一 前言
2020年由于受到新冠疫情的影响,我国互联网医疗企业迎来了“爆发元年”,越来越多居民在家隔离期间不方便去医院看诊,只好采取在线诊疗的手段,互联网医疗企业的迅速发展的同时,也暴露出更多的不足,互联网医疗作为医疗行业发展的趋势,对于解决中国医疗资源分配不平衡和人们日益增长的医疗健康需求之间的矛盾具有诸多意义。但对于能否切实解决居民就诊的问题,以及企业能否实现持续发展等是国家以及企业十分关注的问题。而我司在这条道路上沉淀多年,一直致力于互联网医疗服务,拥有自己完善医疗产品平台以及技术体系
二、项目简介
2.1 建设目标
第三方客户业务环境均是IDC自建机房环境,提供虚拟化服务器资源,计划引入Kubernetes技术,满足互联网医疗需求。
2.2 技术现状
据悉,第三方客户已有的架构体系已不满足日益增长的业务量,缺少一个完整且灵活的技术架构体系。
2.3 平台架构图
线上平面逻辑架构图参考
 上图便是我们项目生产企业架构图,从逻辑上分为四大版块
上图便是我们项目生产企业架构图,从逻辑上分为四大版块
DevOps CI/CD平台
关于CI/CD自动化开源工具相信大家都了解不少,就我个人而言,我所熟知的就有Jenkins、GitLab、Spug、以及我接下来将会为大家介绍的KubeSphere。它同样也能完成企业级CICD持续交付事宜。
Kubernetes集群
因业务需要,这里将测试、生产两套环境独立开,避免相互影响,对于生产集群而言。如上图所示是三个Matsre节点,五个Node节点,这里Master节点标注污点使其Pod不可调度,避免主节点负载过高等情况发生。另外测试环境集群规模相对较小,Master节点数量相同,但Node节点仅只有两个作为使用,因仅做为测试,问题不大。
底层存储环境
这里的存储环境我们并未采用容器化的方式进行部署,而是以传统的方式部署,这样做也是为了高效,在互联网业务中,存储服务都有一定的性能要求来应对高并发场景。因此需要将其部署在裸机服务器上是最佳的选择。MySQL、Redis、NFS均做了高可用,避免了单点问题,NFS在这里是作为KubeSphere StorageClass存储类。关于StorageClass存储类选型还有很多,比如ceph、openebs等等,它们都是KubeSphere 能接入的开源底层存储类解决方案。尤其是ceph,得到了很多互联网大厂的青睐,此时你们可能会问我,为什么选择NFS而不选择ceph,我只能说,在工具类选型中,只有最合适的,没有最好的,适合你的业务类型你就选择什么,而不是人云亦云,哪个工具热度高而去选择哪个工具。
分布式监控平台
一个完整的互联网应用平台自然是少不了监控告警平台了,在过去几年,我们所熟知的Nagios、Zabbix、Cacti这几款都是老牌监控了,现如今都渐渐退出历史的舞台。如今Prometheus脱颖而出,深受各大互联网企业青睐,结合Grafana,不得不说是真的香。在该架构体系中,我也是毫不犹豫的选择了它,在这里就不要跟大家细说了。
三、背景介绍
客户现有平台环境缺少完整的技术架构体系,业务版本更新迭代困难,无论是业务还是技术平台都出现较为严重的瓶颈问题,不足以支撑现有的业务体系,为了避免导致用户流失。需要重新制定完整的架构体系。而如今,互联网技术不断更新迭代,随着Kubernetes日益盛行,云原生技术KubeSphere也孕育而生。一个技术的兴起必定会能带动整个技术生态圈的发展,我相信,KubeSphere的出现,能带给我们远不止你想象的价值和便捷
四、选型说明
Kubernetes集群建设完毕之后,随后便面临一个问题,就是我们内部研发人员如何去管理维护它,需求新增要求版本迭代,研发人员如何去进行发版上线自己的业务代码。出现问题如何更好的去分析定位处理等等一系列问题都需要考虑,难不成让他们登陆到服务器上通过命令行敲?这不现实吧,因此为了解决上面的问题,我们需要在引入一个Dashboard管理平台,
选择KubeSphere原由
KubeSphere 为企业用户提供高性能可伸缩的容器应用管理服务,旨在帮助企业完成新一代互联网技术驱动下的数字化转型,加速应用的快速迭代与业务交付,以满足企业日益增长的业务需求。我所看重的KubeSphere四大主要优势
多集群统一管理
