
1、标准先行,注重生态
Prometheus 最重要的规范就是指标命名方式,数据格式简单易读。比如,对于应用层面的监控,可以要求必须具备这几个信息。
- 指标名称 metric
Prometheus 内置建立的规范就是叫 metric(即 __name__)。如果是 Counter 类型,单调递增的值,指标名称以 _total 结尾。
- 服务名称 service
服务名称 service 要全局唯一,比如 n9e-webapi,p8s-alertmanager,一般是系统名称加上模块名称,组成最终的服务名称。
- 实例名称 instance
一个服务一般会部署多个实例,可以直接使用机器名或 Pod 名作为 instance 名称。如果在物理机部署,有实例混部的情况,就要把端口加上,比如实例一是 10.1.2.3:3306,实例二是 10.1.2.3:3307。
- 服务类型 job
比如所有的 MySQL 的监控数据,都统一打上 job=mysql 的标签,Redis 的监控数据,就打上 job=redis 的标签。如果是自研的模块,也可以使用 webserver backend frontend 这种分类方式。
- 地域可用区 zone
把地域信息放到标签里,有个巨大的好处,比如某个 zone 出问题了,就比较容易看出来,带有某个特定的 zone 的指标数据异常,快速执行切流止损即可。有了 zone 的信息,region 就可有可无了,zone 的前缀一般就是 region。
- 集群名称 cluster
有的时候一个可用区会部署多个集群,特别是一些中间件,比如 ElasticSearch,给每个重要的业务单独部署一个集群,一个大公司可能有几百套 ElasticSearch 集群,几千套 ZooKeeper 集群。
- 环境类型 env
环境类型 env 用来标识是生产环境还是测试环境。当然了,如果监控系统不复用(推荐这么做),生产用生产的监控系统,测试用测试的监控系统,就无需这个标签了。
2、主要使用拉模式
Prometheus 主要使用拉模式获取指标,辅以推模式(Pushgateway 的职能)。很多监控系统都是推模式,比如 Datadog、Open-Falcon、Telegraf+InfluxDB 组合。
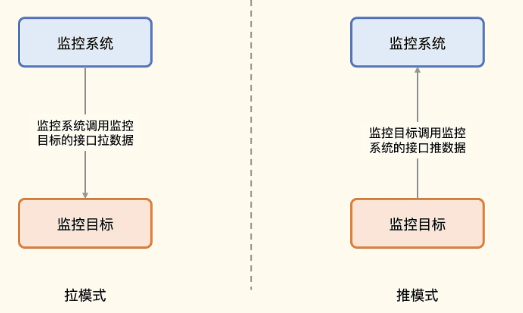
拉模式有个最重要的优势,就是解耦。Prometheus 支持各种服务发现机制,尤其是基于 Kubernetes 的服务发现机制,是最常见的。如果服务没有部署在 Kubernetes 中,而是部署在传统物理机或虚拟机上,这个时候就需要使用 Consul 之类的服务发现机制。
中间件类使用拉模式,自研的服务使用推模式,自研的服务如果都接入了注册中心,则也可以使用拉模式。
3、监控目标动态发现机制
云原生之后,基础设施动态化,监控目标的创建、销毁都比较频繁,就需要有一个更自动化的机制来获取监控目标列表。
Prometheus 内置了多种服务发现机制,最常见的有四种。
- 基于配置文件的发现机制:这种方式看起来很低端,其实非常常用,因为可以配合配置管理工具一起使用,非常方便。使用配置管理工具批量更新配置,然后让监控系统重新加载一下就可以了,比较丝滑。
- 基于 Kubernetes 的发现机制:Kubernetes 中有很多元信息,通过调用 kube-apiserver,可以轻易拿到 Pod、Node、Endpoint 等列表,Prometheus 内置支持了 Kubernetes 的服务发现机制,让这个过程变得更简单,Prometheus 基本成为了 Kubernetes 监控的标配。
- 基于公有云 API 的发现机制:比如要监控公有云上所有的 RDS 服务,一条一条配置比较麻烦,这个时候就可以基于公有云的 OpenAPI 做一个服务发现机制,自动拉取相关账号下所有 RDS 实例列表,大幅降低管理成本。
- 基于注册中心的发现机制:社区里最为常用的是 Consul,典型场景是 PING 监控和 HTTP 监控,把所有目标注册到 Consul 中,然后读取 Consul 生成监控对象列表即可。
4、基于配置文件的管理方式
Prometheus 的告警规则管理、记录规则管理、抓取配置管理与发送策略管理,全部是基于配置文件的,这虽然不是一个关键设计,但确实是一个非常有特色的设计。
这个方式有两个好处,一个是简单,简单到令人发指,很多监控系统都是使用数据库来存储各类配置的,Prometheus 则直接使用 Yaml 文件,非常直观。第二个好处就是便于自动化,配合配置管理工具、Git、Kubernetes 等,与 Infrastructure as Code 的管理风潮非常契合。
可以把各个 Prometheus 中的核心关键指标抽取到一个统一的地方来呈现,比如使用 Prometheus 联邦机制,只共享核心指标,其余指标不需要抽取到中心,自己团队消化就好。
5、灵活的查询语言
PromQL(Prometheus Query Language)是 Prometheus 的查询语言,非常灵活。这也是 Prometheus 的一个关键设计。
采集侧是无法穷举所有计算场景的,采集侧应该采集原始数据,后续的二次计算还是应该放到中心来搞定。
PromQL 为二次计算提供了能力支持,多个指标的关联计算、多条件联合告警,都可以用 PromQL 来实现,作为现代监控系统,Query Language 已经是必备要求了。