
RabbitMQ集群架构模式
主备模式
实现RabbitMQ的高可用集群,一般在并发和数据量不高的情况下,这种模式非常的好且简单。主备模式也称为Warren模式
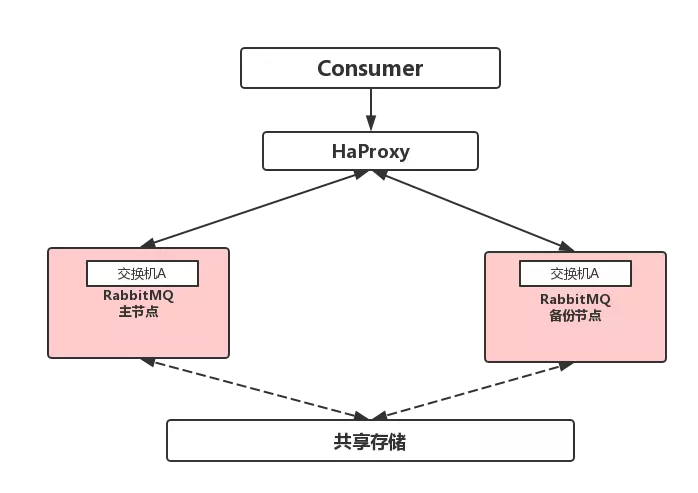
主备模式:主节点提供读写,从节点不提供读写服务,只是负责提供备份服务,备份节点的主要功能是在主节点宕机时,完成自动切换 从-->主,从而继续提供服务主从模式:主节点提供读写,从节点只读
-
主备模式:所谓rabbitmq另外一种模式就是warren(兔子窝),就是一个主/备方案(主节点如果挂了,从节点提供服务而已,和activemq利用zookeeper做主/备一样)
-
HaProxy配置:

listen rabbitmq_cluster
bind 0.0.0.0:5672
mode tcp #配置TCP模式
balance roundrobin #简单的轮询
server bhz76 192.168.11.12:5672 check inter 5000 rise 2 fall 3 #主节点
server bhz77 192.168.11.13:5672 backup check inter 5000 rise 2 fall 3 #备用节点
备注:rabbitmq集群节点配置 #inter 每隔5秒对mq集群做健康检查,2次正确证明服务器可用,3次失败证明服务器不可用,并且配置主备机制
远程模式
远程模式:远距离通信和复制, 远程模式可以实现双活的一种模式,简称 shovel 模式,所谓Shovel就是我们可以把消息进行不同数据中心的复制工作,我们可以跨地域的让两个mq集群互联,远距离通信和复制。我们下面看一下Shovel架构模型:  如图所示,有两个异地的 MQ 集群(可以是更多的集群),当用户在地区 1 这里下单了,系统发消息到 1 区的 MQ 服务器,发现 MQ 服务已超过设定的阈值,负载过高,这条消息就会被转到 地区 2 的 MQ 服务器上,由 2 区的去执行后面的业务逻辑,相当于分摊我们的服务压力。 在使用了 shovel 插件后,模型变成了近端同步确认,远端异步确认的方式,大大提高了订单确认速度,并且还能保证可靠性。 远程模式Shovel集群的拓扑图:
如图所示,有两个异地的 MQ 集群(可以是更多的集群),当用户在地区 1 这里下单了,系统发消息到 1 区的 MQ 服务器,发现 MQ 服务已超过设定的阈值,负载过高,这条消息就会被转到 地区 2 的 MQ 服务器上,由 2 区的去执行后面的业务逻辑,相当于分摊我们的服务压力。 在使用了 shovel 插件后,模型变成了近端同步确认,远端异步确认的方式,大大提高了订单确认速度,并且还能保证可靠性。 远程模式Shovel集群的拓扑图:  如上图所示,当我们的消息到达 exchange,它会判断当前的负载情况以及设定的阈值,如果负载不高就把消息放到我们正常的 warehouse_goleta 队列中,如果负载过高了,就会放到 backup_orders 队列中。backup_orders 队列通过 shovel 插件与另外的 MQ 集群进行同步数据,把消息发到第二个 MQ 集群上。
如上图所示,当我们的消息到达 exchange,它会判断当前的负载情况以及设定的阈值,如果负载不高就把消息放到我们正常的 warehouse_goleta 队列中,如果负载过高了,就会放到 backup_orders 队列中。backup_orders 队列通过 shovel 插件与另外的 MQ 集群进行同步数据,把消息发到第二个 MQ 集群上。
shovel 集群的配置,首先启动 rabbitmq 插件,命令如下:
