1. 豆瓣民谣Top排名爬取
1.1 构建scrapy项目
-
安装Scrapy库
pip install scrapy -
创建Scrapy项目
通过cmd进入命令窗口,执行命令scrapy startproject xxxx (xxxx为scrapy项目名),创建scrapy项目。
scrapy startproject douban_spider2024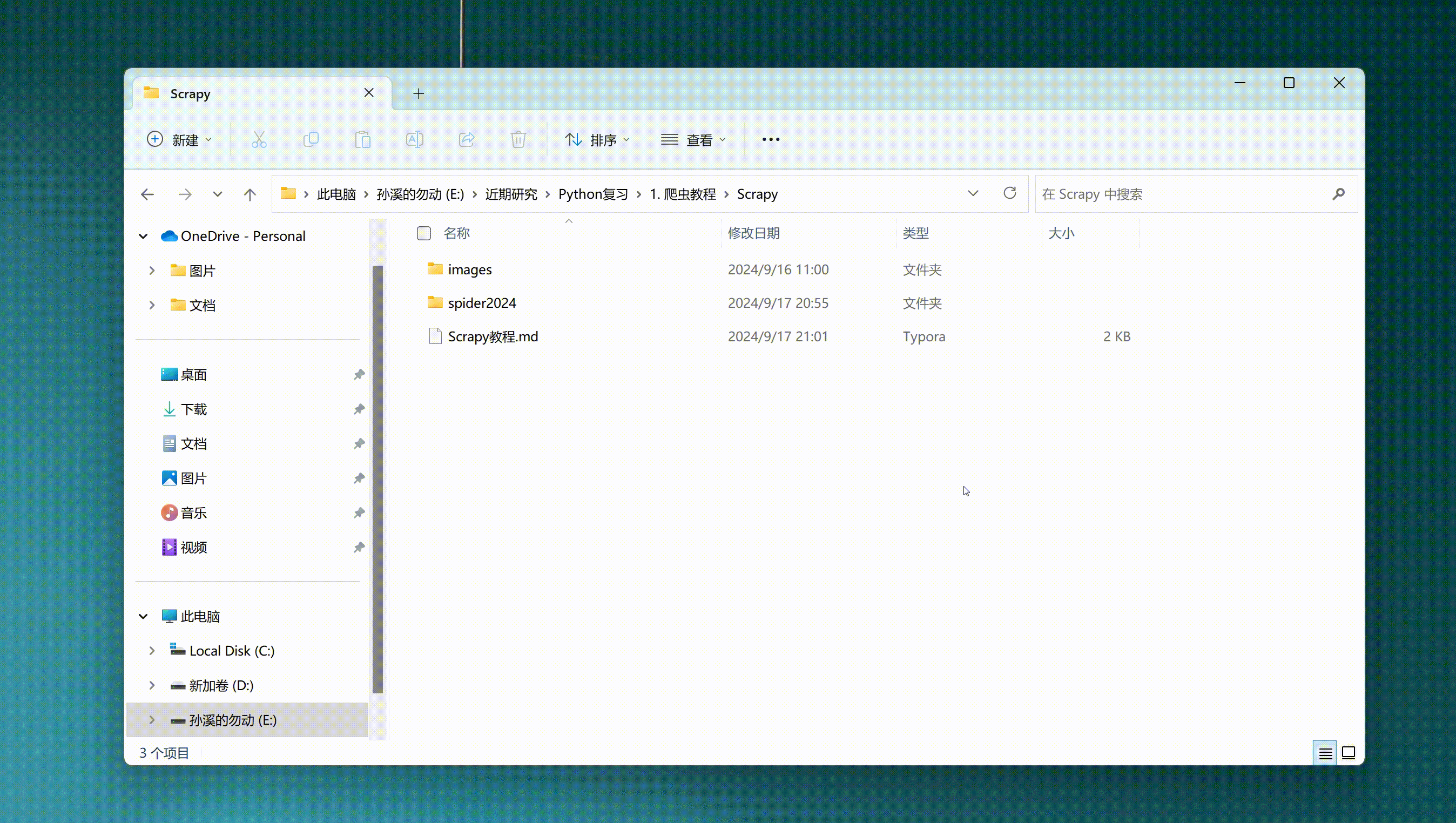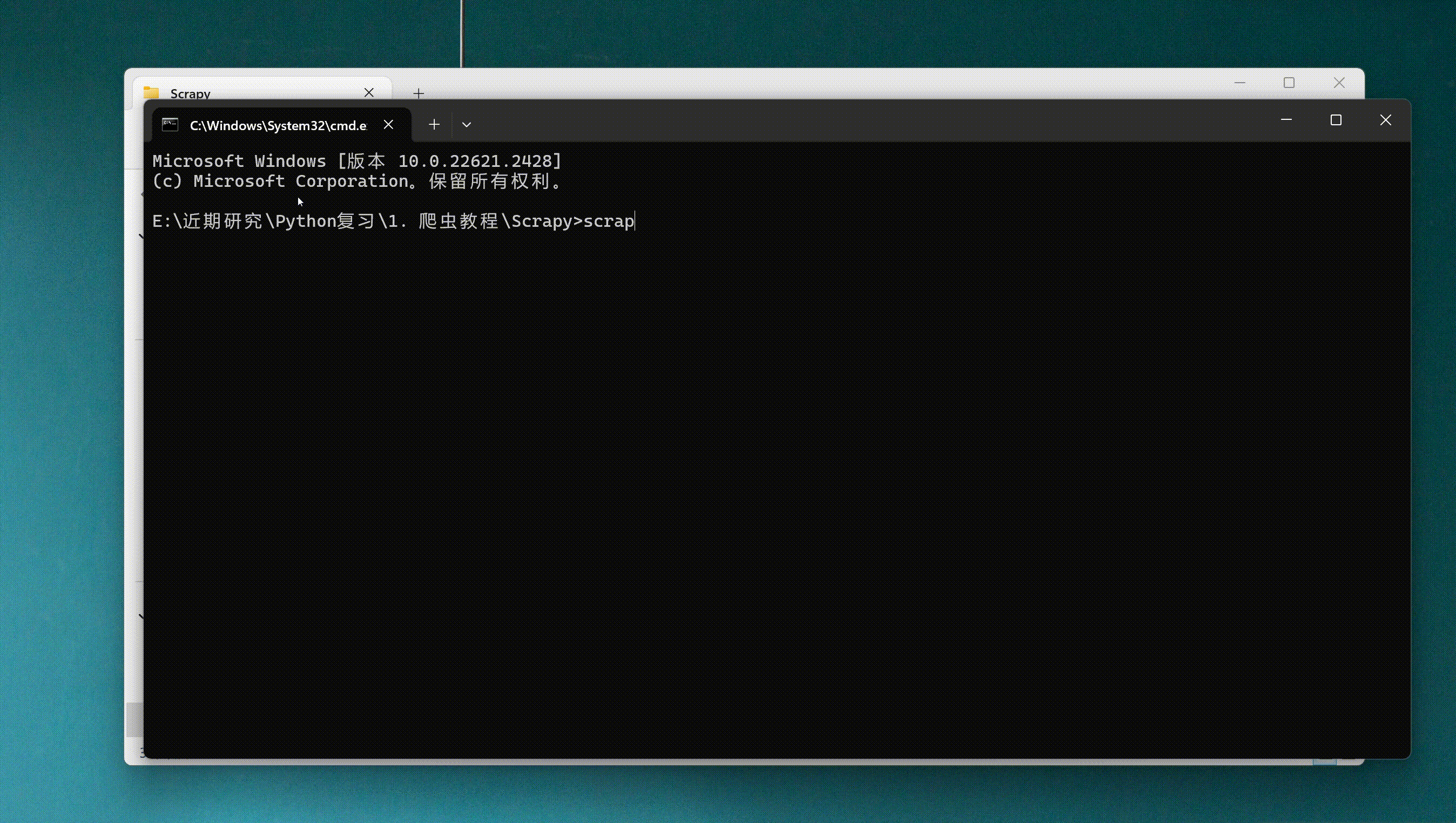