一、数据查询
1、简单查询
日常查询中,最常用的是通过FROM子句实现的查询
语法格式
使用方法:
SELECT [ ,... ] FROM table_reference [ ,... ]
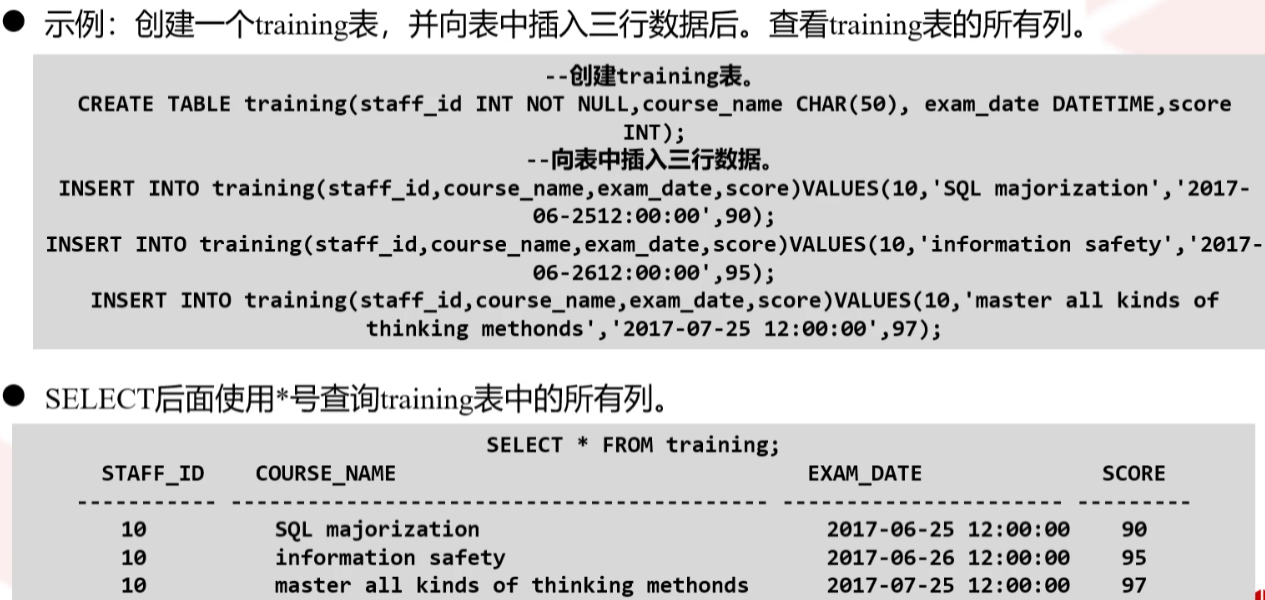
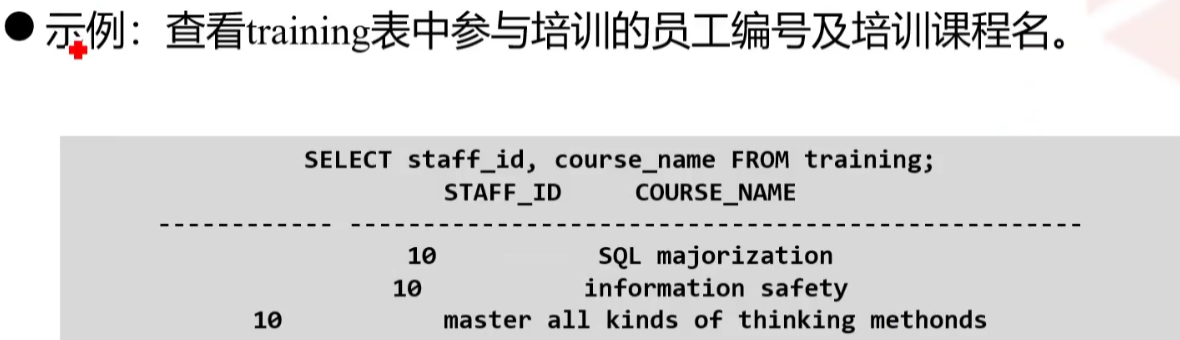
SELECT关键字之后和FROM子句之前出现的表达式称为SELECT项,SELECT项用于指定要查询的列,FROM指定要从哪个表中查询
如果要查询所有列,可以在SELECT后面使用*号,如果只查询特定的列,可以直接在SELECT后面指定列名,列名之间用逗号隔开
2、去除重复值
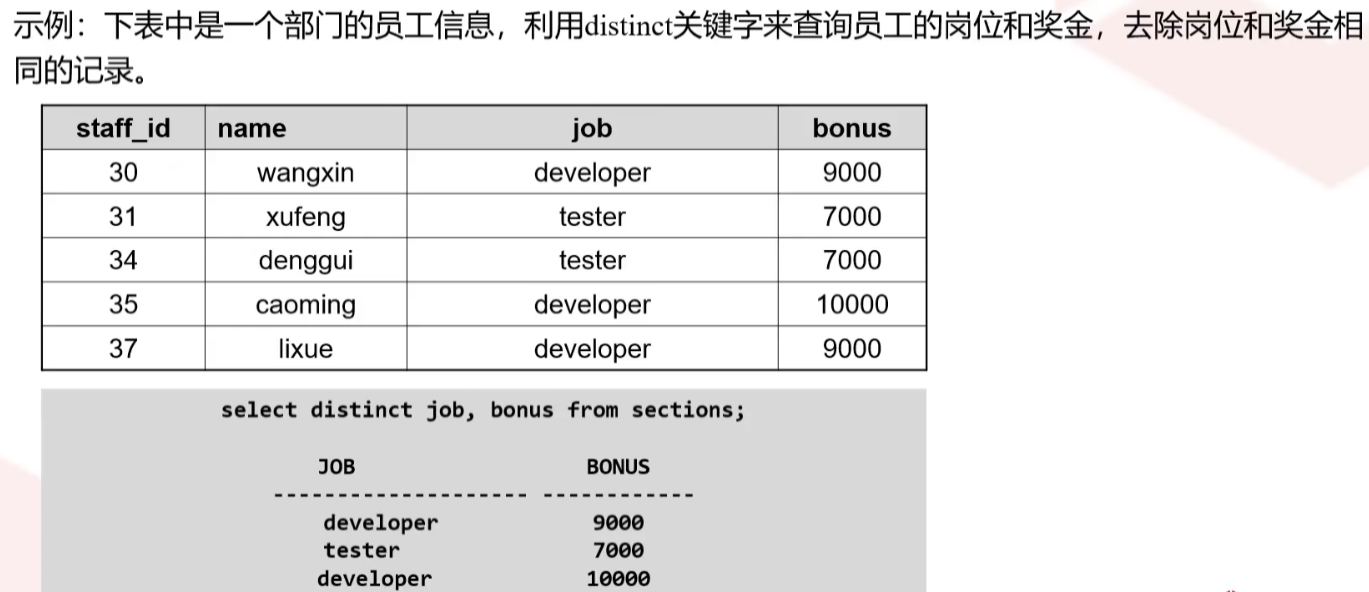
DISTINCT关键字
从SELECT的结果集中删除所有重复的行,使结果集中的每行都是唯一的,取值范围:已存在的字段名,或字段表达式
语法格式
SELECT DISTINCT [ ,... ] FROM table_reference [ ,... ]
如果在distinct关键字后只有一个列,则使用该列来计算重复,如果有两列或者多列,则将使用这些列的组合来进行重复检查
3、查询列的选择
在选择查询列时,列名可以用下面几种形式表达
手动输入列名,多个列之间用英文符号(,)分隔