rabbitmq-plugins enable amqp_client
rabbitmq-plugins enable rabbitmq_shovel
- 创建rabbitmq.conf文件:touch /etc/rabbitmq/rabbitmq.config
- 添加配置见rabbitmq.config
- 最后我们需要资源服务器和目的服务器都使用相同的配置文件(rabbitmq.config)
具体配置 自行百度
镜像模式(常用)
-
镜像模式:集群模式非常经典的就是Mirror镜像模式,保证100%数据不丢失,在实际工作中用的最多的。并且实现集群非常的简单,一般互联网大厂都会构建这种镜像集群模式。
-
Mirror镜像队列,目的是为了保证rabbitmq数据的高可靠性解决方案,主要就是实现数据的同步,一般来讲是2-3个实现数据同步(对于100%数据可靠性解决方案一般是3个节点)集群架构如下:
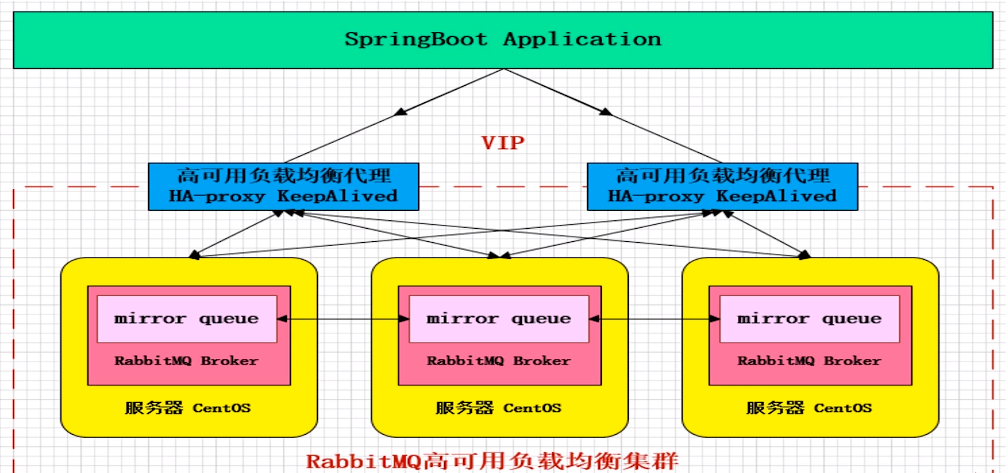 如上图所示,用 KeepAlived 做了 HA-Proxy 的高可用,然后有 3 个节点的 MQ 服务,消息发送到主节点上,主节点通过 mirror 队列把数据同步到其他的 MQ 节点,这样来实现其高可靠。
如上图所示,用 KeepAlived 做了 HA-Proxy 的高可用,然后有 3 个节点的 MQ 服务,消息发送到主节点上,主节点通过 mirror 队列把数据同步到其他的 MQ 节点,这样来实现其高可靠。
 如上图所示,用 KeepAlived 做了 HA-Proxy 的高可用,然后有 3 个节点的 MQ 服务,消息发送到主节点上,主节点通过 mirror 队列把数据同步到其他的 MQ 节点,这样来实现其高可靠。
如上图所示,用 KeepAlived 做了 HA-Proxy 的高可用,然后有 3 个节点的 MQ 服务,消息发送到主节点上,主节点通过 mirror 队列把数据同步到其他的 MQ 节点,这样来实现其高可靠。多活模式
-
多活模式:这种模式也是实现异地数据复制的主流模式,因为Shovel模式配置比较复杂,所以一般来说实现异地集群都是使用双活或者多活模式来实现的。这种模式需要依赖rabbitmq的federation插件,可以实现继续的可靠AMQP数据通信,多活模式在实际配置与应用非常的简单。
-
RabbitMQ部署架构采用双中心模式(多中心),那么在两套(或多套)数据中心中各部署一套RabbitMQ集群,各中心之间还需要实现部分队列消息共享。多活集群架构如下:
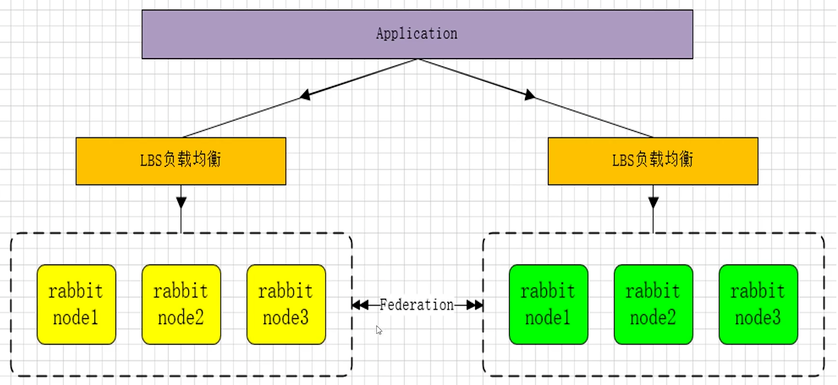

Federation插件是一个不需要构建Cluster,而在Brokers之间传输消息的高性能插件,Federation插件可以在Brokers或者Cluster之间传输消息,连接双方可以使用不同的users和vistual hosts,双方也可以使用版本不同的RabbitMQ和Erlang。Federation插件使用AMQP协议通信,可以接收不连续的传输。 
如上图所示,Federation Exchanges,可以看成Downstream从Upstream主动拉取消息,但并不是拉取所有消息,必须是在Downstream上已经明确定义Bindings关系的Exchange,也就是有实际的物理Queue来接收消息,才会从Upstream拉取消息到Downstream。使用AMQP协议实施代理间通信,Downstream会将绑定关系组合在一起,绑定/解绑命令将会发送到Upstream交换机。因此,FederationExchange只接收具有订阅的消息。
构建高可靠的RabbitMQ集群