随着容器应用的日渐普及,各个企业跨云或在本地环境中部署多个集群,而集群管理的复杂程度也在不断增加。为满足用户统一管理多个异构集群的需求,KubeSphere 配备了全新的多集群管理功能,帮助用户跨区、跨云等多个环境管理、监控、导入和运维多个集群,全面提升用户体验。 多集群功能可在安装 KubeSphere 之前或之后启用。具体来说,该功能有两大特性:
- 统一管理 用户可以使用直接连接或间接连接导入 Kubernetes 集群。只需简单配置,即可在数分钟内在 KubeSphere 的互动式 Web 控制台上完成整个流程。集群导入后,用户可以通过统一的中央控制平面监控集群状态、运维集群资源。
- 高可用 在多集群架构中,一个集群可以运行主要服务,另一集群作为备用集群。一旦该主集群宕机,备用集群可以迅速接管相关服务。此外,当集群跨区域部署时,为最大限度地减少延迟,请求可以发送至距离最近的集群,由此实现跨区跨集群的高可用。
强大的可观测性功能
KubeSphere 的可观测性功能在 v3.0 中全面升级,进一步优化与改善了其中的重要组件,包括监控日志、审计事件以及告警通知。用户可以借助 KubeSphere 强大的监控系统查看平台中的各类数据,该系统主要的优势包括:
- 自定义配置: 用户可以为应用自定义监控面板,有多种模板和图表模式可供选择。用户可按需添加想要监控的指标,甚至选择指标在图表上所显示的颜色。此外,也可自定义告警策略与规则,包括告警间隔、次数和阈值等。
- 全维度数据监控与查询:KubeSphere 提供全维度的资源监控数据,将运维团队从繁杂的数据记录工作中彻底解放,同时配备了高效的通知系统,支持多种通知渠道。基于 KubeSphere 的多租户管理体系,不同租户可以在控制台上查询对应的监控日志与审计事件,支持关键词过滤、模糊匹配和精确匹配。
- 图形化交互式界面设计:KubeSphere 为用户提供图形化 Web 控制台,便于从不同维度监控各个资源。资源的监控数据会显示在交互式图表上,详细记录集群中的资源用量情况。不同级别的资源可以根据用量进行排序,方便用户对数据进行对比与分析。
- 高精度秒级监控: 整个监控系统提供秒级监控数据,帮助用户快速定位组件异常。此外,所有审计事件均会准确记录在 KubeSphere 中,便于后续数据分析。
自动化 DevOps CI/CD流程机制
自动化是落地 DevOps 的重要组成部分,自动、精简的流水线为用户通过 CI/CD 流程交付应用提供了良好的条件,集成 Jenkins:KubeSphere DevOps 系统内置了 Jenkins 作为引擎,支持多种第三方插件。此外,Jenkins 为扩展开发提供了良好的环境,DevOps 团队的整个工作流程可以在统一的平台上无缝对接,包括开发测试、构建部署、监控日志和通知等。KubeSphere 的帐户可以用登录内置的 Jenkins,满足企业对于 CI/CD 流水线和统一认证多租户隔离的需求,便捷的内置工具:无需对 Docker 或 Kubernetes 的底层运作原理有深刻的了解,用户即可快速上手自动化工具,包括 Binary-to-Image 和 Source-to-Image。只需定义镜像仓库地址,上传二进制文件(例如 JAR/WAR/Binary),即可将对应的服务自动发布至 Kubernetes,无需编写 Dockerfile。
细粒度权限控制
KubeSphere 为用户提供不同级别的权限控制,包括集群、企业空间和项目。拥有特定角色的用户可以操作对应的资源。 自定义角色:除了系统内置的角色外,KubeSphere 还支持自定义角色,用户可以给角色分配不同的权限以执行不同的操作,以满足企业对不同租户具体工作分配的要求,即可以定义每个租户所应该负责的部分,不被无关资源所影响。安全性方面由于不同级别的租户之间完全隔离,他们在共享部分资源的同时也不会相互影响。租户之间的网络也完全隔离,确保数据安全。
五、实践过程
基础设施建设与规划
底层集群环境准备就绪之后,我们就需要考虑(CI/CD)持续集成交付的问题,为了保证最后生产服务容器化顺利部署至Kubernetes以及后期更加稳定可控,于是乎我采用了一下战略性方案:
- 第一步:IDC虚拟化平台测试/生产环境同步部署,在现有的两套服务器资源中以二进制的方式部署
Kubernetes集群 - 第二步:然后基于