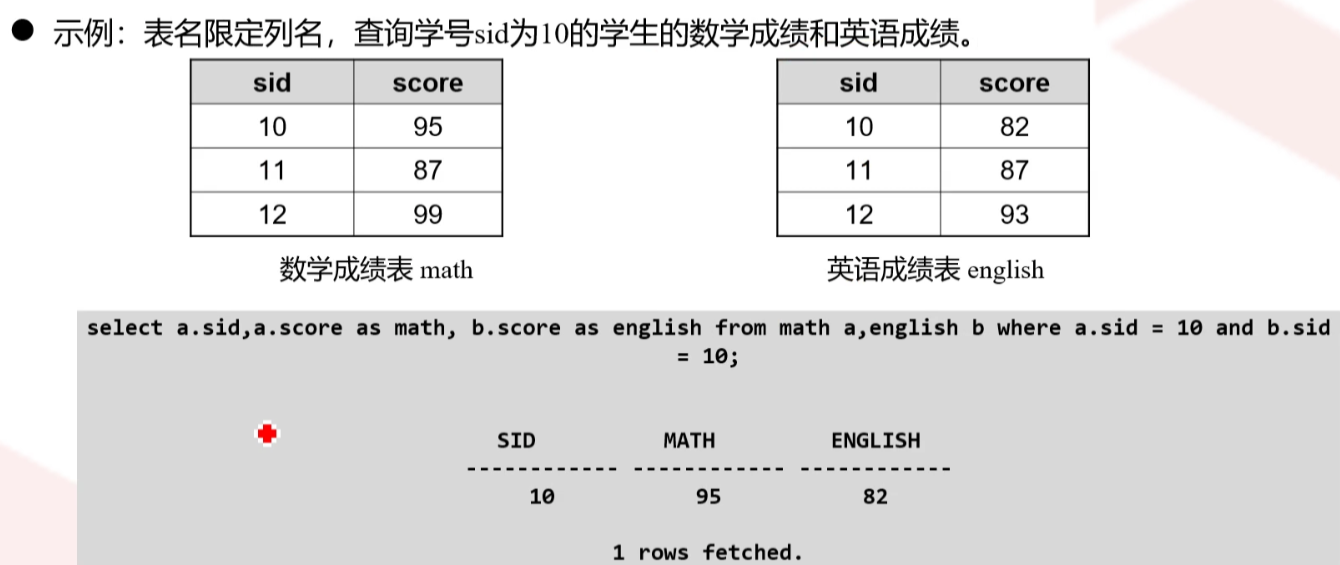
SELECT a,b,f1,f2 FROM t1,t2;
其中,列a、b是表t1中的列,f1、f2是t2中的列
可以是计算出来的字段
SELECT a+b FROM t1;
如果某两个或某几个表正好有一些共同的列名,推荐使用表名限定列名
不限定列名可以得到查询结果,但使用完全限定的表和列名称,可以减少数据库内部的处理工作量,从而提升查询的返回性能,例如
SELECT t1.f1,t2.f1 FROM t1,t2;
4、条件查询
在SELECT语句中,可以通过设置条件以达到更精确的查询,条件由表达式和操作符共同指定,且条件返回的值是TRUE,FALSE或UNKNOWN
查询条件可以应用于WHERE子句,HAVING子句
语法格式
condition子句
select_statement { predicate } [ { AND | OR } condition ] [ ,...n ]

条件查询由表达式和操作符共同定义,常用的条件定义方式如下
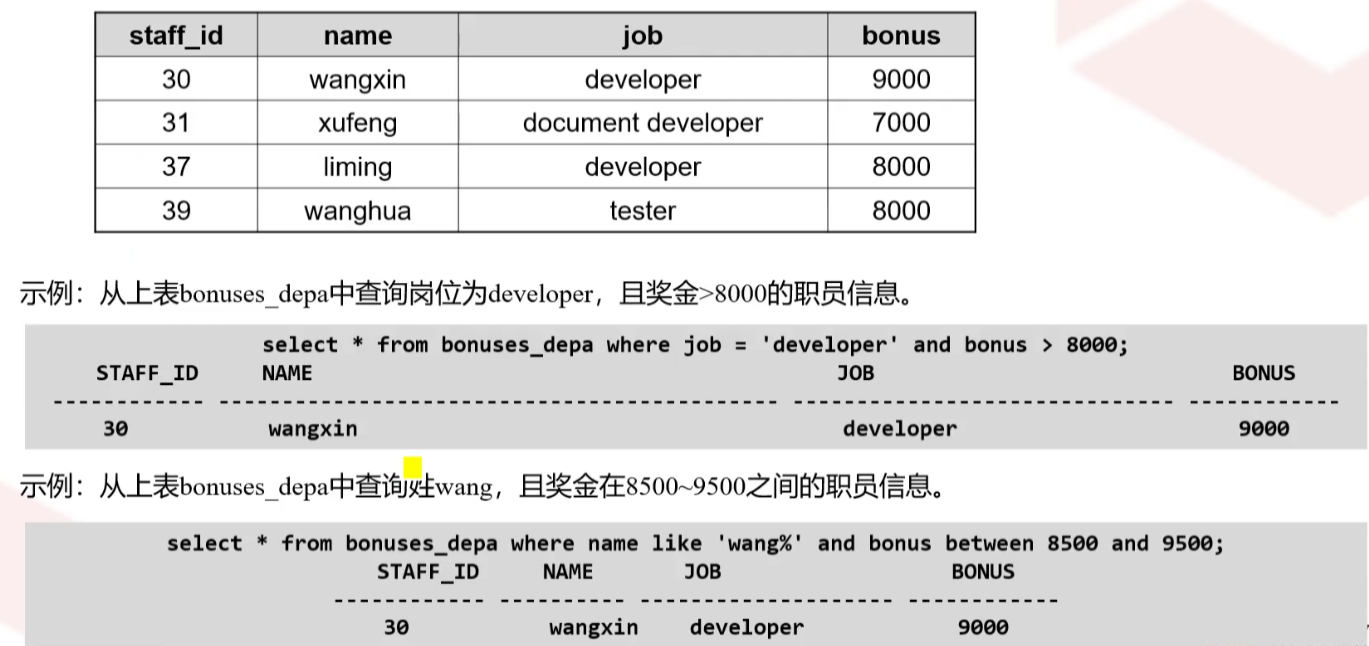
1、比较操作符">,<,>=,<=,!=,<>,="指定的比较查询条件,当查询条件中和数字比较,可以使用单引号引起,也可以不用,
当和字符及日期类型的数据比较,则必须用单引号引起