可以根据这个架构图,做一些RabbitMQ集群完善,主要是将内存节点作为负载,磁盘节点作为存储。 
RabbitMQ集群环境节点说明: 
搭建RabbitMQ Server高可用集群: 搭建 RabbitMQ Server 高可用集群 RabbitMQ集群搭建和使用 https://www.cnblogs.com/xiaoxing/p/9258345.html
HAProxy HAProxy是一款提供高可用性、负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件,支持虚拟主机,他是免费、快速并且可靠的一种解决方案。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在时下的硬件上,完全可以支撑数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中,同时可以保护你的web服务器不被暴露到网络上。 HAProxy借助于OS上几种常见的技术来实现性能的最大化:
- 1、单进程、时间驱动模型显著降低上下文切换的开销及内存占用
- 2、在任何可用的情况下,单缓冲(single buffering)机制能以不复制任何数据的方式完成读写操作,这会节约大量的CPU时钟周期及内存带宽
- 3、借助于Linux2.6上的splice()系统调用,HAProxy可以实现零复制转发(Zero-copy- forwarding),在linux3.5及以上的OS上还可以实现零复制启动(zero-starting)
- 4、内存分配器在固定大小的内存池中可实现即时内存分配,这能够显著减少创建一个会话的时长
- 5、树型存储:侧重于使用其作者多年前开发的弹性二叉树,实现了以O(log(N))的低开销来保持计时器命令、保持运行队列命令、管理轮询及最少连接队列。
KeepAlived
KeepAlived软件主要是通过VRRP协议实现高可用功能的。VRRP是Virtual Router RedundancyProtocol(虚拟路由器冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由单点故障问题的,它能保证党个别节点宕机时,整个网络可以不间断地运行,所以,KeepAlived一方面具有配置管理LVS的功能,同时还具备对LVS下面节点进行健康检查差的功能,另一方面可实现系统网络服务的高可用功能。
KeepAlived服务的三个重要功能:
- 管理LVS负载均衡软件
- 实现LVS集群节点的健康检查
- 作为系统网络服务的高可用性(failover)
KeepAlived高可用原理 KeepAlived高可用服务对之间的故障转移,是通过VRRP(Virtual Router Redundancy Protocol,虚拟路由器冗余协议)来实现的。在KeepAlived服务正常工作是,主Master节点会不断地向备节点发送(多播的方式)心跳消息,用以告诉备Backup节点自己还活着,当主master节点发生故障时,就无法发送心跳消息,备节点也就因此无法继续监测到来自主Master节点的心跳了,于是调用自身的接管程序,接管主Master节点 的IP资源及服务。当主Master节点恢复时,备Backup节点又会释放主节点故障时自身接管的IP资源和服务,恢复到原来的备用角色。
Haproxy+Keepalived高可用环境部署梳理: https://www.cnblogs.com/mrlapulga/p/6871936.html https://www.cnblogs.com/zhangan/p/10930570.html https://www.cnblogs.com/kevingrace/p/5892169.html