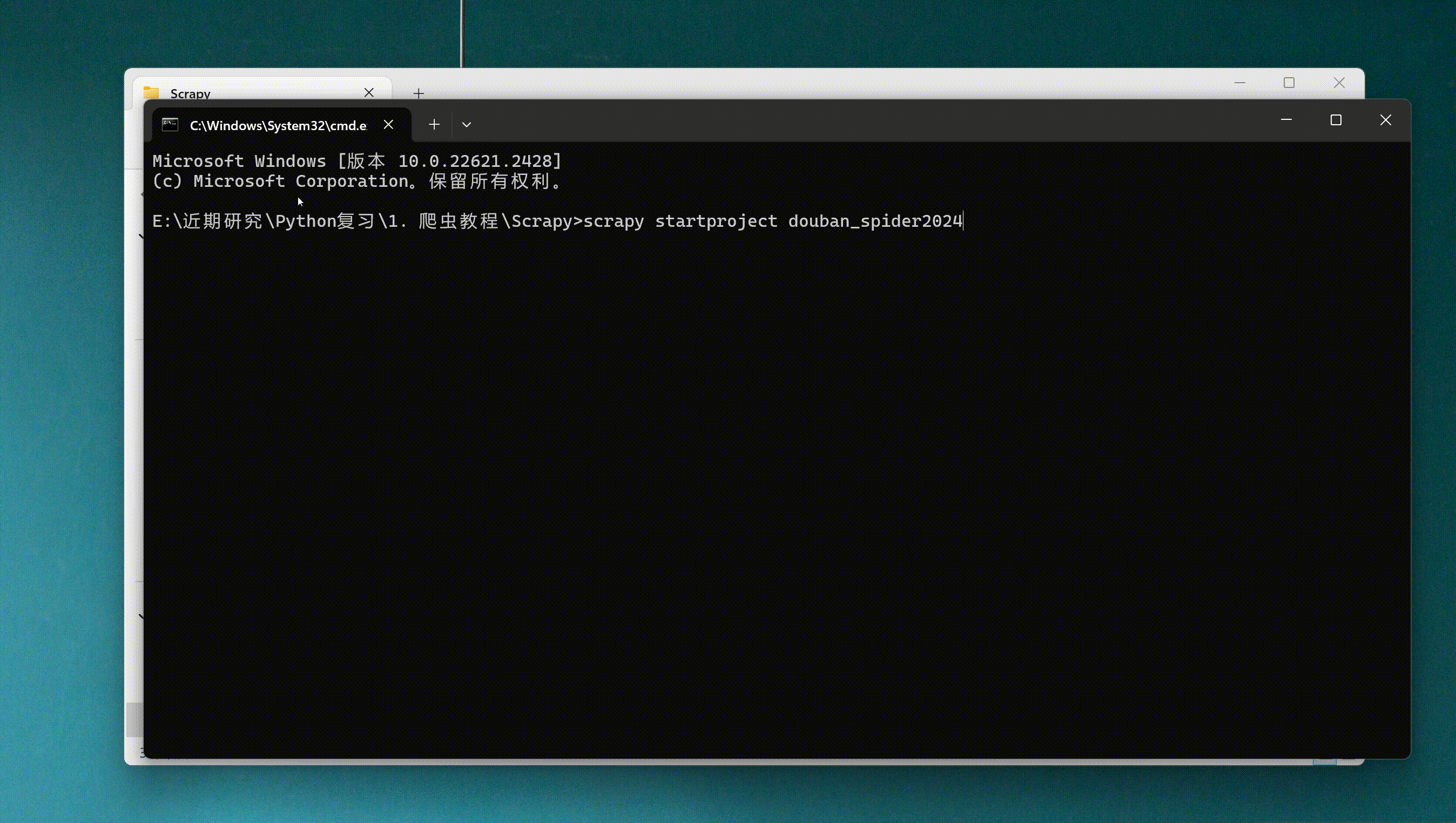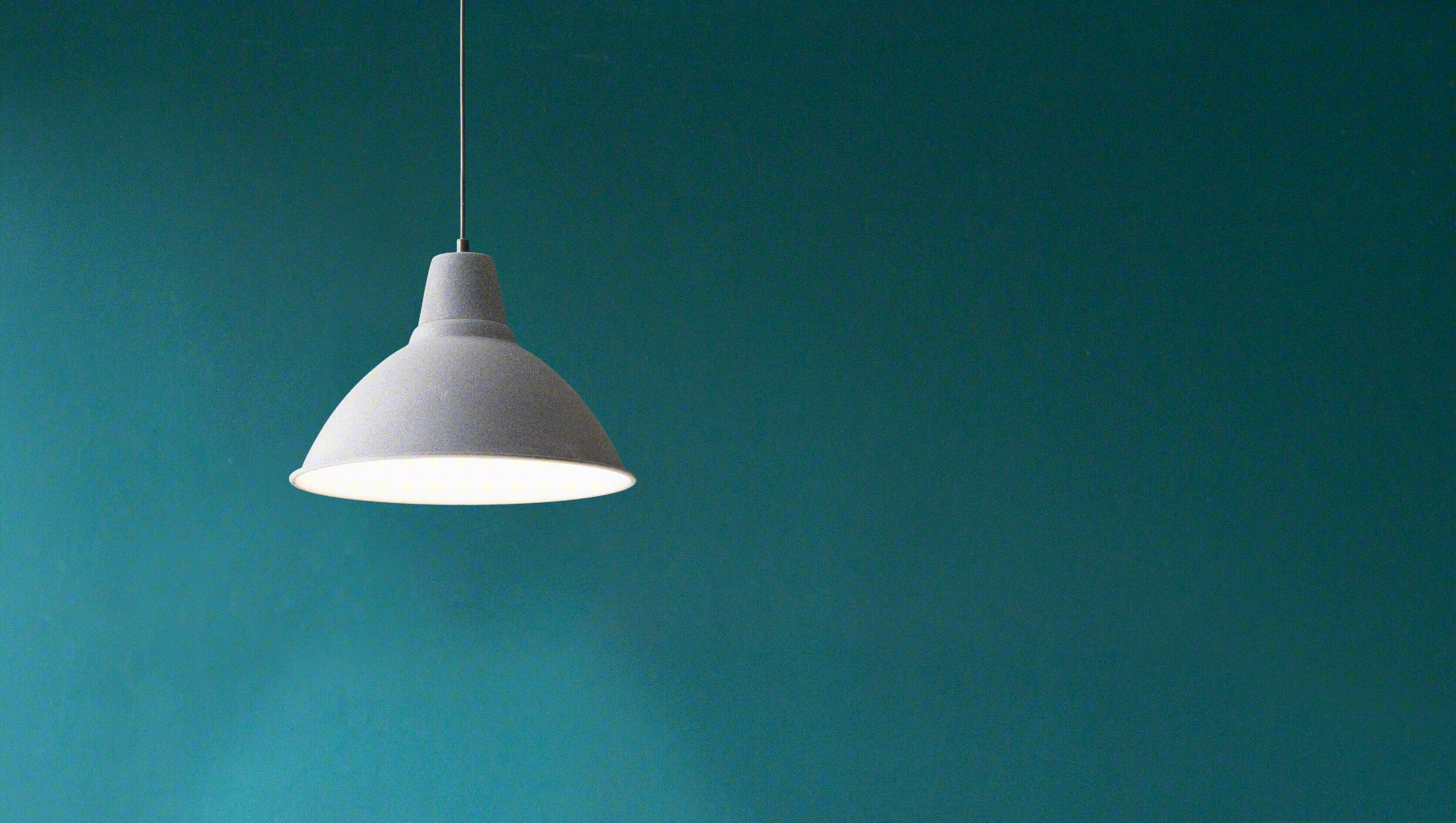
-
创建爬虫项目
执行scrapy genspider xxx(爬虫名称) xxx(网址)创建爬虫项目。
scrapy genspider douban www.bouban.com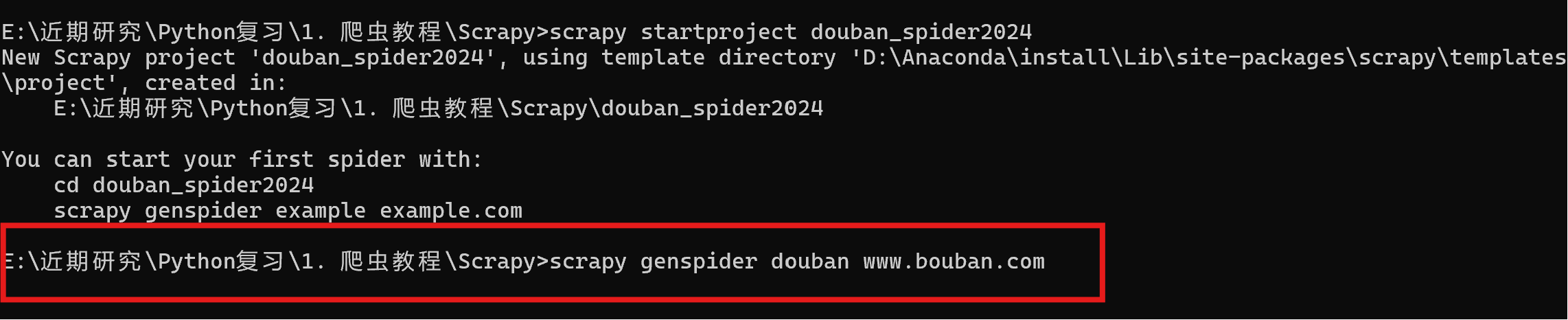



1.2 虚拟环境构建
-
