收者、主题和日期。实际上,IMF消息通常被称为“SMTP消息”。
点击文件>导出对象>IMF
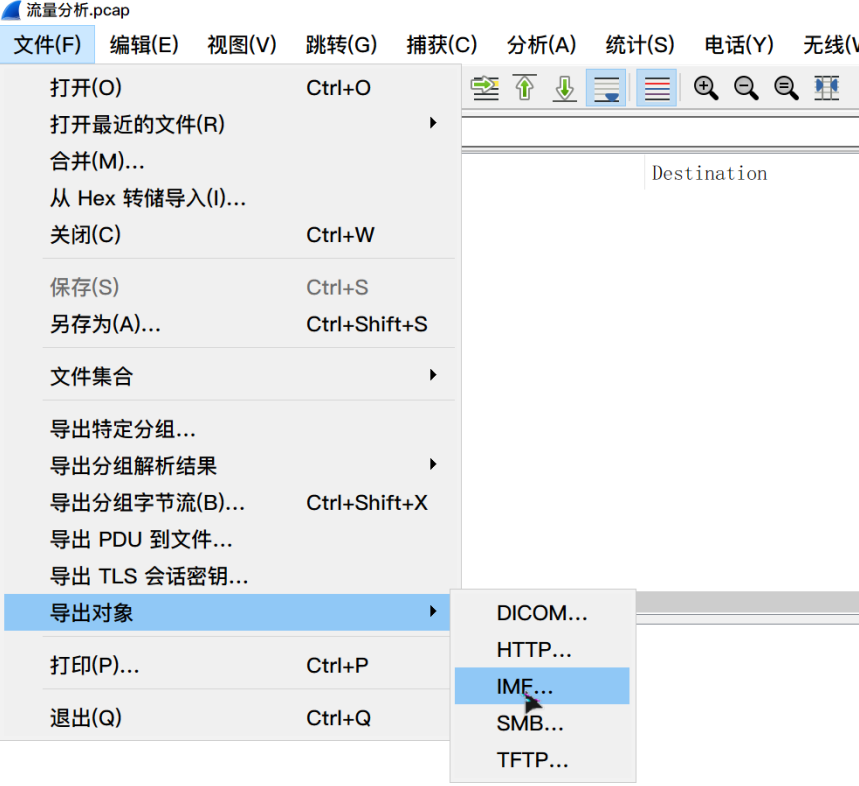
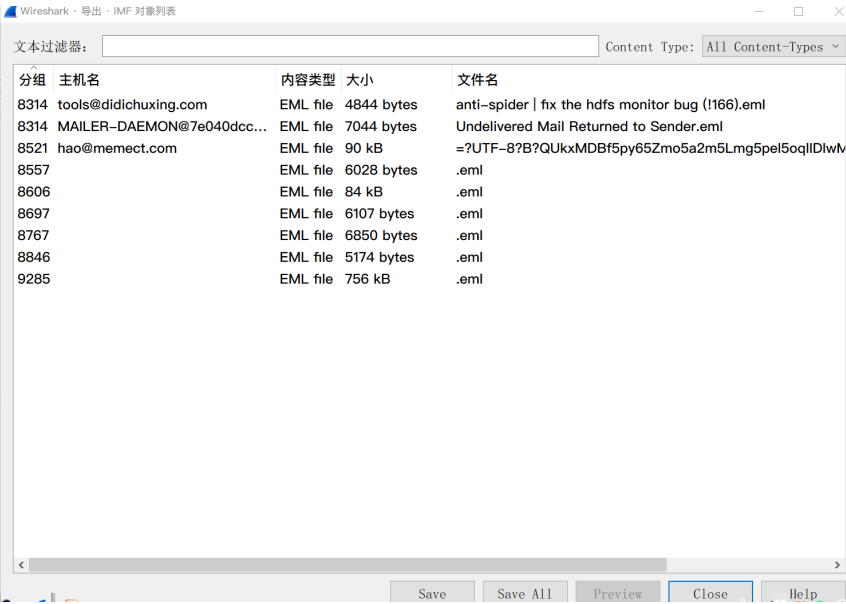
导出之后得到的文件以.eml为扩展名,可以通过邮件查看器(如Windows自带的Mail)或者文本编辑器打开这些邮件查看里面的内容。
逐个打开可以发现只有一个是有用的,以图片的形式告知了我们私钥
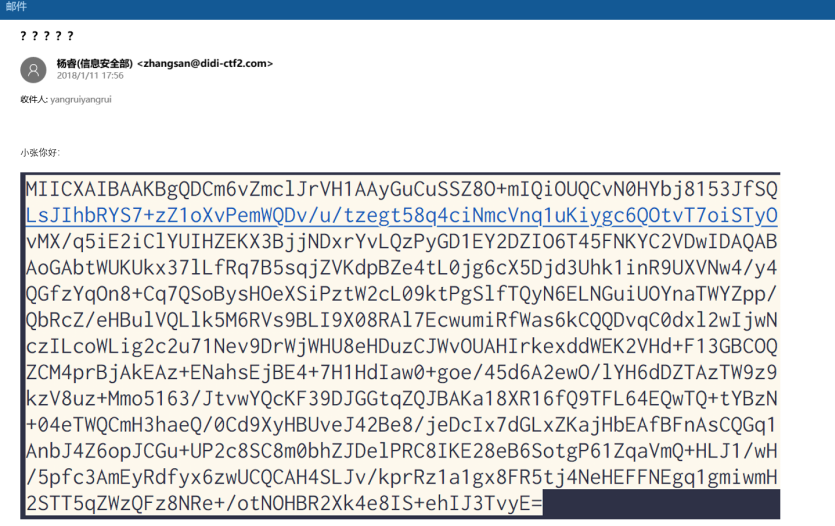
OCR识别一下,包上头尾
-----BEGIN RSA PRIVATE KEY-----
MIICXAIBAAKBgQDCm6vZmclJrVH1AAyGuCuSSZ8O+mIQiOUQCvN0HYbj8153JfSQ
LsJIhbRYS7+zZ1oXvPemWQDv/u/tzegt58q4ciNmcVnq1uKiygc6QOtvT7oiSTyO
vMX/q5iE2iClYUIHZEKX3BjjNDxrYvLQzPyGD1EY2DZIO6T45FNKYC2VDwIDAQAB
AoGAbtWUKUkx37lLfRq7B5sqjZVKdpBZe4tL0jg6cX5Djd3Uhk1inR9UXVNw4/y4
QGfzYqOn8+Cq7QSoBysHOeXSiPztW2cL09ktPgSlfTQyN6ELNGuiUOYnaTWYZpp/
QbRcZ/eHBulVQLlk5M6RVs9BLI9X08RAl7EcwumiRfWas6kCQQDvqC0dxl2wIjwN
czILcoWLig2c2u71Nev9DrWjWHU8eHDuzCJWvOUAHIrkexddWEK2VHd+F13GBCOQ
ZCM4prBjAkEAz+ENahsEjBE4+7H1HdIaw0+goe/45d6A2ewO/lYH6dDZTAzTW9z9
kzV8uz+Mmo5163/JtvwYQcKF39DJGGtqZQJBAKa18XR16fQ9TFL64EQwTQ+tYBzN
+04eTWQCmH3haeQ/0Cd9XyHBUveJ42Be8/jeDcIx7dGLxZKajHbEAfBFnAsCQGq1
AnbJ4Z6opJCGu+UP2c8SC8m0bhZJDelPRC8IKE28eB6SotgP61ZqaVmQ+HLJ1/wH
/5pfc3AmEyRdfyx6zwUCQCAH4SLJv/kprRz1a1gx8FR5tj4NeHEFFNEgq1gmiwmH
2STT5qZWzQFz8NRe+/otNOHBR2Xk4e8IS+ehIJ3TvyE=
-----END RSA PRIVATE KEY-----
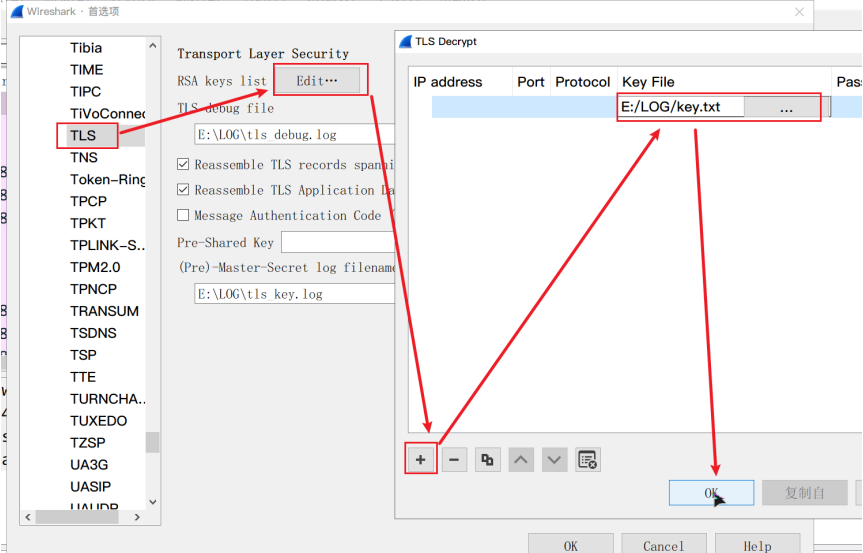
依次点击编辑>首选项>Protocols>TLS>Edit添加私钥文件
然后过滤HTTP报文并追踪HTTP流得到flag
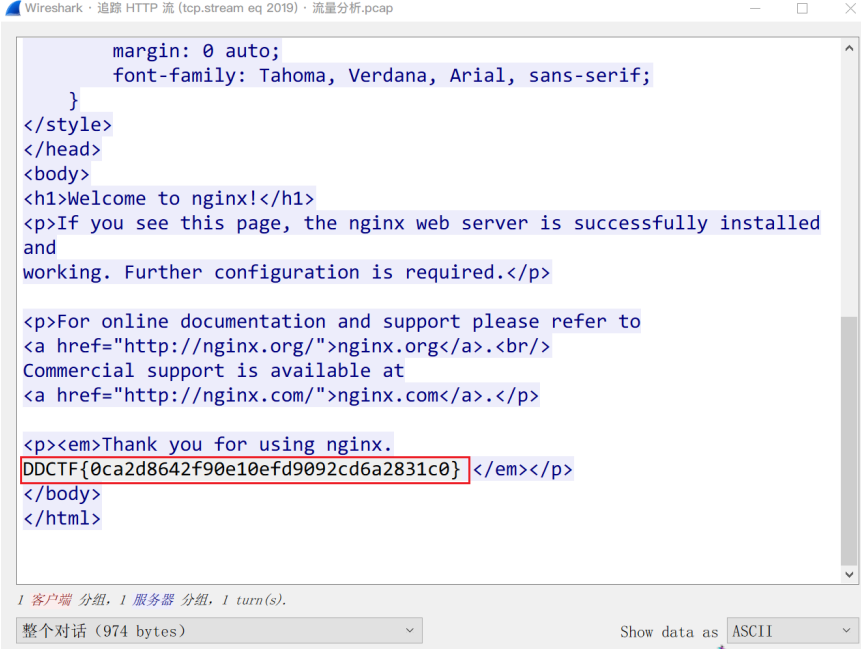
DDCTF{0ca2d8642f90e10efd9092cd6a2831c0}
[UTCTF2020]sstv
慢扫描电视(Slow-scan television 简称SSTV)是业余无线电爱好者的一种主要图片传输方法,慢扫描电视通过无线电传输和接收单色或彩色静态图片。
解码工具可以采用linux下的QSSTV,使用如下命令安装
sudo apt-get install qsstv
启动qsstv,设置一下输入qsstv>Options>Configration>Sound>Sound Input>from file
点击图标选择文件便可解码得到图像
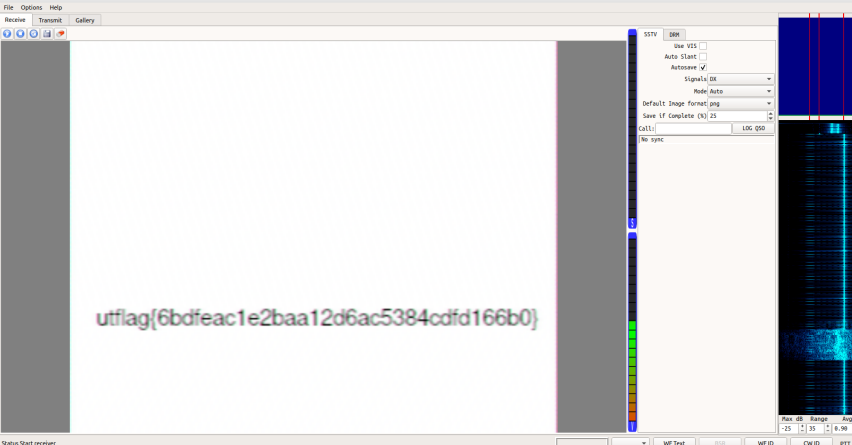
utflag{6bdfeac1e2baa12d6ac5384cdfd166b0}
buu-voip
拿到手的是一个基于RTP的VoIP流量包
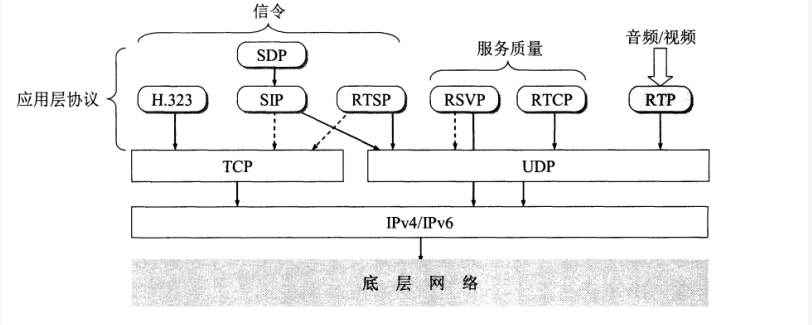