RabbitMQ集群配置文件详解
- tcp_listeners 设置rabbitmq的监听端口,默认为5672
- disk_free_limit 磁盘低水位线,若磁盘容量低于指定值则停止接收数据,默认值为{mem_relative, 1.0}, 即与内存相关联1:1,也可定制为多少byte.
- vm_memeory_high_watemark, 设置内存低水位线,若低于该水位线,则开启流控机制,默认值为0.4,即内存总量的40%
- hipe_compile将部分rabbitmq代码用High Performance Erlang compiler编译,可提升性能,该参数是实验性,若出现erlang vm segfaults,应关掉
- force_fine_statistics,该参数属于rabbitmq_mamagement,若为true这进行精细化统计,但会影响性能
- 集群节点模式:Disk为磁盘模式存储 / Ram为内存模式存储
RabbitMQ集群恢复与故障转移
RabbitMQ 镜像队列集群的几种故障场景 以及对应的恢复方案: 前提: 节点 A 和节点 B 组成一个镜像队列
- 场景1:A 先停了,B 后停
解决方案:该场景下 B 是 master,主要先启动 B,再启动 A 即可。或者 先启动 A,在 30 秒内启动 B 即可恢复镜像队列
- 场景2:A、B 同时停机
解决方案:该场景可能是由于机房掉电等原因造成的,只需要在 30 秒之内连续启动 A 和 B 即可恢复镜像队列
- 场景 3 : A先停,B 后停,且 A 无法恢复
解决方案: 该场景是 场景 1 的加强版,因为 B 是 master, 所以等 B 起来以后,在 B 节点上调用控制台命令: rabbitmqctl forget_cluster_node A 解除与 A 的 cluster 关系,再将新的 slave 节点加入 B 即可重新恢复镜像队列
- 场景 4: A 先停,B 后停,且 B 无法恢复
方案:该场景是场景 3 的升级版,比较难处理,原因是 因为 master 节点无法恢复。在 3.1.X 时代之前没有什么好的解决方案,但是在 3.4.2 以后的版本可以试试 - -offline 这个参数。 因为 B 是 主节点,所以直接启动 A 是不行的,当 A 无法启动的时候,也就没有办法在 A 节点上调用之前的 rabbitmq forget_cluster_node B 命令了。新版本中, forget_cluster_node 支持 -offline 参数。这就意味着允许 rabbitmqctl 在理想节点上执行该命令,迫使 rabbitMQ 会 mock 一个 一个节点代表 A,执行 forget_cluster_node 命令将 B 剔除 cluster,然后 A 就可以正常启动了,最后将新的 slave 节点加入 A 即可重新恢复镜像队列
- 场景 5 : A 先停,B 后停,且 A、B 均无法恢复,但是能得到 A 或 B 的磁盘文件
方案:只能通过恢复数据的方式进行尝试恢复,将 A 或 B 的数据库文件 默认在 $RABBIT_HOME/var/lib/ 目录下,把它 拷贝到新节点的对应目录下,再将新节点的 hostname 改成 A 或者 B 的 hostname。如果是 A 节点(slave)的磁盘文件,则按照场景 4 处理即可;如果是 B 节点(master)的磁盘文件,则按照场景 3 处理,最后将新的 slave 加入到新节点后完成恢复。
- 场景 6: A 先停、B 后停,且 A 、B 均无法恢复,且得不到 A 或 B 的磁盘文件
