
近日,阿里云人工智能平台PAI与华南理工大学朱金辉教授团队、达摩院自然语言处理团队合作在自然语言处理顶级会议EMNLP2023上发表基于机器翻译增加的跨语言机器阅读理解算法X-STA。通过利用一个注意力机制的教师来将源语言的答案转移到目标语言的答案输出空间,从而进行深度级别的辅助以增强跨语言传输能力。同时,提出了一种改进的交叉注意力块,称为梯度解缠知识共享技术。此外,通过多个层次学习语义对齐,并利用教师指导来校准模型输出,增强跨语言传输性能。实验结果显示,我们的方法在三个多语言MRC数据集上表现出色,优于现有的最先进方法。
论文:
Tingfeng Cao, Chengyu Wang, Chuanqi Tan, Jun Huang, Jinhui Zhu. Sharing, Teaching and Aligning: Knowledgeable Transfer Learning for Cross-Lingual Machine Reading Comprehension. EMNLP 2023 (Findings)
背景
大规模预训练语言模型的广泛应用,促进了NLP各个下游任务准确度大幅提升,然而,传统的自然语言理解任务通常需要大量的标注数据来微调预训练语言模型。但低资源语言缺乏标注数据集,难以获取。大部分现有的MRC数据集都是英文的,这对于其他语言来说是一个困难。其次,不同语言之间存在语言和文化的差异,表现为不同的句子结构、词序和形态特征。例如,日语、中文、印地语和阿拉伯语等语言具有不同的文字系统和更复杂的语法系统,这使得MRC模型难以理解这些语言的文本。
为了解决这些挑战,现有文献中通常采用基于机器翻译的数据增强方法,将源语言的数据集翻译成目标语言进行模型训练。然而,在MRC任务中,由于翻译导致的答案跨度偏移,无法直接使用源语言的输出分布来教导目标语言。
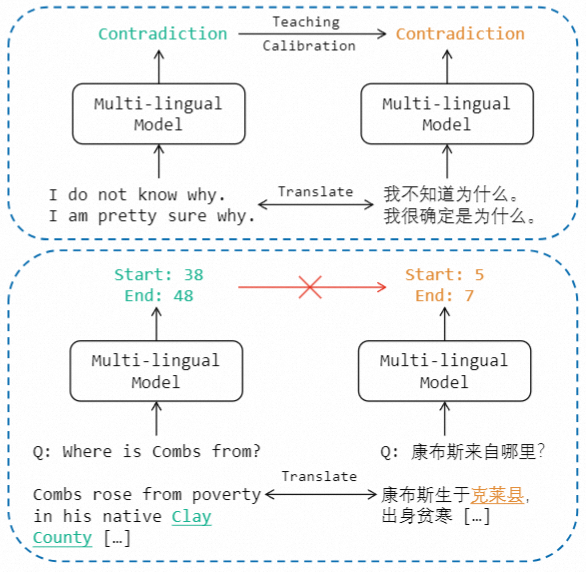
因此,本文提出了一种名为X-STA的跨语言MRC方法,遵循三个原则:共享、教导和对齐。共享方面,提出了梯度分解的知识共享技术,通过使用平行语言对作为模型输入,从源语言中提取知识,增强对目标语言的理解,同时避免源语言表示的退化。教导方面,本方法利用注意机制,在目标语言的上下文中寻找与源语言输出答案语义相似的答案跨度,用于校准输出答案。对齐方面,多层次的对齐被利用来进一步增强MRC模型的跨语言传递能力。通过知识共享、教导和多层次对齐,本方法可以增强模型对不同语言的语言理解能力。
算法概述