基于IP的语音传输(VoIP)是一种语音通话技术,经由IP协议来达成语音通话与多媒体会议,也就是经由互联网来进行通讯,在IP电话的通信中至少需要两种应用协议。
- 一种是信令协议,它使我们能够在互联网上找到被叫用户,如
SIP、H.323- 另一种是话音分组的传送协议,它使我们用来进行电话通信的话音数据能够以时延敏感属性在互联网中传送。如
RTP- 此外,还有一种协议是为了提高服务质量,如
RSVP和RTCP
语音载荷封装在RTP包里面,要对传输中的语音进行截获和还原,可以通过Wireshark对RTP包进行分析和解码。
点击电话>VoIP通话
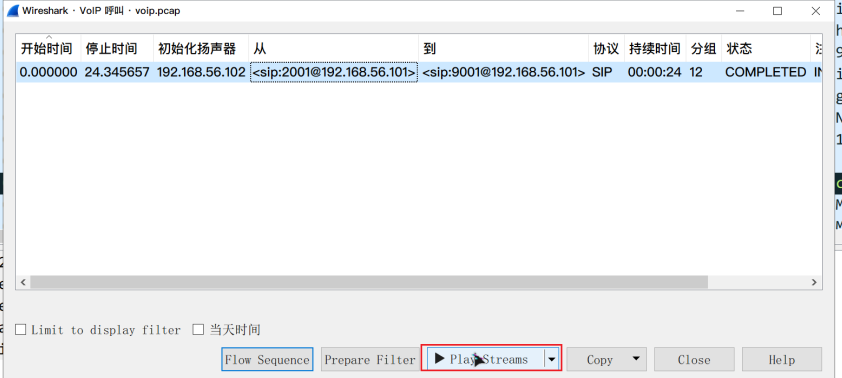
选中记录并播放
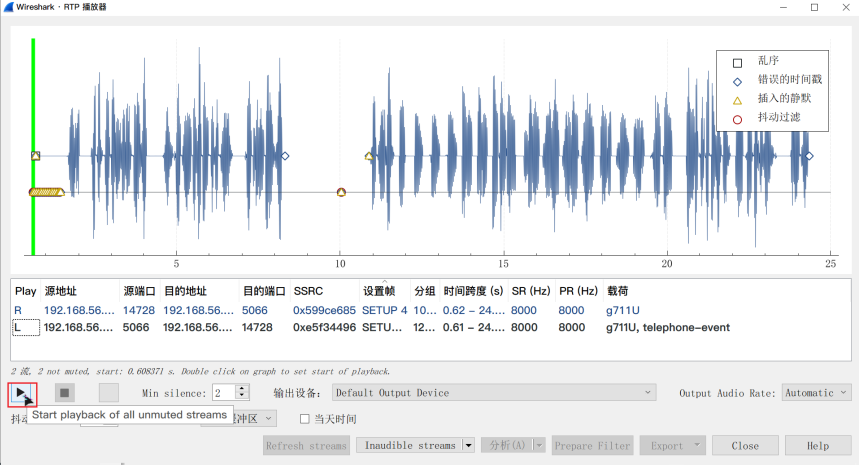
拿到flag
flag{9001IVR}
buu-key不在这里
一个二维码图片,里面的链接打开后是用bing搜索“key不在这里”
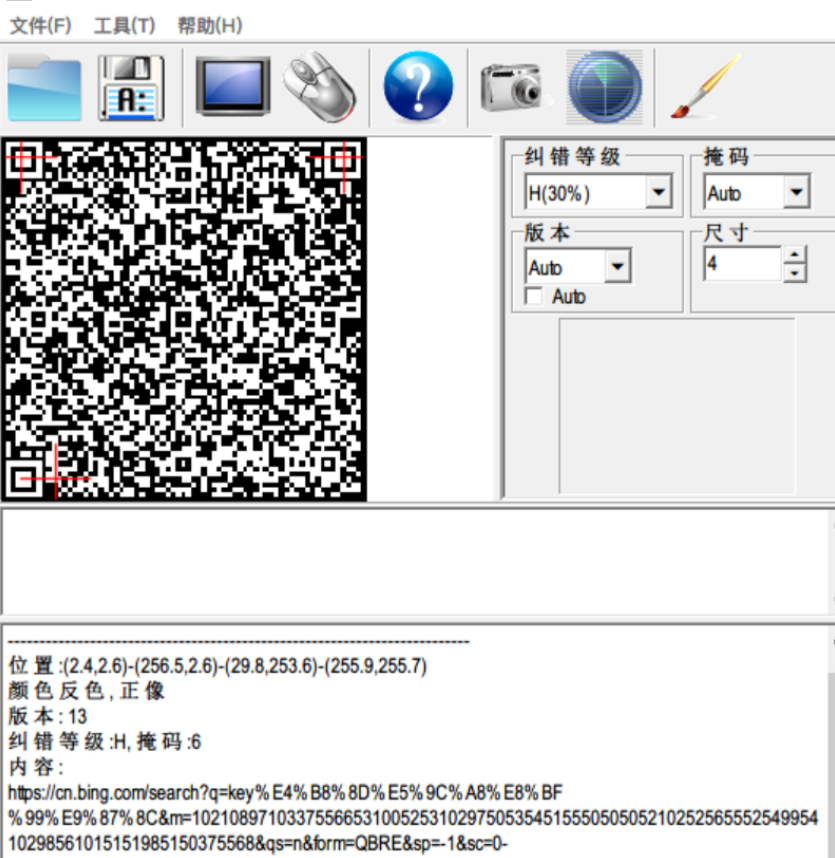
https://cn.bing.com/search?q=key%E4%B8%8D%E5%9C%A8%E8%BF%99%E9%87%8C&m=10210897103375566531005253102975053545155505050521025256555254995410298561015151985150375568&qs=n&form=QBRE&sp=-1&sc=0-38&sk=&cvid=2CE15329C18147CBA4C1CA97C8E1BB8C
只好从链接本身入手,将参数部分提取出来如下
q=key%E4%B8%8D%E5%9C%A8%E8%BF%99%E9%87%8C
m=10210897103375566531005253102975053545155505050521025256555254995410298561015151985150375568
qs=n
form=QBRE
sp=-1
sc=0-38
sk=
cvid=2CE15329C18147CBA4C1CA97C8E1BB8C
参考一下《必应搜索引擎的参数详解》,可以发现m键其实是很可疑的
将这部分数据ASCII解码
s = '10210897103375566531005253102975053545155505050521025256555254995410298561015151985150375568'
temp = ''
while len(s):
if int(s[:3]) < 127:
temp += chr(int(s[:3]))
s = s[3:]
else:
temp += chr(int(s[:2]))
s = s[2:]
print(temp)
得到flag%7B5d45fa256372224f48746c6fb8e33b32%7D,再URL解码(或者直接%7B换{,%7D换})可以得到flag
flag{5d45fa256372224f48746c6fb8e33b32}
[GUET-CTF2019]soul sipse
得到一个音频文件,各种隐写工具都试试发现是Steghide隐写
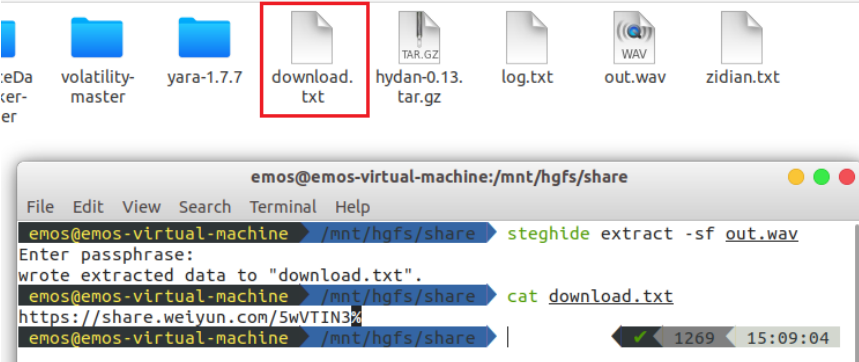
得到一个微云文件分享链接
https://share.weiyun.com/5wVTIN3
下载下来是张格式损坏过的图片,010 Editor打开发现文件头有误,修复一下便可以正常打开
得到的图片如下,是Unicode编码
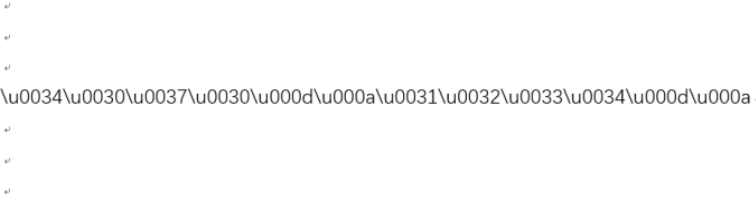
\u0034\u0030\u0037\u0030\u000d\u000a\u0031\u0032\u0033\u0034\u000d\u000a
解码如下
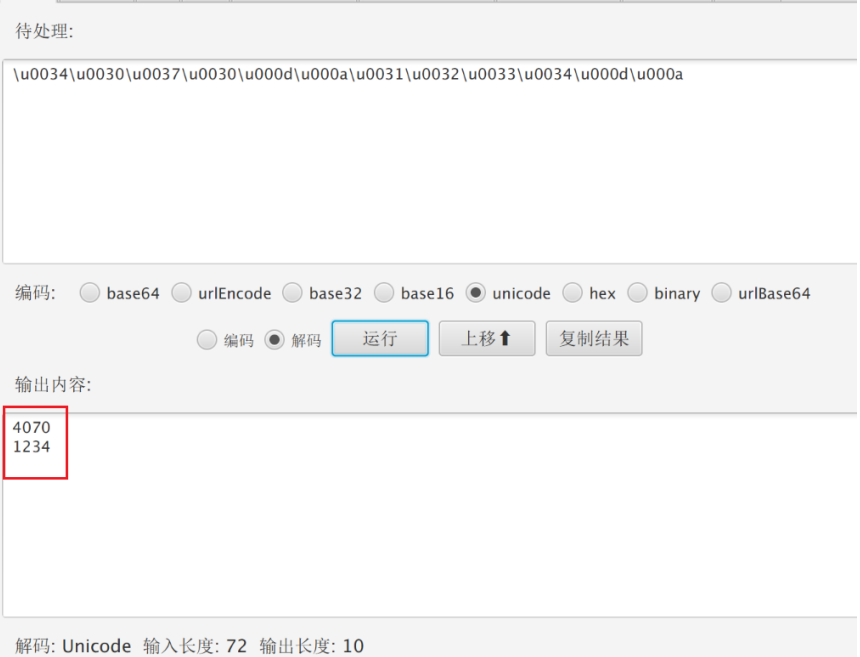
两数相加得到flag。。。。
flag{5304}
[UTCTF2020]spectogram
AU中打开并切换到频谱图
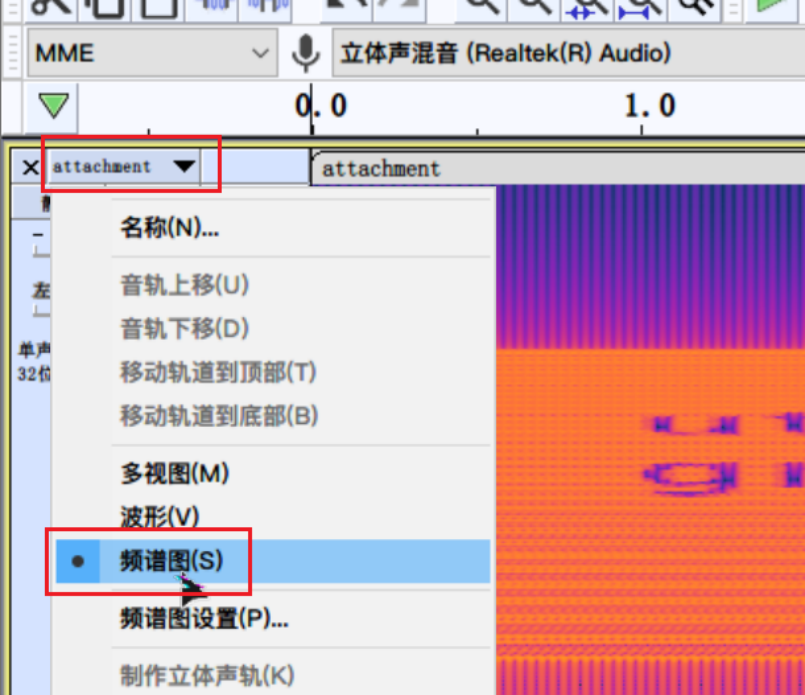
稍微拉伸一下,得到flag
