
Nacos
Nacos体系架构
领域模型
Nacos 领域模型描述了服务与实例之间的边界和层级关系。Nacos 的服务领域模型是以“服 务”为维度构建起来的,这个服务并不是指集群中的单个服务器,而是指微服务的服务名。
“服务”是 Nacos 中位于最上层的概念,在服务之下,还有集群和实例的概念。
-
服务
在服务这个层级上可以配置元数据和服务保护阈值等信息。服务阈值是一个 0~1 之间的 数字,当服务的健康实例数与总实例的比例小于这个阈值的时候,说明能提供服务的机器已经 没多少了。这时候 Nacos 会开启服务保护模式,不再主动剔除服务实例,同时还会将不健康 的实例也返回给消费者。
-
集群
一个服务由很多服务实例组成,在每个服务实例启动的时候,可以设置它所属的集群,在 集群这个层级上,也可以配置元数据。除此之外,还可以为持久化节点设置健康检查 模式。
所谓持久化节点,是一种会保存到 Nacos 服务端的实例,即便该实例的客户端进程没有在运 行,实例也不会被服务端删除,只不过 Nacos 会将这个持久化节点状态标记为不健康, Nacos 可以采用一种“主动探活”的方式来对持久化节点做健康检查。
除了持久化节点以外,大部分服务节点在 Nacos 中以“临时节点”的方式存在,它是默认的 服务注册方式,从名字中就可以看出,这种节点不会被持久化保存在 Nacos 服务器,临 时节点通过主动发送 heartbeat 请求向服务器报送自己的状态。
-
实例
这里所说的实例就是指服务节点,可以在 Nacos 控制台查看每个实例的 IP 地址和端口、 编辑实例的元数据信息、修改它的上线 / 下线状态或者配置路由权重等等。
在这三个层级上都有“元数据”这一数据结构,可以把它理解为一组包含了服务 描述信息(如服务版本等)和自定义标签的数据集合。Client 端通过服务发现技术可以获取到 每个服务实例的元数据,可以将自定义的属性加入到元数据并在 Client 端实现某些定制化 的业务场景。
数据模型
Nacos 的数据模型有三个层次结构,分别是 Namespace、Group 和 Service/DataId。

- Namespace:即命名空间,它是最顶层的数据结构,可以用它来区分开发环境、生产 环境等不同环境。默认情况下,所有服务都部署到一个叫做“public”的公共命名空间;
- Group:在命名空间之下有一个分组结构,默认情况下所有微服务都属于 “DEFAULT_GROUP”这个分组,不同分组间的微服务是相互隔离的;
- Service/DataID:在 Group 分组之下,就是具体的微服务了,比如订单服务、商品服务等等。
通过 Namespace + Group + Service/DataID,就可以精准定位到一个具体的微服务
Nacos 基本架构
Nacos 的核心功能有两个,一个是 Naming Service,用来做服务发现的模块;另 一个是 Config Service,用来提供配置项管理、动态更新配置和元数据的功能
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OFQ0pyt6-1677596762818)(C:\Users\0\AppData\Roaming\Typora\typora-user-images\image-20230226225644390.png)]](http://dev-img.mos.moduyun.com/20231009/702e8593-3995-45ab-b9fd-5891038a1f78.png)
Provider APP 和 Consumer APP 通过 Open API 和 Nacos 服务 器的核心模块进行通信。这里的 Open API 是一组对外暴露的 RESTful 风格的 HTTP 接口。
在 Nacos 和核心模块里,Naming Service 提供了将对象和实体的“名字”映射到元数据的 功能,这是服务发现的基础功能之一。
Nacos 还有一个相当重要的模块:Nacos Core 模块。它可以提供一系列的平台基础功能, 是支撑 Nacos 上层业务场景的基石
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-49FknCy3-1677596762818)(E:\BaiduNetdiskDownload\180SpringCloud微服务项目实战\images\472384\d0c78d0c0f2bb72c45788a5c2d423512.jpg)]](http://dev-img.mos.moduyun.com/20231009/e873da54-76cc-42d1-9893-e3af21a8d7be.png)
Nacos集群环境搭建
Nacos Server 的安装包可以从 Alibaba 官方 GitHub 中的Release 页面下载。
下载完成后,可以在本地将 Nacos Server 压缩包解压,并将解压后的目录名改为“nacos-cluster1”,再复制一份同样的文件到 nacos-cluster2,以此来模拟一个由两台 Nacos Server 组成的集群。
修改启动项参数
Nacos Server 的启动项位于 conf 目录下的 application.properties 文件里,需要修改服务启动端口和数据库连接
Nacos Server 的启动端口由 server.port 属性指定,默认端口是 8848。在 nacos-cluster1 中仍然使用 8848 作为默认端口,需要把 nacos-cluster2 中的端口号改为 8948
在默认情况下,Nacos Server 会使用 Derby 作为数据源,用于保存配置管理数据。将 Nacos Server 的数据源迁移到更加稳定的 MySQL 数据库中,需要修改三处 Nacos Server 的数据库配置。
指定数据源:spring.datasource.platform=mysql 将这行注释放开;
指定 DB 实例数:放开 db.num=1 这一行的注释;
修改 JDBC 连接串:db.url.0 指定了数据库连接字符串,db.user.0 和 db.password.0 分别指定了连接数据库的用户名和密码
创建数据库表
Nacos 已经把建表语句放在解压后的 Nacos Server 安装目录中下的 conf 文件夹里
添加集群机器列表
Nacos Server 可以从一个本地配置文件中获取所有的 Server 地址信息,从而实现服务器之 间的数据同步。
在 Nacos Server 的 conf 目录下创建 cluster.conf 文件,并将 nacos-cluster1 和 nacos-cluster2 这两台服务器的 IP 地址 + 端口号添加到文件中。
## 注意,这里的IP不能是localhost或者127.0.0.1
192.168.1.100:8848
192.168.1.100:8948
启动 Nacos Server
通过 -m standalone 参数,可以单机模式启动。
Nacos 的启动脚本位于安装目录下的 bin 文件夹,其中 Windows 操作系统对应的启动脚本和关闭脚本分别是 startup.cmd 和 shutdown.cmd, Mac 和 Linux 系统对应的启动和关闭脚本是 startup.sh 和 shutdown.sh。
登录 Nacos 控制台
使用 Nacos 默认创建好的用户 nacos 登录系统,用户名和密码都是 nacos。
为了验证集群环境处于正常状态,可以在左侧导航栏中打开“集群管理”下的“节点列表” 页面,在这个页面上显示了集群环境中所有的 Nacos Server 节点以及对应的状态,它们的节点状态都是绿色的“UP”,这表示搭建的集群环境一切正常。
在实际的项目中,如果某个微服务 Client 要连接到 Nacos 集群做服务注册,并不会把 Nacos 集群中的所有服务器都配置在 Client 中,否则每次 Nacos 集群增加或删除了节点, 都要对所有 Client 做一次代码变更并重新发布。
常见的一个做法是提供一个 VIP URL 给到 Client,VIP URL 是一个虚拟 IP 地址,可以把 真实的 Nacos 服务器地址列表“隐藏”在虚拟 IP 后面,客户端只需要连接到虚 IP 即可,由 提供虚 IP 的组件负责将请求转发给背后的服务器列表。这样一来,即便 Nacos 集群机器数量 发生了变动,也不会对客户端造成任何感知。
提供虚 IP 的技术手段有很多,比如通过搭建 Nginx+LVS 或者 keepalived 技术实现高可用集群。
将服务提供者注册到 Nacos 服务器
添加 Nacos 依赖项
Spring Boot、Spring Cloud 和 Spring Cloud Alibaba 三者之间有严格的版本匹配关系
版本说明: link
将 Spring Cloud Alibaba 和 Spring Cloud 的依赖项版本添加到顶层项目下的 pom.xml 文件中。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2020.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2021.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
<!-- 省略部分代码 -->
</dependencyManagement>
定义了组件的大版本之后,就可以直接把 Nacos 的依赖项加入到两个子模块的 pom.xml 文件中
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
在添加完依赖项之后,就可以通过配置项开启 Nacos 的服务治理功能了。Spring Cloud 各个组件都采用了自动装配器实现了轻量级的组件集成功能,只需要几行配置,剩下的初始化工作都可以交给背后的自动装配器来实现。
Nacos 自动装配原理
在 Spring Cloud 稍早一些的版本中,需要在启动类上添加 @EnableDiscoveryClient 注 解开启服务治理功能,而在新版本的 Spring Cloud 中,这个注解不再是一个必须的步骤, 们只需要通过配置项就可以开启 Nacos 的功能。
们将 Nacos 依赖项添加到项目中,同时也引入了 Nacos 自带的自动装配器,比如下面这几 个被引入的自动装配器就掌管了 Nacos 核心功能的初始化任务。
NacosDiscoveryAutoConfiguration:服务发现功能的自动装配器,它主要做两件事 儿:加载 Nacos 配置项,声明 NacosServiceDiscovery 类用作服务发现;
NacosServiceAutoConfiguration:声明核心服务治理类 NacosServiceManager,它可以通过 service id、group 等一系列参数获取已注册的服务列表;
NacosServiceRegistryAutoConfiguration:Nacos 服务注册的自动装配器。
添加 Nacos 配置项
spring:
cloud:
nacos:
discovery:
# Nacos的服务注册地址,可以配置多个,逗号分隔
server-addr: localhost:8848
# 服务注册到Nacos上的名称,一般不用配置
service: coupon-customer-serv
# nacos客户端向服务端发送心跳的时间间隔,时间单位其实是ms
heart-beat-interval: 5000
# 服务端没有接受到客户端心跳请求就将其设为不健康的时间间隔,默认为15s
# 注:推荐值该值为15s即可,如果有的业务线希望服务下线或者出故障时希望尽快被发现,可以适
heart-beat-timeout: 20000
# 元数据部分 - 可以自己随便定制
metadata:
mydata: abc
# 客户端在启动时是否读取本地配置项(一个文件)来获取服务列表
# 注:推荐该值为false,若改成true。则客户端会在本地的一个
# 文件中保存服务信息,当下次宕机启动时,会优先读取本地的配置对外提供服务。
naming-load-cache-at-start: false
# 命名空间ID,Nacos通过不同的命名空间来区分不同的环境,进行数据隔离,
namespace: dev
# 创建不同的集群
cluster-name: Cluster-A
# [注意]两个服务如果存在上下游调用关系,必须配置相同的group才能发起访问
group: myGroup
# 向注册中心注册服务,默认为true
# 如果只消费服务,不作为服务提供方,倒是可以设置成false,减少开销
register-enabled: true
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ri6Gpvkn-1677596762819)(E:\BaiduNetdiskDownload\180SpringCloud微服务项目实战\images\473988\bd3383d12b43a35cfc3c240386c3e0f8.jpg)]](http://dev-img.mos.moduyun.com/20231009/ca488a4e-02f7-44b6-9279-e0650779bda6.png)
Namespace 可以用作环境隔离或者多租户隔离,其中:
环境隔离:比如设置三个命名空间 production、pre-production 和 dev,分别表示生产 环境、预发环境和开发环境,如果一个微服务注册到了 dev 环境,那么他无法调用其他环 境的服务,因为服务发现机制只会获取到同样注册到 dev 环境的服务列表。如果未指定 namespace 则服务会被注册到 public 这个默认 namespace 下。
多租户隔离:即 multi-tenant 架构,通过为每一个用户提供独立的 namespace 以实现租 户与租户之间的环境隔离。
Group 的使用场景非常灵活,列举几个:
环境隔离:在多租户架构之下,由于 namespace 已经被用于租户隔离,为了实现同一个租 户下的环境隔离,可以使用 group 作为环境隔离变量。
线上测试:对于涉及到上下游多服务联动的场景,将线上已部署的待上下游测服务的 group 设置为“group-A”,由于这是一个新的独立分组,所以线上的用户流量不会导向 到这个 group。这样一来,开发人员就可以在不影响线上业务的前提下,通过发送测试请 求到“group-A”的机器完成线上测试。
什么是单元封闭呢?为了保证业务的高可用性,通常会把同一个服务部署在 不同的物理单元(比如张北机房、杭州机房、上海机房),当某个中心机房出现故障的时 候,可以在很短的时间内把用户流量切入其他单元机房。由于同一个单元内的服务器资 源通常部署在同一个物理机房,因此本单元内的服务调用速度最快,而跨单元的服务调用将 要承担巨大的网络等待时间。这种情况下,可以为同一个单元的服务设置相同的 group,使微服务调用封闭在当前单元内,提高业务响应速度。
服务调用
服务消费者添加Nacos依赖项和配置信息
<!-- Nacos服务发现组件 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- 负载均衡组件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<!-- webflux服务调用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
- spring-cloud-starter-loadbalancer:Spring Cloud御用负载均衡组件Loadbalancer,用来代替已经进入维护状态的Netflix Ribbon组件。会在下一课带深入了解Loadbalancer的功能,今天只需要简单了解下它的用法就可以了;
- spring-boot-starter-webflux:Webflux是Spring Boot提供的响应式编程框架,响应式编程是基于异步和事件驱动的非阻塞程序。Webflux实现了Reactive Streams规范,内置了丰富的响应式编程特性。今天将用Webflux组件中一个叫做WebClient的小工具发起远程服务调用。
Nacos服务发现底层实现
Nacos Client通过一种 主动轮询 的机制从Nacos Server获取服务注册信息,包括地址列表、group分组、cluster名称等一系列数据。简单来说,Nacos Client会开启一个本地的定时任务,每间隔一段时间,就尝试从Nacos Server查询服务注册表,并将最新的注册信息更新到本地。这种方式也被称之为“Pull”模式,即客户端主动从服务端拉取的模式。
负责拉取服务的任务是UpdateTask类,它实现了Runnable接口。Nacos以开启线程的方式调用UpdateTask类中的run方法,触发本地的服务发现查询请求。
UpdateTask这个类是HostReactor的一个内部类,
在UpdateTask的源码中,它通过调用updateService方法实现了服务查询和本地注册表更新,在每次任务执行结束的时候,在结尾处它通过finally代码块设置了下一次executor查询的时间,周而复始循环往复。
OpenFeign
OpenFeign提供了一种声明式的远程调用接口,它可以大幅简化远程调用的编程体验。
OpenFeign使用了一种“动态代理”技术来封装远程服务调用的过程,远程服务调用的信息被写在了FeignClient接口中
OpenFeign的动态代理
在项目初始化阶段,OpenFeign会生成一个代理类,对所有通过该接口发起的远程调用进行动态代理。