Kubernetes集群分别以最小化方式部署KubeSphere云原生管理平台,其目的就是为了实现两套Kubernetes集群被KubeSphere托管 - 第三步:建设DevOps CI/CD 流水线机制,在
KubeSphere平台中以Deployment方式建设Jenkins、Harbor、git平台一体化流水线平台 - 第四步:配置Pipeline脚本,将Jenkins集成两套
Kubernetes,使其业务功能更新迭代能正常发版上线 Devops CICD流程剖析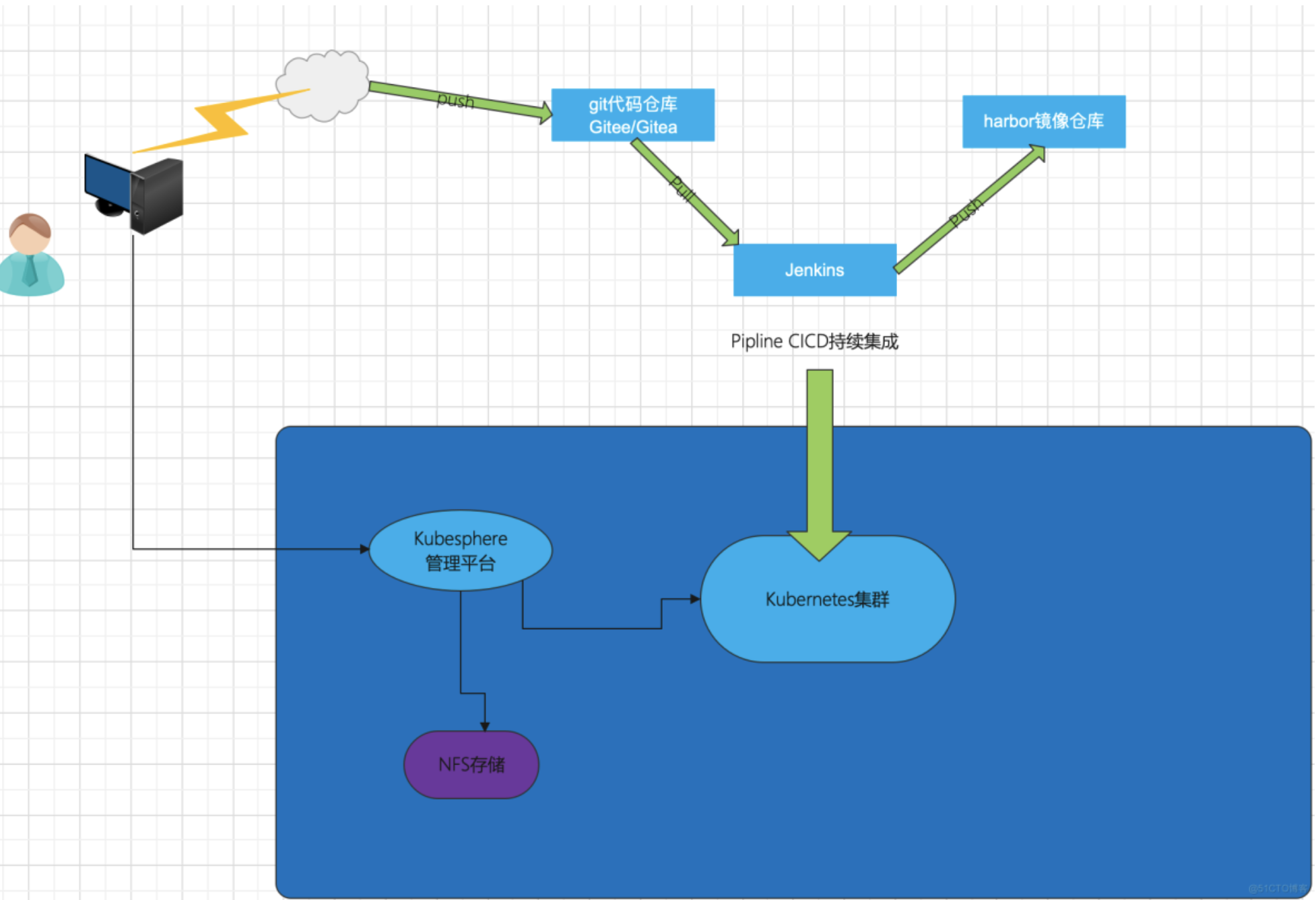 阶段 1:Checkout SCM:从 Git代码仓库检出源代码。 阶段 2:单元测试:待该测试通过后才会进行下一阶段。 阶段 3:SonarQube 分析:SonarQube 代码质量分析(可选)。 阶段 4:构建并推送快照镜像:根据策略设置中选定的分支来构建镜像,并将
阶段 1:Checkout SCM:从 Git代码仓库检出源代码。 阶段 2:单元测试:待该测试通过后才会进行下一阶段。 阶段 3:SonarQube 分析:SonarQube 代码质量分析(可选)。 阶段 4:构建并推送快照镜像:根据策略设置中选定的分支来构建镜像,并将SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER标签推送至 Docker Hub,其中$BUILD_NUMBER为流水线活动列表中的运行序号。 阶段 5:推送最新镜像:将 SonarQube 分支标记为 latest,并推送至 Harbor镜像仓库。 阶段 6:部署至开发环境:将 SonarQube 分支部署到开发环境,此阶段需要审核。 阶段 7:带标签推送:生成标签并发布到 Git,该标签会推送到 Harbor镜像仓库。 阶段 8:部署至生产环境:将已发布的标签部署到生产环境。
 阶段 1:Checkout SCM:从 Git代码仓库检出源代码。 阶段 2:单元测试:待该测试通过后才会进行下一阶段。 阶段 3:SonarQube 分析:SonarQube 代码质量分析(可选)。 阶段 4:构建并推送快照镜像:根据策略设置中选定的分支来构建镜像,并将
阶段 1:Checkout SCM:从 Git代码仓库检出源代码。 阶段 2:单元测试:待该测试通过后才会进行下一阶段。 阶段 3:SonarQube 分析:SonarQube 代码质量分析(可选)。 阶段 4:构建并推送快照镜像:根据策略设置中选定的分支来构建镜像,并将线上DevOps 流水线参考
 无状态服务在
无状态服务在KubeSphere中的服务如下图所示,包括应用层的前后端服务,另外Minio都是以Deployment方式容器部署  有状态服务主要是一些基础设施服务,如下图所示:比如MySql、Redis等,我仍然是选择采用虚机部署,RocketMQ较为特殊,选择了
有状态服务主要是一些基础设施服务,如下图所示:比如MySql、Redis等,我仍然是选择采用虚机部署,RocketMQ较为特殊,选择了Statefulset方式进行部署 
企业实战案例
1 定义Pipeline所依赖的资源文件
下面资源类需要定义在git上,当我们运行KubeSphere DevOps流水线部署环节,需要调用该yaml资源进行服务更新迭代
定义Deployment无状态副本
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: boot-preject
name: boot-preject
namespace: middleware #定义Namespace
spec:
progressDeadlineSeconds: 600
replicas: 1
selector:
matchLabels:
app: boot-preject
strategy:
rollingUpdate:
maxSurge: 50%
maxUnavailable: 50%
type: RollingUpdate
template:
metadata:
labels:
app: boot-preject
spec:
imagePullSecrets:
- name: harbor
containers:
- image: $REGISTRY/$HARBOR_NAMESPACE/boot-preject:SNAPSHOT-$BUILD_NUMBER #这里定义镜像仓库地址+kubesphere 构建变量值