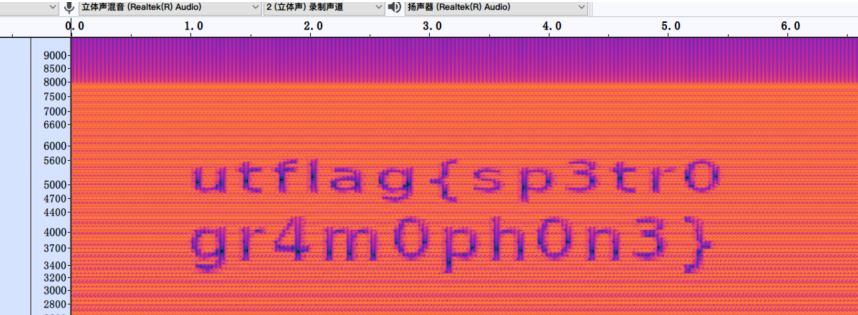
utflag{sp3tr0gr4m0ph0n3}
[湖南省赛2019]Findme
得到5张图片
1.png
1.png无法正常打开,且几处CRC报错,分别是IHDR块和IDAT块
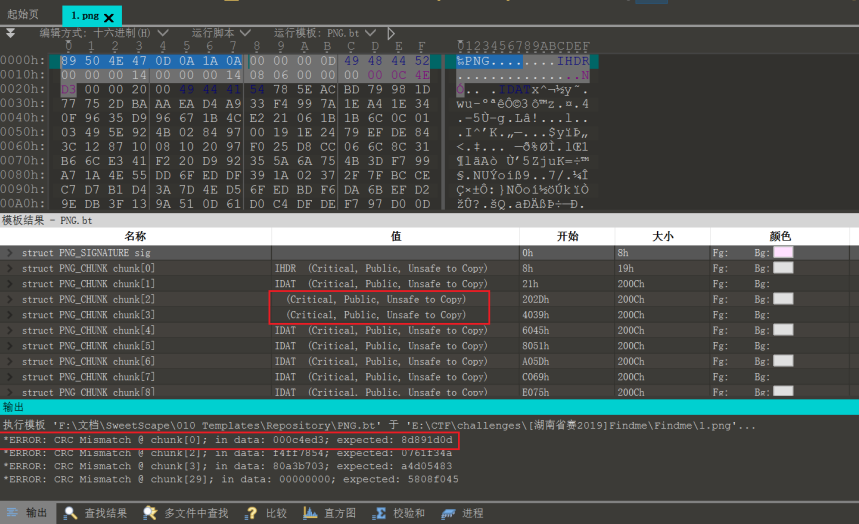
先暴破一下宽高
import zlib
import struct
filename='1.png' #图片路径
crc_str= '0xc4ed3' #图片的CRC值(16进制字符串,如'0xc4ed3')
# 同时暴破宽度和高度
with open(filename, 'rb') as f:
all_b = f.read()
data = bytearray(all_b[12:29])
n = 4095
for w in range(n):
width = bytearray(struct.pack('>i', w))
for h in range(n):
height = bytearray(struct.pack('>i', h))
for x in range(4):
data[x+4] = width[x]
data[x+8] = height[x]
crc32result = zlib.crc32(data)
#替换成图片的crc
if crc32result == int(crc_str,16):
print("宽为:", end = '')
print(width, end = ' ')
print(int.from_bytes(width, byteorder='big'))
print("高为:", end = '')
print(height, end = ' ')
print(int.from_bytes(height, byteorder='big'))
输出结果如下
宽为:bytearray(b'\x00\x00\x00\xe3') 227
高为:bytearray(b'\x00\x00\x01\xc5') 453
修改之后重新在010 Editor中打开可以看到IHDR的CRC报错已经消失了
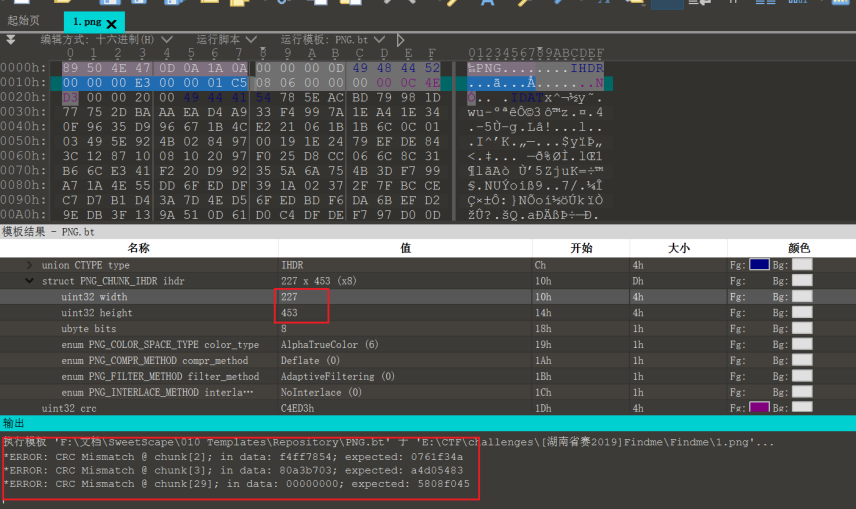
另外有两个IDAT块标识符部分缺损,补全即可
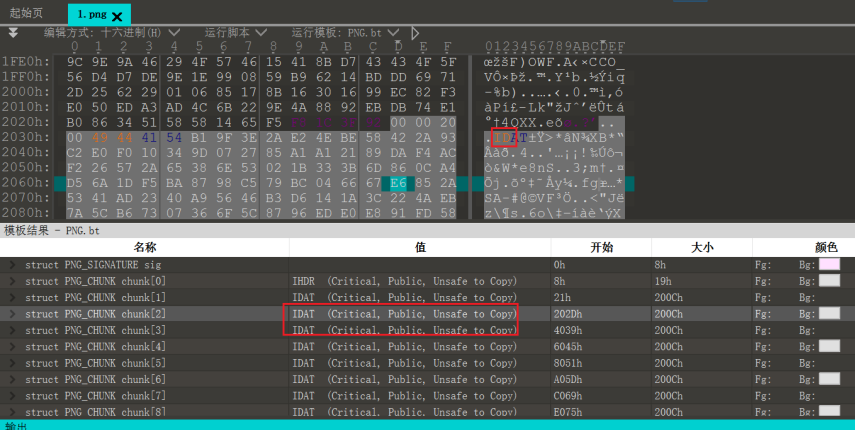
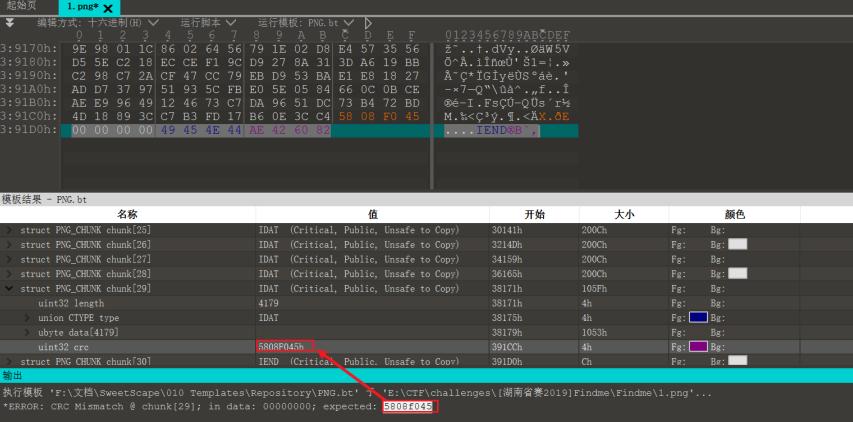
最后还有一处是最后一个IDAT块,它的CRC值被置为0,010 Editor已经给出了期望的CRC值,覆盖上即可
这个时候1.png才算完全修复完成,可以正常打开,拖到Stegsolve中看看有没有隐藏信息
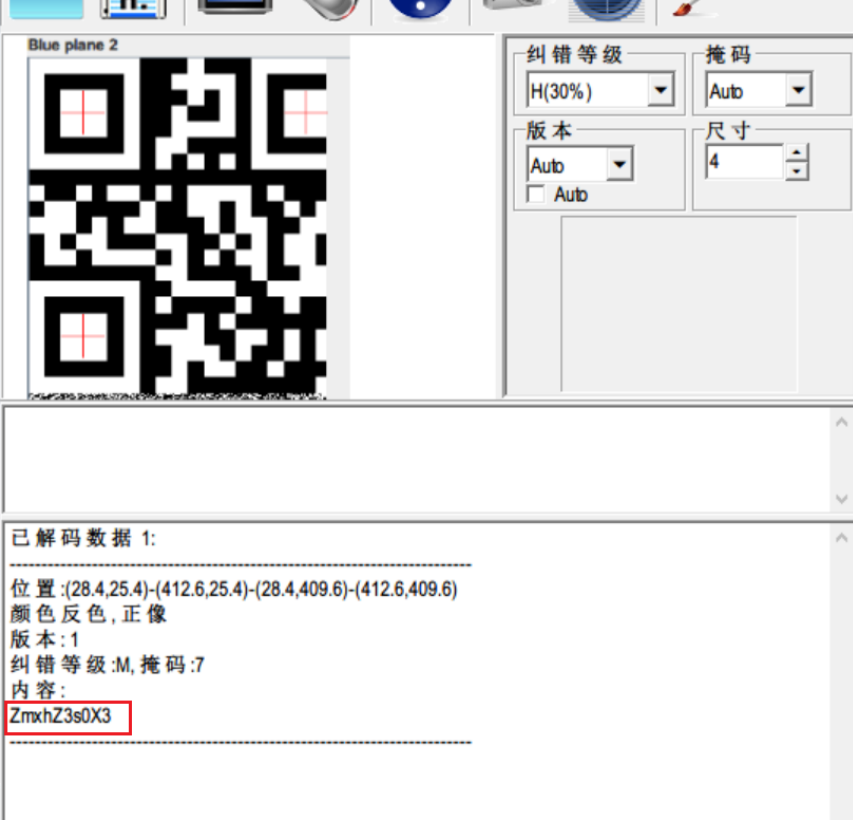
最后也是发现了一个二维码

扫描出来得到一串字符ZmxhZ3s0X3
2.png
接着分析2.png
2.png后面追加了一个压缩包
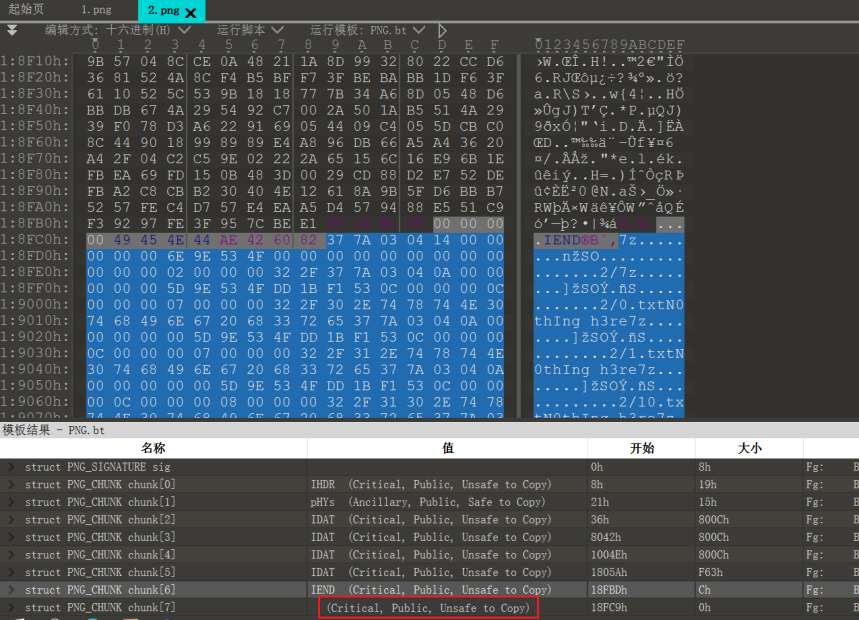
提取出来显示格式损坏
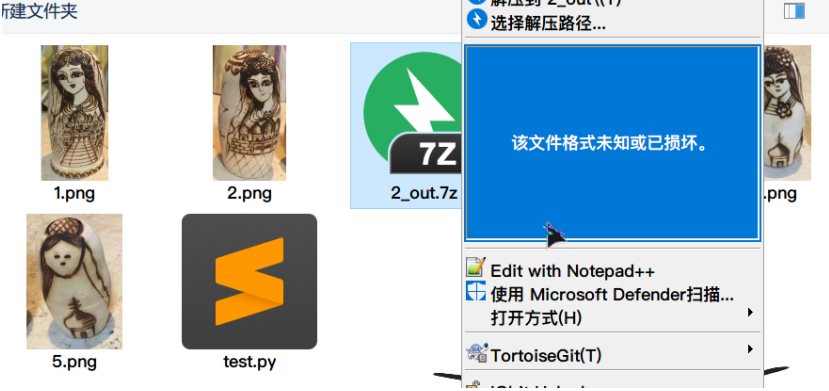
010 Edotor打开看到了可疑之处,正常的7z文件的文件头应该是37 7a bc af 27 1c,但这个与其说是7z不如说更像是普通zip压缩包,只是把PK换成了7z,那就替换回来
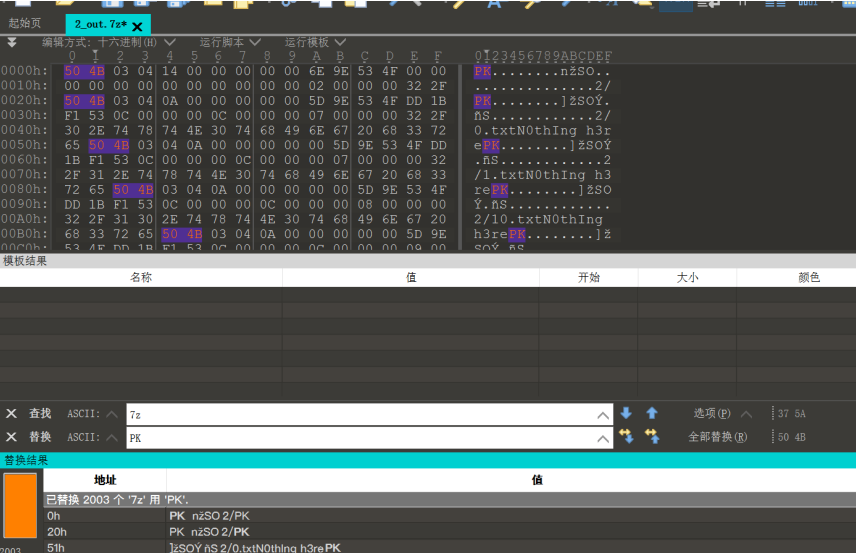
一堆写着N0thIng h3re的txt文件,不过还是文件大小使它露出了鸡jio,得到字符串1RVcmVfc
3.png
除了IEND块,其它块都出现了CRC值报错的问题,且这些CRC值很明显是人为故意设置成这种可打印字符的
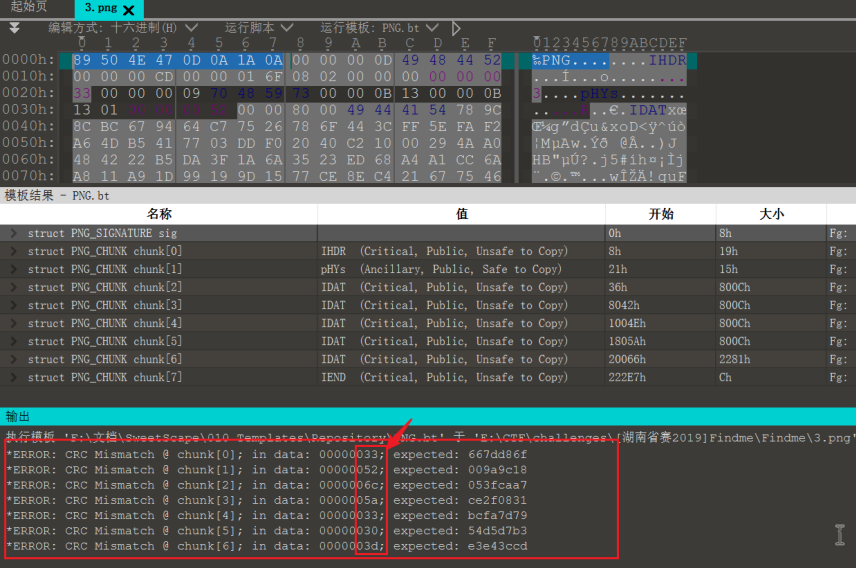
将这些块的CRC值提取出来拼接得到字符串3RlZ30=
4.png
这个直接在tEXt块中给出来了,cExlX1BsY
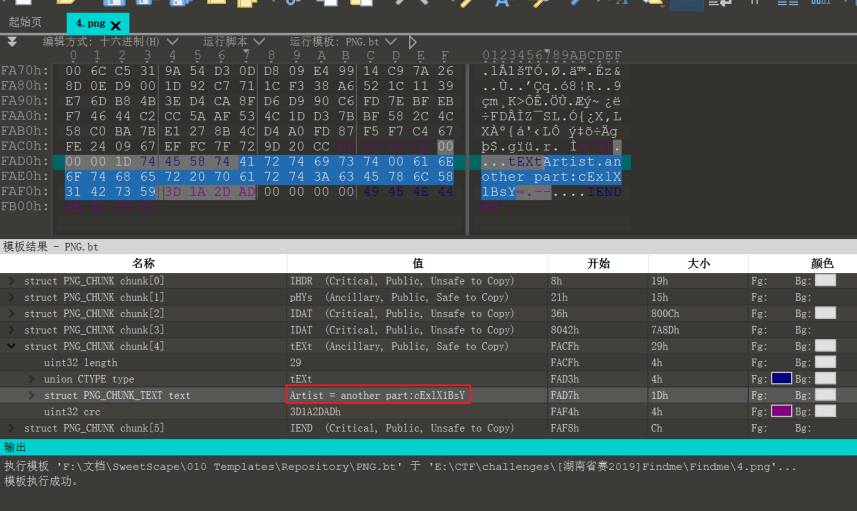
