
Search的运行机制
Search执行的时候分为两个运行步骤:
- Query阶段
- Fetch阶段
Query阶段

Fetch阶段

相关性算分问题
相关性算分在shard与shard之间是相互独立的,也就意味着同一个Term的IDF等值在不同shard上是不同的,文档的相关性算分和它所处的shard相关,在文档数量不多时,会导致相关性算分严重不准的情况发生。
解决思路有两个:
- 1、设置分片数为1个,从根本上排除问题,在文档数量不多的时候可以考虑该方案,比如百万到千万级别的数量。
- 2、使用DFS Query-Then-Fetch查询方式

排序
es默认会采用相关性算分排序,用户可以通过设定sorting参数来自行设定排序规则


-
按照字符串排序比较特殊,因为es有text和keyword两种类型,针对text类型排序,如下所示:

-
针对keyword类型,可以返回预期结果

-
排序的过程实质是对字段原始内容排序的过程,这个过程中,倒排索引无法发挥作用,需要用到正排索引,也就是通过文档id和字段去快速的得到字段原始内容。
-
es对此提供了两种实现方式:
- fielddata:默认禁用。
- doc values:默认启用,除了text类型。


Fielddata VS DocValues
| 对比 | Fielddata | DocValues |
|---|---|---|
| 创建时机 | 搜索时即时创建 | 索引时创建,与倒排索引<br>创建时机一致 |
| 创建位置 | JVM Heap | 磁盘 |
| 优点 | 不会占用额外的磁盘资源 | 不会占用Heap内存 |
| 缺点 | 文档过多时,即时创建会花费过多时间,<br>占用过多的Heap内存 | 减慢索引的速度,占用<br>额外的磁盘空间 |
Fielddata
Fielddata默认是关闭的,可以通过如下api开启:
- 此时字符串是按照分词后的term排序,往往结果很难符合预期。
- 一般是在对分词做聚合分析的时候开启。


DocValues
DocValues默认是启用的,可以在创建索引的时候关闭,如果后面要开启DocValues,需要做reindex操作。 
DocValue_fields
可以通过该字段获取fielddata获取DocValues中储存的内容。 
搜索语法入门
query string search
无条件搜索所有
GET /book/_search
{
"took" : 969,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "Bootstrap开发",
"description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel" : "201002",
"price" : 38.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"bootstrap",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
},
{
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
}
}
]
}
}
解释:
- took:耗费了几毫秒。
- timed_out:是否超时,这里是没有。
- _shards:到几个分片搜索,成功几个,跳过几个,失败几个。
- hits.total:查询结果的数量,3个document。
- hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高。
- hits.hits:包含了匹配搜索的document的所有详细数据。
传参
与http请求传参类似
GET /book/_search?q=name:java&sort=price:desc
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
},
"sort" : [
68.6
]
}
]
}
}
timeout机制
GET /index/_search?timeout=10ms
默认情况下,es的timeout机制是关闭的。比如,如果你的搜索特别慢,每个shard都要花好几分钟才能查询出来所有的数据,那么你的搜索请求也会等待好几分钟才会返回。
我们有些应用系统对时间是非常敏感的,比如说电商网站,你不能让用户等10分钟,才能等到一次搜索请求的结果。
timeout机制:指定每个shard只能在timeout时间范围内,将搜索到的部分数据(也可能是全部数据),直接返回给客户端,而不是等到所有的数据全部搜索出来以后再返回。确保一次搜索请求可以在用户指定的timeout时长内完成,为一些时间敏感的搜索应用提供良好的支持。
全局设置:配置文件中设置search.default_search_timeout:100ms。该设置不常用。
multi-index 多索引搜索
multi-index搜索模式
如何一次性搜索多个index和多个type下的数据
/_search:所有索引下的所有数据都搜索出来
/index1/_search:指定一个index,搜索其下所有的数据
/index1,index2/_search:同时搜索两个index下的数据
/index*/_search:按照通配符去匹配多个索引
应用场景:生产环境log索引可以按照日期分开。
log_to_es_20201110
log_to_es_20201111
log_to_es_20201112
分页与遍历
es提供了3种方式来解决分页与遍历的问题:
- from/size
- scroll
- search_after
from/size
最常用的分页方案:
- from:定义了目标数据的偏移值,默认是 0。
- size:定义当前返回的数目,默认是 10。
GET /index/_search?size=10
GET /index/_search?size=10&from=0
如果每页展示 5 条结果,可以用下面方式请求得到 1 到 3 页的结果:
GET /book/_search?size=5
GET /book/_search?size=5&from=5
GET /book/_search?size=5&from=10
深度分页是一个经典问题:在数据分片存储的情况下,如何获取前1000条数据?
- 获取990-1000的文档,会在每个分片上都先取1000个文档,然后在由Coordinating Node聚合所有分片的结果后,再排序选取前1000个文档。
- 页数越深,处理文档越多,占用内存就越多,耗时也越长。尽量避免深度分页。

