一、Ceph的起源 Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合,为物理机及虚拟机提供块存储,对象存储与文件存储。由于AWS的对象存储S3与OpenStack的对象存储swift并不兼容,而Ceph的对象存储RADOS GW可以同时兼容二者,起到桥接作用。 二、Ceph的特点 1.接口类型 说Ceph是一个统一的分布式存储系统,是因为Ceph底层使用RADOS分布式存储系统,该存储系统对外提供librados接口进行调用,使用者可根据该接口自行开发客户端,考虑到易用性,Ceph官方提供了RDB,RADOS GW和CEPH FS接口,对外提供块存储,对象存储和文件存储,其中RDB和RADOS GW是给予librados的二次封装,而CEPH FS并未使用librados封装,直接使用RADOWS对象存储。  2.存储引擎 ceph后端支持多种存储引擎,以插件化的形式来进行管理使用,目前支持filestore,kvstore,memstore以及bluestore。Filestore因为仍然需要通过操作系统自带的本地文件系统间接管理磁盘,所以所有针对RADOS层的对象操作,都需要预先转换为能够被本地文件系统识别、符合POSIX语义的文件操作。这个转换的过程极其繁琐,效率低下,目前默认使用的是bluestore,即直接使用本地磁盘裸设备。 3.层级结构 对象存储本质上是一个平层结构,不像传统的文件系统倒装树接口,在对象存储下,所有对象位于同一层级,通过K/V方式进行查找,典型的应用就是我们日常见到的云盘,而云盘中不同的目录,在对象存储中是以“/”进行表示,所以对于对象存储而言,云盘中的所有对象都在一个层级目录下。 4.Ceph存储网络 Ceph存储网络分为public network和cluster network两个平面,当仅有一张网卡时,两个平面可以共用一个网络出口,生产环境中推荐两个平面分开。 ● public network:服务端响应客户端请求的流量 ● cluster network:OSD之间的心跳,object之间的复制和修复流量 5.Ceph组件 Ceph 存储集群需要至少一个 Ceph Monitor 、 Ceph Manager和 Ceph OSD ,如果需要对外提供 Ceph FS,需要额外部署 Ceph Metadata 。
2.存储引擎 ceph后端支持多种存储引擎,以插件化的形式来进行管理使用,目前支持filestore,kvstore,memstore以及bluestore。Filestore因为仍然需要通过操作系统自带的本地文件系统间接管理磁盘,所以所有针对RADOS层的对象操作,都需要预先转换为能够被本地文件系统识别、符合POSIX语义的文件操作。这个转换的过程极其繁琐,效率低下,目前默认使用的是bluestore,即直接使用本地磁盘裸设备。 3.层级结构 对象存储本质上是一个平层结构,不像传统的文件系统倒装树接口,在对象存储下,所有对象位于同一层级,通过K/V方式进行查找,典型的应用就是我们日常见到的云盘,而云盘中不同的目录,在对象存储中是以“/”进行表示,所以对于对象存储而言,云盘中的所有对象都在一个层级目录下。 