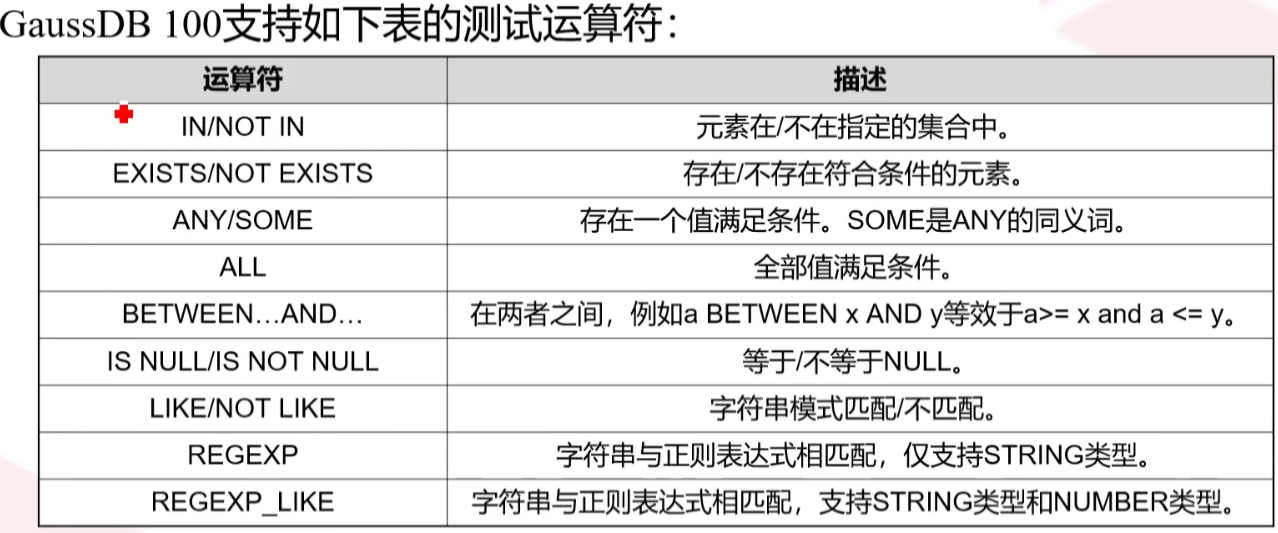
2、测试运算符指定的范围查询条件,如果希望返回的结果必须满足多个条件,可以使用AND逻辑操作符连接这些条件
如果希望返回的结果满足多个条件之一即可,可以使用OR逻辑操作符连接这些条件

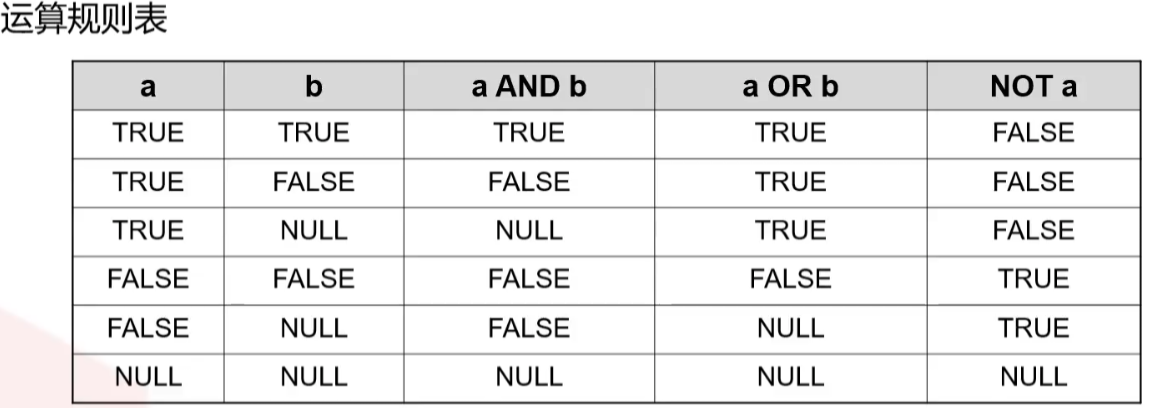
逻辑操作符
常用的逻辑操作符有AND、OR和NOT,他们的运算结果有三个值,分别为TRUE、FALSE和NULL,其中NULL代表未知
他们运算优先级顺序为:NOT>AND>OR
5、join连接查询
实际应用中所需要的数据,经常会需要查询两个或两个以上的表,这种查询两个或两个以上数据表或视图的查询叫做连接查询
连接查询通常建立在存在相互关系的父子表之间




外连接
内连接所指定的两个数据源处于平等的地位,而外连接不同,外连接以一个数据源为基础,将另外一个数据源与之进行条件匹配
内连接返回两个表中所有满足连接条件的数据记录,外连接不仅返回满足连接条件的记录,还将返回不满足连接条件的记录
外连接又分为左外连接、右外连接和全外连接
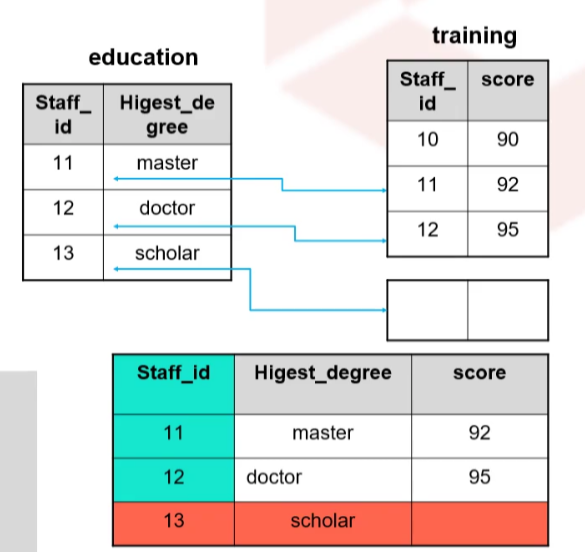
左外连接
又称左连接,如图所示,是指以左边的表为基础表进行查询