imagePullPolicy: Always
name: app
ports:
- containerPort: 8080
protocol: TCP
resources:
limits:
cpu: 300m
memory: 600Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
terminationGracePeriodSeconds: 30
定义Dockerfile文件
FROM registry.cn-beijing.aliyuncs.com/devops-tols/openjdk:8-jre-alpine
MAINTAINER bxy
#ENV TZ=Asia/Shanghai
RUN mkdir /data/webserver -p
ENV LANG en_US.UTF-8
ADD start.sh /data/webserver/
RUN chmod +x /data/webserver/start.sh
#COPY agent /data/agent
ADD repo/boot-preject/spring-cloud-eureka-0.0.1-SNAPSHOT.jar /data/webserver/
#RUN apk add --update ttf-dejavu fontconfig
EXPOSE 8761
ENTRYPOINT ["/data/webserver/start.sh"]
定义java启动脚本
#vim start.sh
#!/bin/sh
echo -------------------------------------------
echo start server
echo -------------------------------------------
# JAVA_HOME
#export JAVA_HOME=/data/jdk
# 设置项目代码路径
export _EXECJAVA="$JAVA_HOME/bin/java"
JAVA_OPTS="-XX:+UseContainerSupport -XX:InitialRAMPercentage=40.0 -XX:MinRAMPercentage=20.0 -XX:MaxRAMPercentage=80.0 -XX:-UseAdaptiveSizePolicy"
#jar包 名称
JAR_NAME=`ls /data/webserver/*jar`
# 启动类
#$_EXECJAVA $JAVA_OPTS -jar -Xms512m -Xmx512m -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m -XX:+UseG1GC -XX:+PrintReferenceGC -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintCommandLineFlags -XX:+PrintFlagsFinal -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=45 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:./gclogs $JAR_NAME
$_EXECJAVA $JAVA_OPTS -jar $Xms $Xmx -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m -XX:+UseG1GC -XX:+PrintReferenceGC -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintCommandLineFlags -XX:+PrintFlagsFinal -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=45 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:./gclogs $JAR_NAME
定义流水线凭据 
2. 新建DevOps项目