- 项目加载:在项目的启动阶段, EnableFeignClients注解 扮演了“启动开关”的角色,它使用Spring框架的 Import注解 导入了FeignClientsRegistrar类,开始了OpenFeign组件的加载过程。
- 扫包: FeignClientsRegistrar 负责FeignClient接口的加载,它会在指定的包路径下扫描所有的FeignClients类,并构造FeignClientFactoryBean对象来解析FeignClient接口。
- 解析FeignClient注解: FeignClientFactoryBean 有两个重要的功能,一个是解析FeignClient接口中的请求路径和降级函数的配置信息;另一个是触发动态代理的构造过程。其中,动态代理构造是由更下一层的ReflectiveFeign完成的。
- 构建动态代理对象:ReflectiveFeign 包含了OpenFeign动态代理的核心逻辑,它主要负责创建出FeignClient接口的动态代理对象。ReflectiveFeign在这个过程中有两个重要任务,一个是解析FeignClient接口上各个方法级别的注解,将其中的远程接口URL、接口类型(GET、POST等)、各个请求参数等封装成元数据,并为每一个方法生成一个对应的MethodHandler类作为方法级别的代理;另一个重要任务是将这些MethodHandler方法代理做进一步封装,通过Java标准的动态代理协议,构建一个实现了InvocationHandler接口的动态代理对象,并将这个动态代理对象绑定到FeignClient接口上。这样一来,所有发生在FeignClient接口上的调用,最终都会由它背后的动态代理对象来承接。
MethodHandler的构建过程涉及到了复杂的元数据解析,OpenFeign组件将FeignClient接口上的各种注解封装成元数据,并利用这些元数据把一个方法调用“翻译”成一个远程调用的Request请求。
那么上面说到的“元数据的解析”是如何完成的呢?它依赖于OpenFeign组件中的Contract协议解析功能。Contract是OpenFeign组件中定义的顶层抽象接口,它有一系列的具体实现。
专门用来解析Spring MVC标签的SpringMvcContract类的继承结构是SpringMvcContract->BaseContract->Contract。
OpenFeign的工作流程的重点是 动态代理机制。OpenFeing通过Java动态代理生成了一个“代理类”,这个代理类将接口调用转化成为了一个远程服务调用。
FeignClientsRegistrar是OpenFeign初始化的起点
实现服务间调用功能
把依赖项spring-cloud-starter-OpenFeign添加到子模块内的pom.xml文件中。
<!-- OpenFeign组件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
在接口上声明了一个FeignClient注解,它专门用来标记被OpenFeign托管的接口。
@FeignClient(value = "coupon-template-serv", path = "/template")
public interface TemplateService {
// 读取优惠券
@GetMapping("/getTemplate")
CouponTemplateInfo getTemplate(@RequestParam("id") Long id);
// 批量获取
@GetMapping("/getBatch")
Map<Long, CouponTemplateInfo> getTemplateInBatch(@RequestParam("ids") Collection<Long> ids);
}
在FeignClient注解中声明的value属性是目标服务的名称,需要确保这里的服务名称和Nacos服务器上显示的服务注册名称是一样的。
配置OpenFeign的加载路径
@EnableFeignClients(basePackages = {"com.xxx"})
public class Application {
}
在EnableFeignClients注解的basePackages属性中定义了一个com.xxx的包名,这个注解就会告诉OpenFeign在启动项目的时候做一件事儿:找到所有位于com.xxx包路径(包括子package)之下使用FeignClient修饰的接口,然后生成相关的代理类并添加到Spring的上下文中。这样才能够在项目中用Autowired注解注入OpenFeign接口。
日志信息打印
服务请求的入参和出参是分析和排查问题的重要线索。为了获得服务请求的参数和返回值,经常使用的一个做法就是 打印日志
首先,需要在配置文件中 指定FeignClient接口的日志级别为Debug。这样做是因为OpenFeign组件默认将日志信息以debug模式输出,而默认情况下Spring Boot的日志级别是Info
接下来,还需要在应用的上下文中使用代码的方式 声明Feign组件的日志级别。这里的日志级别并不是传统意义上的Log Level,它是OpenFeign组件自定义的一种日志级别,用来控制OpenFeign组件向日志中写入什么内容。
@Bean
Logger.Level feignLogger() {
return Logger.Level.FULL;
}
OpenFeign总共有四种不同的日志级别
- NONE:不记录任何信息,这是OpenFeign默认的日志级别;
- BASIC:只记录服务请求的URL、HTTP Method、响应状态码(如200、404等)和服务调用的执行时间;
- HEADERS:在BASIC的基础上,还记录了请求和响应中的HTTP Headers;
- FULL:在HEADERS级别的基础上,还记录了服务请求和服务响应中的Body和metadata,FULL级别记录了最完整的调用信息。
超时判定
超时判定是一种保障可用性的手段。
为了隔离下游接口调用超时所带来的的影响,可以在程序中设置一个 超时判定的阈值,一旦下游接口的响应时间超过了这个阈值,那么程序会自动取消此次调用并返回一个异常。
feign:
client:
config:
# 全局超时配置
default:
# 网络连接阶段1秒超时
connectTimeout: 1000
# 服务请求响应阶段5秒超时
readTimeout: 5000
# 针对某个特定服务的超时配置
coupon-template-serv:
connectTimeout: 1000
readTimeout: 2000
降级
降级逻辑是在远程服务调用发生超时或者异常(比如400、500 Error Code)的时候,自动执行的一段业务逻辑。
OpenFeign实现Client端的服务降级相比于Sentinel而言 更加轻量级且容易实现, 足以满足一些简单的服务降级业务需求。
OpenFeign对服务降级的支持是借助Hystrix组件实现的,由于Hystrix已经从Spring Cloud组件库中被移除,所以要在pom文件中手动添加hystrix项目的依赖。
<!-- hystrix组件,专门用来演示OpenFeign降级 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.2.10.RELEASE</version>
<exclusions>
<!-- 移除Ribbon负载均衡器,避免冲突 -->
<exclusion>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-ribbon</artifactId>
</exclusion>
</exclusions>
</dependency>
OpenFeign支持两种不同的方式来指定降级逻辑,一种是定义fallback类,另一种是定义fallback工厂。
通过fallback类实现降级是最为简单的一种途径,如果想要为FeignClient接口指定一段降级流程,可以定义一个降级类并实现接口,并在接口中指定为降级类。
@FeignClient(value = "coupon-template-serv", path = "/template",
// 通过fallback指定降级逻辑
fallback = TemplateServiceFallback.class)
如果想要在降级方法中获取到 异常的具体原因,那么就要借助 fallback工厂 的方式来指定降级逻辑了。按照OpenFeign的规范,自定义的fallback工厂需要实现FallbackFactory接口
@FeignClient(value = "coupon-template-serv", path = "/template",
// 通过抽象工厂来定义降级逻辑
fallbackFactory = TemplateServiceFallbackFactory.class)
配置中心
分布式配置中心在配置管理方面发挥的作用
高可用性: 微服务组件的高可用性是首要目标。配置中心并不是一个中心化的单点应用,而是一个通过集群对外提供服务的组件。在一致性算法的基础上,集群中各个节点之间会互相同步配置数据,或者从统一数据源读取配置数据。即便个别节点挂掉,也不影响整个集群的可用性;
环境隔离特性:Nacos支持通过Namespace属性指定当前配置项所在的环境,可以为自己的应用系统创建开发环境、预发环境和生产环境,不同环境之间的配置文件是相互隔离的;
多格式支持:Nacos支持多种不同格式的配置内容,可以使用纯文本、JSON、XML、YAML和Properties多种文件后缀;
访问控制:Nacos实现了权限管理功能,可以在控制台创建用户账号和权限组,限制某个账号可以访问哪些命名空间,并配置账号的读写权限(只读、只写、读写)。通过这种方式,可以保障敏感信息(如数据库用户名和密码)的安全;
职责分离:配置项从jar包中抽离了出来,修改配置项再也不需要重新编译打包应用程序了,完美实现了配置项管理与业务代码之间的职责分离;
版本控制和审计功能:配置项也是一种代码,而且配置bug往往比代码中的bug造成的影响更大。因此,在微服务架构中需要确保配置中心具备完善的版本控制和审计功能
Nacos还可以支持 多文件源读取以及运行期配置变更。尤其是 动态变更推送,更是微服务架构下不可或缺的配置管理能力。
添加依赖项
<!-- 添加Nacos Config配置项 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- 读取bootstrap文件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
Nacos配置中心的连接信息需要配置在bootstrap文件,而非application.yml文件中。在Spring Cloud 2020.0.0版本之后,bootstrap文件不会被自动加载,需要主动添加依赖项,来开启bootstrap的自动加载流程。
为什么集成Nacos配置中心必须用到bootstrap配置文件呢?为了保证其他应用能够正常启动,必须 在其它组件初始化之前从Nacos读到所有配置项,之后再将获取到的配置项用于后续的初始化流程。
添加本地Nacos Config配置项
需要在bootstrap.yml文件中添加一些Nacos Config配置项
spring:
# 必须把name属性从application.yml迁移过来,否则无法动态刷新
application:
name: coupon-customer-serv
cloud:
nacos:
config:
# nacos config服务器的地址
server-addr: localhost:8848
file-extension: yml
# prefix: 文件名前缀,默认是spring.application.name
# 如果没有指定命令空间,则默认命令空间为PUBLIC
namespace: dev
# 如果没有配置Group,则默认值为DEFAULT_GROUP
group: DEFAULT_GROUP
# 从Nacos读取配置项的超时时间
timeout: 5000
# 长轮询超时时间
config-long-poll-timeout: 10000
# 轮询的重试时间
config-retry-time: 2000
# 长轮询最大重试次数
max-retry: 3
# 开启监听和自动刷新
refresh-enabled: true
# Nacos的扩展配置项,数字越大优先级越高
extension-configs:
- dataId: redis-config.yml
group: EXT_GROUP
# 动态刷新
refresh: true
- dataId: rabbitmq-config.yml
group: EXT_GROUP
refresh: true
长轮询机制 的工作原理
当Client向Nacos Config服务端发起一个配置查询请求时,服务端并不会立即返回查询结果,而是会将这个请求hold一段时间。如果在这段时间内有配置项数据的变更,那么服务端会触发变更事件,客户端将会监听到该事件,并获取相关配置变更;如果这段时间内没有发生数据变更,那么在这段“hold时间”结束后,服务端将释放请求。
采用长轮询机制可以降低多次请求带来的网络开销,并降低更新配置项的延迟。
动态配置推送
使用@Value注解将Nacos配置中心里的属性注入进来。给属性设置一个默认值,这样做的目的是加一层容错机制。即便Nacos Config连接异常无法获取配置项,应用程序也可以使用默认值完成启动加载。
最后,在类头上添加一个RefreshScope注解,有了这个注解,Nacos Config中的属性变动就会动态同步到当前类的变量中。如果不添加RefreshScope注解,即便应用程序监听到了外部属性变更,那么类变量的值也不会被刷新。
RefreshScope注解
为了实现动态刷新配置,主要就是想办法达成以下两个核心目标:
- 让Spring容器重新加载Environment环境配置变量
- Spring Bean重新创建生成
@RefreshScope主要就是基于@Scope注解的作用域代理的基础上进行扩展实现的,加了@RefreshScope注解的类,在被Bean工厂创建后会加入自己的refresh scope 这个Bean缓存中,后续会优先从Bean缓存中获取,当配置中心发生了变更,会把变更的配置更新到spring容器的Environment中,并且同事bean缓存就会被清空,从而就会从bean工厂中创建bean实例了,而这次创建bean实例的时候就会继续经历这个bean的生命周期,使得@Value属性值能够从Environment中获取到最新的属性值,这样整个过程就达到了动态刷新配置的效果。
Sentinel