根据指定连接条件关联右表,获取基础表以及和条件匹配的右表数据,未匹配条件的右表对应的字段位置填上NULL

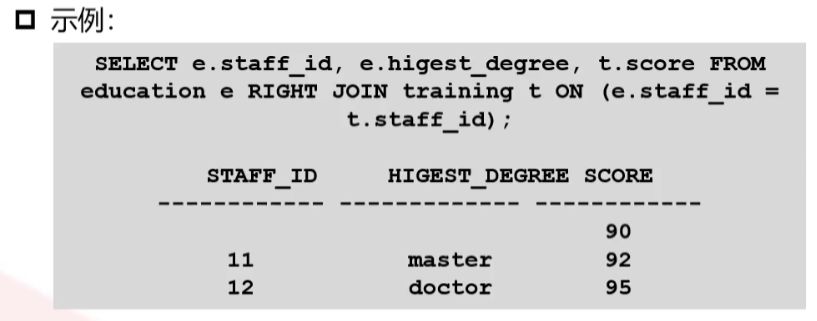
右外连接
又称右连接,是指以右边的表为基础表,在内连接的基础上也查询右边表中有记录,而左边的表中没有记录的数据(左边用NULL值填充)
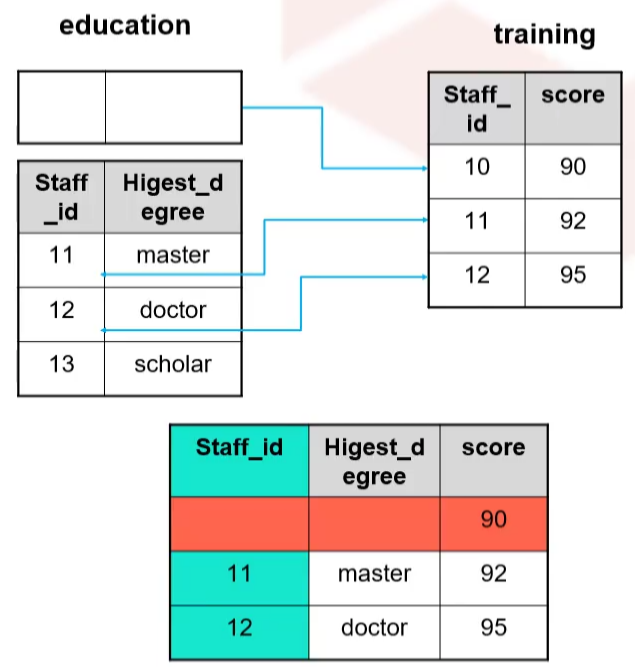
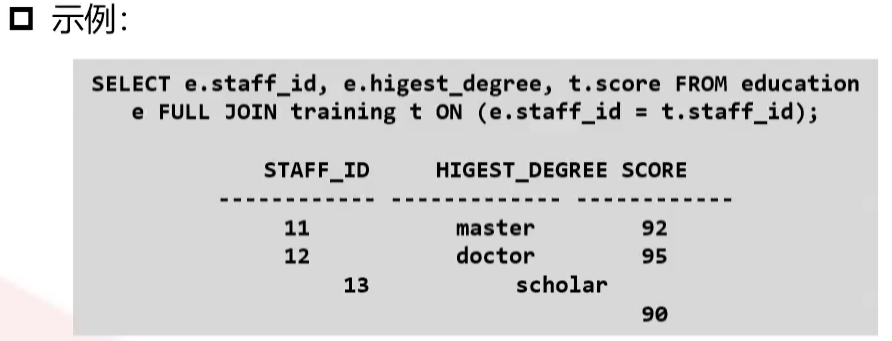
全外连接
又称全连接,是指除了返回两个表中满足连接条件的记录,还会返回两个表中不满足连接条件的所有其他行(不匹配的另外一边用NULL值填充)
6、子查询
子查询是指在查询、建表或插入语句的内部嵌入查询,以获得临时结果集
子查询可以分为相关子查询和非相关子查询
子查询的语法格式与普通查询相同
使用方法
子查询可以出现在FROM子句、WHERE子句、以及WITH AS子句中,
FROM子句中的子查询也称为内联视图
WHERE子句中的子查询也称为嵌套子查询

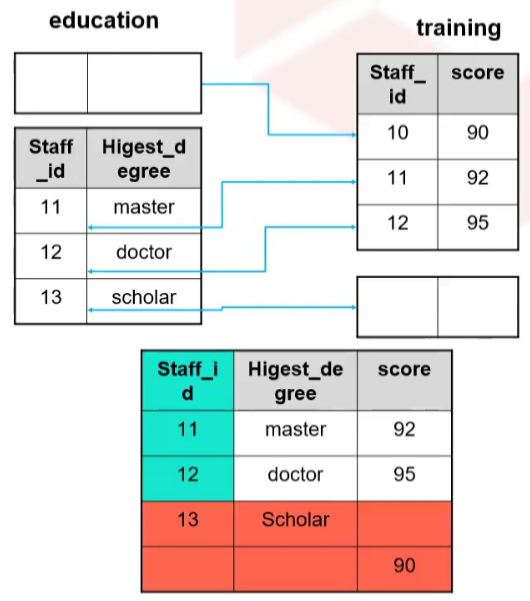
对于staffs表的每一行,父查询使用相关子查询来计算同一部门成员的平均工资,相关子查询为staffs表的每一行执行以下步骤
确定行的section_id
然后使用section_id来评估父查询