使用Pycharm打开创建好的douban_spider2024文件夹,进入项目。
-
构建虚拟环境(venv)

-
利用requirement.txt文件安装依赖库,也可以自己一个个pip安装。
-
查看依赖库:pip freeze > requirements.txt
-
安装依赖库:pip install -r requirements.txt

-



1.3 主程序编写
主程序(douban.py)用于编写解析页面的主要内容的代码。(url: https://music.douban.com/tag/民谣)
-
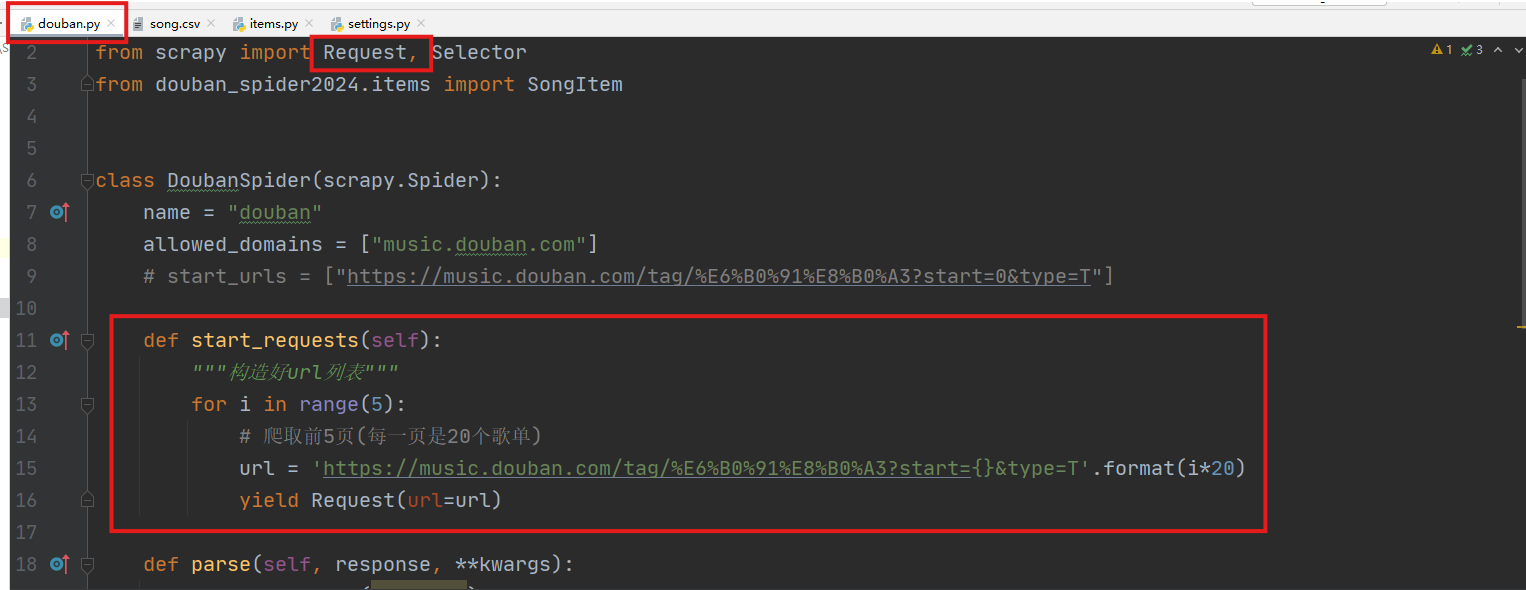
通过start_requests函数获取urls列表,并用Request封装(需要配合在settings.py中启用下载中间件)。
-
通过parse函数进行网页解析。



1.4 items.py设置
-
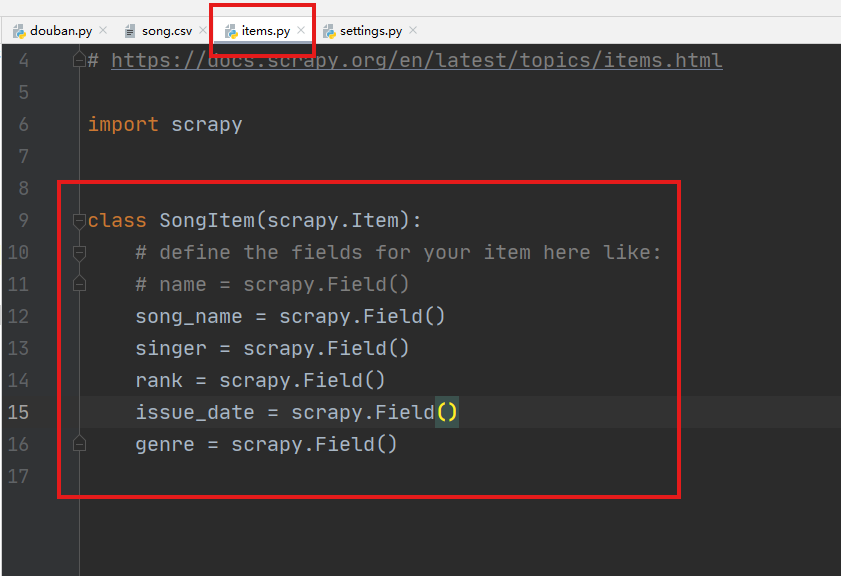
继承scrapy.Item的自定义类SongItem,导入到主程序douban.py中用于存储爬取的字段。

1.5 settings.py设置