在Sentinel的世界中,万物都是可以被保护的“资源”,当一个外部请求想要访问Sentinel的资源时,便会创建一个Entry对象,经过Slot链路的层层考验最终完成自己的业务,可以把Slot当成是一类完成特定任务的“Filter”, 这是一种典型的职责链设计模式。
在这些Slot中,有几个是被专门用来 收集数据 的。比如:
NodeSelectorSlot 被用来构建当前请求的访问路径,它将上下游调用链串联起来,形成了一个服务调用关系的树状结构。
ClusterBuilderSlot 和 StatisticSlot 这两个Slot会从多个维度统计一些运行期信息,比如接口响应时间、服务QPS、当前线程数等等。
由这几个Slot统计出来的结果,会为后续的限流降级等Sentinel策略提供数据支持。
Sentinel还有很多被用作“规则判断”的Slot。比如:
FlowSlot 被用来做流控规则的判定, DegradeSlot 被用来做降级熔断判定,这两个Slot是平时在项目中使用频率最高的服务容错功能。
ParamFlowSlot 可以根据请求参数做精细粒度的流控,它经常被用来在大型应用中控制热点数据所带来的突发流量。
AuthoritySlot 可以针对特定资源设置黑白名单,限制某些应用对资源的访问。
除此之外,Sentinel的Slot机制也具备一定的扩展性,如果想要添加一个自定义的Slot,可以通过实现ProcessorSlot接口来完成,而且还可以通过优先级调整各个Slot之间的执行顺序。
运行Sentinel控制台
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.2.jar
将微服务接入到Sentinel控制台
首先,需要把Sentinel的依赖项引入到项目里
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
然后,需要做一些基本的配置
spring:
cloud:
sentinel:
transport:
# sentinel api端口,默认8719
port: 8719
# dashboard地址
dashboard: localhost:8080
Sentinel会为Controller中的API生成一个默认的资源名称,这个名称就是URL的路径,也可以使用特定的注解为资源打上一个指定的名称标记。
@SentinelResource(value = "getTemplateInBatch", blockHandler = "getTemplateInBatch_block")
注解中的blockHandler属性为当前资源指定了限流后的降级方法,如果当前服务抛出了BlockException,那么就会转而执行这段限流方法。
设置流控规则
Sentinel支持三种不同的流控模式,分别是直接流控、关联流控和链路流控。
-
直接流控:直接作用于当前资源,如果访问压力大于某个阈值,后续请求将被直接拦下来;
-
关联流控:当关联资源的访问量达到某个阈值时,对当前资源进行限流;
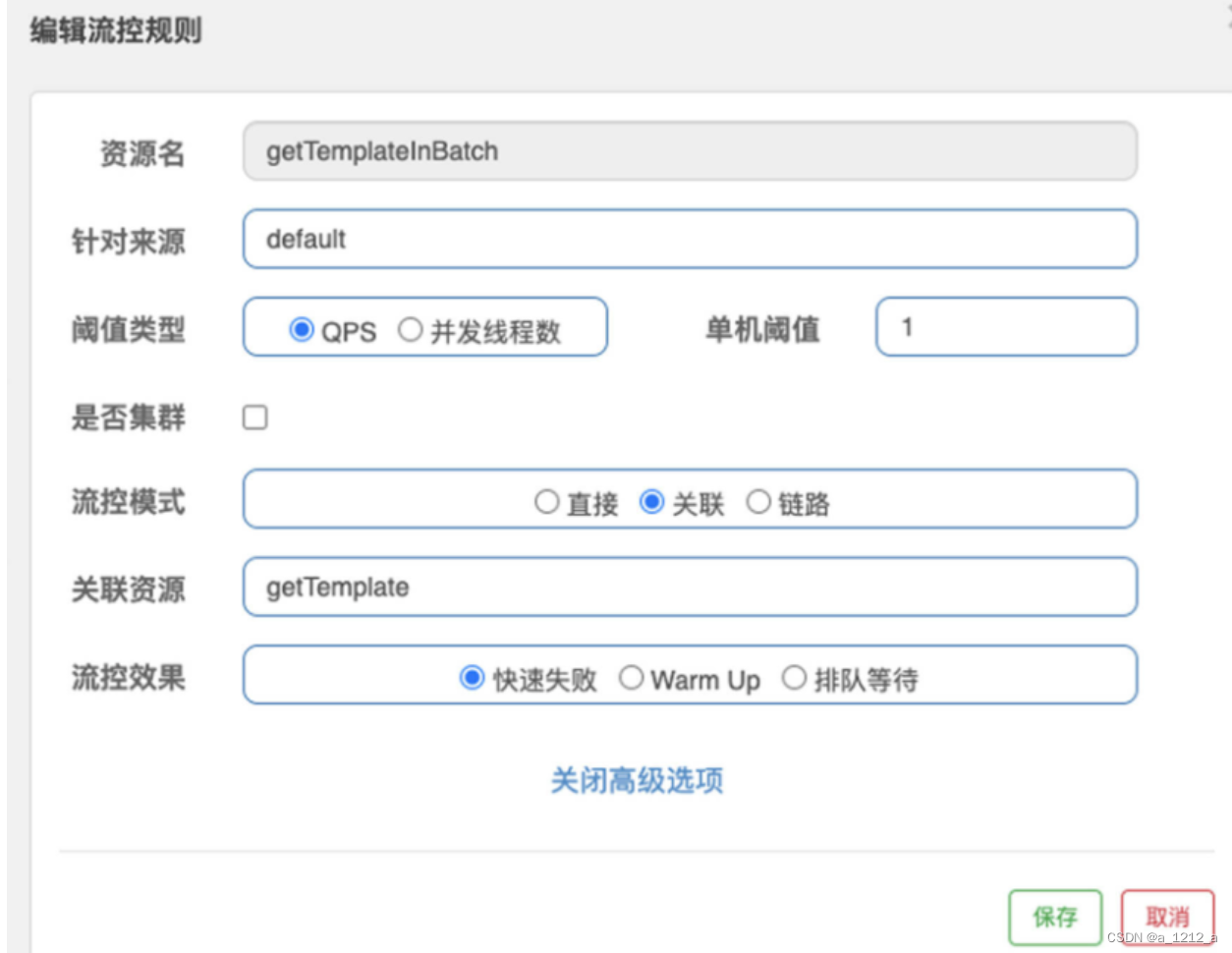
在“关联资源”一栏填了getTemplate,写在这里的是高优先级资源的名称。同时,设置了阈值判断条件为QPS=1,它的意思是,如果高优先级资源的访问频率达到了每秒一次,那么低优先级资源就会被限流。
关联限流的阈值判断是作用于高优先级资源之上的,但是流控效果是作用于低优先级资源之上。
-
链路流控:当指定链路上的访问量大于某个阈值时,对当前资源进行限流,这里的“指定链路”是细化到API级别的限流维度。