4.Ceph存储网络 Ceph存储网络分为public network和cluster network两个平面,当仅有一张网卡时,两个平面可以共用一个网络出口,生产环境中推荐两个平面分开。 ● public network:服务端响应客户端请求的流量 ● cluster network:OSD之间的心跳,object之间的复制和修复流量 5.Ceph组件 Ceph 存储集群需要至少一个 Ceph Monitor 、 Ceph Manager和 Ceph OSD ,如果需要对外提供 Ceph FS,需要额外部署 Ceph Metadata 。  ● Monitors:Ceph Monitor (Ceph-mon),负责维护集群状态信息,包括monitor map、manager map、 OSD map、 MDS map和 CRUSH map。这些map是 Ceph 集群进程间彼此通信的关键信息。monitor还负责服务进程和客户端之间的身份验证。通常monitor需要至少三节点部署来保证冗余和高可用性。 ● Managers:Ceph Manager 守护进程(Ceph-mgr),负责跟踪 Ceph 集群运行时的当前指标状态,包括存储利用率、当前性能指标和系统负载,并且提供 Web 页面的 Ceph Dashboard和 REST API,供监控程序调用,通常mgr为双节点部署。 ● Ceph OSDs:Ceph OSD (对象存储守护进程,Ceph-OSD),负责存储数据,处理数据之间的复制、恢复、重新平衡,并向 Ceph Monitor 和 Manager 提供其他 OSD 的心跳,一般高可用性场景下至少需要三个 Ceph OSD。 ● MDSs:Ceph 元数据服务器(MDS,Ceph-MDS),存储 Ceph FS的元数据(块存储和对象存储不需要使用 MDS)。Ceph 元数据服务器允许 POSIX 文件系统用户执行如 ls、 find 等基本命令 ,而不会给 Ceph 存储集群带来巨大负担。 三、Ceph中的几个概念 在弄清Ceph的映射关系前,先搞清楚Ceph中的三个重要概念:object、PG、OSD。 1.Object Ceph本身是一个对象存储,为了和客户端待存储对象进行区分,下文中将待存储的对象统称为file,Ceph切分后的对象统称为object。Ceph存储时,是将一个file切分为多个object(默认4M大小),每个object经过两重映射,最终存放到RADOS对象存储上,所以无论是块存储,对象存储还是文件存储都可以看作是RADOS存储的二次封装。
● Monitors:Ceph Monitor (Ceph-mon),负责维护集群状态信息,包括monitor map、manager map、 OSD map、 MDS map和 CRUSH map。这些map是 Ceph 集群进程间彼此通信的关键信息。monitor还负责服务进程和客户端之间的身份验证。通常monitor需要至少三节点部署来保证冗余和高可用性。 ● Managers:Ceph Manager 守护进程(Ceph-mgr),负责跟踪 Ceph 集群运行时的当前指标状态,包括存储利用率、当前性能指标和系统负载,并且提供 Web 页面的 Ceph Dashboard和 REST API,供监控程序调用,通常mgr为双节点部署。 ● Ceph OSDs:Ceph OSD (对象存储守护进程,Ceph-OSD),负责存储数据,处理数据之间的复制、恢复、重新平衡,并向 Ceph Monitor 和 Manager 提供其他 OSD 的心跳,一般高可用性场景下至少需要三个 Ceph OSD。 ● MDSs:Ceph 元数据服务器(MDS,Ceph-MDS),存储 Ceph FS的元数据(块存储和对象存储不需要使用 MDS)。Ceph 元数据服务器允许 POSIX 文件系统用户执行如 ls、 find 等基本命令 ,而不会给 Ceph 存储集群带来巨大负担。 三、Ceph中的几个概念 在弄清Ceph的映射关系前,先搞清楚Ceph中的三个重要概念:object、PG、OSD。 1.Object Ceph本身是一个对象存储,为了和客户端待存储对象进行区分,下文中将待存储的对象统称为file,Ceph切分后的对象统称为object。Ceph存储时,是将一个file切分为多个object(默认4M大小),每个object经过两重映射,最终存放到RADOS对象存储上,所以无论是块存储,对象存储还是文件存储都可以看作是RADOS存储的二次封装。  2.OSD RADOS存储内,每一个最小存储单元称为一个OSD,通常每一个OSD代表一块物理磁盘,而该磁盘所在的物理节点上,每一个物理磁盘需要有一个对应的OSD进程来相应客户请求。
2.OSD RADOS存储内,每一个最小存储单元称为一个OSD,通常每一个OSD代表一块物理磁盘,而该磁盘所在的物理节点上,每一个物理磁盘需要有一个对应的OSD进程来相应客户请求。  Ceph官方给出的资源需求如下表所示(以ceph 15.2.17 octopus版为例):
Ceph官方给出的资源需求如下表所示(以ceph 15.2.17 octopus版为例):  3.PG PG全称placement group,直译为归置组,他本身是一个逻辑概念。通过前文得知,每一台物理节点上面会有若干个磁盘设备,在ceph集群中,每一个磁盘设备需要运行一个OSD进程管理,而OSD之间会相互监听心跳信息并及时上报给monitor,而monitor也会监视OSD的状态。如果让monitor监视每一个OSD,当OSD发生故障时进行数据恢复,这样物理节点资源开销很大;如果以物理节点为单位,当物理节点发生故障时再进行数据恢复,恢复的数据量又会非常大,为了兼顾性能与速度,所以在中间加入了一个逻辑归置组PG,其特点如下: ● PG是一个存储池(pool)的最小基本单元,数据在不同节点之间的同步、恢复时的数据修复也都是依赖PG完成。 ● PG位于object和RADOS的中间,往上负责接收和处理来自客户端的请求,往下负责将这些数据请求翻译为能够被本地对象存储所能理解的事务。 ● 在ceph中数据存储到集群后端可以简单的分为两步:object --> PG,PG --> OSD。 四、Ceph的存储映射 客户端将一个数据存储到Ceph集群上,会经过两次映射,object --> PG,PG --> OSD,以下分别对这两次映射进行说明。 