用于控制Scrapy框架中各部件的参数,例如USER_AGENT、COOKIES、代理、中间件启停等。
-
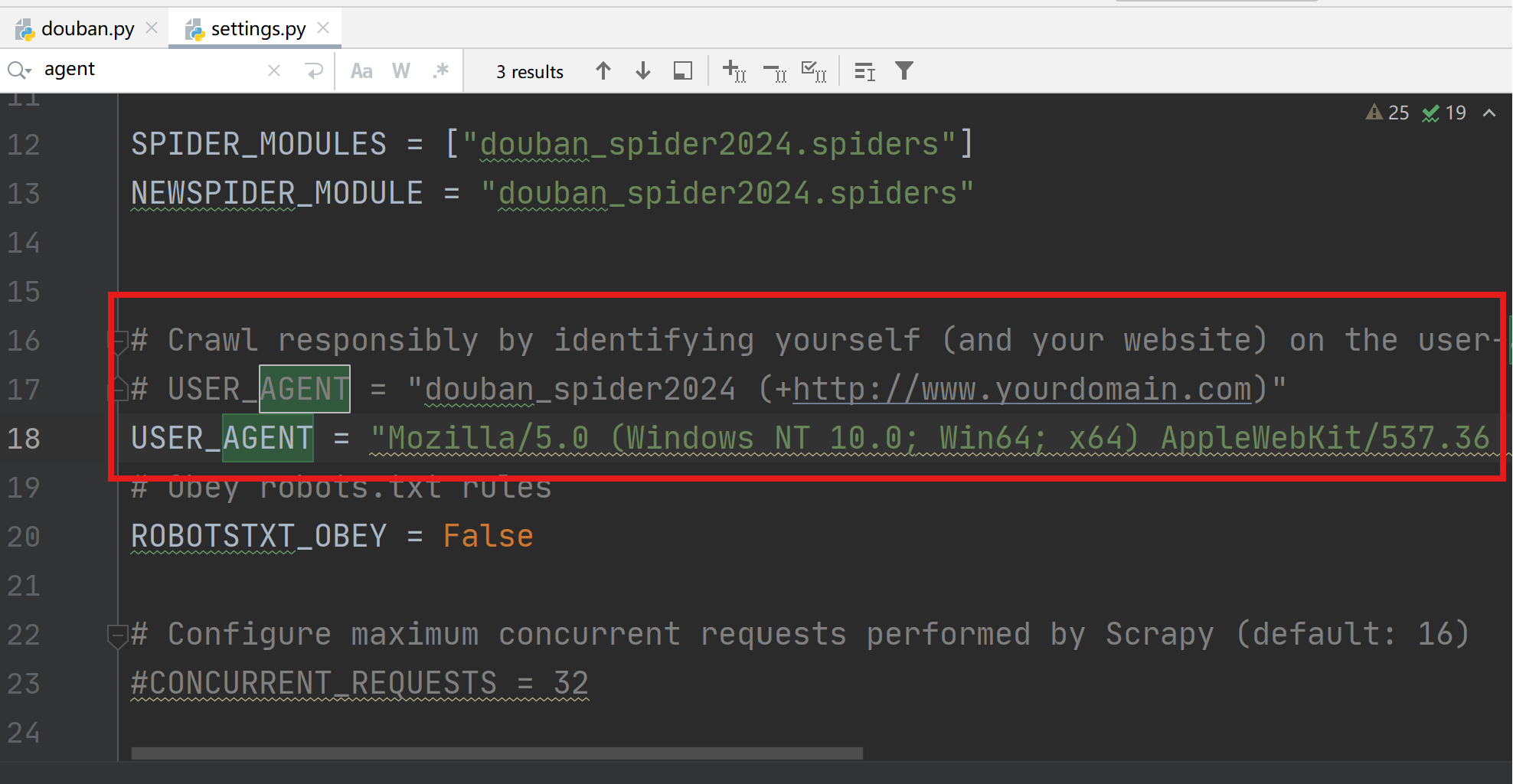
修改USER_AGENT,模拟浏览器登录。
-
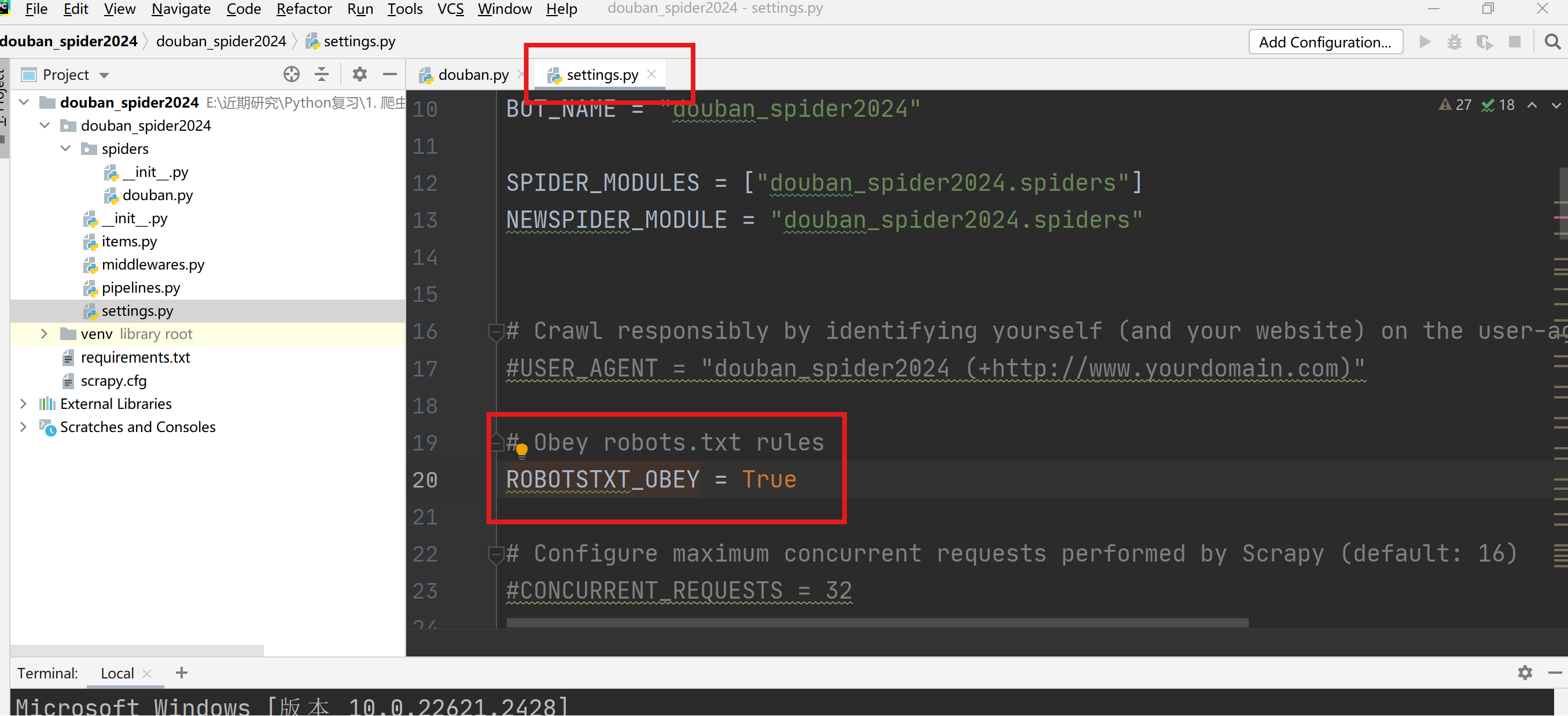
关闭Obey robots.txt rules,将True设置为False。
-
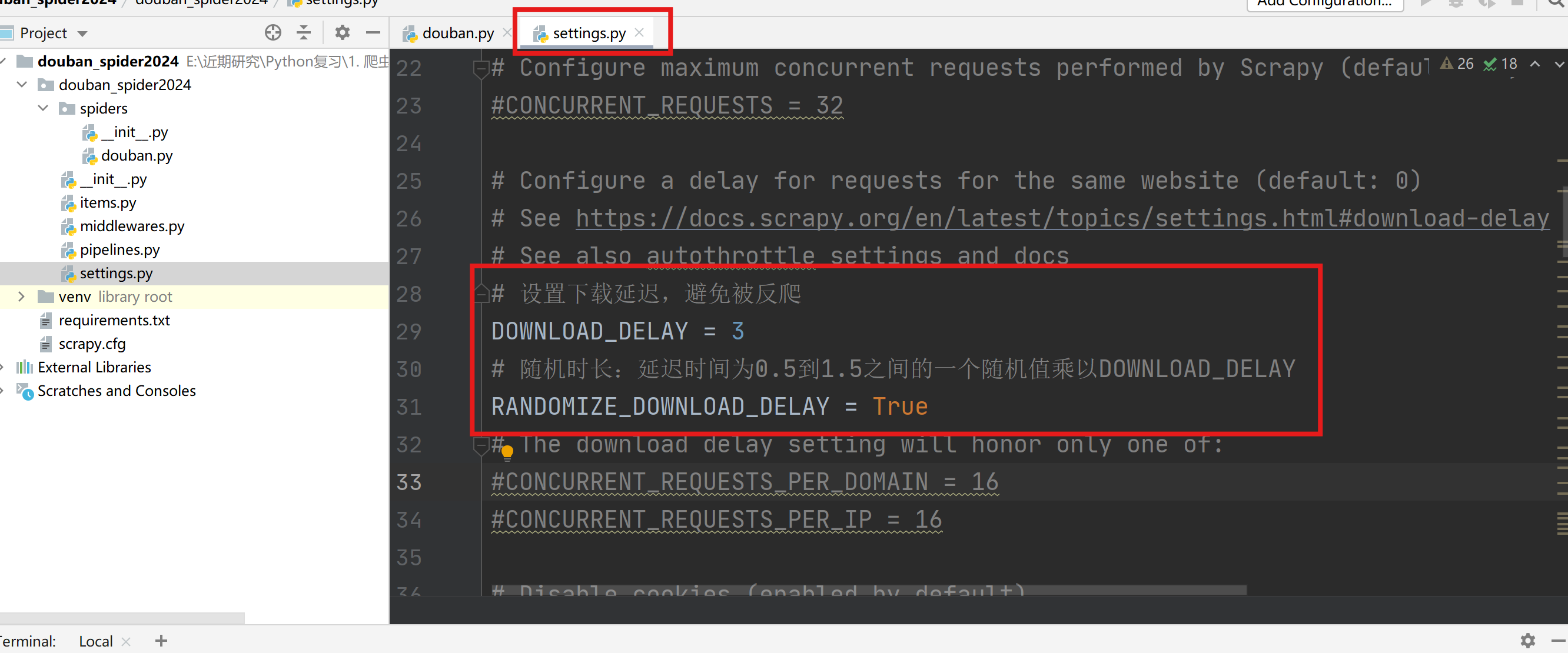
设置下载延迟
-