在上面的图里,一个服务应用中有/api/edit和/api/add两个接口,这两个接口都调用了同一个资源resource-1。如果想只对/api/edit接口流进行限流,那么就可以将“链路流控”应用在resource-1之上,同时指定当前流控规则的“入口资源”是/api/edit。
实现针对调用源的限流
在微服务架构中,一个服务可能被多个服务调用。比如说,Customer服务会调用Template服务的getTemplateInBatch资源,未来可能会研发一个新的服务叫coupon-other-serv,它也会调用相同资源。
如果想为getTemplateInBatch资源设置一个限流规则,并指定其只对来自Customer服务的调用起作用

这个实现过程分为两步。第一步,要想办法在服务请求中加上一个特殊标记,告诉Template服务是谁调用;第二步,需要在Sentinel控制台设置流控规则的针对来源。
第一步。首先,将调用源的应用名加入到由OpenFeign组件构造的Request中。可以借助OpenFeign的RequestInterceptor扩展接口,编写一个自定义的拦截器,在服务请求发送出去之前,往Request的Header里写入一个特殊变量,传递给下游服务的“来源标记”
@Configuration
public class OpenfeignSentinelInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
template.header("SentinelSource", "coupon-customer-serv");
}
}
接下来,需要在Template服务中识别来自上游的标记,并将其加入到Sentinel的链路统计中。可以借助Sentinel提供的RequestOriginParser扩展接口,编写一个自定义的解析器。
@Component
@Slf4j
public class SentinelOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest request) {
log.info("request {}, header={}", request.getParameterMap(), request.getHeaderNames());
return request.getHeader("SentinelSource");
}
在方法中,从服务请求的Header中获取SentinelSource变量的值,作为调用源的name
第二步。在流控规则的编辑页面,“针对来源”这一栏填上coupon-customer-serv并保存,这样一来,当前限流规则就只会针对来自Customer服务的请求生效了。

Sentinel的流控效果
快速失败,Sentinel默认的流控效果,在快速失败模式下,超过阈值设定的请求将会被立即阻拦住。
Warm Up 则实现了“预热模式的流控效果”,这种方式可以平缓拉高系统水位,避免突发流量对当前处于低水位的系统的可用性造成破坏。举个例子,如果设置的系统阈值是QPS=10,预热时间=5,那么Sentinel会在这5秒的预热时间内,将限流阈值从3缓慢拉高到10。为什么起始阈值是3呢?因为Sentinel内部有一个冷加载因子,它的值是3,在预热模式下,起始阈值的计算公式是单机阈值/冷加载因子,也就是10/3=3。
排队等待 模式下,超过阈值的请求不会立即失败,而是会被放入一个队列中,排好队等待被处理。一旦请求在队列中等待的时间超过了设置的超时时间,那么请求就会被从队列中移除。
异常降级方案
使用blockHandler属性指定降级方法的名称,只能在服务抛出BlockException的情况下执行降级逻辑。
BlockException这个异常类是Sentinel组件自带的类,当一个请求被Sentinel规则拦截,这个异常便会被抛出。比如请求被Sentinel流控策略阻拦住,或者请求被熔断策略阻断了,这些情况下可以使用SentinelResource注解的blockHandler来指定降级逻辑。对于其它RuntimeException的异常类型它就无能为力了。
使用SentinelResource中的另一个属性fallback可以指定一段通用的降级逻辑。
需要注意,如果降级方法的方法签名是BlockException,那么fallback是无法正常工作的。在注解中同时使用了fallback和blockHandler属性,如果服务抛出BlockException,则执行blockHandler属性指定的方法,其他异常就由fallback属性所对应的降级方法接管。
可以通过SentinelResource注解的fallbackClass属性指定一个保存降级逻辑的Class。
在控制台添加熔断策略
Sentinel的熔断规则有3种,分别是异常比例、异常数和慢调用比例。
异常比例
指定以“ 异常比例”为熔断开关的判断逻辑。指定10秒的统计窗口内,如果异常调用的比例超过了60%,并且满足请求数量>=5,就开启一段为期5秒的熔断时间。
“熔断时长”的时间单位是秒,而“统计窗口”的时间单位是毫秒

Sentinel底层通过一段跨度为10秒的滑动窗口来统计服务调用情况。在这段窗口时间内,前三个服务请求全部失败,这时失败率已经达到100%,大大超过了定义的60%的阈值,但是熔断开关却没有打开,这是因为统计窗口的最小请求数还没有达到设定值5。
之后又有两个请求被处理,一个成功一个失败,这时请求个数已经达到了5,失败率是80%,那么Sentinel就开启了一段5秒的熔断时间。在这段时间内,所有来访请求都不会得到真实的执行,而是转而执行降级逻辑。
异常数
“ 异常数”熔断规则和前面设置的异常比例熔断规则几乎一样,唯一的区别就是“异常数”的判定条件是统计窗口内发生异常的个数。

熔断器开启的判定条件是异常数>2
慢调用比例
通常来说,慢调用请求所占比例逐渐增多,这是服务雪崩的前兆。为了将影响范围缩小,要做的就是 尽早捕捉到慢调用请求的比例变化趋势,及时通过熔断规则对服务进行减压。

在10秒的统计窗口内,如果响应时间大于1000ms的请求所占总请求数量的比例超过了0.4,并且请求总数量>=5,此时将触发Sentinel的熔断开关,开启5秒的熔断窗口。
熔断开关的状态转换
Sentinel的熔断器会在开启、关闭和半开这三种逻辑状态之间来回切换

从图中可以看出,在第一个统计窗口内熔断器是处于关闭状态的,达到熔断判定条件之后,Sentinel开启了一段熔断窗口。在这段窗口时间内,熔断器是处于开启状态的,这时新的服务请求会执行降级逻辑。待熔断窗口结束,Sentinel会将熔断器状态置为“半开”状态,这是一个介于完全开启和完全关闭之间的中间态。
在半开状态下,如果有一个新请求过来,那么Sentinel会试探性地让这个请求去执行正常的业务逻辑,如果执行成功,那么Sentinel将关闭熔断器并退出熔断状态,如果执行失败,那么Sentinel将再次开启一个新的熔断窗口。
接入 Nacos 实现规则持久化
通过集成Nacos Config来实现持久化方案,需要把Sentinel中设置的限流规则保存到Nacos配置中心。这样一来,当应用服务或Sentinel Dashboard重新启动时,它们就可以自动把Nacos中的限流规则同步到本地,不管怎么重启服务都不会导致规则失效了。

Sentinel控制台将限流规则同步到了Nacos Config服务器来实现持久化。同时,在应用程序中,配置了一个Sentinel Datasource,从Nacos Config服务器获取具体配置信息。
在应用启动阶段,程序会主动从Sentinel Datasource获取限流规则配置。而在运行期,也可以在Sentinel控制台动态修改限流规则,应用程序会实时监听配置中心的数据变化,进而获取变更后的数据。
Sentinel组件二次开发
需要将Sentinel的代码下载到本地。可以从 GitHub的Releases页面 的Assets面板中下载Source code源文件。
将项目导入到开发工具中主要针对其中的sentinel-dashboard子模块做二次开发。整个改造过程按照先后顺序将分为三个步骤:
- 修改Nacos依赖项的应用范围,将其打入jar包中;
- 后端程序对接Nacos,将Sentinel限流规则同步到Nacos;
- 开放单独的前端限流规则配置页面。
修改Nacos依赖项
sentinel-dashboard项目的pom.xml文件中的依赖项sentinel-datasource-nacos是连接Nacos Config所依赖的必要组件。需要将这个依赖项的scope标签注释掉。
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
<!-- 将scope注释掉,改为编译期打包 -->
<!--<scope>test</scope>-->
</dependency>
后端程序对接Nacos
打开sentinel-dashboard项目下的src/test/java目录(注意是test目录而不是main目录),然后定位到com.alibaba.csp.sentinel.dashboard.rule.nacos包。在这个包下面,看到4个和Nacos Config有关的类,它们的功能描述如下:
- NacosConfig:初始化Nacos Config的连接;
- NacosConfigUtil:约定了Nacos配置文件所属的Group和文件命名后缀等常量字段;
- FlowRuleNacosProvider:从Nacos Config上获取限流规则;
- FlowRuleNacosPublisher:将限流规则发布到Nacos Config。
为了让这些类在Sentinel运行期可以发挥作用,需要在src/main/java下创建同样的包路径,然后将这四个文件从test路径拷贝到main路径下。
NacosConfig类中配置Nacos连接串:
打开NacosConfig类,找到其中的nacosConfigService方法。这个方法创建了一个ConfigService类,它是Nacos Config定义的通用接口,提供了Nacos配置项的读取和更新功能。FlowRuleNacosProvider和FlowRuleNacosPublisher这两个类都是基于这个ConfigService类实现Nacos数据同步的。改造后的代码:
@Bean
public ConfigService nacosConfigService() throws Exception {
// 将Nacos的注册地址引入进来
//也可以通过配置文件来注入serverAddr和namespace等属性。
Properties properties = new Properties();
properties.setProperty("serverAddr", "localhost:8848");
properties.setProperty("namespace", "dev");
return ConfigFactory.createConfigService(properties);
}
在Controller层接入Nacos来实现限流规则持久化:
在FlowControllerV2中正式接入Nacos。FlowControllerV2对外暴露了REST API,用来创建和修改限流规则。在这个类的源代码中,需要修改两个变量的Qualifier注解值。
@Autowired
// 指向刚才从test包中迁移过来的FlowRuleNacosProvider类
@Qualifier("flowRuleNacosProvider")
private DynamicRuleProvider<List<FlowRuleEntity>> ruleProvider;
@Autowired
// 指向刚才从test包中迁移过来的FlowRuleNacosPublisher类
@Qualifier("flowRuleNacosPublisher")
private DynamicRulePublisher<List<FlowRuleEntity>> rulePublisher;
通过Qualifier标签将FlowRuleNacosProvider注入到了ruleProvier变量中,又采用同样的方式将FlowRuleNacosPublisher注入到了rulePublisher变量中。FlowRuleNacosProvider和FlowRuleNacosPublisher就是从test目录Copy到main目录下的两个类。
修改完成之后,FlowControllerV2底层的限流规则改动就会被同步到Nacos服务器了。这个同步工作是由FlowRuleNacosPublisher执行的,它会发送一个POST请求到Nacos服务器来修改配置项。
FlowRuleNacosPublisher会在Nacos Config上创建一个用来保存限流规则的配置文件,这个配置文件以“application.name”开头,以“-flow-rules”结尾,而且它所属的Group为“SENTINEL_GROUP”。这里用到的文件命名规则和Group都是通过NacosConfigUtil类中的常量指定的。
前端页面改造
打开sentinel-dashboard模块下的webapp目录,该目录存放了Sentinel控制台的前端页面资源。需要改造的文件是sidebar.html,这个html文件定义了控制台的左侧导航栏。
<li ui-sref-active="active">
<a ui-sref="dashboard.flow({app: entry.app})">
<i class="glyphicon glyphicon-filter"></i> 流控规则持久化</a>
</li>
微服务改造
只需要添加一个新的sentinel-datasource-nacos依赖项,并在配置文件中添加sentinel datasource连接信息就可以了
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
spring:
cloud:
sentinel:
datasource:
# 数据源的key,可以自由命名
geekbang-flow:
# 指定当前数据源是nacos
nacos:
# 设置Nacos的连接地址、命名空间和Group ID
server-addr: localhost:8848
namespace: dev
groupId: SENTINEL_GROUP
# 设置Nacos中配置文件的命名规则
dataId: ${spring.application.name}-flow-rules
# 必填的重要字段,指定当前规则类型是"限流"
rule-type: flow
在微服务端的sentinal数据源中配置的namespace和groupID,一定要和Sentinal Dashoboard二次改造中的中的配置相同,否则将无法正常同步限流规则。Sentinal Dashboard中namespace是在NacosConfig类中指定的,而groupID是在NacosConfigUtil类中指定的。
dataId的文件命名规则,需要和Sentinel二次改造中的FlowRuleNacosPublisher类保持一致,如果修改了FlowRuleNacosPublisher中的命名规则,那么也要在每个微服务端做相应的变更。
调用链追踪:集成 Sleuth 和 Zipkin
Sleuth
如果想提高线上异常排查的效率,那么首先要做的一件事就是: 将一次调用请求中所有访问到的微服务日志前后串联起来。
链路追踪技术会为每次服务调用生成一个全局唯一的ID(Trace ID),从本次服务调用的起点到终点,这个过程中的所有日志信息都会被打上Trace ID的烙印。这样一来,根据日志中的Trace ID,就能很清晰地梳理出一次服务请求前后都经过了哪些微服务节点。
Sleuth的底层逻辑
调用链追踪有两个任务,一是 标记出一次调用请求中的所有日志,二是 梳理日志间的前后关系。
集成了Sleuth组件之后,它会向日志中打入三个“特殊标记”,其中一个标记是Trace ID。剩下的两个标记分别是Span ID和Parent Span ID,这俩用来表示调用的前后顺序关系。
Trace ID完成的是第一个任务:标记,用来标记调用链的全局唯一ID。
Span是Sleuth下面的一个基本工作单元,当服务请求抵达当前单元时,Sleuth就会为这个单元分配一个独一无二的Span ID,并标记单元的开始时间和结束时间,这样就可以记录每个单元的处理用时了。
Parent Span ID指向了当前单元的父级单元,也就是上游的调用者。一个环环相扣的调用链就通过Parent Span ID被串了起来。