除了会遇到效率上的问题,还有一个无法解决的问题是es目前支持最大的skip值是max_result_window默认为10000,也就是说当from+size > max_result_window时,es将返回错误。
解决方案: 问题描述:比如当客户线上的es数据出现问题,当分页到几百页的时候,es无法返回数据,此时为了恢复正常使用,我们可以采用紧急规避的方式,就是将max_result_window的值调至50000。
curl -XPUT "127.0.0.1:9200/custm/_settings" -d
'{
"index" : {
"max_result_window" : 50000
}
}'
对于上面这种解决方案只是暂时解决问题,当es的使用越来越多时,数据量越来越大,深度分页的场景越来越复杂时,可以使用另一种分页方式scroll。
deep paging
什么是deep paging
- 根据相关度评分倒排序,所以分页过深,协调节点会将大量数据聚合分析。
deep paging问题
-
1、消耗网络带宽,因为所搜过深的话,各 shard 要把数据传递给 coordinate node,这个过程是有大量数据传递的,消耗网络。
-
2、消耗内存,各 shard 要把数据传送给 coordinate node,这个传递回来的数据,是被 coordinate node 保存在内存中的,这样会大量消耗内存。
-
3、消耗cup,coordinate node 要把传回来的数据进行排序,这个排序过程很消耗cpu。 所以:鉴于deep paging的性能问题,所有应尽量减少使用。
scroll
遍历文档集的api,以快照的方式来避免深度分页的问题。
-
不能用来做实时搜索,因为数据不是实时的。
-
尽量不要使用复杂的sort条件,使用_doc最高效
-
使用稍嫌复杂
-
1、需要发起1个scroll search,如下所示:
- es在收到该请求后,会根据查询条件创建文档id集合的快照
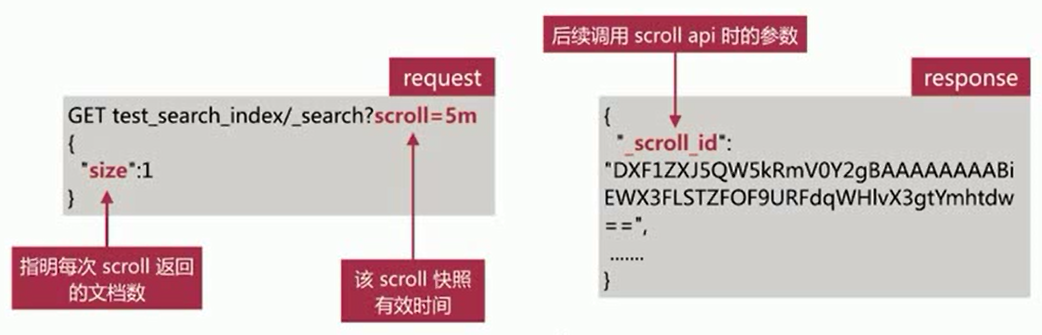
- es在收到该请求后,会根据查询条件创建文档id集合的快照
-
2、调用scroll search的api,获取文档集合,如下所示:
- 不断迭代调用直到返回hits.hits数组为空时停止
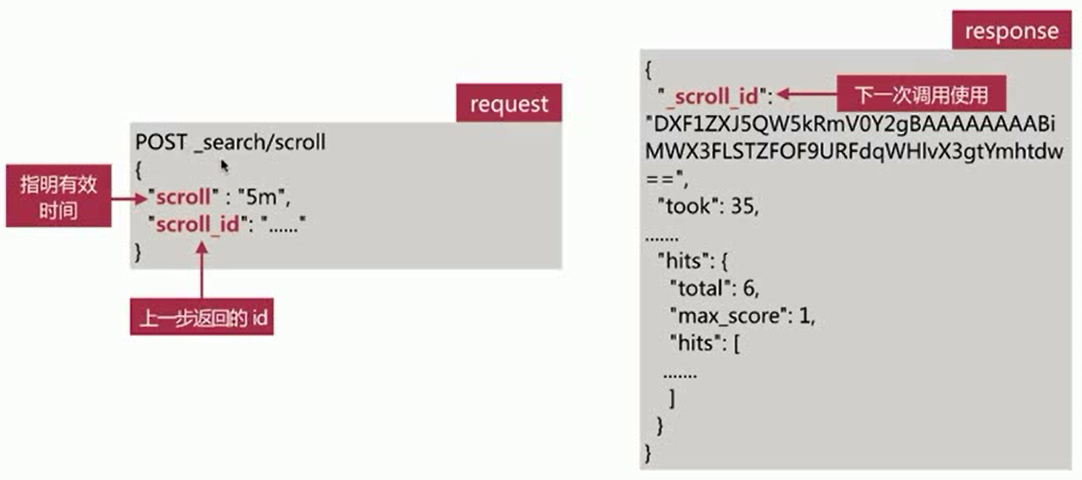
- 不断迭代调用直到返回hits.hits数组为空时停止
-
过多的scroll调用会占用大量内存,可以通过clear api删除过多的scroll快照
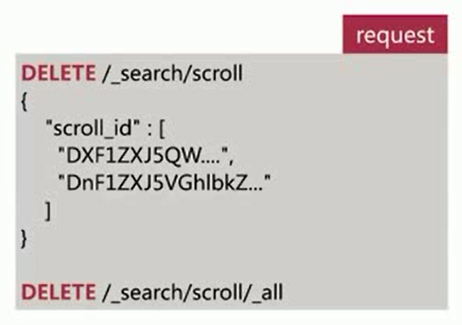