2.1 创建流水线向导



2.2 自定义流水线
KubeSphere 3.3.2版本提供了已有的模版,不过我们可以尝试自己定义流水线体系  图形编辑面板包括两个区域:左侧的画布和右侧的内容。它会根据您对不同阶段和步骤的配置自动生成一个 Jenkinsfile,为开发者提供更加用户友好的操作体验
图形编辑面板包括两个区域:左侧的画布和右侧的内容。它会根据您对不同阶段和步骤的配置自动生成一个 Jenkinsfile,为开发者提供更加用户友好的操作体验
第一阶段
该阶段主要是拉取git代码环境,阶段名称命名为Pulling Code,指定maven容器,在图形编辑面板上,从类型下拉列表中选择 node,从 Label 下拉列表中选择 maven 


 引用之前定义的git凭据至流水线中,保证能正常的拉取代码仓库
引用之前定义的git凭据至流水线中,保证能正常的拉取代码仓库 
第二阶段
选择+号,开始定义代码编译环境,名称定义为Build compilation,添加步骤。  选择指定容器,这里容器名称依然是
选择指定容器,这里容器名称依然是maven。 
 增加嵌套步骤,定义代码编译命令。
增加嵌套步骤,定义代码编译命令。
mvn clean package -Dmaven.test.skip=true


mvn clean package -Dmaven.test.skip=true

第三阶段
该阶段主要是通过Dockerfile打包生成镜像的过程,同样是生成之前先指定容器,然后新增嵌套步骤,指定shell命令定义dockerfile编译过程,这里就不再赘述了, 


 shell命令如下:
shell命令如下:
mkdir -p repo/$APP_NAME
cp target/**.jar repo/${APP_NAME}
cp ./start.sh repo/${APP_NAME}
cp ./Dockerfile repo/${APP_NAME}
ls repo/${APP_NAME}
cd repo/${APP_NAME}
docker build -t boot-preject:latest .

第四阶段
该阶段主要是基于Dockerfile编译之后的镜像上传至镜像仓库中 







echo "$DOCKER_PWD_VAR" | docker login $REGISTRY -u "$DOCKER_USER_VAR" --password-stdin

选择第一个“添加嵌套步骤”

选择shell,执行docker tag 定义镜像名称

docker tag boot-preject:latest $REGISTRY/$HARBOR_NAMESPACE/boot-preject:SNAPSHOT-$BUILD_NUMBER





第五阶段
该阶段主要是部署环境,镜像上传至Harbor仓库中,就开始着手部署的工作了 在这里我们需要提前把Deployment资源定义好,通过kubectl apply -f根据定义好的文件执行即可  选择添加凭据,将我们实现定好的集群凭据引入即可。
选择添加凭据,将我们实现定好的集群凭据引入即可。 





 这里命令是指定的git事先定义完成的yaml文件 指定了存放于git代码仓库中yaml文件路径
这里命令是指定的git事先定义完成的yaml文件 指定了存放于git代码仓库中yaml文件路径
envsubst < deploy/deploy.yml | kubectl apply -f -