上面的图示只是一个简化的流程,在实际的项目中,一次服务调用可不光只会生成一个Span。比如说服务A请求通过OpenFeign组件调用了服务B,那么服务A接收用户请求的过程就是一个单元,而OpenFeign组件发起远程调用的过程又是另一个单元。由此可见,单元的颗粒度其实是非常小的。
Sleuth还有一个特殊的数据结构,叫做Annotation,被用来记录一个具体的“事件”。

集成Sleuth实现链路打标
将Sleuth的依赖项添加到pom.xml文件中
<!-- Sleuth依赖项 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
application.yml配置文件
spring:
sleuth:
sampler:
# 采样率的概率,100%采样
probability: 1.0
# 每秒采样数字最高为1000
rate: 1000
probability,是一个0到1的浮点数,用来表示 采样率。这里设置的probability是1,就表示对请求进行100%采样。如果把probability设置成小于1的数,就说明有的请求不会被采样。如果一个请求未被采样,那么它将不会被调用链追踪系统Track起来。
rate参数,它代表 每秒最多可以对多少个Request进行采样。这有点像一个“限流”参数,如果超过这个阈值,服务请求仍然会被正常处理,但调用链信息不会被采样。
Sleuth如何在调用链中传递标记
Sleuth为了将Trace ID和调用方服务的Span ID传递给被调用的微服务,它在OpenFeign的环节动了一个手脚。Sleuth通过 TracingFeignClient类,将一系列Tag标记塞进了OpenFeign构造的服务请求的Header结构中。
在TracingFeignClient的类中打了一个Debug断点,将Request的Header信息打印出来:

在这个Header结构中,可以看到有几个以X-B3开头的特殊标记,这个X-B3就是Sleuth的特殊接头暗号。其中X-B3-TraceId就是全局唯一的链路追踪ID,而X-B3-SpanId和X-B3-ParentSpandID分别是当前请求的单元ID和父级单元ID,最后的X-B3-Sampled则表示当前链路是否是一个已被采样的链路。通过Header里的这些信息,下游服务就完整地得到了上游服务的情报。
使用Zipkin收集并查看链路数据
Zipkin是一个分布式的Tracing系统,它可以用来收集时序化的链路打标数据。通过Zipkin内置的UI界面,可以根据Trace ID搜索出一次调用链所经过的所有访问单元,并获取每个单元在当前服务调用中所花费的时间。
为了搭建一条高可用的链路信息传递通道,使用RabbitMQ作为中转站,让各个应用服务器将服务调用链信息传递给RabbitMQ,而Zipkin服务器则通过监听RabbitMQ的队列来获取调用链数据。相比于让微服务通过Web接口直连Zipkin, 使用消息队列可以大幅提高信息的送达率和传递效率。
搭建Zipkin服务器
通过访问 maven的中央仓库 下载zipkin-server-2.23.9-exec.jar文件
java -jar zipkin-server-2.23.9-exec.jar --zipkin.collector.rabbitmq.addresses=localhost:5672
Zipkin已经内置了RabbitMQ的默认连接属性,如果没有特殊指定,那么Zipkin会使用guest默认用户登录RabbitMQ。

搭建Zipkin有两种方式,一种是直接下载Jar包,这是官方推荐的标准集成方式;另一种是通过引入Zipkin依赖项的方式,在本地搭建一个Spring Boot版的Zipkin服务器。如果需要对Zipkin做定制化开发,那么可以采取后一种方式。
传送链路数据到Zipkin
在每个微服务模块的pom.xml中添加Zipkin适配插件和Stream的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
将Zipkin的配置信息添加到每个微服务模块的application.yml文件中。Zipkin适配器还支持ActiveMQ、Kafka和直连的方式
spring:
zipkin:
sender:
type: rabbit
rabbitmq:
addresses: 127.0.0.1:5672
queue: zipkin #在应用中指定的队列名称,一定要同Zipkin服务器所指定的队列名称保持一致
在浏览器中打开localhost:9411进到Zipkin的首页,在首页中可以通过各种搜索条件的组合,从服务、时间等不同维度查询调用链数据。
Spring Cloud Gateway
Gateway叫“微服务网关”,就说明它自己就是一个微服务。换句话说,它也是Nacos服务注册中心的一员。既然Gateway能连接到Nacos,那么就意味着它可以轻松获取到Nacos中所有服务的注册表。这样一来,Gateway就可以根据本地的路由规则,将请求精准无误地送达到每个微服务组件中。
高可扩展性,对后台的微服务集群做扩容或缩容的时候,Gateway可以从Nacos注册中心轻松获取所有服务节点的变动,不需要任何额外的配置,一切都在无感知的情况下自然而然地发生。
高度可定制化,它提供了一种对开发人员非常友好的方式,可以通过Java代码去定制各种复杂的路由逻辑,还可以使用Filter对请求进行加工。
Gateway路由规则
Gateway的路由规则主要有三个部分,分别是路由、谓词和过滤器。

路由
路由是Gateway的一个基本单元,每个路由都有一个目标地址,这个目标地址就是当前路由规则要调用的目标服务。那么一条路由规则在什么情况下会去调用目标服务呢?这就要看路由的谓词设置了。
谓词
所谓谓词,实际上是路由的判断规则,一个路由中可以添加多个谓词的组合。如果一个服务请求满足某个路由里设置的所有的谓词规则,那么就说明这个请求是当前路由的心动女神,这时候Gateway就会把请求转发到路由中设置的目标地址。
过滤器
过滤器和路由、目标地址之间是什么关系呢?其实Gateway在把请求转发给目标地址的过程中,把这个任务全权委托给了Filter(过滤器)来处理。