5.png
这个也是直接附加在了文件的结尾Yzcllfc0lN
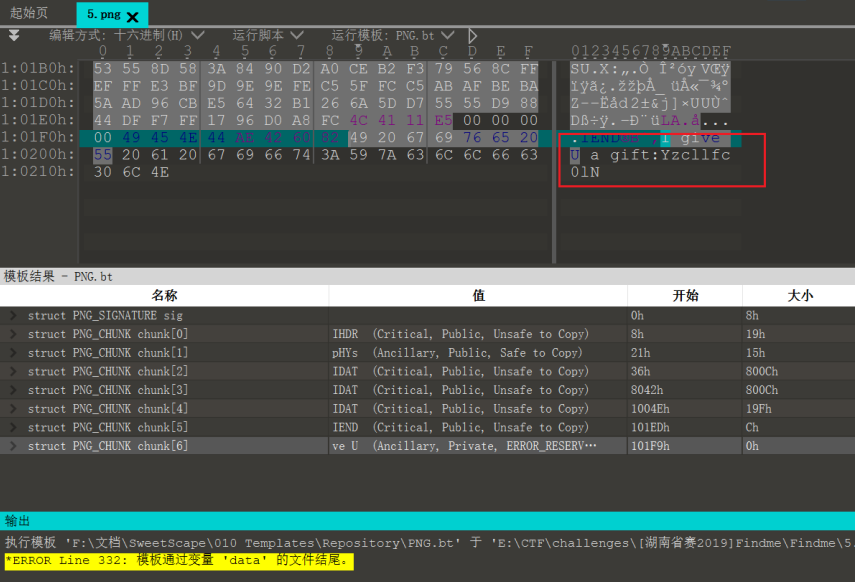
汇总
最后汇总一下
P1:ZmxhZ3s0X3
P2:1RVcmVfc
P3:3RlZ30=
P4:cExlX1BsY
P5:Yzcllfc0lN
P3应该是放最后的,所以这个貌似不是按照顺序给出的,需要排序,那就写个脚本暴破
import base64
def permutations(alist:list)->list:
'''这是一个枚举排列的函数
:参数 alist:一个包含不重复元素的列表
'''
# 基线条件是列表里只有一个元素,直接返回
if len(alist) == 1:
return [alist]
# 求出元素的个数
n = len(alist)
# 这是用于存储所有排列的列表
ans = []
# 遍历这些元素,依次让这些元素做排头兵
for i in range(n):
# 调用递归函数,对除了排头兵以外的剩下的元素进行排列
# 对得到的每种排列,都把排头兵拼在最前面,得到全部元素的排列,添加到答案列表里
for each in permutations(alist[0:i]+alist[i+1:n]):
ans.append([alist[i]]+each)
# 返回答案
return ans
l=['ZmxhZ3s0X3','1RVcmVfc','cExlX1BsY','Yzcllfc0lN']
end='3RlZ30='
l1=permutations(l) # 罗列所有可能的结果
for i in l1:
try:
print(base64.b64decode(''.join(i)+end).decode())
except:
continue
最后得到flag
flag{4_v3rY_sIMpLe_PlcTUre_steg}
Business Planning Group
图片文件末尾追加了文件,提取出来
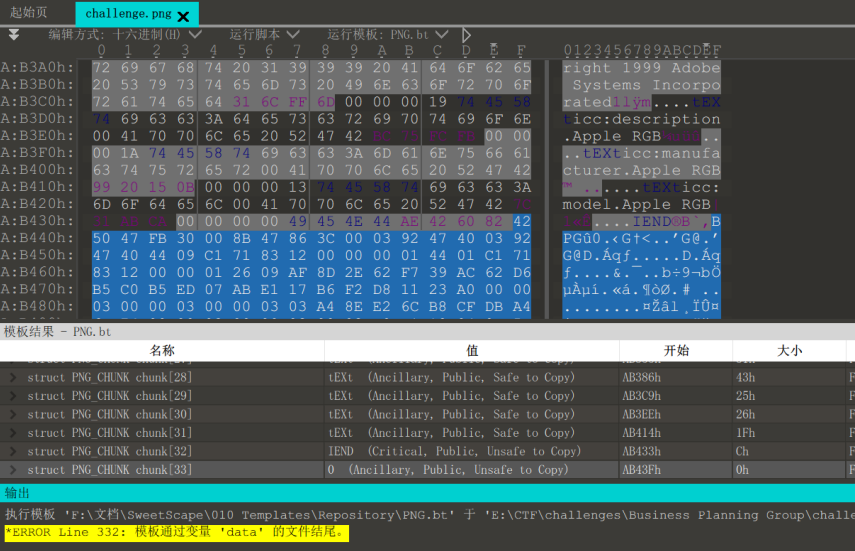
BPG开头的文件,搜索发现是一种新的图像格式,Honeyview是可以查看的

YnNpZGVzX2RlbGhpe0JQR19pNV9iM3R0M3JfN2g0bl9KUEd9Cg==
base64解码得到flag
bsides_delhi{BPG_i5_b3tt3r_7h4n_JPG}
[ACTF新生赛2020]剑龙
待分析的有如下三个文件

O_O可以用file命令知道这是一个pyc文件
推测是pyc隐写,用Stegosaurus 提取信息
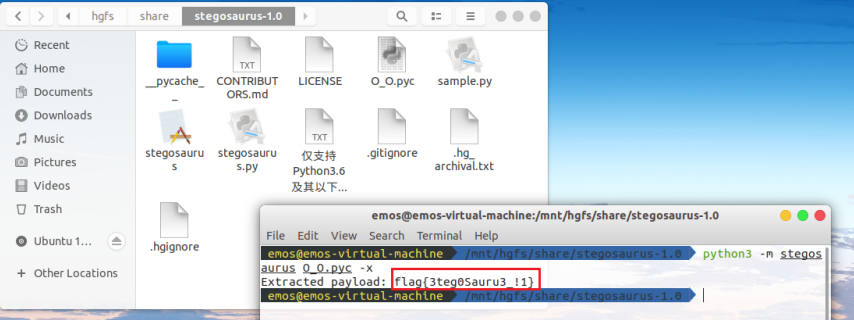
直接就可以得到flag了
flag{3teg0Sauru3_!1}
[HDCTF2019]你能发现什么蛛丝马迹吗
buu-greatescape
里面很多TLS包,那就需要我们找密钥来解析
观察到还有一些FTP包和SMTP包,密钥很可能藏在其中
首先看SMTP包,直接导出IMF对象(文件>导出对象>IMF)
>关于IMF
IMF(Internet Message Format):因特网消息格式。因特网消息格式是指文本消息在因特网上传输的格式。若SMTP等价于邮件信封,则IMF等价于信封中的信件,它包含发起者、接收者、主题和日期。实际上,IMF消息通常被称为“SMTP消息”。
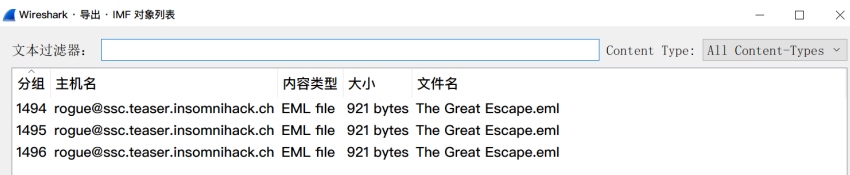
其实是3封内容一样的邮件,没有什么有用信息
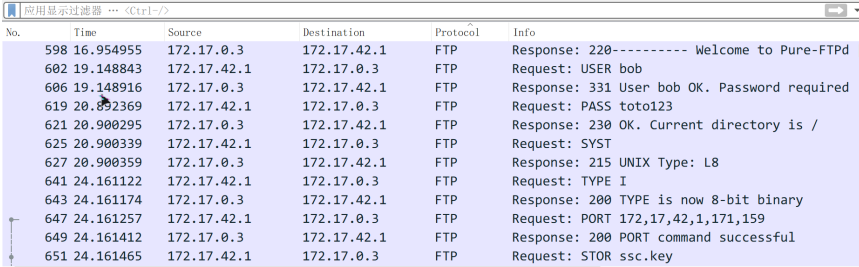
接着分析FTP,直接定位到FTP-DATA,一下子就看到传的密钥了
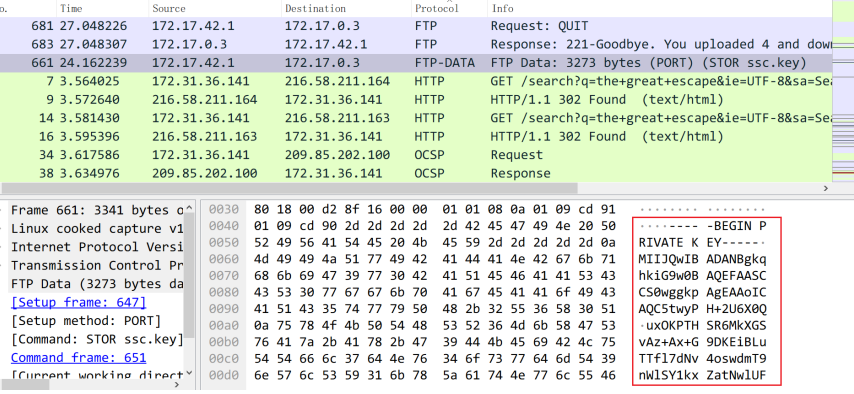
-----BEGIN PRIVATE KEY-----
MIIJQwIBADANBgkqhkiG9w0BAQEFAASCCS0wggkpAgEAAoICAQC5twyPH+2U6X0Q
uxOKPTHSR6MkXGSvAz+Ax+G9DKEiBLuTTfl7dNv4oswdmT9nWlSY1kxZatNwlUF8