如果此行中工资大于所在部门的平均工资,则返回改行
对于staffs表中的每一行,子查询都将被计算一次
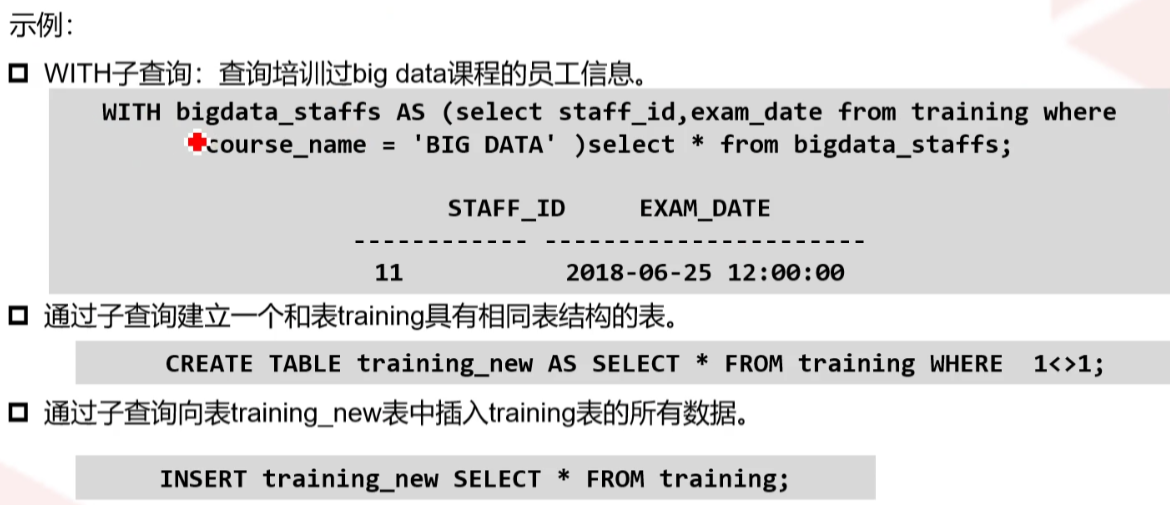
WITH AS子句
定义一个SQL片段,该SQL片段会被整个SQL语句用到
语法格式
WITH { table_name AS select statement1 }[ ,... ] select_statement2
table_name
用户自定义的存储SQL片段的表的名称
select statement1
从基本表中查询数据的SELECT语句
select_statement2
从用户自定义的存储SQL片段的表中查询数据的SELECT语句
7、合并结果集
除子查询外,还可以使用集合运算符处理多个查询的结果集,输出最终结果
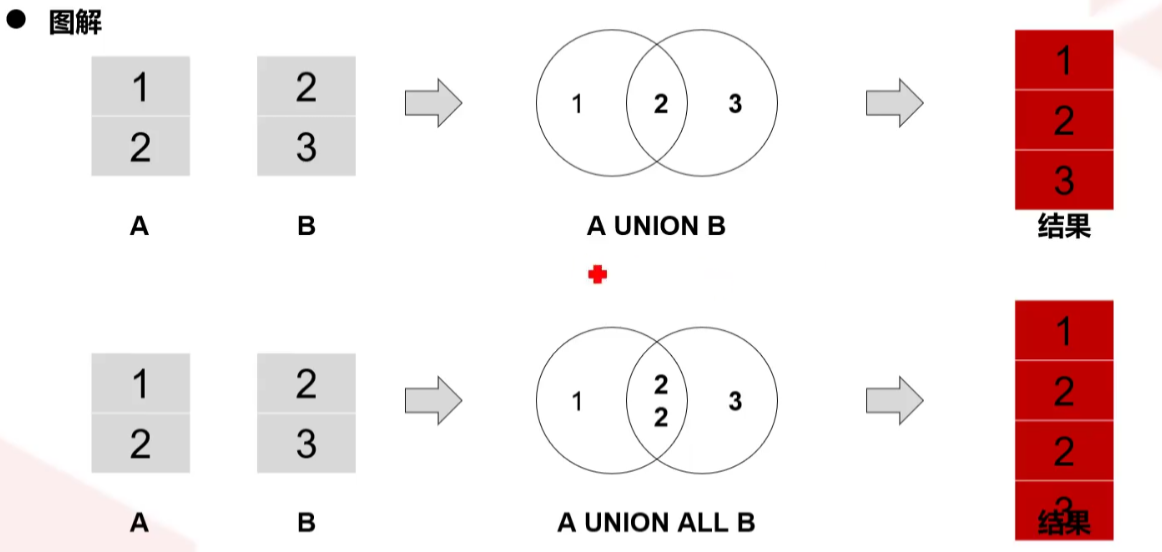
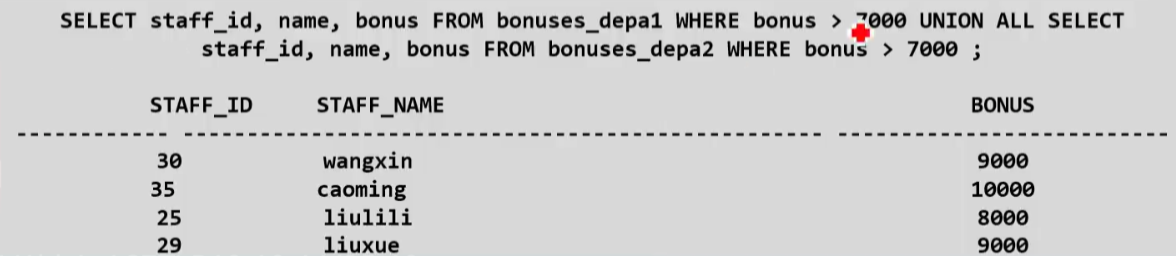
Union运算符:将多个查询块的结果集合并为一个结果集输出
select_statement UNION [ALL] select_subquery
使用方法
每个查询块的查询列数目必须相同
每个查询块对应的查询列必须为相同数据类型或同一数据类型组
关键字ALL的意思是保持所有重复数据,而没有ALL的结果下表示删除所有重复数据