Gateway组件使用了一种FilterChain的模式对请求进行处理,每一个服务请求(Request)在发送到目标服务之前都要被一串FilterChain处理。同理,在Gateway接收服务响应(Response)的过程中也会被FilterChain处理一把。
Gateway的过滤器主要分为两种,一种是GlobalFilter,也就是“ 全局过滤器”;另一种是GatewayFilter,也就是对指定路由生效的“ 局部过滤器”。
全局过滤器继承自GlobalFilter接口,它的作用大多是“例行公事”,也就是一些底层能力的支持。比如,RouteToRequestUrlFilter这个全局过滤器就是用来解析“目标服务地址”的。
除此之外,Gateway还有一系列用来做路径转发、请求跨域、WebSocket、WebClient和Loadbalancer功能支持的全局过滤器。
GatewayAutoConfiguration这个类是Gateway的自动装配器,里面包含了大量GlobalFilter的声明。
GatewayFilter也就是局部过滤器,它的功能可就多了。Gateway提供了一系列的内置过滤器,可以实现对Request/Response的修改、请求路径修改、调用重试、限流等等功能。当然了,也可以通过Gateway的扩展接口实现一个自定义过滤器并应用到路由规则中。
声明路由的几种方式
Gateway提供了三种方式来加载路由规则,分别是Java代码、yaml文件和动态路由。
第一种加载方式是Java代码声明路由,它是可读性和可维护性最好的方式,使用一种链式编程的Builder风格来构造一个route对象,根据path的匹配规则将请求转发到不同的地址。
@Bean
public RouteLocator declare(RouteLocatorBuilder builder) {
return builder.routes()
.route("id-001", route -> route
.path("/geekbang/**")
.uri("http://time.geekbang.org")
).route(route -> route
.path("/test/**")
.uri("http://www.test.com")
).build();
}
第二种方式是通过配置文件来声明路由,可以在application.yml文件中组装路由规则。
spring:
cloud:
gateway:
routes:
- id: id-001
uri: http://time.geekbang.org
predicates:
- Path=/geekbang2/**
- uri: http://www.test.com
predicates:
- Path=/test2/**
如果想要在Gateway运行期更改路由逻辑,那么就要使用第三种方式:动态路由加载。
动态路由也有不同的实现方式。如果在项目中集成了actuator服务,那么就可以通过Gateway对外开放的actuator端点在运行期对路由规则做增删改查。但这种修改只是临时性的,项目重新启动后就会被打回原形,因为这些动态规则并没有持久化到任何地方。
动态路由还有另一种实现方式,那就是借助Nacos配置中心来存储路由规则。Gateway通过监听Nacos Config中的文件变动,就可以动态获取Nacos中配置的规则,并在本地生效了。
Gateway的内置谓词
比较常用的谓词大致分为三个类型:寻址谓词、请求参数谓词和时间谓词。
寻址谓词,顾名思义,就是针对请求地址和类型做判断的谓词条件。
.route("id-001", route -> route
.path("/geekbang/**")
.and().method(HttpMethod.GET, HttpMethod.POST)
.uri("http://time.geekbang.org")
在上面这段代码中,添加了不止一个谓词。在谓词与谓词之间,可以使用and、or、negate这类“与或非”逻辑连词进行组合,构造一个复杂判断条件。
这里用到的path,其实就是一个路径匹配条件,当请求的URL和Path谓词中指定的模式相匹配的时候,这个谓词就会返回一个True的判断。而method谓词则是根据请求的Http Method做为判断条件,比如这里就限定了只有GET和POST请求才能访问当前Route。
请求参数谓词,这类谓词主要对服务请求所附带的参数进行判断。这里的参数不单单是Query参数,还可以是Cookie和Header中包含的参数。
.route("id-001", route -> route
// 验证cookie
.cookie("myCookie", "regex")
// 验证header
.and().header("myHeaderA")
.and().header("myHeaderB", "regex")
// 验证param
.and().query("paramA")
.and().query("paramB", "regex")
.and().remoteAddr("远程服务地址")
.and().host("pattern1", "pattern2")
时间谓词,可以借助before、after、between这三个时间谓词来控制当前路由的生效时间段。
.route("id-001", route -> route
// 在指定时间之前
.before(ZonedDateTime.parse("2022-12-25T14:33:47.789+08:00"))
// 在指定时间之后
.or().after(ZonedDateTime.parse("2022-12-25T14:33:47.789+08:00"))
// 或者在某个时间段以内
.or().between(
ZonedDateTime.parse("起始时间"),
ZonedDateTime.parse("结束时间"))
自定义的谓词逻辑
Gateway组件提供了一个统一的抽象类AbstractRoutePredicateFactory作为谓词工厂,可以通过继承这个类来添加新的谓词逻辑。
// 继承自通用扩展抽象类AbstractRoutePredicateFactory
public class MyPredicateFactory extends
AbstractRoutePredicateFactory<MyPredicateFactory.Config> {
public MyPredicateFactory() {
super(Config.class);
}
// 定义当前谓词所需要用到的参数
@Validated
public static class Config {
private String myField;
}
@Override
public List<String> shortcutFieldOrder() {
// 声明当前谓词参数的传入顺序
// 参数名要和Config中的参数名称一致
return Arrays.asList("myField");
}
// 实现谓词判断的核心方法
// Gateway会将外部传入的参数封装为Config对象
@Override
public Predicate<ServerWebExchange> apply(Config config) {
return new GatewayPredicate() {
// 在这个方法里编写自定义谓词逻辑
@Override
public boolean test(ServerWebExchange exchange) {
return true;
}
@Override
public String toString() {
return String.format("myField: %s", config.myField);
}
};
}
}
这里面的关键步骤就两步,一是定义Config结构来接收外部传入的谓词参数,二是实现apply方法编写谓词判断逻辑。
请求转发、跨域和限流规则
微服务网关模块的pom.xml文件中添加几个关键依赖项
<!-- Gateway依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!-- Nacos服务发现 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<!-- Redis+Lua限流 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
Nacos和Loadbalancer则扮演了“导航”的作用,让Gateway在请求转发的过程中可以通过“服务发现+负载均衡”定位到对应的服务节点。最后一个是Redis依赖项,用它来实现网关层限流。
添加配置文件
server:
port: 30000
spring:
# 分布式限流的Redis连接
redis:
host: localhost
port: 6379
cloud:
nacos:
# Nacos配置项
discovery:
server-addr: localhost:8848
heart-beat-interval: 5000
heart-beat-timeout: 15000
cluster-name: Cluster-A
namespace: dev
group: myGroup
register-enabled: true
gateway:
discovery:
locator:
# 创建默认路由,以"/服务名称/接口地址"的格式规则进行转发
# Nacos服务名称本来就是小写,但Eureka默认大写
enabled: true
lower-case-service-id: true
# 跨域配置
globalcors:
cors-configurations:
'[/**]':
# 授信地址列表
allowed-origins:
- "http://localhost:10000"
- "https://www.geekbang.com"
# cookie, authorization认证信息
expose-headers: "*"
allowed-methods: "*"
allow-credentials: true
allowed-headers: "*"
# 浏览器缓存时间
max-age: 1000