 以上,一个完整的流水线制作完毕。接下来我们运行即可完成编译
以上,一个完整的流水线制作完毕。接下来我们运行即可完成编译 

附上生产Jenkinsfile脚本
在这里给大家附上我本人生产Pipeline案例,可通过该Pipeline流水线,可直接应用于企业生产环境,
pipeline {
agent {
node {
label 'maven'
}
}
stages {
stage('Pulling Code') {
agent none
steps {
container('maven') {
//指定git地址
git(url: 'https://gitee.com/xxx/test-boot-projext.git', credentialsId: 'gitee', branch: 'master', changelog: true, poll: false)
sh 'ls'
}
}
}
stage('Build compilation') {
agent none
steps {
container('maven') {
sh 'ls'
sh 'mvn clean package -Dmaven.test.skip=true'
}
}
}
stage('Build a mirror image') {
agent none
steps {
container('maven') {
sh 'mkdir -p repo/$APP_NAME'
sh 'cp target/**.jar repo/${APP_NAME}'
sh 'cp ./start.sh repo/${APP_NAME}'
sh 'cp ./Dockerfile repo/${APP_NAME}'
sh 'ls repo/${APP_NAME}'
sh 'cd repo/${APP_NAME}'
sh 'docker build -t boot-preject:latest . '
}
}
}
stage('Pack and upload') {
agent none
steps {
container('maven') {
withCredentials([usernamePassword(credentialsId : 'harbor' ,passwordVariable : 'DOCKER_PWD_VAR' ,usernameVariable : 'DOCKER_USER_VAR' ,)]) {
sh 'echo "$DOCKER_PWD_VAR" | docker login $REGISTRY -u "$DOCKER_USER_VAR" --password-stdin'
sh 'docker tag boot-preject:latest $REGISTRY/$HARBOR_NAMESPACE/boot-preject:SNAPSHOT-$BUILD_NUMBER'
sh 'docker push $REGISTRY/$HARBOR_NAMESPACE/boot-preject:SNAPSHOT-$BUILD_NUMBER'
}
}
}
}
stage('Deploying to K8s') {
agent none
steps {