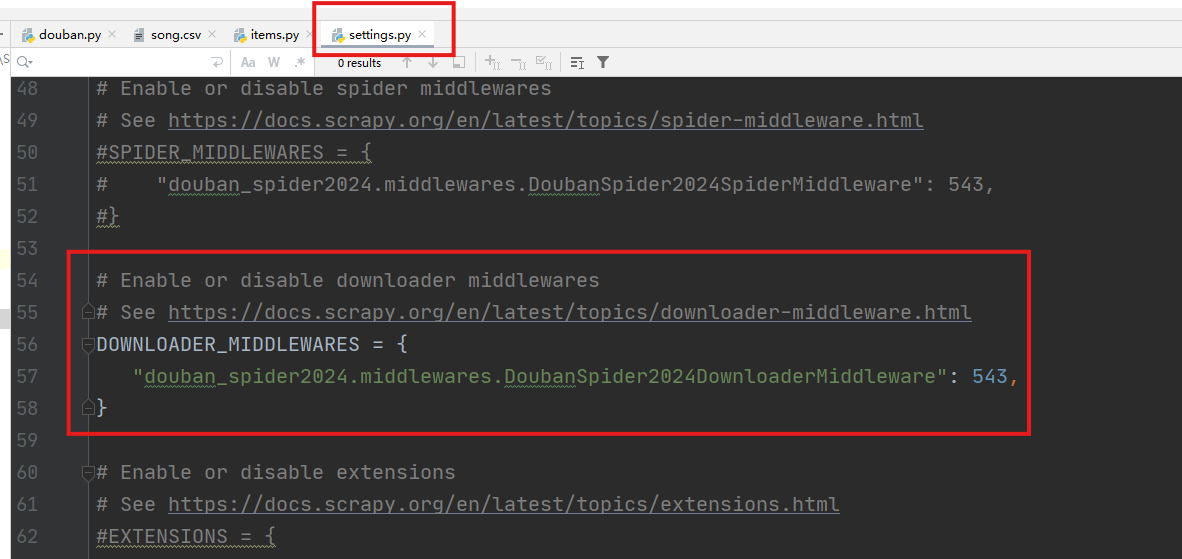
打开下载中间件(downloader_middlewares),实现拦截并修改Request的请求内容。




1.6 middlewares.py设置
-
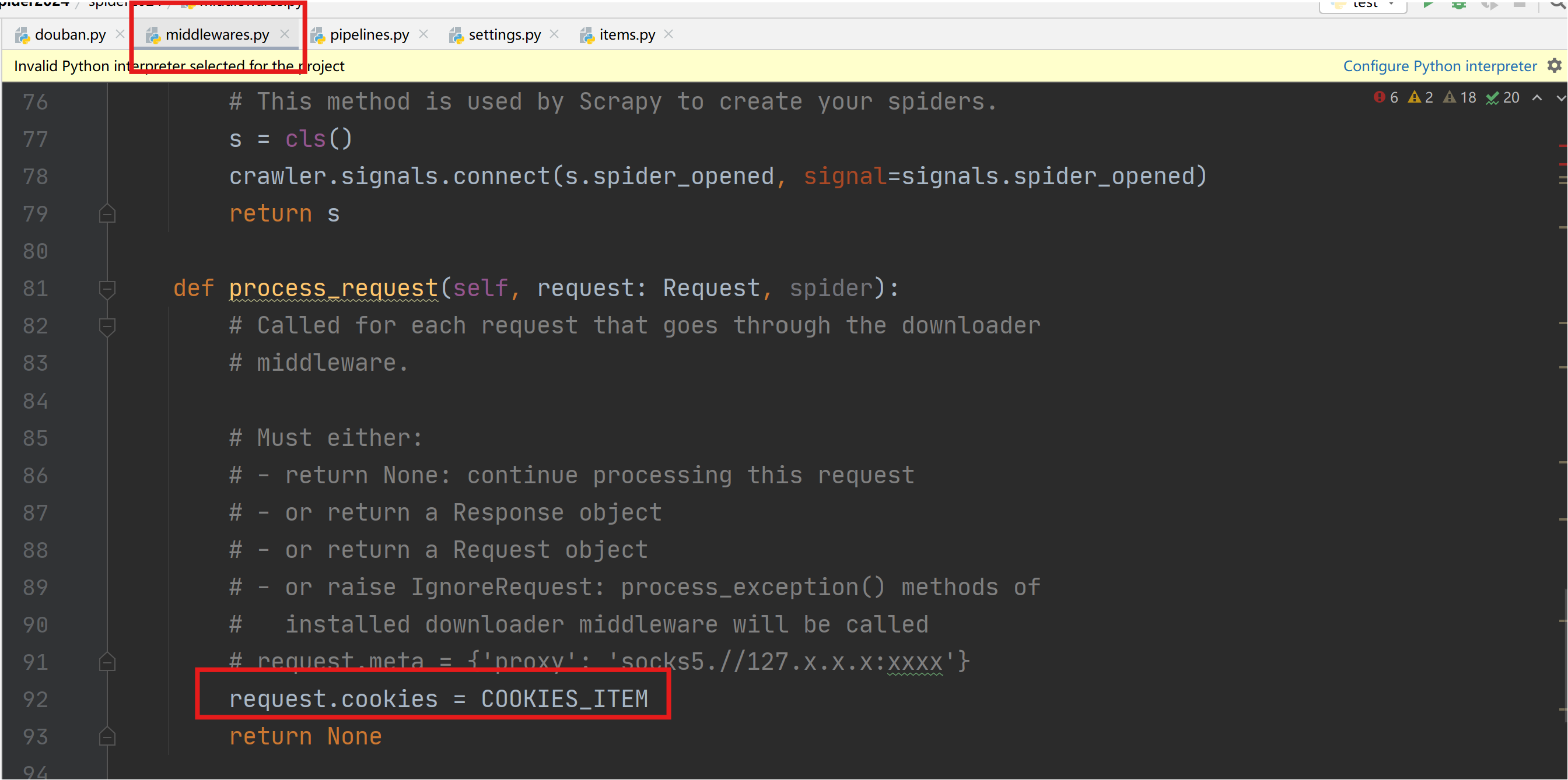
cookies设置
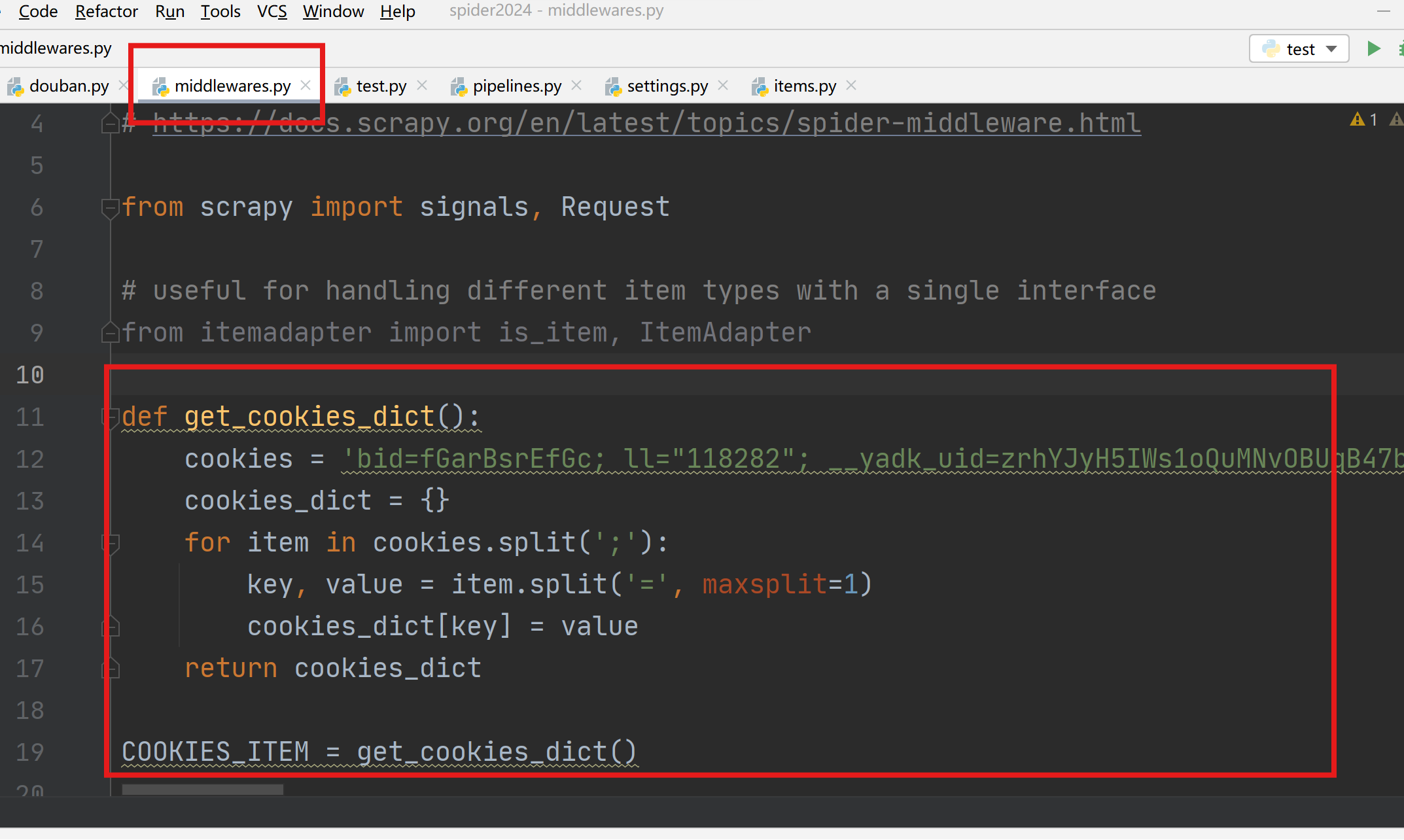
进入middlewares.py程序中设置,新增一个处理cookies的函数,执