定义路由规则
@Configuration
public class RoutesConfiguration {
@Bean
public RouteLocator declare(RouteLocatorBuilder builder) {
return builder.routes()
.route(route -> route
.path("/gateway/coupon-customer/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://coupon-customer-serv")
).route(route -> route
.order(1)
.path("/gateway/template/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://coupon-template-serv")
).route(route -> route
.path("/gateway/calculator/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://coupon-calculation-serv")
).build();
}
}
以第二个路由规则为例,使用path谓词约定了路由的匹配规则为path=“/template/**”。这里要注意的是,如果某一个请求匹配上了多个路由,但又想让各个路由之间有个先后匹配顺序,这时就可以使用order(n)方法设定路由优先级,n数字越小则优先级越高。
接下来,使用了一个stripPrefix过滤器,将path访问路径中的第一个前置子路径删除掉。这样一来,/gateway/template/xxx的访问请求经由过滤器处理后就变成了/template/xxx。同理,如果想去除path中打头的前两个路径,那就使用stripPrefix(2),参数里传入几它就能吞掉几个prefix path。
最后,使用uri方法指定了当前路由的目标转发地址,这里的“lb://coupon-template-serv”表示使用本地负载均衡将请求转发到名为“coupon-template-serv”的服务。
Filter和网关限流
对Request Header和Parameter进行删改,又或者从Response里面删除某个Header
.route(route -> route
.order(1)
.path("/gateway/template/**")
.filters(f -> f.stripPrefix(1)
// 修改Request参数
.removeRequestHeader("mylove")
.addRequestHeader("myLove", "u")
.removeRequestParameter("urLove")
.addRequestParameter("urLove", "me")
// response系列参数
.removeResponseHeader("responseHeader")
)
.uri("lb://coupon-template-serv")
网关限流
一个轻量级的网关层限流方案所采用的底层技术是Redis + Lua。
Lua是一类很小巧的脚本语言,它和Redis可以无缝集成,可以在Lua脚本中执行Redis的CRUD操作。在这个限流方案中,Redis用来保存限流计数,而限流规则定义在Lua脚本中,默认使用令牌桶限流算法。
在Gateway模块里新建了一个RedisLimitationConfig类,专门用来定义限流参数
@Configuration
public class RedisLimitationConfig {
// 限流的维度
@Bean
@Primary
public KeyResolver remoteHostLimitationKey() {
return exchange -> Mono.just(
exchange.getRequest()
.getRemoteAddress()
.getAddress()
.getHostAddress()
);
}
//template服务限流规则
@Bean("tempalteRateLimiter")
public RedisRateLimiter templateRateLimiter() {
return new RedisRateLimiter(10, 20);
}
// customer服务限流规则
@Bean("customerRateLimiter")
public RedisRateLimiter customerRateLimiter() {
return new RedisRateLimiter(20, 40);
}
@Bean("defaultRateLimiter")
@Primary
public RedisRateLimiter defaultRateLimiter() {
return new RedisRateLimiter(50, 100);
}
}
remoteHostLimitationKey这个方法中定义了一个以Remote Host Address为维度的限流规则,也可以改用某个请求参数或者用户ID为限流规则的统计维度。其它的三个方法定义了基于令牌桶算法的限流速率,RedisRateLimiter类接收两个int类型的参数,第一个参数表示每秒发放的令牌数量,第二个参数表示令牌桶的容量。通常来说一个请求会消耗一张令牌,如果一段时间内令牌产生量大于令牌消耗量,那么积累的令牌数量最多不会超过令牌桶的容量。
将限流规则应用到路由表中:
Gateway路由规则都定义在RoutesConfiguration类中,所以需要把定义的限流参数类注入到RoutesConfiguration类中。考虑到不同的路由表可能会使用不同的限流参数,所以在定义多个限流参数的时候,可以使用@Bean(“customerRateLimiter”)这种方式来做区分,然后在Autowired注入对象的时候,使用@Qualifier(“customerRateLimiter”)指定想要加载的限流参数就可以了。
@Autowired
private KeyResolver hostAddrKeyResolver;
@Autowired
@Qualifier("customerRateLimiter")
private RateLimiter customerRateLimiter;
@Autowired
@Qualifier("tempalteRateLimiter")
private RateLimiter templateRateLimiter;
限流参数注入完成之后,接下来只需要添加一个内置的限流过滤器,分别指定限流的维度、限流速率就可以了
.route(route -> route.path("/gateway/coupon-customer/**")
.filters(f -> f.stripPrefix(1)
.requestRateLimiter(limiter-> {
limiter.setKeyResolver(hostAddrKeyResolver);
limiter.setRateLimiter(customerRateLimiter);
// 限流失败后返回的HTTP status code
limiter.setStatusCode(HttpStatus.BANDWIDTH_LIMIT_EXCEEDED);
}
)
)
.uri("lb://coupon-customer-serv")
Gateway组件本身提供了丰富的内置谓词和过滤器,但在实际项目中大多用不到它们,因为网关层的核心用途只是简单的路由转发, 为了保证组件之间的职责隔离,并不建议通过谓词和过滤器实现带有业务属性的逻辑。
那什么样的逻辑可以在网关层实现呢?比如一些通用的身份鉴权、登录检测和签名验签之类的服务,可以将这类安全检测的逻辑前置到网关层来实现,这样可以对不合法请求做快速失败处理。
借助 Nacos 实现动态路由规则持久化
定义一个底层的网关路由规则编辑类,它的作用是将变化后的路由信息添加到网关上下文中。
@Slf4j
@Service
public class GatewayService {
@Autowired
private RouteDefinitionWriter routeDefinitionWriter;
@Autowired
private ApplicationEventPublisher publisher;
public void updateRoutes(List<RouteDefinition> routes) {
if (CollectionUtils.isEmpty(routes)) {
log.info("No routes found");
return;
}
routes.forEach(r -> {
try {
routeDefinitionWriter.save(Mono.just(r)).subscribe();
publisher.publishEvent(new RefreshRoutesEvent(this));
} catch (Exception e) {
log.error("cannot update route, id={}", r.getId());
}
});
}
}
这段代码接收了一个RouteDefinition List对象作为入参,它是Gateway网关组件用来封装路由规则的标准类,在里面包含了谓词、过滤器和metadata等一系列构造路由规则所需要的元素。在主体逻辑部分,调用了Gateway内置的路由编辑类RouteDefinitionWriter,将路由规则写入上下文,再调用ApplicationEventPublisher类发布一个路由刷新事件。
这里不使用@RefreshScope来获取Nacos动态参数,而使用了一种更为灵活的监听机制,通过注册一个“监听器”来获取Nacos Config的配置变化通知。这段逻辑封装在了DynamicRoutesListener类中
@Slf4j
@Component
public class DynamicRoutesListener implements Listener {
@Autowired
private GatewayService gatewayService;
@Override
public Executor getExecutor() {
log.info("getExecutor");
return null;
}
// 使用JSON转换,将plain text变为RouteDefinition
@Override
public void receiveConfigInfo(String configInfo) {
log.info("received routes changes {}", configInfo);
List<RouteDefinition> definitionList = JSON.parseArray(configInfo, RouteDefinition.class);
gatewayService.updateRoutes(definitionList);
}
}
DynamicRoutesListener实现了Listener接口,后者是Nacos Config提供的标准监听器接口,当被监听的Nacos配置文件发生变化的时候,框架会自动调用receiveConfigInfo方法执行自定义逻辑。在这段方法里,接收到的文本对象configInfo转换成了List类,并调用GatewayService完成路由表的更新。
需要注意的一点是,需要按照RouteDefinition的JSON格式来编写Nacos Config中的配置项,如果两者格式不匹配,那么这一步格式转换就会抛出异常。
加载Nacos路由配置项需要在两个场景下加载配置文件,一个是项目首次启动的时候,从Nacos读取文件用来初始化路由表;另一个场景是当Nacos的配置项发生变化的时候,动态获取配置项。定义一个叫做DynamicRoutesLoader的类,它实现了InitializingBean接口,后者是Spring框架提供的标准接口。它的作用是在当前类所有的属性加载完成后,执行一段定义在afterPropertiesSet方法中的自定义逻辑。
@Slf4j
@Configuration
public class DynamicRoutesLoader implements InitializingBean {
@Autowired
private NacosConfigManager configService;
@Autowired
private NacosConfigProperties configProps;
@Autowired
private DynamicRoutesListener dynamicRoutesListener;
private static final String ROUTES_CONFIG = "routes-config.json";
@Override
public void afterPropertiesSet() throws Exception {
// 首次加载配置
String routes = configService.getConfigService().getConfig(
ROUTES_CONFIG, configProps.getGroup(), 10000);
dynamicRoutesListener.receiveConfigInfo(routes);
// 注册监听器
configService.getConfigService().addListener(ROUTES_CONFIG,
configProps.getGroup(),
dynamicRoutesListener);
}
}
在afterPropertiesSet方法中执行了两项任务,第一项任务是调用Nacos提供的NacosConfigManager类加载指定的路由配置文件,配置文件名是routes-config.json;第二项任务是将前面定义的DynamicRoutesListener注册到routes-config.json文件的监听列表中,这样一来,每次这个文件发生变动,监听器都能够获取到通知。
往项目的bootstrap.yml文件中添加Nacos Config的配置项
spring:
application:
name: coupon-gateway
cloud:
nacos:
config:
server-addr: localhost:8848
file-extension: yml
namespace: dev
timeout: 5000
config-long-poll-timeout: 1000
config-retry-time: 100000
max-retry: 3
refresh-enabled: true
enable-remote-sync-config: true
完成了以上步骤之后,Gateway组件的改造任务就算搞定了
添加Nacos配置文件
在Nacos配置列表页中,需要在“dev”的命名空间下创建一个JSON格式的文件,文件名要和Gateway代码中的名称一致,叫做“routes-config.json”,它的Group是默认分组,也就是DEFAULT_GROUP
创建好之后,需要根据RoutesDefinition这个类的格式定义配置文件的内容
[{
"id": "customer-dynamic-router",
"order": 0,
"predicates": [{
"args": {
"pattern": "/dynamic-routes/**"
},
"name": "Path"
}],
"filters": [{
"name": "StripPrefix",
"args": {
"parts": 1
}
}
],
"uri": "lb://coupon-customer-serv"
}]
在这段配置文件中,指定当前路由的ID是customer-dynamic-router,并且优先级为0。除此之外,还定义了一段Path谓词作为路径匹配规则,还通过StripPrefix过滤器将Path中第一个前置路径删除。
删除某个路由:可以对Nacos配置项做一层额外封装,添加几个新字段用来表示“删除路由”这个语义,并创建一个自定义POJO类接收参数;还可以在路由的metadata里为Nacos的动态路由做一个特殊标记,每次当Nacos刷新路由表的时候,就删除上下文当中的所有Nacos路由表,再重新创建;又或者通过metadata做一个逻辑删除的标记,每次更新路由表的时候只要见到这个标记就删除当前路由,否则就更新或新建路由。
Stream
Stream依赖项添加到coupon-customer-impl项目的pom文件中。由于底层使用的中间件是RabbitMQ,所以引入的是stream-rabbit组件
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
添加生产者
使用StreamBridge这个Stream的原生组件,将信息发送给RabbitMQ。
@Service
@Slf4j
public class CouponProducer {
@Autowired
private StreamBridge streamBridge;
public void sendCoupon(RequestCoupon coupon) {
log.info("sent: {}", coupon);
streamBridge.send("addCoupon-out-0", coupon);
}
public void deleteCoupon(Long userId, Long couponId) {
log.info("sent delete coupon event: userId={}, couponId={}", userId, couponId);
streamBridge.send("deleteCoupon-out-0", userId + "," + couponId);
}
}
在这段代码里,streamBridge.send方法的第一个参数是Binding Name,它指定了这条消息要被发到哪一个信道中
添加消息消费者
在这段代码中,有一个“ 约定大于配置”的规矩一定要遵守,那就是不要乱起方法名。要确保消费者方法的名称和配置文件中所定义的Function Name以及Binding Name保持一致,这是function event的一条潜规则。因为在默认情况下,框架会使用消费者方法的method name作为当前消费者的标识,如果消费者标识和配置文件中的名称不一致,那么Spring应用就不知道该把当前的消费者绑定到哪一个Stream信道上去。
@Slf4j
@Service
public class CouponConsumer {
@Autowired
private CouponCustomerService customerService;
@Bean
public Consumer<RequestCoupon> addCoupon() {
return request -> {
log.info("received: {}", request);
customerService.requestCoupon(request);
};
}
@Bean
public Consumer<String> deleteCoupon() {
return request -> {
log.info("received: {}", request);
List<Long> params = Arrays.stream(request.split(","))
.map(Long::valueOf)
.collect(Collectors.toList());
customerService.deleteCoupon(params.get(0), params.get(1));
};
}
}
添加配置文件
Stream的配置项比较多,分Binder和Binding两部分。
Binder中配置了对接外部消息中间件所需要的连接信息。如果程序中只使用了单一的中间件,比如只接入了RabbitMQ,那么可以直接在spring.rabbitmq节点下配置连接串,不需要特别指定binders配置。
如果在Stream中需要同时对接多个不同类型,或多个同类型但地址端口各不相同的消息中间件,那么可以把这些中间件的信息配置在spring.cloud.stream.binders节点下。其中type属性指定了当前消息中间件的类型,而environment则指定了连接信息。
spring:
cloud:
stream:
# 如果项目里只对接一个中间件,那么不用定义binders
# 当系统要定义多个不同消息中间件的时候,使用binders定义
binders:
my-rabbit:
type: rabbit # 消息中间件类型
environment: # 连接信息
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
spring.cloud.stream.bindings节点保存了生产者、消费者、binder和RabbitMQ四方的关联关系
spring:
cloud:
stream:
bindings:
# 添加coupon - Producer
addCoupon-out-0:
destination: request-coupon-topic
content-type: application/json
binder: my-rabbit
# 添加coupon - Consumer
addCoupon-in-0:
destination: request-coupon-topic
content-type: application/json
# 消费组,同一个组内只能被消费一次
group: add-coupon-group
binder: my-rabbit
# 删除coupon - Producer
deleteCoupon-out-0:
destination: delete-coupon-topic
content-type: text/plain
binder: my-rabbit
# 删除coupon - Consumer
deleteCoupon-in-0:
destination: delete-coupon-topic
content-type: text/plain
group: delete-coupon-group
binder: my-rabbit
function:
definition: addCoupon;deleteCoupon
以addCoupon为例,定义了addCoupon-out-0和addCoupon-in-0这两个节点,节点名称中的out代表当前配置的是一个生产者,而in则代表这是一个消费者,这便是spring-function中约定的命名关系:
Input信道(消费者):< functionName > - in - < index >;
Output信道(生产者):< functionName > - out - < index >;
命名规则的最后还有一个index,它是input和output的序列,如果同一个function name只有一个output和一个input,那么这个index永远都是0。而如果需要为一个function添加多个input和output,就需要使用index变量来区分每个生产者消费者了。官方社区文档。
信道和RabbitMQ里定义的消息队列之间的关系:
信道和RabbitMQ的绑定关系是通过binder属性指定的。如果当前配置文件的上下文中只有一个消息中间件(比如使用默认的MQ),并不需要声明binder属性。但如果配置了多个binder,那就需要为每个信道声明对应的binder是谁。addCoupon-out-0对应的binder名称是my-rabbit,这个binder就是在spring.cloud.stream.binders里声明的配置。通过这种方式,生产者消费者信道到消息中间件(binder)的联系就建立起来了。
信道和消息队列的关系是通过destination属性指定的。以addCoupon为例,在addCoupon-out-0生产者配置项中指定了destination=request-coupon-topic,意思是将消息发送到名为request-coupon-topic的Topic中。又在addCoupon-in-0消费者里添加了同样的配置,意思是让当前消费者从request-coupon-topic消费新的消息。
spring.cloud.stream.function:
如果项目中存在多个消费者,使用spring.cloud.stream.function或者spring.cloud.function把所有消费者的function name写出来。
如果项目中只有一组消费者,那么完全不用搭理这个配置项,只要确保消费者代码中的method name和bindings下声明的消费者信道名称相对应就好了;如果项目中有多组消费者(比如声明了addCoupon和deleteCoupon两个消费者),在这种情况下,需要将消费者所对应的function name添加到spring.cloud.function或者spring.cloud.stream.function,否则消费者无法被绑定到正确的信道。
Seata
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。

在分布式事务的执行过程中,各个微服务都要向Seata汇报自己的分支事务状态,亦或是接收来自Seata的Commit/Rollback决议,Seata Server把自己作为了一个微服务注册到了Nacos,各个微服务利用Nacos的服务发现能力获取到Seata Server的地址。如此一来,微服务到Seata Server的通信链路就构建起来了。
搭建Seata服务器
Seata Github地址 Release页面 下载
更改持久化配置
打开Seata安装目录下的conf文件夹,找到file.conf.example文件,把里面的内容复制一下并且Copy到file.conf里。
第一个改动点是 持久化模式。Seata支持本地文件和数据库两种持久化模式,前者只能用在本地开发阶段,因为基于本地文件的持久化方案并不具备高可用能力。这里需要把store节点下的mode属性改成“db”。
## transaction log store, only used in server side
store {
## store mode: file、db
## 【改动点01】 - 替换成db类型
mode = "db"
第二个改动点就是 DB的连接方式。需要把本地的connection配置到store节点下的db节点里
store {
mode = "db"
## 【改动点02】 - 更改参数
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
## if using mysql to store the data, recommend add rewriteBatchedStatements=true in jdbc connection param
url = "jdbc:mysql://127.0.0.1:3306/seata?rewriteBatchedStatements=true"
user = "root"
password = ""
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
}
}
创建数据库表
创建global_table、branch_table和lock_table三张表,这是Seata Server用来保存全局事务、分支事务还有事务锁定状态的表,Seata正是用这三个Table来记录分布式事务执行状态,并控制最终一致性的。
每个微服务背后的数据库(创建在微服务项目自个儿的数据库)创建一个特殊的表,叫做undo_log,在Seata的AT模式下,Seata Server发起一个Rollback指令后,微服务作为Client端要负责执行一段Rollback脚本,这个脚本所要执行的回滚逻辑就保存在undo_log中。
开启服务发现
打开Seata安装目录下的conf/registry.conf文件,找到registry节点,这就是用来配置服务注册的地方。
registry {
# 【改动点01】 - type变成nacos
type = "nacos"
# 【改动点02】 - 更换
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "myGroup"
namespace = "dev"
cluster = "default"
username = ""
password = ""
}
}
接下来,还需要修改registry.nacos里的内容