withCredentials([kubeconfigFile(credentialsId : 'demo-kubeconfig' ,variable : 'KUBECONFIG' )]) {
container('maven') {
sh 'envsubst < deploy/deploy.yml | kubectl apply -f -'
}
}
}
}
}
environment {
DOCKER_CREDENTIAL_ID = 'dockerhub-id' #定义docker镜像认证
GITHUB_CREDENTIAL_ID = 'github-id' #定义git代码仓库认证
KUBECONFIG_CREDENTIAL_ID = 'demo-kubeconfig' #定义kubeconfig kubectl api认证文件
REGISTRY = 'harbor.xxx.com' #定义镜像仓库地址
HARBOR_NAMESPACE = 'ks-devopos'
APP_NAME = 'boot-preject'
}
parameters {
string(name: 'TAG_NAME', defaultValue: '', description: '')
}
}
存储与网络
业务存储我们选择的是MySQl、Redis。MySQL结合Xenon实现高可用方案 MySQL  Redis
Redis 
六、预期效果
引入KubeSphere很大程度的减轻了公司研发持续集成、持续部署的负担,极大提升了整个研发团队生产里项目交付效率,研发团队只需自行在本地实现function修复Bug,之后Commit提交代码至git,然后基于Kubesphere的Devops直接点击运行,发布测试环境/生产环境的工程,此时整套CICD持续集成交付的工作流程就彻底完成了,剩余的联调工作就交给研发。 基于KubeSphere实现DevOps,给我们带来了最大的效率亮点如下:
- 平台一体化管理 在服务功能迭代方面,只需要登录KubeSphere平台,点击各自所负责的项目流水线即可,极大的减轻了部署工作量,虽说可以通过Jenkins结合Kubesphere,同样能实现项目交付工作,但整套流程相对繁琐,既要关注Jenkins平台的构建情况,同时也要关注Kubesphere 交付结果;造成了诸多不便,也背离的了我们交付的初衷
- 资源利用率显著提高 KubeSphere和Kubernetes相结合,进一步优化了系统资源利用率,降低了使用成本,最大限度增加了DevOps资源利用率
七、未来规划(改进)
从目前来看,通过这次生产项目中引入KubeSphere云原生平台实践,发现确实给我们解决了微服务部署和管理的了问题,极大的提高我们的便捷性。负载均衡、应用路由、自动扩缩容、DevOps等等,都能对我们Kubernetes产生极大的推进,未来继续深耕云原生以及Kubernetes容器化领域,继续推进现有业务容器化,去拥抱云原生这个生态圈,为我们的业务保驾护航。 同时,对于 KubeSphere,我个人也有一些建议:
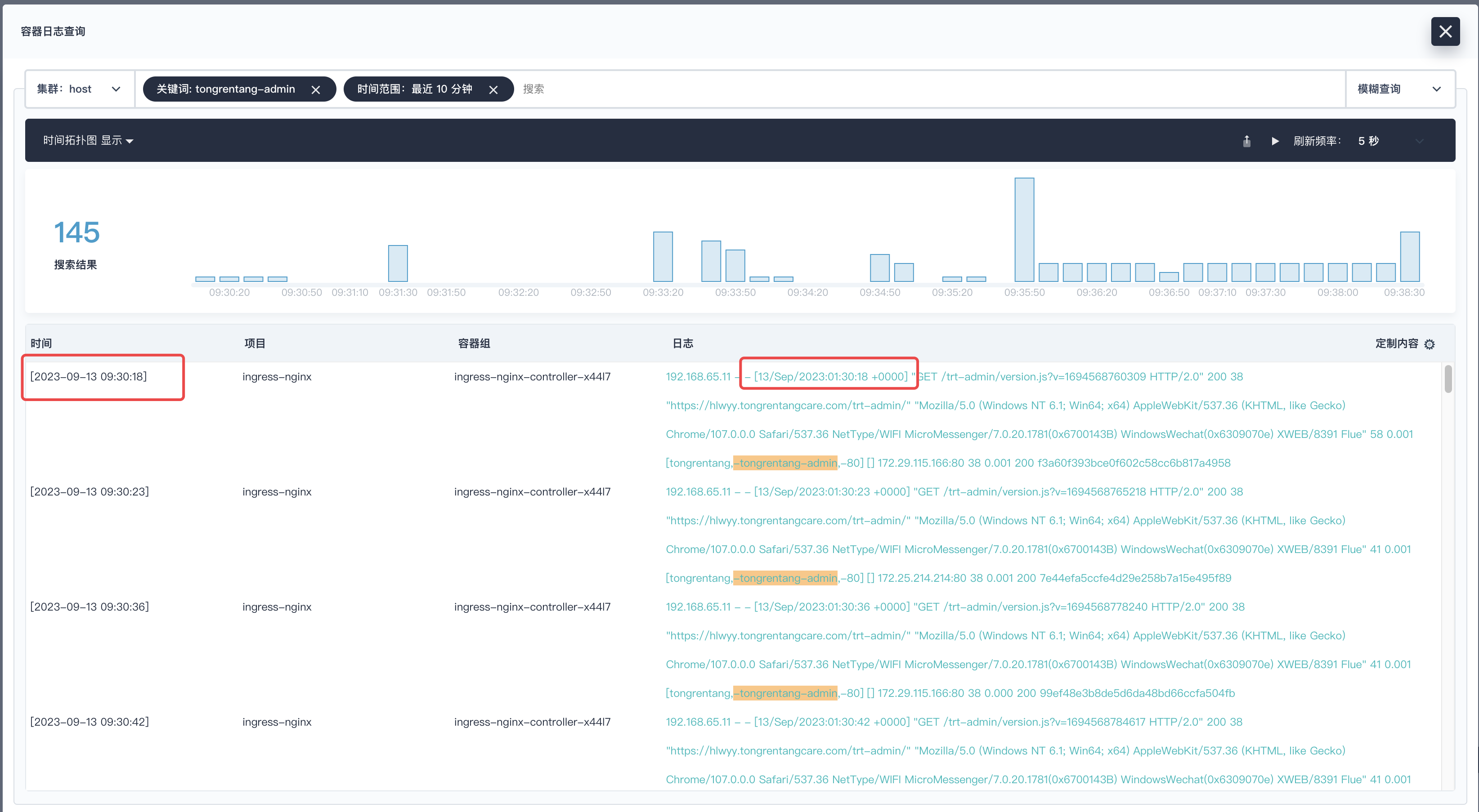
KubeSphere日志功检索方面需要优化改进一些,比如我们需要检索某一时间段范围的日志信息,发现最左侧的时间戳和日志内容本身时间戳对应不上,另外导出的日志的时间戳也不符合预期,这对我们分析日志定位问题造成很大的困扰和不便。