WAuGLntO5xTEmOJlMtBFrWGD+DVpCE9KORGvyif8e4xxi6vh4mkW78IxV03VxHM0
mk/cq5kkERfWQW81pVeYm9UAm4dj+LcCwQ9aGd/vfTtcACqS5OGtELFbsHJuFVyn
srpp4K6tLtRk2ensSnmXUXNEjqpodfdb/wqGT86NYg7i6d/4Rqa440a6BD7RKrgp
YPaXl7pQusemHQPd248fxsuEfEwhPNDJhIb8fDX9BWv2xTfBLhGwOh7euzSh2C4o
KSuBAO+bIkL+pGY1z7DFtuJYfTOSJyQ5zQzToxS+jE+2x9/3GpD2LUD0xkA8bWhv
eecq0v6ZWBVYNX54V5ME3s2qxYc6CSQhi6Moy8xWlcSpTSAa7voNQNa9RvQ4/3KF
3gCbKtFvdd7IHvxfn8vcCrCZ37eVkq0Fl1y5UNeJU/Y0Tt8m7UDn3uKNpB841BQa
hiGayCSjsHuTS8B+MnpnzWCrzD+rAzCB37B599iBK4t/mwSIZZUZaqxTWNoFS2Lz
7m0LumZ4Yk8DpDEuWhNs8OUD8FsgAvWFVAvivaaAciF3kMs8pkmNTs2LFBowOshz
SXfONsHupgXEwwFrKOOZXNhb+O/WKQIDAQABAoICAAT6mFaZ94efft/c9BgnrddC
XmhSJczfXGt6cF3eIc/Eqra3R3H83wzaaHh+rEl8DXqPfDqFd6e0CK5pud1eD6Y8
4bynkKI/63+Ct3OPSvdG5sFJqGS7GblWIpzErtX+eOzJfr5N5eNOQfxuCqgS3acu
4iG3XWDlzuRjgSFkCgwvFdD4Fg5HVU6ZX+cGhh2sDzTRlr+rilXTMsm4K/E8udIg
yEbv5KqWEI5y+5Eh9gWY7AnGW6TgLNxzfYyt0nhYhI2+Yh4IkRqQd6F8XQARbEhP
yZx1eK4Q/dRPQxOJNY1KkRpl+Cx6tAPVimByRx1hu82qsTstb6rLHemruOPbf5Dw
aqgSFdp7it3uqjJHCwJ2hAZoijAcvlhn1sa1hr/qFFlY/WeDAi8OyvGdCSh3OvS6
yazkah85GOnY85rz+s98F9cvIqcRdGJrAeNbUHHnj6+X9qFVtwDpF0V1vlvn2Ggp
7m8hiZ0Y+8T+7qfnS9WsdPh7MkoIEoZ0CPryYvX+YPLYWqzxtCvrRWF8tAScI6H+
XBz3NlCAUaOk+ZOkKlZ8ZYMSn/g5EV2jj/mwZVdtYoeQjLaCDuLq8E1Hswnpgq7F
54hHU7vOeJ1/TQltLCNfJFQRaUD+tPz9R6jVpbqBiXxIC2eiGTo1rP4Ii7hsQRFC
W0KKqu+bV69HJAmi06yBAoIBAQDvz+c+3z9njQFFaeUUqyzl31HOzRHmWhJEoriR
nRhWTLzqMyn+RLGrD3DJQj/dGH6tyxHJ7PdI7gtJ3qaF4lCc2dKR3uQW3CBKI9Ys
wzjBWOTijafbttXHanXEwXR3vnPk+sH52BqTXZQVA5vzPwIPJnz3H6E9hL66b/uM
DS9owYRBmykXlV9Gt91Vl5cpg3yxPixaeLMhqDD2Ebq6OFyuacExQHfGUeP0Va/A
IdM9+H5DE13qR2INX+N0kAFyFzW7k8AvY37KGZdoACUrDzmmGoilfs/pFAC0kZaZ
tKXoR9iLNxWSBtlI2Fr3qz4gc5nItYb7JSQsdu6Lc92+9z4xAoIBAQDGQFDXVQyk
Q5tsWicru5v2c9VoFpLUtBg4Dx3uXOMEVl/S5hZ8jYbUH4dcwKyLCYQLtNSc9aei
