
Mysql在建表之初就要考虑到他的存储量和性能问题,所以一般Mysql数据库建议单表最大两千万,但是为啥是两千万呢这里我们解释一下,知其然还要知其所以然!
这一块的知识解释起来会涉及一点存储引型的相关知识了这里给提供一个基本概念,但是了解完之后会对InnonDB引型会有一定的了解
- 数据页相关知识
首先我们存储在数据库中的行数据被分成了很多份放在“数据页”中,每个“数据页”大小为16k。
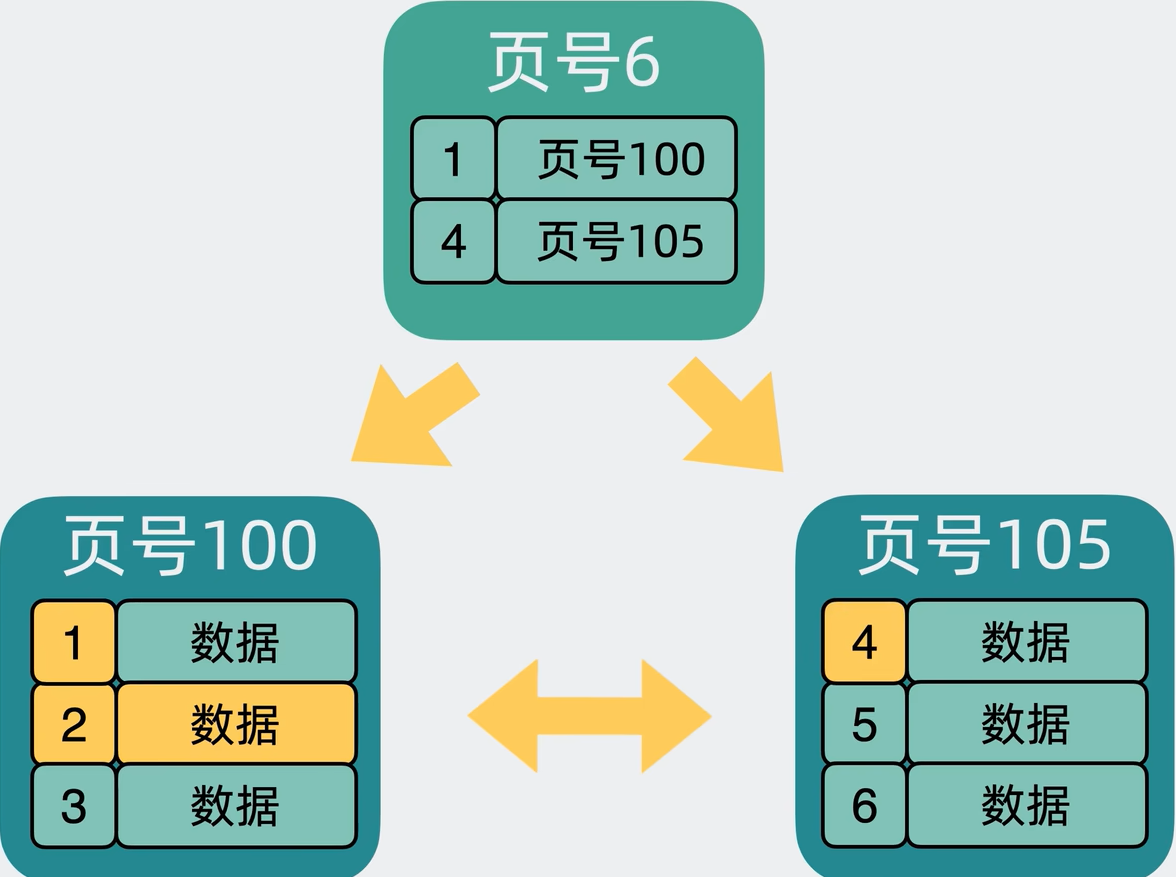
1、数据页为了进行唯一标识在每个数据页中表头会有“页号”。
2、为了将“数据页”前后关联起来于是在“数据页”的表头中引入了前后指针,用于指向前后的数据页。
3、为了避免“数据页”在被编写过程中出现异常情况(如断电),保证数据的正确性所以在“数据页”的页尾增加了“校验码”。
4、剩下的空间才是用来放行数据的,但如果行数据特别多,查询时需要逐行遍历页内的数据效率会很低,所以为了这些行数据生成了一个“页目录”。

现在我们设想一下
如果我们想查询一条行数据我们要把表空间的每一页都捞出来,然后挨个判断里面的行数据是不是我们要找的。
在这个场景下数据多了,行数变得很大那么性能就会变低,因为每次查找都要遍历所有的行数据。
没办法为了加速、为了效率,上述的方法肯定是不行滴!
为了加速搜索:所以精通设计的我们在每个数据页里选出主键ID最小的行数据,只需要他们的主键ID以及所在页的页号并将它们组建成新的行数据放入新的数据页中。
这个新的数据页和之前的页结构基本一致而且大小也是16k。为了跟之前的数据页进行区分,新数据页中加入页层级的信息,就有了上下层级的概念(其实就是B+树的概念版)
最后那么绕了这么一堆 2000w的说法到底从何而来呢!
同样一个B+树页的最末子节点放了行数据,而非末子节点里只放了为了加速查询的索引数据,用来指向其他数据页。
设:指向指向其他数据页的指针数为X,子节点里能容纳的行数据数量为y,层数为z

再假设:非页子节点中掐头去尾(页头、页尾、页目录)数据页的大小大约15k用来放索引数据。
继续假设:因为每条索引数据主要由主键和指向页号构成。主键bigint的大小是8byte,页号是4byte。那么非叶子节点的一行数据大约12byte左右。
然后15k除以12byte等于1280行 得出指针数x=1280
设:因为页子节点和非页子节点的数据结构是一样的,所以掐头去尾剩15k。
再设:因为页子节点放的是真正的行数据,假设一条行数据是1k,那么一个“数据页”大约能放15条行数据
得出:y=15
又因为:总行数=x的z-1次方乘y
最后假设:
B+是两层:z=2那么数据表的总行数据就是2w
B+是两层:z=3那么数据表的总行数据就是2.5kw
2.5Kw就是我们单表建议最大行数的由来。
最后补充一下,上数的假设是单行数据是1k来设计的,如果单行数据用的很少,那么单个数据页是可以远超过15条数据的。那么最后的单表支持也会远超2.5kw条数据