8、差异结果集
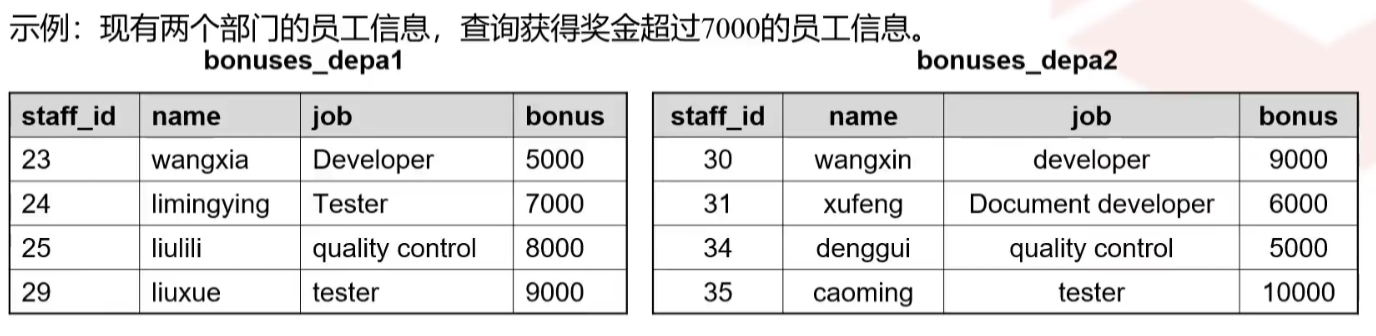
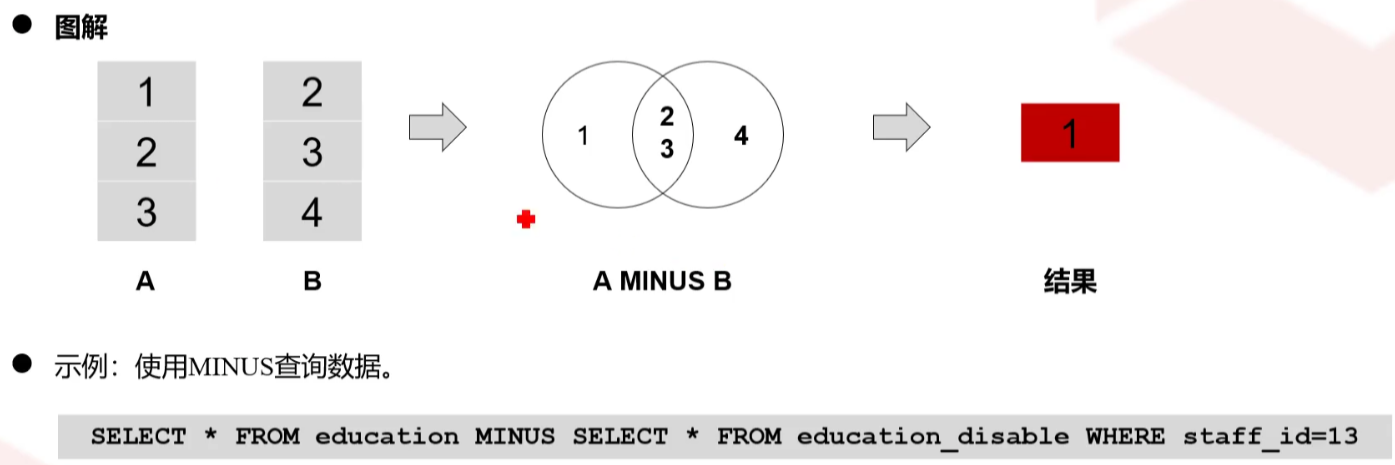
MINUS/EXCEPT运算符
对查询结果集的减法,计算存在于左边查询语句的输出、而不存在于右边查询语句输出的结果
A minus B C就意味着将结果集A去除结果集B和结果集C中所包含的所有记录后的结果,即在A中存在,而在B、C中不存在的记录
语法格式
select_statement1 MINUS/EXCEPT select_statement2 [ ... ]
select_statement1
产生第一个结果集的SELECT语句
select_statement2
产生第二个结果集的SELECT语句
9、数据分组
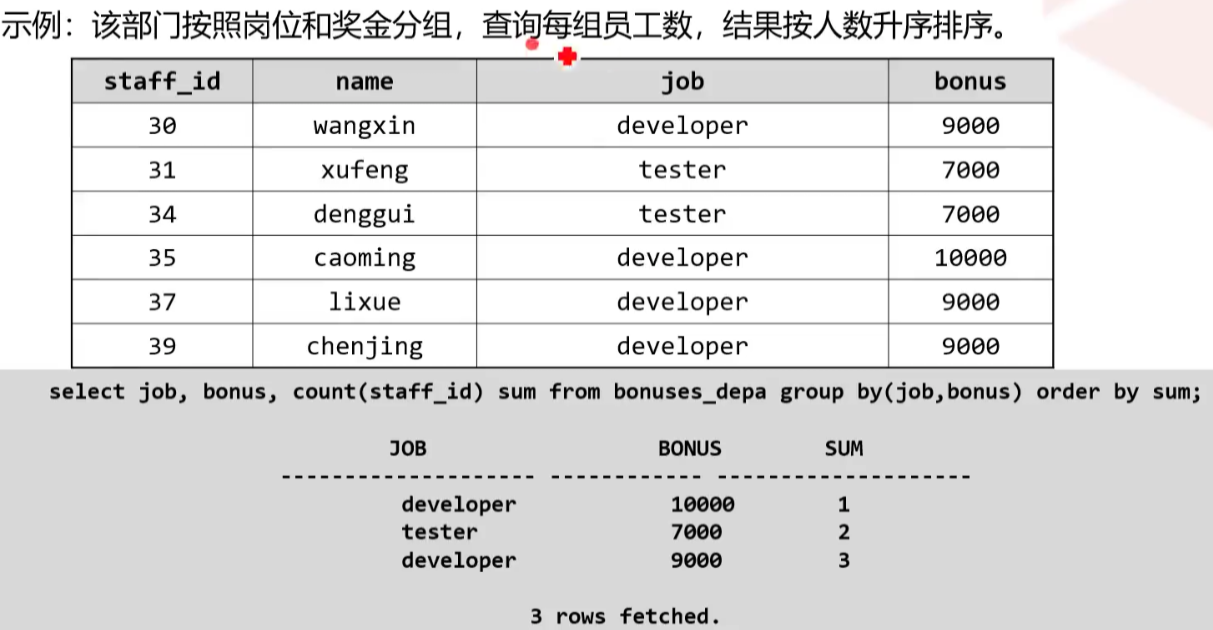
数据库查询中,分组是一个非常重要的应用,分组是指将数据表中的记录以某个或者某些列为标准,值相等的划分为一组
语法格式
GROUP BY { column_name } [ ,... ]
使用方法
GROUP BY子句中的表达式可以包含FROM子句中表,视图的任何列,无论这些列是否出现在SELECT列表中
GROUP BY子句对行进行分组,但不保证结果集的顺序,要对分组进行排序,请使用ORDER BY子句