8zm18TdOGm0nCLOo7OPMeet+JHyx8uz1l/Sx4ucI/Jq3yVSTqdtXYakxzijTldNQ
M7YnjpBcs0yDk806R7J3xvxZNMbElQH1bP947Ej0sv40cBcA0hdpjuuNI5C2Ot4P
fUZXfqR34L7aPZPuP82W2WqFgkTyMY8FO235qR+Sy5xrcHSS4L1FdF+PhS5ZjiPN
sUdXRvfNFQlKZRUyqB147XY7EDnx6BZW2aoM7AiYPiGhxZeV4NHy1ChdBO2CSmOA
03FvucMEmUF5AoIBAD2xorAOBuXA5L7Sy1hR4S8SEJ2/LAeyzFhT9F+hpo0tGLy3
hOohCgQT6NQd8wgSMSTMxTrJd6SPeN/8I6L14f84Gm/kg5FN+BCav5KsdoFnORr/
jlt74et3e+yuSCQ2HuKdkCGScuPOgzYUw54Ea6cyI5v/yx9kcxzLik8xZSzx+/BU
1nF2wBgVXR+T7BOF/CIs+IQd4RebiV0EmqElttI36rec+jNPBfHpyVkIWqvqrbDb
3qFS0+rU7FMkaPrM9cnX7O1ED242vzjGMMmvFQmicd0BjsNLnhLWEYRhcP0c3pyS
Az6Z/HQ9FMn6h/UZSErWSG970p6NyjieCkICoUECggEBALdyXhvTPD5nvNL3XRWv
pXLY3plRgg7Gkz6UZmrhksO5tTOu6xHX1/JDNntSYpbJeGFos/CFs9gp3rYH/dgM
xgH/oFdo1KWqD4oK80OqeTAMq0VLo+OB8xyrdNKqsydZXDmU/dxD4GRvZVeXKOhO
lTePtbD/FRqWi310Q5U2GLjkYkWfxyZ+1pDpQ6/jt/xaXoacaVTmhgKpNkTSEBhJ
Y/EIV/F3IqM6jcH6uBewWhpKUspZf7jTJeuZBJXA1gMF20MvxqLhzymPqGcPaU9g
7tbjUEkunQ8AFI40xpmc28cD5MHOS2ms3GwYLdtnTH65aJwiajBM62QSw/3RU67W
rWkCggEBAOtMBi9ko4ZR96BCFcuyPsiMcoDBQBEFgH/drT3hMlwmmVt5dcInw3Zk
DQb3gIWHP1Ul//Ma8qwSeuIua0+6wkQ3NcsDywlJ2cqfZUe7kVJTCl8fuudTAYqT
Bs5Y1ktYPSyQOxmidMeX5IcGe5fPSdpFu9wMXXQ31l8o9SzccFKwz1P1o8G00xvx
wtcfAZ204Dcrdfm6xTWmzMrHqngS1uUDOJbW175gQqeAszy8wLMz41Yau3ypk3ga
edWr4Hzbiph0V1Dv/V+kmmreWBmHetH6bhrTWQq3UZ5WbGMpiTmSsD0EXU5vZLbX
xmZSEXjNvG9grjxwR96vp1PK/4Bq1jo=
-----END PRIVATE KEY-----
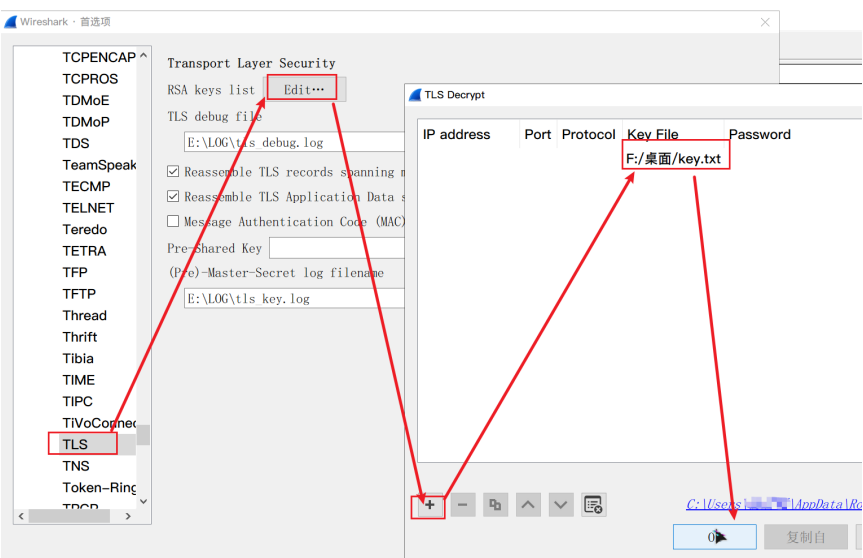
将其存为key.txt,依次点击编辑>首选项>Protocols>TLS>Edit添加这个私钥文件然后就可以解密了
接着就可以用http contains过滤查找字符串"CTF"、"FLAG"、"flag"
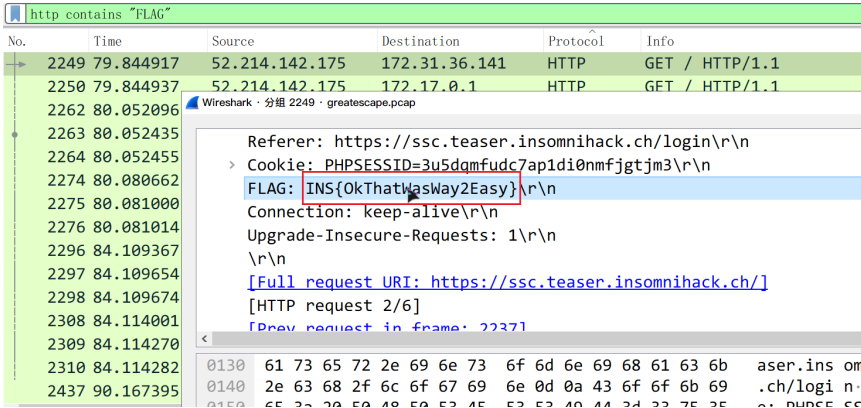
得到flag
flag{OkThatWasWay2Easy}
[GKCTF 2021]你知道apng吗
其实是个动图,用Honeyview打开是这个样子的,可以看到有二维码闪现

ScreenToGif录制后,逐帧查看发现一共有四个二维码。。。

那个不明显的可以用StegSolve
那个歪的可以用PS拉伸(先给图层解锁然后编辑>变换>扭曲/变形)
得到flag
flag{a3c7e4e5-9b9d-ad20-0327-288a235370ea}
buu-很好的色彩呃?