行cookies函数返回一个包含cookies的字典COOKIE_ITEM。
在xxDownloaderMiddleware类中process_request函数配置COOKIES_ITEM。
-
scrapy 利用sock代理??



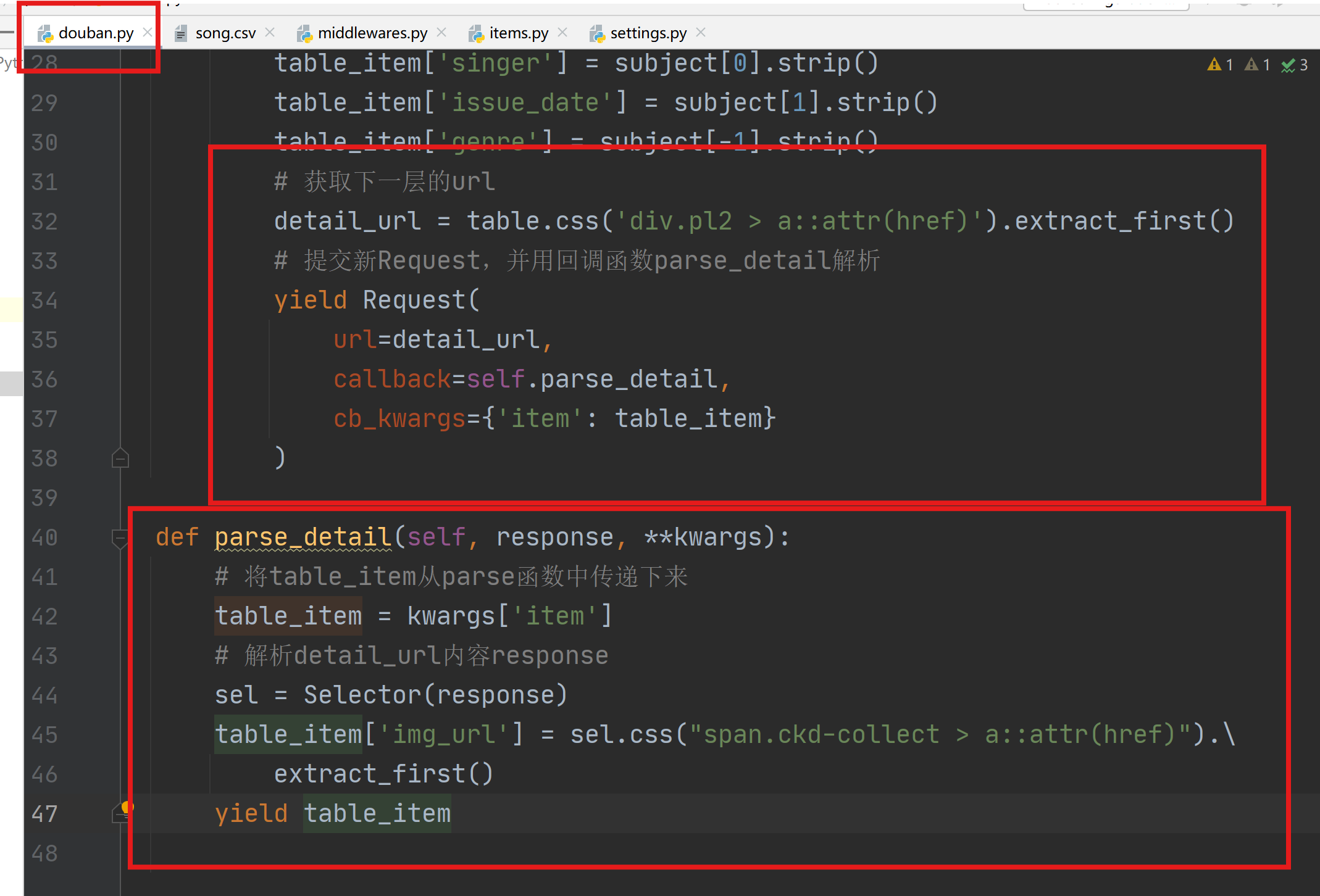
1.7 多层url解析
-
利用回调函数解析多层url:在parse函数最后解析获取新的url,并提交新的Request,并传递item到回调函数parse_detail中解析。
-