GROUP BY后的表达式可以使用括号,如: group by (expr1,expr2),或者group by (expr1),(expr2),但不支持group by (expr1,expr2),expr3格式
HAVING子句
与GROUP BY子句配合用来选择特殊的组,HAVING子句将组的一些属性与一个常数值比较,只有满足HAVING子句中条件的组才会被提取出来

10、数据排序
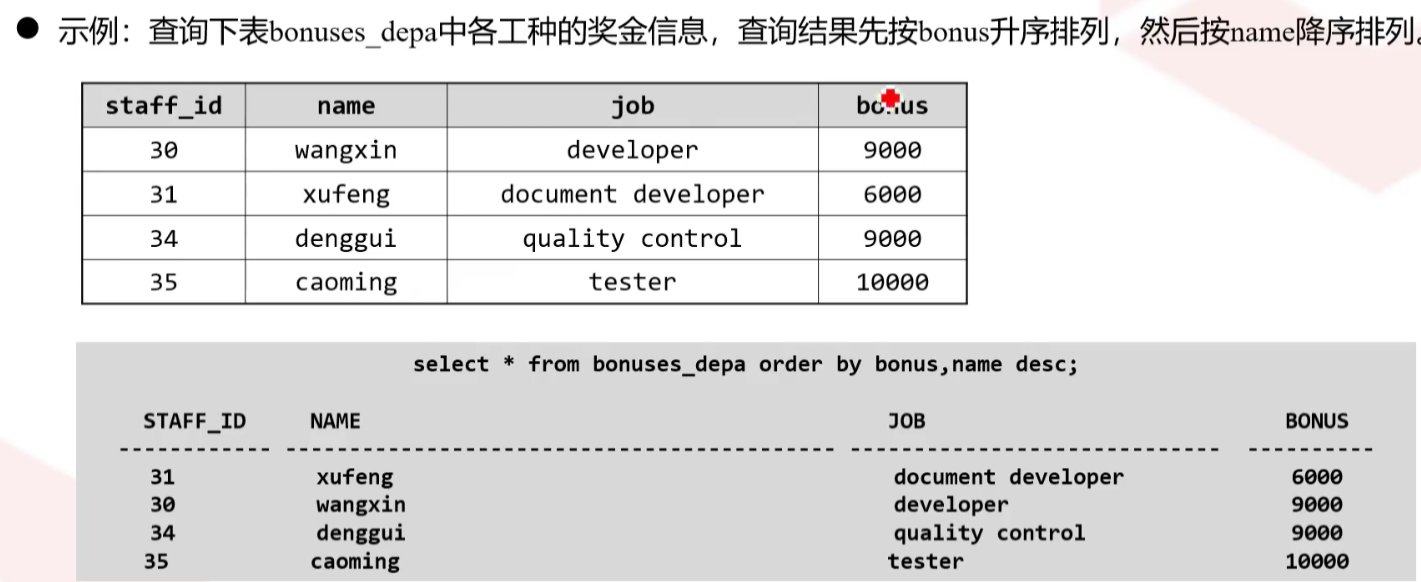
ORDER BY子句
使用ORDER BY子句对查询语句返回的行根据指定的列进行排序,如果没有ORDER BY子句,则多次执行的同一查询将不一定以相同的顺序进行行的检索
语法格式
ORDER BY { column_name | number | expression } [ ASC | DESC ][ NULLS FIRST | NULLS LAST ] [ ,... ]
使用方法
ORDER BY语句默认按照升序对记录进行排序,如果希望按照降序对记录进行排序,请使用DESC关键字
NULLS FIRST | NULLS LAST关键字指定ORDER BY列中NULL值的排序位置
FIRST表示将NULL值排在最前面,LAST表示将NULL值排在最后面,若不指定该选项,ASC默认为NULLS LAST,DESC默认为NULLS FIRST