1.object --> PG(一致性哈希算法) Ceph存储池在创建时要求指定PG数量(假设为32),客户端数据在存储时默认会以4M为单位切分成多个object,以一个object为例,该object通过一致性哈希算法对32取模,最终选取一个PG,其余object进行类似操作,所有object可能分布于不同PG,但同一object多次访问会得到相同PG,通过这种伪随机算法提升I/O性能。 2.PG --> OSD(crush算法) CRUSH算法通过计算数据存储位置来确定如何存储和检索数据。CRUSH使Ceph客户机能够直接与OSDs通信,而不是通过集中的服务器或代理。通过算法确定的数据存储和检索方法,Ceph避免了单点故障、性能瓶颈和对其可伸缩性的物理限制(后续会出一篇专门说明crush算法),此时数据存储过程如下:
3.PG PG全称placement group,直译为归置组,他本身是一个逻辑概念。通过前文得知,每一台物理节点上面会有若干个磁盘设备,在ceph集群中,每一个磁盘设备需要运行一个OSD进程管理,而OSD之间会相互监听心跳信息并及时上报给monitor,而monitor也会监视OSD的状态。如果让monitor监视每一个OSD,当OSD发生故障时进行数据恢复,这样物理节点资源开销很大;如果以物理节点为单位,当物理节点发生故障时再进行数据恢复,恢复的数据量又会非常大,为了兼顾性能与速度,所以在中间加入了一个逻辑归置组PG,其特点如下: ● PG是一个存储池(pool)的最小基本单元,数据在不同节点之间的同步、恢复时的数据修复也都是依赖PG完成。 ● PG位于object和RADOS的中间,往上负责接收和处理来自客户端的请求,往下负责将这些数据请求翻译为能够被本地对象存储所能理解的事务。 ● 在ceph中数据存储到集群后端可以简单的分为两步:object --> PG,PG --> OSD。 四、Ceph的存储映射 客户端将一个数据存储到Ceph集群上,会经过两次映射,object --> PG,PG --> OSD,以下分别对这两次映射进行说明。 1.object --> PG(一致性哈希算法) Ceph存储池在创建时要求指定PG数量(假设为32),客户端数据在存储时默认会以4M为单位切分成多个object,以一个object为例,该object通过一致性哈希算法对32取模,最终选取一个PG,其余object进行类似操作,所有object可能分布于不同PG,但同一object多次访问会得到相同PG,通过这种伪随机算法提升I/O性能。 2.PG --> OSD(crush算法) CRUSH算法通过计算数据存储位置来确定如何存储和检索数据。CRUSH使Ceph客户机能够直接与OSDs通信,而不是通过集中的服务器或代理。通过算法确定的数据存储和检索方法,Ceph避免了单点故障、性能瓶颈和对其可伸缩性的物理限制(后续会出一篇专门说明crush算法),此时数据存储过程如下:
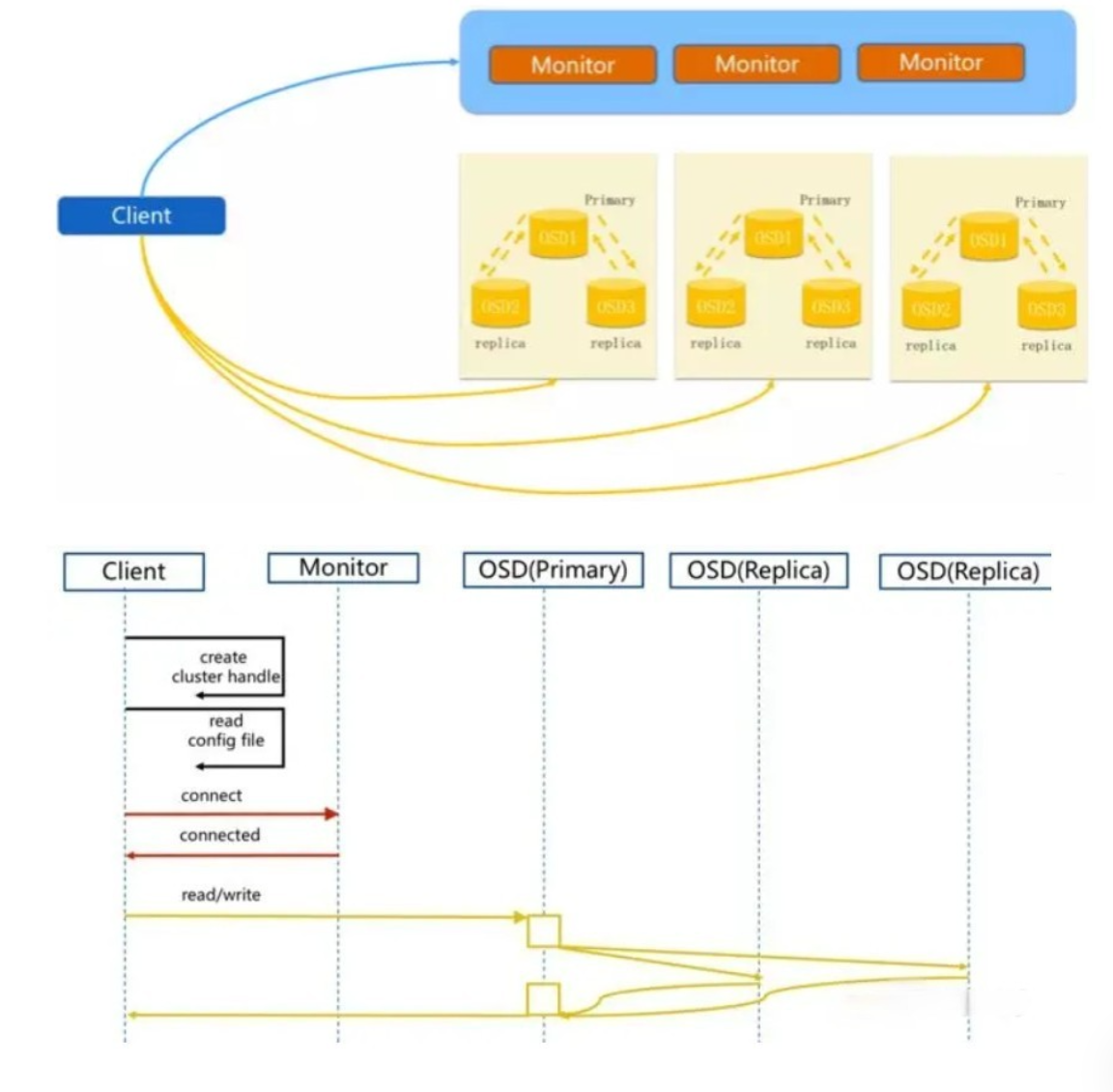
- 客户端向monitor节点发起请求,获取到集群状态信息
- 客户端经过本地计算,得到数据存放的OSD位置
- 客户端直接向primaryOSD发起读写请求
- primary OSD负责向second OSD发起数据同步
- second OSD复制完成后向primary OSD进行确认
- primary OSD向客户进行确认