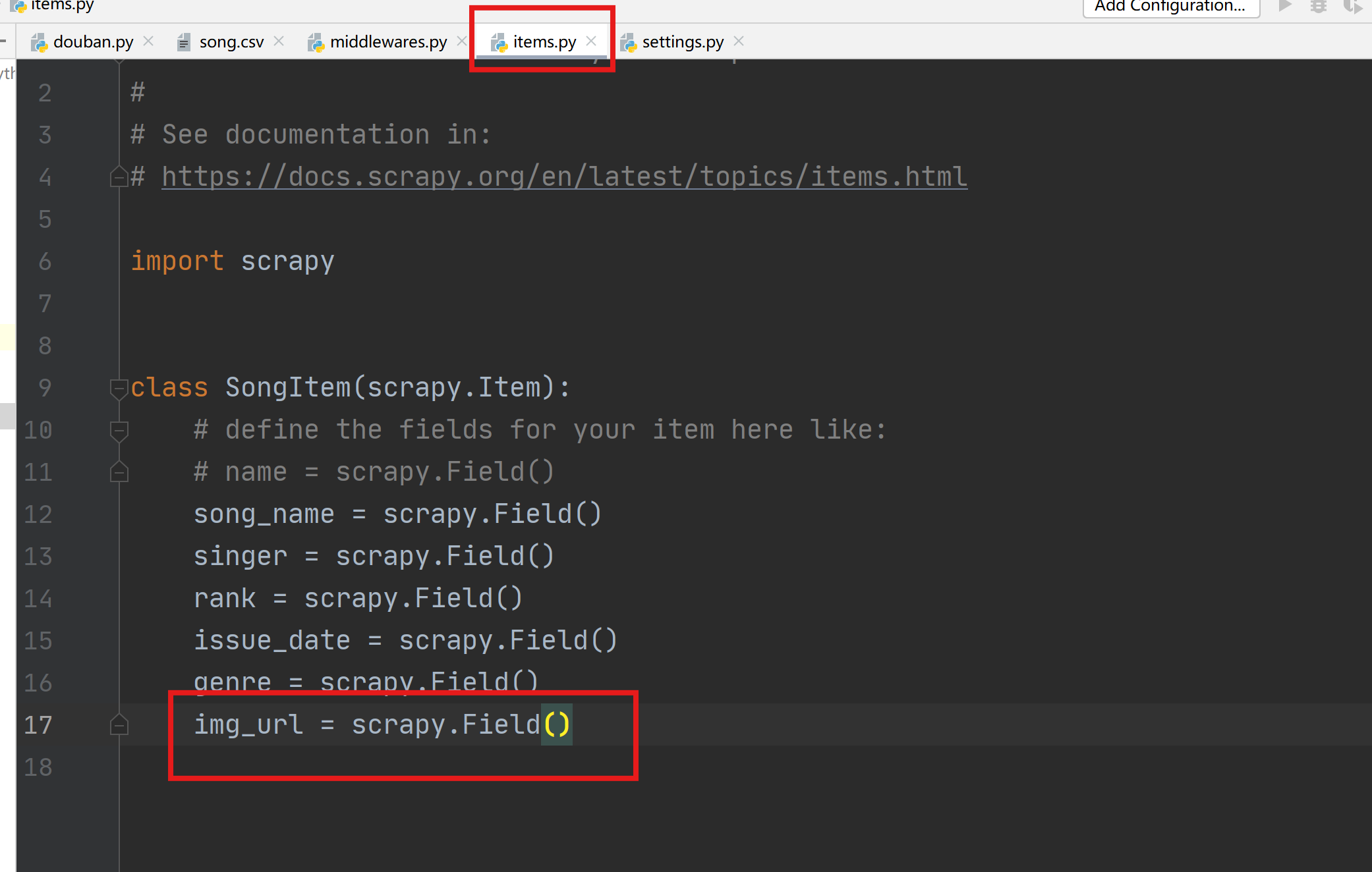
在items.py中添加新的item信息。


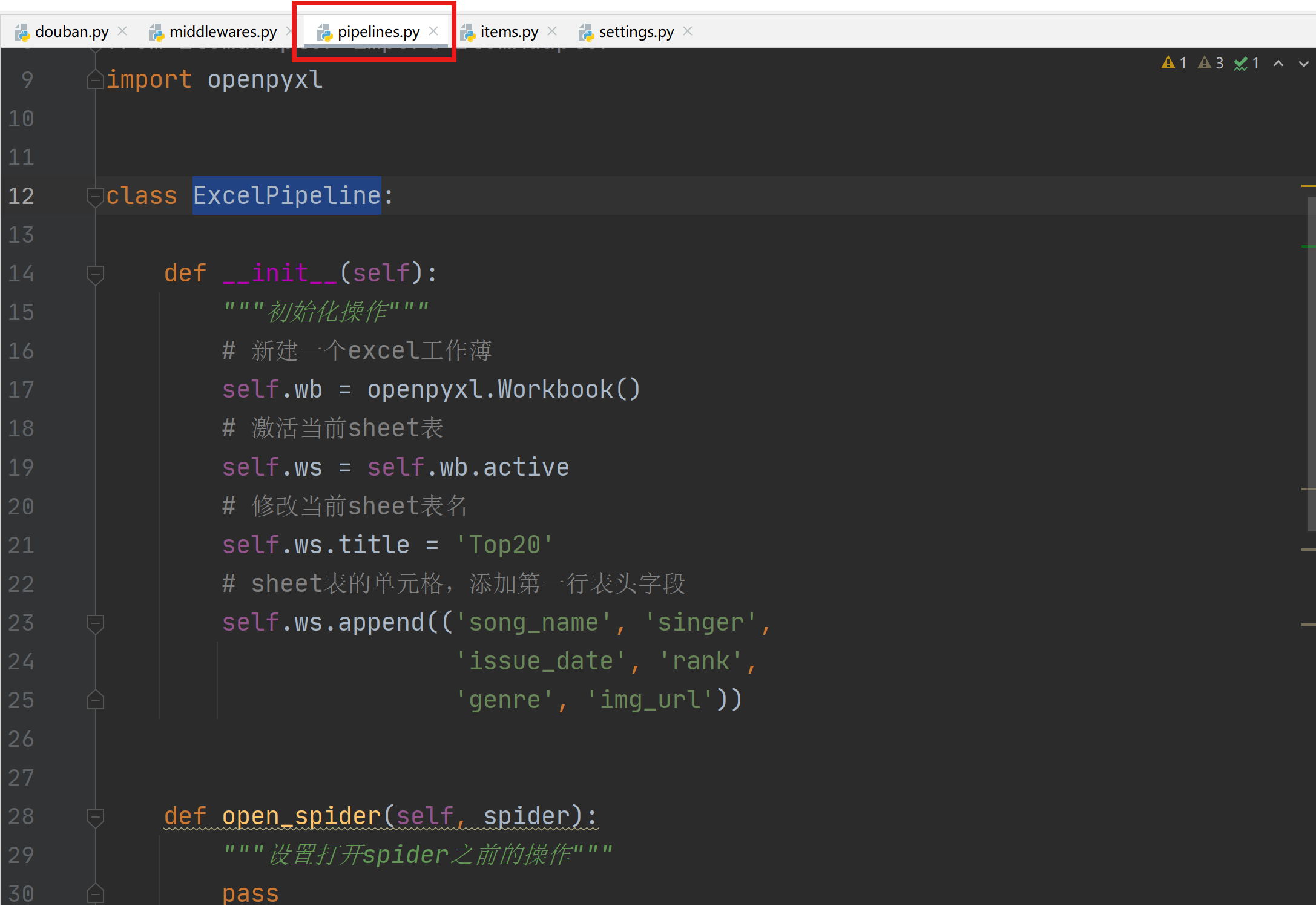
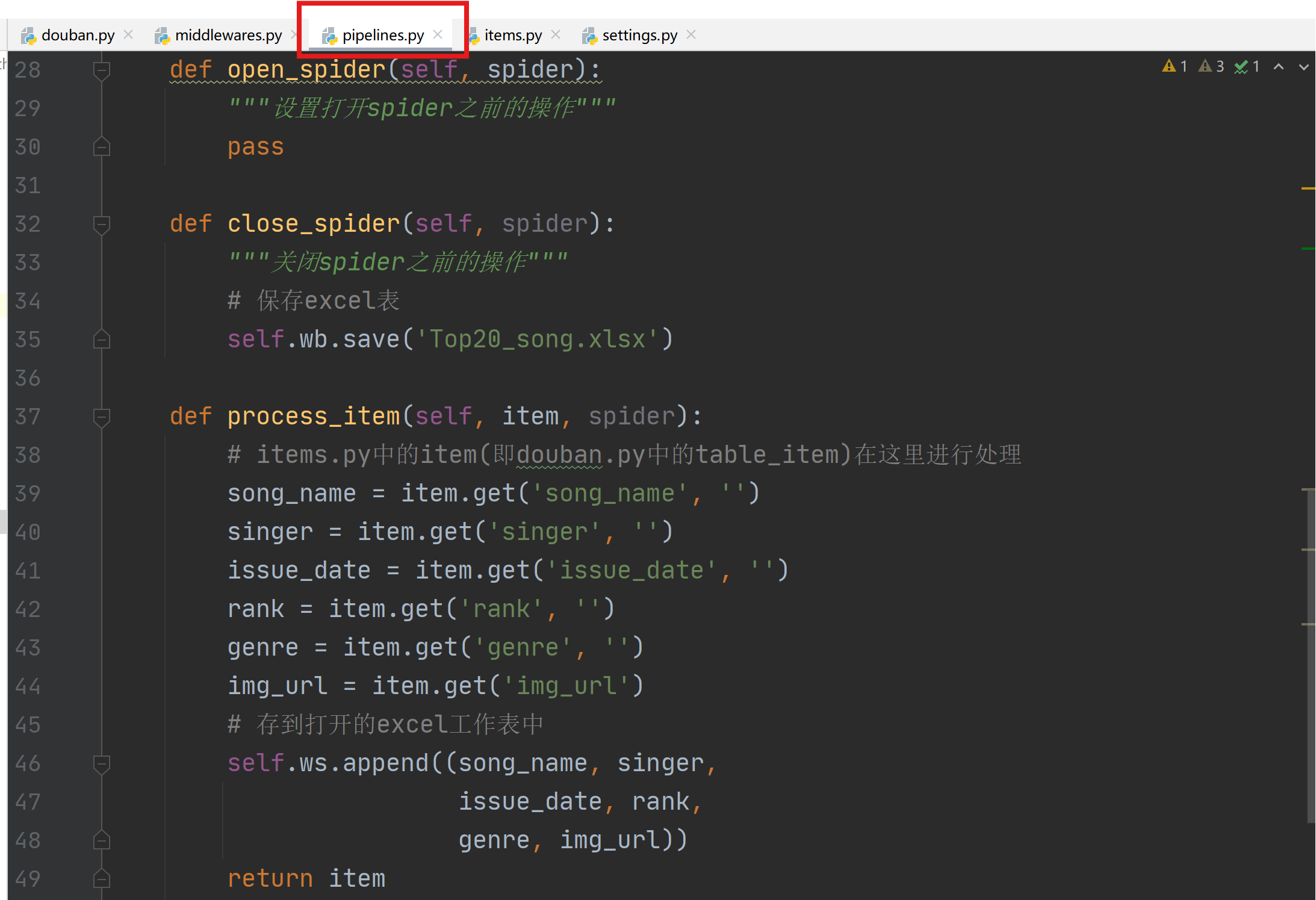
1.8 pipelines.py设置
-
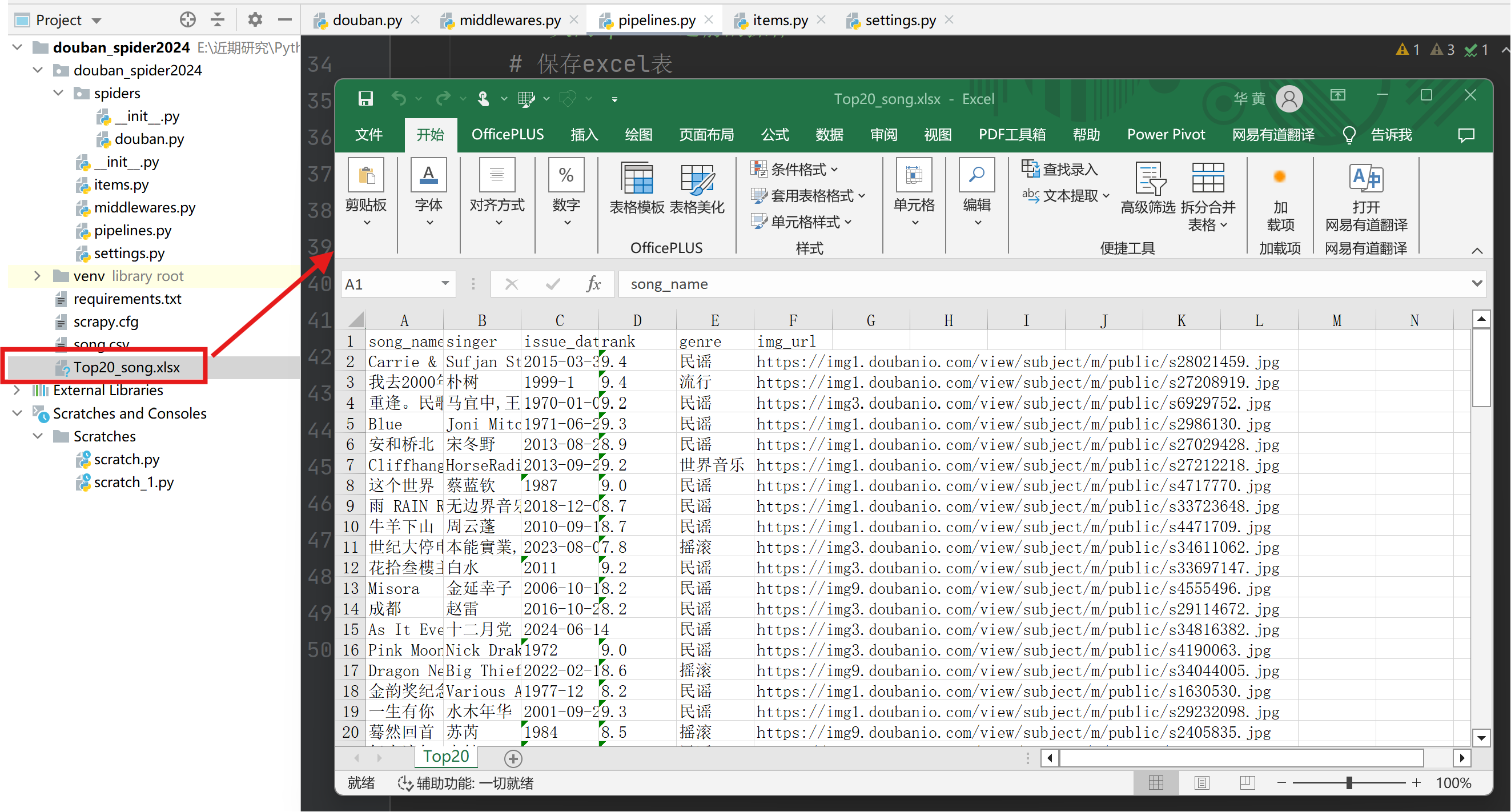
通过pipelines.py构建Excel存储管道,用于将爬取的数据存储到excel中。