X-STA模型框架图如下所示:
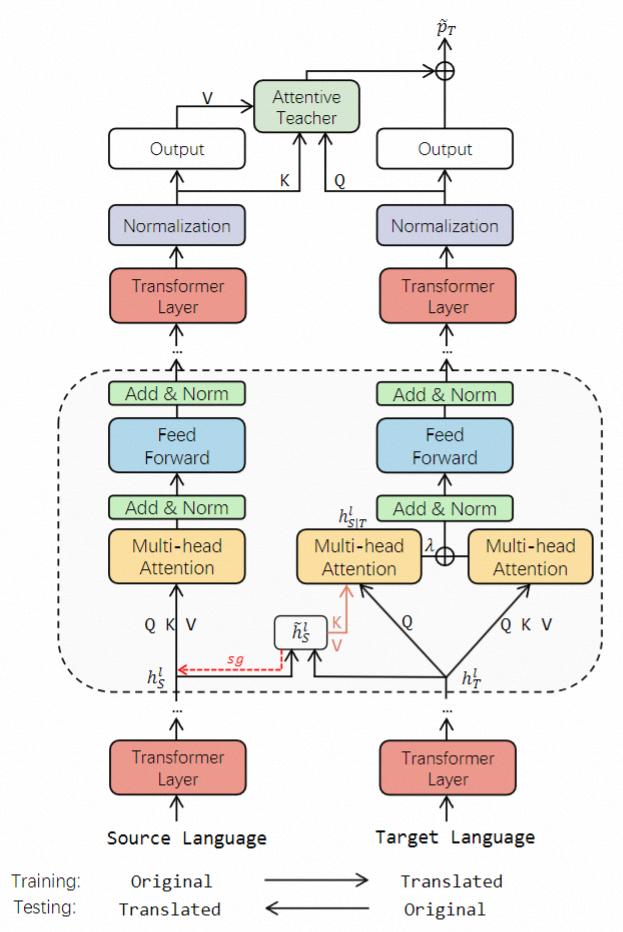
给定上下文C和问题Q, MRC任务是从上下文C提取子序列作为问题Q的正确答案。将输入序列表示为
其中N是序列长度。我们使用$\textbf{p}\text{start} \in \mathbb{R}^{N}
\textbf{p}\text{end} \in \mathbb{R}^{N}
\textbf{p} \in \mathbb{R}^{N\times 2}
\mathbf{y} \in \mathbb{R}^{N\times 2} $表示一个序列的one-hot标签。
具体流程如下:
- 先将源语言的目标数据翻译到各个目标语言,目标语言的测试数据也翻译回源语言。
- 每项数据包含问题Q和上下文段落C。
- 构建并行语言对={源语言训练数据,目标语言训练数据}送入模型并使用反向传播进行模型训练。
- 将并行语言对={源语言测试数据,目标语言测试数据}送入模型获取答案的预测。
算法精度评测
为了验证X-STA算法的有效性,我们在三个跨语言MRC数据集上进行了测试,效果证明X-STA对精度提升明显:
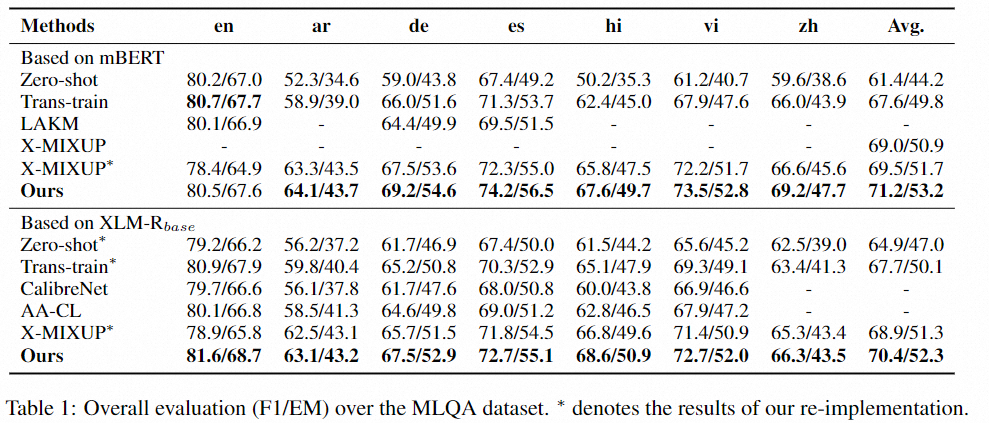
我们也对算法的模块进行了详细有效性分析,我们可以发现各模块均对模型有一定贡献。

为了更好地服务开源社区,这一算法的源代码即将贡献在自然语言处理算法框架EasyNLP中,欢迎NLP从业人员和研究者使用。
EasyNLP开源框架:https://github.com/alibaba/EasyNLP
参考文献
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- Rajpurkar, Pranav, et al. "SQuAD: 100,000+ Questions for Machine Comprehension of Text." Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016.
论文信息
论文标题:Sharing, Teaching and Aligning: Knowledgeable Transfer Learning for Cross-Lingual Machine Reading Comprehension
论文作者:曹庭锋、汪诚愚、谭传奇、黄俊、朱金辉
论文pdf链接:<https://arxiv.org/abs/2311.06758>