
G-A3C的代码:
https://gitee.com/devilmaycry812839668/gpu_a3c
论文:
《Reinforcement Learning thorugh Asynchronous Advantage Actor-Critic on a GPU》
论文地址:
https://openreview.net/forum?id=r1VGvBcxl
=====================================================
G-A3C,原意是GPU版本的A3C,但是仔细读过后发现这个GPU版本的算法好像和CPU版本的并不相同。
其中最大的区别就是网络反传时副本是不是由多个进程持有;在A3C中,多个进程中均持有一份可以前后向传播的神经网络,也就是说在多个进程中都可以使用自有的神经网络进行前向推理来进行数据采样,同时也能使用后向计算来进行神经网络的训练;也就是说,在A3C中数据采样和训练用的是同一套神经网络的参数,因此在A3C中的并行算法的异步参数更新和监督学习的并行化异步更新更相似,因此在A3C中虽然使用异步更新的方式,虽然对收敛性造成影响但是也不至于完全发散。
G-A3C中,所有的采样进程并不持有神经网络,全局只有一个神经网络在GPU中,所以不论是神经网络的前向推理还是后向训练都是使用这个神经网络,但是由于异步更新的特点,所以各进程采样的数据时所用的神经网络参数和训练时的神经网络参数时存在一定滞后性的,因此就导致G-A3C中训练神经网络时使用的数据往往对收敛性造成更大的影响,这也implicit的将同策略强化学习算法变成了异策略的强化学习算法;在之前的blog中也讨论过类似的问题,那就是同策略的强化学习算法如果按照异策略强化学习算法那样使用的数据和训练时神经网络有一定滞后性,这样虽然会极大的影响收敛,并且严重时导致不收敛,但是在很多情况下(很多的game环境下)也是可以保证收敛的。
总的来说,A3C算法采集数据和训练数据使用的是同一套神经网络参数,虽然在参数更新时使用异步方式,但是该方式更类似于监督学习中的异步更新方式,虽然也会对算法收敛性造成影响但是要远远低于G-A3C;在G-A3C中,由于数据采样时的神经网络参数与训练时的神经网络参数存在一定的滞后性,而这种滞后性是一种概率分布上的不同,因此这种对收敛性的影响往往要高于A3C算法。
在G-A3C中,为了抑制滞后性造成的对收敛性的影响,使用了一种概率下限的方式,也就是说对于采样后的数据在训练时其概率值是设置了一个下限值的,如果某个采样数据的动作在训练时低于该值那么就应该使其至少不低于该值;在具体实现时,则是在运行时对采样动作的log概率加入一个极小项,也就是log(p+epsilon),即:
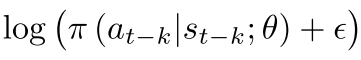
---------------------------------------------------
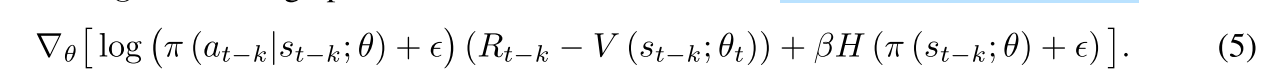
--------------------------------------------------------------

PS:
可以说在AC类算法中都是可以使用这个概率下限的操作的,这个可以作为一个trick来使用,这样可以抑制发散,对收敛性起到好的作用。
=====================================================