search_after
-
避免深度分页的性能问题,提供实时的下一页文档获取功能。
- 缺点是不能使用from参数,即不能指定页数。
- 只能下一页,不能上一页。
- 使用简单。
-
1、第一步为正常的搜索,但要指定sort值,并保证值唯一。
-
2、第二步为使用上一步最后一个文档中的sort值进行查询。

-
如何避免深度分页问题?
- 通过唯一排序值定位将每次要处理的文档数都控制在size内。


应用场景:
| 类型 | 场景 |
|---|---|
| From/Size | 需要实时获取顶部的部分文档,且需要自由翻页 |
| Scroll | 需要全部文档,如导出所有数据的功能 |
| Search_after | 需要全部文档,不需要自由翻页 |
query string基础语法
GET /book/_search?q=name:java
GET /book/_search?q=+name:java
GET /book/_search?q=-name:java
- +和-的含义:
+表示必须包含-表示 不包含
_all metadata的原理和作用
GET /book/_search?q=java
直接可以搜索所有的field,任意一个field包含指定的关键字就可以搜索出来。我们在进行中搜索的时候,难道是对document中的每一个field都进行一次搜索吗?不是的。
es中all元数据。建立索引的时候,插入一条document,es会将所有的field值经行全量分词,把这些分词,放到all field中。在搜索的时候,没有指定field,就在_all搜索。
举例
{
name:jack
email:123@qq.com
address:beijing
}
_all : jack,123@qq.com,beijing
参考: https://blog.csdn.net/fy_java1995/article/details/106674455