得到一个图片,用栅栏将几个相近的颜色隔开

用GIMP或者PS等将这些颜色的RGB值提取出来如下
8b8b61
8b8b61
8b8b70
8b8b6a
8b8b65
8b8b73
最后两位提取出来用ASCII解码得到flag
>>> import binascii
>>> binascii.unhexlify('6161706a6573')
b'aapjes'
flag{aapjes}
[*CTF2019]otaku
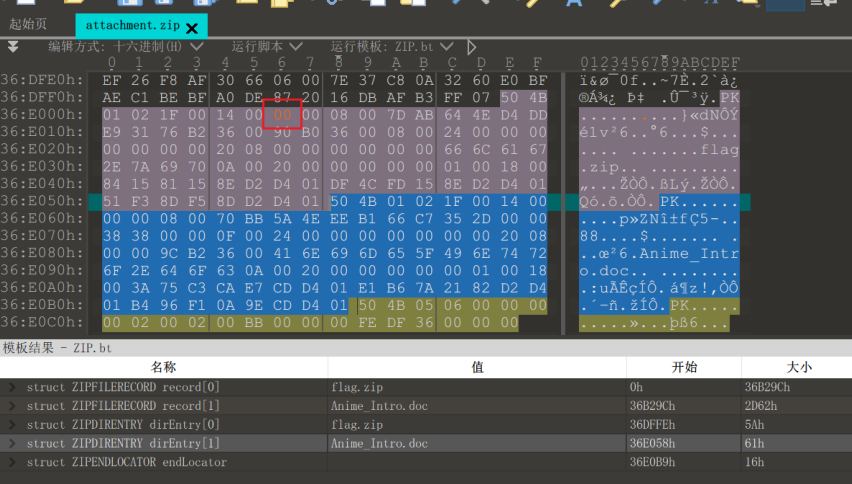
先是一个伪加密,去除之后解压缩得到一个word文档和加密过的压缩包flag.zip
doc文档中找到隐藏文字(在文件选项中单击“文件” \(\rightarrow\) “更多”\(\rightarrow\) “选项”\(\rightarrow\) “显示”,在始终在屏幕上显示这些格式标记标签下选择隐藏文字复选框,即可查看隐藏文字)

选中后在字体对话框取消隐藏就可以复制
Hello everyone, I am Gilbert. Everyone thought that I was killed, but actually I survived. Now that I have no cash with me and I’m trapped in another country. I can't contact Violet now. She must be desperate to see me and I don't want her to cry for me. I need to pay 300 for the train, and 88 for the meal. Cash or battlenet point are both accepted. I don't play the Hearthstone, and I don't even know what is Rastakhan's Rumble.
接下来按理说是要用已知明文攻击把flag.zip中的flag.png破解出来的,这段话就是已知明文,但如果我们直接将这段话粘贴到文件可以看到与flag.zip中的last words.txt大小相差了1个字节
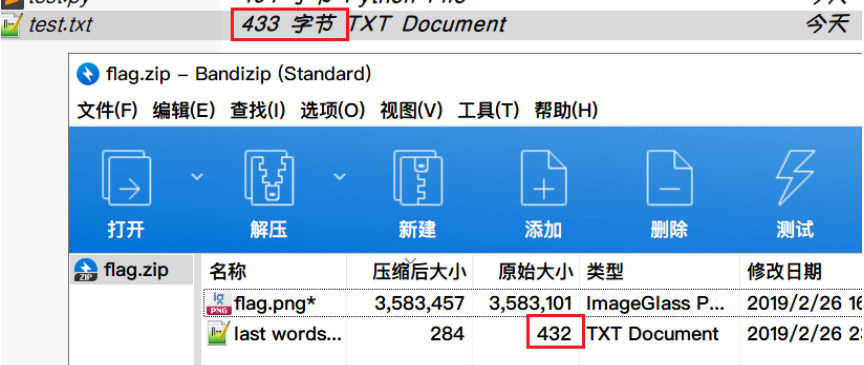
这里其实是一个编码问题,因为这段话里面有一个中文的引号。。。(下图中左边的框,可以与右边的框做个对比看看就可以看到区别了),对这个引号在文件中的编码方式的不同导致了文件的大小有所差异

UTF-8处理中文符号是用3个字节存储,而GBK则是用2个字节,Notepad++默认用UTF-8编码存储所以多出来1个字节,因而我们需要调整编码格式后再复制,或者直接用windows自带的记事本(记事本默认采用GBK编码)
这里我就直接用Notepad++了,按照如下方式更改编码格式后直接将那段文字粘贴即可
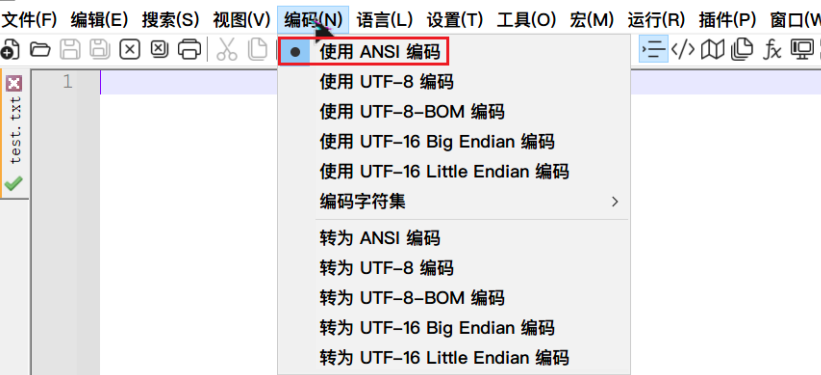
flag.zip的注释中给出了压缩细节,按照这个压缩test.txt得到已知明文