column_name|number|expression
order By后面可跟列名、数字、表达式
跟数字:order by 1表示根据查询选择列中第一个字段排序
跟表达式:order by (column1+column2) 表示根据column1与column2的和的大小来排序
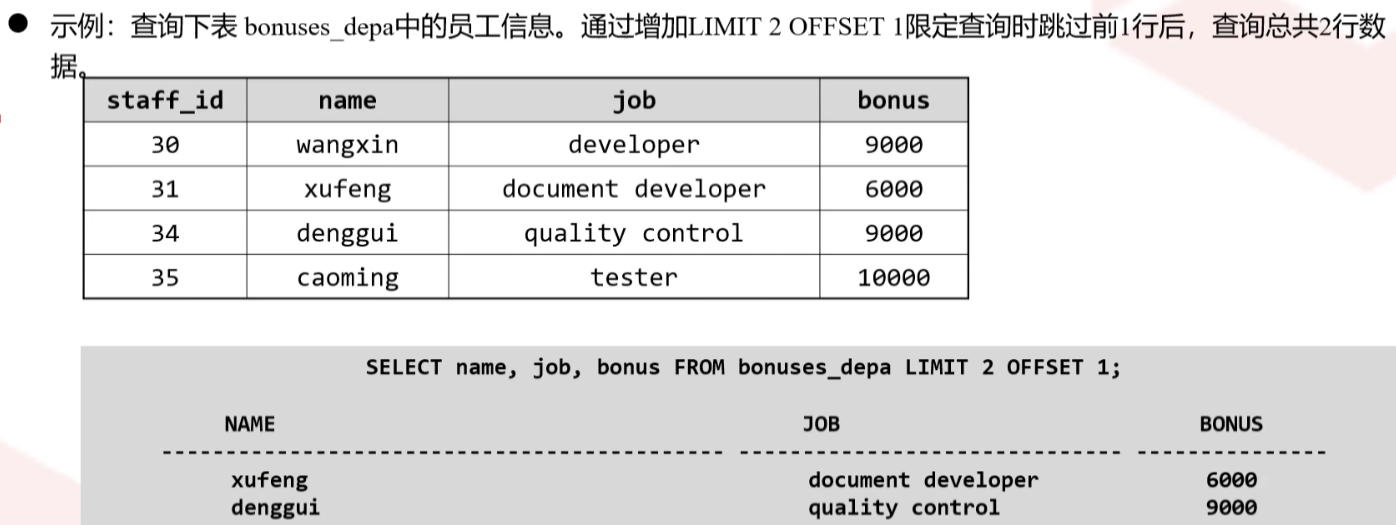
11、数据限制
数据限制功能包括两个独立的子句,LIMIT子句和OFFSET子句
LIMIT子句允许限制查询返回的行,可以指定偏移量,以及要返回的行数或者百分比
可以使用此子句实现top-N报表。要获得一致的结果,请指定ORDER BY子句以确保确定性排序顺序
LIMIT { count | ALL }
OFFSET子句设置开始返回的位置
OFFSET START
使用方法
start:指定在返回行之前要跳过的行数
count:指定要返回的最大行数
start和count都被指定时,在开始计算要返回的count行之前会跳过start行
LIMIT 5,20与LIMIT 20 OFFSET 5及OFFSET 5 LIMIT 20等效
LIMIT 5,20与LIMIT 20 OFFSET 5及OFFSET 5 LIMIT 20均表示跳过5行后输出20行记录