方案:可以洗洗睡了~没有方案,解决不了!
高级插件的使用
延迟插件(即延迟队列)的作用:
比如消息的延迟推送、定时任务(消息)的执行。包括一些消息重试策略的配合使用,以及用于业务削峰限流、降级的异步延迟消息机制,都是延迟队列的实际应用场景。
延迟插件的安装:
- 1、下载插件(两种方式):
A、下载zip包,下载地址:http://www.rabbitmq.com/community-plugins.html
/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.5/plugins B、在指定目录下载该插件:/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.5/plugins 目录下执行wget https://dl.bintray.com/rabbitmq/community-plugins/3.6.x/rabbitmq_delayed_message_exchange/rabbitmq_delayed_message_exchange-20171215-3.6.x.zip
 /usr/lib/rabbitmq/lib/rabbitmq_server-3.6.5/plugins B、在指定目录下载该插件:/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.5/plugins 目录下执行wget https://dl.bintray.com/rabbitmq/community-plugins/3.6.x/rabbitmq_delayed_message_exchange/rabbitmq_delayed_message_exchange-20171215-3.6.x.zip
/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.5/plugins B、在指定目录下载该插件:/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.5/plugins 目录下执行wget https://dl.bintray.com/rabbitmq/community-plugins/3.6.x/rabbitmq_delayed_message_exchange/rabbitmq_delayed_message_exchange-20171215-3.6.x.zip- 2、将插件/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.5/plugins 目录下
解压插件:unzip rabbitmq_delayed_message_exchange-20171215-3.6.x.zip
- 3、启动延时插件:rabbitmq-plugins enable rabbitmq_delayed_message_exchange
- 4、访问地址: http://{ip}:15672/#/exchanges
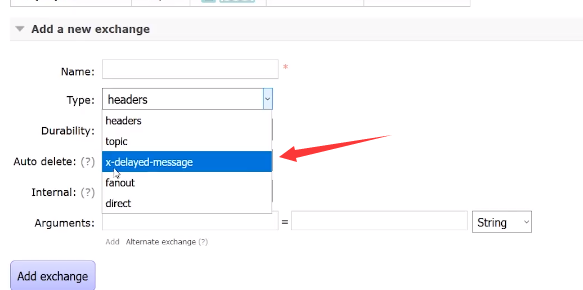

Rabbitmq的延迟消息队列实现: rabbitmq的延迟消息队列实现
RabbitMQ 延迟队列插件应用 以及 java 代码使用延迟消息
参考: https://www.jianshu.com/p/588e1c959f03 https://www.jianshu.com/p/b7cc32b94d2a https://www.jianshu.com/p/8fe6947efa53