AT模式
Seata框架的三个重要角色,TC、TM和RM。
TC全称是Transaction Coordinator,TC扮演了一个中心化的事务协调者的角色,负责协调全局事务的提交和回滚,并维护全局事务和分支事务的状态。
TM全称是Transaction Manager,它是事务管理器,主要作用是发起一个全局事务,对全局事务的提交和回滚做出决议。在AT方案中,TM通常是由发起全局事务的那个微服务所扮演的。
RM全称是Resource Manager,它是资源管理器,向TC注册分支事务并上报事务状态,同时负责对当前分支事务进行提交和回滚。每一个分支事务都是全局事务的参与者,这些分支事务的所属应用扮演了RM的角色。

Seata AT的业务流程分为两个阶段来执行。
- 一阶段: 执行核心业务逻辑(即代码中的CRUD操作)。Seata会根据DB操作自动生成相应的回滚日志,并将回滚日志添加到RM对应的undo_log表中。执行业务代码和添加回滚日志这两步都是在同一个本地事务中提交的。
- 二阶段: 如果全局事务的最终决议是Commit,则更新分支事务状态并清空回滚日志;如果最终决议是Rollback,则根据undo_log中的回滚日志进行rollback操作。二阶段是以异步化的方式来执行的。
Seata AT方案的核心在于这个undo_log。正是有了这个记录回滚日志的undo_log表,才能将一阶段和二阶段剥离成两个独立的本地事务来执行。而Seata AT之所以执行效率高,主要原因有两个。一是核心业务逻辑可以在一阶段得到快速提交,DB资源被快速释放;二是全局事务的Commit和Rollback是异步执行。
分布式事务的起点,扮演了一个TM的角色,它会向TC注册并发起一个全局事务。全局事务会生成一个XID,它是全局唯一的ID标识,所有分支事务都会和这个XID进行绑定。XID在服务内部(非跨服务调用)的传播机制是基于ThreadLocal构建的,即XID在当前线程的上下文中进行透传,对于跨服务调用来说,则依赖seata-all组件内置的各个适配器(如Interceptor和Filter)将XID传递给对象服务。
被调用服务的RM开启了一个分支事务,并注册到TC。在执行分支事务的过程中,RM还会生成回滚日志并提交到undo_log表中。除此之外,RM还需要获取到两个特殊的Lock。其中一个是Local Lock(本地锁),另一个是Global Lock(全局锁)。
Lock信息存放在lock_table这张表里,它会记录待修改的资源ID以及它的全局事务和分支事务ID等信息。无论是一阶段提交还是二阶段回滚,RM都需要获取待修改记录的本地锁,然后才会去执行CRUD操作。而在RM提交一阶段事务之前,它还会尝试获取Global Lock(全局锁),目的是防止多个分布式事务对同一条记录进行修改。假设有两个不同的分布式事务想要修改记录A,那么只有同时获取到Local Lock和Global Lock的事务才能正常提交一阶段事务。
本地锁会随一阶段事务的提交/回滚而释放,而全局锁只有等到全局事务提交/回滚之后才会被释放。在一阶段中,如果某一个事务在一定的尝试次数后仍然无法获取全局锁,它会知难而退,执行本地事务回滚操作。而如果在二阶段回滚的时候,RM无法获取本地锁,它会原地打转不停重试,直到成功获取本地锁并完成重试。
接下来,服务调用成功,起点服务开始执行自己的本地事务,流程都大同小异。TM端根据业务的执行情况,最终做出二阶段决议,Commit或Rollback。
最后,TC向各个分支下达了二阶段决议。如果最终决议是Commit,那么各个RM会执行一段异步操作,删除undo_log;如果最终决议是Rollback,那么RM端会根据undo_log中记录的回滚日志做反向补偿。
添加依赖项
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
声明数据源代理
Seata AT之所以能够实现无感知的编程体验,其中的一个秘诀就在这个数据源代理上了
在分布式事务的场景上,为了能够在分支事务开启/提交等关键节点上做一番手脚(比如向Seata注册分支事务、生成undo_log等),需要用Seata特有的数据源“接管”项目原有的数据源。
创建一个SeataConfiguration的类,用来声明一个Seata特有的数据源,作为当前项目的DataSrouce代理。
@Configuration
public class SeataConfiguration {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Bean("dataSource")
@Primary
public DataSource dataSourceDelegation(DruidDataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
}
在上面的代码中,先是创建了一个DruidDataSource作为数据源连接池,并指定其读取spring.datasoource下的数据库连接信息。
在dataSourceDelegation方法中,声明了一个DataSourceProxy的类,并接收DruidDataSource作为构造器初始化参数。DataSourceProxy是由Seata框架提供的一个数据源代理类,为了确保Spring上下文使用DataSourceProxy而不是其它三方数据源,在dataSourceDelegation方法上添加了@Primary注解,将其作为javax.sql.DataSource的默认代理类。
添加Seata配置项
spring:
cloud:
alibaba:
seata:
tx-service-group: seata-server-group
seata:
application-id: coupon-customer-serv
registry:
type: nacos
nacos:
application: seata-server
server-addr: localhost:8848
namespace: dev
group: myGroup
cluster: default
service:
vgroup-mapping:
seata-server-group: default
spring.cloud.alibaba.seata.tx-service-group中的分组名称一定要和seata.service.vgroup-mapping中定义的分组名称一致,seata-server-group分组所指定的值是default,这个值会被用来获取Seata Server地址。
在项目启动的时候,Seata框架会尝试从Nacos获取Seata Server的地址信息,执行这个操作的类是NacosRegistryServiceImpl。在这个类的lookup方法中,Seata使用了下面这行代码查找seata-server服务,其中clusters参数的值就来自于seata.service.vgroup-mapping.seata-server-group所对应的值。
List<Instance> firstAllInstances = getNamingInstance()
.getAllInstances(getServiceName(), getServiceGroup(), clusters);
实现AT
@GlobalTransactional,它是Seata用来开启分布式事务的顶层注解。=只要在全局事务“开始”的地方把这个注解添加上去就好了,并不需要在每个分支事务中都声明它。全局事务碰到任何Exception异常,都会触发全局事务回滚操作,这个行为是通过GlobalTransactional注解的rollbackFor方法指定的。
@GlobalTransactional(name = "coupon-customer-serv", rollbackFor = Exception.class)
在开启Seata分布式事务的时候,必须把异常抛出到全局事务的发起方,让@GlobalTransactional注解的方法能够感知到这个异常,才能顺利触发事务的回滚。如果开发了统一的异常处理拦截器,记得千万不要把异常吞掉。
TCC 补偿模式
TCC事务模型
TCC名字里这三个字母分别是三个单词的首字母缩写,从前到后分别是Try、Confirm和Cancel,这三个单词分别对应了TCC模式的三个执行阶段,每一个阶段都是独立的本地事务。

Try阶段完成的工作是 预定操作资源(Prepare), 说白了就是“占座”的意思,在正式开始执行业务逻辑之前,先把要操作的资源占上座。
Confirm阶段完成的工作是 执行主要业务逻辑(Commit),它类似于事务的Commit操作。在这个阶段中,可以对Try阶段锁定的资源进行各种CRUD操作。如果Confirm阶段被成功执行,就宣告当前分支事务提交成功。
Cancel阶段的工作是 事务回滚(Rollback), 它类似于事务的Rollback操作。在这个阶段中,没有AT方案的undo_log帮做自动回滚,需要通过业务代码,对Confirm阶段执行的操作进行人工回滚。
实现TCC
注册TCC接口
@LocalTCC
public interface CouponTemplateServiceTCC extends CouponTemplateService {
@TwoPhaseBusinessAction(
name = "deleteTemplateTCC",
commitMethod = "deleteTemplateCommit",
rollbackMethod = "deleteTemplateCancel"
)
void deleteTemplateTCC(@BusinessActionContextParameter(paramName = "id") Long id);
void deleteTemplateCommit(BusinessActionContext context);
void deleteTemplateCancel(BusinessActionContext context);
}
@LocalTCC注解被用来修饰实现了二阶段提交的本地TCC接口,而@TwoPhaseBusinessAction注解标识当前方法使用TCC模式管理事务提交。
Try阶段所要执行的方法,便是被@TwoPhaseBusinessAction所修饰的deleteTemplateTCC方法了。
在deleteTemplateCommit和deleteTemplateCancel这两个方法中使用了一个特殊的入参BusinessActionContext,可以使用它传递查询参数。在TCC模式下,查询参数将作为BusinessActionContext的一部分,在事务上下文中进行传递。
编写一阶段Prepare逻辑
@Transactional
在一阶段Prepare的过程中,执行的是Try逻辑。对数据库做一个小修改,引入一个名为locked的变量,用来标记当前资源是否被锁定。
资源不存在的话,在Try阶段就会抛出异常,TCC会转而执行Rollback方法,进不到Commit阶段。
编写二阶段Commit逻辑
@Transactional
二阶段Commit就是TCC中的Confirm阶段,只要TCC框架执行到了Commit逻辑,那么就代表各个分支事务已经成功执行了Try逻辑。但是别忘了还要将Try阶段的资源锁定解除掉。
编写二阶段Rollback逻辑
@Transactional
二阶段Rollback对应的是TCC中的Cancel阶段,如果在Try或者Confirm阶段发生了异常,就会触发TCC全局事务回滚,Seata Server会将Rollback指令发送给每一个分支事务。
TCC空回滚
所谓空回滚,是在没有执行Try方法的情况下,TC下发了回滚指令并执行了Cancel逻辑。
比如某个分支事务的一阶段Try方法因为网络不可用发生了Timeout异常,或者Try阶段执行失败,这时候TM端会判定全局事务回滚,TC端向各个分支事务发送Cancel指令,这就产生了一次空回滚。
处理空回滚的正确的做法是,在Cancel阶段,应当先判断一阶段Try有没有执行成功。先是判断资源是否已经被锁定,再执行释放操作。如果资源未被锁定或者压根不存在,可以认为Try阶段没有执行成功,这时在Cancel阶段直接返回成功即可。
更为完善的一种做法是,引入独立的事务控制表,在Try阶段中将XID和分支事务ID落表保存,如果Cancel阶段查不到事务控制记录,那么就说明Try阶段未被执行。同理,Cancel阶段执行成功后,也可以在事务控制表中记录回滚状态,这样做是为了防止另一个TCC的坑,“倒悬”。
TCC倒悬
倒悬又被叫做“悬挂”,它是指TCC三个阶段没有按照先后顺序执行。拿刚讲过的空回滚的例子来说,如果Try方法因为网络问题卡在了网关层,导致锁定资源超时,这时Cancel阶段执行了一次空回滚,到目前为止一切正常。但回滚之后,原先超时的Try方法经过网关层的重试,又被后台服务接收到了,这就产生了一次倒悬场景,即一阶段Try在二阶段回滚之后被触发。
在倒悬的情况下,整个事务已经被全局回滚,那么如果再执行一次Try操作,当前资源将被长期锁定,这就造成了一种类似死锁的局面。