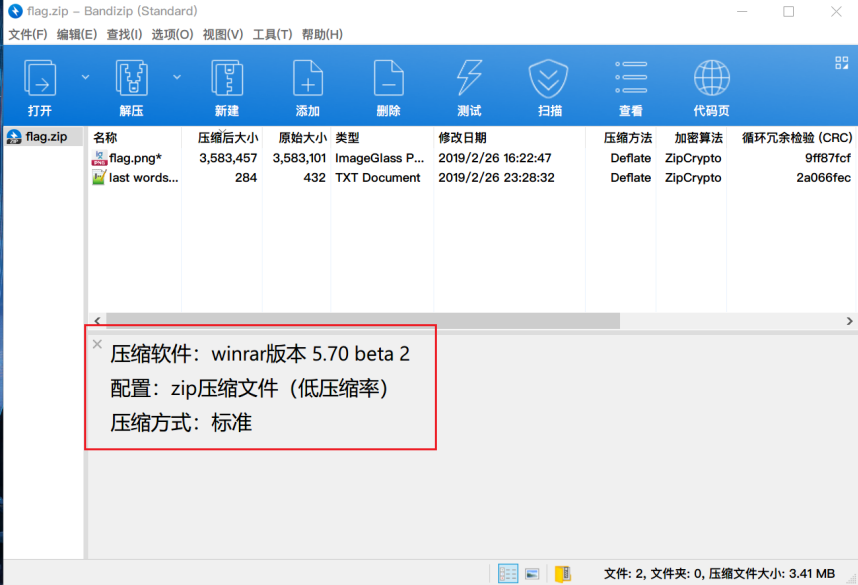
比对二者的CRC确保一致
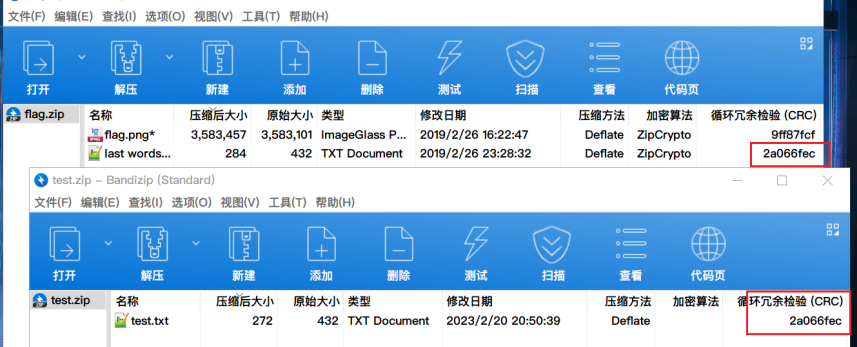
用ARCHPR进行已知明文攻击
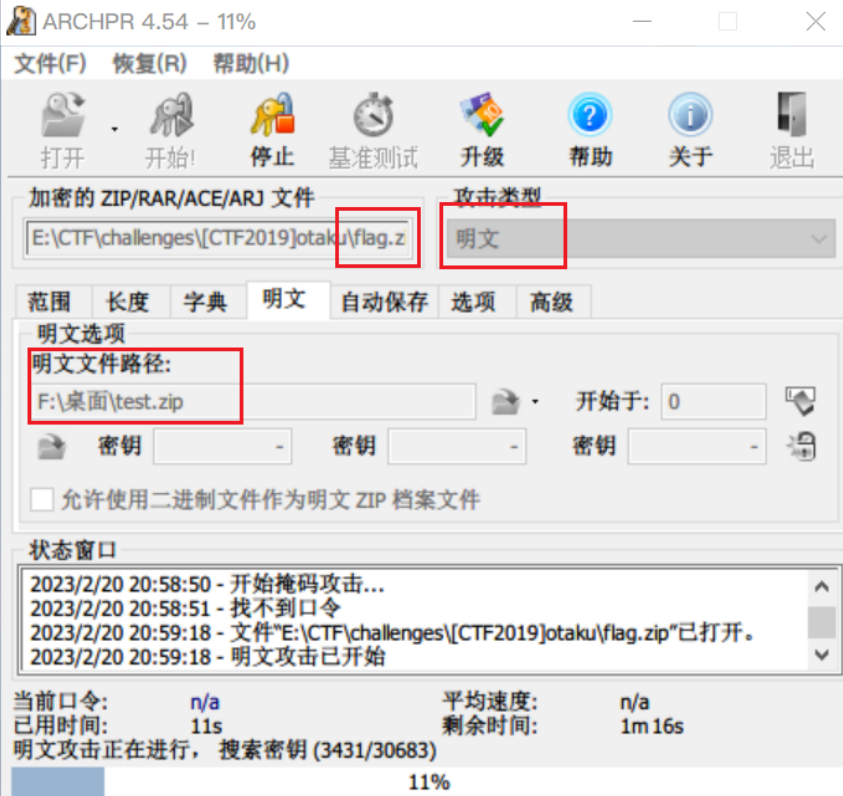
得到口令My_waifu
LSB隐写,找到flag
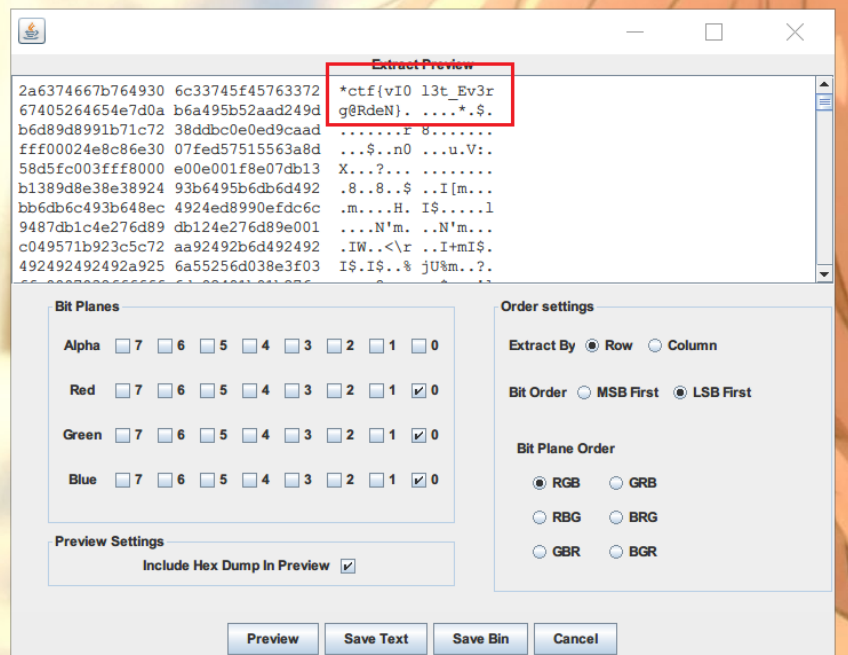
*ctf{vI0l3t_Ev3rg@RdeN}
buu-大流量分析(一)
题目:某黑客对A公司发动了攻击,以下是一段时间内我们获取到的流量包,那黑客的攻击ip是多少?(答案加上flag{})附件链接: https://pan.baidu.com/s/1EgLI37y6m9btzwIWZYDL9g 提取码: 9jva 注意:得到的 flag 请包上 flag{} 提交
要获取黑客的攻击IP,那就直接在Wireshark中统计IP出现的频率(统计>IPv4 Statistics>All Address)
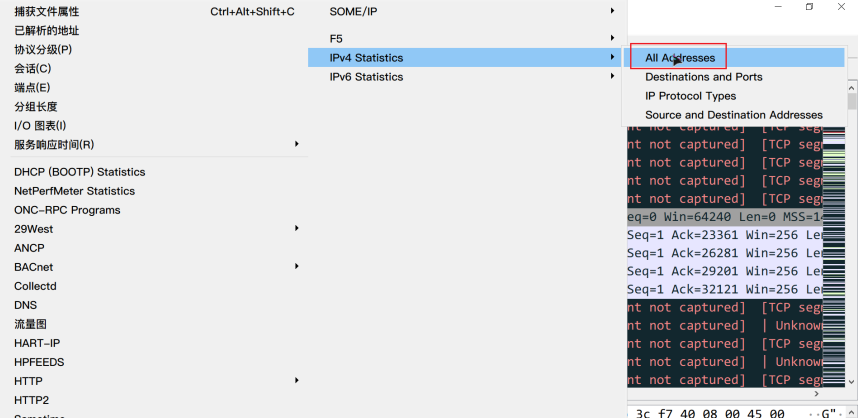
找到非私有IP地址中频数最高的
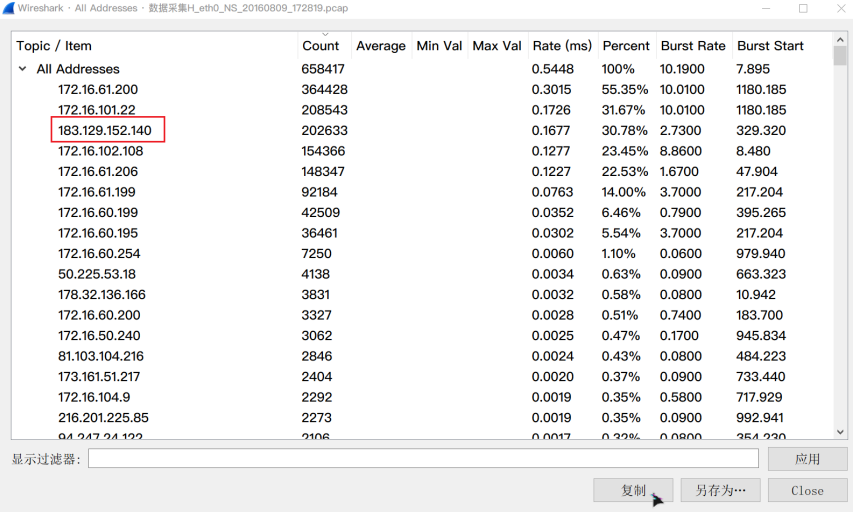
flag{183.129.152.140}
[XMAN2018排位赛]AutoKey
打开发现是键盘流量包,于是用脚本UsbKeyboardDataHacker.py提取一下击键信息
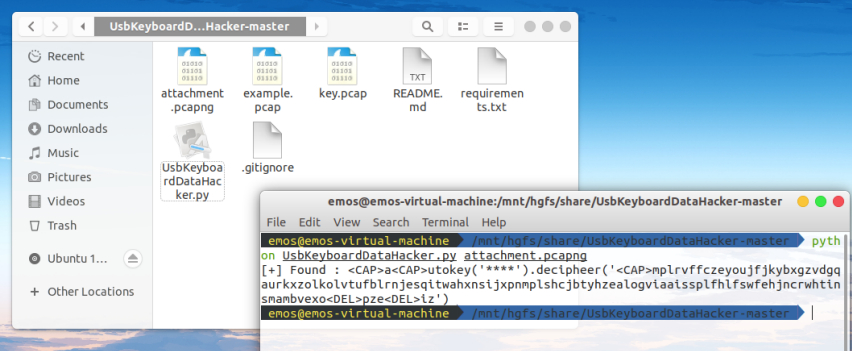
python UsbKeyboardDataHacker.py attachment.pcapng
<CAP>a<CAP>utokey('****').decipheer('<CAP>mplrvffczeyoujfjkybxgzvdgqaurkxzolkolvtufblrnjesqitwahxnsijxpnmplshcjbtyhzealogviaaissplfhlfswfehjncrwhtinsmambvexo<DEL>pze<DEL>iz')
不难看出,<CAP> 是转换大小写的键,<DEL> 是删除键,于是上面的相当于输入了Autokey.decipher('MPLRVFFCZEYOUJFJKYBXGZVDGQAURKXZOLKOLVTUFBLRNJESQITWAHXNSIJXPNMPLSHCJBTYHZEALOGVIAAISSPLFHLFSWFEHJNCRWHTINSMAMBVEXPZIZ'),是个python代码,但这个直接在python环境中运行是缺少参数的,而这个未知的参数就是密钥。

于是用breakautokey脚本暴破,脚本需要运行在Python2环境下,先安装pycipher库(pip2 install pycipher),将得到的密文赋给变量ctext(如下),然后再python2 breakautokey.py运行。
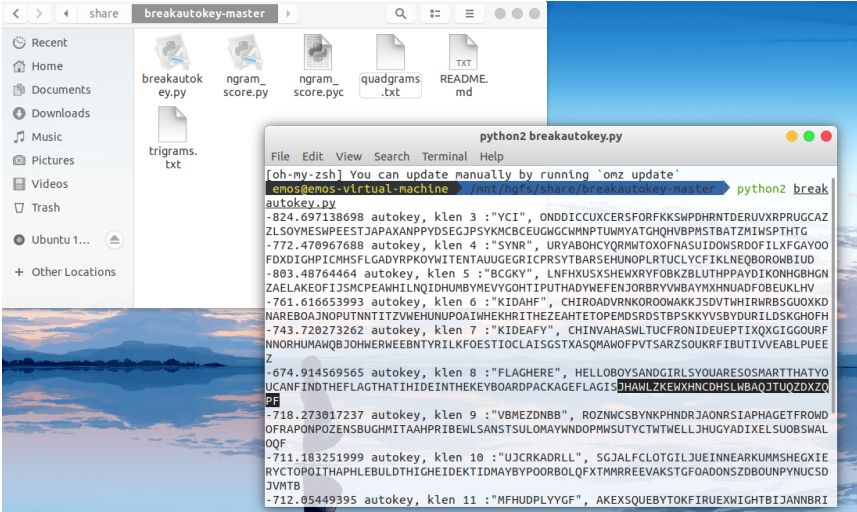
得到flag
flag{JHAWLZKEWXHNCDHSLWBAQJTUQZDXZQPF}